Prozessor
Ein Prozessor ist ein (meist sehr stark verkleinertes und meist frei) programmierbares Rechenwerk, also eine Maschine oder eine elektronische Schaltung, die gemäß übergebenen Befehlen andere Maschinen oder elektrische Schaltungen steuert und dabei einen Algorithmus (Prozess) vorantreibt, was meist Datenverarbeitung beinhaltet. Der weitere Artikel beschreibt ausschließlich diese Bedeutung, am Beispiel des Prozessors eines Computers. Am bekanntesten sind Prozessoren als Hauptprozessor, Zentrale Recheneinheit, Zentraleinheit oder Zentrale Verarbeitungseinheit (kurz ZVE, englisch central processing unit, kurz CPU) für Computer oder computerähnliche Geräte, in denen sie Befehle ausführen. Am weitesten verbreitet sind Prozessoren heutzutage als integrierte Schaltungen in Form von Mikroprozessoren und Mikrocontroller in eingebetteten Systemen (etwa in Waschmaschinen, Ticketautomaten, DVD-Spielern, Smartphones usw.).

Begriffsverständnis
Im früheren Sprachgebrauch wurde unter dem Begriff „Prozessor“ sowohl das Bauteil verstanden (ein Halbleiter-Chip in einem Plastikgehäuse, der mit seinen Beinchen in einen Sockel eingesteckt wird), als auch eine datenverarbeitende Logik-Einheit. Heutzutage besitzen jedoch viele Mikroprozessoren mehrere sogenannte Prozessorkerne, wobei jeder Kern für sich eine (weitgehend) eigenständige Logik-Einheit darstellt. Unter dem Begriff Prozessor wird heute im Allgemeinen das Bauteil verstanden; ist die datenverarbeitende Logik-Einheit gemeint, wird meist vom Prozessorkern gesprochen.
Übertragene Bedeutungen des Begriffs CPU
Der Begriff CPU wird umgangssprachlich auch in anderem Kontext für Zentraleinheit (ZE) benutzt, hierbei kann dies für einen zentralen Hauptrechner (ein kompletter Computer) stehen, an dem einzelne Terminal-Arbeitsstationen angeschlossen sind. Teilweise wird der Begriff auch als Metapher benutzt, bei Computerspielen zum Beispiel als „Ein Spiel gegen die CPU“.
Grundlegende Informationen
Hauptbestandteile eines Prozessor(kern)s sind das Rechenwerk (insbesondere die arithmetisch-logische Einheit, ALU) sowie das Steuerwerk (inkl. Adresswerk).[1][2] Darüber hinaus enthalten sie meist mehrere Register und einen Speichermanager (engl. Memory Management Unit, MMU), der den Arbeitsspeicher verwaltet. Zu den zentralen Aufgaben des Prozessors gehören die Abarbeitung des Maschinenprogramms: arithmetische und logische Operationen zur Verarbeitung von Daten aus internen oder externen Quellen, beispielsweise dem Arbeitsspeicher.
Neben diesen Hauptbestandteilen, die die Grundfunktionen bereitstellen, kann es weitere Recheneinheiten geben, die spezialisierte Funktionen zur Verfügung stellen und den eigentlichen Prozessor entlasten sollen – diese Einheiten werden meist als Koprozessor bezeichnet. Beispiele hierfür sind der bis in die 1990er Jahre separate mathematische Koprozessor für Gleitkommaoperationen (die Gleitkommaeinheit) sowie Grafik- und Soundprozessoren. In diesem Zusammenhang wird der zentrale Prozessor mit seinen im vorhergehenden Absatz beschriebenen Grundfunktionen auch als Hauptprozessor (oder kurz, mit der englischen Abkürzung, als CPU) bezeichnet. Weitere Synonyme sind Zentrale Verarbeitungseinheit (kurz ZVE oder auch Zentraleinheit). Die moderne Form des Prozessors ist der Mikroprozessor, der alle Bausteine des Prozessors in einem integrierten Schaltkreis (Mikrochip) vereinigt. Moderne Prozessoren für Desktop-Computer und Notebooks aber auch für Smartphones und Tabletcomputer sind oft Mehrkernprozessoren mit zwei, vier oder mehr Prozessorkernen. Die Prozessorkerne sind hierbei oft eigenständige „Prozessoren“ mit Steuer-/Leitwerk und Rechenwerk auf einem Chip. Beispiele hierfür sind der Intel Core 2, der AMD Athlon X2 oder der Nvidia Tegra 3. Eine klare Abgrenzung der Begriffe Prozessor, Hauptprozessor, CPU und Prozessorkern ist in der Literatur nicht zu finden, siehe Abschnitt Hauptprozessor, CPU und Prozessorkern.
Prozessoren werden oft im Bereich der eingebetteten Systeme (englisch embedded systems) eingesetzt: zur Steuerung von Haushaltsgeräten, Industrieanlagen, Unterhaltungselektronik usw. In Großrechnern (englisch mainframes) wurden früher meist herstellereigene Prozessorarchitekturen verwendet, wie etwa bei IBM (PowerPC, Cell-Prozessor) oder SUN (SPARC-Prozessor); heute werden überwiegend angepasste Versionen der verbreiteten PC-Prozessormodelle verwendet.
Prozessoren für eingebettete Systeme machen etwa 95 Prozent des Prozessormarkts aus, wobei davon 90 Prozent sogenannte Mikrocontroller sind, die neben dem eigentlichen Prozessor weitere Funktionen (zum Beispiel spezielle Hardwareschnittstellen oder direkt integrierte Sensoren) enthalten. Nur etwa 5 Prozent werden in PCs, Workstations oder Servern eingesetzt.[3]
Historische Entwicklung


In den 1940er Jahren wurden die vormals rein mechanischen Rechenwerke durch Computer aus Relais und mechanischen Bauelementen abgelöst. Die ZUSE Z3 gilt als der erste funktionsfähige Digitalrechner weltweit und wurde im Jahr 1941 von Konrad Zuse in Zusammenarbeit mit Helmut Schreyer in Berlin gebaut. Die Z3 bestand aus 600 Relais für das Rechenwerk und 1400 Relais für das Speicherwerk.[4] Diese ersten Computer waren also elektromechanische Rechner, die äußerst störanfällig waren. Noch in den 1940ern begannen findige Elektroingenieure damit, Computer mit Hilfe von Elektronenröhren zu bauen. Der erste funktionsfähige Rechner dieser Generation war der ENIAC. Der ENIAC verfügte über 20 elektronische Register, 3 Funktionstafeln als Festspeicher und bestand aus 18.000 Röhren sowie 1.500 Relais.[5] Damit konnten die Rechenautomaten komplexere Berechnungen ausführen und wurden weniger störanfällig, aber von einzelnen Prozessoren in späteren Sinne konnte noch keine Rede sein. Waren diese Rechner anfangs teure Einzelprojekte, so reifte die Technik im Laufe der 1950er Jahre immer mehr aus. Röhrencomputer wurden nach und nach zu Artikeln der Serienfertigung, die für Universitäten, Forschungseinrichtungen und Unternehmen durchaus erschwinglich waren. Um dieses Ziel zu erreichen, war es notwendig, die Anzahl der benötigten Röhren auf ein Mindestmaß zu reduzieren. Aus diesem Grund setzte man Röhren nur dort ein, wo sie unabdingbar waren. So begann man damit, Hauptspeicher und CPU-Register auf einer Magnettrommel unterzubringen, Rechenoperationen seriell auszuführen und die Ablaufsteuerung mit Hilfe einer Diodenmatrix zu realisieren. Ein typischer Vertreter dieser Rechnergeneration war der LGP-30.
Erste Erwähnungen des Begriffes CPU gehen in die Anfänge der 1950er Jahre zurück. So wurde in einer Broschüre von IBM zu dem 705 EDPM aus dem Jahr 1955 der Begriff „Central Processing Unit“ zuerst ausgeschrieben, später mit der Abkürzung CPU in Klammern ergänzt und danach nur noch in seiner Kurzform verwendet.[6] Ältere IBM-Broschüren verwenden den Begriff nicht, so z. B. die Broschüre „Magnetic Cores for Memory in Microseconds in a Great New IBM Electronic Data Processing Machine for Business“ von 1954, in der zwar ebenfalls die IBM 705 dargestellt wird, an den entsprechenden Stellen jedoch lediglich von „data processing“ die Rede ist.[7] Auch in dem Informationstext von IBM zur 704 EDPM, dem Vorgänger der 705 EDPM, aus dem Mai 1954 sucht der Leser den Begriff vergeblich.[8]
In den 1950er Jahren wurden die unzuverlässigen Elektronenröhren von Transistoren verdrängt, die zudem den Stromverbrauch der Computer senkten. Anfangs wurden die Prozessoren aus einzelnen Transistoren aufgebaut. Im Laufe der Jahre brachte man aber immer mehr Transistorfunktionen auf integrierten Schaltkreisen (ICs) unter. Waren es zunächst nur einzelne Gatter, integrierte man immer häufiger auch ganze Register und Funktionseinheiten wie Addierer und Zähler, schließlich dann sogar Registerbänke und Rechenwerke auf einem Chip. Der Hauptprozessor konnte in einem einzelnen Schaltschrank untergebracht werden, was zum Begriff Mainframe, also „Hauptrahmen“, bzw. „Hauptschrank“ führte. Dies war die Zeit der Minicomputer, die nun keinen ganzen Saal mehr ausfüllten, sondern nur noch ein Zimmer. Die zunehmende Integration von immer mehr Transistor- und Gatterfunktionen auf einem Chip und die stetige Verkleinerung der Transistorabmaße führte dann Anfang der 1970er Jahre fast zwangsläufig zu der Integration aller Funktionen eines Prozessors auf einem Chip, dem Mikroprozessor. Anfangs noch wegen ihrer vergleichsweise geringen Leistungsfähigkeit belächelt (der Legende nach soll ein IBM-Ingenieur über den ersten Mikroprozessor gesagt haben: „Nett, aber wozu soll das gut sein?“), haben Mikroprozessoren heute alle vorangegangenen Techniken für den Aufbau eines Hauptprozessors abgelöst.
Dieser Trend setzte sich auch in den nachfolgenden Jahrzehnten fort. So wurde Ende der 1980er Jahre der mathematische Coprozessor und Ende der 2000er Jahre auch der Grafikprozessor in den (Haupt-)Prozessor integriert, vgl. APU.
Aufbau / Funktionale Einheiten
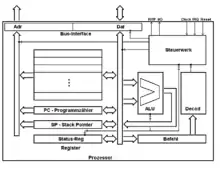
Ein Prozessor(kern) besteht mindestens aus Registern (Speicher), einem Rechenwerk (der Arithmetic Logic Unit, kurz ALU), einem Steuerwerk sowie den Datenleitungen (Busse), die die Kommunikation mit anderen Komponenten ermöglichen (Abbildung siehe weiter unten). Diese Komponenten sind im Allgemeinen weiter unterteilbar, zum Beispiel enthält das Steuerwerk zur effizienteren Bearbeitung von Befehlen die Befehls-Pipeline mit meist mehreren Stufen, unter anderem den Befehlsdecoder, sowie ein Adresswerk; die ALU enthält unter anderem zum Beispiel Hardwaremultiplizierer. Darüber hinaus befinden sich vor allem in modernen Mikroprozessoren mitunter sehr viel feiner unterteilte Einheiten, die flexibel einsetzbar/zuteilbar sind, sowie mehrfach ausgeführte Einheiten, die das gleichzeitige Abarbeiten mehrerer Befehle erlauben (siehe zum Beispiel Simultaneous Multithreading, Hyper-Threading, Out-of-order execution).
Oft ist in heutigen Prozessoren die Memory Management Unit sowie ein (evtl. mehrstufiger) Cache integriert (Level-1-Cache „L1“ bis Level-4-Cache „L4“). Mitunter ist auch eine I/O-Unit integriert, oft zumindest ein Interrupt-Controller.
Zusätzlich finden sich auch häufig spezialisierte Recheneinheiten z. B. eine Gleitkommaeinheit, eine Einheit für Vektorfunktionen oder für Signalverarbeitung. Unter diesem Aspekt sind die Übergänge zu Mikrocontrollern oder einem System-on-a-Chip, die weitere Komponenten eines Rechnersystems in einem integrierten Schaltkreis vereinen, mitunter fließend.
Hauptprozessor, CPU und Prozessorkern
Ein Prozessor besteht primär aus dem Steuer-/Leit- und dem Rechenwerk (ALU). Es gibt jedoch weitere Recheneinheiten, die zwar kein Steuer- bzw. Leitwerk enthalten, aber dennoch oft ebenfalls als Prozessor bezeichnet werden. Diese im Allgemeinen Koprozessor genannten Einheiten stellen in der Regel spezialisierte Funktionen zur Verfügung. Beispiele sind die Gleitkommaeinheit sowie Grafik- und Soundprozessoren. Zur Abgrenzung dieser Koprozessoren zu einem „echten“ Prozessor mit Steuer- und Rechenwerk wird der Begriff CPU (englisch central processing unit [ˈsɛntɹəl ˈpɹəʊsɛsɪŋ ˈju:nɪt]) oder zu deutsch Hauptprozessor genutzt.
Moderne Mikroprozessoren sind häufig als sogenannte Mehrkernprozessoren (Multi-Core-Prozessoren) ausgelegt. Sie erlauben zusammen mit entsprechender Software eine weitere Steigerung der Gesamtrechenleistung ohne eine merkliche Erhöhung der Taktfrequenz (die bis in die 2000er Jahre übliche Technik die Rechenleistung eines Mikroprozessors zu erhöhen). Mehrkernprozessoren bestehen aus mehreren voneinander unabhängigen Einheiten mit einem Rechen- und Steuerwerk, um die herum weitere Komponenten wie Cache und Memory Management Unit (MMU) angeordnet sind. Diese Einheiten werden als Prozessorkern (engl. core) bezeichnet. Im Sprachgebrauch sind die Begriffe Single-Core-Prozessor, Dual-Core-, Quad-Core- und Hexa-Core-Prozessor (Sechskernprozessor) gebräuchlich (nur selten: Triple-Core-, Octa-Core-Prozessor (Achtkern), Deca-Core-Prozessor (Zehnkern)). Da die Kerne eigenständige Prozessoren sind, werden die einzelnen Kerne häufig auch als CPU bezeichnet. Diese Bezeichnung „CPU“ wird synonym zu „Core“ genutzt, beispielsweise um in Mehrkernprozessoren oder System-on-a-Chip (SoC) mit weiteren integrierten Einheiten, z. B. einem Grafikprozessor (GPU), die Kerne mit Steuer- und Rechenwerk von den anderen Einheiten zu unterscheiden, siehe u. a. Accelerated Processing Unit (APU).[9]
Die klassische Einteilung, dass ein Steuerwerk und eine ALU als ein CPU, Kern bzw. Prozessor bezeichnet werden, verschwimmt zunehmend. Heutige Prozessoren (auch Einkernprozessoren) besitzen oft Steuerwerke, die jeweils mehrere Hardware-Threads verwalten (Multi-/Hyper-Threading); das Betriebssystem „sieht“ mehr Prozessorkerne, als tatsächlich (vollwertige) Steuerwerke vorhanden sind. Außerdem betreibt ein Steuerwerk oft mehrere ALUs sowie noch weitere Baugruppen wie z. B. Gleitkomma-Recheneinheit, Vektoreinheit (siehe auch AltiVec, SSE) oder eine Kryptographie-Einheit. Umgekehrt müssen sich manchmal mehrere Steuerwerke diese Spezial-Recheneinheiten teilen, was eine eindeutige Zuordnung verhindert.
Steuer- bzw. Leitwerk
Das Steuerwerk, auch Leitwerk genannt, kontrolliert die Ausführung der Anweisungen. Es sorgt dafür, dass der Maschinenbefehl im Befehlsregister vom Befehlsdecoder dekodiert und vom Rechenwerk und den übrigen Komponenten der Rechenanlage ausgeführt wird. Dazu übersetzt der Befehlsdecoder binäre Maschinenbefehle mit Hilfe der Befehlstabelle (englisch instruction table) in entsprechende Anweisungen (Microcode), welche die für die Ausführung des Befehls benötigten Schaltungen aktivieren. Dabei werden drei wesentliche Register, das heißt sehr schnell ansprechbare prozessorinterne Speicher, benötigt:[10]
- Das Befehlsregister (englisch instruction register): Es enthält den aktuell auszuführenden Maschinenbefehl.
- Der Befehlszähler (englisch program counter): Dieses Register zeigt bei der Befehlsausführung auf den nächstfolgenden Befehl. (Ein Sprungbefehl lädt die Adresse seines Sprungziels hierher.)
- Das Statusregister: Es zeigt über sogenannte Flags den Status an, der von anderen Teilen der Rechenanlage, u. a. dem Rechen- und dem Leitwerk, bei der Ausführung bestimmter Befehle erzeugt wird, um ihn in nachfolgenden Befehlen auswerten zu können. Beispiel: Ergebnis einer arithmetischen oder einer Vergleichsoperation ergibt ‚Null‘, ‚Minus‘ o. ä., ein Übertrag (Carry) ist bei einer Rechenoperation zu berücksichtigen.
In RISC-Prozessoren ist mitunter kein Befehlsdekoder notwendig – in manchen RISC-Prozessoren verschalten die Befehls-Bits die entsprechenden ALU- und Register-Einheiten direkt. Dort gibt es dann auch keinen Microcode. Die meisten modernen Prozessorarchitekturen sind RISC-artig oder besitzen einen RISC-Kern für die häufigen, einfachen Befehle sowie eine übersetzende Emulationsschicht davor, die komplexe Befehle in mehrere RISC-Befehle übersetzt.
Ebenso kann ein explizites Befehlregister durch eine Pipeline ersetzt sein. Mitunter sind mehrere Befehle gleichzeitig in Bearbeitung, dann kann auch die Reihenfolge ihrer Abarbeitung umsortiert werden (Out-of-order execution).
Rechenwerk und Register
Das Rechenwerk führt die Elementaroperationen eines Prozessors durch. Es besteht zum einen aus der arithmetisch-logischen Einheit (ALU), zum anderen aus den Arbeitsregistern. Es kann sowohl arithmetische (etwa die Addition zweier Zahlen) als auch logische (etwa AND oder OR) Operationen ausführen. Aufgrund der Komplexität moderner Prozessoren, bei denen meist mehrere Rechenwerke mit spezialisierten Funktionen vorhanden sind, spricht man auch allgemein vom Operationswerk.
Die Arbeitsregister können Daten (als Datenregister) und, abhängig vom Prozessortyp, auch Adressen (als Adressregister) aufnehmen. Meist können nur mit den Werten in den Registern Operationen direkt ausgeführt werden. Sie stellen daher die erste Stufe der Speicherhierarchie dar. Von den Eigenschaften und insbesondere der Größe und Anzahl der Register (abhängig vom Prozessortyp) hängt u. a. die Leistungsfähigkeit des jeweiligen Prozessors ab.
Ein spezielles Adressregister ist der Stapelzeiger (englisch stackpointer), der die Rücksprungadresse bei einem Unterprogrammaufruf aufnimmt. Auf dem Stack werden dann zusätzlich oft Registerkopien gesichert und neue, lokale Variablen angelegt.
Datenleitungen
Über verschiedene Busse (Signalleitungen) ist der Prozessor mit anderen Komponenten verbunden.
- Über den Datenbus werden Daten mit dem Arbeitsspeicher ausgetauscht, etwa die Informationen für die Arbeitsregister und das Befehlsregister. Je nach verwendeter Prozessorarchitektur hat ein Hauptprozessor (eine CPU) einen einzigen Bus für Daten aus dem Arbeitsspeicher (Von-Neumann-Architektur) oder mehrere (meist zwei) separate Datenleitungen für den Programmcode und normale Daten (Harvard-Architektur).
- Der Adressbus dient zur Übertragung von Speicheradressen. Dabei wird jeweils eine Speicherzelle des RAM adressiert (ausgewählt) in die – je nach Signal des Steuerbusses – die Daten, die gerade auf dem Datenbus liegen, geschrieben oder aus denen die Daten gelesen, d. h. auf den Datenbus gelegt, werden.
- Mit dem Steuerbus (Kontrollbus) steuert der Prozessor u. a., ob Daten gerade geschrieben oder gelesen werden sollen, ob er einem anderen Bus-Master im Rahmen eines Speicherdirektzugriffs (DMA) den Bus überlässt, oder der Adressbus statt des RAMs einen Peripherie-Anschluss meint (beim Isolated I/O). Eingangsleitungen lösen beispielsweise einen Reset oder Interrupts aus, versorgen ihn mit einem Taktsignal oder empfangen eine „Bus-Anforderung“ von einem DMA-Gerät.
Zwischen die Datenleitungen und das Registerwerk ist als Teil des Steuerwerks das sogenannte Bus-Interface geschaltet, das die Zugriffe steuert und bei gleichzeitigen Anforderungen verschiedener Untereinheiten eine Priorisierung vornimmt.
Caches und MMU
Moderne Prozessoren, die in PCs oder anderen Geräten eingesetzt werden, die eine schnelle Datenverarbeitung benötigen, sind mit sogenannten Caches ausgestattet. Caches sind Zwischenspeicher, die die zuletzt verarbeiteten Daten und Befehle zwischenspeichern und so die rasche Wiederverwendung ermöglichen. Sie stellen die zweite Stufe der Speicherhierarchie dar. Normalerweise besitzt ein Prozessor heutzutage bis zu vierstufige Caches:
- Level-1-Cache (L1-Cache): Dieser Cache läuft mit dem Prozessortakt. Er ist sehr klein (etwa 4 bis 256 Kilobyte), dafür aufgrund seiner Position im Prozessorkern selbst sehr schnell abrufbar.
- Level-2-Cache (L2-Cache): Der L2-Cache befindet sich meist im Prozessor, aber nicht im Kern selbst. Er umfasst zwischen 64 Kilobyte und 12 Megabyte.
- Level-3-Cache (L3-Cache): Bei Mehrkernprozessoren teilen sich die einzelnen Kerne den L3-Cache. Er ist der zweit-langsamste der vier Caches, aber meist bereits sehr groß (bis zu 256 Megabyte).
- Level-4-Cache (L4-Cache): Wenn vorhanden, dann meist außerhalb der CPU auf einem Interposer oder dem Mainboard. Er ist der langsamste der vier Caches (nur selten über 128 Megabyte).
Die Memory Management Unit übersetzt die virtuelle Adressen der in Ausführung befindlichen Prozesse in reale Adressen, für alle Prozessorkerne gleichzeitig, und stellt die Cache-Kohärenz sicher: Ändert ein Kern einen Speicherinhalt, so muss sichergestellt werden, dass die anderen Caches keine veralteten Werte enthalten. Abhängig von ihrer genauen Ansiedlung beinhalten die Cache-Stufen Daten entweder bezüglich virtueller oder realer Adressen.
Verarbeitung eines einzelnen Befehls
Um die Rollen der Untereinheiten konkreter zu veranschaulichen, hier der Ablauf der Verarbeitung eines einzelnen Maschinenbefehls. Die aufgeführten Einzelschritte können teilweise gleichzeitig oder überlappend ablaufen, die Nummerierung hat nichts mit der Anzahl der Taktzyklen zu tun, die der Befehl benötigt. Zusätzliche Feinheiten wie Prozessor-Pipelines oder Sprungvorhersage (Branch Prediction) führen zu weiteren Timing-Finessen, die hier im Sinne der Vereinfachung vorerst weggelassen werden. Aus dem gleichen Grund sind komplexe Berechnungen abhängig von der gewählten Adressierungsart zur Ermittlung einer endgültigen Speicheradresse nicht erwähnt.
- Laden des nächsten Befehls: Der Befehlszähler, der die Adresse des nächsten Befehls enthält, wird vom Steuerwerk über das Bus-Interface auf den Adressbus gelegt; dann wird ein Leseimpuls an die Speicherverwaltung signalisiert.
Der Befehlszähler wird parallel dazu auf die nächste Adresse weitergezählt. - Die Speicherverwaltung legt den Datenwert aus dieser (virtuellen) RAM-Adresse auf die Datenleitungen; sie hat den Wert im Cache oder im RAM gefunden. Nach der Verzögerung durch die endliche Zugriffszeit des RAMs liegt an den Datenleitungen der Inhalt dieser Speicherzelle an.
- Das Steuerwerk kopiert diese Daten über das Bus-Interface in das Befehlsregister.
- Der Befehl wird vor-decodiert, ob er komplett geladen ist.
- Wenn es ein Befehl ist, der aus mehreren Bytes besteht, werden sie (falls das durch eine größere Busbreite nicht schon geschehen ist) durch Wiederholung der Schritte 1 bis 4 aus dem Speicher geholt und in die zuständigen Prozessorregister kopiert.
- Gehört zum Befehl auch das Auslesen einer Speicherzelle des RAMs, wird vom Steuerwerk die Adresse für diese Daten auf die Adressleitungen gelegt, ein Leseimpuls wird signalisiert. Danach muss genügend lange Zeit gewartet werden, dass das RAM diese Informationen sicher bereitstellen konnte. Anschließend wird der Datenbus ausgelesen und in das zuständige Prozessorregister kopiert.
- Der Befehl wird fertig-decodiert und die zu seiner Abarbeitung benötigten Untereinheiten aktiviert, die internen Datenpfade werden entsprechend geschaltet.
- Das Rechenwerk erledigt die eigentliche Verarbeitung innerhalb des Prozessors, beispielsweise die Addition zweier Registerinhalte. Das Ergebnis landet wieder in einem der Prozessorregister.
- Wenn der Befehl ein Sprung- oder Verzweigungsbefehl ist, wird das Ergebnis nicht in einem Datenregister abgelegt, sondern im Befehlszähler.
- Das Steuerwerk aktualisiert je nach Ergebniswert ggf. das Statusregister mit seinen Zustandsflags.
- Gehört zum Befehl auch das Rückspeichern eines Ergebnisses/Registerinhalts in das RAM, wird vom Steuerwerk die Adresse für diese Daten auf die Adressleitungen gelegt und der Dateninhalt auf die Datenleitungen, ein Schreibimpuls wird signalisiert. Danach muss genügend lange Zeit gewartet werden, dass das RAM diese Informationen sicher aufnehmen konnte.
- Der Befehl ist jetzt abgearbeitet, und es kann oben bei Schritt 1 zum nächsten Befehl weitergeschritten werden.
Verschiedene Architekturen
Die beiden wesentlichen Grundarchitekturen für CPUs sind die Von-Neumann- und die Harvard-Architektur.
Bei der nach dem Mathematiker John von Neumann benannten Von-Neumann-Architektur gibt es keine Trennung zwischen dem Speicher für Daten und Programmcode. Dagegen sind bei der Harvard-Architektur Daten und Programm(e) in strikt voneinander getrennten Speicher- und Adressräumen abgelegt, auf die typischerweise durch zwei separierte Bussysteme parallel zugegriffen wird.
Beide Architekturen haben ihre spezifischen Vor- und Nachteile. In der Von-Neumann-Architektur können Programmcode und Daten grundsätzlich identisch behandelt werden. Hierdurch sind einheitliche Betriebssystem-Routinen zum Laden und Speichern verwendbar. Auch kann der Programmcode im Gegensatz zur Harvard-Architektur sich selbst modifizieren oder als „Daten“ behandelt werden, wodurch Maschinencode z. B. per Debugger leicht bearbeitbar und modifizierbar ist. Nachteile/Risiken liegen im Bereich der Softwareergonomie und -Stabilität, zum Beispiel können Laufzeitfehler wie ein Pufferüberlauf den Programmcode modifizieren.
Durch die Trennung in zwei physikalische Speicher und Busse hat die Harvard-Architektur potenziell eine höhere Leistungsfähigkeit, da Daten- und Programmzugriffe parallel erfolgen können. Bei einer Harvard-Architektur sind durch die physische Trennung von Daten und Programm einfach eine Zugriffsrechtetrennung und Speicherschutz realisierbar. Um z. B. zu verhindern, dass bei Softwarefehlern Programmcode überschrieben werden kann, wurde (vor allem historisch) für Programmcode ein im Betrieb nur lesbarer Speicher (z. B. ROM, Lochkarten) verwendet, für die Daten dagegen schreib- und lesbarer Speicher (z. B. RAM, Ringkernspeicher).
Praktisch alle modernen CPUs stellen sich aus Programmsicht als Von-Neumann-Architektur dar, ihr interner Aufbau entspricht aber aus Leistungsgründen in vielen Aspekten eher einer parallelen Harvard-Architektur. So ist es nicht unüblich, dass eine CPU intern mehrere unabhängige Datenpfade (insbesondere beim L1-Cache) und Cachehierarchiestufen besitzt, um mit möglichst vielen parallelen Datenpfaden eine hohe Leistung zu erzielen. Die dadurch potenziell möglichen Daten-Inkohärenzen und Zugriffs-Race-Conditions werden intern durch aufwändige Datenprotokolle und -management verhindert.
Auch werden heutzutage Arbeitsspeicher-Bereiche, die ausschließlich Daten beinhalten, als nicht ausführbar markiert, sodass Exploits, die ausführbaren Code in Datenbereichen ablegen, diesen nicht ausführen können. Umgekehrt kann das Schreiben in Bereiche mit Programmcode verweigert werden (Pufferüberlauf-Exploits).
Befehlssatz
Der Befehlssatz bezeichnet die Gesamtheit der Maschinenbefehle eines Prozessors. Der Umfang des Befehlssatzes variiert je nach Prozessortyp beträchtlich. Ein großer Befehlssatz ist typisch für Prozessoren mit CISC-Architektur (englisch Complex Instruction Set Computing – Rechnen mit komplexem Befehlssatz), ein kleiner Befehlssatz ist typisch für Prozessoren mit RISC-Prozessorarchitektur (englisch Reduced Instruction Set Computing – Rechnen mit reduziertem Befehlssatz).
Die traditionelle CISC-Architektur versucht, immer mehr und immer komplexere Funktionen direkt durch Maschinenbefehle auszudrücken. Sie zeichnet sich besonders durch die große Anzahl zur Verfügung stehender Maschinenbefehle aus, die meist 100 (weit) überschreitet. Diese sind außerdem in der Lage, komplexe Operationen direkt auszuführen (etwa Gleitkommazahl-Operationen). Dadurch können komplexe Vorgänge durch wenige, „mächtige“ Befehle implementiert werden. Das Nebeneinander von komplexen (langwierigen) und einfachen (schnell ausführbaren) Befehlen macht ein effizientes Prozessordesign schwierig, besonders das Pipelinedesign.
In den 1980er Jahren entstand als Reaktion darauf das RISC-Konzept, mit dem bewussten Verzicht auf das Bereitstellen von komplexer Funktionalität in Instruktionsform. Es werden ausschließlich einfache, untereinander ähnlich komplexe Instruktionen bereitgestellt. Dabei wird versucht, sehr schnell abzuarbeitende Befehle zur Verfügung zu stellen, dafür jedoch nur wenige (weniger als 100), sehr einfache. Hierdurch vereinfachte sich das Prozessordesign deutlich und ermöglichte Optimierungen, die üblicherweise eine höhere Prozessortaktung und wiederum schnellere Ausführungsgeschwindigkeit erlaubten. Dies geht unter anderem darauf zurück, dass weniger Taktzyklen benötigt werden und die Dekodierung aufgrund geringerer Komplexität schneller ist. Ein einfacheres Prozessordesign bedeutet jedoch eine Verschiebung des Entwicklungsaufwands hin zur Software als Bereitsteller komplexerer Funktionalität. Der Compiler hat nun die Aufgabe einer effizienten und korrekten Umsetzung mit dem vereinfachten Instruktionsatz.
Heute ähnelt die weit verbreitete x86-Architektur – als (früher) typischer Vertreter der CISC-Klasse – intern einer RISC-Architektur: Einfache Befehle sind meist direkt µ-Operationen; komplexe Befehle werden in µ-Ops zerlegt. Diese µ-Ops ähneln den einfachen Maschinenbefehlen von RISC-Systemen, wie auch der interne Prozessoraufbau (z. B. gibt es keinen Microcode mehr für die µ-Operationen, sie werden „direkt verwendet“).
Eine weitere Art eines Prozessordesigns ist die Verwendung von VLIW. Dort werden mehrere Instruktionen in einem Wort zusammengefasst. Dadurch ist vom Anfang an definiert, auf welcher Einheit welche Instruktion läuft. Out-of-Order-Ausführung, wie sie in modernen Prozessoren zu finden ist, gibt es bei dieser Art von Befehlen nicht.
Zusätzlich unterscheidet man auch noch zwischen der Adressanzahl im Maschinenbefehl:
- Null-Adressbefehle (Stackrechner)
- Ein-Adressbefehle (Akkumulatorrechner)
- Zwei-, Drei- und Vier-Adressbefehle (ALTIVEC hatte z. B. Vieroperanden-Befehle)
Funktionsweise
Die Befehlsbearbeitung eines Prozessorkerns folgt prinzipiell dem Von-Neumann-Zyklus.
- „FETCH“: Aus dem Befehlsadressregister wird die Adresse des nächsten Maschinenbefehls gelesen. Anschließend wird dieser aus dem Arbeitsspeicher (genauer: aus dem L1-Cache) in das Befehlsregister geladen.
- „DECODE“: Der Befehlsdecoder decodiert den Befehl und aktiviert entsprechende Schaltungen, die für die Ausführung des Befehls nötig sind.
- „FETCH OPERANDS“: Sofern zur Ausführung weitere Daten zu laden sind (benötigte Parameter), werden diese aus dem L1-Cache-Speicher in die Arbeitsregister geladen.
- „EXECUTE“: Der Befehl wird ausgeführt. Dies können zum Beispiel Operationen im Rechenwerk, ein Sprung im Programm (eine Veränderung des Befehlsadressregisters), das Zurückschreiben von Ergebnissen in den Arbeitsspeicher oder die Ansteuerung von Peripheriegeräten sein. Abhängig vom Ergebnis mancher Befehle wird das Statusregister gesetzt, das durch nachfolgende Befehle auswertbar ist.
- „UPDATE INSTRUCTION POINTER“: Sollte kein Sprungbefehl in der EXECUTE-Phase erfolgt sein, wird nun das Befehlsadressregister um die Länge des Befehls erhöht, so dass es auf den nächsten Maschinenbefehl zeigt.
Gelegentlich unterscheidet man auch noch eine Rückschreibphase, in der eventuell anfallende Rechenergebnisse in bestimmte Register geschrieben werden (siehe Out-of-order execution, Schritt 6). Erwähnt werden sollten noch sogenannte Hardware-Interrupts. Die Hardware eines Computers kann Anfragen an den Prozessor stellen. Da diese Anfragen asynchron auftreten, ist der Prozessor gezwungen, regelmäßig zu prüfen, ob solche vorliegen und diese eventuell vor der Fortsetzung des eigentlichen Programms zu bearbeiten.
Steuerung
Alle Programme liegen als eine Folge von binären Maschinenbefehlen im Speicher. Nur diese Befehle können vom Prozessor verarbeitet werden. Dieser Code ist für einen Menschen jedoch beinahe unmöglich zu lesen. Aus diesem Grund werden Programme zunächst in Assemblersprache oder einer Hochsprache (etwa BASIC, C, C++, Java) geschrieben und dann von einem Compiler in eine ausführbare Datei, also in Maschinensprache übersetzt oder einem Interpreter zur Laufzeit ausgeführt.
Symbolische Maschinenbefehle
Um es zu ermöglichen, Programme in akzeptabler Zeit und verständlich zu schreiben, wurde eine symbolische Schreibweise für Maschinenbefehle eingeführt, sogenannte Mnemonics. Maschinenbefehle werden durch Schlüsselworte für Operationen (z. B. MOV für move, also „bewegen“ oder „[ver]schieben“) und durch optionale Argumente (wie BX und 85F3h) dargestellt. Da verschiedene Prozessortypen verschiedene Maschinenbefehle besitzen, existieren für diese auch verschiedene Mnemonics. Assemblersprachen setzen oberhalb dieser prozessortypenabhängigen Mnemonik auf und beinhalten Speicherreservierung, Verwaltung von Adressen, Makros, Funktionsheader, Definieren von Strukturen usw.
Prozessorunabhängige Programmierung ist erst durch Benutzung abstrakter Sprachen möglich. Dies können Hochsprachen sein, aber auch Sprachen wie FORTH oder gar RTL. Es ist nicht die Komplexität der Sprache wichtig, sondern deren Hardware-Abstraktion.
- MOV BX, 85F3h
(movw $0x85F3, %bx)
Der Wert 85F3h (dezimal: 34291) wird in das Register BX geladen. - MOV BX, word ptr [85F2h]
(movw 0x85F2, %bx)
Die Inhalte der Speicherzellen mit den Adresse 85F2h und 85F3h (dezimal: 34290 und 34291) relativ zum Start des Datensegments (bestimmt durch DS) werden in das Register BX geladen. Dabei wird der Inhalt von 85F2h in den niederwertigen Teil BL und der Inhalt von 85F3h in den höherwertigen Teil BH geschrieben. - ADD BX, 15
(addw $15, %bx)
Der Wert 15 wird zum Inhalt des Arbeitsregisters BX addiert. Das Flagregister wird entsprechend dem Ergebnis gesetzt.
Binäre Maschinenbefehle
Maschinenbefehle sind sehr prozessorspezifisch und bestehen aus mehreren Teilen. Diese umfassen zumindest den eigentlichen Befehl, den Operationscode (OP-CODE), die Adressierungsart, und den Operandenwert oder eine Adresse. Sie können grob in folgende Kategorien eingeteilt werden:
- Arithmetische Befehle
- Logische Befehle
- Sprungbefehle
- Transportbefehle
- Prozessorkontrollbefehle
Befehlsbearbeitung
Alle Prozessoren mit höherer Verarbeitungsleistung sind heutzutage modifizierte Harvard-Architekturen,[11] da die Harvard-Architektur durch die strikte Trennung zwischen Befehlen und Daten einige Probleme mit sich bringt. Zum Beispiel ist es für selbstmodifizierenden Code nötig, dass Daten auch als Befehle ausgeführt werden können. Ebenso ist es für Debugger wichtig, einen Haltepunkt im Programmablauf setzen zu können, was ebenfalls einen Transfer zwischen Befehls- und Datenadressraum nötig macht.[12] Die Von-Neumann-Architektur findet man bei kleinen Mikrocontrollern. Der Laie darf sich nicht durch den gemeinsamen Adressraum von Befehlen und Daten eines oder mehrerer Kerne irritieren lassen. Das Zusammenfassen von Befehls- und Datenadressraum findet auf Ebene von Cache-Controllern und deren Kohärenzprotokollen statt. Das gilt nicht nur für diese beiden Adressräume (wo dies meist auf L2-Ebene erfolgt), sondern bei Multiprozessor-Systemen auch zwischen denen verschiedener Kerne (hier erfolgt es meist auf L3-Ebene) bzw. bei Multi-Sockel-Systemen beim Zusammenfassen deren Hauptspeichers.
Mikroprozessoren sind bis auf wenige Ausnahmen (z. B. der Sharp SC61860) interruptfähig, Programmabläufe können durch externe Signale unterbrochen oder aber auch abgebrochen werden, ohne dass das im Programmablauf vorgesehen sein muss. Ein Interrupt-System erfordert zum einen ein Interrupt-Logik (d. h. auf Zuruf einschiebbare Befehle) und zum anderen die Fähigkeit, den internen Zustand des Prozessors zu retten und wiederherzustellen, um das ursprüngliche Programm nicht zu beeinträchtigen. Hat ein Mikroprozessor kein Interruptsystem, muss die Software durch Polling die Hardware selbst abfragen.
Neben der geordneten Befehlsausführung beherrschen vor allem moderne Hochleistungsprozessoren weitere Techniken, um die Programmabarbeitung zu beschleunigen. Vor allem moderne Hochleistungsmikroprozessoren setzen parallele Techniken wie etwa Pipelining und Superskalarität ein, um eine evtl. mögliche parallele Abarbeitung mehrerer Befehle zu ermöglichen, wobei die einzelnen Teilschritte der Befehlsausführung leicht versetzt zueinander sind. Eine weitere Möglichkeit, die Ausführung von Programmen zu beschleunigen, ist die ungeordnete Befehlsausführung (englisch Out-of-order execution), bei der die Befehle nicht strikt nach der durch das Programm vorgegebenen Reihenfolge ausgeführt werden, sondern der Prozessor die Reihenfolge der Befehle selbständig zu optimieren versucht. Die Motivation für eine Abweichung von der vorgegebenen Befehlsfolge besteht darin, dass aufgrund von Verzweigungsbefehlen der Programmlauf nicht immer sicher vorhergesehen werden kann. Möchte man Befehle bis zu einem gewissen Grad parallel ausführen, so ist es in diesen Fällen notwendig, sich für eine Verzweigung zu entscheiden und die jeweilige Befehlsfolge spekulativ auszuführen. Es ist dann möglich, dass der weitere Programmlauf dazu führt, dass eine andere Befehlsfolge ausgeführt werden muss, so dass die spekulativ ausgeführten Befehle wieder rückgängig gemacht werden müssen. In diesem Sinne spricht man von einer ungeordneten Befehlsausführung.
Adressierungsarten
Maschinenbefehle beziehen sich auf festgelegte Quell- oder Zielobjekte, die sie entweder verwenden und/oder auf diese wirken. Diese Objekte sind in codierter Form als Teil des Maschinenbefehls angegeben, weshalb ihre effektive (logische*) Speicheradresse bei bzw. vor der eigentlichen Ausführung des Befehls ermittelt werden muss. Das Ergebnis der Berechnung wird in speziellen Adressierungseinrichtungen der Hardware (Registern) bereitgestellt und bei der Befehlsausführung benutzt. Zur Berechnung werden verschiedene Adressierungsarten (-Varianten) verwendet, abhängig von der Struktur des Befehls, die je Befehlscode einheitlich festgelegt ist.
(*) Die Berechnung der physikalischen Adressen anhand der logischen Adressen ist davon unabhängig und wird in der Regel von einer Memory Management Unit durchgeführt.
Die folgende Grafik gibt einen Überblick über die wichtigsten Adressierungsarten, weitere Angaben zur Adressierung siehe Adressierung (Rechnerarchitektur).
| Register-Adressierung | implizit |
| explizit | |
| Einstufig Speicheradressierung |
unmittelbar |
| direkt | |
| Register-indirekt | |
| indiziert | |
| Programmzähler-relativ | |
| Zweistufige Speicheradressierung |
indirekt-absolut |
| Andere … |
Registeradressierung
Bei einer Registeradressierung steht der Operand bereits in einem Prozessorregister bereit und muss nicht erst aus dem Speicher geladen werden.
- Erfolgt die Registeradressierung implizit, so wird das implizit für den Opcode festgelegte Register mitadressiert (Beispiel: der Opcode bezieht sich implizit auf den Akkumulator).
- Bei expliziter Registeradressierung ist die Nummer des Registers in einem Registerfeld des Maschinenbefehls eingetragen.
- Beispiel: | C | R1 | R2 | Addiere Inhalt von R1 auf den Inhalt von R2; C=Befehlscode, Rn=Register(n)
Einstufige Adressierung
Bei einstufigen Adressierungsarten kann die effektive Adresse durch eine einzige Adressberechnung ermittelt werden. Es muss also im Laufe der Adressberechnung nicht erneut auf den Speicher zugegriffen werden.
- Bei unmittelbarer Adressierung enthält der Befehl keine Adresse, sondern den Operanden selbst; meist nur für kurze Operanden wie '0', '1', 'AB' usw. anwendbar.
- Bei direkter Adressierung enthält der Befehl die logische Adresse selbst, es muss also keine Adressberechnung mehr ausgeführt werden.
- Bei Register-indirekter Adressierung ist die logische Adresse bereits in einem Adressregister des Prozessors enthalten. Die Nummer dieses Adressregisters wird im Maschinenbefehl übergeben.
- Bei der indizierten Adressierung erfolgt die Adressberechnung mittels Addition: Der Inhalt eines Registers wird zu einer zusätzlich im Befehl übergebenen Adressangabe hinzugerechnet. Eine der beiden Adressangaben enthält dabei i. d. R. eine Basisadresse, während die andere ein 'Offset' zu dieser Adresse enthält. Siehe auch Registertypen.
- Beispiel: | C | R1 | R2 | O | Lade Inhalt von R2 + Inhalt (Offset) ins R1; O=Offset
- Bei Programmzähler-relativer Adressierung wird die neue Adresse aus dem aktuellen Wert des Programmzählers und einem Offset ermittelt.
Zweistufige Adressierung
Bei zweistufigen Adressierungsarten sind mehrere Rechenschritte notwendig, um die effektive Adresse zu erhalten. Insbesondere ist im Laufe der Berechnung meist ein zusätzlicher Speicherzugriff notwendig.
Als Beispiel sei hier die indirekte absolute Adressierung genannt. Dabei enthält der Befehl eine absolute Speicheradresse. Das Speicherwort, das unter dieser Adresse zu finden ist, enthält die gesuchte effektive Adresse. Es muss also zunächst mittels die gegebene Speicheradresse im Speicher zurückgegriffen werden, um die effektive Adresse für die Befehlsausführung zu ermitteln. Das kennzeichnet alle zweistufigen Verfahren.
Beispiel: | C | R1 | R2 | AA | Lade nach R1 = Inhalt R2 + an Adr(AA) stehenden Inhalt
Leistungsmerkmale
Die Leistung eines Prozessors wird maßgeblich durch die Anzahl der Transistoren sowie durch die Wortbreite und den Prozessortakt bestimmt.
Wortbreite
Die Wortbreite legt fest, wie lang ein Maschinenwort des Prozessors sein kann, d. h. aus wie vielen Bits es maximal bestehen kann. Ausschlaggebend sind dabei folgende Werte:
- Arbeits- oder Datenregister: Die Wortbreite bestimmt die maximale Größe der verarbeitbaren Ganz- und Gleitkommazahlen.
- Datenbus: Die Wortbreite legt fest, wie viele Bits gleichzeitig aus dem Arbeitsspeicher gelesen werden können.
- Adressbus: Die Wortbreite legt die maximale Größe einer Speicheradresse, d. h. die maximale Größe des Arbeitsspeichers, fest.
- Steuerbus: Die Wortbreite legt die Art der Peripherieanschlüsse fest.
Die Wortbreite dieser Einheiten stimmt im Normalfall überein, bei aktuellen PCs beträgt sie 32 bzw. 64 Bit.
Prozessortakt
Die Taktrate (englisch clock rate) wird besonders in der Werbung oft als Beurteilungskriterium für einen Prozessor präsentiert. Es wird allerdings nicht vom Prozessor selbst bestimmt, sondern ist ein Vielfaches des Mainboard-Grundtaktes. Dieser Multiplikator und der Grundtakt lässt sich bei einigen Mainboards manuell oder im BIOS einstellen, was als Über- oder Untertakten bezeichnet wird. Bei vielen Prozessoren ist der Multiplikator jedoch gesperrt, sodass er entweder gar nicht verändert werden kann oder nur bestimmte Werte zulässig sind (oft ist der Standardwert gleichzeitig der Maximalwert, sodass über den Multiplikator nur Untertakten möglich ist). Das Übertakten kann zu irreparablen Schäden an der Hardware führen.
CPU-Ausführungszeit = CPU-Taktzyklen × Taktzykluszeit
Weiterhin gilt:
Taktzykluszeit = 1 / Taktrate = Programmbefehle × CPI × Taktzykluszeit
Die Geschwindigkeit des gesamten Systems ist jedoch auch von der Größe der Caches, des Arbeitsspeichers und anderen Faktoren abhängig.
Einige Prozessoren haben die Möglichkeit die Taktrate zu erhöhen, bzw. zu verringern, wenn es nötig ist. Zum Beispiel, wenn hochauflösende Videos angeschaut oder Spiele gespielt werden, die hohe Anforderungen an das System stellen, oder umgekehrt der Prozessor nicht stark beansprucht wird.
Anwendungsbereich
Im Bereich der Personal Computer ist die historisch gewachsene x86-Architektur weit verbreitet, wobei für eine genauere Diskussion dieser Thematik der entsprechende Artikel empfohlen wird.
Interessanter und weniger bekannt ist der Einsatz von Embedded-Prozessoren und Mikrocontrollern beispielsweise in Motorsteuergeräten, Uhren, Druckern sowie einer Vielzahl elektronisch gesteuerter Geräte.
Siehe auch
Literatur
- Helmut Herold, Bruno Lurz, Jürgen Wohlrab: Grundlagen der Informatik. Pearson Studium, München 2007, ISBN 978-3-8273-7305-2.
Weblinks
- umfassende Sammlung von Prozessoren (englisch)
- FAQ der Usenet-Hierarchie de.comp.hardware.cpu+mainboard.*
- cpu-museum.de Bebildertes CPU-Museum (englisch)
- CPU-Sammlung/CPU-Museum
- Selbstbauprojekt einer CPU aus einzelnen TTL-Bausteinen
- Intel Engineering Samples verifizieren
- 25 Microchips that shook the world, ein Artikel des Institute of Electrical and Electronics Engineers, Mai 2009
Einzelnachweise
- Dieter Sautter, Hans Weinerth: Lexikon Elektronik Und Mikroelektronik. Springer, 1993, ISBN 978-3-642-58006-2, S. 825 (eingeschränkte Vorschau in der Google-Buchsuche).
- Peter Fischer, Peter Hofer: Lexikon Der Informatik. Springer, 2011, ISBN 978-3-642-15126-2, S. 710 (eingeschränkte Vorschau in der Google-Buchsuche).
- Helmut Herold, Bruno Lurz, Jürgen Wohlrab: Grundlagen der Informatik. Pearson Studium, München 2007, ISBN 978-3-8273-7305-2, S. 101.
- Konrad Zuse: Der Computer – Mein Lebenswerk. 5., unveränd. Auflage. Springer-Verlag, Berlin Heidelberg 2010, ISBN 978-3-642-12095-4, S. 55 (100 Jahre Zuse).
- Wilfried de Beauclair: Rechnen mit Maschinen. Eine Bildgeschichte der Rechentechnik. 2. Auflage. Springer, Berlin Heidelberg New York 2005, ISBN 3-540-24179-5, S. 111–113.
- IBM Archives 705 Data Processing System. In: ibm.com. 1. Oktober 1954, abgerufen am 13. Januar 2021 (englisch).
- Magnetic Cores for Memory in Microseconds in a Great New IBM Electronic Data Processing Machine for Business. (PDF) In: archive.computerhistory.org. 1. Oktober 1954, abgerufen am 13. Januar 2021 (englisch).
- IBM Archives 704 Data Processing System. In: ibm.com. 1. Oktober 1954, abgerufen am 13. Januar 2021 (englisch).
- Tim Towell: Intel Architecture Based Smartphone Platforms. (PDF) (Nicht mehr online verfügbar.) 6. November 2012, S. 7, archiviert vom Original am 3. Juni 2013; abgerufen am 22. März 2013.
- Peter Rechenberg: Informatik-Handbuch. Hanser Verlag, 2006, ISBN 978-3-446-40185-3, S. 337.
- Learning to Program – A Beginners Guide – Part Four – A Simple Model of a Computer (englisch); abgerufen am 11. September 2016.
- ARM Technical Support Knowledge Articles: What is the difference between a von Neumann architecture and a Harvard architecture? (englisch); abgerufen am 11. September 2016.
| nach Wortbreite |
1-Bit-Architektur • Bit-Slice-Architektur • 4-Bit-Architektur • 8-Bit-Architektur • 16-Bit-Architektur • 32-Bit-Architektur • 64-Bit-Architektur | |
| nach Befehlssatzaufbau | ||
| mit Optimierung für Einsatzzweck |
(Haupt-)Prozessor • Grafikprozessor • GPGPU • Streamprozessor • Soundprozessor • Gleitkommaeinheit • Netzwerkprozessor • Physikbeschleuniger • Vektorprozessor • TensorFlow Processing Unit |