Supercomputer
Als Supercomputer (auch Hochleistungsrechner[1][2] oder Superrechner genannt) werden für ihre Zeit besonders schnelle Computer bezeichnet. Dabei ist es unerheblich, auf welcher Bauweise der Computer beruht, solange es sich um einen universell einsetzbaren Rechner handelt. Ein typisches Merkmal eines modernen Supercomputers ist seine besonders große Anzahl an Prozessoren, die auf gemeinsame Peripheriegeräte und einen teilweise gemeinsamen Hauptspeicher zugreifen können. Supercomputer werden häufig für Computersimulationen im Bereich des Hochleistungsrechnens eingesetzt.


Supercomputer spielen eine essenzielle Rolle im wissenschaftlichen Rechnen und werden dort in diversen Disziplinen eingesetzt, etwa Simulationen im Bereich der Quantenmechanik, Wettervorhersagen, Klimatologie, Entdeckung von Öl- und Gasvorkommen, Molekulardynamik, biologischen Makromolekülen, Kosmologie, Astrophysik, Fusionsforschung, Erforschung von Kernwaffentests bis hin zur Kryptoanalyse.
In Deutschland sind Supercomputer überwiegend an Universitäten und Forschungseinrichtungen wie etwa den Max-Planck-Instituten zu finden. Wegen ihrer Einsatzmöglichkeiten fallen sie unter deutsche Gesetze zur Waffenexportkontrolle.[3]
Geschichte und Aufbau

Supercomputer spalteten sich in der Geschichte der Computerentwicklung in den 1960er Jahren von den wissenschaftlichen Rechnern und den Großrechnern ab. Während Großrechner eher auf hohe Zuverlässigkeit hin optimiert wurden, wurden Supercomputer in Richtung hoher Rechenleistung optimiert. Der erste offiziell installierte Supercomputer Cray-1 schaffte 1976 130 MegaFLOPS.
Ursprünglich wurde die herausragende Rechenleistung durch maximale Ausnutzung der verfügbaren Technik erzielt, indem Konstruktionen gewählt wurden, die für größere Serienproduktion zu teuer waren (z. B. Flüssigkeitskühlung, exotische Bauelemente und Materialien, kompakter Aufbau für kurze Signalwege), die Zahl der Prozessoren war eher gering. Seit geraumer Zeit etablieren sich vermehrt sogenannte Cluster, bei denen eine große Anzahl von (meist preiswerten) Einzelrechnern zu einem großen Rechner vernetzt werden. Im Vergleich zu einem Vektorrechner besitzen die Knoten in einem Cluster eigene Peripherie und ausschließlich einen eigenen, lokalen Hauptspeicher. Cluster verwenden Standardkomponenten, deshalb bieten sie zunächst Kostenvorteile gegenüber Vektorrechnern. Sie erfordern aber einen weit höheren Programmieraufwand. Es ist abzuwägen, ob die eingesetzten Programme sich dafür eignen, auf viele Prozessoren verteilt zu werden.
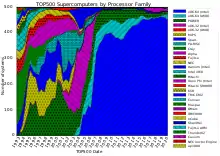

Moderne Hochleistungsrechner sind vor allem Parallelrechner. Sie bestehen aus einer großen Anzahl an miteinander vernetzten Computern. Zusätzlich verfügt jeder Computer in der Regel über mehrere Hauptprozessoren (CPUs). Auf einem Supercomputer können nicht unmodifiziert die gleichen Programme wie auf einem gewöhnlichen Computer laufen, sondern speziell abgestimmte Programme, die die einzelnen, parallel arbeitenden Prozessoren beschäftigen. Supercomputer sind (wie auch heutzutage jeder handelsübliche Computer im unteren Preissegment) Vektorrechner. Dominierend sind mittlerweile Standardarchitekturen aus dem Bereich von Personalcomputern und Servern, etwa x86-64 von Intel (Xeon) und AMD (Epyc). Sie unterscheiden sich von gewöhnlicher Personalcomputer-Hardware nur geringfügig. Es gibt aber auch immer noch Spezialhardware wie IBM BlueGene/Q und Sparc64.
Die Verbindungen zwischen Einzelcomputern werden bei Supercomputern mit speziellen Hochleistungsnetzwerken umgesetzt, verbreitet ist dabei unter anderem InfiniBand. Computer werden oft mit Beschleunigerkarten ausgestattet, etwa Grafikkarten oder der Intel Xeon Phi. Grafikkarten eignen sich zum Einsatz im High Performance Computing, weil sie exzellente Vektorrecheneinheiten darstellen und Probleme der Linearen Algebra effizient lösen. Die zugehörige Technik nennt sich General Purpose Computation on Graphics Processing Unit (GPGPU).
Bei Clustern werden die einzelnen Computer oft Knoten (englisch nodes) genannt und mittels Clustermanagament-Werkzeugen zentral konfiguriert und überwacht.
Betriebssystem und Programmierung
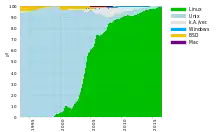
Während noch in den 1990er Jahren diverse Unix-Varianten bei Supercomputern verbreitet waren, hat sich in den 2000er Jahren die Freie Software Linux als Betriebssystem durchgesetzt. In der TOP500-Liste der schnellsten Computersysteme (Stand Juni 2012) werden insgesamt 462 ausschließlich unter Linux betriebene Systeme und 11 teilweise (CNK/SLES 9) unter Linux betriebene Systeme aufgelistet. Damit laufen 92,4 % der Systeme vollständig unter Linux. Fast alle anderen Systeme werden unter Unix oder Unix-artigen Systemen betrieben. Der im Desktop-Bereich größte Konkurrent Windows spielt im Bereich der Höchstleistungsrechner kaum eine Rolle (0,4 %).
Verwendete Programmiersprachen zur Programmierung von Programmen sind vor allem Fortran und C bzw. C++. Um möglichst schnellen Code zu generieren, wird meist auf Compiler der Supercomputer-Hersteller (etwa CRAY oder Intel) zurückgegriffen. Programme im High Performance Computing (HPC) werden typischerweise in zwei Kategorien eingeteilt:
- Shared-Memory-Parallelisierung, in der Regel lokal auf einem einzelnen Knoten. Hierzu sind Schnittstellen wie OpenMP oder TBB verbreitet. Ein einzelner Betriebssystemprozess beschäftigt in der Regel alle zur Verfügung stehenden CPU-Kerne bzw. CPUs.
- Distributed Memory-Parallelisierung: Ein Betriebssystemprozess läuft auf einem Kern und muss zur gemeinschaftlichen Problemlösung Nachrichten mit anderen Prozessen austauschen (Message passing). Dies geht Knotenintern oder über Knotengrenzen hinweg. Das Message Passing Interface ist der Defaktostandard, um diese Art Programme zu programmieren.
In der Praxis findet man oft die Kombination beider Parallelisierungstechniken, die oft Hybrid-Parallelisierung genannt wird. Sie ist deswegen populär, weil Programme oft nicht gut genug skalieren, um alle Kerne eines Supercomputers mit reinem message passing auszulasten.
Wenn Supercomputer mit Beschleunigerkarten (Grafikkarten oder Rechenkarten) ausgestattet sind, zergliedert sich die Programmierung nochmals auf die des Hostcomputers und die der Beschleunigerkarte. OpenCL und CUDA sind dabei zwei Schnittstellen, die die Programmierung derartiger Komponenten ermöglichen.
Hochleistungsrechner werden in der Regel nicht von einem einzigen Benutzer bzw. Programm genutzt. Stattdessen werden Job-Scheduler wie Simple Linux Utility for Resource Management (SLURM) oder IBMs LoadLeveler verwendet, um einer großen Anzahl an Benutzern zu ermöglichen, kurzzeitig Teile des Supercomputers zu verwenden. Die Zuteilung erfolgt dabei exklusiv auf Ebene von Knotenzuordnung oder Prozessorzuordnung. Die verbrauchte Prozessorzeit wird dabei in Einheiten wie CPU-Stunden oder Knoten-Stunden gemessen und ggf. abgerechnet.
Einsatzzweck
Die Herstellungskosten eines Supercomputers aus der TOP10 bewegen sich derzeit in einem hohen zweistelligen, oftmals bereits dreistelligen Euro-Millionenbetrag.
Die heutigen Supercomputer werden überwiegend zu Simulationszwecken eingesetzt. Je realitätsnäher eine Simulation komplexer Zusammenhänge wird, desto mehr Rechenleistung wird in der Regel benötigt. Ein Vorteil der Supercomputer ist, dass sie durch ihre extrem schnelle und damit große Rechenleistung immer mehr Interdependenzen berücksichtigen können. Dies erlaubt das Einbeziehen weiterreichender, oftmals auch unscheinbarer Neben- oder Randbedingungen zur eigentlichen Simulation und gewährleistet dadurch ein immer aussagekräftigeres Gesamtergebnis.
Die derzeitigen Haupteinsatzgebiete der Supercomputer umfassen dabei die Bereiche Biologie, Chemie, Geologie, Luft- und Raumfahrt, Medizin, Wettervorhersage, Klimaforschung, Militär und Physik.
Im militärischen Bereich haben Supercomputer es z. B. ermöglicht, neue Atombombenentwicklungen durch Simulation, ohne Stützdaten durch weitere unterirdische Atombombenversuche, durchzuführen. Die Bereiche kennzeichnen sich dadurch, dass es sich um sehr komplexe Systeme bzw. Teilsysteme handelt, die in weitreichendem Maße miteinander verknüpft sind. So haben Veränderungen in dem einen Teilsystem meist mehr oder minder starke Auswirkungen auf benachbarte oder angeschlossene Systeme. Durch den Einsatz von Supercomputern wird es immer leichter möglich, viele solcher Konsequenzen zu berücksichtigen oder sogar zu prognostizieren, wodurch bereits weit im Vorfeld etwaige Gegenmaßnahmen getroffen werden könnten. Dies gilt z. B. bei Simulationen zum Klimawandel, der Vorhersagen von Erdbeben oder Vulkanausbrüchen sowie in der Medizin bei der Simulation neuer Wirkstoffe auf den Organismus. Solche Simulationen sind logischerweise, ganz unabhängig von der Rechenleistung, nur so genau, wie es die programmierten Parameter bzw. Modelle zur Berechnung zulassen. Die enormen Investitionssummen in die stetige Steigerung der FLOPS und damit die Entwicklung von immer schnelleren Supercomputern werden vor allem mit den Nutzenvorteilen und dem eventuellen „Wissensvorsprung“ für die Menschheit gerechtfertigt, weniger aus den Aspekten des allgemeinen technischen Fortschritts.
Situation in Deutschland
Das wissenschaftliche Hochleistungsrechnen ist in Deutschland durch das Gauss Centre for Supercomputing (GCS) organisiert, welches Mitglied im europäischen Partnership for Advanced Computing in Europe (PRACE) ist. Der Verbund für Nationales Hochleistungsrechnen (NRH) stellt Hochleistungsrechenressourcen der mittleren Leistungsklasse (Ebene 2) zur Verfügung. Die Mehrzahl der 16 deutschen Bundesländer unterhalten Landeshochrechnerverbände, um die Nutzung ihrer Hochleistungsrechner zu organisieren. In der Wissenschaftswelt wird in der Regel ein Kontingent an CPU-Stunden ausgeschrieben und unter Bewerbern verteilt.
Ausgewählte Superrechner
Aktuelle Superrechner
Die schnellsten Superrechner nach Leistung werden heutzutage halbjährlich in der TOP500-Liste aufgeführt. Als Bewertungsgrundlage dient der LINPACK-Benchmark. Die schnellsten Superrechner nach Energieeffizienz bzw. MFLOPS/W werden seit November 2007 in der Green500-Liste geführt.[6] Den größten Anteil (117) der Top 500 leistungsstärksten Rechner weltweit konnte 2018 Lenovo installieren.[7]
Diese Green500-Liste vom November 2014 weist länderweise gemittelte Effizienzen von 1895 MFLOPS/W (Italien) bis hinunter zu 168 MFLOPS/W (Malaysia) auf.
Ausgewählte aktuelle Superrechner (weltweit)
Stand früher als Juni 2017 (2016?). Jedoch Piz Daint, Schweiz nachgetragen.
| Name | Standort | TeraFLOPS | Konfiguration | Energiebedarf | Zweck |
|---|---|---|---|---|---|
| Fugaku | RIKEN Center for Computational Science, Kobe, (Japan) | 415.530,00 | 152.064 A64FX (48 Kerne, 2,2 GHz),4,64 PB RAM | 15.000 kW | Wissenschaftliche Anwendungen |
| Summit | Oak Ridge National Laboratory (Tennessee, USA) | 122.300,00 aufgerüstet auf 148.600,00 | 9.216 POWER9 CPUs (22 Kerne, 3,1 GHz), 27,648 Nvidia Tesla V100 GPUs | 10.096 kW | Physikalische Berechnungen |
| Sunway TaihuLight | National Supercomputing Center, Wuxi, Jiangsu | 93.014,60 | 40.960 Sunway SW26010 (260 Kerne, 1,45 GHz), 1,31 PB RAM, 40 Serverschränke mit jeweils 4 × 256 Nodes, insgesamt 10.649.600 Kerne | 15.370 kW | Wissenschaftliche und kommerzielle Anwendungen |
| Sierra[8] | Lawrence Livermore National Laboratory (Kalifornien, USA) | 71.600,00 | IBM Power9 (22 Kerne, 3,1 GHz) 1,5 PB RAM | 7.438 kW | physikalische Berechnungen (z. B. Simulation von Kernwaffentests) |
| Tianhe-2[9] | National University for Defense Technology, Changsha, China finaler Standort: National Supercomputer Center (Guangzhou, Volksrepublik China) |
33.862,70 aufgerüstet auf 61.400,00 | 32.000 Intel Xeon E5-2692 CPUs (Ivy Bridge, 12 Kerne, 2,2 GHz) + 48.000 Intel Xeon Phi 31S1P Co-Prozessoren (57 Kerne, 1,1 GHz), 1,4 PB RAM | 17.808 kW | Chemische und physikalische Berechnungen (z. B. Untersuchungen von Erdöl und Flugzeugentwicklung) |
| Hawk[10][11] | Höchstleistungsrechenzentrum Stuttgart (Deutschland) | 26.000,00 | 11.264 AMD EPYC 7742(64 Kerne, 2,25 GHz), 1.44 PB RAM | 3.500 kW | Wissenschaftliche und kommerzielle Anwendungen |
| Piz Daint | Swiss National Supercomputing Centre (CSCS) (Schweiz) | 21.230,00 | Cray XC50, Xeon E5-2690v3 12C 2,6 GHz, Aries interconnect, NVIDIA Tesla P100, Cray Inc. (361.760 Kerne) | 2.384 kW | wissenschaftliche und kommerzielle Anwendungen |
| Titan | Oak Ridge National Laboratory (Tennessee, USA) | 17.590,00 | Cray XK7, 18.688 AMD Opteron 6274 CPUs (16 Kerne, 2,20 GHz) + 18.688 Nvidia Tesla K20 GPGPUs, 693,5 TB RAM | 8.209 kW | Physikalische Berechnungen |
| Sequoia[12] | Lawrence Livermore National Laboratory (Kalifornien, USA) | 17.173,20 | IBM BlueGene/Q, 98.304 Power BQC-Prozessoren (16 Kerne, 1,60 GHz), 1,6 PB RAM | 7.890 kW | Simulation von Kernwaffentests |
| K computer | Advanced Institute for Computational Science (Japan) | 10.510,00 | 88.128 SPARC64-VIII 8-Core-Prozessoren (2,00 GHz), 1.377 TB RAM | 12.660 kW | Chemische und physikalische Berechnungen |
| Mira | Argonne National Laboratory (Illinois, USA) | 8.586,6 | IBM BlueGene/Q, 49.152 Power BQC-Prozessoren (16 Kerne, 1,60 GHz) | 3.945 kW | Entwicklung neuer Energiequellen, Technologien und Materialien, Bioinformatik |
| JUQUEEN[13] | Forschungszentrum Jülich (Deutschland) | 5.008,9 | IBM BlueGene/Q, 28.672 Power BQC-Prozessoren (16 Kerne, 1,60 GHz), 448 TB RAM | 2.301 kW | Materialwissenschaften, theoretische Chemie, Elementarteilchenphysik, Umwelt, Astrophysik |
| Phase 1 – Cray XC30[14] | Europäisches Zentrum für mittelfristige Wettervorhersage (Reading, England) | 3.593,00 | 7.010 Intel E5-2697v2 „Ivy Bridge“ (12 Kerne, 2,7 GHz) | ||
| SuperMUC IBM[15][16] | Leibniz-Rechenzentrum (LRZ) (Garching bei München, Deutschland) | 2.897,00 | 18.432 Xeon E5-2680 CPUs (8 Kerne, 2,7 GHz) + 820 Xeon E7-4870 CPUs (10 Kerne, 2,4 GHz), 340 TB RAM | 3.423 kW | Kosmologie über die Entstehung des Universums, Seismologie/Erdbebenvorhersage, uvm. |
| Stampede | Texas Advanced Computing Center (Texas, USA) | 5.168,10 | Xeon E5-2680 CPUs (8 Kerne, 2,7 GHz) + Xeon E7-4870 CPUs, 185 TB RAM | 4.510 kW | Chemische und physikalische, biologische (z. B. Proteinstrukturanalyse), geologische (z. B. Erdbebenvorhersage), medizinische Berechnungen (z. B. Krebswachstum) |
| Tianhe-1A | National Supercomputer Center (Tianjin, Volksrepublik China) | 2.266,00 | 14.336 Intel 6-Core-Xeon X5670 CPUs (2,93 GHz) + 7.168 Nvidia Tesla M2050 GPGPUs, 224 TB RAM | 4.040 kW | Chemische und physikalische Berechnungen (z. B. Untersuchungen von Erdöl und Flugzeugentwicklung) |
| Dawning Nebulae | National Supercomputing Center (Shenzhen, Volksrepublik China) | 1.271,00 | Hybridsystem aus 55.680 Intel Xeon-Prozessoren (2,66 GHz) + 64.960 Nvidia Tesla GPGPU (1,15 GHz), 224 TB RAM | 2.580 kW | Meteorologie, Finanzwirtschaft u. a. |
| IBM Roadrunner | Los Alamos National Laboratory (New Mexico, USA) | 1.105,00 | 6.000 AMD Dual-Core-Prozessoren (3,2 GHz), 13.000 IBM Cell-Prozessoren (1,8 GHz), 103 TB RAM | 4.040 kW | Physikalische Simulationen (z. B. Atomwaffensimulationen) |
| N. n. | Universität Bielefeld (Deutschland) | 529,70 | 208x Nvidia Tesla M2075-GPGPUs + 192x Nvidia GTX-580-GPUs + 152x Dual Quadcore Intel Xeon 5600 CPUs, 9,1 TB RAM | Fakultät für Physik: Numerische Simulationen, physikalische Berechnungen[17][18] | |
| SGI Altix | NASA (USA) | 487,00 | 51.200 4-Core-Xeon, 3 GHz, 274,5 TB RAM | 3.897 kW | Weltraumforschung |
| BlueGene/L | Lawrence Livermore National Laboratory Livermore (USA) | 478,20 | 212.992 PowerPC 440 Prozessoren 700 MHz, 73.728 GB RAM | 924 kW | Physikalische Simulationen |
| Blue Gene Watson | IBM Thomas J. Watson Research Center (USA) | 91,29 | 40.960 PowerPC 440 Prozessoren, 10.240 GB RAM | 448 kW | Forschungsabteilung von IBM, aber auch Anwendungen aus Wissenschaft und Wirtschaft |
| ASC Purple | Lawrence Livermore National Laboratory Livermore (USA) | 75,76 | 12.208 Power5 CPUs, 48.832 GB RAM | 7.500 kW | Physikalische Simulationen (z. B. Atomwaffensimulationen) |
| MareNostrum | Universitat Politècnica de Catalunya (Spanien) | 63,8 | 10.240 PowerPC 970MP 2,3 GHz, 20,4 TB RAM | 1.015 kW | Klima- und Genforschung, Pharmazie |
| Columbia | NASA Ames Research Center (Silicon Valley, Kalifornien, USA) | 51,87 | 10.160 Intel Itanium 2 Prozessoren (Madison Kern), 9 TB RAM | Klimamodellierung, astrophysikalische Simulationen |
Ausgewählte aktuelle Superrechner (deutschlandweit)
| Name | Standort | TeraFLOPS (peak) | Konfiguration | TB RAM | Energiebedarf | Zweck |
|---|---|---|---|---|---|---|
| Hawk[10][11] | Höchstleistungsrechenzentrum Stuttgart (Deutschland) | 26.000,00 | 11.264 AMD EPYC 7742(64 Kerne, 2,25 GHz), 1.44 PB RAM | 1440 | 3.500 kW | Wissenschaftliche und kommerzielle Anwendungen |
| JUWELS[19] | Forschungszentrum Jülich | 9.891,07 | 2511 Nodes mit je 4 Dual Intel Xeon Platinum 8168 (mit je 24 Kernen, 2,70 GHz),64 Nodes mit je 6 Dual Intel Xeon Gold 6148 (mit je 20 Kernen, 2,40 GHz) | 258 | 1.361 kW | |
| JUQUEEN[13] | Forschungszentrum Jülich (Deutschland) | 5.900,00 | IBM BlueGene/Q, 28.672 Power BQC-Prozessoren (16 Kerne, 1,60 GHz) | 448 | 2.301 kW | Materialwissenschaften, theoretische Chemie, Elementarteilchenphysik, Umwelt, Astrophysik |
| SuperMUC IBM[15][20] | Leibniz-Rechenzentrum (LRZ) (Garching bei München, Deutschland) | 2.897,00 | 18.432 Xeon E5-2680 CPUs (8 Kerne, 2,7 GHz), 820 Xeon E7-4870 CPUs (10 Kerne, 2,4 GHz) | 340 | 3.423 kW | Kosmologie über die Entstehung des Universums, Seismologie und Erdbebenvorhersage |
| HLRN-III[21] (Cray XC40) | Zuse-Institut Berlin, Regionales Rechenzentrum für Niedersachsen | 2.685,60 | 42.624 Cores Intel Xeon Haswell @2,5 GHz und IvyBridge @ 2,4 GHz | 222 | 500 – 1.000 kW | Physik, Chemie, Umwelt- und Meeresforschung, Ingenieurwissenschaften |
| HRSK-II[22][23] | Zentrum für Informationsdienste und Hochleistungsrechnen, TU Dresden | 1.600,00 | 43.866 CPU Kerne, Intel Haswell-EP-CPUs (Xeon E5 2680v3), 216 Nvidia Tesla-GPUs | 130 | Wissenschaftliche Anwendungen | |
| HLRE-3 „Mistral“[24][25] | Deutsches Klimarechenzentrum Hamburg | 1.400,00 | 1.550 Knoten á 2 Intel Haswell-EP-CPUs (Xeon E5-2680v3) (12 Kerne 2,5 GHz), 1750 Knoten á 2 Intel Broadwell-EP-CPUs (Xeon E5-2695V4) (18 Kerne 2,1 GHz), 100.000 Kerne, 54 PB Lustre-Festplattensystem, 21 Visualisierungsknoten (á 2 Nvidia Tesla K80 GPUs) oder (á 2 Nvidia GeForce GTX 9xx) | 120 | Klimamodellierung | |
| Cray XC40 | Deutscher Wetterdienst (Offenbach) | 1.100,00 | Cray Aries Netzwerk; 1.952 CPUs Intel Xeon E5-2680v3/E5-2695v4 | 122 | 407 kW | Numerische Wettervorhersage und Klimasimulationen |
| Lichtenberg-Hochleistungsrechner[26] | Technische Universität Darmstadt | 951.34 | Phase 1: 704 Knoten á 2 Intel Xeon (8 Cores), 4 Knoten á 8 Intel Xeon (8 Cores), 70 Knoten á 2 Intel Xeon.
Phase 2: 596 Knoten á 2 Intel Xeon (12 Cores), 4 Knoten á 4 Intel Xeon (15 Cores), 32 Knoten á 2 Intel Xeon. |
76 | Wissenschaftliche Anwendungen | |
| CARL und EDDY[27][28] | Carl von Ossietzky Universität Oldenburg | 457,2 | Lenovo NeXtScale nx360M5, 12.960 Cores (Intel Xeon E5-2650v4 12C 2,2 GHz), Infiniband FDR | 80 | 180 kW | Theoretische Chemie, Windenergieforschung, Theoretischer Physik, Neurowissenschaften und Hörforschung, Meeresforschung, Biodiversität und Informatik |
| Mogon | Johannes Gutenberg-Universität Mainz | 283,90 | 33.792 Opteron 6272 | 84 | 467 kW | Naturwissenschaften, Physik, Mathematik, Biologie, Medizin |
| OCuLUS[29] | Paderborn Center for Parallel Computing, Universität Paderborn | 200,00 | 614 Knoten Dual Intel E5-2670 (9856 Cores) und 64 GB RAM | 45 | Ingenieurwissenschaften, Naturwissenschaften | |
| HLRE 2[25] | Deutsches Klimarechenzentrum Hamburg | 144,00 | 8064 IBM Power6 Dual Core CPUs, 6 Petabyte Disk | 20 | Klimamodellierung | |
| Komplex MPI 2 | RWTH Aachen | 103,60 | 176 Knoten mit insgesamt 1.408 Intel Xeon 2,3 GHz 8-Core-Prozessoren | 22 | Wissenschaftliche Anwendungen | |
| HPC-FF | Forschungszentrum Jülich | 101,00 | 2160 Intel Core i7 (Nehalem-EP) 4-Core, 2,93 GHz Prozessoren | 24 | europäische Fusionsforschung | |
| HLRB II | LRZ Garching | 56,52 | 9.728 CPUs 1,6 GHz Intel Itanium 2 (Montecito Dual Core) | 39 | Naturwissenschaften, Astrophysik und Materialforschung | |
| ClusterVision HPC[30] | Technische Universität Bergakademie Freiberg | 22,61 | 1728 Cores Intel Xeon X5670 (2,93 GHz) + 280 Cores AMD Opteron 6276, (2,3 GHz) | 0,5 | Ingenieurwissenschaften, Quantenchemie, Strömungsmechanik, Geophysik | |
| CHiC[31] Cluster (IBM x3455) | TU Chemnitz | 8,21 | 2152 Cores aus 1076 Dual Core 64 bit AMD Opteron 2218 (2,6 GHz) | Modellierung und numerische Simulationen |
Ausgewählte aktuelle Superrechner (DACH ohne Deutschland)
Die jeweils 3 schnellsten Rechner aus der Schweiz und Österreich. Daten aus Top500 List 2017 Einträge Pos. 3, 82, 265, 330, 346, 385. In der Liste der 500 schnellsten Supercomputer der Welt findet sich keiner aus Liechtenstein. (Stand Juni 2017)
| Name | Standort | TeraFLOPS (peak) | Konfiguration | TB RAM | Energiebedarf | Zweck |
|---|---|---|---|---|---|---|
| Piz Daint (Upgrade 2016/2017, Stand Juni 2017) | Swiss National Supercomputing Centre (CSCS) (Schweiz) | 19.590,00 | Cray XC50, Xeon E5-2690v3 12C 2,6 GHz, Aries interconnect, NVIDIA Tesla P100, Cray Inc. (361.760 Kerne) | 2.272 kW | ||
| Piz Daint Multicore (Stand Juni 2017) | Swiss National Supercomputing Centre (CSCS) (Schweiz) | 1.410,70 | Cray XC40, Xeon E5-2695v4 18C 2,1 GHz, Aries interconnect, Cray Inc. (44.928 Kerne) | 519 kW | ||
| EPFL Blue Brain IV (Stand Juni 2017) | Swiss National Supercomputing Centre (CSCS) (Schweiz) | 715,60 | BlueGene/Q, Power BQC 16C 1.600GHz, Custom Interconnect; IBM (65.536 Kerne) | 329 kW | ||
| VSC-3 (Stand Juni 2017) | Vienna Scientific Cluster (Wien, Österreich) | 596,00 | Oil blade server, Intel Xeon E5-2650v2 8C 2,6 GHz, Intel TrueScale Infiniband; ClusterVision (32.768 Kerne) | 450 kW | ||
| Cluster Platform DL360 (Stand Juni 2017) | Hosting Company (Österreich) | 572,60 | Cluster Platform DL360, Xeon E5-2673v4 20C 2,3 GHz, 10G Ethernet; HPE (26.880 Kerne) | 529 kW | ||
| Cluster Platform DL360 (Stand Juni 2017) | Hosting Company (Österreich) | 527,20 | Cluster Platform DL360, Xeon E5-2673v3 12C 2,4 GHz, 10G Ethernet;HPE (20.352 Kerne) | 678 kW | ||
Die geschichtlich Schnellsten ihrer Zeit
Nachfolgende Tabelle (Stand Juni 2017) listet einige der schnellsten Superrechner ihrer jeweiligen Zeit auf:
| Jahr | Supercomputer | Spitzengeschwindigkeit bis 1959 in Operationen pro Sekunde (OPS) ab 1960 in FLOPS |
Ort |
|---|---|---|---|
| 1906 | Babbage Analytical Engine, Mill | 0,3 | RW Munro, Woodford Green, Essex, England |
| 1928 | IBM 301[32] | 1,7 | verschiedene Orte weltweit |
| 1931 | IBM Columbia Difference Tabulator[33] | 2,5 | Columbia University |
| 1940 | Zuse Z2 | 3,0 | Berlin, Deutschland |
| 1941 | Zuse Z3 | 5,3 | Berlin, Deutschland |
| 1942 | Atanasoff-Berry Computer (ABC) | 30,0 | Iowa State University, Ames (Iowa), USA |
| TRE Heath Robinson | 200,0 | Bletchley Park, Milton Keynes, England | |
| 1.000,0 | entspricht 1 kilo-OPS | ||
| 1943 | Flowers Colossus | 5.000,0 | Bletchley Park, Milton Keynes, England |
| 1946 | UPenn ENIAC (vor den Modifikationen von 1948+) |
50.000,0 | Aberdeen Proving Ground, Maryland, USA |
| 1954 | IBM NORC | 67.000,0 | U.S. Naval Proving Ground, Dahlgren, Virginia, USA |
| 1956 | MIT TX-0 | 83.000,0 | Massachusetts Inst. of Technology, Lexington, Massachusetts, USA |
| 1958 | IBM SAGE | 400.000,0 | 25 Stützpunkte der U.S. Air Force in den USA und ein Ort in Kanada (52 Computer) |
| 1960 | UNIVAC LARC | 500.000,0 | Lawrence Livermore National Laboratory, Kalifornien, USA |
| 1.000.000,0 | entspricht 1 MFLOPS, 1 Mega-FLOPS | ||
| 1961 | IBM 7030 „Stretch“ | 1.200.000,0 | Los Alamos National Laboratory, New Mexico, USA |
| 1964 | CDC 6600 | 3.000.000,0 | Lawrence Livermore National Laboratory, Kalifornien, USA |
| 1969 | CDC 7600 | 36.000.000,0 | |
| 1974 | CDC STAR-100 | 100.000.000,0 | |
| 1975 | Burroughs ILLIAC IV | 150.000.000,0 | NASA Ames Research Center, Kalifornien, USA |
| 1976 | Cray-1 | 250.000.000,0 | Los Alamos National Laboratory, New Mexico, USA (weltweit über 80 Mal verkauft) |
| 1981 | CDC Cyber 205 | 400.000.000,0 | verschiedene Orte weltweit |
| 1983 | Cray X-MP/4 | 941.000.000,0 | Los Alamos National Laboratory; Lawrence Livermore National Laboratory; Battelle; Boeing |
| 1.000.000.000,0 | entspricht 1 GFLOPS, 1 Giga-FLOPS | ||
| 1984 | M-13 | 2.400.000.000,0 | Scientific Research Institute of Computer Complexes, Moskau, UdSSR |
| 1985 | Cray-2/8 | 3.900.000.000,0 | Lawrence Livermore National Laboratory, Kalifornien, USA |
| 1989 | ETA10-G/8 | 10.300.000.000,0 | Florida State University, Florida, USA |
| 1990 | NEC SX-3/44R | 23.200.000.000,0 | NEC Fuchu Plant, Fuchū, Japan |
| 1993 | Thinking Machines CM-5/1024 | 65.500.000.000,0 | Los Alamos National Laboratory; National Security Agency |
| Fujitsu Numerical Wind Tunnel | 124.500.000.000,0 | National Aerospace Laboratory, Tokio, Japan | |
| Intel Paragon XP/S 140 | 143.400.000.000,0 | Sandia National Laboratories, New Mexico, USA | |
| 1994 | Fujitsu Numerical Wind Tunnel | 170.400.000.000,0 | National Aerospace Laboratory, Tokio, Japan |
| 1996 | Hitachi SR2201/1024 | 220.400.000.000,0 | Universität Tokio, Japan |
| 1996 | Hitachi/Tsukuba CP-PACS/2048 | 368.200.000.000,0 | Center for Computational Physics, University of Tsukuba, Tsukuba, Japan |
| 1.000.000.000.000,0 | entspricht 1 TFLOPS, 1 Tera-FLOPS | ||
| 1997 | Intel ASCI Red/9152 | 1.338.000.000.000,0 | Sandia National Laboratories, New Mexico, USA |
| 1999 | Intel ASCI Red/9632 | 2.379.600.000.000,0 | |
| 2000 | IBM ASCI White | 7.226.000.000.000,0 | Lawrence Livermore National Laboratory, Kalifornien, USA |
| 2002 | NEC Earth Simulator | 35.860.000.000.000,0 | Earth Simulator Center, Yokohama-shi, Japan |
| 2004 | SGI Project Columbia | 42.700.000.000.000,0 | Project Columbia, NASA Advanced Supercomputing Facility, USA |
| IBM BlueGene/L | 70.720.000.000.000,0 | U.S. Department of Energy/IBM, USA | |
| 2005 | IBM BlueGene/L | 136.800.000.000.000,0 | U.S. Department of Energy/U.S. National Nuclear Security Administration, Lawrence Livermore National Laboratory, Kalifornien, USA |
| 1.000.000.000.000.000,0 | entspricht 1 PFLOPS, 1 Peta-FLOPS | ||
| 2008 | IBM Roadrunner | 1.105.000.000.000.000,0 | U.S. Department of Energy/U.S. National Nuclear Security Administration, Los Alamos National Laboratory |
| 2010 | Tianhe-1A | 2.507.000.000.000.000,0 | National Supercomputer Center in Tianjin, China |
| 2011 | K computer | 10.510.000.000.000.000,0 | Advanced Institute for Computational Science, Japan |
| 2012 | Sequoia | 16.324.750.000.000.000,0 | Lawrence Livermore National Laboratory, Kalifornien, USA |
| 2012 | Titan | 17.590.000.000.000.000,0 | Oak Ridge National Laboratory, Tennessee, USA |
| 2013 | Tianhe-2 | 33.863.000.000.000.000,0 | National Supercomputer Center in Guangzhou, China |
| 2016 | Sunway TaihuLight[34] | 93.000.000.000.000.000,0 | National Supercomputing Center, Wuxi, China |
| 2018 | Summit[35] | 200.000.000.000.000.000,0 | Oak Ridge National Laboratory, Tennessee, USA |
| 1.000.000.000.000.000.000,0 | entspricht 1 EFLOPS, 1 Exa-FLOPS | ||
| Zukunft | Tianhe-3[36] | 1.000.000.000.000.000.000,0 | China, Nationales Zentrum für Supercomputer – Baustart Feb. 2017, Fertigstellung des Prototyps für Anfang 2018 angekündigt |
| Frontier[37] | 1.500.000.000.000.000.000,0 | USA, Oak Ridge National Laboratory (ORNL) – Fertigstellung 2021 angekündigt | |
| El Capitan[38] | 2.000.000.000.000.000.000,0 | USA, DOE’s Lawrence Livermore National Laboratory (LLNL) - Fertigstellung 2023 angekündigt |
Trägt man die FLOPs der schnellsten Computer ihrer Zeit gegen die Zeit auf, erhält man eine exponentielle Kurve, logarithmisch in etwa ein Gerade, wie im folgenden Graph dargestellt.
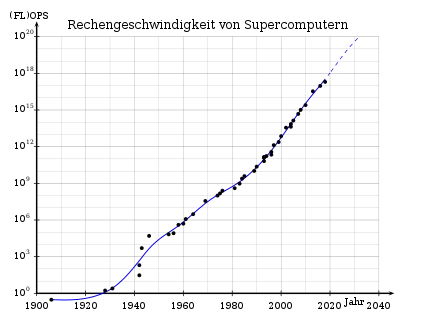
Zukünftige Entwicklung von Supercomputern
USA
Mit einer Executive Order hatte US-Präsident Barack Obama die US-Bundesbehörden angewiesen, die Entwicklung eines ExaFlops-Supercomputers voranzutreiben.[39][40] Im Jahr 2018 sollte Intels Aurora-Supercomputer eine Rechenleistung von 180 PetaFlops erreichen.[41] Im Jahr 2021 wollte das DOE einen ersten Exascale-Supercomputer aufstellen und 9 Monate später in Betrieb nehmen.[42]
China
China wollte bis 2020 einen Supercomputer mit einer Geschwindigkeit im Exaflops-Bereich entwickeln.[43] Der Prototyp von „Tianhe-3“ sollte bis Anfang 2018 fertig sein, berichtete „China Daily“ am 20. Februar 2017.[36] Im Mai 2018 wurde er vorgestellt.[44]
Europa
2011 starteten in der EU zahlreiche Projekte mit dem Ziel Software für Exascale-Supercomputer zu entwickeln. Das CRESTA-Projekt (Collaborative Research into Exascale Systemware, Tools and Applications),[45] das DEEP-Projekt (Dynamical ExaScale Entry Platform),[46][47] und das Projekt Mont-Blanc.[48] Das MaX (Materials at the Exascale) ist als weiteres wichtiges Projekt zu nennen.[49] Im März 2015 startete das SERT-Projekt unter Beteiligung der Universität von Manchester und der STFC in Cheshire.[50]
Siehe auch: Europäisches Hochleistungsrechnen.
Japan
In Japan begann 2013 das RIKEN die Planung eines Exascale-Systems für 2020 mit einem elektrischen Leistungsbedarf von weniger als 30 MW.[51] 2014 wurde Fujitsu beauftragt, die nächste Generation des K computer zu entwickeln.[52] 2015 verkündete Fujitsu auf der International Supercomputing Conference, dass dieser Supercomputer Prozessoren der ARMv8-Architektur verwenden werde.[53]
Sonstige Leistungen
Meilensteine
- 1997: Deep Blue 2 (Hochleistungsrechner von IBM) schlägt als erster Computer einen Schachweltmeister in einem offiziellen Zweikampf.
- 2002: Yasumasa Kanada bestimmt die Kreiszahl Pi mit einem Hitachi SR8000 der Universität Tokio auf 1,24 Billionen Stellen genau.
- 2007: Intels Desktopprozessor Core 2 Quad Q6600 schafft ca. 38,40 GFLOPS und hat damit Supercomputerniveau der frühen 1990er Jahre.[54]
- 2014: NVIDIAs GPU-Prozessor Tesla K80 erzielt eine Leistung von ca. 8,7 TeraFLOPS und hat damit das Supercomputerniveau der frühen 2000er Jahre. Er schlägt somit den Supercomputer des Jahres 2000, den IBM ASCI White, welcher damals eine Leistung von 7,226 TeraFLOPS bot.[55]
- 2020: Xbox Series X erzielt eine Leistung von 12 TFLOPS.[56]
Vergleiche
- Die über 500.000 aktiven Rechner der Berkeley Open Infrastructure for Network Computing (kurz BOINC) erbringen derzeit (Stand: Januar 2020) eine Spitzenrechenleistung von ca. 26 PetaFLOPS, die je nach Tag schwanken kann.[57][58]
- Die über 380.000 aktiven Rechner des Projektes Folding@home erbrachten im März 2020 eine Rechenleistung von über 1 ExaFLOP.[59][60] Damit wird das Volunteer-Verteilte System das erste Computing-System das ein exaFLOPS erreicht.[61][62][63] Das System simulierte Proteinfaltung für Forschungen zu COVID-19 und erreichte am 13. April eine Geschwindigkeit von ca. 2.43 x86-ExaFLOPS − einige Male schneller als der vorherige Rekordhalter, Supercomputer Summit.[64]
- Sämtliche Berechnungen aller Computer weltweit von 1960 bis 1970 könnte der Earth Simulator in etwa 35 Minuten durchführen.
- Wenn jeder der rund 7 Milliarden Menschen auf der Welt mit einem Taschenrechner ohne jede Unterbrechung in jeder Sekunde eine Rechnung absolvierte, müsste die gesamte Menschheit 538 Jahre arbeiten, um das zu erledigen, was der Tianhe-2 in einer Stunde bewältigen könnte.
- Mit seiner Performance könnte der K computer die Meter eines Lichtjahres binnen etwa einer Sekunde „zählen“.
- Hans Moravec bezifferte die Rechenleistung des Gehirns auf 100 Teraflops, Raymond Kurzweil auf 10.000 Teraflops. Diese Rechenleistung haben Supercomputer bereits deutlich überschritten. Zum Vergleich liegt eine Grafikkarte für 800 Euro (11/2020) bei einer Leistung von etwa 30 Teraflops.[65] (s. technologische Singularität)
Korrelatoren im Vergleich
Korrelatoren sind spezielle Geräte in der Radiointerferometrie deren Leistung man ebenfalls in Einheiten von FLOPs messen kann. Sie fallen nicht unter die Kategorie der Supercomputer, weil es sich um Spezialcomputer handelt, mit denen sich nicht jede Art von Problemen lösen lässt.
- Der Korrelator des Atacama Large Millimeter/submillimeter Array (ALMA) führt derzeit (Dezember 2012) 17 PetaFLOPS aus.[66][67]
- Die Rechenleistung des WIDAR-Korrelator am Expanded Very Large Arrays (EVLA) ist (Juni 2010) mit 40 PetaFLOPS angegeben.[68][69]
- Der geplante Korrelator des Square Kilometre Array (SKA) (Bauzeit 2016 bis 2023) soll 4 ExaFLOPS (4000 PetaFLOPS) (Informationsstand Juni 2010) ausführen können.[68]
Literatur
- Werner Gans: Supercomputing: Rekorde; Innovation; Perspektive. Hrsg.: Christoph Pöppe (= Spektrum der Wissenschaft / Dossier. Nr. 2). Spektrum-der-Wissenschaft-Verl.-Ges., Heidelberg 2007, ISBN 978-3-938639-52-8.
- Shlomi Dolev: Optical supercomputing. Springer, Berlin 2008, ISBN 3-540-85672-2.
- William J. Kaufmann, et al.: Supercomputing and the transformation of science. Scientific American Lib., New York 1993, ISBN 0-7167-5038-4.
- Paul B. Schneck: Supercomputer architecture. Kluwer, Boston 1987, ISBN 0-89838-238-6.
- Aad J. van der Steen: Evaluating supercomputers – strategies for exploiting, evaluating and benchmarking computers with advanced architectures. Chapman and Hall, London 1990, ISBN 0-412-37860-4.
Weblinks
- TOP500 Liste der leistungsstärksten Supercomputer (englisch)
- TOP500 Liste der energieeffizientesten Supercomputer (englisch)
- The International Conference for High Performance Computing and Communications (englisch)
- The International Supercomputing Conference (englisch)
- Newsletter on Supercomputing and big data (englisch und deutsch)
Einzelnachweise
- Mario Golling, Michael Kretzschmar: Entwicklung einer Architektur für das Accounting in dynamischen Virtuellen Organisationen. ISBN 978-3-7357-8767-5.
- Martin Kleppmann: Datenintensive Anwendungen designen: Konzepte für zuverlässige, skalierbare und wartbare Systeme. O'Reilly, ISBN 978-3-96010-183-3.
- Am Beispiel des SuperMUC: Supercomputer und Exportkontrolle. Hinweise zu internationalen wissenschaftlichen Kooperationen. (PDF; 293 kB) BMBF, abgerufen am 14. Juni 2018.
- List Statistics
- China verteidigt Spitzenposition orf.at, 19. Juni 2017, abgerufen 19. Juni 2017.
- The Green 500 List (Memento des Originals vom 26. August 2016 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis.
- Lenovo größter Anbieter Top500 Computer Business Wire 26.6.2018
- USA haben wieder stärksten Supercomputer orf.at, 24. Juni 2018, abgerufen 24. Juni 2018.
- Jack Dongarra: Trip Report to China and Tianhe-2 Supercomputer, 3 Juni 2013 (PDF; 8,2 MB)
- http://www.hlrs.de/systems/hpe-apollo-9000-hawk/
- https://www.uni-stuttgart.de/en/university/news/press-release/Hawk-Supercomputer-Inaugurated/
- asc.llnl.gov ASC Sequoia
- JUQUEEN Forschungszentrum Jülich
- Supercomputer. ECMWF, 2013, abgerufen am 14. Juni 2018 (englisch).
- Supercomputer: USA holen Spitzenposition zurück. Heise Online, 18. Juni 2012
- SuperMUC Petascale System. lrz.de
- Technische Daten
- sysGen-Projektreferenz (PDF; 291 kB) Universität Bielefeld, Fakultät für Physik
- JUWELS - Configuration. Forschungszentrum Jülich, abgerufen am 28. Juni 2018 (englisch).
- LRZ: SuperMUC Nr. 4 der Top500-Liste
- HLRN
- Andreas Stiller: Supercomputer an der TU-Dresden nimmt offiziell den Betrieb auf. In: Heise online. 13. März 2015, abgerufen am 14. Juni 2018.
- Andreas Stiller: Neuer Petaflops-Rechner an der TU Dresden. In: c’t. 29. Mai 2015, abgerufen am 14. Juni 2018.
- HLRE-3 "Mistral". DKRZ, abgerufen am 14. Juni 2018.
- Rechnerhistorie am DKRZ. DKRZ, abgerufen am 14. Juni 2018.
- Lichtenberg Hochleistungsrechner. HHLR, abgerufen am 4. August 2016.
- HPC Systeme an der Universität Oldenburg
- Oldenburger Universitätsrechner zählen zu den schnellsten weltweit
- OCuLUS
- ClusterVision HPC (Memento vom 23. Februar 2015 im Internet Archive)
- CHiC (Memento des Originals vom 9. Februar 2007 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis.
- IBM 301 Accounting Machine
- The Columbia Difference Tabulator – 1931
- Andreas Stiller: Supercomputer: China überholt die USA. In: Heise online. 20. Juni 2016, abgerufen am 14. Juni 2018.
- ORNL Launches Summit Supercomputer. Oak Ridge National Laboratory, 8. Juni 2018, abgerufen am 14. Juni 2018 (englisch).
- China startete Bau von neuem Supercomputer orf.at, 20. Februar 2017, abgerufen 20. Februar 2017.
- Marc Sauter: Frontier mit 1,5 Exaflops: AMD baut weltweit schnellsten Supercomputer. In: golem.de. 7. Mai 2019, abgerufen am 16. Juli 2019.
- HPE and AMD power complex scientific discovery in world’s fastest supercomputer for U.S. Department of Energy’s (DOE) National Nuclear Security Administration (NNSA). 4. März 2020, abgerufen am 6. März 2020 (englisch).
- The White House: CREATING A NATIONAL STRATEGIC COMPUTING Abgerufen: Januar 2017
- golem.de: Wie die Exaflop Marke geknackt werden soll Abgerufen: Januar 2017
- Aurora Supercomputer. top500.org. 2016. Abgerufen am 13. Januar 2017.
- First US Exascale Supercomputer Now On Track for 2021. top500.org. 10. Dezember 2016. Abgerufen am 13. Januar 2017.
- China Research: Exascale Supercomputer Abgerufen: Januar 2017
- http://german.xinhuanet.com/2018-05/18/c_137187901.htm
- Europe Gears Up for the Exascale Software Challenge with the 8.3M Euro CRESTA project. Project consortium. 14. November 2011. Abgerufen am 10. Dezember 2011.
- Booster for Next-Generation Supercomputers Kick-off for the European exascale project DEEP. FZ Jülich. 15. November 2011. Abgerufen am 13. Januar 2017.
- Supercomputer mit Turbolader. FZ Jülich. 5. November 2016. Abgerufen am 13. Januar 2017.
- Mont-Blanc project sets Exascale aims. Project consortium. 31. Oktober 2011. Abgerufen am 10. Dezember 2011.
- MaX website. project consortium. 25. November 2016. Abgerufen am 25. November 2016.
- Developing Simulation Software to Combat Humanity’s Biggest Issues. Scientific Computing. 25. Februar 2015. Abgerufen am 8. April 2015.
- Patrick Thibodeau: Why the U.S. may lose the race to exascale. In: Computerworld. 22. November 2013.
- RIKEN selects contractor for basic design of post-K supercomputer. In: www.aics.riken.jp. 1. Oktober 2014.
- Fujitsu picks 64-bit ARM for Japan's monster 1,000-PFLOPS super. In: www.theregister.co.uk. 20. Juni 2016.
- intel.com
- Michael Günsch: Tesla K80: Dual-Kepler mit bis zu 8,7 TFLOPS für Superrechner. In: ComputerBase. 17. November 2014, abgerufen am 14. Juni 2018.
- XBOX SERIES X. In: Microsoft. 2021, abgerufen am 16. Mai 2021.
- Host-Übersicht auf boincstats.com
- Übersicht BOINC-Leistung auf boincstats.com
- Folding@home stats report. Abgerufen am 26. März 2020 (englisch).
- Folding@home: Thanks to our AMAZING community, we’ve crossed the exaFLOP barrier! That’s over a 1,000,000,000,000,000,000 operations per second, making us ~10x faster than the IBM Summit!pic.twitter.com/mPMnb4xdH3. In: @foldingathome. 25. März 2020, abgerufen am 26. März 2020 (englisch).
- Folding@Home Crushes Exascale Barrier, Now Faster Than Dozens of Supercomputers - ExtremeTech. In: www.extremetech.com. Abgerufen am 13. Mai 2020.
- Folding@home crowdsourced computing project passes 1 million downloads amid coronavirus research. In: VentureBeat, 31. März 2020. Abgerufen am 13. Mai 2020.
- The coronavirus pandemic turned Folding@Home into an exaFLOP supercomputer (en-us). In: Ars Technica, 14. April 2020. Abgerufen am 13. Mai 2020.
- Liam Tung: CERN throws 10,000 CPU cores at Folding@home coronavirus simulation project (en). In: ZDNet. Abgerufen am 13. Mai 2020.
- Genug Power für 4K-Gaming. Abgerufen am 6. November 2020.
- Powerful Supercomputer Makes ALMA a Telescope
- Höchstgelegener Supercomputer der Welt gleicht Astronomiedaten ab. Heise online
- Cross-Correlators & New Correlators – Implementation & choice of architecture. (PDF; 9,4 MB) National Radio Astronomy Observatory, S. 27
- The Expanded Very Large Array Project – The ‚WIDAR‘ Correlator. (PDF; 13,2 MB) National Radio Astronomy Observatory, S. 10