Varianzanalyse
Als Varianzanalyse, kurz VA (englisch analysis of variance, kurz ANOVA), auch Streuungsanalyse oder Streuungszerlegung genannt, bezeichnet man eine große Gruppe datenanalytischer und strukturprüfender statistischer Verfahren, die zahlreiche unterschiedliche Anwendungen zulassen.
Ihnen gemeinsam ist, dass sie Varianzen und Prüfgrößen berechnen, um Aufschlüsse über die hinter den Daten steckenden Gesetzmäßigkeiten zu erlangen. Die Varianz einer oder mehrerer Zielvariablen wird dabei durch den Einfluss einer oder mehrerer Einflussvariablen (Faktoren) erklärt. Die einfachste Form der Varianzanalyse testet den Einfluss einer einzelnen nominalskalierten auf eine intervallskalierte Variable, indem sie die Mittelwerte der abhängigen Variable innerhalb der durch die Kategorien der unabhängigen Variable definierten Gruppen vergleicht. Somit stellt die Varianzanalyse in ihrer einfachsten Form eine Alternative zum t-Test dar, die für Vergleiche zwischen mehr als zwei Gruppen geeignet ist. Varianzanalytische Modelle sind in der Regel spezielle lineare Regressionsmodelle. Das Verfahren der Varianzanalyse geht im Wesentlichen auf Ronald Aylmer Fisher zurück.
Überblick
Grundbegriffe
Die abhängige Variable heißt Zielvariable:
- Die metrische Zufallsvariable, deren Wert durch die kategorialen Variablen erklärt werden soll. Die abhängige Variable enthält Messwerte.
Die unabhängige Variable nennt man Einflussvariable oder Faktor:
- Die kategoriale Variable (= Faktor), die die Gruppen vorgibt. Ihr Einfluss soll überprüft werden, sie ist nominalskaliert.
- Die Kategorien eines Faktors heißen dann Faktorstufen. Diese Bezeichnung ist nicht identisch mit jener bei der Faktorenanalyse.
Anzahl der Zielvariablen
Je nachdem, ob eine oder mehrere Zielvariablen vorliegen, unterscheidet man zwei Formen der Varianzanalyse:
- die univariate Varianzanalyse, nach der englischen Bezeichnung analysis of variance auch als ANOVA abgekürzt
- die multivariate Varianzanalyse, nach der englischen Bezeichnung multivariate analysis of variance auch als MANOVA abgekürzt
Je nachdem, ob ein oder mehrere Faktoren vorliegen, unterscheidet man zwischen einfacher (einfaktorieller) und mehrfacher bzw. multipler (mehrfaktorieller) Varianzanalyse.
Anzahl der Untersuchungseinheiten
Im einfachsten Fall werden aus jeder Faktorstufe gleich viele Beobachtungen betrachtet. Man spricht in diesem Fall auch von einer orthogonalen Varianzanalyse oder von einem balancierten Modell. Die Arbeit mit und Interpretation von Daten, deren Faktorstufen unterschiedlich viele Elemente enthalten (z. B. auch fehlende Werte), ist schwieriger (vgl. unbalanciertes Modell).
Feste und zufällige Effekte
Eine gebräuchliche Modellunterscheidung der Varianzanalyse wird danach vorgenommen, ob die Faktoren mit festen Effekten (englisch fixed factors) oder Faktoren mit zufälligen Effekten (englisch random factors) vorliegen.[1] Von festen Effekten spricht man, wenn die Einflussfaktoren in endlich vielen Faktorstufen vorkommen und man diese alle erfasst hat bzw. die in der Untersuchung interessierende Aussage sich nur auf diese Faktorstufen bezieht. Von Modellen mit zufälligen Effekten spricht man, wenn man nur eine Auswahl aller möglichen Faktorstufen erfassen kann (vgl. hierzu auch Lineare Paneldatenmodelle).
Grundidee
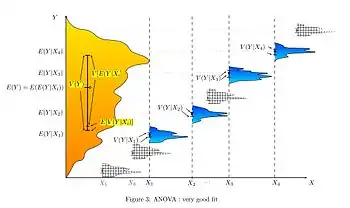
Die Verfahren untersuchen, ob (und gegebenenfalls wie) sich die Erwartungswerte der metrischen Zufallsvariablen in verschiedenen Gruppen (auch Klassen) unterscheiden. Mit den Prüfgrößen des Verfahrens wird getestet, ob die Varianz zwischen den Gruppen größer ist als die Varianz innerhalb der Gruppen. Dadurch kann ermittelt werden, ob die Gruppeneinteilung sinnvoll ist oder nicht bzw. ob sich die Gruppen signifikant unterscheiden oder nicht.
Wenn sie sich signifikant unterscheiden, kann angenommen werden, dass in den Gruppen unterschiedliche Gesetzmäßigkeiten wirken. So lässt sich beispielsweise klären, ob das Verhalten einer Kontrollgruppe mit dem einer Experimentalgruppe identisch ist. Ist beispielsweise die Varianz einer dieser beiden Gruppen bereits auf Ursachen (Varianzquellen) zurückgeführt, kann bei Varianzgleichheit darauf geschlossen werden, dass in der anderen Gruppe keine neue Wirkungsursache (z. B. durch die Experimentalbedingungen) hinzukam.
Siehe auch: Diskriminanzanalyse, Bestimmtheitsmaß
Voraussetzungen und Alternativen
Die Zuverlässigkeit der Signifikanztests im Rahmen der Varianzanalyse hängt davon ab, inwieweit ihre Voraussetzungen erfüllt sind. Diese Voraussetzungen sind je nach Anwendung etwas unterschiedlich, allgemein gelten folgende:
- Varianzhomogenität (Homoskedastizität): Die Messabweichung sollte über alle möglichen Werte der unabhängigen Variablen hinweg gleich verteilt sein.
- Normalverteilung der Vorhersagefehler (Residuen): Die Residuen sollten aus einer normalverteilten Grundgesamtheit stammen.
Die Überprüfung erfolgt mit anderen Tests außerhalb der Varianzanalyse, die allerdings heute standardmäßig in Statistik-Programmen als Option mitgeliefert werden. Die Normalverteilung der Residuen kann unter anderem mit dem Shapiro-Wilk-Test überprüft werden, Varianzhomogenität mit dem Levene-Test.
Gegen Abweichungen von der Normalverteilungsannahme gelten Varianzanalysen als robust, vor allem bei größeren Stichprobenumfängen (siehe Zentraler Grenzwertsatz). Inhomogene Varianzen stellen bei ungleichen Gruppengrößen ein Problem dar. Im Falle einfacher Varianzanalysen kann in solch einem Fall gegebenenfalls der Brown-Forsythe-Test gerechnet werden. Ferner kommt gegebenenfalls eine Transformation der abhängigen Variable in Betracht, um die Varianzen der Gruppen anzugleichen, beispielsweise durch Logarithmierung. Wenn die Voraussetzungen nicht ausreichend erfüllt sind, bieten sich zudem verteilungsfreie, nichtparametrische Verfahren an, die robust sind, aber geringere Teststärke besitzen und andere Parameter testen als die Varianzanalyse, da sie auf Rängen basieren.
- nichtparametrische Verfahren:
- für zwei Stichproben (t-Test-Alternativen):
- gepaarte (abhängige) Sp.: Wilcoxon-Vorzeichen-Rang-Test
- ungepaarte (unabhängige) Sp.: Mann-Whitney-U-Test auch Wilcoxon-Mann-Whitney-Test, U-Test, Mann-Whitney-Wilcoxon, (MWW)-Test oder Wilcoxon-Rangsummentest genannt.
- für drei oder mehr Stichproben:
- gepaarte Daten: Friedman-Test, Quade-Test
- ungepaarte Daten: Kruskal-Wallis-Test, Jonckheere-Terpstra-Test, Umbrella-Test, oder bei gleichzeitiger Verletzung von Normalverteilungsannahme und Varianzhomogenitätsannahme auch der Median-Test
- zur mehrfaktoriellen Analyse: Scheirer-Ray-Hare-Test
- PERMANOVA: ein Permutationstest
- für zwei Stichproben (t-Test-Alternativen):
Einfache Varianzanalyse
Bei einer einfachen Varianzanalyse, auch Einweg-Varianzanalyse (englisch one-way analysis of variance, kurz: one-way ANOVA), oder einfaktorielle Varianzanalyse genannt, untersucht man den Einfluss einer unabhängigen Variable (Faktor) mit verschiedenen Stufen (Gruppen) auf die Ausprägungen einer Zufallsvariablen. Dazu werden die Mittelwerte der Ausprägungen für die Gruppen miteinander verglichen, und zwar vergleicht man die Varianz zwischen den Gruppen mit der Varianz innerhalb der Gruppen. Weil sich die totale Varianz aus den zwei genannten Komponenten zusammensetzt, spricht man von Varianzanalyse. Die einfache Varianzanalyse ist die Verallgemeinerung des t-Tests im Falle mehr als zwei Gruppen. Für ist sie äquivalent mit dem t-Test.


Voraussetzungen
- Die Fehlerkomponenten müssen normalverteilt sein. Fehlerkomponenten bezeichnen die jeweiligen Varianzen (Gesamt-, Behandlungs- und Fehlervarianz). Die Gültigkeit dieser Voraussetzung setzt gleichzeitig eine Normalverteilung der Messwerte in der jeweiligen Grundgesamtheit voraus.
- Die Fehlervarianzen müssen zwischen den Gruppen (also den k Faktorstufen) gleich bzw. homogen sein (Homoskedastizität).
- Die Messwerte bzw. Faktorstufen müssen unabhängig voneinander sein.
Beispiel
Diese Form der Varianzanalyse ist angezeigt, wenn beispielsweise untersucht werden soll, ob Rauchen einen Einfluss auf die Aggressivität hat. Rauchen ist hier eine unabhängige Variable, welche in drei Ausprägungen ( Faktorstufen) unterteilt werden kann: Nichtraucher, schwache Raucher und starke Raucher. Die durch einen Fragebogen erfasste Aggressivität ist die abhängige Variable. Zur Durchführung der Untersuchung werden die Versuchspersonen den drei Gruppen zugeordnet. Danach wird der Fragebogen vorgelegt, mit dem die Aggressivität erfasst wird.

Hypothesen
Es sei der Erwartungswert der abhängigen Variable in der . Gruppe. Die Nullhypothese einer einfachen Varianzanalyse lautet:



Die Alternativhypothese lautet:

Die Nullhypothese besagt demnach, dass zwischen den Erwartungswerten der Gruppen (die den Faktorausprägungen bzw. Faktorstufen entsprechen) kein Unterschied besteht. Die Alternativhypothese besagt, dass zwischen mindestens zwei Erwartungswerten ein Unterschied besteht. Wenn wir beispielsweise fünf Faktorstufen haben, dann ist die Alternativhypothese bestätigt, wenn sich mindestens zwei der Gruppenmittelwerte unterscheiden. Es können sich aber auch drei Erwartungswerte oder vier oder alle fünf deutlich voneinander unterscheiden.
Wird die Nullhypothese verworfen, liefert die Varianzanalyse also weder Aufschluss darüber, zwischen wie vielen noch zwischen welchen Faktorstufen ein Unterschied besteht. Wir wissen dann nur mit einer bestimmten Wahrscheinlichkeit (siehe Signifikanzniveau), dass mindestens zwei Ausprägungen einen bedeutsamen Unterschied aufweisen.
Man kann nun fragen, ob es zulässig wäre, mit verschiedenen t-Tests jeweils paarweise Einzelvergleiche zwischen den Mittelwerten durchzuführen. Vergleicht man mit der Varianzanalyse nur zwei Gruppen (also zwei Mittelwerte), dann führen t-Test und Varianzanalyse zum gleichen Ergebnis. Liegen jedoch mehr als zwei Gruppen vor, ist die Überprüfung der globalen Nullhypothese der Varianzanalyse über paarweise t-Tests nicht zulässig – es kommt zur sogenannten Alphafehler-Kumulierung bzw. Alphafehler-Inflation. Mit Hilfe multipler Vergleichstechniken kann nach einem signifikanten Varianzanalyse-Ergebnis überprüft werden, bei welchem Mittelwertspaar der oder die Unterschiede liegen. Beispiele solcher Vergleichstechniken sind der Bonferroni-Test auf kleinsten signifikanten Unterschied und der Scheffé-Test (vgl. auch Post-hoc-Test). Der Vorteil dieser Verfahren liegt darin, dass sie den Aspekt der Alphafehler-Inflation berücksichtigen.
Grundgedanken der Rechnung
- Bei der Berechnung der Varianzanalyse berechnet man zunächst die beobachtete Gesamtvarianz in allen Gruppen. Dazu fasst man alle Messwerte aus allen Gruppen zusammen, errechnet den Gesamtmittelwert und die Gesamtvarianz.
- Dann möchte man den Varianzanteil der Gesamtvarianz, der allein auf den Faktor zurückgeht, ermitteln. Wenn die gesamte beobachtete Varianz auf den Faktor zurückginge, dann müssten alle Messwerte in einer Faktorstufe gleich sein – in diesem Fall dürften nur Unterschiede zwischen den Gruppen bestehen. Da alle Messwerte innerhalb einer Gruppe dieselbe Faktorausprägung aufweisen, müssten sie folglich alle den gleichen Wert haben, da der Faktor die einzige varianzgenerierende Quelle wäre. In der Praxis werden sich aber auch Messwerte innerhalb einer Faktorstufe unterscheiden. Diese Unterschiede innerhalb der Gruppen müssen also von anderen Einflüssen stammen (entweder Zufall oder sogenannten Störvariablen).
- Um nun auszurechnen, welche Varianz allein auf die Ausprägungen des Faktors zurückgeht, stellt man seine Daten für einen Moment gewissermaßen „ideal“ um: Man weist allen Messwerten innerhalb einer Faktorstufe den Mittelwert der jeweiligen Faktorstufe zu. Somit macht man alle Werte innerhalb einer Faktorstufe gleich, und der einzige Unterschied besteht nun noch zwischen den Faktorstufen. Nun errechnet man mit diesen „idealisierten“ Daten erneut die Varianz. Diese kennzeichnet die Varianz, die durch den Faktor zustande kommt („Varianz der Behandlungen“, Treatment-Varianz).
- Teilt man die Varianz der Behandlungen durch die Gesamtvarianz, erhält man den relativen Anteil der auf den Faktor zurückzuführenden Varianz.
- Zwischen der Gesamtvarianz und der Varianz der Behandlungen besteht in aller Regel eine Diskrepanz – die Gesamtvarianz ist größer als die Varianz der Behandlungen. Die Varianz, die nicht auf den Faktor (die Behandlung) zurückzuführen ist, bezeichnet man als Fehlervarianz. Diese beruht entweder auf Zufall oder anderen, nicht untersuchten Variablen (Störvariablen).
- Die Fehlervarianz lässt sich berechnen, indem man seine Daten erneut umstellt: Man errechnet für jeden einzelnen Messwert dessen Abweichung vom jeweiligen Gruppenmittelwert seiner Faktorstufe. Daraus berechnet man erneut die gesamte Varianz. Diese kennzeichnet dann die Fehlervarianz.
- Eine wichtige Beziehung zwischen den Komponenten ist die Additivität der Quadratsummen. Als Quadratsumme bezeichnet man den Teil der Varianzformel, der im Zähler steht. Lässt man also bei der Berechnung der Varianz der Behandlung den Nenner (die Anzahl der Freiheitsgrade) weg, erhält man die Quadratsumme der Behandlung. Die Gesamtquadratsumme (also Gesamtvarianz ohne Nenner) ergibt sich aus der Summe von Behandlungs- und Residuenquadratsumme.
- Die letztendliche Signifikanzprüfung erfolgt über einen „gewöhnlichen“ F-Test. Man kann mathematisch zeigen, dass bei Gültigkeit der Nullhypothese der Varianzanalyse gleichzeitig gilt, dass Treatment- und Fehlervarianz gleich sein müssen. Mit einem F-Test kann man die Nullhypothese überprüfen, dass zwei Varianzen gleich sind, indem man den Quotienten aus ihnen bildet.
- Im Falle der Varianzanalyse bildet man den Quotienten aus Varianz der Behandlungen geteilt durch die Fehlervarianz. Dieser Quotient ist F-verteilt mit Zählerfreiheitsgraden und bzw. Nennerfreiheitsgraden ( ist die Anzahl der Gruppen, ist die Gesamtzahl aller Versuchspersonen, ist die jeweilige Zahl der Versuchspersonen pro Faktorstufe).





- In Tabellen der F-Verteilung kann man dann den entsprechenden F-Wert mit entsprechenden Freiheitsgraden nachschlagen und liest ab, wie viel Prozent der F-Verteilungsdichte dieser Wert „abschneidet“. Einigen wir uns beispielsweise vor der Durchführung der Varianzanalyse auf ein Signifikanzniveau von 5 %, dann müsste der F-Wert mindestens 95 % der F-Verteilung auf der linken Seite abschneiden. Ist dies der Fall, dann haben wir ein signifikantes Ergebnis und können die Nullhypothese auf dem 5 %-Niveau verwerfen.
Mathematisches Modell
Die einfache Varianzanalyse betrachtet jeden Messwert als Summe einer „von der Faktorwirkung unabhängigen Komponente“ , der „Faktorwirkung“ und dem Versuchsfehler . Jeder Messwert kann somit durch den folgenden datengenerierenden Prozess




generiert werden. Die zweite Gleichheit resultiert daraus, dass sich der von der Faktorstufe abhängige feste Mittelwert (Mittelwert von unter der Versuchsbedingung ) aufspalten lässt in eine Komponente , die unabhängig von der Faktorwirkung ist und in die Faktorwirkung selbst. Es gilt also[2]


- .

Für den Versuchsfehler nimmt man an, dass er auf jeder Faktorstufe und für jede Wiederholung normalverteilt ist mit einem Erwartungswert von Null und einer (von der Faktorstufe unabhängigen) homoskedastischen unbekannten Fehlervarianz . Diese Annahme lässt sich so interpretieren, dass sich die Versuchsfehler im Mittel wieder ausgleichen und dass die Variabilität in allen Gruppen gleich ist.[3] Des Weiteren nimmt man an, dass die Versuchsfehler zu verschiedenen Wiederholungen unabhängig sind. Zusammenfassend lässt sich für die Versuchsfehler schreiben: . Ziel ist es die Modellparameter , und statistisch zu schätzen, also Punktschätzer , und zu finden. Mithilfe einer sogenannten Tafel der Varianzanalyse oder auch Tabelle der Varianzanalyse genannt, lässt sich das -te Faktorstufenmittel







und die -te Faktorstufenvarianz[4]

berechnen. Das Gesamtmittel stellt das mit den Fallzahlen gewichtete Mittel der Faktorstufenmittelwerte dar:


- ,

wobei den gesamten Umfang der Stichproben auf allen Faktorstufen darstellt. Der globale Erwartungswert bzw. das globale Mittel (englisch grand mean) wird gleich dem Mittel der Stufenmittelwerte gesetzt:

- .

Eine Zusatzbedingung an die Modellparameter, um die Identifizierbarkeit des Regressionsmodells sicherzustellen, ist die sogenannte Reparametrisierungsbedingung, bei der eine neue Parametrisierung vorgenommen wird. In der einfachen Varianzanalyse lautet sie
- .

D. h. die mit den Fallzahlen gewichtete Summe der Faktorwirkung ergibt Null. In diesem Fall spricht man von einer Effektkodierung. Durch die Reparametrisierungsbedingung können die Effekte eindeutig geschätzt werden. Der globale Mittelwert wird durch das Gesamtmittel geschätzt, der Parameter wird durch das Faktorstufenmittel geschätzt und die Faktorwirkung wird durch die Abweichung geschätzt. Die jeweilige Abweichung zwischen Messwert und Schätzwert (Residuum) ist durch





gegeben. Das Residuum ist gegeben durch die Abweichung des Messwertes vom -Stufenmittel und ist Ausdruck der zufälligen Variation der Variablen auf der -ten Faktorstufe. Sie kann als eine Realisierung des Versuchsfehlers bei der -ten Wiederholung auf der -ten Faktorstufe betrachtet werden.[5] Jede Realisierung der Zielgröße setzt sich additiv zusammen aus dem Gesamtmittel , der Faktorwirkung und Residuum :






- .

Quadratsummen
Die „gesamte Quadratsumme“ bzw. „totale Quadratsumme“, kurz SQT (Summe der Quadrate der Totalen Abweichungen), lässt sich in zwei Teile zerlegen. Ein Teil bezieht sich auf die Gruppenzugehörigkeit, und der andere Teil, der Rest, wird dem Zufall zugeschrieben. Der erste Teil, d. h. die „Quadratsumme bedingt durch Faktor A“, kurz SQA, lässt sich ausdrücken als die Summe der Abweichungsquadrate der Mittelwerte vom Gesamtmittelwert der Gruppen. Die durch die Regression „nicht erklärte Quadratsumme“ bzw. die Residuenquadratsumme, kurz SQR (Summe der Quadrate der Restabweichungen (oder: „Residuen“)), die die Unterschiede innerhalb der Gruppen betrifft, wird ausgedrückt als die gesamte Abweichung von den Mittelwerten in den Gruppen. Es gilt also:
- .

Hierbei ist:
- ,

- ,

und[6]
- .

Die zwei Quadratsummen und sind stochastisch unabhängig. Im Fall von Gruppen mit gleichem Umfang kann man zeigen, dass unter der Nullhypothese folgendes gilt:



- , d. h. die Quadratsumme folgt einer Chi-Quadrat-Verteilung mit Freiheitsgraden,

und
- , d. h. die Quadratsumme folgt einer Chi-Quadrat-Verteilung mit Freiheitsgraden.

Prüfgröße
Man definiert meistens auch noch die „mittleren Abweichungsquadrate“ (oft fälschlicherweise mittlere Quadratsummen genannt):
- ,

und
- .

Damit lässt sich die Prüfgröße bzw. die F-Statistik wie folgt definieren:
- .

Im Falle von Gruppen gleicher Größe ist unter der Nullhypothese also F-verteilt mit Freiheitsgraden im Zähler und Freiheitsgraden im Nenner.

Wenn die Prüfgröße signifikant wird, unterscheiden sich mindestens zwei Gruppen voneinander. In Post-hoc-Tests kann dann berechnet werden, zwischen welchen einzelnen Gruppen der Unterschied liegt.
Beispielrechnung
Bei dem folgenden Beispiel handelt es sich um eine einfache Varianzanalyse mit zwei Gruppen (auch Zwei-Stichproben-F-Test). In einem Versuch erhalten zwei Gruppen () von jeweils () Tieren unterschiedliche Nahrung. Nach einer gewissen Zeit wird ihre Gewichtszunahme mit folgenden Werten gemessen:


| Gruppe 1 | ||||||||||
| Gruppe 2 | ||||||||||




















Es soll untersucht werden, ob die unterschiedliche Nahrung einen signifikanten Einfluss auf das Gewicht hat. Der Mittelwert und die Varianz (hier „Schätzwert“, empirische Varianz) der beiden Gruppen betragen
- und
- und




Weil , lässt sich daraus berechnen:

und

Das zugrunde liegende Wahrscheinlichkeitsmodell setzt voraus, dass die Gewichte der Tiere normalverteilt sind und pro Gruppe dieselbe Varianz aufweisen. Die zu testende Nullhypothese ist
- : „Die Mittelwerte der beiden Gruppen sind gleich“

Offensichtlich unterscheiden sich die Mittelwerte und . Diese Abweichung könnte jedoch auch im Bereich der natürlichen Schwankungen liegen. Um zu prüfen, ob die Unterscheidung signifikant ist, wird die Testgröße berechnet.



Die Größe ist nach dem zugrunde liegenden Modell eine Zufallsvariable mit einer -Verteilung, wobei die Anzahl der Gruppen (Faktorstufen) und die Anzahl der Messwerte sind. Die Indizes werden als Freiheitsgrade bezeichnet. Der Wert der F-Verteilung für gegebene Freiheitsgrade (F-Quantil) kann in einer Fisher-Tafel nachgeschlagen werden. Dabei muss noch ein gewünschtes Signifikanzniveau (die Irrtumswahrscheinlichkeit) angegeben werden. Im vorliegenden Fall ist das F-Quantil zum Fehler 1. Art von 5 %. Das heißt, dass bei allen Werten der Testgröße bis 4,41 die Nullhypothese nicht abgelehnt werden kann. Da , wird die Nullhypothese bei den vorliegenden Werten abgelehnt.



Es kann also davon ausgegangen werden, dass die Tiere in den beiden Gruppen im Mittel wirklich ein unterschiedliches Gewicht aufweisen. Die Wahrscheinlichkeit, einen Unterschied anzunehmen, obwohl dieser nicht vorliegt, liegt bei unter 5 %.
Zweifache Varianzanalyse
Die zweifache Varianzanalyse, auch Zweiweg-Varianzanalyse (englisch two-way analysis of variance, kurz: two-way ANOVA), oder zweifaktorielle Varianzanalyse genannt, berücksichtigt zur Erklärung der Zielvariablen zwei Faktoren (Faktor A und Faktor B).
Beispiel
Diese Form der Varianzanalyse ist z. B. bei Untersuchungen angezeigt, welche den Einfluss von Rauchen und Kaffeetrinken auf die Nervosität darstellen wollen. Rauchen ist hier der Faktor A, welcher in z. B. drei Ausprägungen (Faktorstufen) unterteilt werden kann: Nicht-Raucher, leichter Raucher und Kettenraucher. Der Faktor B kann die täglich genutzte Menge Kaffee sein mit den Stufen: 0 Tassen, 1–3 Tassen, 4–8 Tassen, mehr als 8 Tassen. Die Nervosität ist die abhängige Variable. Zur Durchführung der Untersuchung werden Versuchspersonen über 12 Gruppen verteilt entsprechend der Kombinationen der Faktorstufen. Dabei wird die Messung der Nervosität durchgeführt, die metrische Daten liefert.
Grundgedanken der Rechnung
Das Modell (für den Fall mit festen Effekten) in Effektdarstellung lautet:

Darin sind:
- : Zielvariable; annahmegemäß in den Gruppen normalverteilt
- : Anzahl der Faktorstufen des ersten Faktors (A)
- : Anzahl der Faktorstufen des zweiten Faktors (B)
- : Anzahl der Beobachtungen pro Faktorstufe (hier für alle Kombinationen von Faktorstufen gleich)
- : Effekt der -ten Faktorstufe des Faktors A
- : Effekt der -ten Faktorstufe des Faktors B
- : Interaktion (Wechselwirkung) der Faktoren auf der Faktorstufenkombination .








Die Interaktion beschreibt einen besonderen Effekt, der nur auftritt, wenn die Faktorstufenkombination vorliegt.
- : Störvariablen, unabhängig und normalverteilt mit Erwartungswert und gleichen Varianzen.


Die Gesamtquadratsumme wird hier zerlegt in vier unabhängige Quadratsummen (Quadratsummenzerlegung):


Darin sind:
- die Gesamtquadratsumme,
- die Residuenquadratsumme,
- die Quadratsumme bedingt durch die Interaktion von A und B,
- die durch Faktor A bedingte Quadratsumme
- die durch Faktor B bedingte Quadratsumme.





Die Erwartungswerte der Quadratsummen sind:




Die Quadratsummen dividiert durch sind unter geeigneten Annahmen Chi-Quadrat-verteilt, und zwar:
- mit Freiheitsgraden
- mit Freiheitsgraden, wenn
- mit Freiheitsgraden, wenn
- mit Freiheitsgraden, wenn











Die mittleren Abweichungsquadrate ergeben sich bei Division der Quadratsummen durch ihre Freiheitsgrade:




Die zutreffende Prüfgrößen berechnen sich wie die Quotienten der mittleren Abweichungsquadrate, mit als Nenner.

Man berechnet nun die Varianzen für die einzelnen Faktoren und die Varianz für die Wechselwirkung von und . Die Hypothese lautet: Es gibt keine Wechselwirkung. Wieder wird die Hypothese mit der Prüfstatistik berechnet. Diese setzt sich nun zusammen als der Quotient der durch die Wechselwirkung von und entstand und die Fehlervarianz. Man vergleicht nun mit den F-Quantilen nach Angabe eines gewünschten Signifikanzniveaus. Ist die Prüfgröße größer als das Quantil (letzteres ist in einschlägigen Tabellen ablesbar), dann wird verworfen, es gibt also eine Wechselwirkung zwischen den Faktoren und .


Tafel der Varianzanalyse
In einer praktischen Analyse werden die Ergebnisse in der Tafel der Varianzanalyse zusammengefasst:
Variationsquelle Abweichungsquadratsumme (SQ) Anzahl der Freiheitsgrade (FG) Mittleres Abweichungsquadrat (MQ) F-Statistik (F) Faktor A Faktor B Interaktion Residual Total










Mehrfache Varianzanalyse (mehr als zwei Faktoren)
Auch mehrere Faktoren sind möglich. Diese Art der Varianzanalyse wird als mehrfache Varianzanalyse oder als mehrfaktorielle Varianzanalyse bezeichnet. Allerdings steigt der Datenbedarf für eine Schätzung der Modellparameter mit der Anzahl der Faktoren stark an. Auch die Darstellungen des Modells (z. B. in Tabellen) werden mit zunehmender Anzahl der Faktoren unübersichtlicher. Mehr als drei Faktoren können nur noch schwer dargestellt werden.
Siehe auch
Literatur
- Ludwig Fahrmeir u. a. (Hrsg.): Multivariate statistische Verfahren. 2. überarbeitete Auflage. Walter de Gruyter, Berlin u. a. 1996, ISBN 3-11-013806-9.
- Ludwig Fahrmeir, Rita Künstler, Iris Pigeot, Gerhard Tutz: Statistik. Der Weg zur Datenanalyse. 8., überarb. und erg. Auflage. Springer Spektrum, Berlin/ Heidelberg 2016, ISBN 978-3-662-50371-3 (Springer-Lehrbuch).
- Joachim Hartung, Bärbel Elpelt: Multivariate Statistik. Lehr- und Handbuch der angewandten Statistik. 6. unwesentlich veränderte Auflage. Oldenbourg, München u. a. 1999, ISBN 3-486-25287-9.
- Klaus Backhaus u. a.: Multivariate Analysemethoden. Eine anwendungsorientierte Einführung. 11. überarbeitete Auflage. Springer, Berlin u. a. 2006, ISBN 3-540-27870-2 (Springer-Lehrbuch).
Einzelnachweise
- Hans Friedrich Eckey: Multivariate Statistik: Grundlagen - Methoden - Beispiele. Dr. Th. Gabler Verlag; Auflage: 2002 (12. September 2002). ISBN 978-3409119696. S. 94.
- Werner Timischl: Angewandte Statistik. Eine Einführung für Biologen und Mediziner. 2013, 3. Auflage, S. 360.
- Ludwig Fahrmeir, Rita Künstler, Iris Pigeot, Gerhard Tutz: Statistik. Der Weg zur Datenanalyse. 8., überarb. und erg. Auflage. Springer Spektrum, Berlin/ Heidelberg 2016, ISBN 978-3-662-50371-3, S. 480.
- Werner Timischl: Angewandte Statistik. Eine Einführung für Biologen und Mediziner. 2013, 3. Auflage, S. 361.
- Werner Timischl: Angewandte Statistik. Eine Einführung für Biologen und Mediziner. 2013, 3. Auflage, S. 362.
- Werner Timischl: Angewandte Statistik. Eine Einführung für Biologen und Mediziner. 2013, 3. Auflage, S. 362.