American Standard Code for Information Interchange
Der American Standard Code for Information Interchange (ASCII, alternativ US-ASCII, oft [ˈæski] ausgesprochen, deutsch „Amerikanischer Standard-Code für den Informationsaustausch“) ist eine 7-Bit-Zeichenkodierung; sie entspricht der US-Variante von ISO 646 und dient als Grundlage für spätere, auf mehr Bits basierende Kodierungen für Zeichensätze.
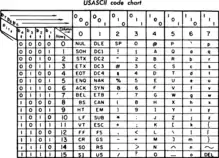
Der ASCII-Code wurde zuerst am 17. Juni 1963 von der American Standards Association (ASA) als Standard ASA X3.4-1963 gebilligt[1]:1[2]:50 und 1967/1968[3] wesentlich sowie zuletzt im Jahr 1986 (ANSI X3.4-1986)[4] von ihren Nachfolgeinstitutionen aktualisiert und wird bis heute noch benutzt. Die Zeichenkodierung definiert 128 Zeichen, bestehend aus 33 nicht druckbaren sowie den folgenden 95 druckbaren Zeichen, beginnend mit dem Leerzeichen:
{kind=link}
{kind=link}
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
Die druckbaren Zeichen umfassen das lateinische Alphabet in Groß- und Kleinschreibung, die zehn indisch-arabischen Ziffern sowie einige Interpunktionszeichen (Satzzeichen, Wortzeichen) und andere Sonderzeichen. Der Zeichenvorrat entspricht weitgehend dem einer Tastatur oder Schreibmaschine für die englische Sprache. In Computern und anderen elektronischen Geräten, die Text darstellen, wird dieser in der Regel gemäß ASCII oder abwärtskompatibel (ISO 8859, Unicode) dazu gespeichert.
Die nicht druckbaren Steuerzeichen enthalten Ausgabezeichen wie Zeilenvorschub oder Tabulatorzeichen, Protokollzeichen wie Übertragungsende oder Bestätigung und Trennzeichen wie Datensatztrennzeichen.
Kodierung
| ASCII | Dez | Hex | Binär |
|---|---|---|---|
A | 65 | 41 | (0)100 0001 |
B | 66 | 42 | (0)100 0010 |
C | 67 | 43 | (0)100 0011 |
| … | … | … | … |
Z | 90 | 5A | (0)101 1010 |
Jedem Zeichen wird ein Bitmuster aus 7 Bit zugeordnet. Da jedes Bit zwei Werte annehmen kann, gibt es 27 = 128 verschiedene Bitmuster, die auch als die ganzen Zahlen 0–127 (hexadezimal 00hex–7Fhex) interpretiert werden können.
Das für ASCII nicht benutzte achte Bit kann für Fehlerkorrekturzwecke (Paritätsbit) auf den Kommunikationsleitungen oder für andere Steuerungsaufgaben verwendet werden. Heute wird es aber fast immer zur Erweiterung von ASCII auf einen 8-Bit-Code verwendet. Diese Erweiterungen sind mit dem ursprünglichen ASCII weitgehend kompatibel, so dass alle im ASCII definierten Zeichen auch in den verschiedenen Erweiterungen durch die gleichen Bitmuster kodiert werden. Die einfachsten Erweiterungen sind Kodierungen mit sprachspezifischen Zeichen, die nicht im lateinischen Grundalphabet enthalten sind, vgl. unten.
Zusammensetzung
| Code | …0 | …1 | …2 | …3 | …4 | …5 | …6 | …7 | …8 | …9 | …A | …B | …C | …D | …E | …F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0… | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1… | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2… | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3… | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4… | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5… | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6… | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7… | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Die ersten 32 ASCII-Zeichencodes (von 00hex bis 1Fhex) sind für Steuerzeichen (control character) reserviert; siehe dort für die Erklärung der Abkürzungen in der rechts (oder oben) stehenden Tabelle. Diese Zeichen stellen keine Schriftzeichen dar, sondern dienen (oder dienten) zur Steuerung von solchen Geräten, die den ASCII verwenden (etwa Drucker). Steuerzeichen sind beispielsweise der Wagenrücklauf für den Zeilenumbruch oder Bell (die Glocke); ihre Definition ist historisch begründet.
Code 20hex (SP) ist das Leerzeichen (engl. space oder blank), das in einem Text als Leer- und Trennzeichen zwischen Wörtern verwendet und auf der Tastatur durch die Leertaste erzeugt wird.
Die Codes 21hex bis 7Ehex stehen für druckbare Zeichen, die Buchstaben, Ziffern und Interpunktionszeichen (Satzzeichen, Wortzeichen) umfassen. Die Buchstaben sind lediglich Klein- und Großbuchstaben des lateinischen Alphabets. In nicht-englischen Sprachen verwendete Buchstabenvarianten – beispielsweise die deutschen Umlaute – sind im ASCII-Zeichensatz nicht enthalten. Ebenso fehlen typografisch korrekte Gedankenstriche und Anführungszeichen, die Typografie beschränkt sich auf den Schreibmaschinensatz. Der Zweck war Informationsaustausch, nicht Drucksatz.
Code 7Fhex (alle sieben Bits auf eins gesetzt) ist ein Sonderzeichen, das auch als Löschzeichen bezeichnet wird (DEL). Dieser Code wurde früher wie ein Steuerzeichen verwendet, um auf Lochstreifen oder Lochkarten ein bereits gelochtes Zeichen nachträglich durch das Setzen aller Bits, das heißt durch Auslochen aller sieben Markierungen, löschen zu können. Dies war die einzige Möglichkeit zum Löschen, da einmal vorhandene Löcher nicht mehr rückgängig gemacht werden können. Bereiche ohne Löcher (also mit dem Code 00hex) fanden sich vor allem am Anfang und Ende eines Lochstreifens (NUL).
Aus diesem Grund gehörten zum eigentlichen ASCII nur 126 Zeichen, denn den Bitmustern 0 (0000000) und 127 (1111111) entsprachen keine Zeichencodes. Der Code 0 wurde später in der Programmiersprache C als „Ende der Zeichenkette“ interpretiert; dem Zeichen 127 wurden verschiedene grafische Symbole zugeordnet.
Geschichte
Fernschreiber
Eine frühe Form der Zeichenkodierung war der Morsecode. Er wurde mit der Einführung von Fernschreibern aus den Telegrafennetzen verdrängt und durch den Baudot-Code und Murray-Code ersetzt. Vom 5-Bit-Murray-Code zum 7-Bit-ASCII war es dann nur noch ein kleiner Schritt – auch ASCII wurde zuerst für bestimmte amerikanische Fernschreibermodelle, wie den Teletype ASR33, eingesetzt.
Die erste Version, noch ohne Kleinbuchstaben und mit kleinen Abweichungen vom heutigen ASCII bei den Steuer- und Sonderzeichen, entstand im Jahr 1963.
Im Jahr 1965 folgt die zweite Form des ASCII-Standards. Obwohl die Norm genehmigt wurde, wurde sie nie veröffentlicht und fand daher auch nie Anwendung. Der Grund dafür war, dass der ASA gemeldet wurde, dass die ISO (die International Standards Organization) einen Zeichensatz standardisieren würde, der ähnlich wie diese Norm war, aber leicht im Widerspruch zu dieser stünde.[5]
1968 wurde dann die bis heute gültige Fassung des ASCII-Standards festgelegt.[5]
| Dez | Hex | ASCII 1963 (veraltet) | ASCII 1965 (verworfen) | ASCII 1968 (aktuell) |
|---|---|---|---|---|
| 0–63 | 00–3F | siehe normale Zusammensetzung | ||
| 64 | 40 | @ | ` | @ |
| 65–91 | 41–5B | siehe normale Zusammensetzung | ||
| 92 | 5C | \ | ~ | \ |
| 93 | 5D | siehe normale Zusammensetzung | ||
| 94 | 5E | ↑ |
^ | |
| 95 | 5F | ← |
_ | |
| 96 | 60 | unbelegt | @ | ` |
| 97–122 | 61–7A | unbelegt | a – z | |
| 123 | 7B | unbelegt | { | |
| 124 | 7C | unbelegt | ¬ | | |
| 125 | 7D | unbelegt | } | |
| 126 | 7E | ESC | | | ~ |
| 127 | 7F | siehe normale Zusammensetzung | ||
Computer
In den Anfängen des Computerzeitalters entwickelte sich ASCII zum Standard-Code für Schriftzeichen. Zum Beispiel wurden viele Terminals (VT100) und Drucker nur mit ASCII angesteuert.
Für die Kodierung lateinischer Zeichen wird fast nur bei Großrechnern die zu ASCII inkompatible 8-Bit-Kodierung EBCDIC verwendet, die IBM parallel zu ASCII für sein System/360 entwickelte, damals ein ernsthafter Konkurrent. Die Handhabung des Alphabets ist in EBCDIC schwieriger, denn es ist dort auf zwei auseinander liegende Codebereiche verteilt. IBM selbst verwendete ASCII für interne Dokumente. ASCII wurde durch Präsident Lyndon B. Johnsons Anordnung 1968 gestützt, es in den Regierungsbüros zu verwenden.
Verwendung für andere Sprachen
Mit dem Internationalen Alphabet 5 (IA5) wurde 1963 eine 7-Bit-Codierung auf Basis des ASCII als ISO 646 normiert. Die Referenzversion (ISO 646-IRV) entspricht dabei bis auf eine Position dem ASCII. Um Buchstaben und Sonderzeichen verschiedener Sprachen darstellen zu können (beispielsweise die deutschen Umlaute), wurden 12 Zeichenpositionen zur Umdefinition vorgesehen (#$@[\]^`{|}~). Eine gleichzeitige Darstellung ist nicht möglich. Fehlende Anpassungen der Software an die jeweils zur Anzeige verwendete Variante führte oft zu ungewollt komischen Ergebnissen, z. B. erschien beim Einschalten des Apple II „APPLE ÜÄ“ anstelle von „APPLE ][“.
Da sich darunter Zeichen befinden, die in der Programmierung verwendet werden, insbesondere z. B. die verschiedenen Klammern, wurden Programmiersprachen über Ersatzkombinationen (Digraphen) für die Internationalisierung ertüchtigt. Zur Kodierung wurden dazu ausschließlich Zeichen aus dem invarianten Teil von ISO 646 verwendet. Die Kombinationen sind sprachspezifisch. So entspricht bei Pascal (* und *) den geschweiften Klammern ({}), während C <% und %> dafür vorsieht.
Erweiterungen
Nutzung der übrigen 128 Positionen im Byte
Zur Überwindung der Inkompatibilitäten nationaler 7-Bit-Varianten von ASCII entwickelten zunächst verschiedene Hersteller eigene ASCII-kompatible 8-Bit-Codes (d. h. solche, die auf den ersten 128 Positionen mit ASCII übereinstimmen). Der Codepage 437 genannte Code war lange Zeit der am weitesten verbreitete, er kam auf dem IBM-PC unter englischem MS-DOS, und kommt heute noch im DOS-Fenster von englischem Windows zur Anwendung. In deren deutschen Installationen ist seit MS-DOS 3.3 die westeuropäische Codepage 850 der Standard.
Auch bei späteren Standards wie ISO 8859 wurden acht Bits verwendet. Dabei existieren mehrere Varianten, zum Beispiel ISO 8859-1 für die westeuropäischen Sprachen, die in Deutschland als DIN 66303 übernommen wurde. Deutschsprachige Versionen von Windows (außer DOS-Fenster) verwenden die auf ISO 8859-1 aufbauende Kodierung Windows-1252 – daher sehen zum Beispiel die deutschen Umlaute falsch aus, wenn Textdateien unter DOS erstellt wurden und unter Windows betrachtet werden.
Jenseits von 8 Bit
Viele ältere Programme, die das achte Bit für eigene Zwecke verwendeten, konnten damit nicht umgehen. Sie wurden im Lauf der Zeit oft den neuen Erfordernissen angepasst.
Auch 8-Bit-Codes, in denen ein Byte für ein Zeichen stand, boten zu wenig Platz, um alle Zeichen der menschlichen Schriftkultur gleichzeitig unterzubringen. Dadurch wurden mehrere verschiedene spezialisierte Erweiterungen notwendig. Daneben existieren vor allem für den ostasiatischen Raum einige ASCII-kompatible Kodierungen, die entweder zwischen verschiedenen Codetabellen umschalten oder mehr als ein Byte für jedes Nicht-ASCII-Zeichen benötigen.[6] Keine dieser 8-Bit-Erweiterungen ist aber „ASCII“, denn das bezeichnet nur den einheitlichen 7-Bit-Code.
Um den Anforderungen der verschiedenen Sprachen gerecht zu werden, wurde der Unicode (in seinem Zeichenvorrat identisch mit ISO 10646) entwickelt. Er verwendet bis zu 32 Bit pro Zeichen und könnte somit über vier Milliarden verschiedene Zeichen unterscheiden, wird jedoch auf etwa eine Million erlaubte Codepoints eingeschränkt. Damit können alle bislang von Menschen verwendeten Schriftzeichen dargestellt werden, sofern sie in den Unicode-Standard aufgenommen wurden. UTF-8 ist eine 8-Bit-Kodierung von Unicode, die zu ASCII abwärtskompatibel ist. Ein Zeichen kann dabei ein bis vier 8-Bit-Wörter einnehmen. Sieben-Bit-Varianten müssen nicht mehr verwendet werden, dennoch kann Unicode auch mit Hilfe von UTF-7 in sieben Bit kodiert werden. UTF-8 entwickelte sich zum Standard unter vielen Betriebssystemen. So nutzen unter anderem Apples macOS sowie einige Linux-Distributionen standardmäßig UTF-8, und mehr als 90 %[7] der Websites werden in UTF-8 erstellt.
Formatierungszeichen gegenüber Auszeichnungssprachen
ASCII enthält nur wenige Zeichen, die allgemeinverbindlich zur Formatierung oder Strukturierung von Text verwendet werden; diese gingen aus den Steuerbefehlen der Fernschreiber hervor. Dazu zählen insbesondere der Zeilenvorschub (Linefeed), der Wagenrücklauf (Carriage Return), das Horizontal-Tabulatorzeichen, der Seitenvorschub (Form Feed) und das Vertikal-Tabulatorzeichen. In typischen ASCII-Textdateien findet sich neben den druckbaren Zeichen meist nur noch der Wagenrücklauf oder der Zeilenvorschub, um das Zeilenende zu markieren; dabei werden in DOS- und Windows-Systemen üblicherweise beide nacheinander verwendet, bei älteren Apple- und Commodore-Rechnern (ohne Amiga) nur der Wagenrücklauf und auf Unix-artigen sowie Amiga-Systemen nur der Zeilenvorschub. Die Verwendung weiterer Zeichen zur Textformatierung wird unterschiedlich gehandhabt. Zur Formatierung von Text werden inzwischen eher Markup-Sprachen wie zum Beispiel HTML verwendet.
Kompatible Zeichenkodierungen
Die meisten Zeichenkodierungen sind so entworfen, dass sie für Zeichen zwischen 0 … 127 den gleichen Code verwenden wie ASCII und den Bereich über 127 für weitere Zeichen benutzen.
Kodierungen mit fester Länge (Auswahl)
Hier steht eine feste Anzahl Bytes für jeweils ein Zeichen. In den meisten Kodierungen ist das ein Byte pro Zeichen – Single Byte Character Set oder kurz SBCS genannt. Bei den ostasiatischen Schriften sind es zwei oder mehr Byte pro Zeichen, wodurch diese Kodierungen nicht mehr ASCII-kompatibel sind. Die kompatiblen SBCS-Zeichensätze entsprechen den oben besprochenen ASCII-Erweiterungen:
- ISO 8859 mit 15 verschiedenen Zeichenkodierungen zur Abdeckung aller europäischen Sprachen, Türkisch, Arabisch, Hebräisch sowie Thai (siehe Tabelle rechts)
- MacRoman, MacCyrillic und andere proprietäre Zeichensätze für Apple Mac Computer vor Mac OS X
- DOS-Codepages (z. B. 437, 850) und Windows-Codepages (z. B. Windows-1252)
- KOI8-R für Russisch und KOI8-U für Ukrainisch
- ARMSCII-8 und ARMSCII-8a für Armenisch
- GEOSTD für Georgisch
- ISCII für alle indischen Sprachen
- TSCII für Tamil
|
|
|
Kodierungen mit variabler Länge
Um mehr Zeichen kodieren zu können, werden die Zeichen 0 bis 127 in einem Byte kodiert, andere Zeichen werden durch mehrere Bytes mit Werten von über 127 kodiert:
ASCII-Tabelle
Die folgende Tabelle gibt neben den hexadezimalen Codes auch noch die Dezimal- und Oktalcodes an.
|
|
|
|
Eponyme
Der 1936 entdeckte Asteroid (3568) ASCII wurde 1988 nach der Zeichenkodierung benannt.[8]
Ausgaben
- American Standards Association: American Standard Code for Information Interchange. ASA X3.4-1963. American Standards Association, New York 1963 (PDF 11 Seiten (Memento vom 26. Mai 2016 im Internet Archive))
- American Standards Association: American Standard Code for Information Interchange. ASA X3.4-1965. American Standards Association, New York 1965 (genehmigt, aber nicht veröffentlicht)
- United States of America Standards Institute: USA Standard Code for Information Interchange. USAS X3.4-1967. United States of America Standards Institute, 1967.
- United States of America Standards Institute: USA Standard Code for Information Interchange. USAS X3.4-1968. United States of America Standards Institute, 1968.
- American National Standards Institute: American National Standard for Information Systems. ANSI X3.4-1977. 1977.
- American National Standards Institute: American National Standard for Information Systems. Coded Character Sets. 7-Bit American National Standard Code for Information Interchange (7-Bit ASCII). ANSI X3.4-1986. 1986.
- Weitere Revisionen:
- ANSI X3.4-1986 (R1992)
- ANSI X3.4-1986 (R1997)
- ANSI INCITS 4-1986 (R2002)
- ANSI INCITS 4-1986 (R2007)
- ANSI INCITS 4-1986 (R2012)
Literatur
- Jacques André: Caractères numériques: introduction. In: Cahiers GUTenberg. Band 26, Mai 1997, ISSN 1257-2217, S. 5–44, (französisch).
- Yannis Haralambous: Fonts & encodings. From Unicode to advanced typography and everything in between. Übersetzt von P. Scott Horne. O’Reilly, Beijing u. a. 2007, ISBN 978-0-596-10242-5 (englisch).
- Peter Karow: Digitale Schriften. Darstellung und Formate. 2. verbesserte Auflage. Springer, Berlin u. a. 1992, ISBN 3-540-54917-X.
- Mai-Linh Thi Truong, Jürgen Siebert, Erik Spiekermann (Hrsg.): FontBook. Digital Typeface Compendium (= FontBook 4). 4. überarbeitete und erweiterte Auflage. FSI FontShop International, Berlin 2006, ISBN 3-930023-04-0 (englisch).
Weblinks
- RFC 20. – ASCII format for Network Interchange. 16. Oktober 1969. (ANSI X 3.4-1968 – englisch).
- ITU T.50 (09/1992) International Alphabet No. 5 (englisch)
- ISO/IEC 646:1991 (englisch)
- ASA X3.4-1963 (englisch)
- Erläuterungen zu den Steuerzeichen (englisch)
- ASCII-Tabelle mit Erläuterungen (deutsch)
- Umwandlung von und zu Dezimale, Oktale, Hexadezimale und Binäre ASCII-Schreibweise (englisch)
Einzelnachweise
- American Standards Association (Hrsg.): American Standard Code for Information Interchange. 1963 (Scans).
- Fred W. Smith: New American Standard Code for Information Interchange. In: Western Union Technical Review. April 1964, S. 50–58 (worldpowersystems.com).
- United States of America Standards Institute (Hrsg.): USA Standard Code for Information Interchange USAS X3.4-1967. 1967.
- American National Standards Institute (Hrsg.): American National Standard for Information Systems – Coded Character Sets – 7-Bit American Standard Code for Information Interchange (7-Bit ASCII) ANSI X3.4-1986. 1986 (unicode.org [PDF; 1,7 MB] ANSI INCITS 4-1986 [R2002]).
- ASA/USASI/ANSI + ISO (Memento vom 16. Januar 2010 im Internet Archive)
- Grundlagen der technischen Informatik für Technische Informatiker, HAW Hamburg, Abschnitt 3.5.1 (Memento vom 28. September 2007 im Internet Archive) (PDF)
- w3techs.com
- Minor Planet Circ. 12973 (PDF; 300 kB)