UTF-16
UTF-16 (englisch für Universal Multiple-Octet Coded Character Set (UCS) Transformation Format for 16 Planes of Group 00) ist eine Kodierung mit variabler Länge für Unicode-Zeichen. UTF-16 ist optimiert für die häufig gebrauchten Zeichen aus der Basic multilingual plane (BMP). Es ist das älteste der Unicode-Kodierungsformate.
Allgemeines
Bei der UTF-16-Kodierung wird jedem Unicode-Codepunkt eine speziell kodierte Kette von ein oder zwei 16-Bit-Einheiten zugeordnet, d. h. von zwei oder vier Bytes, so dass sich – wie auch bei den anderen UTF-Formaten – alle Unicode-Zeichen abbilden lassen.
Während UTF-8 eine zentrale Bedeutung in Internet-Protokollen hat, wird UTF-16 vielerorts zur internen Repräsentation von Zeichenketten verwendet, z. B. in aktuellen Versionen von .NET, Java und Tcl.
Eigenschaften
Aufgrund der Kodierung aller Zeichen der BMP in zwei Bytes hat die UTF-16-Kodierung bei Texten, welche hauptsächlich aus lateinischen Buchstaben bestehen, den doppelten Platzbedarf im Vergleich zu geeigneten ISO-8859-Kodierungen oder zu UTF-8. Werden jedoch viele BMP-Zeichen jenseits des Codepoints U+007F codiert, so benötigt UTF-16 vergleichbar viel oder weniger Platz als UTF-8.
Im Gegensatz zu UTF-8 besteht keine Kodierungsreserve. Wird ein UTF-16-kodierter Text als ISO 8859-1 interpretiert, so sind zwar sämtliche auch in letzterer Kodierung enthaltenen Buchstaben erkennbar, aber durch Null-Bytes getrennt; bei anderen ISO-8859-Kodierungen ist die Kompatibilität schlechter.
Normung
UTF-16 wird sowohl vom Unicode-Konsortium als auch von ISO/IEC 10646 definiert. Unicode definiert dabei zusätzliche Semantik. Ein genauer Vergleich findet sich im Anhang C des Unicode-4.0-Standards.[1] Die ISO-Norm definierte weiterhin eine Kodierung UCS-2, in der jedoch nur 16-Bit-Darstellungen der BMP zulässig sind.
Kodierung
Zeichen auf der BMP
Die gültigen Zeichen der BMP (U+0000 bis U+D7FF und U+E000 bis U+FFFF) werden jeweils direkt auf ein einziges 16-Bit-Wort bzw. auf zwei Bytes abgebildet.
Zeichen außerhalb der BMP
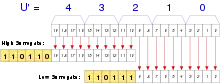
U' ist nicht der ursprüngliche Code U, sondern der Code nach Differenzbildung:
U' = U - 10000hex
Unicode-Zeichen außerhalb der BMP (d. h. U+10000 bis U+10FFFF) werden jeweils durch zwei zusammengehörige 16-Bit-Wörter (engl. code units), also insgesamt vier Bytes dargestellt. (Das sind zwar 32 Bits, aber die Kodierung ist nicht UTF-32.)
Um ein solches Zeichen in UTF-16 zu kodieren wird zunächst von der Codenummer des Zeichens (hier U genannt) die Zahl 65536 (10000hex = Größe der BMP) abgezogen, wodurch eine 20-Bit-Zahl U' im Bereich von 00000hex bis FFFFFhex entsteht. Diese wird anschließend in zwei Blöcke zu je 10 Bit aufgeteilt:
- dem ersten Block (d. h. den 10 höherwertigen Bits des Codes U') wird die Bitfolge 110110 vorangestellt, das entstandene 16-Bit-Wort aus zwei Byte bezeichnet man als High-Surrogate
- dem zweiten Block (d. h. den 10 niederwertigen Bits des Codes U') wird die Bitfolge 110111 vorangestellt, das entstandene 16-Bit-Wort aus zwei Byte bezeichnet man als Low-Surrogate.
Folgende Codebereiche sind speziell für solche Surrogate, d. h. UTF-16-Ersatzzeichen, reserviert und enthalten daher keine eigenständigen Zeichen:
- von U+D800 bis U+DBFF (210 = 1024 High-Surrogates)
- von U+DC00 bis U+DFFF (210 = 1024 Low-Surrogates).
Bei der Umwandlung von UTF-16-kodierten Zeichenketten in UTF-8-Bytefolgen ist zu beachten, dass Paare aus High- und Low-Surrogates zuerst wieder zu jeweils einem Unicode-Zeichencode zusammengefasst werden müssen, bevor dieser dann in eine UTF-8-Bytefolge umgewandelt werden kann (Beispiel in der Beschreibung zu UTF-8). Da dies oft nicht beachtet wird, hat sich eine andere, inkompatible Kodierung für die Ersatzzeichen etabliert, die im Nachhinein als CESU-8 normiert worden ist.
Byte Order
Je nachdem, welches der beiden Bytes eines 16-Bit-Wortes zuerst übertragen bzw. gespeichert wird, spricht man von Big Endian (UTF-16BE) oder von Little Endian (UTF-16LE). Unabhängig davon kommt das High Surrogate-Wort immer vor dem Low Surrogate-Wort.
Für ASCII-Zeichen, die nach UTF-16 übersetzt werden, bedeutet dies, dass das hinzugefügte 0-Zeichen im höchstwertigen Bit
- bei Big Endian vorangestellt und
- bei Little Endian nachgestellt wird.
Bei unzureichend spezifizierten Protokollen wird empfohlen, das Unicode-Zeichen U+FEFF (BOM, byte order mark), das für ein Leerzeichen mit Breite Null und ohne Zeilenumbruch (zero width no-break space) steht, an den Anfang des Datenstroms zu setzen – wird es als das ungültige Unicode-Zeichen U+FFFE (not a character) interpretiert, so heißt das, dass die Byte-Reihenfolge zwischen Sender und Empfänger verschieden ist und die Bytes jedes 16-Bit-Worts beim Empfänger vertauscht werden müssen, um den anschließenden Datenstrom korrekt auszuwerten.
Beispiele
In folgender Tabelle sind einige Kodierungsbeispiele für UTF-16 angegeben:
| Zeichen | Unicode | Unicode binär | UTF-16BE binär | UTF-16BE hexadezimal |
|---|---|---|---|---|
| Buchstabe y | U+0079 | 00000000 01111001 | 00000000 01111001 | 00 79 |
| Buchstabe ä | U+00E4 | 00000000 11100100 | 00000000 11100100 | 00 E4 |
| Eurozeichen € | U+20AC | 00100000 10101100 | 00100000 10101100 | 20 AC |
| Violinschlüssel 𝄞 | U+1D11E | 00000001 11010001 00011110 | 11011000 00110100 11011101 00011110 | D8 34 DD 1E |
| CJK-Ideogramm 𤽜 | U+24F5C | 00000010 01001111 01011100 | 11011000 01010011 11011111 01011100 | D8 53 DF 5C |
Die letzten beiden Beispiele liegen außerhalb der BMP. Da derzeit viele Schriftarten diese neuen Unicode-Bereiche noch nicht enthalten, können die dort enthaltenen Zeichen auf vielen Plattformen nicht korrekt dargestellt werden. Stattdessen wird ein Ersatzzeichen dargestellt, welches als Platzhalter dient. In den Beispielen wird durch die Subtraktion von 10000hex lediglich ein bzw. zwei Bits verändert (Im Beispiel in der Farbe Magenta angezeigt) und aus den so entstandenen Bits die Surrogates gebildet.
Beispiel-Berechnung der Surrogates
Alle Zahlen werden im Folgenden zur Basis 16 angegeben.
Für die Unicode-Position v
SG-Word1 = + D800 SG-Word2 = + DC00


= 64321 SG-Word1 = + D800 = D950


SG-Word2 = + DC00
= DF21

Siehe auch
Einzelnachweise
- Unicode 4.0, Anhang C (PDF; 155 kB)