Unicode
Der Unicode-Standard (Aussprachen: amerikanisches Englisch [ˈjuːnikoʊd], britisches Englisch [ˈjuːnikəʊd]; dt. [ˈjuːnikoːt]) legt fest, wie Schrift elektronisch gespeichert wird, z. B. auf einem Computer oder Telefon. Der durch den Standard festgelegte Zeichensatz enthält 145'000 Zeichen. Das Unicode-Konsortium hat dazu 159 moderne und alte Schriften berücksichtigt, wie auch Symbole, Emojis und nicht druckbare Steuerzeichen. Die ISO bezeichnet den Standard als ISO 10646 und den Zeichensatz als Universal Coded Character Set (UCS).
Unicode muss auch tatsächlich in Nullen und Einsen übersetzt werden. Eine solche Umwandlung wird als Unicode Transformation Format (UTF) bezeichnet. Durchgesetzt hat sich dabei UTF-8. In einigen Fällen ist auch noch UTF-16 anzutreffen, speziell in Betriebssystemen und Programmiersprachen, da eine Umstellung nicht einfach ist.
Geschichte
Herkömmliche Computer-Zeichensätze umfassen nur einen begrenzten Vorrat an Zeichen, bei westlichen Zeichenkodierungen liegt diese Grenze meistens bei 128 (7 Bit) Codepositionen – wie bei dem sehr bekannten ASCII-Standard – oder 256 (8 Bit) Positionen, wie z. B. bei ISO 8859-1 (auch als Latin-1 bekannt) oder EBCDIC. Davon sind nach Abzug der Steuerzeichen 95 Elemente bei ASCII und 191 Elemente bei den 8-Bit ISO-Zeichensätzen als Schrift- und Sonderzeichen darstellbar. Diese Zeichenkodierungen erlauben die gleichzeitige Darstellung nur weniger Sprachen im selben Text, wenn man sich nicht damit behilft, in einem Text verschiedene Schriften mit unterschiedlichen Zeichensätzen zu verwenden. Das behinderte den internationalen Datenaustausch in den 1980er und 1990er Jahren erheblich.
ISO 2022[1] war ein erster Versuch, mehrere Sprachen mit nur einer Zeichenkodierung darstellen zu können. Die Kodierung benutzt Escape-Sequenzen, um zwischen verschiedenen Zeichensätzen (z. B. zwischen Latin-1 und Latin-2) wechseln zu können. Das System setzte sich jedoch nur in Ostasien durch.[2]
Joseph D. Becker von Xerox schrieb 1988 den ersten Entwurf für einen universalen Zeichensatz. Dieser 16-Bit-Zeichensatz sollte nach den ursprünglichen Plänen lediglich die Zeichen moderner Sprachen kodieren:
“Unicode gives higher priority to ensuring utility for the future than to preserving past antiquities. Unicode aims in the first instance at the characters published in modern text (e.g. in the union of all newspapers and magazines printed in the world in 1988), whose number is undoubtedly far below 214 = 16,384. Beyond those modern-use characters, all others may be defined to be obsolete or rare, these are better candidates for private-use registration than for congesting the public list of generally-useful Unicodes.”
„Unicode legt größeren Wert darauf, die Verwendbarkeit für die Zukunft sicherzustellen, als vergangene Altertümlichkeiten zu erhalten. Unicode zielt in erster Linie auf alle Zeichen, die in modernen Texten veröffentlicht werden (etwa in allen Zeitungen und Zeitschriften der Welt des Jahres 1988), deren Anzahl zweifelsfrei weit unter 214 = 16.384 liegt. Weitere Zeichen, die über diese heutigen Zeichen hinausgehen, können als veraltet oder selten erachtet werden, diese sollten besser über einen privaten Modus registriert werden, statt die öffentliche Liste der allgemein nützlichen Unicodes zu überfüllen.“
Im Oktober 1991[4] wurde nach mehrjähriger Entwicklungszeit die Version 1.0.0 des Unicode-Standards veröffentlicht, die damals nur die europäischen, nahöstlichen und indischen Schriften kodierte.[5] Erst acht Monate später, nachdem die Han-Vereinheitlichung abgeschlossen war, erschien Version 1.0.1, die erstmals ostasiatische Zeichen kodierte. Mit der Veröffentlichung von Unicode 2.0 im Juli 1996 wurde der Standard von ursprünglich 65.536 auf die heutigen 1.114.112 Codepunkte, von U+0000 bis U+10FFFF erweitert.[6]
Versionen
| Version | Datum | Schriftsysteme | Zeichen | Erweiterungen |
|---|---|---|---|---|
| 1.0.0[7] | Oktober 1991 | 24 | 7.161 | Erste Version: Arabisch, Armenisch, Bengalisch, Bopomofo, Kyrillisch, Devanagari, Georgisch, Griechisch und Koptisch, Gujarati, Gurmukhi, Hangul, Hebräisch, Hiragana, Kannada, Katakana, Laotisch, Lateinisch, Malayalam, Oriya, Tamilisch, Telugu, Thailändisch und Tibetisch; Währungszeichen |
| 1.0.1[8] | Juni 1992 | 25 | 28.359 | Vereinheitlichte chinesisch-japanisch-koreanische Schriftzeichen (CJK-Schriftzeichen; siehe auch Unicodeblock Vereinheitlichte CJK-Ideogramme) |
| 1.1[9] | Juni 1993 | 24 | 34.233 | Zusätzliche koreanische Silbenzeichen, Entfernung der tibetischen Schrift aus dem Standard,[10] Dingbats, langes s |
| 2.0[11] | Juli 1996 | 25 | 38.950 | Neuer Unicodeblock für Hangeul-Silbenzeichen, Wiedereinführung der tibetischen Schrift[10] |
| 2.1[12] | Mai 1998 | 25 | 38.952 | Eurozeichen sowie ein Objektersetzungszeichen |
| 3.0[13] | September 1999 | 38 | 49.259 | Syrisches Alphabet, Thaana-Alphabet, singhalesische Schrift, birmanische Schrift, äthiopische Schrift, Cherokee-Alphabet, Cree-Schrift, Ogham, Runen, Khmer-Schrift, mongolische Schrift, Brailleschrift, Yi, zusätzliche CJK-Schriftzeichen |
| 3.1[14] | März 2001 | 41 | 94.205 | Altitalisches Alphabet, gotisches Alphabet, Deseret-Alphabet, Notenschrift, weitere CJK-Schriftzeichen |
| 3.2[15] | März 2002 | 45 | 95.221 | Baybayin, Hanunó'o, Buid-Schrift, Tagbanuwa-Schrift |
| 4.0[16] | April 2003 | 52 | 96.447 | Limbu-Schrift, Tai Nüa, Linearschrift B, ugaritische Schrift, Shaw-Alphabet, Osmaniya-Schrift, kyprische Schrift |
| 4.1[17] | März 2005 | 59 | 97.720 | Koptische Schrift (als eigenständig vom griechischen Alphabet), Tai Lü, Lontara, glagolitische Schrift, Nuschuri, Tifinagh-Schrift, Sylheti Nagari, Persische Keilschrift, Kharoshthi-Schrift |
| 5.0[18] | Juli 2006 | 64 | 99.089 | N’Ko, balinesische Schrift, Phagpa-Schrift, phönizische Schrift, Keilschrift |
| 5.1[19] | April 2008 | 75 | 100.713 | Sundanesische Schrift, Lepcha-Schrift, Ol Chiki, Vai-Schrift, Saurashtri-Schrift, Kayah Li, Rejang-Schrift, Cham-Schrift, lykische Schrift, karische Schrift, lydische Schrift, großes ß |
| 5.2[20] | Oktober 2009 | 90 | 107.361 | Samaritanische Schrift, Lanna-Schrift, Fraser-Alphabet, Bamun-Schrift, javanische Schrift, Tai-Viet-Schrift, Meitei-Mayek, aramäische Schrift, altsüdarabische Schrift, avestische Schrift, parthische Schrift, Pahlavi-Schrift, Orchon-Runen, Kaithi-Schrift, ägyptische Hieroglyphen, zusätzliche CJK-Schriftzeichen |
| 6.0[21] | Oktober 2010 | 93 | 109.242 | Batak-Schrift, Brahmi-Schrift, mandäische Schrift, Emoji |
| 6.1[22] | Januar 2012 | 100 | 110.181 | Meroitische Schrift, Sora-Sompeng, Chakma-Schrift, Sharada-Schrift, Takri-Schrift, Pollard-Schrift |
| 6.2[23] | September 2012 | 100 | 110.182 | Währungszeichen der türkischen Lira |
| 6.3[24] | September 2013 | 100 | 110.187 | 5 weitere bidirektionale Steuerzeichen mit Änderungen des Unicode-Bidi-Algorithmus, Variantenselektoren für CJK-Kompatibilitätsideogramme, verbesserter hebräischer Wortumbruch und CJK-Zeilenumbruch |
| 7.0[25] | Juni 2014 | 123 | 113.021 | Währungssymbole für Manat und Rubel, Lautschriftzeichen für Teuthonista und andere in der deutschen Dialektologie verwendete Schriftzeichen, piktografische Symbole, Altnordarabische Schrift, Altpermische Schrift, Bassa-Schrift, Duployé-Kurzschrift, Elbasan-Schrift, Grantha-Schrift, Kaukasisch-Albanische Schrift, Khojki-Schrift, Khudabadi-Schrift, Linearschrift A, Mahajani-Schrift, Manichäische Schrift, Mende-Schrift, Modi-Schrift, Mro-Schrift, Nabatäische Schrift, Pahawh Hmong, Palmyrenische Schrift, Pau Cin Hau, Psalter-Pahlavi, Siddham, Tirhuta, Warang Citi |
| 8.0[26] | Juni 2015 | 129 | 120.737 | Kleinbuchstaben des Cherokee-Alphabets, 5771 weitere CJK-Zeichen, 41 weitere Emoji, Währungssymbol für den georgischen Lari, Ziffernformen für das Duodezimalsystem, Schriftzeichen für Icetot, Ahom-Schrift, Anatolische Hieroglyphen, Hatran-Schrift, Altungarische Schrift, Multani-Schrift, SignWriting |
| 9.0[27] | Juni 2016 | 135 | 128.172 | Schriften für Osage, Newari, Fulfulde, Swahili-Dialekt von Baraawe, Warsh-Variante des Arabischen, Tangut (Xixia-Schrift), sowie 72 neue Emoji und 19 Symbole für Ultra High Definition Television |
| 10.0[28] | Juni 2017 | 139 | 136.690 | Schriften für Gondi, Nüshu, Hentaigana, sowie 56 neue Emoji und das Bitcoin-Symbol |
| 11.0[29] | Juni 2018 | 146 | 137.374 | Schriften für Dogri, Makassar-Sprache, Medefaidrin, Sogdische Sprache, Hanifi Rohingya, Gondi, Mtavruli, sowie 66 neue Emoji |
| 12.0[30] | März 2019 | 150 | 137.928 | Schriften für Elymäisch, Nagari, Hmong und Miao, sowie 61 neue Emoji. |
| 12.1[31] | Mai 2019 | 150 | 137.929 | Ein neues Zeichen für die Reiwa-Zeit wurde hinzugefügt. |
| 13.0[32] | März 2020 | 154 | 143.859 | Schriften für Choresmische Sprache, Dives Akuru, Khitan Small Script, Jesidisch, sowie 55 neue Emoji. |
| 14.0[33] | September 2021 | 159 | 144.697 | Schriften für Cypro-Minoan, Old Uyghur, Vithkuqi, Tangsa, Toto, sowie 37 neue Emoji. |
Die Veröffentlichung neuer Versionen zieht sich teilweise über einen längeren Zeitraum hin, sodass zum Veröffentlichungszeitpunkt zunächst nur die Zeichentabellen und einzelne Teile der Spezifikation fertig sind, während die endgültige Veröffentlichung der Hauptspezifikation erst einige Zeit später erfolgt.
Inhalt des Standards
Das Unicode-Konsortium stellt mehrere Dokumente zur Unterstützung von Unicode bereit. Neben dem eigentlichen Zeichensatz sind dies des Weiteren auch andere Dokumente, die zwar nicht zwingend notwendig, aber dennoch hilfreich zur Interpretation des Unicode-Standards sind.
Gliederung
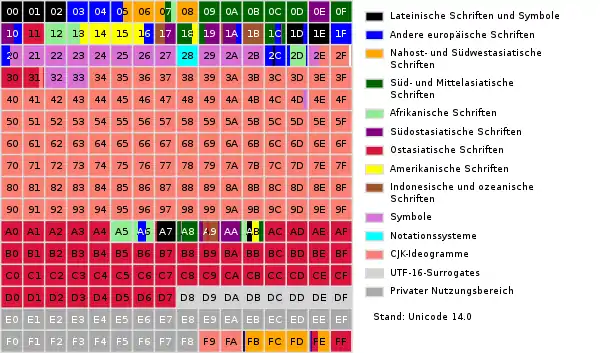
Im Gegensatz zu früheren Zeichenkodierungen, die meist nur ein bestimmtes Schriftsystem kodierten, ist es das Ziel von Unicode, alle in Gebrauch befindlichen Schriftsysteme und Zeichen zu kodieren.[34] Der Zeichenumfang ist dazu in 17 Ebenen (englisch planes) gegliedert, welche jeweils 216 = 65.536 Codepoints umfassen.[35] Sechs dieser Ebenen werden bereits verwendet, die restlichen sind für spätere Nutzung reserviert:
- Die Basic Multilingual Plane (BMP; deutsch Mehrsprachige Basis-Ebene, auch als Plane 0 bezeichnet) enthält hauptsächlich Schriftsysteme, die aktuell in Gebrauch sind, Satzzeichen und Symbole, Kontrollzeichen und Surrogate-Paare, und einen privat nutzbaren Bereich (PUA).[35] Die Ebene ist stark fragmentiert und weitgehend belegt, sodass neu zu codierende Schriftsysteme hier keinen Platz mehr finden. Der Zugriff auf andere Ebenen als der BMP ist in manchen Programmen noch nicht oder nur eingeschränkt möglich.
- Die Supplementary Multilingual Plane (SMP; dt. Ergänzende mehrsprachige Ebene, auch als Plane 1 bezeichnet) wurde mit Unicode 3.1 eingeführt. Sie enthält vor allem historische Schriftsysteme, aber auch größere Ansammlungen an Zeichen, die selten in Gebrauch sind, wie z. B. Domino- und Mah-Jonggsteine und Emoji. Mittlerweile werden auch Schriftsysteme in der SMP codiert, die noch in Benutzung sind, aber in der BMP keinen Platz mehr finden.[35]
- Die Supplementary Ideographic Plane (SIP; dt. Ergänzende ideographische Ebene, auch als Plane 2 bezeichnet), die ebenfalls mit Unicode 3.1 eingeführt wurde, enthält ausschließlich CJK-Schriftzeichen, die selten benutzt werden, dazu zählen unter anderem auch die Chữ Nôm, die früher in Vietnam benutzt wurden.[35] Sollte diese Ebene dafür nicht ausreichen, ist Plane 3 für weitere CJK-Schriftzeichen reserviert.[36]
- Die Supplementary Special-purpose Plane (SSP; dt. Ergänzende Ebene für spezielle Verwendungen, auch als Plane 14 bezeichnet) enthält einige wenige Kontrollzeichen zur Sprachmarkierung.[35]
- Die letzten beiden Ebenen, jeweils Supplementary Private Use Area-A und -B (PUA; auch Plane 15 und Plane 16), stehen als privat nutzbare Bereiche (PUA) zur Verfügung.[37] Sie werden teilweise auch als Private Use Planes[38] (PUP) bezeichnet.
Innerhalb dieser Ebenen werden zusammengehörende Zeichen in Blöcken (engl. blocks) zusammengefasst. Meist behandelt ein Unicodeblock ein Schriftsystem, aus historischen Gründen hat sich allerdings ein gewisses Maß an Fragmentierung eingestellt. Oft wurden später noch Zeichen hinzugefügt und in anderen Blöcken als Ergänzung untergebracht.[37]
Codepunkte und Zeichen
Jedes im Unicode-Standard codierte elementare Zeichen ist einem Codepunkt (engl. code points) zugeordnet. Diese werden üblicherweise hexadezimal (mindestens vierstellig, d. h. ggf. mit führenden Nullen) und mit einem vorangestellten U+ dargestellt, z. B. U+00DF für das ß.[39]
Der gesamte vom Unicode-Standard beschriebene Bereich umfasst 1.114.112 Codepunkte (U+0000 … U+10FFFF, 17 Ebenen zu je 216, d. h. 65536 Zeichen). Davon lässt der Standard jedoch für einige Bereiche die Verwendung zur Zeichenkodierung nicht zu:
- 2048 Codepunkte im Bereich U+D800 … U+DFFF werden als Teile von Surrogate-Paaren im Kodierungsschema UTF-16 zur Darstellung von Codepunkten oberhalb der BMP (also im Bereich U+10000 … U+10FFFF) verwendet und stehen deshalb nicht selbst als Codepunkt für einzelne Zeichen zur Verfügung.
- 66 Codepunkte, 32 im Bereich U+FDD0 … U+FDEF sowie je 2 am Ende jeder der 17 Ebenen (also U+FFFE, U+FFFF, U+1FFFE, U+1FFFF, …, U+10FFFE, U+10FFFF) sind für process-internal uses reserviert und nicht für die Verwendung als einzelne Zeichen vorgesehen.
Somit stehen für die Zeichencodierung insgesamt 1.111.998 Codepunkte zur Verfügung. Die Anzahl der tatsächlich zugewiesenen Codepunkte ist jedoch deutlich niedriger; eine Übersicht, wie viele Codepunkte in den verschiedenen Versionen jeweils zugewiesen sind und wofür sie genutzt werden, bieten die Tabellen D-2 und D-3 im Anhang D des Unicode-Standards.[40]
PUA (Private Use Area privat nutzbarer Bereich)
Spezielle Bereiche sind für private Nutzung reserviert, d. h. in diesen werden niemals Codepunkte für in Unicode standardisierte Zeichen zugewiesen. Diese können für privat definierte Zeichen verwendet werden, die zwischen den Erzeugern und Verwendern der Texte, die sie enthalten, individuell abgesprochen sein müssen. Diese Bereiche sind:
- in der BMP: U+E000 … U+F8FF
- in anderen Ebenen: U+F0000 … U+FFFFD und U+100000 … U+10FFFD
Es haben sich für verschiedene Anwendungen spezielle Konventionen entwickelt, die speziell für den PUA-Bereich der BMP Zeichenbelegungen vorgeben. Zum einen finden sich hier häufig precomposed characters aus Grundzeichen und diakritischen Zeichen, da in vielen (speziell älteren) Software-Anwendungen nicht davon ausgegangen werden kann, dass solche Zeichen gemäß den Unicode-Regeln bei Eingabe als Folge aus Grundzeichen und diakritischem Zeichen korrekt dargestellt werden. Zum anderen finden sich Zeichen, die nicht den Regeln für eine Aufnahme in Unicode entsprechen, oder deren Beantragung zur Aufnahme in Unicode aus anderen Gründen erfolglos war oder unterblieb. So findet sich in vielen Fonts auf der Position U+F000 ein Hersteller-Logo (Logos werden in Unicode prinzipiell nicht codiert).
Quellen für PUA-Zeichen sind z. B.:
- MUFI (Medieval Unicode Font Initiative)[41]
- SIL PUA für Sonderbuchstaben diverser Minderheitensprachen weltweit[42]
- Languagegeek für indigene Sprachen Nordamerikas[43]
- ConScript[44] für erfundene Schriftsysteme wie Klingonisch
Kodierung
Neben dem eigentlichen Zeichensatz sind auch eine Reihe von Zeichenkodierungen definiert, die den Unicode-Zeichensatz implementieren und die benutzt werden können, um den vollen Zugriff auf alle Unicode-Zeichen zu haben. Sie werden Unicode Transformation Format (kurz UTF) genannt; am weitesten verbreitet sind zum einen UTF-16, das sich als interne Zeichendarstellung einiger Betriebssysteme (Windows,[45] OS X) und Softwareentwicklungs-Frameworks (Java,[46] .NET[47]) etabliert hat, zum anderen UTF-8, das ebenfalls in Betriebssystemen (GNU/Linux, Unix) sowie in verschiedenen Internetdiensten (E-Mail, WWW) eine große Rolle spielt. Basierend auf dem proprietären EBCDIC-Format von IBM-Großrechnern ist die UTF-EBCDIC-Kodierung definiert. Punycode dient dazu, Domainnamen mit Nicht-ASCII-Zeichen zu kodieren. Mit dem Standard Compression Scheme for Unicode existiert ein Kodierungsformat, das die Texte gleichzeitig komprimiert. Weitere Formate zur Kodierung von Unicode-Zeichen sind u. a. CESU-8 und GB 18030.
Normalisierung
Viele Zeichen, die im Unicode-Standard enthalten sind, sind sogenannte Kompatibilitätszeichen, die aus Unicode-Sicht bereits mit anderen in Unicode kodierten Zeichen bzw. Zeichensequenzen dargestellt werden können, so z. B. die deutschen Umlaute, die theoretisch mit einer Sequenz aus dem Basisbuchstaben und einem kombinierenden Trema (horizontaler Doppelpunkt) dargestellt werden können. Bei der Unicode-Normalisierung werden die Kompatibilitätszeichen automatisch durch die in Unicode vorgesehenen Sequenzen ersetzt. Dies erleichtert die Verarbeitung von Unicode-Texten erheblich, da so nur eine mögliche Kombination für ein bestimmtes Zeichen steht, und nicht mehrere verschiedene.
Sortierung
Für viele Schriftsysteme sind die Zeichen in Unicode nicht in einer Reihenfolge codiert, die einer bei den Anwendern dieses Schriftsystems üblichen Sortierung entspricht. Deshalb kann bei einer Sortierung z. B. in einer Datenbankanwendung üblicherweise nicht die Reihenfolge der Codepunkte verwendet werden. Außerdem sind die Sortierungen in vielen Schriftsystemen von komplexen, kontextabhängigen Regelungen geprägt. Hier definiert der Unicode Collation Algorithm, wie Zeichenfolgen innerhalb eines bestimmten Schriftsystems oder auch schriftsystemübergreifend sortiert werden können.
In vielen Fällen ist jedoch die tatsächlich anzuwendende Reihenfolge von anderen Faktoren (z. B. der verwendeten Sprache) abhängig (z. B. sortiert „ä“ im Deutschen anwendungsabhängig wie „ae“ oder „a“, im Schwedischen jedoch hinter „z“ und „å“), sodass der Unicode-Sortierungsalgorithmus dann anzuwenden ist, wenn die Sortierung nicht von spezielleren Rahmenbedingungen bestimmt wird.
Normierungsinstitutionen
Das gemeinnützige Unicode-Konsortium wurde 1991 gegründet und ist für den Industriestandard Unicode verantwortlich. Von der ISO (Internationale Organisation für Normung) wird in Zusammenarbeit mit IEC die internationale Norm ISO 10646 herausgegeben. Beide Institutionen arbeiten eng zusammen. Seit 1993 sind Unicode und ISO 10646 bezüglich der Zeichenkodierung praktisch identisch. Während ISO 10646 lediglich die eigentliche Zeichenkodierung festlegt, gehört zum Unicode ein umfassendes Regelwerk, das unter anderem für alle Zeichen weitere zur konkreten Anwendung wichtige Eigenschaften (sogenannte Properties) eindeutig festlegt wie Sortierreihenfolge, Leserichtung und Regeln für das Kombinieren von Zeichen.[48]
Seit einiger Zeit entspricht der Codeumfang von ISO 10646 exakt dem von Unicode, da auch dort der Codebereich auf 17 Ebenen, darstellbar mit 21 Bit, beschränkt wurde.[49]
Kodierungskriterien
Gegenüber anderen Normen gibt es bei Unicode die Besonderheit, dass einmal kodierte Zeichen niemals wieder entfernt werden, um die Langlebigkeit digitaler Daten zu gewährleisten.[50] Sollte sich die Normierung eines Zeichens nachträglich als Fehler erweisen, wird allenfalls von seiner Verwendung abgeraten. Daher bedarf die Aufnahme eines Zeichens in den Standard einer äußerst sorgfältigen Prüfung, die sich über Jahre hinziehen kann.
Im Unicode werden lediglich „abstrakte Zeichen“ (englisch: characters) kodiert, nicht dagegen die grafische Darstellung (Glyphen) dieser Zeichen, die von Schriftart zu Schriftart extrem unterschiedlich ausfallen kann, beim lateinischen Alphabet etwa in Form der Antiqua, Fraktur, der irischen Schrift oder der verschiedenen Handschriften.[51] Für Glyphenvarianten, deren Normierung als sinnvoll und notwendig nachgewiesen wird, sind dabei allerdings vorsorglich 256 „Variation Selectors“ reserviert, die ggf. dem eigentlichen Code nachgestellt werden können. In vielen Schriftsystemen können Zeichen außerdem je nach Position unterschiedliche Formen annehmen oder Ligaturen bilden. Von Ausnahmen abgesehen (z. B. Arabisch) werden solche Varianten ebenfalls nicht in den Unicode-Standard übernommen, sondern es wird eine sogenannte Smartfont-Technik wie OpenType vorausgesetzt, die die Formen angemessen ersetzen kann.
Andererseits werden identische Glyphen, wenn sie verschiedene Bedeutungen haben, auch mehrfach kodiert, etwa die Glyphen А, В, Е, K, М, Н, О, Р, Т und Х, die – mit zum Teil unterschiedlicher Bedeutung – sowohl im lateinischen als auch im griechischen und kyrillischen Alphabet vorkommen.
In Grenzfällen wird hart um die Entscheidung gerungen, ob es sich um Glyphenvarianten oder tatsächlich unterschiedliche, einer eigenen Kodierung würdige Zeichen (Grapheme) handelt. Beispielsweise sind nicht wenige Fachleute der Meinung, man könne das phönizische Alphabet als Glyphenvarianten des hebräischen Alphabets betrachten, da der gesamte Zeichenvorrat des Phönizischen dort eindeutige Entsprechungen hat und auch beide Sprachen sehr eng miteinander verwandt sind. Letztlich durchgesetzt hat sich allerdings schließlich die Auffassung, es handele sich um separate Zeichensysteme, in der Unicode-Terminologie „scripts“ genannt.[52]
Anders verhält es sich bei CJK (Chinesisch, Japanisch und Koreanisch): Hier haben sich in den letzten Jahrhunderten die Formen vieler gleichbedeutender Schriftzeichen auseinanderentwickelt. Dennoch teilen sich die sprachspezifischen Glyphen dieselben Codes im Unicode (mit Ausnahme einiger Zeichen aus Kompatibilitätsgründen). In der Praxis werden hier überwiegend sprachspezifische Schriftarten verwendet, wodurch der Platzbedarf der Schriften zusammen hoch ist. Die einheitliche Kodierung der CJK-Schriftzeichen (Han Unification) war eine der wichtigsten und umfangreichsten Vorarbeiten für die Entwicklung von Unicode. Besonders in Japan ist sie durchaus umstritten.
Als der Grundstein für Unicode gelegt wurde, musste berücksichtigt werden, dass bereits eine Vielzahl unterschiedlicher Kodierungen im Einsatz waren. Unicode-basierte Systeme sollten herkömmlich kodierte Daten mit geringem Aufwand handhaben können. Dazu wurde für die unteren 256 Zeichen die weit verbreitete ISO-8859-1-Kodierung (Latin1) ebenso wie die Kodierungsarten verschiedener nationaler Normen beibehalten, z. B. TIS-620 für Thailändisch (fast identisch mit ISO 8859-11) oder ISCII für indische Schriften, die in der ursprünglichen Reihenfolge lediglich in höhere Bereiche verschoben wurden.
Jedes Zeichen maßgeblicher überkommener Kodierungen wurde in den Standard übernommen, auch wenn es den normalerweise angelegten Maßstäben nicht gerecht wird. Hierbei handelt es sich zu einem großen Teil um Zeichen, die aus zwei oder mehr Zeichen zusammengesetzt sind, wie Buchstaben mit diakritischen Zeichen. Im übrigen verfügt auch heute noch ein großer Teil der Software nicht über die Möglichkeit, Zeichen mit Diakritika ordentlich zusammenzusetzen. Die exakte Festlegung von äquivalenten Kodierungen ist Teil des zum Unicode gehörenden umfangreichen Regelwerks.
Darüber hinaus gibt es viele Unicode-Zeichen, denen keine Glyphe zugeordnet ist und die trotzdem als „characters“ behandelt werden. So sind neben Steuerzeichen wie dem Tabulatorzeichen (U+0009), dem Zeilenvorschub (U+000A) usw. allein 19 verschiedene Zeichen explizit als Leerzeichen definiert, sogar solche ohne Breite, die u. a. für Sprachen wie Thai, die ohne Wortzwischenraum geschrieben werden, als Worttrenner eingesetzt werden. Für bidirektionalen Text, z. B. Arabisch mit Lateinisch, sind sieben Formatierungszeichen kodiert. Darüber hinaus gibt es weitere unsichtbare Zeichen, die nur unter bestimmten Umständen ausgewertet werden sollen, etwa der Combining Grapheme Joiner.
Verwendung auf Computersystemen
Microsoft Windows
Unter Windows (ab Windows 2000) kann in einigen Programmen (genauer in RichEdit-Feldern) der Code dezimal als Alt+<dezimales Unicode> (bei eingeschaltetem Num-Lock) auf dem numerischen Tastaturfeld eingegeben werden. Dabei ist jedoch zu beachten, dass Zeichennummern kleiner als 1000 um eine führende Null zu ergänzen sind (z. B. Alt+0234 für Codepoint 23410 [ê]). Diese Maßnahme ist notwendig, da die (immer noch in Windows verfügbare) Eingabemethode Alt+<ein- bis dreistellige dezimale Zeichennummer ohne führende Null> bereits in MS-DOS-Zeiten genutzt wurde, um die Zeichen der Codepage 850 (vor allem bei früheren MS-DOS-Versionen auch Codepage 437) einzugeben.
Eine weitere Eingabemethode setzt voraus, dass in der Registrierungsdatenbank im Schlüssel HKEY_CURRENT_USER\Control Panel\Input Method ein Eintrag (Wert) vom Typ REG_SZ („Zeichenfolge“) namens EnableHexNumpad existiert und ihm der Wert (das Datum) 1 zugewiesen ist. Nach dem Editieren der Registry müssen Benutzer sich unter Windows 8.1, Windows 8, Windows 7 und Vista vom Windows-Benutzerkonto ab- und wieder anmelden, bei früheren Windows-Versionen ist ein Neustart des Rechners notwendig, damit die Änderungen in der Registry wirksam werden.
Danach können Unicode-Zeichen wie folgt eingegeben werden: Zuerst die (linke) Alt-Taste drücken und halten, dann auf dem Ziffernblock die Plus-Taste drücken und wieder loslassen und anschließend den hexadezimalen Code des Zeichens eingeben, wobei für Ziffern der Ziffernblock verwendet werden muss. Abschließend die Alt-Taste wieder loslassen.
Zwar funktioniert diese Eingabemethode prinzipiell in jedem Eingabefeld jedes Windows-Programms, allerdings kann es vorkommen, dass Schnellzugriffstasten für Menüfunktionen die Eingabe hexadezimaler Codepunkte verhindern: Will man beispielsweise den Buchstaben Ø (U+00D8) eingeben, so führt die Kombination Alt+D in vielen Programmen dazu, dass stattdessen das Menü Datei geöffnet wird.
Ein weiterer Nachteil besteht darin, dass Windows hier die explizite Angabe der (intern in Windows verwendeten) UTF-16-Codierung statt der Unicode-Kodierung selbst verlangt[53] und daher nur die Eingabe vierstelliger Codewerte zulässt; für Zeichen, die oberhalb der BMP liegen und über Codepunkte mit fünf- oder sechsstelliger Hexadezimaldarstellung verfügen, sind stattdessen sogenannte Surrogate Pairs zu verwenden, bei denen ein fünf- oder sechsstelliger Codepunkt auf zwei je vierstellige Ersatzcodepunkte abgebildet wird. So ist etwa der Violinschlüssel 𝄞 (U+1D11E) als hexadezimales UTF-16-Wertpaar D834 und DD1E einzugeben; eine direkte Eingabe fünf- oder sechsstelliger Codepunkte ist hier also nicht möglich.
Apple macOS
Bei Apple macOS muss die Eingabe von Unicode-Zeichen als Sonderfall zuerst über die Systemeinstellungen „Tastatur“ aktiviert werden.[54] Hierzu ist im Dialog Registerkarte „Eingabequellen“ über das Plus-Symbol die „Unicode-Hex-Eingabe“ hinzuzufügen. Diese befindet sich unter dem Oberpunkt „Andere“. Danach kann der Unicode-Wert bei gedrückter ⌥Option-Taste mit dem vierstelligen Hex-Code des Unicode-Zeichens eingegeben werden; sollte der Hexcode kleiner als vierstellig sein, so müssen führende Nullen eingegeben werden.[54] Sollte der Hexcode fünfstellig sein, so ist keine unmittelbare Eingabe per Tastatur möglich und es muss über den Dialog „Zeichenübersicht“ ausgewählt werden.[55] Wenn die Unicode-Hex-Eingabe aktiviert ist, dann liegt keine deutschsprachige Tastaturbelegung vor (u. a. für Umlaute), so dass zwischen beiden Tastatur-Modi gewechselt werden muss. Der jeweilige Status der Tastaturbelegung lässt sich per Zusatzoption in der Menüzeile einblenden.[55]
Microsoft Office und LibreOffice
Unter Microsoft Office (ab Office XP) kann Unicode auch hexadezimal eingegeben werden, indem im Dokument <Unicode> oder U+<Unicode> eingetippt wird und anschließend die Tastenkombination Alt+c, bzw. in Dialogfeldern Alt+x, gedrückt wird. Diese Tastenkombination kann auch benutzt werden, um den Code des vor dem Cursor stehenden Zeichens anzuzeigen.[56] (LibreOffice hat eine ähnliche Funktion mit der Tastenkombination Alt+c oder Alt+x[57].) Eine alternative Möglichkeit, welche auch in älteren Versionen funktioniert, ist, mit „Einfügen“ – „Sonderzeichen“ eine Tabelle mit Unicode-Zeichen aufzurufen, darin mit dem Cursor ein gewünschtes auszusuchen und in den Text einzufügen. Das Programm ermöglicht auch, für häufiger benötigte Zeichen Makros festzulegen, die dann mit einer Tastenkombination abgerufen werden können.
Qt und GTK+
GTK+, Qt und alle darauf basierenden Programme und Umgebungen (wie beispielsweise die Desktop-Umgebung Gnome) unterstützen die Eingabe über die Kombination Strg+Umschalttaste bzw. in neueren Versionen Strg+U bzw. Strg+Umschalttaste+u. Nach dem Drücken der Tasten erscheint ein unterstrichenes kleines u. Danach kann der Unicode in hexadezimaler Form eingegeben werden und wird auch unterstrichen, damit man erkennen kann, was zum Unicode gehört. Nach einem Druck der Leer- oder Eingabetaste erscheint dann das entsprechende Zeichen. Auf der Desktop-Umgebung KDE wird diese Funktionalität nicht unterstützt.
Vim
Im Texteditor Vim können Unicode-Zeichen mit Strg+v, gefolgt von der Taste u und dem Unicode in hexadezimaler Form, eingegeben werden.
Auswahl über Zeichentabellen
Seit Windows NT 4.0 ist das Programm charmap.exe, genannt Zeichentabelle, in Windows integriert. Mit diesem Programm ist über eine grafische Benutzeroberfläche möglich, Unicode-Zeichen einzufügen. Außerdem bietet es ein Eingabefeld für den Hexadezimalcode.
Unter macOS steht unter Einfügen → Sonderzeichen ebenfalls eine systemweite Zeichenpalette bereit.
Die freien Programme gucharmap (für Windows und Linux/Unix) und kcharselect (für Linux/UNIX) stellen den Unicode-Zeichensatz auf dem Bildschirm dar und bieten zusätzliche Informationen zu den einzelnen Zeichen.
Codepunkt-Angaben in Dokumenten
HTML und XML unterstützen Unicode mit Zeichencodes, die unabhängig vom eingestellten Zeichensatz das Unicode-Zeichen darstellen. Die Notation lautet � für dezimale Notation bzw. � für hexadezimale Notation, wobei das 0000 die Unicode-Nummer des Zeichens darstellt. Für bestimmte Zeichen sind auch benannte Zeichen (engl. named entities) definiert, so z. B. stellt ä das ä dar,[58] das gilt allerdings nur für HTML; XML und das davon abgeleitete XHTML definieren benannte Notationen nur für die Zeichen, die bei normalem Gebrauch als Teile der Auszeichnungssprache interpretiert würden, also < als <, > als >, & als & und " als ".
Kritik
Unicode wird vor allem aus den Reihen der Wissenschaftler und in ostasiatischen Ländern kritisiert. Einer der Kritikpunkte ist hierbei die Han-Vereinheitlichung; aus ostasiatischer Sicht werden bei diesem Vorgehen Schriftzeichen verschiedener nicht verwandter Sprachen vereinigt.[59] Unter anderem wird kritisiert, dass antike Texte in Unicode aufgrund dieser Vereinheitlichung ähnlicher CJK-Schriftzeichen nicht originalgetreu wiedergegeben werden können.[60] Aufgrund dessen wurden in Japan zahlreiche Alternativen zu Unicode entwickelt, wie etwa der Mojikyō-Standard.
Die Kodierung der thailändischen Schrift wird teilweise kritisiert, weil sie anders als alle anderen Schriftsysteme in Unicode nicht auf logischer, sondern visueller Reihenfolge basiert, was unter anderem die Sortierung thailändischer Wörter erheblich erschwert.[59] Die Unicode-Kodierung basiert auf dem thailändischen Standard TIS-620, der ebenfalls die visuelle Reihenfolge verwendet.[61] Umgekehrt wird die Kodierung der anderen indischen Schriften manchmal als „zu kompliziert“ bezeichnet, vor allem von Vertretern der Tamil-Schrift. Das Modell separater Konsonanten- und Vokalzeichen, welches Unicode vom indischen Standard ISCII übernommen hat,[62] wird von jenen abgelehnt, die separate Codepunkte für alle möglichen Konsonant-Vokal-Verbindungen bevorzugen.[63] Die Regierung der Volksrepublik China machte einen ähnlichen Vorschlag, die tibetische Schrift als Silbenfolgen anstatt als einzelne Konsonanten und Vokale zu kodieren.[64]
Auch gab es Versuche von Unternehmen, Symbole in Unicode zu platzieren, die für deren Produkte stehen sollen.[65]
Schriftarten
Ob das entsprechende Unicode-Zeichen auch tatsächlich am Bildschirm erscheint, hängt davon ab, ob die verwendete Schriftart eine Glyphe für das gewünschte Zeichen (also eine Grafik für die gewünschte Zeichennummer) enthält. Oftmals, z. B. unter Windows, wird, falls die verwendete Schrift ein Zeichen nicht enthält, nach Möglichkeit ein Zeichen aus einer anderen Schrift eingefügt.
Mittlerweile hat der Coderaum von Unicode/ISO einen Umfang angenommen (mehr als 100.000 Schriftzeichen), der sich nicht mehr vollständig in einer Schriftdatei unterbringen lässt. Die heute gängigsten Schriftdateiformate, TrueType und OpenType, können maximal 65.536 Glyphen enthalten. Unicode/ISO-Konformität einer Schrift bedeutet also nicht, dass der komplette Zeichensatz enthalten ist, sondern lediglich, dass die darin enthaltenen Zeichen normgerecht kodiert sind. In der Publikation »decodeunicode«, die alle Zeichen vorstellt, werden insgesamt 66 Fonts genannt, aus denen die Zeichentabellen zusammengesetzt sind.
Auswahl an Unicode-Schriftarten
- Arial Unicode MS (wird ab Microsoft Office XP ausgeliefert. Unterstützung nur bis Unicode 2.0. Enthält 50 377 Glyphen (38 917 Zeichen) in Version 1.01.)
- Bitstream Cyberbit (kostenlos bei nichtkommerzieller Nutzung. 29 934 Zeichen in Version 2.0 beta.)
- Bitstream Vera (frei, serifenlose Version der Cyberbit)
- Cardo (kostenlos bei nichtkommerzieller Nutzung, 2 882 Zeichen in Version 0.098, 2004)
- ClearlyU (frei, die Pixel-Schriftartenfamilie umfasst einen Satz von 12pt bis 100dpi proportionalen BDF-Schriftarten mit vielen benötigten Zeichen von Unicode. 9 538 Zeichen in Version 1.9.)
- Code2000, Code2001 und Code2002: Drei freie Schriftarten, welche für die drei Planes 0, 1 und 2 Zeichen bereitstellen. Diese Schriftarten werden seit 2008 nicht mehr weiterentwickelt und sind deshalb weitgehend veraltet. Davon ausgenommen ist Code2000 für die Blöcke Saurashtra, Kayah Li, Rejang und Cham. Im übrigen gibt es für Code2000 und Code2001 zahlreich Alternativen, für Code2002 z. B. „HanaMinA“ mit „HanaMinB“, „MingLiU-ExtB“, „SimSun-ExtB“ und „Sun-ExtB“.
- DejaVu (frei, „DejaVu Sans“ enthält 3 471 Zeichen und 2 558 Unterschneidungspaare in Version 2.6)
- Doulos SIL (frei; enthält das IPA. 3 083 Zeichen in Version 4.014.)
- Everson Mono (Shareware; umfasst einen Großteil der Nicht-CJK-Buchstaben. 9632 Zeichen in Macromedia Fontographer v7.0.0 12. Dezember 2014.)
- Free UCS Outline Fonts (frei, „FreeSerif“ umfasst 3 914 Zeichen in Version 1.52, MES-1 compliant)
- Gentium Plus (Weiterentwicklung von Gentium. Version 1.510 vom August 2012 enthält 5 586 Glyphen für 2 520 Zeichen. – Download-Seite bei SIL International)
- HanaMinA und HanaMinB überdecken zusammen die Ebene 2 (U+2XXXX). HanaMinA den Block Unicodeblock CJK-Ideogramme, Kompatibilität, Ergänzung, HanaMinB die Blöcke Vereinheitlichte CJK-Ideogramme, Erweiterung B, Vereinheitlichte CJK-Ideogramme, Erweiterung C und Vereinheitlichte CJK-Ideogramme, Erweiterung D.
- Helvetica World (lizenzierbar bei Linotype)
- Junicode (frei; umfasst viele altertümliche Zeichen, entworfen für Historiker. 1 435 Zeichen in Version 0.6.3.)
- Linux Libertine (frei, umfasst westliche Zeichensätze (Latein, Kyrillisch, Griechisch, Hebräisch, u. a. mit archaischen Sonderzeichen, Ligaturen, mediävale, proportionale und römische Ziffern, enthält mehr als 2000 Zeichen in Version 2.6.0), 2007)
- Lucida Grande (Unicode-Schriftart enthalten in macOS; umfasst 1 266 Zeichen)
- Lucida Sans Unicode (enthalten in aktuelleren Microsoft-Windows-Versionen; unterstützt nur ISO-8859-x-Buchstaben. 1 776 Zeichen in Version 2.00.)
- New Gulim (wird ausgeliefert mit Microsoft Office 2000. Großteil von CJK-Buchstaben. 49 284 Zeichen in Version 3.10.)
- Noto ist eine Schriftfamilie, die von Google und Adobe entwickelt und unter der freien Apache-Lizenz angeboten wird. Obwohl ein noch laufendes Projekt, sind bereits die meisten Unicode-kodierten modernen und historischen Schriften abgedeckt. (Download-Seite bei google.com)
- Sun-ExtA überdeckt weite Teile der Ebene 0, darunter 20924 der 20941 Zeichen im Unicodeblock Vereinheitlichte CJK-Ideogramme und alle 6582 Zeichen im Unicodeblock Vereinheitlichte CJK-Ideogramme, Erweiterung A.
- Sun-ExtB überdeckt die Ebene 2 (U+2XXXX) weitgehend:Unicodeblock CJK-Ideogramme, Kompatibilität, Ergänzung, Unicodeblock Vereinheitlichte CJK-Ideogramme, Erweiterung B und Unicodeblock Vereinheitlichte CJK-Ideogramme, Erweiterung C vollständig, vom Unicodeblock Vereinheitlichte CJK-Ideogramme, Erweiterung D 59 der 222 Zeichen. Außerdem noch den Unicodeblock Tai-Xuan-Jing-Symbole.
- TITUS Cyberbit Basic (frei; aktualisierte Version der Cyberbit. 9 779 Zeichen in Version 3.0, 2000.)
- Y.OzFontN (frei. enthält viele japanische CJK-Buchstaben, umfasst wenig SMP-Zeichen. 59 678 Zeichen in Version 9.13.)
Ersatzschriftarten
Eine Ersatzschriftart dient der Ersatzdarstellung für Zeichen, für die kein Font mit korrekter Darstellung zur Verfügung steht.
Hier gibt z. B. folgende Fonts:
- Unicode BMP Fallback SIL, eine von SIL International erstellte Ersatzschriftart, welche alle in Version 6.1 definierten Zeichen der Ebene Null (Basic Multilingual Plane) als Quadrat mit einbeschriebenem Hex-Code darstellt. Zu finden unter sil.org.
- LastResort, designt von Michael Everson, eine in Mac OS 8.5 und höher enthaltene Ersatzschriftart, welche die erste Glyphe eines Blocks für alle Zeichen des Blocks verwendet. Frei herunterladbar von unicode.org.
Siehe auch
Literatur
- Johannes Bergerhausen, Siri Poarangan: decodeunicode: Die Schriftzeichen der Welt. Hermann Schmidt, Mainz 2011, ISBN 978-3-87439-813-8 (Alle 109.242 Unicode-Zeichen in einem Buch.).
- Julie D. Allen: The Unicode Standard, version 6.0. The Unicode Consortium. The Unicode Consortium, Mountain View 2011, ISBN 978-1-936213-01-6 (Online-Version).
- Richard Gillam: Unicode Demystified: a practical programmer’s guide to the encoding standard. Addison-Wesley, Boston 2003, ISBN 0-201-70052-2.
Weblinks
- Offizielle Website des Unicode Consortium (englisch)
- Der universale Code: Unicode. SELFHTML
- Imperia Unicode- und Multi-Language-Howto. (Memento vom 28. Oktober 2014 im Internet Archive) – Allgemeinverständliche, deutschsprachige Einführung in Unicode
- UTF-8 and Unicode FAQ for Unix/Linux von Markus Kuhn (englisch)
- UniSearcher – Suchen von Unicodes
- Shapecatcher grafische Unicode Zeichensuche (englisch)
- The World’s Writing Systems, alle 294 bekannten Schriftsysteme mit je einer Referenz-Glyphe, darunter die 131 noch nicht in Unicode kodierten
- Ermitteln des Zeichennamens und der Codeposition durch Eingabe des Zeichens
- Unicode – The Movie Alle 109.242 Unicode-Zeichen in einem Film
- Unicode-Fontviewer (Freeware)
- Alle Unicode-Zeichen, Emojis und Schriftarten in Windows 10
- Ausführliche Auflistung aller Unicode-Eingabemethoden für Windows (englisch)
- ausführlicher Blog-Artikel zum Minimalverständnis über Unicode (englisch)
- Golo Roden: Was man über Unicode wissen sollte. In: Heise online. 28. Januar 2021 (Heise Developer).
Einzelnachweise
- Dieser Standard ist identisch zu ECMA 35 (PDF; 304 kB), einem Standard von Ecma International.
- Internationalisation and the Web
- Joseph D. Becker: Unicode 88. (PDF; 2,9 MB) 29. August 1988, S. 5
- History of Unicode Release and Publication Dates
- Chronology of Unicode Version 1.0
- Unicode in Japan: Guide to a technical and psychological struggle. (Memento vom 27. Juni 2009 im Internet Archive)
- UnicodeData.txt (1.0.0)
- UnicodeData.txt (1.0.1)
- UnicodeData.txt (1.1)
- What’s new in Unicode 5.1? BabelStone
- UnicodeData.txt (2.0)
- UTR #8: The Unicode Standard, Version 2.1
- Unicode 3.0.0
- UAX #27: Unicode 3.1
- UTR #28: Unicode 3.2
- Unicode 4.0.0
- Unicode 4.1.0
- Unicode 5.0.0
- Unicode 5.1.0
- Unicode 5.2.0
- Unicode 6.0.0
- Unicode 6.1.0
- Unicode 6.2.0
- Unicode 6.3.0
- Unicode 7.0.0
- Unicode 8.0.0
- Unicode 9.0.0. In: unicode.org. Abgerufen am 22. Juni 2016.
- Unicode 10.0.0. In: unicode.org. Abgerufen am 20. April 2017.
- Unicode 11.0.0. In: unicode.org. Abgerufen am 21. Juli 2018.
- Unicode 12.0.0. In: unicode.org. Abgerufen am 28. Februar 2019.
- Unicode 12.1.0. In: unicode.org. Abgerufen am 7. Mai 2019.
- Unicode 13.0.0. In: unicode.org. Abgerufen am 25. April 2021.
- Unicode 14.0.0. In: unicode.org. Abgerufen am 16. September 2021.
- What is Unicode?
- The Unicode Standard, S. 33
- Roadmap to the SIP
- The Unicode Standard, S. 34
- Unicode 6.3 Kapitel 2.8, Seite 34, erster Absatz (da die Core-Spezifikation für Version 6.3 nicht verändert und auch nicht neu veröffentlicht wurde, gelten die Dateien von Version 6.2 für 6.3 unverändert weiter.)
- The Unicode Standard, S. 21f
- Unicode 6.3 Anhang D, Seite 602, Tabellen D-2 und D-3 (da die Core-Spezifikation für Version 6.3 nicht verändert und auch nicht neu veröffentlicht wurde, gelten die Dateien von Version 6.2 für 6.3 unverändert weiter.)
- Medieval Unicode Font Initiative. Abgerufen am 21. August 2012.
- Peter Constable and Lorna A. Priest: SIL Corporate PUA Assignments. 17. April 2012, abgerufen am 21. August 2012.
- Chris Harvey: Languagegeek Fonts. 29. Juni 2012, abgerufen am 21. August 2012.
- ConScript Unicode Registry. Abgerufen am 21. August 2012.
- Character Sets
- Java Internationalization FAQ
- Unicode in the .NET Framework
- FAQ – Unicode and ISO 10646
- The Unicode Standard, S. 573
- Unicode Character Encoding Stability Policy
- Unicode Technical Report #17 – Character Encoding Model
- Response to the revised “Final proposal for encoding the Phoenician script in the UCS” (L2/04-141R2)
- unicode.org
- Jan Mahn: Sonderbare Zeichen. Sonderzeichen unter Windows, Linux, macOS. In: c't. Nr. 20, 2019, S. 126–127 (heise.de [abgerufen am 28. Januar 2021]).
- Unicode unter Mac OS X. apfelwiki.de; abgerufen am 27. April 2013
- Tastenkombinationen für internationale Zeichen
- Allgemeine Tastenkombinationen in LibreOffice. Abgerufen am 20. September 2021.
- Character entity references in HTML 4 w3.org
- Suzanne Topping: The secret life of Unicode. IBM DeveloperWorks, 1. Mai 2001, archiviert vom Original am 14. November 2007; abgerufen am 7. November 2015 (englisch).
- Otfried Cheong: Han Unification in Unicode. 12. Oktober 1999, archiviert vom Original am 28. März 2010; abgerufen am 7. November 2015 (englisch).
- The Unicode Standard, S. 350
- The Unicode Standard, S. 268
- Krishnamurthy, Elangovan, P. Chellappan Kanithamizh Sangam: Evolution of the 16 Bit Encoding Scheme for Tamil. Archiviert vom Original am 16. August 2012; abgerufen am 22. November 2015 (englisch).
- Precomposed Tibetan Part 1: BrdaRten. BabelStone
- winfuture.de
Basis-Lateinisch • Lateinisch-1, Ergänzung • Lateinisch, erw.-A • Lateinisch, erw.-B • IPA-Erweiterungen • Spacing Modifier Letters • Kombinierende diakritische Zeichen • Griechisch und Koptisch • Kyrillisch • Kyrillisch, Ergänzung • Armenisch • Hebräisch • Arabisch • Syrisch • Arabisch, Ergänzung • Thaana • N’Ko • Samaritanisch • Mandäisch • Syrisch, Ergänzung • Arabisch, erw.-B • Arabisch, erw.-A • Devanagari • Bengalisch • Gurmukhi • Gujarati • Oriya • Tamilisch • Telugu • Kannada • Malayalam • Singhalesisch • Thailändisch • Laotisch • Tibetisch • Birmanisch • Georgisch • Hangeul-Jamo • Äthiopisch • Äthiopisch, Zusatz • Cherokee • Vereinh. Silbenz. kanad. Ureinw. • Ogam • Runen • Tagalog • Hanunóo • Buid • Tagbanuwa • Khmer • Mongolisch • Vereinh. Silbenz. kanad. Ureinw., erw. • Limbu • Tai Le • Neu-Tai-Lue • Khmer-Symbole • Buginesisch • Lanna • Kombinierende diakritische Zeichen, erw. • Balinesisch • Sundanesisch • Batak • Lepcha • Ol Chiki • Kyrillisch, erw.-C • Georgisch, erweitert • Sundanesisch, Ergänzung • Vedische Erweiterungen • Phonetische Erweiterungen • Phonetische Erweiterungen, Ergänzung • Kombinierende diakritische Zeichen, Ergänzung • Lateinisch, weiterer Zusatz • Griechisch, Zusatz • Allgemeine Interpunktion • Hoch- und tiefgestellte Zeichen • Währungszeichen • Kombinierende diakritische Zeichen für Symbole • Buchstabenähnliche Symbole • Zahlzeichen • Pfeile • Mathematische Operatoren • Verschiedene technische Zeichen • Symbole für Steuerzeichen • Optische Zeichenerkennung • Umschlossene alphanum. Zeichen • Rahmenzeichnung • Blockelemente • Geometrische Formen • Verschiedene Symbole • Dingbats • Verschiedene mathem. Symbole-A • Zusätzliche Pfeile-A • Braille-Zeichen • Zusätzliche Pfeile-B • Verschiedene mathem. Symbole-B • Zusätzliche mathem. Operatoren • Verschiedene Symbole und Pfeile • Glagolitisch • Lateinisch, erw.-C • Koptisch • Georgisch, Ergänzung • Tifinagh • Äthiopisch, erweitert • Kyrillisch, erw.-A • Zusätzliche Interpunktion • CJK-Radikale, Ergänzung • Kangxi-Radikale • Ideographische Beschreibungszeichen • CJK-Symbole und -Interpunktion • Hiragana • Katakana • Bopomofo • Hangeul-Jamo, Kompatibilität • Kanbun • Bopomofo, erweitert • CJK-Striche • Katakana, Phonetische Erweiterungen • Umschlossene CJK-Zeichen und -Monate • CJK-Kompatibilität • Vereinh. CJK-Ideogramme, Erw. A • I-Ging-Hexagramme • Vereinh. CJK-Ideogramme • Yi-Silbenzeichen • Yi-Radikale • Lisu • Vai • Kyrillisch, erw.-B • Bamum • Modifizierende Tonzeichen • Lateinisch, erw.-D • Syloti Nagri • Allgemeine indische Ziffern • Phagspa • Saurashtra • Devanagari, erw. • Kayah Li • Rejang • Hangeul-Jamo, erw.-A • Javanisch • Birmanisch, erw.-B • Cham • Birmanisch, erw.-A • Tai Viet • Meitei-Mayek, Erw. • Äthiopisch, erw.-A • Lateinisch, erw.-E • Cherokee, Zusatz • Meitei-Mayek • Hangeul-Silbenzeichen • Hangeul-Jamo, erw.-B • Private Use Zone • CJK-Ideogramme, Kompatibilität • Alphabetische Präsentationsformen • Arabische Präsentationsformen-A • Variantenselektoren • Vertikale Formen • Kombinierende halbe diakritische Zeichen • CJK-Kompatibilitätsformen • Kleine Formvarianten • Arabische Präsentationsformen-B • Halbbreite und vollbreite Formen • Spezielles
Linear-B-Silbenzeichen • Linear-B-Ideogramme • Ägäische Zahlzeichen • Altgriechische Zahlzeichen • Alte Symbole • Diskos von Phaistos • Lykisch • Karisch • Koptische Zahlzeichen • Altitalisch • Gotisch • Altpermisch • Ugaritisch • Altpersisch • Mormonen-Alphabet • Shaw-Alphabet • Osmaniya • Osage • Albanisch • Alwanisch • Vithkuq-Alphabet • Linear A • Lateinisch, erw.-F • Kyprisch • Aramäisch • Palmyrenisch • Nabatäisch • Hatra-Schrift • Phönizisch • Lydisch • Meroitische Hieroglyphen • Meroitisch-demotisch • Kharoshthi • Altsüdarabisch • Altnordarabisch • Manichäisch • Avestisch • Parthisch • Inschriften-Pahlavi • Psalter-Pahlavi • Alttürkisch • Altungarisch • Hanifi Rohingya • Rumi-Ziffern • Jesidisch • Altsogdisch • Sogdisch • Altuigurisch • Choresmisch • Elymäisch • Brahmi • Kaithi • Sorang-Sompeng • Chakma • Mahajani • Sharada • Singhalesische Zahlzeichen • Khojki • Multanisch • Khudabadi • Grantha • Newa • Tirhuta • Siddham • Modi • Mongolisch, Ergänzung • Takri • Ahom • Dogra • Varang Kshiti • Dives Akuru • Nandinagari • Dsanabadsar-Quadratschrift • Sojombo • Vereinh. Silbenz. kanad. Ureinw., erw.-A • Pau Cin Hau • Bhaiksuki • Marchen • Masaram Gondi • Gunjala Gondi • Makassar • Lisu, Ergänzung • Tamilisch, Ergänzung • Keilschrift • Keilschrift-Zahlzeichen und -Interpunktion • Frühe Keilschrift • Kypro-minoisch • Ägyptische Hieroglyphen • Ägypt. Hieroglyphen-Steuerzeichen • Anatolische Hieroglyphen • Bamum, Ergänzung • Mro • Tangsa • Bassa Vah • Pahawh Hmong • Medefaidrin • Pollard-Schrift • Ideographische Symbole und Interpunktion • Xixia • Xixia-Komponenten • Kleine Kitan-Schrift • Xixia, Ergänzung • Kana, erw.-B • Kana, Ergänzung • Kana, erw.-A • Kleine Kana, erweitert • Frauenschrift • Duployé-Kurzschrift • Kurzschrift-Steuerzeichen • Snamennyj-Notenschrift • Byzantinische Noten • Notenschrift • Altgriechische Noten • Maya-Zahlzeichen • Tai-Xuan-Jing-Symbole • Zählstabziffern • Mathem. alphanum. Symbole • SignWriting • Lateinisch, erw.-G • Glagolitisch, Ergänzung • Nyiakeng Puachue Hmong • Toto • Wancho • Äthiopisch, erw.-B • Mende-Schrift • Adlam • Indische Siyaq-Zahlzeichen • Osmanische Siyaq-Zahlzeichen • Arab. mathem. alphanum. Symbole • Mahjonggsteine • Dominosteine • Spielkarten • Zusätzliche umschlossene alphanum. Zeichen • Zusätzliche umschlossene CJK-Zeichen • Verschiedene piktografische Symbole • Smileys • Ziersymbole • Verkehrs- und Kartensymbole • Alchemistische Symbole • Geometrische Formen, erw. • Zusätzliche Pfeile-C • Zusätzliche piktografische Symbole • Schachsymbole • Piktografische Symbole, erw.-A • Symbole für Retrocomputer
Vereinh. CJK-Ideogramme, Erw. B • Vereinh. CJK-Ideogramme, Erw. C • Vereinh. CJK-Ideogramme, Erw. D • Vereinh. CJK-Ideogramme, Erw. E • Vereinh. CJK-Ideogramme, Erw. F • CJK-Ideogramme, Kompatibilität, Ergänzung • Vereinh. CJK-Ideogramme, Erw. G
Tags • Variantenselektoren, Ergänzung • Zusätzlicher Privatnutzungsbereich–A • Zusätzlicher Privatnutzungsbereich–B
Adlam • Ägäische Zahlzeichen • Ägyptische Hieroglyphen • Ägypt. Hieroglyphen-Steuerzeichen • Ahom • Albanisch • Alchemistische Symbole • Allgemeine indische Ziffern • Allgemeine Interpunktion • Alphabetische Präsentationsformen • Alte Symbole • Altgriechische Noten • Altgriechische Zahlzeichen • Altitalisch • Altnordarabisch • Altpermisch • Altpersisch • Altsogdisch • Altsüdarabisch • Alttürkisch • Altuigurisch • Altungarisch • Alwanisch • Anatolische Hieroglyphen • Arabisch • Arabisch, Ergänzung • Arabisch, erw.-A • Arabisch, erw.-B • Arab. mathem. alphanum. Symbole • Arabische Präsentationsformen-A • Arabische Präsentationsformen-B • Aramäisch • Armenisch • Äthiopisch • Äthiopisch, erweitert • Äthiopisch, erw.-A • Äthiopisch, erw.-B • Äthiopisch, Zusatz • Avestisch • Balinesisch • Bamum • Bamum, Ergänzung • Basis-Lateinisch • Bassa Vah • Batak • Bengalisch • Bhaiksuki • Birmanisch • Birmanisch, erw.-A • Birmanisch, erw.-B • Blockelemente • Bopomofo • Bopomofo, erweitert • Brahmi • Braille-Zeichen • Buchstabenähnliche Symbole • Buginesisch • Buid • Byzantinische Noten • Chakma • Cham • Cherokee • Cherokee, Zusatz • Choresmisch • CJK-Ideogramme, Kompatibilität • CJK-Ideogramme, Kompatibilität, Ergänzung • CJK-Kompatibilität • CJK-Kompatibilitätsformen • CJK-Radikale, Ergänzung • CJK-Striche • CJK-Symbole und -Interpunktion • Devanagari • Devanagari, erw. • Dingbats • Diskos von Phaistos • Dives Akuru • Dogra • Dominosteine • Dsanabadsar-Quadratschrift • Duployé-Kurzschrift • Elymäisch • Frauenschrift • Frühe Keilschrift • Geometrische Formen • Geometrische Formen, erw. • Georgisch • Georgisch, Ergänzung • Georgisch, erweitert • Glagolitisch • Glagolitisch, Ergänzung • Gotisch • Grantha • Griechisch und Koptisch • Griechisch, Zusatz • Gujarati • Gunjala Gondi • Gurmukhi • Halbbreite und vollbreite Formen • Hangeul-Jamo • Hangeul-Jamo, erw.-A • Hangeul-Jamo, erw.-B • Hangeul-Jamo, Kompatibilität • Hangeul-Silbenzeichen • Hanifi Rohingya • Hanunóo • Hatra-Schrift • Hebräisch • Hiragana • Hoch- und tiefgestellte Zeichen • Ideographische Beschreibungszeichen • Ideographische Symbole und Interpunktion • I-Ging-Hexagramme • Indische Siyaq-Zahlzeichen • Inschriften-Pahlavi • IPA-Erweiterungen • Javanisch • Jesidisch • Kaithi • Kana, Ergänzung • Kana, erw.-A • Kana, erw.-B • Kanbun • Kangxi-Radikale • Kannada • Karisch • Katakana • Katakana, Phonetische Erweiterungen • Kayah Li • Keilschrift • Keilschrift-Zahlzeichen und -Interpunktion • Kharoshthi • Khmer • Khmer-Symbole • Khojki • Khudabadi • Kleine Formvarianten • Kleine Kana, erweitert • Kleine Kitan-Schrift • Kombinierende diakritische Zeichen für Symbole • Kombinierende diakritische Zeichen • Kombinierende diakritische Zeichen, Ergänzung • Kombinierende diakritische Zeichen, erw. • Kombinierende halbe diakritische Zeichen • Koptisch • Koptische Zahlzeichen • Kurzschrift-Steuerzeichen • Kyprisch • Kypro-minoisch • Kyrillisch • Kyrillisch, Ergänzung • Kyrillisch, erw.-A • Kyrillisch, erw.-B • Kyrillisch, erw.-C • Lanna • Laotisch • Lateinisch, erw.-A • Lateinisch, erw.-B • Lateinisch, erw.-C • Lateinisch, erw.-D • Lateinisch, erw.-E • Lateinisch, erw.-F • Lateinisch, erw.-G • Lateinisch, weiterer Zusatz • Lateinisch-1, Ergänzung • Lepcha • Limbu • Linear A • Linear-B-Ideogramme • Linear-B-Silbenzeichen • Lisu • Lisu, Ergänzung • Lydisch • Lykisch • Mahajani • Mahjonggsteine • Makassar • Malayalam • Mandäisch • Manichäisch • Marchen • Masaram Gondi • Mathem. alphanum. Symbole • Mathematische Operatoren • Maya-Zahlzeichen • Medefaidrin • Meitei-Mayek • Meitei-Mayek, Erw. • Mende-Schrift • Meroitisch-demotisch • Meroitische Hieroglyphen • Modi • Modifizierende Tonzeichen • Mongolisch • Mongolisch, Ergänzung • Mormonen-Alphabet • Mro • Multanisch • Nabatäisch • Nandinagari • Neu-Tai-Lue • Newa • N’Ko • Notenschrift • Nyiakeng Puachue Hmong • Ogam • Ol Chiki • Optische Zeichenerkennung • Oriya • Osage • Osmanische Siyaq-Zahlzeichen • Osmaniya • Pahawh Hmong • Palmyrenisch • Parthisch • Pau Cin Hau • Pfeile • Phagspa • Phonetische Erweiterungen • Phonetische Erweiterungen, Ergänzung • Phönizisch • Piktografische Symbole, erw.-A • Pollard-Schrift • Privatnutzungsbereich • Zusätzlicher Privatnutzungsbereich-A • Zusätzlicher Privatnutzungsbereich-B • Psalter-Pahlavi • Rahmenzeichnung • Rejang • Rumi-Ziffern • Runen • Samaritanisch • Saurashtra • Schachsymbole • Sharada • Shaw-Alphabet • Siddham • Singhalesisch • Singhalesische Zahlzeichen • Smileys • Snamennyj-Notenschrift • Sogdisch • Sojombo • Sorang-Sompeng • Spacing Modifier Letters • Spezielles • Spielkarten • Sundanesisch • Sundanesisch, Ergänzung • SignWriting • Syloti Nagri • Symbole für Retrocomputer • Symbole für Steuerzeichen • Syrisch • Syrisch, Ergänzung • Tagalog • Tagbanuwa • Tags • Tai Le • Tai Viet • Tai-Xuan-Jing-Symbole • Takri • Tamilisch • Tamilisch, Ergänzung • Tangsa • Telugu • Thaana • Thailändisch • Tibetisch • Tifinagh • Tirhuta • Toto • Ugaritisch • Umschlossene alphanum. Zeichen • Umschlossene CJK-Zeichen und -Monate • Vai • Varang Kshiti • Variantenselektoren • Variantenselektoren, Ergänzung • Vedische Erweiterungen • Vereinh. CJK-Ideogramme • Vereinh. CJK-Ideogramme, Erw. A • Vereinh. CJK-Ideogramme, Erw. B • Vereinh. CJK-Ideogramme, Erw. C • Vereinh. CJK-Ideogramme, Erw. D • Vereinh. CJK-Ideogramme, Erw. E • Vereinh. CJK-Ideogramme, Erw. F • Vereinh. CJK-Ideogramme, Erw. G • Vereinh. Silbenz. kanad. Ureinw. • Vereinh. Silbenz. kanad. Ureinw., erw. • Vereinh. Silbenz. kanad. Ureinw., erw.-A • Verkehrs- und Kartensymbole • Verschiedene mathem. Symbole-A • Verschiedene mathem. Symbole-B • Verschiedene piktografische Symbole • Verschiedene Symbole und Pfeile • Verschiedene Symbole • Verschiedene technische Zeichen • Vertikale Formen • Vithkuq-Alphabet • Währungszeichen • Wancho • Xixia • Xixia, Ergänzung • Xixia-Komponenten • Yi-Radikale • Yi-Silbenzeichen • Zählstabziffern • Zahlzeichen • Ziersymbole • Zusätzliche Interpunktion • Zusätzliche mathem. Operatoren • Zusätzliche Pfeile-A • Zusätzliche Pfeile-B • Zusätzliche Pfeile-C • Zusätzliche piktografische Symbole • Zusätzliche umschlossene alphanum. Zeichen • Zusätzliche umschlossene CJK-Zeichen