Programmiersprache
Eine Programmiersprache ist eine formale Sprache zur Formulierung von Datenstrukturen und Algorithmen, d. h. von Rechenvorschriften, die von einem Computer ausgeführt werden können.[1] Sie setzen sich üblicherweise aus schrittweisen Anweisungen aus erlaubten (Text-)Mustern zusammen, der sogenannten Syntax.
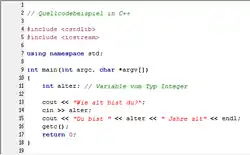
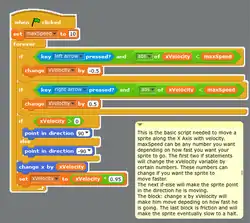
Während die ersten Programmiersprachen noch unmittelbar an den Eigenschaften der jeweiligen Rechner ausgerichtet waren, werden heute meist problemorientierte oder auch (allgemeiner) höhere Programmiersprachen verwendet, die eine maschinenunabhängigere[2] und somit für den Menschen leichter verständliche Ausdrucksweise erlauben. In diesen Sprachen geschriebene Programme können automatisiert in Maschinensprache übersetzt werden, welche unmittelbar von einem Prozessor ausgeführt werden kann. Zunehmend kommen auch visuelle Programmiersprachen zum Einsatz, welche den Zugang zu Programmiersprachen erleichtern.
Bei deklarativen Programmiersprachen ist der Ausführungsalgorithmus schon vorab festgelegt und wird nicht im Quelltext ausformuliert/beschrieben, sondern es werden nur seine Anfangswerte und Bedingungen festgelegt, sowie die Regeln, die das Ergebnis erfüllen muss.
Übersicht
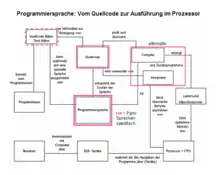
Die Anweisungen eines Programms werden meist mittels einfacher Texteditoren erzeugt; man nennt sie den Quelltext (oder auch Quellcode). Um auf einem Computer ausgeführt zu werden, muss der Quelltext in die Maschinensprache dieses Computer(typ)s übersetzt werden. Diese ist im Gegensatz zu höheren Programmiersprachen und zur Assemblersprache ein für Menschen schwer lesbarer Binärcode. Wird von Programmierung in Maschinensprache gesprochen, so ist heute meist die Assemblersprache gemeint.
Die Übersetzung in Maschinensprache kann entweder vor der Ausführung durch einen Compiler oder – zur Laufzeit – durch einen Interpreter oder JIT-Compiler geschehen. Oft wird eine Kombination aus beiden Varianten gewählt, bei der zuerst der Quelltext des Programms in einen Zwischencode übersetzt wird, welcher dann zur Laufzeit innerhalb einer Laufzeitumgebung in Maschinencode überführt wird. Dieses Prinzip hat den Vorteil, dass derselbe Zwischencode auf verschiedenen Plattformen ausführbar ist. Beispiele für einen solchen Zwischencode sind der Java-Bytecode sowie die Common Intermediate Language.
Programmiersprachen bieten meist mindestens
- Ein-/Ausgabe-Befehle, damit das Programm Daten entgegennehmen und wieder ausgeben kann;
- Deklaration von Variablen und Feldern, um Informationen zwischenspeichern zu können;
- mathematische Grund- und Standardfunktionen;
- Grundfunktionen zur Zeichenkettenverarbeitung;
- Steueranweisungen für bedingte Ausführung, Wiederholung, Programmunterteilung (z. B. in Unterfunktionen) sowie Einbinden von Bibliotheken.
Meist ist es möglich, aus diesen Grundfunktionen höhere Funktionen zu erstellen und diese als Bibliothek wiederverwendbar zu kapseln. Von dort zu einer höheren oder problemorientierten Sprache zu gelangen, ist kein großer Schritt mehr. So gab es schon bald eine große Zahl an Spezialsprachen für die verschiedensten Anwendungsgebiete. Damit steigt die Effizienz der Programmierer und die Portabilität der Programme, meist nimmt dafür die Verarbeitungsgeschwindigkeit der erzeugten Programme ab, und die Mächtigkeit der Sprache nimmt ab: Je höher und komfortabler die Sprache, desto mehr ist der Programmierer daran gebunden, die in ihr vorgesehenen Wege zu beschreiten.
Sprachen sind verschieden erfolgreich – manche „wachsen“ und finden zunehmend breitere Anwendung; immer wieder sind auch Sprachen mit dem Anspruch entworfen worden, Mehrzweck- und Breitbandsprachen zu sein, oft mit bescheidenem Erfolg (PL/1, Ada, Algol 68). Verschiedene Dienste versuchen, die Verbreitung der verschiedenen Sprachen zu messen; bekannt sind beispielsweise der TIOBE-Index, PYPL[3] und die Analysen von RedMonk.[4]
Panorama
Die Bedeutung von Programmiersprachen für die Informatik drückt sich auch in der Vielfalt der Ausprägungen und der Breite der Anwendungen aus.
- Maschinensprache, Assemblersprachen oder C erlauben eine hardwarenahe Programmierung.
- Höhere Programmiersprachen erlauben komfortableres, schnelleres Programmieren.
- Skriptsprachen dienen zur einfachen Steuerung von Rechnern, wie bei der Stapelverarbeitung.
- Sprachen mit visuellen Programmierumgebungen erleichtern die graphische Gestaltung von Benutzeroberflächen.
- Esoterische Programmiersprachen sind experimentelle Sprachen mit unüblichen Programmierkonzepten und/oder Berücksichtigung themenfremder Aspekte, z. B. ästhetisches Aussehen des Quellcodes.
- Grafische Programmiersprachen sollen einen besonders leichten Zugang zum Programmieren bieten; statt Quelltext zu schreiben, kann das Programm aus Verarbeitungsblöcken zusammengeklickt werden.
- Minisprachen sollen Kinder früh ans Programmieren heranführen (nicht zu verwechseln mit minilanguages, einem Synonym für domain-specific languages).
Umgangssprachlich wird auch in anderen Bereichen von Programmiersprachen gesprochen. Nachfolgende Sprachen sind jedoch nicht für die Beschreibung von Algorithmen und allgemeine Datenverarbeitung entworfen, also keine General Purpose Languages:
- Auszeichnungssprachen werden für die Formatierung von Texten und Dateien verwendet.
- CNC-Programmiersprachen sind (oder dienen der Erzeugung von) Steuerungsinformationen für Werkzeugmaschinen.
- Datenbanksprachen sind für den Einsatz in und die Abfrage von Datenbanken gedacht.
- Seitenbeschreibungssprachen sowie sonstige Beschreibungssprachen (z. B. VHDL) sind eine imperative Form eines Dateiformats.
- Stylesheet-Sprachen werden verwendet um das Erscheinungsbild zu bestimmen
Derartige Sprachen fallen unter die domänenspezifischen Sprachen.
Anweisungskategorien
Die Anweisungen von Programmiersprachen (Beispiele siehe hier) lassen sich nach folgenden Gruppen klassifizieren:
- Eingabe- und Ausgabe-Befehle – lesen Daten von der Tastatur, von einer Datei oder aus anderen Quellen ein oder sie geben sie auf/über ein bestimmtes Ausgabegerät (Bildschirm, Datei, Drucker, …) aus.
- Zuweisungen und Berechnungen – verändern oder erzeugen Dateninhalte.
- Kontrollflussanweisungen: Entscheidungsanweisungen (auch Verzweigungsanweisungen), Iterationsanweisungen, Sprunganweisungen entscheiden aufgrund der vorliegenden Daten, welche Befehle als Nächstes ausgeführt werden.
- Deklarationen – reservieren Speicherplatz für Variablen oder Datenstrukturen unter einem fast frei wählbaren Namen. Über diesen Namen können sie später angesprochen werden.
- Aufrufe „programm-externer“ Unterroutinen/Module wie Systemfunktionen (z. B. „Read“) oder funktionaler Module, auch aus anderen Programmiersprachen.
Übersetzer
Um ein in einer bestimmten Programmiersprache erstelltes Programm ausführen zu können, muss anstatt dessen Quellcode eine äquivalente Folge von Maschinenbefehlen ausgeführt werden. Das ist notwendig, da der Quellcode aus Zeichenfolgen besteht (z. B. „A = B + 100 * C“), die der Prozessor nicht „versteht“.
Die in der Geschichte der Computertechnik und der Softwaretechnologie eingetretenen Entwicklungssprünge brachten auch unterschiedliche Werkzeuge zur Erzeugung von Maschinencode, ggf. über mehrere Stufen, mit sich. Diese werden beispielsweise als Compiler, Interpreter, Precompiler, Linker etc. bezeichnet.
In Bezug auf die Art und den Zeitpunkt, wie der Computer zu einem äquivalenten Maschinencode kommt, können zwei Prinzipien unterschieden werden:
- Wird ein Programmtext als Ganzes „übersetzt“, also aus dem Quelltext ein Maschinenprogramm erstellt, so spricht man in Bezug auf den Übersetzungsmechanismus von einem Compiler. Der Compiler selbst ist ein Programm, das als Dateneingabe den Programm-Quellcode liest und als Datenausgabe den Maschinencode (z. B. Objectcode, EXE-Datei, „executable“) oder einen Zwischencode liefert.
- Wenn abhängig vom Programmtext während der Ausführung entsprechende Maschinencodeblöcke ausgeführt werden, spricht man von einer interpretierten Sprache. Das Programm wird in einer Laufzeitumgebung (z. B. veraltete JVM) interpretiert und je nach Programmbefehl ein entsprechender Maschinenbefehlblock ausgeführt.
Daneben existieren verschiedene Mischvarianten:
- Bei der „Just-in-Time-Kompilierung“ wird der Programmtext direkt vor jedem Programmlauf neu übersetzt; ggf. werden erst während des (interpretierten) Programmlaufs einzelne Programmabschnitte kompiliert.
- Zum Teil erzeugen Compiler einen noch nicht ausführbaren Programmcode, der von nachfolgenden Systemprogrammen zu ausführbarem Maschinencode umgeformt wird. Hier sind die Konzepte „plattformunabhängiger Zwischencode“ (z. B. im Rahmen der Software-Verteilung) und „plattformgebundener Objektcode“ (wird zusammen mit weiteren Modulen zu ausführbarem Code, z. T. Lademodul genannt, zusammengebunden) zu unterscheiden.
- Mit Precompilern können spezielle, in der Programmiersprache selbst nicht vorgesehene Syntax-Konstrukte (zum Beispiel Entscheidungstabellen) bearbeitet und, vor-übersetzt in die gewählte Programmiersprache, im Quellcode eingefügt werden.
Zur Steuerung des Übersetzens kann der Quelltext neben den Anweisungen der Programmiersprache zusätzliche spezielle Compiler-Anweisungen enthalten. Komplexe Übersetzungsvorgänge werden bei Anwendung bestimmter Programmiersprachen / Entwicklungsumgebungen durch einen Projekterstellungsprozess und die darin gesetzten Parameter gesteuert.
Geschichte

Zur Vorgeschichte der Programmiersprachen kann man von praktischer Seite die zahlreichen Notationen zählen, die sowohl in der Fernmeldetechnik (Morsecode) als auch zur Steuerung von Maschinen (Jacquardwebstuhl) entwickelt worden waren; dann die Assemblersprachen der ersten Rechner, die doch nur deren Weiterentwicklung waren. Von theoretischer Seite zählen dazu die vielen Präzisierungen des Algorithmusbegriffs, von denen der λ-Kalkül die bei weitem bedeutendste ist. Auch Zuses Plankalkül gehört hierhin, denn er ist dem minimalistischen Ansatz der Theoretiker verpflichtet (Bit als Grundbaustein).
In einer ersten Phase wurden ab Mitte der 1950er Jahre unzählige Sprachen[5] entwickelt, die praktisch an gegebenen Aufgaben und Mitteln orientiert waren. Seit der Entwicklung von Algol 60 (1958–1963) ist die Aufgabe des Übersetzerbaus in der praktischen Informatik etabliert und wird zunächst mit Schwerpunkt Syntax (-erkennung, Parser) intensiv bearbeitet. Auf der praktischen Seite wurden erweiterte Datentypen wie Verbunde, Zeichenketten und Zeiger eingeführt (konsequent z. B. in Algol 68).
In den 1950er Jahren wurden in den USA die ersten drei weiter verbreiteten, praktisch eingesetzten höhere Programmiersprachen entwickelt. Dabei verfolgten diese sowohl imperative als auch deklarativ-funktionale Ansätze.
Die Entwicklung von Algol 60 läutete eine fruchtbare Phase vieler neuer Konzepte, wie das der prozeduralen Programmierung ein. Der Bedarf an neuen Programmiersprachen wurde durch den schnellen Fortschritt der Computertechnik gesteigert. In dieser Phase entstanden die bis heute verbreiteten Programmiersprachen BASIC und C.
In der Nachfolgezeit ab 1980 konnten sich die neu entwickelten logischen Programmiersprachen nicht gegen die Weiterentwicklung traditioneller Konzepte in Form des objektorientierten Programmierens durchsetzen. Das in den 1990er Jahren immer schneller wachsende Internet forderte seinen Tribut beispielsweise in Form von neuen Skriptsprachen für die Entwicklung von Webserver-Anwendungen.
Derzeit schreitet die Integration der Konzepte der letzten Jahrzehnte voran. Größere Beachtung findet so beispielsweise der Aspekt der Codesicherheit in Form von virtuellen Maschinen. Neuere integrierte, visuelle Entwicklungsumgebungen erfordern deutlich weniger Aufwand an Zeit und Kosten. Bedienoberflächen lassen sich meist visuell gestalten, Codefragmente sind per Klick direkt erreichbar. Dokumentation zu anderen Programmteilen und Bibliotheken ist direkt einsehbar, meist gibt es sogar lookup-Funktionalität, die noch während des Schreibens herausfindet, welche Symbole an dieser Stelle erlaubt sind und entsprechende Vorschläge macht (Autovervollständigen).
Neben der mittlerweile etablierten objektorientierten Programmierung ist die modellgetriebene Architektur ein weiterer Ansatz zur Verbesserung der Software-Entwicklung, in der Programme aus syntaktisch und semantisch formal spezifizierten Modellen generiert werden. Diese Techniken markieren gleichzeitig den Übergang von einer eher handwerklichen, individuellen Kunst zu einem industriell organisierten Prozess.
- Sprachgenerationen
Man hat die Maschinen-, Assembler- und höheren Programmiersprachen auch als Sprachen der ersten bis dritten Generation bezeichnet; auch in Analogie zu den gleichzeitigen Hardwaregenerationen. Als vierte Generation wurden verschiedenste Systeme beworben, die mit Programmgeneratoren und Hilfsprogrammen z. B. zur Gestaltung von Bildschirmmasken (screen painter) ausgestattet waren. Die Sprache der fünften Generation schließlich sollte in den 1980er Jahren im Sinne des Fifth Generation Computing Concurrent Prolog sein.
Programmierparadigmen
| Name | funktional | imperativ | objektorientiert | deklarativ | logisch | nebenläufig |
| Ada | X | X | X | |||
| C | X | |||||
| Prolog | X | X | ||||
| Scheme | X | X | (X) | X | (X) | |
| Haskell | X | (X) | X | (X) | ||
| Scala | X | (X) | X | (X) | X |
Die Programmiersprachen lassen sich in Kategorien einteilen, die sich im evolutionären Verlauf der Programmiersprachen-Entwicklung als sog. Programmierparadigmen gebildet haben. Grundlegend sind die Paradigmen der strukturierten, der imperativen, der deklarativen und der objektorientierten Programmierung – mit jeweils weiteren Unterteilungen. Eine Programmiersprache kann jedoch auch mehreren Paradigmen gehorchen, das heißt die begriffsbestimmenden Merkmale mehrerer Paradigmen unterstützen.
Strukturierte Programmiersprachen
Strukturierte Programmierung ist Anfang der 1970er Jahre auch aufgrund der Softwarekrise populär geworden. Es beinhaltet die Zerlegung eines Programms in Unterprogramme (prozedurale Programmierung) und die Beschränkung auf die drei elementaren Kontrollstrukturen Anweisungs-Reihenfolge, Verzweigung und Wiederholung.
Imperative Programmiersprachen
Ein in einer imperativen Programmiersprache geschriebenes Programm besteht aus Anweisungen (latein. imperare = befehlen), die beschreiben, wie das Programm seine Ergebnisse erzeugt (zum Beispiel Wenn-dann-Folgen, Schleifen, Multiplikationen etc.).
Deklarative Programmiersprachen
Den genau umgekehrten Ansatz verfolgen die deklarativen Programmiersprachen. Dabei beschreibt der Programmierer, welche Bedingungen die Ausgabe des Programms (das Was) erfüllen muss. Wie die Ergebnisse konkret erzeugt werden, wird bei der Übersetzung, zum Beispiel durch einen Interpreter festgelegt. Ein Beispiel ist die Datenbankabfragesprache SQL.
Ein Programm muss nicht unbedingt eine Liste von Anweisungen enthalten. Stattdessen können grafische Programmieransätze, zum Beispiel wie bei der in der Automatisierung verwendeten Plattform STEP 7, benutzt werden.
Die Art der formulierten Bedingungen unterteilen die deklarativen Programmiersprachen in logische Programmiersprachen, die mathematische Logik benutzen, und funktionale Programmiersprachen, die dafür mathematische Funktionen einsetzen.
Objektorientierte Programmiersprachen
Im Gegensatz zur prozeduralen Programmierung, wo zuerst die verarbeitenden Prozeduren im Fokus stehen („Was will ich rechnen?“) und die Daten „irgendwie durchgeschleust“ werden, konzentriert sich die objektorientierte Programmierung zunächst auf die Daten: „Mit welchen Dingen (der Real-/Außenwelt) soll gearbeitet werden? Welche Attribute/Daten beschreiben diese (→ Objekt-Klassen)?“ Erst anschließend wird die Handhabung zu den Objekten entworfen (→ Methoden, „was kann man mit diesem Objekt machen? Was kann dieses Objekt für das Programm machen?“). Die Methoden werden den Daten zugeordnet, und zusammen werden beide in Objekten/Objekt-Klassen zusammengefasst. Objektorientierung verringert die Komplexität der entstehenden Programme, macht sie wiederverwendbarer und bildet die Realität meist genauer ab als dies bei rein prozeduraler Programmierung der Fall ist.
Objektorientierung bietet die folgenden Paradigmen:[6]
- Datenkapselung
- Verbergen von Implementierungsdetails: Ein Objekt bietet dem Verwender eine festgelegte Menge an Möglichkeiten (Methoden), es zu ändern, zu beeinflussen, etwas zu berechnen oder Auskünfte zu erhalten. Darüber hinausgehende Hilfsroutinen oder Zustandsspeicher werden verborgen, auf sie kann nicht (direkt) zugegriffen werden.
- Vererbung, Spezialisierung und Generalisierung
- Vererbung heißt vereinfacht, dass eine abgeleitete Klasse die Methoden und Attribute der Basisklasse ebenfalls besitzt, also erbt. Zudem kann sie zusätzliche Attribute und Eigenschaften besitzen und zusätzliche Handlungsmöglichkeiten bieten – eine abgeleitete Klasse ist ein „Spezialfall“ der Basisklasse.
Umgekehrt kann gleiche Funktionalität mehrerer Klassen in eine gemeinsamen Basisklasse „ausgelagert“ werden, wo sie nur noch 1 Mal programmiert ist, was Code spart, leichter wartbar ist und ggf. für weitere Spezialklassen wiederverwendbar ist – sie erben einfach von dieser Basisklasse; die Basisklasse beschreibt das generelle Verhalten aller abgeleiteten (Spezial-)Klassen. - Polymorphie
- Ein Objekt einer Spezialklasse kann stets auch als Mitglied der Basisklasse betrachtet werden. Dadurch kann in einer Variable, die ein Objekt der Basisklasse aufnehmen kann, auch ein Objekt einer abgeleiteten Klasse gespeichert werden, denn aufgrund der Vererbung bietet es ja die Methoden und Attribute der Basisklasse.
Typsystem
Variablen sind mit einem Namen versehene Orte im Speicher, die einen Wert aufnehmen können. Um die Art des abgelegten Wertes festzulegen, muss in vielen Programmiersprachen der Variablen ein Datentyp zugewiesen werden. Häufige Datentypen sind Ganz- und Gleitkommazahlen oder auch Zeichenketten.
Es wird zwischen typisierten und typenlosen Sprachen unterschieden. In typisierten Sprachen (zum Beispiel C++ oder Java) wird der Inhalt der Variable durch einen Datentyp festgelegt. So gibt es für Ganz- und Gleitkommazahlen verschiedene Datentypen, die sich durch ihren Wertebereich unterscheiden. Sie können vorzeichenlos oder vorzeichenbehaftet sein. Nach aufsteigendem Wertebereich sind dies zum Beispiel: Short, Integer oder Long. Datentypen für Gleitkommazahlen sind zum Beispiel Float oder Double. Einzelne Zeichen können im Datentyp Char gespeichert werden. Für Zeichenketten steht der Datentyp String zur Verfügung.
Die typisierten Sprachen können anhand des Zeitpunkts der Typüberprüfung unterschieden werden. Findet die Typüberprüfung bereits bei der Übersetzung des Programms statt, spricht man von statischer Typisierung. Findet die Typprüfung zur Laufzeit statt, spricht man von dynamischer Typisierung. Erkennt eine Programmiersprache Typfehler spätestens zur Laufzeit, wird sie als typsicher bezeichnet.
Bei statischer Typprüfung ist der Programmierer versucht, diese zu umgehen, oder sie wird nicht vollständig durchgesetzt (zum jetzigen Stand der Technik muss es in jeder statischen Sprache eine Möglichkeit geben, typlose Daten zu erzeugen oder zwischen Typen zu wechseln – etwa wenn Daten vom Massenspeicher gelesen werden). In Sprachen mit dynamischer Typprüfung werden manche Typfehler erst gefunden, wenn es zu spät ist. Soll der Datentyp einer Variablen geändert werden, ist ein expliziter Befehl zur Umwandlung nötig.
Die typenlosen Sprachen (zum Beispiel JavaScript oder Prolog) verfügen, im Gegensatz zu den typisierten Sprachen, über keine differenzierten Datentypen. Der Datentyp einer Variablen wird erst zur Laufzeit festgelegt. Wird einer Variablen ein Wert eines anderen Typs zugewiesen, findet eine Umwandlung der Variablen in den neuen Typ statt. Die typenlosen Sprachen behandeln oftmals alle Einheiten als Zeichenketten und kennen für zusammengesetzte Daten eine allgemeine Liste.
Durch die Festlegung des Datentyps werden vor allem zwei Zwecke verfolgt:
- Deskriptive Typangaben erleichtern die Programmierung und entlasten die Notation. Beim Zugriff auf ein Feld mit einem Index kann die Speicherstelle, an der sich der abgefragte Wert befindet, abhängig vom verwendeten Datentyp berechnet werden.
- Präskriptive Typangaben schließen bestimmte Operationen aus. Es kann zum Beispiel das Einhalten von Feldgrenzen geprüft werden, um einen Zugriff über die Feldgrenzen hinaus zu verhindern.
Das sichere Typsystem der Programmiersprache ML bildet die Grundlage für die Korrektheit der in ihr programmierten Beweissysteme (LCF, HOL, Isabelle); in ähnlicher Weise versucht man jetzt auch die Sicherheit von Betriebssystemen zu gewährleisten.[7] Schließlich ermöglichen erst unterschiedliche Typangaben das populäre Überladen von Bezeichnern. Nach Strachey sollte das Typsystem im Mittelpunkt der Definition einer Programmiersprache stehen.
Die Definition von Daten erfolgt im Allgemeinen durch die Angabe einer konkreten Spezifikation zur Datenhaltung und der dazu nötigen Operationen. Diese konkrete Spezifikation legt das allgemeine Verhalten der Operationen fest und abstrahiert damit von der konkreten Implementierung der Datenstruktur (s. a. Deklaration).
Oft kann an den Bürgern erster Klasse (First class Citizens – FCCs) einer Programmiersprache – also den Formen von Daten, die direkt verwendet werden können, erkannt werden, welchem Paradigma die Sprache gehorcht. In Java z. B. sind Objekte FCCs, in Lisp ist jedes Stück Programm FCCs, in Perl sind es Zeichenketten, Arrays und Hashes. Auch der Aufbau der Daten folgt syntaktischen Regeln. Mit Variablen kann man bequem auf die Daten zugreifen und den dualen Charakter von Referenz und Datum einer Variablen ausnutzen. Um die Zeichenketten der Daten mit ihrer (semantischen) Bedeutung nutzen zu können, muss man diese Bedeutung durch die Angabe eines Datentyps angeben. Zumeist besteht im Rahmen des Typsystems auch die Möglichkeit, neue Typen zu vereinbaren. LISP verwendet als konzeptionelle Hauptstruktur Listen. Auch das Programm ist eine Liste von Befehlen, die andere Listen verändern. Forth verwendet als konzeptionelle Hauptstruktur Stacks und Stack-Operationen sowie ein zur Laufzeit erweiterbares Wörterbuch von Definitionen und führt in den meisten Implementationen überhaupt keine Typprüfungen durch.
Sonstiges
Ein beliebter Einstieg in eine Programmiersprache ist es, mit ihr den Text Hello World (oder deutsch „Hallo Welt“) auf den Bildschirm oder einem anderen Ausgabegerät auszugeben (siehe Hallo-Welt-Programm). Entsprechend gibt es Listen von Hallo-Welt-Programmen und eigene Webseiten,[8] die beispielhafte Implementierungen in verschiedenen Programmiersprachen gegenüberstellen.
Siehe auch
Literatur
- Friedrich L. Bauer, Hans Wössner: Algorithmische Sprache und Programmentwicklung. 2. verbesserte Auflage. Springer, Berlin u. a. 1984, ISBN 3-540-12962-6.
- Peter A. Henning, Holger Vogelsang: Handbuch Programmiersprachen. Softwareentwicklung zum Lernen und Nachschlagen. Hanser, München 2007, ISBN 978-3-446-40558-5.
- Kenneth C. Louden: Programmiersprachen: Grundlagen, Konzepte, Entwurf. Internat. Thomson Publ., Bonn/ Albany u. a. 1994, ISBN 3-929821-03-6.
- John C. Reynolds: Theories of Programming Languages. Cambridge Univ. Press, Cambridge 1998, ISBN 0-521-59414-6.
- Robert Harper: Practical Foundations for Programming Languages. Cambridge Univ. Press, Cambridge 2016, ISBN 978-1-107-15030-0.
- Peter van Roy, Seif Haridi: Concepts, Techniques, and Models of Computer Programming. MIT Press, Cambridge 2004, ISBN 0-262-22069-5.
- Michael L. Scott: Programming language pragmatics. 2. Auflage. Elsevier, Morgan Kaufmann, Amsterdam 2006, ISBN 0-12-633951-1.
Weblinks
- 99 Bottles of Beer: Ein Programm in hunderten von Programmiersprachen bzw. Dialekten (englisch)
Einzelnachweise
- Programmiersprache – Duden, 2019; dort wörtlich mit „System von Wörtern und Symbolen, die zur Formulierung von Programmen (4) für die elektronische Datenverarbeitung verwendet werden“; siehe auch Duden Informatik, ISBN 3-411-05232-5
- … siehe auch Plattformunabhängigkeit (vor allem auch im Sinne der Herstellerunabhängigkeit bezüglich der Rechenwerke) sowie Abstraktion (Informatik) …
- PYPL
- RedMonk
- Um 1965 zählte man 1700, vgl. ISWIM.
- Peter A. Henning, Holger Vogelsang: Taschenbuch Programmiersprachen. Fachbuchverlag im Carl Hanser Verlag, Leipzig 2007, ISBN 978-3-446-40744-2.
- Vgl. Sprachbasiertes System – z. B. Singularity basierend auf der Programmiersprache Sing#, JX für Java, Coyotos mit der Sprache BitC.
- Auflistung von Hello-World-Programmen nach Programmiersprachen