Message Passing Interface
Message Passing Interface (MPI) ist ein Standard, der den Nachrichtenaustausch bei parallelen Berechnungen auf verteilten Computersystemen beschreibt. Er legt dabei eine Sammlung von Operationen und ihre Semantik, also eine Programmierschnittstelle fest, aber kein konkretes Protokoll und keine Implementierung.
| MPI | |
|---|---|
| Basisdaten | |
| Entwickler | MPI Forum |
| Aktuelle Version | Version 4.0 (PDF; 4,3 MB) (9. Juni 2021) |
| Betriebssystem | Linux, Unix, Microsoft Windows NT, macOS |
| Kategorie | API |
| deutschsprachig | nein |
| MPI Webseite | |
Eine MPI-Applikation besteht in der Regel aus mehreren miteinander kommunizierenden Prozessen, die alle zu Beginn der Programmausführung parallel gestartet werden. Alle diese Prozesse arbeiten dann gemeinsam an einem Problem und nutzen zum Datenaustausch Nachrichten, welche explizit von einem zum anderen Prozess geschickt werden. Ein Vorteil dieses Prinzips ist es, dass der Nachrichtenaustausch auch über Rechnergrenzen hinweg funktioniert. Parallele MPI-Programme sind somit sowohl auf PC-Clustern (hier funktioniert der Austausch der Nachrichten z. B. über TCP), als auch auf dedizierten Parallelrechnern ausführbar (hier läuft der Nachrichtenaustausch über ein Hochgeschwindigkeitsnetz wie InfiniBand oder Myrinet oder über den gemeinsamen Hauptspeicher).
Geschichte
1992 begann die Entwicklung des MPI 1.0 Standards mit Entwürfen (November 1992, Februar 1993, November 1993). Ausgangspunkt waren ältere Kommunikationsbibliotheken wie PVM, PARMACS, P4, Chameleon und Zipcode. Der Standard erschien am 5. Mai 1994 mit
- Punkt-zu-Punkt-Kommunikation
- globale Kommunikation
- Gruppen, Kontext und Kommunikatoren
- Umgebung
- Profiling-Schnittstelle
- Spracheinbindung für C und Fortran 77
Im Juni 1995 erfolgten Fehlerkorrekturen mit MPI 1.1.
Am 18. Juli 1997 wurde die stabile Version MPI 1.2 veröffentlicht, die neben weiteren Fehlerkorrekturen eine Versionidentifikation erlaubt. Sie wird auch als MPI-1 bezeichnet.
Am 30. Mai 2008 erschien MPI 1.3 mit weiteren Fehlerkorrekturen und Klarstellungen.
Zeitgleich zur Version 1.2 wurde am 18. Juli 1997 auch der MPI 2.0 Standard verabschiedet. Dieser wird auch als MPI-2 bezeichnet und enthält unter anderem folgende Erweiterungen:
- parallele Datei-Ein-/Ausgabe
- dynamische Prozessverwaltung
- Zugriff auf Speicher anderer Prozesse
- zusätzliche Spracheinbindung von C++ und Fortran 90
Am 23. Juni 2008 wurden die bisher separaten Teile MPI-1 und MPI-2 zu einem gemeinsamen Dokument vereint und als MPI 2.1 veröffentlicht. MPI Standard Version 2.2 ist vom 4. September 2009 und enthält weitere Verbesserungen und kleinere Erweiterungen.
Am 21. September 2012 hat das MPI Forum MPI-3 veröffentlicht,[1] das neue Funktionalität einarbeitet wie beispielsweise nicht blockierende Kollektive, ein verbessertes einseitiges Kommunikationsmodell (RMA, Remote Memory Access), ein neues Fortran-Interface, topographiebezogene Kommunikation und nicht blockierende parallele Ein- und Ausgabe.[2]
Am 9. Juni 2021 wurde MPI-4 veröffentlicht. Wesentliche Neuerungen sind Funktionsinterfaces, die Parameter mit einem größeren Wertebereich unterstützen. Zuvor waren durch den vorgegebenen 32-bit Datentyp wesentliche Größen, wie z. B. die Anzahl zu kommunizierender Datenelemente, auf etwas mehr als zwei Milliarden beschränkt. Persistente Kollektive eröffnen Möglichkeiten zur Optimierung wiederholt ausgeführter Kommunikation und sind zudem im Gegensatz zu den schon vorhandenen kollektiven Operationen in beliebiger Reihenfolge ausführbar. Zudem wurde die Fehlerbehandlung in vielen Punkten verbessert und ein neues Session-Modell zur dynamischen Nutzung der von MPI verwalteten Ressourcen eingeführt.[3]
Zu den Hauptentwicklern gehört Bill Gropp.
Punkt-zu-Punkt Kommunikation
Die grundlegendste Art der Kommunikation findet zwischen zwei Prozessen statt: ein Sendeprozess übermittelt dabei Informationen an einen Empfangsprozess. In MPI werden diese Informationen in sogenannte Nachrichten verpackt, die mit den Parametern buffer, count, und datatype beschrieben werden. Zu jeder Sendeoperation muss eine passende Empfangsoperation existieren. Da in parallelen Anwendungen die bloße Reihenfolge der Abarbeitung von Operationen nicht immer ausreichend ist, bietet MPI zusätzlich den tag-Parameter an – nur wenn dieser Wert bei Sende- und Empfangsoperation identisch ist, dann passen beide zusammen.
Blockierendes Senden und Empfangen
Die einfachsten Operationen für eine Punkt-zu-Punkt Kommunikation sind senden und empfangen:
int MPI_Send (void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
- buf: Zeiger auf den Sendepuffer
- count: Zahl der Elemente im Sendepuffer
- datatype: Datentyp der Elemente im Sendepuffer
- dest: Rang des Zielprozesses
- tag: Markierung der Nachricht
- comm: Kommunikator der Prozessgruppe
int MPI_Recv (void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status* status)
buf: Zeiger auf einen Empfangspuffer ausreichender Größecount: Zahl der Elemente im Empfangspufferdatatype: Datentyp der Elemente im Empfangspuffersource: Rang des Quellprozesses (mitsource=MPI_ANY_SOURCEwird von einem beliebigen Prozess empfangen)tag: erwartete Markierung der Nachricht (mittag=MPI_ANY_TAGwird jede Nachricht empfangen)comm: Kommunikator der Prozessgruppestatus: Zeiger auf eine Statusstruktur, in der Informationen über die empfangene Nachricht abgelegt werden sollen
Die beiden Operationen sind blockierend und asynchron. Das bedeutet:
MPI_Recvkann ausgeführt werden, bevor das zugehörigeMPI_Sendgestartet wurdeMPI_Recvblockiert, bis die Nachricht vollständig empfangen wurde
Analog gilt:
MPI_Sendkann ausgeführt werden, bevor das zugehörigeMPI_Recvgestartet wurdeMPI_Sendblockiert, bis der Sendepuffer wiederverwendet werden kann (d. h. die Nachricht vollständig übermittelt oder zwischengepuffert wurde)
Programmbeispiel
Die Verwendung von MPI_Send und MPI_Recv wird im folgenden ANSI-C-Beispiel für 2 MPI-Prozesse veranschaulicht:
#include "mpi.h"
#include <stdio.h>
#include <string.h>
int main(int argc, char *argv[])
{
int myrank, message_size=50, tag=42;
char message[message_size];
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
if (myrank == 0) {
MPI_Recv(message, message_size, MPI_CHAR, 1, tag, MPI_COMM_WORLD, &status);
printf("received \"%s\"\n", message);
}
else {
strcpy(message, "Hello, there");
MPI_Send(message, strlen(message)+1, MPI_CHAR, 0, tag, MPI_COMM_WORLD);
}
MPI_Finalize();
return 0;
}
Nichtblockierende Kommunikation
Die Effizienz einer parallelen Anwendung kann oftmals gesteigert werden, indem man Kommunikation mit Berechnung überlappt und/oder synchronisationsbedingte Wartezeiten vermeidet. Dazu definiert der MPI-Standard sogenannte nichtblockierende Kommunikation, bei der die Kommunikationsoperation lediglich angestoßen wird. Eine separate Funktion muss dann aufgerufen werden, um solch eine Operation zu beenden. Im Unterschied zur blockierenden Variante wird beim Starten der Operation ein Request-Objekt erzeugt, mit dessen Hilfe auf die Beendigung dieser Operation geprüft oder gewartet werden kann.
int MPI_Isend (void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request* request)
- …
request: Adresse der Datenstruktur, die Informationen zur Operation enthält
int MPI_Irecv (void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request* request)
- …
Fortschritt abfragen
Um den Fortschritt einer dieser Operationen zu erfahren, wird folgende Operation verwendet:
int MPI_Test (MPI_Request* request, int* flag, MPI_Status* status)
Wobei flag=1 oder 0 gesetzt wird, je nachdem, ob die Operation abgeschlossen ist oder noch andauert.
Blockierend warten
Um dennoch blockierend auf eine MPI_Isend- oder MPI_Irecv-Operation zu warten, wird folgende Operation benutzt:
int MPI_Wait (MPI_Request* request, MPI_Status* status)
Synchronisierendes Senden
Für die Sendeoperationen werden auch die synchronen Varianten MPI_Ssend und MPI_Issend definiert. In diesem Modus wird das Senden erst dann beendet, wenn die zugehörige Empfangsoperation begonnen wurde.
Puffernde Varianten
…
Gruppen und Kommunikatoren
Prozesse lassen sich in Gruppen zusammenfassen, wobei jedem Prozess eine eindeutige Nummer, der sogenannte Rang zugeordnet wird. Für den Zugriff auf eine Gruppe wird ein Kommunikator benötigt. Soll also eine globale Kommunikationsoperation auf eine Gruppe beschränkt werden, so muss der zur Gruppe gehörende Kommunikator angegeben werden. Der Kommunikator für die Menge aller Prozesse heißt MPI_COMM_WORLD.
Die zum Kommunikator comm gehörende Gruppe erhält man mit
int MPI_Comm_group (MPI_Comm comm, MPI_Group* group)
Für Prozessgruppen stehen die üblichen Mengenoperationen zur Verfügung.
Vereinigung
Zwei Gruppen group1 und group2 können zu einer neuen Gruppe new_group vereinigt werden:
int MPI_Group_union (MPI_Group group1, MPI_Group group2, MPI_Group* new_group)
Die Prozesse aus group1 behalten ihre ursprüngliche Nummerierung. Die aus group2, die nicht bereits in der ersten enthalten sind, werden fortlaufend weiter nummeriert.
Schnittmenge
Die Schnittmenge zweier Gruppen erhält man mit
int MPI_Group_intersection (MPI_Group group1, MPI_Group group2, MPI_Group* new_group)
Differenz
Die Differenz zweier Gruppen erhält man mit
int MPI_Group_difference (MPI_Group group1, MPI_Group group2, MPI_Group* new_group)
Globale Kommunikation
In parallelen Anwendungen trifft man häufig spezielle Kommunikationsmuster an, bei denen mehrere oder gar alle MPI Prozesse gleichzeitig beteiligt sind. Der MPI-Standard hat deswegen für die wichtigsten Muster eigene Operationen definiert. Diese unterscheidet man grob in drei Arten: Synchronisation (Barrier), Kommunikation (z.Bsp. Broadcast, Gather, Alltoall) und Kommunikation gekoppelt mit Berechnung (z. B. Reduce oder Scan). Manche dieser Operationen verwenden einen ausgewählten MPI-Prozess, der eine Sonderrolle einnimmt und der typischerweise mit root bezeichnet wird. Wo es sinnvoll ist, existieren zusätzlich zu den regulären Kommunikationsoperationen noch vektorbasierte Varianten (z. B. Scatterv), die unterschiedliche Argumente pro Prozess ermöglichen.
Broadcast (ausstrahlen)

Mit der Broadcast-Operation schickt ein ausgewählter MPI-Prozess root allen anderen Prozessen in seiner Gruppe comm die gleichen Daten.
Die dafür definierte Funktion ist dabei für alle beteiligten Prozesse identisch:
int MPI_Bcast (void *buffer, int count, MPI_Datatype type, int root, MPI_Comm comm)
Der MPI Prozess root stellt in buffer seine Daten zur Verfügung, während die anderen Prozesse hier die Adresse ihres Empfangspuffers übergeben. Die restlichen Parameter müssen bei allen Prozessen gleich (bzw. gleichwertig) sein. Nachdem die Funktion zurückkehrt, befinden sich in allen Puffern die Daten, die ursprünglich nur bei root vorhanden waren.
Gather (sammeln)

Mit der Gather-Operation sammelt der MPI-Prozess root die Daten aller beteiligten Prozesse ein. Die Daten aller Sendepuffer werden dabei (nach Rang sortiert) hintereinander im Empfangspuffer abgelegt:
int MPI_Gather (void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
Vektorbasierte Variante
Die vektorbasierte Variante der Gather-Operation erlaubt eine prozessabhängige Anzahl von Elementen:
int MPI_Gatherv (void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int *recvcounts, int *displs, MPI_Datatype recvtype, int root, MPI_Comm comm)
recvcounts: Feld, das die Zahl der Elemente enthält, die von den einzelnen Prozessen empfangen werden (nur fürrootrelevant)displs: Feld, dessen Eintrag i die Verschiebung im Empfangspuffer festlegt, bei der die Daten von Prozess i abgelegt werden sollen (ebenfalls nur fürrootrelevant)
Bei den Feldern ist zu beachten, dass im Empfangspuffer zwar Lücken erlaubt sind aber keine Überlappungen.
Sollen also etwa von 3 Prozessen jeweils 1, 2 und 3 Elemente vom Typ Integer empfangen werden, so muss recvcounts = {1, 2, 3} und displs = {0, 1 * sizeof(int), 3 * sizeof(int)} gesetzt werden.
Scatter (streuen)
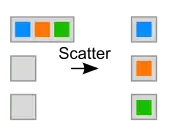
Mit einer Scatter-Operation schickt der MPI Prozess root jedem beteiligten Prozess ein unterschiedliches, aber gleich großes Datenelement:
int MPI_Scatter (void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
Vektorbasierte Variante
int MPI_Scatterv (void *sendbuf, int *sendcounts, int *displs, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
Akkumulation
Die Akkumulation ist eine spezielle Form der Gather-Operation. Hierbei werden ebenfalls die Daten aller beteiligten Prozesse aufgesammelt, aber zusätzlich noch mittels einer festgelegten Reduktionsoperation zu einem Datum reduziert. Sei beispielsweise der Wert bei dem Prozess mit Rang , dann liefert Reduce(+) die Gesamtsumme aller Werte: .



int MPI_Reduce (void *sendbuf, void *recvbuf, int count, MPI_Datatype type, MPI_Op op, int root, MPI_Comm comm)
Für den Parameter op existieren dabei folgende vordefinierte Reduktionsoperationen:
Logische Operationen
MPI_LAND: logische UND-VerknüpfungMPI_BAND: bitweise UND-VerknüpfungMPI_LOR: logische ODER-VerknüpfungMPI_BOR: bitweise ODER-VerknüpfungMPI_LXOR: logische exklusiv-ODER-VerknüpfungMPI_BXOR: bitweise exklusiv-ODER-Verknüpfung
Arithmetische Operationen
MPI_MAX: MaximumMPI_MIN: MinimumMPI_SUM: SummeMPI_PROD: ProduktMPI_MINLOC: Minimum mit ProzessMPI_MAXLOC: Maximum mit Prozess
Die Operationen MPI_MINLOC und MPI_MAXLOC geben zusätzlich den Rang des MPI-Prozesses zurück, der das Ergebnis bestimmte.
Benutzerdefinierte Operationen
Zusätzlich zu den vordefinierten Reduktionsoperationen können auch eigene Reduktionsoperationen verwendet werden. Dazu wird eine frei programmierbare binäre Verknüpfungsoperation, die assoziativ sein muss und optional kommutativ sein kann, dem MPI bekanntgegeben:
int MPI_Op_create (MPI_User_function *function, int commute, MPI_Op *op)
Die dazugehörige Nutzerfunktion berechnet aus zwei Eingabewerten einen Ausgabewert und macht dies – aus Optimierungsgründen – nicht nur einmal mit Skalaren, sondern elementweise auf Vektoren beliebiger Länge:
typedef void MPI_User_function (void *invec, void *inoutvec, int *len, MPI_Datatype *datatype)
Präfixreduzierung
Zusätzlich zur oben genannten Akkumulation, existiert auch eine Allreduce Variante – welche das gleiche Ergebnis allen MPI-Prozessen zur Verfügung stellt und nicht nur einem root Prozess. Die sogenannte Präfixreduzierung erweitert nun diese Möglichkeit, indem nicht allen Prozessen das gleiche Ergebnis, sondern stattdessen ein prozessspezifisches Teilergebnis berechnet wird. Sei beispielsweise erneut der Wert bei dem Prozess mit Rang , dann liefert Scan(+) die Partialsumme der Werte von Rang bis : .


int MPI_Scan (void *sendbuf, void *recvbuf, int count, MPI_Datatype type, MPI_Op op, MPI_Comm comm)
Soll der eigene Wert nicht mit in die Berechnung eingehen (d. h., ausgeschlossen werden), so kann dies mit der exklusiven Scan Funktion MPI_Exscan bewerkstelligt werden.
Allgather
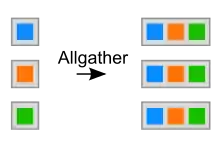
Bei der Allgather-Operation schickt jeder Prozess an jeden anderen Prozess die gleichen Daten. Es handelt sich also um eine Multi-Broadcast-Operation, bei der es keinen gesonderten MPI-Prozess gibt.
int MPI_Allgather (void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm)
All-to-all (Gesamtaustausch)

Bei der All-to-all-Kommunikation werden – ähnlich wie bei der Allgather-Kommunikation – Daten zwischen allen Prozessen ausgetauscht. Dabei wird jedoch nur der i-te Teil des Sendebuffers an den i-ten Prozess gesendet. Daten, die vom Prozess mit dem Rang j kommen, werden entsprechend an j-ter Stelle im Empfangsbuffer gespeichert.
int MPI_Alltoall (void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm)
Des Weiteren gibt es noch die synchronisierende MPI_Barrier-Operation. Diese Funktion kehrt erst zurück, nachdem alle in der angegebenen Gruppe befindlichen MPI-Prozesse diesen Teil des Programmes erreicht haben.
MPI-2
Seit 1997 ist eine zweite Version des MPI-Standards verfügbar, die einige Erweiterungen zu dem weiterhin bestehenden MPI-1.1 Standard hinzufügt. Zu diesen Erweiterungen gehören unter anderem
- eine dynamische Prozessverwaltung, d. h. Prozesse können nun zur Laufzeit erzeugt und gelöscht werden
- [paralleler] Zugriff auf das Dateisystem
- einseitige Kommunikation
- Spezifikation zusätzlicher Sprachschnittstellen (C++, Fortran 90), wobei die Sprachschnittstellen zu C++ seit MPI 2.2 als veraltet markiert sind
Beispiel: Lesen einer nx(n+1)-Matrix mit paralleler Datei-Eingabe und size Prozessen mit den Nummern rank = 0 … size-1. Die Spalte n+1 enthält die rechte Seite des Gleichungssystems A * x = b in Form der erweiterten Matrix [A, b]. Die Zeilen der Matrix werden gleichmäßig auf die Prozessoren verteilt. Die Verteilung erfolgt zyklisch (Jeder Prozessor eine Zeile, nach size Zeilen wird wieder rank=0 bedient) und nicht blockweise (jeder Prozessor bekommt einen zusammenhängenden Block von n/size Zeilen):
ndims = 1; /* dimensions */ aosi [0] = size * (n+1); /* array of sizes */ aoss [0] = n+1; /* array of subsizes */ aost [0] = rank * (n+1); /* array of starts */ order = MPI_ORDER_C; /* row or column order */ MPI_Type_create_subarray (ndims, aosi, aoss, aost, order, MPI_DOUBLE, &ft); MPI_Type_commit (&ft);
MPI_File_open (MPI_COMM_WORLD, fn, MPI_MODE_RDONLY, MPI_INFO_NULL, &fh); MPI_File_set_view (fh, sizeof (int), MPI_DOUBLE, ft, „native“, MPI_INFO_NULL);
for (i = rank; i < n; i+=size)
{ MPI_File_read (fh, rdbuffer, n+1, MPI_DOUBLE, &status);
for (j = 0; j < n+1; j++)
{ A [i / size] [j] = rdbuffer [j]; /* nur die dem Prozess zugeordneten Zeilen */
} }
MPI_File_close (&fh);
Die Schnittstelle folgt mit leichten der Parallelität geschuldeten Änderungen dem POSIX-1003.1-Standard. Die Datei wird mit MPI_File_open zum gemeinsamen Lesen eröffnet. Die Blenden (views) für die einzelnen Prozesse werden mit MPI_File_set_view festgelegt. Hier wird die vorher definierte Variable ft (filetype) benötigt, in der in einem Block von size * (n+1) doubles eine Zeile mit n+1 doubles herausgepickt wird, die bei Position rank * (n+1) beginnt. Somit wird vom gesamten Block jedem Prozess sukzessive genau eine Zeile zugewiesen. Dieser Typ wird mit MPI_Type_create_subarray definiert und mit MPI_Type_commit im MPI-System bekanntgemacht. Jeder Prozess liest mit MPI_File_read „seine“ Zeilen mit den Nummern i = rank, rank + size, rank + 2*size, … bis die gesamte Matrix gelesen wurden. Das Argument size of (int) berücksichtigt die Größe der Matrix, die am Anfang der Datei als int gespeichert wird.
Gewinn: In size Prozessoren kann eine Matrix verteilt gespeichert werden, die auf einem einzelnen Prozessor in dessen Speicher keinen Platz mehr hätte. Das rechtfertigt auch die Konvention, als Speicher einer Parallelanlage die Summe des Speichers der Einzelcores und Einzelknoten anzugeben.
Dateiformat:
n Zeile 0 (n+1) Zahlen für Prozess rank 0 Zeile 1 (n+1) Zahlen für Prozess rank 1 … Zeile r (n+1) Zahlen für Prozess rank r … Zeile size-1 (n+1) Zahlen für Prozess rank size-1
Zeile size (n+1) Zahlen für Prozess rank 0 Zeile size+1 (n+1) Zahlen für Prozess rank 1 … Zeile size+r (n+1) Zahlen für Prozess rank r … Zeile 2*size-1 (n+1) Zahlen für Prozess rank size-1
Zeile 2*size (n+1) Zahlen für Prozess rank 0 … … es folgen entsprechend der Zeilenzahl der Matrix ausreichend viele solcher Blöcke
Das eigentliche Lesen erfolgt mit MPI_File_read. Jeder Prozess liest sequentiell nur die ihm zugeteilten Zeilen. Die kollektive Operation besteht darin, dass die MPI-Bibliothek das Lesen optimieren und parallelisieren kann. Nach Ende des Lesens muss die Datei wie üblich geschlossen werden. Das geschieht mit MPI_File_close. MPI verfügt für die Operationen über eigene Datentypen MPI_Datatype ft und MPI_File fh. Die Beschreibung des filetypes erfolgt mit normalen C-Variablen: int ndims; int aosi [1]; int aoss [1]; int aost [1]; int order;
Weiteres in.[4]
Implementierungen
C++, C und Fortran
Die erste Implementierung des MPI-1.x-Standards war MPICH vom Argonne National Laboratory und der Mississippi State University. Mittlerweile ist MPICH2 verfügbar, das den MPI-2.1-Standard implementiert. LAM/MPI vom Ohio Supercomputing Center war eine weitere freie Version, deren Weiterentwicklung inzwischen zugunsten von Open MPI eingestellt wurde.
Ab der Version 1.35 der Boost Libraries gibt es Boost.MPI, eine C++-freundliche Schnittstelle zu verschiedenen MPI-Implementierungen. Auch andere Projekte, wie z. B. TPO++, bieten diese Möglichkeit und sind in der Lage, STL-Container zu versenden und zu empfangen.
C#
- MPI.NET (MPI1)
Python
- MPI for Python (MPI-1/MPI-2)
- pyMPI
- Boost:MPI Python Bindings (Entwicklung eingestellt)
Java
- MPJ Express
- mpiJava (MPI-1; Entwicklung eingestellt)
Perl
R
Haskell
Siehe auch
Literatur
- Heiko Bauke, Stephan Mertens: Cluster Computing. Springer, 2006, ISBN 3-540-42299-4
- William Gropp, Ewing Lusk, Anthony Skjellum: MPI – Eine Einführung – Portable parallele Programmierung mit dem Message-Passing Interface. München 2007, ISBN 978-3-486-58068-6.
- M. Firuziaan, O. Nommensen: Parallel Processing via MPI & OpenMP. Linux Enterprise, 10/2002
- Marc Snir, Steve Otto, Steven Huss-Lederman, David Walker, Jack Dongarra: MPI – The complete reference, Vol 1: The MPI core. 2. Auflage. MIT Press, 1998
- William Gropp, Steven Huss-Lederman, Andrew Lumsdaine, Ewing Lusk, Bill Nitzberg, William Saphir, Marc Snir: MPI-The Complete Reference, Vol. 2: The MPI-2 Extensions. The MIT Press, 1998.
Weblinks
Einzelnachweise
- MPI Documents (Memento des Originals vom 6. November 2006 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis.
- The Future of MPI. (PDF; 2,4 MB)
- Changes in MPI-4.0
- MPI-2: Extensions to the Message-Passing Interface (Memento des Originals vom 21. September 2007 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis.