Parser
Ein Parser [ˈpɑːʁzɐ] (engl. to parse, „analysieren“, bzw. lateinisch pars, „Teil“; im Deutschen gelegentlich auch Zerteiler) ist ein Computerprogramm, das in der Informatik für die Zerlegung und Umwandlung einer Eingabe in ein für die Weiterverarbeitung geeigneteres Format zuständig ist. Häufig werden Parser eingesetzt, um im Anschluss an den Analysevorgang die Semantik der Eingabe zu erschließen und daraufhin Aktionen durchzuführen.
Im Vergleich zu einem Recognizer, der die Eingabe analysiert und ausgibt, ob diese im Sinne der Vorgaben richtig oder falsch ist, gibt der Parser die Analyse einer Eingabe in einer gewünschten Form aus und erzeugt zusätzlich Strukturbeschreibungen.
Die Syntaxanalyse (Parsing) findet auch außerhalb der Informatik Anwendung, z. B. bei der Untersuchung der Struktur von natürlichen Sprachen. In der Grammatik würde die Syntaxanalyse eines Satzes dem Zerlegen des Satzes in seine grammatikalischen Bestandteile (Syntax) entsprechen. Siehe dazu Linguistik.
Anwendung und Beispiele
Im Allgemeinen wird ein Parser dazu verwendet, einen Text in eine neue Struktur zu übersetzen, z. B. in einen Syntaxbaum, welcher die Hierarchie zwischen den Elementen ausdrückt.
- HTML-Code besteht aus reinem Text. Der in einem Webbrowser enthaltene Parser erstellt daraus den logischen Aufbau als Datenstruktur. Das Aussehen dieser Elemente wird getrennt via CSS definiert.
- RSS-Parser wandeln RSS-Feeds in ein anderes Datenformat, beispielsweise für eine HTML-Seite.
- XML-Parser analysieren XML-Dokumente und stellen die darin enthaltenen Informationen (also Elemente, Attribute usw.) für die weitere Verarbeitung zur Verfügung.
- URI-Parser lösen Schemata wie URLs in ihren hierarchischen Aufbau auf (siehe dazu RFC 3986).
- Logdatei-Parser dienen zum Extrahieren von relevanten Informationen aus Webserver-Protokolldateien, Ereignisprotokollen und anderer in Logdateien gespeicherter Informationen zur automatisierten Analyse.
- Suchmaschinen parsen Webseiten und crawlen relevante Textpassagen.
- Auslesen einer Programmiersprache. Aus der erhaltenen Datenstruktur kann ein Compiler dann Maschinencode bzw. Bytecode erzeugen.
- Ein Kommandozeileninterpreter parst Befehle mitsamt deren Parameter für die korrekte Ausführung der Anweisungen des Benutzers (z. B. via COMMAND.COM).
- In Textadventures erfolgt die Steuerung der Spielfigur über die Eingabe von Befehlen in natürlicher Sprache, z. B. „Schließe die Haustür mit dem Hausschlüssel auf“. Der Parser greift auf eine Datenbank aller manipulierbarer Objekte im Spiel zu und analysiert, welche Interaktion mit welchen Objekten der Spielwelt der Spieler mit seiner Befehlseingabe meinte.
Funktionsweise
Zur Analyse des Texts verwenden Parser in der Regel einen separaten lexikalischen Scanner (auch Lexer genannt). Dieser zerlegt die (als simple Aneinanderreihung von Zeichen vorliegenden) Eingabedaten in Token (Eingabesymbole bzw. „Wörter“, die der Parser versteht); weil die Zerlegung in Token einer regulären Grammatik folgt, ist der Scanner meist ein endlicher Automat. Diese Token dienen als atomare Eingabezeichen des Parsers. Parser, die keinen separaten Scanner verwenden, werden Scannerless parsers genannt.
Der eigentliche Parser als Implementierung eines abstrakten Automaten (meist realisiert als Kellerautomat) kümmert sich dagegen um die Grammatik der Eingabe, führt eine syntaktische Überprüfung der Eingangsdaten durch und erstellt in der Regel aus den Daten einen Ableitungsbaum (in Anlehnung an das Englische gelegentlich auch als Parse-Baum bezeichnet). Dieser wird danach zur Weiterverarbeitung der Daten verwendet; typische Anwendungen sind die semantische Analyse, Codegenerierung in einem Compiler oder Ausführung durch einen Interpreter.
Bei HTML würde ein lexikalischer Scanner die HTML-Datei in HTML-Tags und Fließtext zerlegen und diese Bestandteile an den Parser weiterreichen – d. h. den Scanner „interessiert“ nur das Aussehen der Syntaxelemente („wenn es in spitzen Klammern steht, ist es ein HTML-Tag“). Der Parser dagegen verarbeitet die syntaktischen Zusammenhänge, d. h. untersucht, welche Paare von Tags zusammengehören bzw. wie die Tags ineinander verschachtelt sind; die inhaltliche Bedeutung der Tags interessiert den Parser dagegen nicht, sondern wird erst von der darauf folgenden Weiterverarbeitung berücksichtigt.
Anschaulich dargestellt ist ein Parser diejenige Software, welche die Anweisungen im Quelltext des Anwenders überprüft, weiterverarbeitet und weiterleitet.
Parser-Typen
Man unterscheidet verschiedene Parse-Verfahren. Dabei wird nach genereller Vorgehensweise, also der Unterscheidung nach der Reihenfolge, in der die Knoten des Ableitungsbaums erstellt werden (top-down, auch theoriegetriebenes Parsing oder bottom-up, auch eingabegetriebenes Parsing, sowie left corner), spezifischer Vorgehensweise (LL, LR, SLR, LALR, LC, …) und Implementierungstechnik (rekursiv absteigend, rekursiv aufsteigend oder tabellengesteuert) unterschieden. Weiter wird auch nach Grammatikart unterschieden.
Parser für kontextfreie Grammatiken
Hier ein paar auf kontextfreien Grammatiken basierende Verfahren:
- Top-Down-Parser
- Bottom-Up-Parser
- LR-Parser
- SLR-Parser
- LALR-Parser
- Chart-Parser
- Left-Corner-Parser
- LC-Parser
Parser für kontextsensitive Grammatiken
- Packrat Parser (Parsing Expression Grammars)
Das Parsen wohldefinierter künstlicher Sprachen (siehe formale Sprachen, Programmiersprachen) ist weniger komplex als das Parsen frei gewachsener natürlicher Sprachen wie Englisch oder Deutsch, die durch eine Vielzahl von Mehrdeutigkeiten, Irregularitäten und Inkonsistenzen geprägt sind. Siehe hierzu auch Computerlinguistik.
Hinweis: Der Begriff parsen sollte nicht mit dem Begriff kompilieren verwechselt werden. Letzteres erzeugt einen Zielcode aus einem Quellcode, dabei wird unter anderem auch geparst, darüber hinaus finden aber weitere Aktionen statt.
Beispiel
Parser werden häufig eingesetzt, um aus einer Aneinanderreihung von Symbolen eine Baumstruktur zu machen. Ein typisches Beispiel dafür sind mathematische Ausdrücke wie
- .

Dieser Ausdruck, so wie er hier steht, besteht erstmal nur aus einer Reihe von Symbolen. Es ist die Aufgabe eines Tokenizers als Teil eines Parsers, diese Symbole (zum Beispiel in Leserichtung von links nach rechts) zu identifizieren und einzuordnen. Das Ergebnis ist eine Liste, die im Folgenden als Tabelle dargestellt wird und Zeile für Zeile zu lesen ist:
| Symbol | Kategorie | Erläuterung |
|---|---|---|
| 2 | Zahl | |
| + | Rechenzeichen | |
| ( | Klammer auf | |
| 2 | Zahl | |
| + | Rechenzeichen | |
| 2 | Zahl | |
| ) | Klammer zu | |
| - | Rechenzeichen | |
| sin | Symbolname | (hier: die Sinus-Funktion) |
| ( | Klammer auf | |
| π | Symbolname | (hier: die Kreiszahl π) |
| ) | Klammer zu |
Die (weitere) Aufgabe des Parsers ist nun, die zugrundeliegende Struktur dieser Symbolfolge zu erkennen. Häufig geschieht das in Form eines Parsebaums (abstrakter Syntaxbaum), der in diesem Fall so aussehen kann:
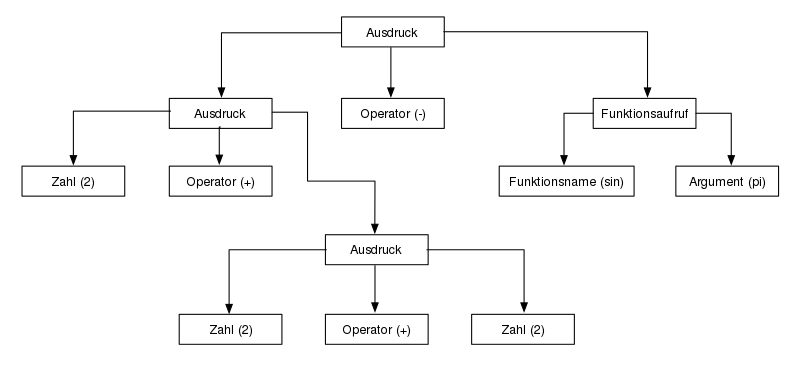
Dies ist die Ausgabe eines einfachen Parsers. Diese Ausgabe kann nun durch weitere Programme analysiert werden.
Siehe auch
Literatur
- A. W. Appel: Modern Compiler Implementation in Java. Cambridge 1998.
- Paul Bennett: A Course in Generalized Phrase Structure Grammar. London: UCL Press 1995. ISBN 1-85728-217-5.
- Robert D. Borsley: Syntactic Theory. A unified approach. London: Edward Arnold 1991. 2. überarbeitete Auflage 1998, ISBN 0-340-70610-4. Deutsche Übersetzung: Syntax-Theorie. Ein zusammengefasster Zugang. Tübingen: Niemeyer Verlag 1997. ISBN 3-484-22055-4.
- Sven Naumann, Hagen Langer: Parsing. Teubner Verlag 1994.
Weblinks
- Mathos Parser – mathematical expression parser in C# (englisch)
- Parsing Techniques – A Practical Guide (englisch)
- Syntaxanalyse (Parsing) (PS)