Cell (Prozessor)
Cell (oder auch Cell-Broadband-Engine) ist eine Prozessorserie, die von IBM gemeinsam mit Sony und Toshiba entwickelt wurde. Die Prozessoren zeichnen sich durch die Nutzung eines 64-Bit-PowerPC-Kernes, einer Pipeline-Architektur, Unterstützung für Simultaneous Multithreading und den Einsatz einer heterogenen Mehrkern-Architektur aus, wodurch sie für paralleles Rechnen prädestiniert sind.
Aufbau
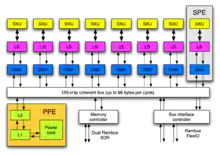
Das Grundkonzept der Cell-Prozessoren sieht acht Synergistic Processing Elements (SPE) und ein PowerPC Processing Element (PPE) vor. Die einzelnen Prozessorkerne sind über einen Element Interconnect Bus (EIB) gekoppelt, der Daten mit bis zu 96 Byte pro CPU-Takt übertragen kann. Sowohl das PPE als auch die SPEs können pro CPU-Takt mit 8 Bytes auf den EIB zugreifen. Der EIB ist dabei als Ringbus (4× 128 Bit) realisiert und wird mit halbem CPU-Takt getaktet. Der Zugriff auf den Hauptspeicher erfolgt über einen Memory Interface Controller (MIC).[1]
Synergistic Processing Element (SPE)
Jedes SPE besteht aus einer Recheneinheit (ALU) mit vierfachem SIMD, bezeichnet als Synergistic Processing Unit (SPU oder auch SPX). Diese verfügt über 128 Register, die jeweils 128 Bit groß sind. Zum SPE gehört weiterhin ein Memory Flow Controller (MFC), der DMA-Übertragungen zum Hauptspeicher oder zu anderen SPEs steuert, sowie ein eigener lokaler Speicher von 256 kB.
Lokaler Speicher und Speicherverwaltung
Der lokale Speicher (auch Load Store Unit, kurz LS) besteht aus vier getrennten 64 KB großen Speicherblöcken mit sechs Takten Latenzzeit.[2] Direkt kann eine SPU lediglich mit dem lokalen Speicher kommunizieren. Für Zugriffe oder Kommunikation mit dem Hauptspeicher, der PPE oder anderen SPUs zeichnet ein Memory Flow Controller (MFC) verantwortlich, welcher komplett unabhängig agiert. Damit lässt sich der Speicher der einzelnen SPEs theoretisch frei aufteilen oder auch mit spezifischen Zugriffsrechten schützen. Insgesamt sind 16 Speicheraktionen mit dem MFC gleichzeitig möglich.[3]
Mit dem vollständigen Verzicht auf Cache zugunsten eines direkt adressierbaren und SRAM basierten lokalen Speichers können Speicherlatenzen gegenüber einer Cache-gestützten In-Order-Architektur kontrolliert und entsprechend gering gehalten werden. Dank dieser Methode können Programmabläufe sowohl durch Compiler als auch durch direkte Programmierung in hohem Maße kontrolliert werden, sodass Out-of-order execution oder ausgefeilte Sprungvorhersagen, die unnötig die Komplexität des Prozessors erhöht hätten, für eine hohe Performance überflüssig wurden.[4]
.png.webp)
Synergistic Processing Unit (SPU)
Eine SPU arbeitet mit zwei Pipelines (even und odd), die insgesamt 23-Stufen lang sind. Die even Pipeline beherbergt die Floating Point und Fixed Point Units, während sich sämtliche andere Funktionseinheiten auf der odd Pipeline befinden. Eine SPU kann zwei Instruktionen pro Takt ausführen (dual issue), davon je eine pro Pipeline. Dies entspricht maximal acht Gleitkommaoperationen pro Takt bei einfacher Genauigkeit. Bei 3,2 GHz Taktrate ergibt sich somit eine theoretische Leistung von 25,6 GFLOPS pro SPU.[5]
Implementiert ist lediglich eine statische Sprungvorhersage. Wichtig ist in diesem Bezug deshalb die Leistung des Compilers, da Pipeline-Hazards eine Wartezeit von 18 Takten nach sich ziehen. Die hohe Anzahl an Registersätzen hilft zusätzlich Latenzen zu überbrücken, indem Schleifen aufgelöst (Loop unrolling) oder Algorithmen mehrfach parallel ausgeführt werden können.[3]
Bei den SPUs handelt es sich nicht um Koprozessoren. Sie können unabhängig voneinander arbeiten und sind zudem kompatibel zu PPE-Programmcode, sofern dieser rekompiliert und um DMA-Calls erweitert wurde. Obwohl SPUs für spezifischere Anwendungsgebiete entworfen wurden, handelt es sich um Prozessoren mit General Purpose Instruction Set.[6][7]
.png.webp)
Power Processor Element (PPE)
Der Steuerprozessor (PPE) basiert auf der 64-Bit-PowerPC-Architektur von IBM, dessen Pipeline aber im Vergleich zu üblichen PowerPC-Prozessoren in order, das heißt nacheinander abarbeitend, arbeitet. Jedoch verfügt das PPE über Delayed-Execution Pipelines, welche Out-Of-Order Execution zumindest für Load Instructions erlauben.[8] Da er zwei Threads gleichzeitig abarbeiten kann, entstehen bei entsprechend eingerichteten Programmen die üblichen In-Order-Nachteile durch blockierte Pipelines in geringerem Maße. Dem PPE stehen 512 KB L2-Cache zur Verfügung. Insgesamt verfügt die CPU also über 2,5 MB internen Speicher.
Geschichte
Der Cell-Prozessor ist eine Gemeinschaftsentwicklung von Sony, Toshiba und IBM. Die Entwicklung begann im März 2001 in einem Entwicklungscenter in Austin unter Beteiligung von Ingenieuren aller drei Firmen. Es waren zusammen über 400 Fachkräfte, verteilt über zehn Standorte weltweit, in die Entwicklung des Cell involviert. Die Synergistic Processing Units wurden dabei weitgehend am IBM-Standort im schwäbischen Böblingen entworfen.[3][5]
Insgesamt veranschlagte die Entwicklung über 400 Millionen US-Dollar,[9] weitere Milliarden wurden in die Errichtung von Foundrys investiert, darunter am IBM-Produktionsstandort in East Fishkill, New York.[5]
Der erste Cell-Prozessor wurde in 90 nm Strukturgröße im SOI-Verfahren gefertigt, dabei erreichte das Die eine Fläche von rund 235 mm². Berichte vor April 2005, die sich auf einen früheren Prototyp (DD1) des Prozessors beziehen, sprechen von einer geringfügig kleineren Die-Fläche von 221 mm². Die finale Version (DD2) verfügt über ein verbessertes PPE mit höherer SIMD-Leistung, welche mehr Platz beansprucht.[10] Ab März 2007 stellte IBM den Prozessor in 65-nm-Verfahren her, was zu einer kleineren Die-Fläche und somit zu geringeren Fertigungskosten führte.[11] Mit Einführung der PlayStation 3 Slim im August 2009 folgte ein weiterer Shrink auf 45 nm bei einer Fläche von lediglich 115 mm².[12][13]
2007 wurde eine verbesserte Variante des Cell-Prozessors auf den Markt gebracht, der PowerXCell 8i. Dieser wurde bereits vom Start weg in 65 nm gefertigt und unterstützt im Vergleich zu seinem Vorgänger Berechnungen mit Gleitkommazahlen doppelter Genauigkeit nativ, das heißt ohne Hilfsfunktionen und damit wesentlich schneller.
Einsatz
.jpg.webp)
Der Cell-Prozessor wurde mit speziellem Augenmerk auf breitbandige Berechnungsanwendungen entwickelt, vor allem Grafikberechnung und Videokodierung/-dekodierung. Die erste kommerzielle Verwendung fand das Design im September 2006 in IBM-Bladeservern mit acht SPEs.[14] Bekannt wurde der Prozessor aber vor allem durch seinen Einsatz in Sonys Spielkonsole PlayStation 3, wo er mit 3,2-GHz-Takt läuft, jedoch nur mit sieben SPEs. So können auch Cell-Chips mit nur sieben funktionierenden SPEs noch verwendet werden, wodurch die Kosten gesenkt werden können. Auch mit nur sieben SPEs erreicht der Prozessor aber eine theoretische Spitzenleistung von über 200 GFlops bei einfach genauen Gleitkommazahlen, was den Prozessoren der Konkurrenzkonsolen der siebten Generation (Xbox 360 und Wii) überlegen ist.
Des Weiteren wird der Prozessor auch in Fernsehern mit erweiterten Videofunktionen eingesetzt,[15] Cell-Derivate mit nur vier SPEs und zusätzlicher Hardware zur Videokodierung und -dekodierung finden auch in speziellen Notebooks von Toshiba Verwendung[16][17] sowie in Erweiterungskarten für PCs.[18] Der Nachfolgeprozessor PowerXCell 8i wird seit März 2007 in Servern eingesetzt.[19][20]
Weitere Informationen

Im LINPACK-Leistungsvergleich mit anderen Prozessoren schneidet der Cell BE wie folgt ab:[8]
| LINPACK (DP) | Takt- frequenz |
theoretische Leistung |
durchschnittliche Leistung |
Effizienz | Matrix |
|---|---|---|---|---|---|
| Cell BEa | 3,2 GHz | 100,00 GFlops | b | b | 4k×4k |
| SPUc | 3,2 GHz | 1,83 GFlops | 1,45 GFlops | 79,23 % | 1k×1k |
| 8 SPUsc | 3,2 GHz | 14,63 GFlops | 9,46 GFlops | 64,66 % | 1k×1k |
| Pentium 4 | 3,2 GHz | 6,40 GFlops | 3,10 GFlops | 48,44 % | 1k×1k |
| Pentium 4 + SSE3 | 3,6 GHz | 14,40 GFlops | 7,20 GFlops | 50,00 % | 1k×1k |
| Itanium | 1,6 GHz | 6,40 GFlops | 5,95 GFlops | 92,97 % | 1k×1k |
Die Werte beziehen sich auf doppelt genaue Gleitkommazahlen (64 Bits), für welche die SPUs des Cell-Prozessors nicht ausgelegt sind. Mithilfe der für doppelten Genauigkeit optimierten VMX-Einheit im PPE gelingt dem Cell-Prozessor unter der Implementierung von IBM bis zu 21,03 GFlops. Eine Arbeitsgruppe unter der Leitung von Jack Dongarra optimierte den Code durch die Nutzung eines iterativen Verfahrens. Damit lässt sich unter LINPACK bei doppelter Genauigkeit eine Performance entsprechend 100 GFlops auf einer 4K×4K-Matrix erreichen. Das PPE trägt dabei zwar ebenfalls nicht zur eigentlichen Berechnung bei, dient jedoch als Steuereinheit der SPUs.[21]
LINPACK-Berechnungen mit einfach genauen Gleitkommazahlen (32 Bits) erreichen auf einem Cell-Prozessor mit acht SPUs über 73 GFlops. Mit zunehmender Matrixgröße steigt die Recheneffizienz, so dass 8 SPUs auf einer 4K×4K-Matrix unter LINPACK etwa 156 GFlops erreichen.
Zudem ist es auch interessant, den Cell-Prozessor mit anderen Multiprozessoren zu vergleichen:
| Hersteller | Prozessor | Kerne | SIMD- Einheiten |
Takt (GHz) |
FMUL+FADD (GFLOPS) |
Spitzenleistung (GFLOPS) |
BLAS/SGEMM (GFLOPS) |
Verlustleistung (Watt) |
Ausführung |
|---|---|---|---|---|---|---|---|---|---|
| IBM | Cell BEa | 8 | 4 | 3,2 | 2 | 204,8 | 201 | 80 | Prozessor |
| Nvidia | 8800Ultra (G80) | 128 | 1 | 1,512 | 2 | 387,1 | b | >170 | Karte |
| Nvidia | 8800GTX (G80) | 128 | 1 | 1,350 | 2 | 345,6 | 105c | 120–170 | Karte |
| Nvidia | GT200b | 240 | 1 | 1,476 | n/a | 1062,7 | b | 180–240 | Karte |
| ATI | HD2900 XT (R600) | 320 | 5 | 0,742 | 2 | 474,9 | b | 150–200 | Karte |
| ATI | 1900XTX (R580) | 48 | 4 | 0,65 | 2 | 249,6 | 120 | 130–170d | Karte |
| ATI | RV770 | 800 | 5 | 0,75 | n/a | 1200 | b | 80–160 | Karte |
| ClearSpeed | CSX700[23] | 192 | 1 | 0,25 | 2 | 96 | 80 | 10 | Prozessor |
| ClearSpeed | e710 | 192 | 1 | 0,25 | 2 | 96 | 80 | 25 | Karte |
Siehe auch
Weblinks
- Cell Broadband Engine. IBM (englisch)
- Cell Architecture Explained. Details zur Cell Broadband Engine (englisch)
- Cell Broadband Engine resource center. IBM (englisch)
Einzelnachweise
- D. Pham, S. Asano, M. Bolliger, M. Day, H. Hofstee, C. Johns, J. Kahle, A. Kameyama, J. Keaty, Y. Masubuchi, M. Riley, D. Shippy, D. Stasiak, M. Suzuoki, M. Wang, J. Warnock, S. Weitzel, D. Wendel, T. Yamazakiund K. Yazawa: The design and implementation of a first-generation CELL processor. International Solid-State Circuits Conference, Februar 2005, S. 184–185
- ISSCC 2005: The CELL Microprocessor, Artikel auf Realworldtech vom 10. Februar 2005
- Cell-Kultur – Innenleben und Programmierung des Cell-Prozessons. In: c’t, S. 28 ff., Ausgabe c’t special 01/07 - Playstation 3
- Cell’s Approach - In Order with no Cache. abgerufen am 28. Januar 2011
- Cell Architecture Explained. abgerufen am 20. Januar 2013
- Practical SPU Programming in God of War III. (PDF; 4,4 MB) abgerufen am 28. Januar 2011
- The PlayStation3’s SPUs in the Real World (PDF; 62,4 MB) abgerufen am 24. Januar 2013
- IBM: Cell Broadband Engine Architecture and its first implementation - A performance view
- Holy Chip!, 30. Januar 2006 (englisch); abgerufen 13. Januar 2013.
- CELL Microprocessor III. Realworldtech, 24. Juli 2005
- IBM Produces Cell Processor Using New Fabrication Technology. (Memento des Originals vom 15. März 2007 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis. X-bit Labs, 12. März 2007
- Sony answers our questions about the new PlayStation 3. Arstechnica, 18. August 2009
- Console Die Sizes. Beyond3D, 21. November 2012
- IBM stellt Blade-Server-Modul mit Cell-Prozessoren vor. Heise.de, 13. September 2006
- Toshiba Demonstrates Cell Microprocessor Simultaneously Decoding 48 MPEG-2 Streams. Tech-On, 25. April 2005
- Toshiba Qosmio G55 – erstes Notebook mit SpursEngine. Golem.de, 18. Juni 2008
- Toshiba Qosmio G55-Q802 Laptop Computers Specs & Customer Reviews. Produktspezifikation zum Notebook mit SpursEngine-Prozessor, einem Cell-Derivat
- The WinFast PxVC1100 Video Transcoding Card: Worth The Price? Testbericht auf tomshardware.com, 28. Januar 2010
- IBM announces PowerXCell 8i, QS22 blade server. (Memento des Originals vom 16. Juni 2008 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis. Beyond3D, 13. Mai 2008
- IBM BladeCenter QS22, Produktspezifikation zum IBM-Bladeserver mit PowerXCell 8i
- Exploiting the Performance of 32 bit Floating Point Arithmetic in Obtaining 64 bit Accuracy. (PDF; 227 kB), 31. Oktober 2006 (englisch); abgerufen 5. Januar 2011
- Zelluläre Strukturen. In: c’t, 12/2007, S. 196 ff.
- Clearspeed CSX700 (Memento des Originals vom 18. Mai 2009 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis., Produktspezifikation zum CSX700-Prozessor