Aussprache der deutschen Sprache
Die Aussprache der deutschen Sprache bezeichnet die Phonetik und Phonologie der deutschen Standardsprache. Diese ist nicht überall dieselbe, denn Deutsch ist eine plurizentrische Sprache mit verschiedenen Varietäten, die in ihrer Aussprache jedoch weitgehend übereinstimmen.

Im weiteren Sinn kann unter der Aussprache der deutschen Sprache auch die der deutschen Dialekte verstanden werden. Weitere Informationen dazu finden sich in dem Artikel über die deutschen Mundarten.
Geschichte
Anfänglich war die deutsche Standardsprache eine reine Schriftnorm. Wenn sie gesprochen wurde, dann entsprechend dem Lautstand der regionalen Mundarten.
Vom 16. bis zum 18. Jahrhundert galt die sächsische Aussprache des Standarddeutschen – das Meißnische – als vorbildlich, und zwar insbesondere in Mittel- und Norddeutschland, während sie sich im Süden des deutschen Sprachraums nur allmählich durchsetzte. Hinweise auf die ehemalige Vorbildlichkeit einer sächsisch gefärbten Aussprache finden sich etwa darin, dass noch zur Zeit der Weimarer Klassik ein Wortpaar wie müde – Friede als anstandsloser reiner Reim akzeptiert war.[1]
Im 19. Jahrhundert wurde die norddeutsche Aussprache zur einflussreichsten. Verschiedene Faktoren spielten dabei eine Rolle. Einerseits war Preußen insbesondere seit der Gründung des deutschen Kaiserreichs zur dominierenden Macht geworden, andererseits waren in vielen Gegenden Norddeutschlands die Mundarten zugunsten der Standardsprache aufgegeben worden, so dass die Sprecher eine natürliche Gewandtheit im mündlichen Gebrauch der Standardsprache erreichten.
Kodifiziert wurde diese Aussprache der deutschen Sprache erstmals 1898 in der Deutschen Bühnenaussprache von Theodor Siebs. Moderne Aussprachewörterbücher stimmen im Großen und Ganzen mit der Siebs’schen Aussprache überein, wenn sie auch in verschiedenen Details von ihr abweichen (beispielsweise wird heute [r] nicht mehr als die einzige zulässige Aussprache des Phonems /r/ angesehen). Als maßgeblich für die heute weitgehend anerkannte Fassung dieser Norm „der deutschen Standardaussprache“ (so das Wörterbuch) kann das Duden-Aussprachewörterbuch (Max Mangold) gelten, in dem sie besonders ausführlich beschrieben wird. (Allerdings ist zu beachten, dass einige der dort formulierten Grundannahmen in der Phonetik und der Phonologie auch anders gesehen werden und nicht immer den neuesten Forschungsstand in diesen Disziplinen widerspiegeln.) Üblicherweise wird diese Aussprachenorm auch im Deutschunterricht für Ausländer gelehrt und mehr oder weniger exakt in ein- und mehrsprachigen Wörterbüchern des Deutschen verwendet.
Variation
Die als Norm formulierte Standardaussprache gilt als einheitliches Ideal. Es gibt verschiedene Aussprachevarianten des Deutschen, die in den jeweiligen Regionen eine Vorbildwirkung ausüben.[2]
Es ist daher unrealistisch zu sagen, dass allein eine dieser verschiedenen Aussprachen des Standarddeutschen die „richtige“ sei (und dem einen Ideal entspreche) und alles andere dialektgefärbte Abweichungen. Diese auch heute noch verbreitete Auffassung galt früher unhinterfragt, als eine präskriptive Haltung auch in Grammatikdarstellung und Didaktik üblich war (als es also üblich war vorzuschreiben, wie die Leute sprechen sollten).
Beobachten lassen sich diese Normvariationen beispielsweise daran, dass in Radio und Fernsehen nicht nur eine einzige Aussprache der deutschen Sprache gebraucht wird. Nachrichtensprecher aus Deutschland, Österreich und der Schweiz unterscheiden sich in ihrer Aussprache des Standarddeutschen. Das Übergewicht der Normvariante aus der Bundesrepublik ist allein als ein quantitatives zu beschreiben (wegen der höheren Bevölkerungszahl in Deutschland gibt es mehr Sender und diese haben eine größere Reichweite). Aber auch innerhalb Deutschlands lassen sich Unterschiede feststellen, wenn man z. B. die Aussprache bayerischer und norddeutscher Radio- und Fernsehsprecher vergleicht.
Vokalsystem
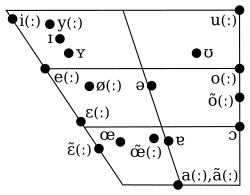
Das Vokalsystem des Deutschen ist mit rund 15 (Monophthong-)Vokal-Phonemen relativ groß, die spanische Sprache zum Beispiel kennt nur fünf. Diese Vokalphoneme werden durch die acht Vokalbuchstaben a, e, i, o, u, ä, ö und ü dargestellt, in Fremdwörtern und Eigennamen in bestimmten Positionen auch durch y und seltener durch é. Vor allem i, u, y werden aber zum Teil auch zur Wiedergabe von Konsonanten verwendet.
Die Vokalphoneme der betonten Silben werden oft in Paare eingeteilt: /aː/ und /a/, /eː/ und /ɛ/, /iː/ und /ɪ/, /oː/ und /ɔ/, /uː/ und /ʊ/, /ɛː/ und /ɛ/, /øː/ und /œ/ sowie /yː/ und /ʏ/. Zur phonologischen Begründung dieser Paarbildungen gibt es verschiedene Ansätze:
- Das Unterscheidungsmerkmal ist die Vokalquantität. Der Unterschied in der Vokalqualität folgt sekundär daraus. Problematisch bleibt in diesem Ansatz die Stellung des Vokals /ɛː/, der trotz seiner Länge nicht geschlossen ist.
- Das Unterscheidungsmerkmal ist die Vokalqualität. Der Unterschied in der Vokalquantität folgt sekundär daraus. Problematisch bleibt in diesem Ansatz neben der Stellung des Vokals /ɛː/ auch diejenige des Paars /aː – a/, wo trotz einem Unterschied in der Länge keiner in der Qualität vorliegt. (In vom Niederdeutschen beeinflussten Aussprachevarianten des Standarddeutschen ist allerdings oft ein Unterschied vorhanden: Der Langvokal ist ein Hinterzungenvokal, der Kurzvokal hingegen ein Vorderzungenvokal, während beide a-Vokale sonst meistens als Zentralvokal artikuliert werden. In diesen existiert in aller Regel auch das Phonem /ɛː/ nicht, s. u., so dass die Analyse auf der Grundlage der Vokalqualität möglich ist.)
- Das Unterscheidungsmerkmal ist der Silbenschnitt. Die Unterschiede in Vokalqualität und Vokalquantität folgen sekundär daraus. Problematisch bleibt in diesem Ansatz die Frage, ob eine empirische Grundlage für die Annahme eines Unterschieds im Silbenschnitt besteht.
Geschlossene (lange) Vokale werden in unbetonter Position meistens kurz ausgesprochen, z. B. /ɡeˈnoːm/, /viˈtaːl/.
Ritt /rɪt/ und riet /riːt/ unterscheiden sich beispielsweise auch in der Qualität voneinander, wie die Notation des Internationalen Phonetischen Alphabets zeigt. Die Mehrzahl der langen Vokalphoneme werden also geschlossener ausgesprochen und sind andere Phoneme als ihre kurzen verschrifteten Entsprechungen.
Ähnliche Vokalpaare betonter Silben wie im Deutschen gibt es in allen germanischen Sprachen.
/ɛː/ wie in Käse wird in mehreren Varietäten der deutschen Standardsprache, besonders im Norden Deutschlands und Osten Österreichs, üblicherweise wie /eː/ ausgesprochen. In der Hochlautung wird /ɛː/ als [ɛː] und /eː/ als [eː] realisiert.[3][4] Beispiele für Minimalpaare: Seele – Säle, Belege – Beläge, Hefen – Häfen, sehen – säen, Ehre – Ähre, Gewehr – Gewähr. In den beiden letzten Beispielpaaren allerdings stehen [ɛː] und [eː] vor /r/. Hier gibt es eine starke Tendenz, den Unterschied zwischen [ɛː] und [eː] zu neutralisieren.[5]
In Lehnwörtern aus dem Französischen können zusätzlich die (immer langen) Nasalvokale /ãː/, /ɛ̃ː/, /œ̃ː/ und /õː/ auftreten. Allerdings ist ihr Phonemstatus fraglich und sie werden oft in Oralvokal + [ŋ] (im Norden) oder Oralvokal + [n] oder auch [m] aufgelöst, z. B. finden sich statt Ballon /baˈlõː/ die Aussprachen [baˈlɔŋ] oder [baˈloːn], statt Parfüm /parˈfœ̃ː/ die Aussprachen [parˈfœŋ] oder [parˈfyːm] und statt Orange /oˈrãːʒə/ die Aussprachen [oˈraŋʒə] oder [oˈranʒə].
Monophthonge
Diphthonge
| Laut | Beispiel | Beschreibung |
|---|---|---|
| aʊ̯ | Haus | Der schließende Diphthong setzt mit einem [a] wie in Schwamm ein und gleitet in Richtung auf das deutsche [ʊ], wobei sich die Lippen runden. |
| aɪ̯ | Heim | Der schließende Diphthong setzt mit einem [a] wie in Schwamm ein und gleitet in Richtung auf das deutsche [ɪ]. |
| ɔʏ̯ | Eule | Der schließende Diphthong setzt mit einem [ɔ] wie in Gott ein, und gleitet in Richtung [ʏ], wobei die leichte Rundung der Lippen zum Ende hin fast verlorengehen kann (aus [ʏ] wird fast [ɪ]). |
Gelegentlich werden in Beschreibungen auch noch eine Gruppe von peripheren Diphthongen, die in Interjektionen oder entlehnten Wörtern vorkommen, angeführt: [ʊɪ̯], wie in hui! oder pfui!, [ɛɪ̯], wie in Mail oder Fake, und [ɔʊ̯], wie in Soul oder Code.
Konsonantensystem
Das deutsche Konsonantensystem weist mit rund 25 Phonemen im Vergleich mit anderen Sprachen eine durchschnittliche Größe auf. Eine Besonderheit ist die ungewöhnliche Affrikate /p͡f/.[6]
Verschiedene deutsche Konsonanten treten in Paaren von gleichem Artikulationsort und gleicher Artikulationsart auf, nämlich die Paare /p–b, t–d, k–ɡ, s–z, ʃ–ʒ/. Diese Paare werden oft als Fortis-Lenis-Paare bezeichnet, da sie als Stimmlos-stimmhaft-Paare nur unzulänglich beschrieben sind. Mit gewissen Einschränkungen zählen auch /t͡ʃ–d͡ʒ, f-v/ zu diesen Paaren.
Die Fortis-Plosive /p, t, k/ werden in den meisten Varietäten aspiriert, wobei die Aspiration im Anlaut betonter Silben am stärksten ist (beispielsweise in Taler [ˈtʰaːlɐ]), schwächer im Anlaut unbetonter Silben (beispielsweise in Vater [ˈfaːtʰɐ]) und am schwächsten im Silbenauslaut (beispielsweise in Saat [zaːt(ʰ)]). Keine Aspiration hat es in den Kombinationen [ʃt ʃp] (beispielsweise in Stein [ʃtaɪ̯n], Spur [ʃpuːɐ̯]).
Die Lenis-Konsonanten /b, d, ɡ, z, ʒ/ sind in den meisten süddeutschen Varietäten stimmlos. Um dies zu verdeutlichen, werden sie oft als [b̥, d̥, ɡ̊, z̥, ʒ̊] notiert. Es ist umstritten, worin der phonetische Unterschied zwischen den stimmlosen Lenis-Konsonanten und den ebenfalls stimmlosen Fortis-Konsonanten liegt. Üblicherweise wird er als Unterschied in der Artikulationsspannung beschrieben, gelegentlich jedoch als Unterschied in der Artikulationsdauer, wobei meist angenommen wird, dass eine dieser Eigenschaften die andere zur Folge hat.
Im nördlichen Deutschen ist die Opposition zwischen Fortis und Lenis im Silbenauslaut aufgehoben (siehe Auslautverhärtung).[7]
In verschiedenen mittel- und süddeutschen Varietäten ist die Opposition zwischen Fortis und Lenis im Silbenanlaut aufgehoben, teils nur im Anlaut betonter Silben, teils in allen Fällen (binnendeutsche Konsonantenschwächung).
Das Paar /f–v/ zählt nicht zu den Fortis-Lenis-Paaren, da /v/ auch in den süddeutschen Varietäten stimmhaft bleibt. Üblicherweise wird die süddeutsche Aussprache mit dem stimmhaften Approximanten [ʋ] angegeben. Hingegen gibt es süddeutsche Varietäten, die zwischen einem Fortis-f ([f], beispielsweise in sträflich [ˈʃtrɛːflɪç] zu mhd. stræflich) und einem Lenis-f ([v̥], beispielsweise in höflich [ˈhøːv̥lɪç] zu mhd. hovelîch) unterscheiden, analog zur Opposition von Fortis-s ([s]) und Lenis-s ([z̥]).
| Laut | Beispiel | Beschreibung |
|---|---|---|
| ʔ | beachten /bəˈʔaxtən/ | Glottisschlag (Knacklaut) – Oft wird dieser Laut nicht als Phonem der deutschen Sprache beschrieben, sondern als morphologisches Grenzmarkierungsphänomen. |
| b | Biene /ˈbiːnə, b̥iːnə/, aber /ˈaːbər, ˈaːb̥ər/ | stimmhafter bilabialer Plosiv – Da dieser Laut in den südlichen Varietäten stimmlos ist ([b̥]), wird er oft als Lenis bezeichnet und nicht als stimmhaft. |
| ç | Ich /ɪç/, Furcht /fʊrçt/, Frauchen /fra͡ʊçən/, nicht-südliche Varietäten: China /ˈçiːna/, dreißig /ˈdra͡ɪsɪç/ | stimmloser palataler Frikativ (Ich-Laut) – Dieser Laut bildet zusammen mit [x] ein komplementäres Allophon-Paar. Er tritt nach vorderen Vokalen sowie nach Konsonanten auf. Im Diminutiv-Suffix [çən] tritt ausschließlich dieser Laut auf. Mit Ausnahme dieses Suffixes tritt [ç] in südlichen Varietäten im Silbenanlaut nicht auf, während es in anderen Varietäten oft im Silbenanlaut anzutreffen ist. In nicht-südlichen Varietäten ist [ç] ein übliches Allophon von /ɡ/ im Silbenauslaut (nach vorderen Vokalen oder nach Konsonanten); die gemäßigte Standardlautung verlangt diese Spirantisierung nur in der Endung /ɪɡ/, allerdings nur für Norddeutschland, während sonst die Aussprache /ɪk/ gilt.[8] |
| d | dann /dan, d̥an/, Laden /ˈlaːdən, laːd̥ən/ | stimmhafter alveolarer Plosiv – Da dieser Laut in den südlichen Varietäten stimmlos ist ([d̥]), wird er oft als Lenis bezeichnet und nicht als stimmhaft. |
| d͡ʒ | Dschungel /ˈd͡ʒʊŋəl/ | stimmhafte postalveolare Affrikate – Dieser Laut tritt nur in Fremdwörtern auf. In den südlichen Varietäten, die keine stimmhaften Plosive aufweisen, fällt er mit [t͡ʃ] zusammen. |
| f | Vogel /ˈfoːɡəl/, Hafen /ˈhaːfən/ | stimmloser labiodentaler Frikativ |
| ɡ | Ganɡ /ˈɡaŋ, ɡ̊aŋ/, Lager /ˈlaːɡər, laːɡ̊ər/ | stimmhafter velarer Plosiv – Da dieser Laut in den südlichen Varietäten stimmlos ist ([ɡ̊]), wird er oft als Lenis bezeichnet und nicht als stimmhaft. |
| h | Haus /ha͡ʊs/, Uhu /ˈuːhu/ | stimmloser glottaler Frikativ |
| j | jung /jʊŋ/, Boje /ˈboːjə/ | stimmhafter palataler Approximant |
| k | Katze /ˈkat͡sə/, Strecke /ʃtrɛkə/ | stimmloser velarer Plosiv |
| l | Lamm /lam/, alle /ˈalə/ | stimmhafter lateraler alveolarer Approximant |
| m | Maus /maʊ̯s/, Dame /daːmə/ | stimmhafter bilabialer Nasal |
| n | Nord /nɔrt/, Kanne /ˈkanə/ | stimmhafter alveolarer Nasal |
| ŋ | Lang /laŋ/, singen /ˈzɪŋən/ | stimmhafter velarer Nasal |
| p | Pate /ˈpaːtə/, Mappe /ˈmapə/ | stimmloser bilabialer Plosiv |
| p͡f | Pfaffe /ˈp͡fafə/, Apfel /ˈap͡fəl/ | stimmlose labiodentale Affrikate |
| r ʀ ʁ | rot [roːt, ʀoːt, ʁoːt], starre [ˈʃtarə, ˈʃtaʀə, ˈʃtaʁe], mit Vokalisierung: sehr [zeːɐ̯], besser [ˈbɛsɐ] | stimmhafter alveolarer Vibrant ([r]), stimmhafter uvularer Vibrant ([ʀ]), stimmhafter uvularer Frikativ ([ʁ]) – Diese drei Laute sind freie Allophone. Ihre Verteilung ist lokal, wobei [r] fast ausschließlich in einigen südlichen Varietäten anzutreffen ist. Im Silbenauslaut wird das /r/ oft vokalisiert zu [ɐ̯], besonders nach langen Vokalen und in der unbetonten Endung /ər/, die bei Vokalisierung als [ɐ] realisiert wird. |
| s | Straße /ˈʃtraːsə/, Last /last/, Fässer /ˈfɛsər/ | stimmloser alveolarer Frikativ |
| ʃ | Schule /ˈʃuːlə/, Stier /ʃtiːr/, Spur /ʃpuːr/ | stimmloser postalveolarer Frikativ |
| t | Tag /taːk/, Vetter /ˈfɛtər/ | stimmloser alveolarer Plosiv |
| t͡s | Zaun /t͡sa͡ʊn/, Katze /ˈkat͡sə/ | stimmlose alveolare Affrikate |
| t͡ʃ | Deutsch /dɔ͡ʏt͡ʃ/, Kutsche /ˈkʊt͡ʃə/ | stimmlose postalveolare Affrikate |
| v | Winter /ˈvɪntər/, Löwe /ˈløːvə/ | stimmhafter labiodentaler Frikativ – Bisweilen wird dieser Laut als stimmhafter labiodentaler Approximant ([ʋ]) beschrieben. |
| x | Buch [buːx] | stimmloser velarer Frikativ – Dieser Laut (auch "uch"-Laut) bildet zusammen mit den Allophonen [ç] und [χ] ein Phonem. Er tritt nach /o:/ und /u:/ auf. |
| χ | Bach [baχ] | stimmloser uvularer Frikativ – Dieser Laut (auch "ach"-Laut) bildet zusammen mit [ç] und [x] ein Phonem. Er tritt nach /a/, /a:/, /ɔ/ und /ʊ/ auf. |
| z | sechs /zɛks, z̥ɛks/, Wiese /ˈviːzə, ˈviːz̥ə/ | stimmhafter alveolarer Frikativ – Da dieser Laut in den südlichen Varietäten stimmlos ist ([z̥]), wird er oft als Lenis bezeichnet und nicht als stimmhaft. |
| ʒ | Genie /ʒeˈniː, ʒ̊enˈiː/, Plantage /planˈtaːʒə, planˈtaːʒ̊ə/ | stimmhafter postalveolarer Frikativ – Dieser Laut tritt nur in Fremdwörtern auf. Da dieser Laut in den südlichen Varietäten stimmlos ist ([ʒ̊]), wird er oft als Lenis bezeichnet und nicht als stimmhaft. |
| bilabial | labio- dental |
alveolar | post- alveolar |
palatal | velar | uvular | glottal | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | |
| Plosive | p | b | t | d | k | ɡ | (ʔ) | |||||||||
| Nasale | m | n | ŋ | |||||||||||||
| Frikative | f | v | s | z | ʃ | ʒ | ç | x | χ | ʁ | h | |||||
| Approximanten | j | |||||||||||||||
| laterale Approximanten | l | |||||||||||||||
| Affrikate | p͡f | t͡s | t͡ʃ | d͡ʒ | ||||||||||||
Phonotaktik
Ein typisches Merkmal für den phonotaktischen Aufbau deutscher Wörter sind relativ komplexe Konsonantencluster in den Wortstämmen, konjugierten Formen und an der Wortfuge, die in der geschriebenen, graphotaktischen Form (wegen der verwendeten Di- und Trigraphen) oft besonders komplex wirken (z. B. kleckste, auftrumpfen, Angstschweiß, schreiben, ernst, schrumpfst, seufztest, trittst, knutschst, hältst, Herbst, jetzt, Schrift, Schnitt).
Prosodie
Wortbetonung
In deutschen Wörtern herrscht nach traditioneller Vorstellung Stammbetonung vor, das heißt, es wird die erste Silbe des Stamms betont: „lehren, Lehrer, Lehrerin, lehrhaft, Lehrerkollegium, belehren.“ Manche Präfixe und Suffixe allerdings ziehen die Betonung auf sich: „(Aus-spra-che, vor-le-sen, Bä-cke-rei).“
In neueren Studien wird der Wortakzent im Deutschen dagegen vom rechten/hinteren Rand des Wortes betrachtet. Nach Vennemanns Dreisilbenregel[9] liegt der Hauptakzent auf einer der drei letzten Silben des Wortes, wie in Kamera, Kanone, Kamerad. Manche Autoren sehen die vorletzte Silbe (Pänultima) als die einzige reguläre Position für den Wortakzent an[10], andere betonen die Rolle der Silbenquantität für die Positionierung des Wortakzents[11]. Danach wird eine schwere Silbe am absoluten Wortende betont, sonst die vorletzte oder die drittletzte, letzteres aber nur, wenn die vorletzte Silbe leicht bzw. offen ist.
Daneben bestimmen Worbildungssuffixe den Wortakzent, da es akzentneutrale Suffixe und akzentbestimmende Suffixe gibt. Zu ersteren gehören -heit/-keit, -er, -ig oder -ung; zu letzteren gehören -ei, -ion, -al oder -ier. Bei mehreren Suffixen determiniert das letzte akzentbestimmende Suffix den Wortakzent, wie in Neutr-al-isier-ung.
Für Fremdwörter/Lehnwörter im Deutschen lassen sich keine Regeln angeben, da die Betonung häufig zusammen mit dem Wort übernommen wird. Das gilt allerdings vor allem für aus dem Französischen entlehnte Fremdwörter. Aus unbekannteren Sprachen entnommene Fremdwörter zeigen aber die Rolle der oben erwähnten Regeln, siehe zum Beispiel japanische Wörter wie Harakiri, Nagasaki mit Pänultima-Akzent und Kimono und Hiroshima mit Antepänultima-Akzent.
Bei zusammengesetzten Wörtern (Komposita) wird meistens das erste Wort (Bestimmungswort) betont. Ausnahmen sind zum Beispiel Kilometer und Jahrhundert. Die betonte Silbe wird im Vergleich zu den unbetonten stärker und damit lauter gesprochen (dynamischer Akzent). Bei dreiteiligen Komposita hängt die Betonung von der Wortstruktur ab: Wenn der zweite Teil aus zwei Wörtern besteht, liegt die Betonung auf dem zweiten Teil, wie in Bundesgartenschau, das die Struktur [Bundes[gartenschau]] besitzt. Mit der alternativen Struktur (zwei Wörter im ersten Teil) ist die Hauptbetonung auf dem ersten Wort, wie in Schreibtischlampe [[Schreibtisch]lampe].
Intonation
Das Deutsche kennt drei verschiedene Melodieverläufe, nämlich fallende, steigende und schwebende (progrediente) Intonation. Die fallende Intonation kennzeichnet den Satzschluss bei Aussagesätzen und Wortfragen wie zum Beispiel bei den Sätzen: „Wann kommst du?“ – „Ich komme jetzt.“ Die schwebende Intonation wird bei Pausen wie zum Beispiel zwischen Haupt- und Nebensatz verwendet. Die steigende Intonation ist typisch für Satzfragen (auch Entscheidungsfragen) wie zum Beispiel: „Isst du gerne Schokolade?“ Auch Wortfragen können mit steigender Intonation gesprochen werden, wenn man ihnen einen freundlichen Ton verleihen will.
Eine Ausnahme bildet das Schweizer Hochdeutsch, wo die steigende Intonation auch in Aussagesätzen anzutreffen ist.
Der Hauptakzent liegt im Satz auf dem Rhema, meistens gegen Ende des Satzes. Die Hebung oder Senkung der Stimme erfolgt ausgehend von der letzten betonten Silbe im Satz. Bei fallender Intonation wird diese Silbe etwas höher gesprochen als die Vorangehenden. Die nachfolgenden Silben fallen dann bis unter das Niveau des Satzes. Ist die letzte betonte Silbe ein einziges Wort, findet diese Melodiebewegung innerhalb dieses Wortes statt. Bei steigender Intonation wird die letzte betonte Silbe analog etwas tiefer gesprochen.
Rhythmus
Die deutsche Sprache ist gekennzeichnet durch einen so genannten „punktierten Sprechrhythmus“. Die betonte Silbe überragt im Deutschen die unbetonten Silben nicht nur in ihrer Schallfülle, sondern auch hinsichtlich ihrer Länge: Auf eine betonte Silbe folgende unbetonte Silben werden fast immer kürzer gesprochen.
Ausspracheregeln
Vokalbuchstaben und ihre Vokalqualität
- ä wird [ɛ] oder [ɛː] gesprochen (Vokalphonempaar /ɛ/ – /ɛː/), unbetont in offener Silbe: [ɛ].
- Man beachte außerdem die besondere Vokalqualität in der Graphemkombination äu [ɔʏ̯] (vgl.u.).
- e wird [ɛ] oder [eː] gesprochen (Vokalphonempaar /ɛ/ – /eː/), unbetont in offener Silbe: [e] oder [ə].
- In unbetonten offenen Silben vor der betonten Silbe wird meist [e] gesprochen (enorm, Beate), in den Präfixen be- und ge- jedoch regelmäßig [ə] (beachte, Gespür). Nach der betonten Silbe wird in unbetonten offenen Silben meist [ə] gesprochen (vor allem kann solch ein e vor den Buchstaben l, n, r, t und am Wortende vorkommen) (Ummantelung, weitere, schaltete). In gewissen Varietäten wird in allen Fällen [e] ausgesprochen, so oft im Kunstgesang oder im schweizerischen Deutsch.
- In unbetonten geschlossenen Silben nach der betonten Silbe (= Reduktionssilben) kann e (/ɛ/) ebenfalls als [ə] (neben [ɛ]) gesprochen werden, und zwar vor allem in den Kombinationen el, em, en, er, es, et (mindestens). el, em, en werden dabei üblicherweise als silbische Konsonanten [l̩, m̩, n̩] realisiert, bei deutlicherem Sprechen aber auch als [əl, əm, ən] (Apfel, großem, essen). en [n̩] wird dabei ggf. an die Artikulationsstelle des vorangehenden plosiven Konsonanten angeglichen (also nach b/p bzw. g/k als [m̩] bzw. [ŋ̩] realisiert: leben, wecken). er wird in vielen Varietäten als [ɐ] realisiert, das in manchen Regionen einem kurzen [a] sehr nahekommt, in anderen Varietäten aber ebenfalls als silbischer Konsonant [r̩] oder als [ər] (Vater).
- Man beachte außerdem die besondere Vokalqualität in den Graphemkombinationen eu, ei [ɔʏ̯, aɪ̯] und in Eigennamen auch ey [aɪ̯] (Meyer, Ceylon) (vgl.u.).
- é wird [eː] gesprochen (unbetont [e]) (Varieté, André).
- i wird [ɪ] oder [iː] gesprochen (Vokalphonempaar /ɪ/ – /iː/), unbetont in offener Silbe: [i].
- o wird [ɔ] oder [oː] gesprochen (Vokalphonempaar /ɔ/ – /oː/), unbetont in offener Silbe: [o].
- ö wird [œ] oder [øː] gesprochen (Vokalphonempaar /œ/ – /øː/), unbetont in offener Silbe: [ø].
- u wird [ʊ] oder [uː] gesprochen (Vokalphonempaar /ʊ/ – /uː/), unbetont in offener Silbe: [u].
- Man beachte außerdem die besondere Vokalqualität in den Graphemkombinationen eu, äu [ɔʏ̯] (vgl.u.).
- ü, y werden [ʏ] oder [yː] gesprochen (Vokalphonempaar /ʏ/ – /yː/), unbetont in offener Silbe: [y].
- y wird in bestimmten Kontexten entsprechend den Ausspracheregeln für i gesprochen: a) in Positionen, wo y unsilbisch zu sprechen ist (vgl. u.), und zwar am Wortanfang und nach Vokalbuchstaben (Yacht, Bayern), b) unbetont am Wortende (Party), sowie c) manchmal in Eigennamen (Kyffhäuser, Schwyz).
Vokalbuchstabenkombinationen
Vokalbuchstaben, die nicht den Silbenkern der betonten Silbe darstellen, werden unter bestimmten Bedingungen unsilbisch bzw. konsonantisch gesprochen (und bilden mit dem silbischen Vokal zusammen einen Diphthong). Dies betrifft einerseits Vokalbuchstaben, die anderen Vokalbuchstaben folgen, und andererseits Vokalbuchstaben, die anderen Vokalbuchstaben vorangehen (meist nach Konsonantenbuchstaben):
- In der Regel als kurzer silbischer Vokal + unsilbischer Vokal (klassische Diphthonge) gesprochen: ai, ay, ao, au, oi, oy, ui (dies ist die Grundregel und kann produktiv z. B. für die Dialektschreibung eingesetzt werden: äi, öi, oa, ua usw.), mit zusätzlicher Änderung der Vokalqualität: ei, ey, eu, äu (in Eigennamen manchmal auch ui, uy, euy: gesprochen wie eu).
- Oft als unsilbischer Vokal + silbischer Vokal (kurz oder lang) gesprochen: ia, iä, io usw. (ie nur teilweise), ya, ye, yo usw., ua, uä, uo usw., ähnlich oft auch bei ea, eo (ideal), oa (bzw. oi in Wörtern aus dem Französischen anstelle von oa), öo (Homöo-) u. ä. Unsilbisches i (ähnlich auch e) und vor allem y entspricht dabei oft einem [j], unsilbisches u (ähnlich manchmal auch o) kann in bestimmten Fällen [v] gesprochen werden: regelmäßig nach q (qu [kv]), manchmal auch nach k, s, t, g u. a. (Biskuit, Suite, Etui, z. T. auch bei eventuell, Linguistik).
ii und uu (außer nach q) werden dagegen immer zweisilbig gesprochen (initiieren, Vakuum).
Davon zu unterscheiden sind besondere Vokalbuchstabenkombinationen, die einen eigenen Lautwert haben (Di- und Trigraphen): aa, ee, oo, ie (zur Längenkennzeichnung, s. u.); in Fremdwörtern auch ou (Aussprache wie u), regelmäßig eu (wie ö) in der Endung eur, sowie viele Ausnahmefälle; in Eigennamen auch ae (wie ä oder langes a: Aerzen, Raesfeld), oe (wie ö oder langes o: Bonhoeffer, Soest), oi (wie langes o: Voigt), ue (wie ü oder langes u: Ueckermünde, Buer), ui, uy (wie langes ü: Duisburg, Huy), oey, öö (wie langes ö: Oeynhausen, Gööck), uu (wie langes u: Luuk) – vergleiche Dehnungs-e und Dehnungs-i.
Unterscheidung von Vokalquantität und -qualität bei einzelnen Vokalbuchstaben
Die deutsche Rechtschreibung bezeichnet die Quantität (Länge) und damit auch die Qualität (geschlossen/offen) der Vokale nur teilweise direkt. Trotzdem kann die Unterscheidung zwischen langen und kurzen resp. geschlossenen und offenen Vokalen und damit die Entscheidung, welches Phonem eines Vokalphonempaares zu wählen ist, meistens aus der Schreibung erschlossen werden.
Dass es sich um einen Langvokal handelt, kann durch
- die Verdopplung des Vokalbuchstabens (aa, ee, oo, z. B. wie in Tee),
- (sofern es sich nicht um Eigennamen handelt, nur bei i) durch ein folgendes stummes e (ie wie in Liebe) oder
- durch ein folgendes stummes h (ah, äh, eh, ih, ieh, oh, öh, uh, üh wie in Zahl, fahnden, fähig, wehst, ihm, ziehst, lohnt, Frühstück, in Eigennamen auch yh wie in Pyhra)
eindeutig gemacht sein. In unbetonten Silben aber werden Vokale in manchen Fällen sogar dann kurz gesprochen, wenn der Buchstabe von einem Dehnungszeichen begleitet ist (siehe Vokalquantität#Orthografische Probleme in unbetonten Silben).
Zu beachten ist, dass diese Buchstabenkombinationen innerhalb eines Wortes nicht immer als Di- und Trigraphen zu lesen sind, sondern zum Teil auch getrennt:
- aa, ee, oo, ie werden meist in Wörtern, die aus mehreren Vollvokalsilben bestehen (außer am Wortende und in der letzten Silbe vor -r(e)), getrennt gesprochen – insbesondere, wenn der zweite Vokalbuchstabe zu einem Suffix gehört: Kanaan, zoologisch, Orient; ideell, Ideen, industriell, Industrien. Am Wortende und vor -r(e) dagegen als Langvokal: Idee, Zoo, Industrie; Galeere, regieren, Klavier. Die Aussprache von ie ist in dieser Position aber oft, die von ee manchmal uneindeutig: vgl. Studie/Partie, Premiere, Azalee,
- h in ah, äh, eh usw. ist dann nicht stumm, wenn ein weiterer Vollvokal folgt (außer vor den einheimischen Wortausgängen/Suffixen -ig, -ich, -ung): Uhu, Ahorn, Alkohol, nihilistisch.
Einzelne Vokalbuchstaben sind ganz regelmäßig lang, wenn sie in offenen Silben stehen (wie das erste „e“ in „Leben“ oder das „a“ in „raten“). Eine offene Silbe liegt dann vor, wenn im Wort ein einzelner Konsonantenbuchstabe plus Vokalbuchstabe folgt. Denn ein einzelner Konsonantenbuchstabe gehört in der Regel zur nächsten Silbe.
Kurz sind dagegen Vokale häufig in geschlossenen Silben, vor allem wenn im Wort weitere Silben folgen („Kante“, „Hüfte“, „Wolke“).
Von daher leitet sich die Regel ab, dass zwei gleiche Konsonantenbuchstaben (ebenso „ck“ und „tz“) nach einem einzelnen Vokal dessen Kürze signalisieren (zum Beispiel in „Sonne“, „irren“, „Ratte“, „Masse“), da der doppelt dargestellte Konsonant zu beiden Silben gehört und damit die erste Silbe zu einer geschlossenen macht.
Umgekehrt deutet daher ein einzelner Konsonantenbuchstabe (inkl. ß, dessen Gebrauch gerade in dieser funktionalen Abgrenzung zu „ss“ begründet wird) die Länge des vorangehenden Vokals an („Krone“, „hören“, „raten“, „Maße“), da er, wie gesagt, den Vokal in einer offenen Silbe stehen lässt. (Ausnahme: der Konsonantenbuchstabe x – vor „x“ wird ein einzelner Vokalbuchstabe immer kurz gesprochen, z. B. „Hexe“, „Axt“.)
Ebenfalls lang sind Vokale, die zwar in geschlossenen Silben stehen, welche aber so erweitert werden können, dass eine offene Silbe entsteht. Bei „hörst“ handelt es sich um eine geschlossene Silbe, „hö“ in „hören“ ist offen, deshalb wird auch das „ö“ in „hörst“ lang gesprochen.
Ebenfalls lang sind Vokale, die zwar in geschlossenen Silben stehen, welche nicht zu offenen Silben erweiterbar sind, welche aber erkennbar in Parallele zu solchen erweiterbaren Silben aufgebaut sind. „Obst“ hat einen erkennbar parallelen Aufbau zu „lobst“ (von „loben“), da von der Aussprache her statt b eigentlich der Buchstabe p zu erwarten wäre.
So lässt sich verallgemeinern: Lang sind Vokale vor den Konsonantenbuchstaben „b“, „d“, „g“, „ß“ (wenn „t“, „s“ oder „st“ folgt) sowie vor „gd“ und „ks“. (Diese markieren die lange Aussprache, da sie anstelle von sonst zu erwartenden „p“, „t“, „k“, „s“; „kt“ und „x“/„chs“ stehen.) Die Vorhersagbarkeit der Vokallänge gilt vor diesen Konsonantenbuchstaben also unabhängig von der Erweiterbarkeit der Silben. Vgl.: „Obst“/„lobst“ (lang) vs. „optisch“ (kurz), „Krebs“/„lebst“ vs. „Klops“, „beredt“/„lädt“ vs. „nett“, „Vogt“/„legt“ vs. „Sekt“, „spaßt“ vs. „fast“, „Magd“/„Jagd“ vs. „Akt“, „Keks“/„piksen“ vs. „fix“. In Eigennamen gilt dies auch für „w“ (statt „f“) und „sd“ (statt „st“): „Drews“, „Dresden“.
Vor anderen Häufungen von Konsonantenbuchstaben sind die Vokale in der Regel kurz (da es sich hier oft um geschlossene Silben handelt). Allerdings gibt es einige, vor denen Vokale kurz oder lang vorkommen können („tsch“, „st“, „chs“, „nd“, „rd“ u. a.) oder in der Regel lang sind („br“, „kl“, „tr“ u. a.); insbesondere vor Di- und Trigrafen: vor „ch“, „sch“ meist kurz, vor „ph“, „th“ meist lang).
Einzelne Vokale in Wörtern aus geschlossenen Silben mit nur einem Konsonantenbuchstaben am Ende, die aber keine erweiterte Form mit langem Vokal haben (in der Regel Funktionswörter und Präfixe), wie zum Beispiel bei „mit“, „ab“, „um“, „un-“ (nach alter Rechtschreibung auch „daß“, „miß-“), werden meistens kurz gesprochen (aber lang: „dem“, „nun“, vor „r“: „der“, „er“, „wir“, „für“, „ur-“). Diese Ausspracheregel wird unter bestimmten Bedingungen auch auf Nomen und Adjektive angewandt: Bei (orthografisch) noch nicht vollständig integrierten Wörtern aus dem Englischen und Französischen („Top“, „fit“, „Bus“, „chic“), bei sog. Abkürzungswörtern („TÜV“, „MAZ“), bei einigen undurchschaubaren Wortbestandteilen („Brombeere“). Generell gilt diese Regel für Wörter mit „x“ (vgl. oben) und (wenn es denn ausnahmsweise vorkommt) für Wörter mit „j“ am Ende („Fax“; „Andrej“, „ahoj“). Nach alter Rechtschreibung galt dies auch für einen Teil der Wörter mit „ß“: „Nuß“, „Boß“, „iß!“. Die kurze Aussprache des Vokals in solchen Wörtern, denen orthographisch der doppelt dargestellte Konsonant am Wortende fehlt, lässt sich zum Teil daraus erschließen, dass es verwandte Formen mit orthographisch markiertem kurzen Vokal gibt (kurzer Vokal bei „in“ wg. „innen“, „fit“ wg. „fitter“, „Bus“ wg. „Busse“, „Top“ wg. „toppen“, „Nuß“ wg. „Nüsse“; dagegen lang: „Biotop“ wg. „Biotope“, „Fuß“ wg. „Füße“).
In Eigennamen (Familien- und geografische Namen) kann die Vokalkürze auch vor doppelt dargestellten Konsonanten nicht immer eindeutig bestimmt werden. Insbesondere „ck“, „ff“, „ss“ und „tz“, aber auch andere, kommen dort nicht ausschließlich nur nach kurzen Vokalen vor („Bismarck“, „Hauff“, „Zeiss“, „Hartz“, „Kneipp“, „Württemberg“). So kann auch ein einzelner Vokal vor diesen Doppelbuchstaben ausnahmsweise lang sein: „Buckow“, „Mecklenburg“, „Bonhoeffer“, „Gross“, „Lietzensee“.
Da in der Schweiz anstelle des Eszetts „ss“ in Gebrauch ist, signalisiert dort „ss“ als einziger doppelter Konsonantenbuchstabe (außerhalb von Eigennamen) nicht die Kürze des vorangehenden Vokals; Länge oder Kürze des Vokals ist also in diesem Fall nicht vorhersagbar (wie sonst auch vor den Di- und Trigrafen „ch“, „sch“ u. a.).
Deutsche Aussprache im klassischen Gesang
Im Vergleich mit der Sprechtheaterbühne bedient sich die (klassische) Vokalmusik einer leicht variierten Aussprache.
- Der besseren Verständlichkeit gesungener Sprache halber wird das Schwa oft als [ɛ] gesungen.
- Das r wird in der klassischen Musik stets mit der Zungenspitze als [r] ausgesprochen. Dies gilt auch für die Endung -er, sofern das r am Wortende nicht einfach weggelassen wird.
- Der Glottisschlag im anlautenden Vokal wird in der Musik teilweise als unschön empfunden, er fällt häufig zugunsten eines aspirierten Tonansatzes weg, was allerdings zu gesangstechnischen Problemen und zu einer Beeinträchtigung der Textverständlichkeit führt.
Abgesehen davon werden in der klassischen Musik die Konsonanten meist viel forcierter ausgesprochen als im gesprochenen Deutsch. Auch dies dient der besseren Sprachverständlichkeit.
Siehe auch
Literatur
- Aussprachewörterbuch. Duden Mannheim/Wien/Zürich 2005, Bd. 6, ISBN 978-3-411-04066-7.
- Hans Bickel, Christoph Landolt: Schweizerhochdeutsch. Wörterbuch der Standardsprache in der deutschen Schweiz. 2., vollständig überarbeitete und erweiterte Auflage. Hrsg. vom Schweizerischen Verein für die deutsche Sprache. Dudenverlag, Berlin 2018, ISBN 978-3-411-70418-7.
- Luciano Canepari: German Pronunciation & Accents. LINCOM, München 2014, ISBN 978-3-86288-562-6.
- Fausto Cercignani: The Consonants of German: Synchrony and Diachrony. Cisalpino, Milano 1979.
- Karoline Ehrlich, Wie spricht man „richtig“ Deutsch? Kritische Betrachtung der Aussprachenormen von Siebs, GWDA und Aussprache-Duden. Praesens, Wien 2009, ISBN 978-3-7069-0481-0.
- Großes Wörterbuch der deutschen Aussprache. GWDA, Leipzig 1982.
- Ingrid Hove: Die Aussprache der Standardsprache in der Schweiz. Niemeyer, Tübingen 2002, ISBN 978-3-484-23147-4.
- Eva-Maria Krech, Eberhard Stock, Ursula Hirschfeld, Lutz Christian Anders: Deutsches Aussprachewörterbuch. Berlin 2009, ISBN 978-3-11-018202-6.
- Klaus J. Kohler: Einführung in die Phonetik des Deutschen. Erich Schmidt, Berlin 1995², ISBN 978-3-503-03097-2.
- Kai Langer: Kontrastive Phonetik: Deutsch – Brasilianisches Portugiesisch. Frankfurt am Main 2010, ISBN 978-3-631-60843-2.
- Theodor Siebs: Deutsche Aussprache – Reine und gemäßigte Hochlautung mit Aussprachewörterbuch. Berlin 2007, ISBN 978-3-11-018203-3.
- Richard Wiese: The Phonology of German. Oxford 1996 (2. Auflage 2000), ISBN 0-19-824040-6.
Weblinks
- Sigrun Kotb: Literatur zum Seminar „Phonetik des Deutschen“ Deutsches Institut, Johannes-Gutenberg-Universität Mainz
- Kai Langer: Kontrastive Phonetik: Deutsch – Brasilianisches Portugiesisch.
- Das deutsche Alphabet mit Aussprache (Memento vom 10. September 2011 im Internet Archive)
Einzelnachweise
- Werner König: dtv-Atlas zur deutschen Sprache. Deutscher Taschenbuch Verlag, München 1989, S. 104, 149.
- Eva-Maria Krech, Eberhard Stock, Ursula Hirschfeld et al.: Deutsches Aussprachewörterbuch. Berlin 2010, S. 1.
- Jörg Jesch: Grundlagen der Sprecherziehung. Walter de Gruyter, 1973, S. 39.
- Werner Geiger et al.: Sprechen am Mikrofon bei Schweizer Radio DRS. Schweizer Radio DRS, 2006, S. 39. (PDF)
- Richard Wiese: Phonology of German. 2. Auflage. Oxford University Press, Oxford 2000, ISBN 0-19-824040-6.
- Über die deutschen Konsonanten in synchronischer und diachronischer Sicht siehe Fausto Cercignani: The Consonants of German: Synchrony and Diachrony. Cisalpino, Milano 1979.
- Ulrich Ammon, Hans Bickel, Jakob Ebner, Ruth Esterhammer, Markus Gasser, Lorenz Hofer, Birte Kellermeier-Rehbein, Heinrich Löffler, Doris Mangott, Hans Moser, Robert Schläpfer, Michael Schloßmacher, Regula Schmidlin, Günter Vallaster: Variantenwörterbuch des Deutschen. Die Standardsprache in Österreich, der Schweiz und Deutschland sowie in Liechtenstein, Luxemburg, Ostbelgien und Südtirol. Walter de Gruyter, Berlin, New York 2004, ISBN 3-11-016575-9, S. LVII.
- „Siebs“, regionale Hochlautung
- Theo Vennemann: Skizze der deutschen Wortprosodie. In: Zeitschrift für Sprachwissenschaft. Band 10, Nr. 1, 1991, S. 86–111.
- Peter Eisenberg: Syllabische Struktur und Wortakzent. Prinzipien der Prosodik deutscher Wörter. In: Zeitschrift für Sprachwissenschaft. Band 10, Nr. 1, 1991, S. 37–64.
- Timo Röttger, Ulrike Domahs, Marion Grande & Frank Domahs: Structural factors affecting the assignment of word stress in German. In: Journal of Germanic linguistics. Band 24, Nr. 1, 2012, S. 53–94.