Kovarianzmatrix
In der Stochastik ist die Kovarianzmatrix die Verallgemeinerung der Varianz einer eindimensionalen Zufallsvariable auf eine mehrdimensionale Zufallsvariable, d. h. auf einen Zufallsvektor. Die Elemente auf der Hauptdiagonalen der Kovarianzmatrix stellen die jeweiligen Varianzen dar, und alle übrigen Elemente Kovarianzen. Die Kovarianzmatrix wird auch Varianz-Kovarianzmatrix oder selten Streuungsmatrix bzw. Dispersionsmatrix (lateinisch dispersio „Zerstreuung“, von dispergere „verteilen, ausbreiten, zerstreuen“) genannt und ist eine positiv semidefinite Matrix. Sind alle Komponenten des Zufallsvektors linear unabhängig, so ist die Kovarianzmatrix positiv definit.




Definition
Sei ein Zufallsvektor
- ,

wobei den Erwartungswert von , die Varianz von und die Kovarianz der reellen Zufallsvariablen und darstellt. Der Erwartungswertvektor von ist dann gegeben durch (siehe Erwartungswert von Matrizen und Vektoren)





- ,

d. h. der Erwartungswert des Zufallsvektors ist der Vektor der Erwartungswerte. Eine Kovarianzmatrix für den Zufallsvektor lässt sich wie folgt definieren:[1]

Die Kovarianzmatrix wird mit , oder notiert und die Kovarianzmatrix der asymptotischen Verteilung einer Zufallsvariablen mit oder . Die Kovarianzmatrix und der Erwartungswertvektor sind die wichtigsten Kenngrößen einer Wahrscheinlichkeitsverteilung. Sie werden bei einer Zufallsvariablen als Zusatzinformationen wie folgt angegeben: . Die Kovarianzmatrix als Matrix aller paarweisen Kovarianzen der Elemente des Zufallsvektors enthält Informationen über seine Streuung und über Korrelationen zwischen seinen Komponenten. Wenn keine der Zufallsvariablen degeneriert ist (d. h. wenn keine von ihnen eine Varianz von Null aufweist) und kein exakter linearer Zusammenhang zwischen den vorliegt, dann ist die Kovarianzmatrix positiv definit.[2] Man spricht außerdem von einer skalaren Kovarianzmatrix, wenn alle Außerdiagonaleinträge der Matrix Null sind und die Diagonalelemente dieselbe positive Konstante darstellen.[3]






Eigenschaften
Grundlegende Eigenschaften
- Für gilt: . Somit enthält die Kovarianzmatrix auf der Hauptdiagonalen die Varianzen der einzelnen Komponenten des Zufallsvektors. Alle Elemente auf der Hauptdiagonalen sind daher nichtnegativ.
- Eine reelle Kovarianzmatrix ist symmetrisch, da die Kovarianz zweier Zufallsvariablen symmetrisch ist.
- Die Kovarianzmatrix ist positiv semidefinit: Aufgrund der Symmetrie ist jede Kovarianzmatrix mittels Hauptachsentransformation diagonalisierbar, wobei die Diagonalmatrix wieder eine Kovarianzmatrix ist. Da auf der Diagonale nur Varianzen stehen, ist die Diagonalmatrix folglich positiv semidefinit und somit auch die ursprüngliche Kovarianzmatrix.
- Umgekehrt kann jede symmetrische positiv semidefinite -Matrix als Kovarianzmatrix eines -dimensionalen Zufallsvektors aufgefasst werden.
- Aufgrund der Diagonalisierbarkeit, wobei die Eigenwerte (auf der Diagonale) wegen der positiven Semidefinitheit nicht-negativ sind, können Kovarianzmatrizen als Ellipsoide dargestellt werden.
- Für alle Matrizen gilt .
- Für alle Vektoren gilt .
- Sind und unkorrelierte Zufallsvektoren, dann gilt .
- Man erhält mit der Diagonalmatrix die Kovarianzmatrix durch die Beziehung , wobei die Korrelationsmatrix in der Grundgesamtheit darstellt
- Sind die Zufallsvariablen standardisiert, so enthält die Kovarianzmatrix gerade die Korrelationskoeffizienten und man erhält die Korrelationsmatrix
- Die Inverse der Kovarianzmatrix heißt Präzisionsmatrix oder Konzentrationsmatrix
- Die Determinante der Kovarianzmatrix wird verallgemeinerte Varianz genannt und ist ein Maß für die Gesamtstreuung eines multivariaten Datensatzes
- Für die Spur der Kovarianzmatrix gilt

















Beziehung zum Erwartungswert des Zufallsvektors
Ist der Erwartungswertvektor, so lässt sich mit dem Verschiebungssatz von Steiner angewandt auf mehrdimensionale Zufallsvariablen zeigen, dass

- .

Hierbei sind Erwartungswerte von Vektoren und Matrizen komponentenweise zu verstehen.
Ein Zufallsvektor, der einer gegebenen Kovarianzmatrix gehorchen und den Erwartungswert haben soll, kann wie folgt simuliert werden:
zunächst ist die Kovarianzmatrix zu zerlegen (z. B. mit der Cholesky-Zerlegung):

- .

Anschließend lässt sich der Zufallsvektor berechnen zu

mit einem (anderen) Zufallsvektor mit voneinander unabhängigen standardnormalverteilten Komponenten.

Kovarianzmatrix zweier Vektoren
Die Kovarianzmatrix zweier Vektoren lautet

mit dem Erwartungswert des Zufallsvektors und dem Erwartungswert des Zufallsvektors .



Kovarianzmatrix als Effizienzkriterium
Die Effizienz bzw. Präzision eines Punktschätzers lässt sich mittels der Varianz-Kovarianzmatrix messen, da diese die Informationen über die Streuung des Zufallsvektors zwischen seinen Komponenten enthält. Im Allgemeinen gilt, dass sich die Effizienz eines Parameterschätzers anhand der „Größe“ seiner Varianz-Kovarianzmatrix messen lässt. Es gilt je „kleiner“ die Varianz-Kovarianzmatrix, desto größer die Effizienz des Schätzers. Seien und zwei unverzerrte Zufallsvektoren. Wenn ein Zufallsvektor ist, dann ist eine positiv definite und symmetrische Matrix. Man kann sagen, dass „kleiner“ ist als in Sinne der Loewner-Halbordnung, d. h., dass eine positiv semidefinite Matrix ist.[4]








Kovarianzmatrix in Matrix-Notation
Die Kovarianzmatrix lässt sich in der Matrix-Notation darstellen als
- ,

wobei die Einsmatrix und die Anzahl Dimensionen bezeichnet.[5]


Stichproben-Kovarianzmatrix
Eine Schätzung der Korrelationsmatrix in der Grundgesamtheit erhält man, indem man die Varianzen und Kovarianzen in der Grundgesamtheit und durch die empirischen Varianzen und empirischen Kovarianzen (ihre empirischen Gegenstücke) und ersetzt (sofern die -Variablen Zufallsvariablen darstellen schätzen die die Parameter in der Grundgesamtheit). Diese sind gegeben durch[6][7]




- und .


Dies führt zur Stichproben-Kovarianzmatrix :

- .

Zum Beispiel sind und gegeben durch


- und ,


mit dem arithmetischen Mittel
- .

Spezielle Kovarianzmatrizen
Kovarianzmatrix des gewöhnlichen Kleinste-Quadrate-Schätzers
Für die Kovarianzmatrix des gewöhnlichen Kleinste-Quadrate-Schätzers

ergibt sich nach den obigen Rechenregeln:
- .

Diese Kovarianzmatrix ist unbekannt, da die Varianz der Störgrößen unbekannt ist. Einen Schätzer für die Kovarianzmatrix erhält man, indem man die unbekannte Störgrößenvarianz durch den erwartungstreuen Schätzer der Störgrößenvarianz ersetzt (siehe hierzu: Erwartungstreue Schätzung des unbekannten Varianzparameters).



Kovarianzmatrix bei scheinbar unverbundenen Regressionsgleichungen
Bei scheinbar unverbundenen Regressionsgleichungen (englisch: seemingly unrelated regression equations, kurz SURE) des Modells
- ,

wobei der Fehlerterm idiosynkratisch ist, ergibt sich die Kovarianzmatrix als


Beispiel
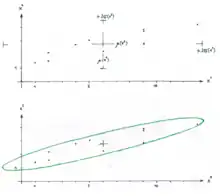
Bei 10 Datenpunkten seien jeweils die Werte und gemessen worden:


| 1,0 | 1,41 |
| 2,0 | 1,56 |
| 2,0 | 2,19 |
| 4,0 | 2,79 |
| 5,0 | 3,04 |
| 6,0 | 2,23 |
| 9,0 | 3,74 |
| 9,0 | 3,84 |
| 9,0 | 2,80 |
| 13,0 | 4,18 |
Die Berechnung des geschätzten Mittelwertes ergibt: , , ; , .





Daher ist die Stichprobenkovarianzmatrix .

In Bezug auf den Mittelpunkt der Punktwolke kann im Diagramm eine Konzentrationsellipse eingezeichnet werden. Die Punkte auf dem Rand der Ellipse sind also durch folgende Menge gegeben:

.

Siehe auch
Literatur
- Friedrich Schmid, Mark Trede: Finanzmarktstatistik. Springer-Verlag, Berlin 2006, ISBN 3-540-27723-4 (eingeschränkte Vorschau in der Google-Buchsuche).
Einzelnachweise
- George G. Judge, R. Carter Hill, W. Griffiths, Helmut Lütkepohl, T. C. Lee. Introduction to the Theory and Practice of Econometrics. 2. Auflage. John Wiley & Sons, New York/ Chichester/ Brisbane/ Toronto/ Singapore 1988, ISBN 0-471-62414-4, S. 43.
- George G. Judge, R. Carter Hill, W. Griffiths, Helmut Lütkepohl, T. C. Lee. Introduction to the Theory and Practice of Econometrics. 2. Auflage. John Wiley & Sons, New York/ Chichester/ Brisbane/ Toronto/ Singapore 1988, ISBN 0-471-62414-4, S. 43.
- Jeffrey Marc Wooldridge: Introductory econometrics: A modern approach. 5. Auflage. Nelson Education, 2015, S. 857.
- George G. Judge, R. Carter Hill, W. Griffiths, Helmut Lütkepohl, T. C. Lee. Introduction to the Theory and Practice of Econometrics. 2. Auflage. John Wiley & Sons, New York/ Chichester/ Brisbane/ Toronto/ Singapore 1988, ISBN 0-471-62414-4, S. 78.
- Arnold, L. O., & Owaida, M. (2020). Single-Pass Covariance Matrix Calculation on a Hybrid FPGA/CPU Platform. In EPJ Web of Conferences (Vol. 245). EDP Sciences.
- Ludwig Fahrmeir, Thomas Kneib, Stefan Lang, Brian Marx: Regression: models, methods and applications. Springer Science & Business Media, 2013, ISBN 978-3-642-34332-2, S. 648.
- Rencher, Alvin C., und G. Bruce Schaalje: Linear models in statistics., John Wiley & Sons, 2008., S. 156.