Lateinisches Schriftsystem
Das lateinische Schriftsystem ist ein alphabetisches Schriftsystem. Es basiert auf dem lateinischen Alphabet, das seit dem Ende seiner Entwicklung während der Renaissance 26 Buchstaben umfasst.
| Lateinisches Schriftsystem | ||
|---|---|---|
| Schrifttyp | Alphabetschrift | |
| Sprachen | siehe Liste | |
| Verwendungszeit | seit ca. 700 v. Chr. | |
| Abstammung | Phönizische Schrift → Griechisches Alphabet → Etruskische Schrift → Lateinisches Alphabet → Lateinisches Schriftsystem | |
| Verwandte | Kyrillisches Alphabet Koptische Schrift Armenisches Alphabet | |
| Unicodeblock | U+0000–U+02AF U+1E00–U+1EFF U+2C60–U+2C7F U+A720–U+A7FF U+AB30–U+AB6F | |
| ISO 15924 | Latin, 215 | |
Das lateinische Schriftsystem wird in den meisten romanischen, germanischen, slawischen und finno-ugrischen Sprachen verwendet. Im Zuge des Kolonialismus wurde es in andere Teile der Welt verbreitet, insbesondere nach Amerika, Afrika südlich der Sahara und Ozeanien. Darüber hinaus wurde es in einigen Ländern, etwa der Türkei, aus freier Entscheidung eingeführt. Damit ist das lateinische Schriftsystem das am weitesten verbreitete Schriftsystem der Welt. Alphabete von über 60 Ländern leiten sich mit Anpassungen davon ab und werden als „lateinische Alphabete“ charakterisiert.
Das lateinische Schriftsystem selbst ist hingegen kein Alphabet, da für die Gesamtheit der Schriftzeichen – neben den 26 Grundbuchstaben über 90 weitere – keine allgemeingültige und für Alphabete konstituierende Buchstabenfolge definiert ist. Beispielsweise ist der Buchstabe ö im deutschen Alphabet als Variante des o einsortiert, im schwedischen jedoch als letzter Buchstabe nach z, å und ä. Dennoch wird die Bezeichnung Lateinisches Alphabet oft für das Schriftsystem an sich verwendet.
Als Folge der Anpassung an zahlreiche Sprachen oder Sprachgruppen gehören zum lateinischen Schriftsystem viele Buchstaben, teils mit diakritischen Zeichen, die nur in bestimmten Sprachen verwendet werden.[1] Die 26 am weitesten verbreiteten Buchstaben des lateinischen Alphabets sind in verschiedenen Standards festgehalten, etwa in ASCII, in ISO 646 oder im Unicodeblock Basis-Lateinisch.
Eine vom lateinischen Grundalphabet abgeleitete Schrift wird als lateinische Schrift oder Lateinschrift bezeichnet. Eine Umschrift anderer Schriftsysteme in ein lateinisches Alphabet nennt man Romanisierung.
Das lateinische Schriftsystem
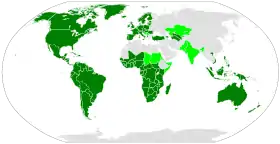
Der Zeichenvorrat des lateinischen Schriftsystems umfasst die Buchstaben aller Alphabete, die aus dem lateinischen Alphabet abgeleitet sind. Die einzelnen Alphabete enthalten entweder alle 26 Buchstaben des lateinischen Grundalphabets oder einen Großteil davon:
| Großbuchstaben | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kleinbuchstaben | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z |
Bei vielen Alphabeten kommen zusätzliche Zeichen hinzu, beispielsweise im deutschen Alphabet die drei Umlaute (Ä, Ö, Ü) und das Eszett (ß). Die zusätzlichen Zeichen sind zumeist Buchstaben mit diakritischen Zeichen. Einige Sprachen verwenden das lateinische Grundalphabet in unverändertem Umfang, darunter die Weltsprache Englisch und das Malaiische mit 200 Millionen Sprechern.
Eigenschaften
Schriftelemente
Die Lateinschrift ist eine Buchstabenschrift, d. h. ihre Schriftzeichen sind Buchstaben, die (einzeln oder in Gruppen) Phoneme (Laute) einer Sprache repräsentieren. Die Zuordnung von Buchstaben bzw. -gruppen zu Lauten kann jedoch für jedes sprachspezifische Alphabet unterschiedlich festgelegt werden (so kann der Buchstabe w im Deutschen den Konsonanten /v/, im Englischen den Halbvokal /w/ und im Walisischen den Vokal /uː/ repräsentieren). Auch kann ein Buchstabe für eine Sprache je nach Stellung im Wort unterschiedliche Laute repräsentieren oder sogar nur einer Schreibkonvention entsprechen, ohne dass sich aus der Buchstabenfolge die Lautung ergibt (z. B. englisch read kann gelesen werden als [ɹiːd] ‚lesen‘ oder [ɹɛd] ‚las‘).
Die Lateinschrift ist im Unterschied zum klassischen lateinischen Alphabet bikameral, d. h., grundsätzlich hat jeder Buchstabe zwei Formen: Großbuchstabe (Majuskel) und Kleinbuchstabe (Minuskel). In den meisten Orthographien werden der erste Buchstabe des ersten Wortes im Satz sowie der erste Buchstabe eines Eigennamens als Großbuchstabe dargestellt. Viele Orthographien erlauben auch die Großschreibung des Anfangsbuchstabens weiterer Wörter in Überschriften. Weiterhin wird üblicherweise die ausschließliche Verwendung von Großbuchstaben in speziell hervorzuhebenden Texten (wie Schlagzeilen) erlaubt. Die deutsche Rechtschreibung hat die Besonderheit, dass gemäß ihr die Anfangsbuchstaben von Substantiven grundsätzlich als Großbuchstaben geschrieben werden. Für die dänische Rechtschreibung wurde eine ähnliche Regelung mit der Reform von 1948 abgeschafft. – Ausnahmen sind beispielsweise das Alphabet der Saanich, die nur Großbuchstaben für Lautdarstellung und den Kleinbuchstaben s für das Possessivsuffix verwenden, oder das der Yuchi, die Klein- und Großbuchstaben für unterschiedliche Phoneme verwenden.
Zum lateinischen Schriftsystem gehören auch verschiedene Lautschriftsysteme, insbesondere das Internationale Phonetische Alphabet (IPA), die Teuthonista, das Amerikanistische Phonetische Alphabet und das Uralische Phonetische Alphabet (UPA). Alle genannten Lautschriften verwenden ausschließlich Kleinbuchstaben, zu denen dann keine Großbuchstabenform existiert, wenn eine solche nicht bei der Übernahme eines solchen Buchstabens in ein anderes Alphabet geschaffen wurde (wie es mit einzelnen IPA-Buchstaben zur Verschriftung subsahara-afrikanischer Sprachen wie das pannigerianische Alphabet gemacht wurde). Sofern einzelne Großbuchstabenformen als Lautschriftzeichen übernommen wurden, gelten diese als eigenständige Kleinbuchstaben, nicht als Bestandteil des ursprünglichen Groß-/Kleinbuchstabenpaares. Beispielsweise ist der IPA-Buchstabe [ɪ] (Unicode: U+026A latin letter small capital i) kein Bestandteil des Buchstabenpaares ‚I/i‘, bei Übernahme in das Alphabet der in der Elfenbeinküste und in Ghana gesprochenen Kulango-Sprache wurde der zugehörige Großbuchstabe ‚Ɪ‘ (U+A7AE latin capital letter small capital i) geschaffen.[2]
Typografie
Typografisch stehen die Buchstaben auf einer selbst nicht dargestellten Grundlinie und sind (außer in speziellen Schriftarten oder in Schreibschrift) nicht miteinander verbunden (im Unterschied beispielsweise zu Devanagari, in dem die Zeichen an einer sichtbar durchgezeichneten Grundlinie hängen, oder zur arabischen Schrift, bei der die Zeichen eines Wortes grundsätzlich miteinander verbunden werden). Die Buchstaben lassen sich mit Hilfe eines typografischen Liniensystems beschreiben.
Wörter werden grundsätzlich durch ein Leerzeichen voneinander getrennt (im Gegensatz zur scriptio continua beispielsweise im klassischen lateinischen Alphabet oder in der thailändischen Schrift). Satzenden und Gliederungen innerhalb eines Satzes werden durch Satzzeichen markiert, von denen die in modernen Texten häufigsten (Punkt und Komma) wesentlich kleiner als die Buchstaben dargestellt werden (im Gegensatz beispielsweise zu den Virgeln frühneuzeitlicher Drucke oder den Dandas des indischen Schriftenkreises).
Diakritika, Ligaturen, Variationen
_2.svg.png.webp)
In den Alphabeten zahlreicher Sprachen wurden die Buchstaben um diakritische Zeichen ergänzt (z. B. å, é, ï, ò, û), um weitere sprachspezifische Laute darstellen zu können. Sehr viele Diakritika existieren in der vietnamesischen Schrift, welche wie das Türkische erst spät ein lateinschriftliches Alphabet erhielt. Hingegen verwendet das Indonesische bzw. Malaiische, eine andere südostasiatische Sprache, die auch erst relativ spät ein lateinisches Alphabet erhielt, so gut wie keine diakritischen Zeichen.
Daneben wurden Buchstabenkombinationen (wie ch, sch, th, ng, sz) entwickelt, aus denen im Laufe der Zeit auch Ligaturen werden konnten, die später (wie W aus VV im Spätlateinischen, æ aus a und e im Dänischen, Norwegischen und Isländischen oder das kleine ß aus langem s (ſ) und rundem s oder z) oft zu selbständigen Buchstaben wurden. Erst in den letzten Jahrzehnten entwickelte sich schließlich auch ein großes ß (ẞ), das in der 2008 in Kraft getretenen Ergänzung der ISO/IEC-10646-Norm offiziell anerkannt wurde.[3]
Neue Buchstaben entstanden aber auch dadurch, dass bisherige in ihrer Form differenziert, modifiziert oder ergänzt wurden, etwa das G in Unterscheidung zum C schon im klassischen Latein, das Ð (u. a. im Isländischen) oder das Ŋ (u. a. im Samischen).
Weitere Buchstaben erstanden dadurch, dass aus ursprünglichen Varianten (Allografen) eines Buchstabens mit der Zeit zwei eigenständige Buchstaben wurden (wie schon im späteren Latein das J neben dem I oder das U neben dem V).
Andere Buchstaben wurden aus anderen Schriftsystemen als neue lateinschriftliche Buchstaben übernommen. So gelangten bereits zu Zeiten des klassischen Lateins Y und Z aus dem Griechischen ans Ende des lateinischen Alphabets, und im Isländischen wurde der Buchstabe Þ (Thorn) aus dem Runenalphabet übernommen.
Zeichenkodierung
Die 26 Buchstaben des englischen Alphabets und die wichtigsten Satz- und Sonderzeichen sind in dem mit 7 Bits zu adressierenden (also 128 Codepositionen umfassenden) American Standard Code for Information Interchange (ASCII) enthalten, der 1968 eingeführt wurde. Die englische Sprache verwendet alle diese 26 Zeichen und benötigt darüber hinaus keine Sonderzeichen. Um die je nach Land oder Sprache zusätzlich benötigten Sonderzeichen einzubeziehen, wurden im Rahmen von ISO 646 Varianten dieses Codes geschaffen, bei denen einzelne Zeichen des 7-Bit-Codes ausgetauscht wurden.
Später wurden auf dem ASCII aufbauende, je nach Region der Erde unterschiedliche 8-Bit-Codes entworfen, die jeweils 128 weitere Zeichen adressieren können. Die verbreitetsten dieser 8-Bit-Codes sind Latin-1 bis Latin-10 des internationalen Standards ISO 8859 (ASCII+ANSI), sowie ISO 6937. In dieser Phase der Entwicklung ging jedes Computersystem seinen eigenen Weg; im Westen verbreitete Implementierungen von Zeichensatztabellen waren die Windows Codepage 1252, Macintosh Roman sowie die IBM-Codepages 437 oder 850.
Um die für alle Sprachen der Welt benötigten Zeichen in einem einzigen Code zusammenzufassen, wurde 1991 der zunächst 16 Bit umfassende (und inzwischen auf über eine Million Zeichen erweiterbare) Unicode geschaffen, der in einer Reihe sogenannter Blöcke lateinische Buchstaben mit diakritischen Zeichen enthält (Details dazu unter Lateinische Zeichen in Unicode). Der zugehörige ISO-Standard ist das ISO 10646 Universal Coded Character Set, das parallel aufgebaut und konform gehalten wird.
Siehe auch
Literatur
- Johannes Bergerhausen, Siri Poarangan: decodeunicode: Die Schriftzeichen der Welt Hermann Schmidt, Mainz 2011, ISBN 978-3874398138.
- Carl Faulmann: Das Buch der Schrift, enthaltend die Schriftzeichen und Alphabete aller Zeiten und aller Völker des Erdkreises. 1878, aktuell in Nachdrucken erhältlich.
- Harald Haarmann: Geschichte der Schrift. Beck, München 2002, ISBN 3-406-47998-7.
- Harald Haarmann: Universalgeschichte der Schrift. Campus, Frankfurt am Main, New York, NY 1990, ISBN 3-593-34346-0.
- Hans Jensen: Die Schrift in Vergangenheit und Gegenwart. 1987 (Reprint), ISBN 3-326-00232-7.
- Albert Kapr: Schriftkunst. Geschichte, Anatomie und Schönheit der lateinischen Buchstaben. Verlag der Kunst, Dresden 1971, ISBN 3-364-00624-5.
- Rudolf Wachter: Altlateinische Inschriften. Lang, Bern 1987, ISBN 978-3-261-03722-0, S. 324–33: Die Erfindung des Buchstabens G.
Weblinks
- Unicode-Codetabellen bei www.unicode.org (alle PDF, je ca. 150 kb): Basic Latin, Latin-1 Supplement, Latin Extended-A, Latin Extended-B, Latin Extended Additional
Einzelnachweise
- Definition von Latin script in: Chapter 7: Europe I – Modern and Liturgical Scripts. (PDF) In: The Unicode Standard: Version 8.0 – Core Specification. Unicode Consortium, August 2015, S. 289, abgerufen am 19. Oktober 2015 (englisch).
- Michael Everson, Denis Jacquerye, Chris Lilley: Document L2/12-270: Proposal for the addition of ten Latin characters to the UCS. Unicode Consortium, 26. Juli 2012, S. 5, abgerufen am 18. Oktober 2015.
- ISO/IEC 10646