Lineare Paneldatenmodelle
Lineare Paneldatenmodelle sind statistische Modelle, die bei der Analyse von Paneldaten benutzt werden, bei denen mehrere Individuen über mehrere Zeitperioden beobachtet werden. Paneldatenmodelle nutzen diese Panelstruktur aus und erlauben es, unbeobachtete Heterogenität der Individuen zu berücksichtigen. Die beiden wichtigsten linearen Paneldatenmodelle sind das Paneldatenmodell mit festen Effekten[1] (englisch fixed effects model) und das Paneldatenmodell mit zufälligen Effekten[2] (englisch random effects model). Die beiden Modelle unterscheiden sich in den Annahmen, die an den Fehlerterm des Modells gestellt werden und erlauben die Herleitung verschiedener Schätzer. Anwendungsgebiete von linearen Paneldatenmodellen finden sich vor allem in der Empirischen Sozialforschung.

Paneldaten und für sie entwickelte Modelle werden zur Beantwortung solcher und anderer Fragen benutzt.
Grundlagen
Bei der Auswertung statistischer Daten sollen aus einer endlichen Menge an Daten Aussagen über die zugrundeliegende Verteilung von Merkmalen in einer Grundgesamtheit ermittelt werden. Man versucht, die unbekannten Parameter dieser Grundgesamtheit mit Hilfe von Schätzern zu ermitteln. Eine typische Anwendung ist die Schätzung des Effekts einer Variablen auf eine andere Variable (siehe auch Regressionsanalyse). Ein Beispiel hierfür wäre die in der Arbeitsökonomik relevante Frage nach dem Effekt von Bildung () auf das Einkommen einer Person ().[3]


Ein Schätzer ist eine Zufallsvariable, was zu Unschärfe bei den ermittelten Parametern führt (siehe auch Verteilungsfunktion und Varianz). Deswegen wird selbst im Idealfall der „wahre Wert“ des unbekannten Parameters nicht erreicht, sondern nur Näherungswerte.
Die Fähigkeit, den wahren Wert zumindest im Erwartungswert zu erreichen (Erwartungstreue) oder für große Stichproben gegen ihn zu konvergieren (Konsistenz), sowie die Varianz des Schätzers um den wahren Wert sind deswegen wichtige Eigenschaften eines Schätzers. Die Methode der kleinsten Quadrate ist eine weit verbreitete Methode, um Schätzer zu konstruieren, die unter den Gauß-Markow-Annahmen konsistent und effizient sind. Werden jedoch relevante Größen nicht in die Regression mit aufgenommen, so können Endogenität, Heteroskedastie und Autokorrelation entstehen, wodurch die Kleinste-Quadrate-Schätzung ihre wünschenswerten Eigenschaften verliert und ineffizient oder sogar inkonsistent wird. Durch die Nutzung von Paneldaten und Paneldatenmodellen können Schätzer hergeleitet werden, die diese Probleme lösen.
Eine typische Gleichung eines linearen Paneldatenmodelles für ein Panel mit Individuen und Zeitperioden hat die Form


- .

Dabei stellt die Ausprägung der erklärten/abhängigen Variable für Individuum und Zeitperiode dar. ist ein Vektor, der die Ausprägungen der erklärenden/unabhängigen Variablen enthält. Als Beispiel könnte das Einkommen einer Person im Jahr sein. Variablen im Vektor wären dann jene Faktoren, die einen Einfluss auf das Einkommen einer Person haben, wie Alter, Arbeitserfahrung, ob eine Person arbeitslos ist oder nicht, Geschlecht, Nationalität oder die Anzahl besuchter Fortbildungsseminare. Die im Vektor zusammengefassten Variablen sind allesamt beobachtbar und stehen in dem Datensatz zur Verfügung. Neben diesen Variablen gibt es jedoch noch weitere Faktoren, die nicht oder nur sehr schwer beobachtet werden können und deswegen nicht im Datensatz zur Verfügung stehen. Diese Faktoren werden durch die Terme und repräsentiert. stellt dabei einen Sammelterm für all jene unbeobachteten Variablen dar, die sich über Zeit und Personen unterscheiden, zum Beispiel die Gesundheit einer Person im Jahr . steht für die unbeobachteten Variablen, die sich zwischen Personen unterscheiden, für eine gegebene Person aber über die Zeit konstant sind. Beispiele hierfür wären die grundsätzlichen Wertvorstellungen einer Person oder ihre Intelligenz/Fähigkeit. Die Terme sind unter anderem als „unbeobachtete Heterogenität“, „latente Variable“ oder „individuelle Heterogenität“ bekannt.[4][5]






Alternativ zur obigen Schreibweise findet auch oft eine Matrizenschreibweise Anwendung, bei der die einzelnen Gleichungen quasi „übereinander“ gestellt werden. Dies ergibt dann das Modell
- .

Dabei ist ein Vektor mit den Ausprägungen der erklärten Variable, eine Matrix mit den Ausprägungen der erklärenden Variablen. ist ein Vektor mit den Koeffizienten der erklärenden Variablen, und und sind Vektoren mit den Fehlertermen.







Die beiden wichtigsten linearen Paneldatenmodelle sind das Modell mit festen Effekten und das Modell mit zufälligen Effekten. Der zentrale Unterschied zwischen diesen beiden Modellen ist, welche Annahme an die Korrelation zwischen der individuellen Heterogenität und den beobachteten erklärenden Variablen getroffen wird.
Beispiel
Ein Beispiel für die Anwendung von Modellen mit zufälligen und Modellen mit festen Effekten und ihren Schätzern findet man in der oben genannten Frage nach dem Einfluss von Bildung auf das Einkommen einer Person. Wie oben erwähnt wäre das jährliche Einkommen einer Person die erklärte Variable; erklärende Variablen wären zum einen die Bildung (gemessen in Jahren oder in abgeschlossenen Klassen/Kursen), deren Effekt gemessen werden soll. Daneben müssten noch alle Variablen in die Regression mit aufgenommen werden, die sowohl mit dem Einkommen als auch mit der Bildung korreliert sind. Exemplarisch wären hier das Alter, die Berufserfahrung oder die Bildung der Eltern zu nennen. Daneben ist es möglich, dass andere relevante Faktoren (zum Beispiel die Intelligenz, die Gesundheit oder die Werthaltung einer Person) nicht erfasst werden – es wird also individuelle Heterogenität bestehen. Eine mögliche zu schätzende Gleichung wäre

wobei einen Vektor mit zusätzlichen Kontrollvariablen wie Alter, Erfahrung und ähnlichem darstellt. Die Variable umfasst dabei nicht nur die vor Berufsbeginn abgeschlossene Bildung, sondern auch später erworbene Abschlüsse.[6] wird hierbei alle Effekte auffangen, die bei einem Individuum über die Zeit konstant sind, aber nicht als Kontrollvariablen in die Regression mit aufgenommen werden können, etwa weil sie nicht direkt beobachtbar sind. Wie bereits erwähnt, ist die Intelligenz der beobachteten Individuen ein Beispiel dafür. Diese wird wahrscheinlich eine Auswirkung auf den Verdienst eines Individuums haben und wird darüber hinaus auch mit der Bildung korreliert sein. Intelligenz kann aber nur schwer gemessen und folglich nur schwer als Kontrollvariable in die Regression mit aufgenommen werden. Ähnliches gilt für andere unbeobachtete, aber relevante Variablen, die gemeinsam die „individuelle Heterogenität“ bilden. Die Korrelation zwischen dieser Heterogenität und den erklärenden Variablen ist der zentrale Unterschied zwischen dem Modell mit zufälligen und dem mit festen Effekten. Besteht keine solche Korrelation, so wird das Modell mit zufälligen Effekten verwendet. Das Modell mit festen Effekten kommt zum Einsatz, wenn die individuelle Heterogenität mit erklärenden Variablen korreliert ist.

Modell mit zufälligen Effekten
Grundlagen
Das Modell mit zufälligen Effekten (zur Abgrenzung manchmal auch Modell mit zufälligem Achsenabschnitt[7] genannt) macht die Annahme, dass die unbeobachtete Heterogenität orthogonal zu den erklärenden Variablen steht, d. h. nicht mit den erklärenden Variablen korreliert:

Darüber hinaus muss auch strikte Exogenität des Fehlerterms angenommen werden:
- .[8]

Unter diesen Annahmen kann die individuelle Heterogenität als ein weiterer Fehlerterm gesehen werden, d. h. das zu schätzende Modell kann umgeschrieben werden als

mit
- .

Aufgrund der obigen Annahmen ist dann für .[9]


Das Modell mit zufälligen Effekten erfüllt also die Anforderung, dass der Fehlerterm der Regression und die erklärenden Variablen unkorreliert sind. Aus diesem Grund würde eine gewöhnliche Kleinste-Quadrate-Schätzung zu konsistenten Schätzern für führen. Aufgrund der individuellen Heterogenität erfüllt das Modell mit zufälligen Effekten allerdings die Annahme der Unkorreliertheit der Fehlerterme nicht. Selbst wenn

und

Konstanten sind und die idiosynkratischen Fehlerterme unkorreliert sind (, ), wird zwischen den zusammengesetzten Fehlertermen des gleichen Individuums für verschiedene Zeitpunkte eine Korrelation bestehen:



Aus diesem Grund wird die Varianz-Kovarianzmatrix eine -Diagonalmatrix sein, gegeben durch

- ,

wobei die einzelnen Diagonalelemente gegeben sind durch -Matrizen

- .

Die Matrix ist also keine Diagonalmatrix, sondern eine Blockdiagonalmatrix. Die besondere Struktur mit nur zwei Parametern ( und ) wird auch als RE-Struktur bezeichnet.[11]



Auf Basis dieses Modells können dann mehrere Schätzer hergeleitet werden, die konsistent und gegebenenfalls auch effizient sind.
Kleinste-Quadrate-Schätzung
Wie oben ausgeführt, sind im Modell mit zufälligen Effekten der zusammengesetzte Fehlerterm und die erklärenden Variablen unkorreliert, weswegen die Methode der Kleinsten Quadrate zu konsistenten Schätzungen führt. Im Zusammenhang mit Paneldaten wird die Kleinste-Quadrate-Schätzung (engl. ordinary least squares estimation, kurz OLSE) auch als gepoolte Kleinste-Quadrate-Schätzung (engl. pooled OLS) bezeichnet, weil die Paneldaten gepoolt (über beide Gruppen zusammengefasst) werden, d. h. die Zeitstruktur der Paneldaten außer Acht gelassen und das Modell anhand der gepoolten Daten mit der Kleinste-Quadrate-Schätzung geschätzt wird.[12]
Eine Matrix mit der RE-Struktur erfüllt allerdings die für den Satz von Gauß-Markow zentrale Annahme der Unkorreliertheit der Fehlerterme nicht, die eine diagonale Varianz-Kovarianzmatrix mit konstantem Diagonalelement erfordert. Die Kleinste-Quadrate-Schätzung ist im Modell mit zufälligen Effekten deswegen nicht notwendigerweise effizient. Darüber hinaus sind die Kleinste-Quadrate-geschätzten Standardfehler nicht korrekt, eben, weil dabei die Korrelation über Zeit ignoriert wird. Für Inferenz und Hypothesentests müssten die Standardfehler also angepasst werden.[13]
Schätzer für zufällige Effekte
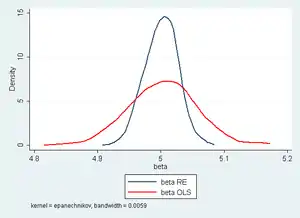
Der „Schätzer für zufällige Effekte“ („RE-Schätzer“) schafft an dieser Stelle Abhilfe. Konkret handelt es sich dabei um den auf das Modell mit zufälligen Effekten angewandten geschätzten verallgemeinerten KQ-Schätzer, kurz GVKQ-Schätzer. Angenommen, die Varianz-Kovarianzmatrix wäre bekannt. Dann könnte das Modell transformiert werden, indem es auf beiden Seiten mit multipliziert wird:


Setzt man nun , dann ist die Varianz-Kovarianzmatrix des Fehlerterms im solcherart transformierten Modell

- .

Da
- gilt, gilt folglich .


Wäre die Varianz-Kovarianzmatrix also bekannt, könnte das Modell durch sie so transformiert werden, dass das transformierte Modell die Einheitsmatrix als Varianz-Kovarianzmatrix hätte. Diese Einheitsmatrix würde die Annahmen des Satzes von Gauß-Markow erfüllen, der Schätzer wäre also effizient. Dieses hypothetische Modell, das sich nicht nur auf Modell mit zufälligen Effekten, sondern auf alle linearen Modelle mit Heteroskedastie und Autokorrelation anwenden lässt, ist als verallgemeinerte Kleinste-Quadrate-Schätzung, kurz VKQ (englisch Generalised Least Squares, kurz GLS) bekannt.[14] Im Modell mit zufälligen Effekten ist die genaue Varianz-Kovarianzmatrix allerdings unbekannt, die VKQ-Schätzung kann also nicht durchgeführt werden. Stattdessen kann aber die sogenannte geschätzte verallgemeinerte Kleinste-Quadrate-Schätzung (englisch Estimated Generalized Least Squares, kurz: EGLS) angewandt werden, eine zweistufige Prozedur.[15]
Hierbei wird das zugrundeliegende Modell zunächst mit einer Kleinste-Quadrate-Schätzung geschätzt, die, wie oben ausgeführt, zu konsistenten Schätzern führt. Auf Basis dieser Kleinste-Quadrate-Schätzung und ihrer Residuen können dann konsistente Schätzer und berechnet[16] und mit ihnen eine geschätzte Varianz-Kovarianzmatrix konstruiert werden. wird dann benutzt, um das zugrundeliegende Modell zu transformieren:



- .

Anschließend wird dieses transformierte Modell wieder mit der Kleinste-Quadrate-Schätzung geschätzt, woraus sich der GVKQ- bzw. Schätzer für zufällige Effekte ergibt:
- .[17]

Der Schätzer für zufällige Effekte als Mitglied der GVKQ-Familie weist auch die gleichen wünschenswerten Eigenschaften wie andere GVKQ-Schätzer auf: Er ist asymptotisch äquivalent zum VKQ-Schätzer und deswegen asymptotisch effizient.[18] Zur einfachen Implementierung des Schätzer für zufällige Effektes kann bei modernen Statistik-Programmen auf bereits programmierte Routinen zurückgegriffen werden.
Between-Schätzer
Ein weiterer konsistenter Schätzer im Modell mit zufälligen Effekten ist der sogenannte „Between-Schätzer“. Dabei wird durch Bildung von Mittelwerten eine Art Querschnittsstruktur erzeugt:
- ,

wobei alle Mittelwerte über die Zeit berechnet wurden, also zum Beispiel . Berechnet wird der Between-Schätzer dann durch eine Kleinste-Quadrate-Schätzung des in Mittelwerten ausgedrückten Modelles. Er ist konsistent, falls und der zusammengesetzte Fehlerterm unkorreliert sind. Im Modell mit zufälligen Effekten ist dies aufgrund der Orthogonalitätsannahme




der Fall und der Between-Schätzer folglich konsistent.[19]
Potentielle Probleme
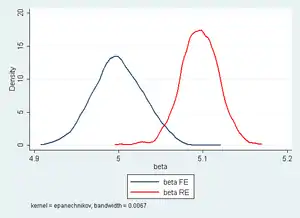
Die zentrale Annahme des Modells mit zufälligen Effekten ist, dass die unbeobachtete individuelle Heterogenität nicht mit den anderen erklärenden Variablen korreliert ist. Falls jedoch , so ist das Modell mit zufälligen Effekten nicht anwendbar, die zufälligen Effekte, Kleinste-Quadrate- und Between-Schätzer sind inkonsistent.

Modell mit festen Effekten
Grundlagen
Das Modell mit festen Effekten (auch Feste-Effekte-Modell, kurz FE-Modell) und darauf aufbauende Schätzer ermöglichen es, auch dann die Effekte der erklärenden Variablen konsistent zu schätzen, wenn die individuelle, zeitkonstante Heterogenität mit den erklärenden Variablen korreliert ist.
Schätzer für feste Effekte/Within-Schätzer
Die grundsätzliche Idee des Schätzers für feste Effekte ist es, die individuelle Heterogenität durch eine geeignete Transformation der Schätzgleichung aus dieser zu entfernen. Dabei wird zum einen die Panel- bzw. Mehrebenenstruktur der Daten ausgenutzt, zum anderen die Annahme, dass die individuelle Heterogenität fix, also eine für jedes Individuum spezifische Konstante ist.
Das zugrundeliegende Modell sei wiederum
- .

Weiterhin gelte die Annahme der strikten Exogenität in Bezug auf , d. h.
- .

Im Gegensatz zum Modell mit zufälligen Effekten kann jedoch sein. Trifft dies zu, so ist

und eine gewöhnliche Kleinste-Quadrate- oder RE-Schätzung wird in diesem Fall nicht konsistent sein.
Eine Abhilfe ist der sogenannte Schätzer für feste Effekte (manchmal auch Within Estimator genannt[20]). Die Idee hierbei ist, die über die Zeit konstante, individuums-spezifische Heterogenität dadurch zu eliminieren, dass von jeder Beobachtung der individuums-spezifische Durchschnitt über die Zeitperioden subtrahiert wird. Das zu schätzende Modell wird also zu

wobei (und analog für die anderen Variablen) gilt. Da gilt, fällt die individuumsspezifische Heterogenität (der „feste Effekt“) aus dem Modell heraus.[21] Der Schätzer für feste Effekte ergibt sich dann durch eine gewöhnliche Kleinste-Quadrate-Schätzung des transformierten Modelles. Der FE- oder Within-Schätzer ist konsistent: Da , ist im transformierten Modell , d. h. die Fehlerterme und ihre Zeitmittelwerte sind nicht mit den erklärenden Variablen und ihren Zeitmittelwerten korreliert. Unter der Annahme, dass die Fehlerterme für eine Beobachtungseinheit über die Zeit hinweg eine konstante Varianz haben und nicht miteinander korreliert sind, ist der Within-Schätzer auch effizient.[22]


Weiter kann gezeigt werden, dass der Within-Schätzer asymptotisch normalverteilt ist. Unter der Annahme von Homoskedastie und keiner Autokorrelation der Fehlerterme kann die asymptotische Varianz des Schätzers berechnet werden als

Dabei ist die Varianz des Fehlerterms u, . Zur Schätzung der Varianz wird dann lediglich noch ein konsistenter Schätzer der Fehlertermvarianz benötigt. Ein solcher ist gegeben durch



Falls von der Homoskedastie-Annahme abgewichen werden soll, kann die Varianz auch durch einen „robusten“ Schätzer geschätzt werden. Dieser ist im Falle des Within-Schätzers
- [23].

Auf Basis der geschätzten Varianz können dann Hypothesentests durchgeführt und Konfidenzintervalle berechnet werden.
Anstatt der geschilderten Transformation des Modells durch Subtraktion der individuellen Durchschnitte über die Zeit, können auch andere Schätzer verwendet werden. Der sogenannte Kleinste-Quadrate-Schätzer mit Dummyvariablen bzw. OLSDV-Schätzer (englisch OLSDV für ordinary least squares dummy variable) beispielsweise fügt den erklärenden Variablen des Modells noch Dummyvariablen für jede Beobachtungseinheit hinzu; anschließend wird eine gewöhnliche Kleinste-Quadrate-Schätzung dieses erweiterten Modells durchgeführt. Mithilfe des Frisch-Waugh-Lovell-Theorems lässt sich zeigen, dass die daraus resultierenden Schätzer für die -Koeffizienten identisch zu denen des Schätzer für feste Effektes sind. Darüber hinaus ergibt die LSDV-Regression auch Schätzungen für die individuellen Terme . Diese sind allerdings nur dann konsistent, wenn die Anzahl der Zeitperioden groß ist.[24]

Erste Differenzenschätzer
Eine weitere Möglichkeit, das Problem der individuellen Heterogenität mit Hilfe von Paneldaten-Methoden zu adressieren, ist die Differenzenbildung, die zum erste Differenzenschätzer führt. Dabei wird von jeder Beobachtung die zeitlich eine Periode vorhergehende Beobachtung abgezogen:
- .

Da die individuelle Heterogenität als über die Zeit konstant angenommen wird, fällt sie hierbei heraus, und das Modell in Differenzen kann durch eine Kleinste-Quadrate-Schätzung geschätzt werden. Falls angenommen wird, dass die Fehlerterme in der Regression homoskedastisch und über die Zeit unkorreliert sind, ist der Within-Schätzer (= Schätzer für feste Effekte) effizienter als der Erste Differenzenschätzer. Unter der schwächeren Annahme, dass die ersten Differenzen der Fehlerterme über die Zeit unkorreliert sind, ist dagegen der Erste Differenzenschätzer effizienter.[25]
Potenzielle Probleme
Ein weit verbreitetes Problem bei der Anwendung von Schätzern im Modell mit festen Effekten besteht, falls die zugrundeliegenden Daten mit einem Messfehler erhoben wurden. Fehlerbehaftete Datenerhebungen sind auch in normalen Kleinste-Quadrate-Schätzungen auf Basis von Querschnittsdaten ein Problem, das zu inkonsistenter Schätzung führen kann. Die dem Within-Schätzer zugrundeliegende Transformation kann diese Fehlerbehaftung noch verstärken.[26] Als Beispiel hierfür kann eine Studie des amerikanischen Ökonomen Richard B. Freeman aus dem Jahr 1984 genannt werden. Zu dieser Zeit wurden Schätzungen der festen Effekte oft verwendet, um den kausalen Effekt einer Gewerkschaftsmitgliedschaft auf den Verdienst eines Arbeitnehmers zu schätzen. Die zugrundeliegende Argumentation war, dass Arbeitnehmer, die einer Gewerkschaft beitreten, sich auch in anderen, unbeobachtbaren Eigenschaften von den Arbeitnehmern unterscheiden, die nicht Mitglied einer Gewerkschaft sind. Aufgrund dieser vermuteten systematischen Unterschiede boten sich Paneldaten und Schätzer für feste Effekte geradezu an. Freemans Ergebnisse zeigten jedoch, dass die Ergebnisse der festen Effekte aufgrund von fehlerbehafteten Datenerhebungen nach unten verzerrt sind, während gewöhnliche Kleinste-Quadrate-Schätzungen auf Basis von Querschnittsdaten nach oben verzerrt sind; beide Techniken ermöglichen in diesem Fall also keine konsistente Schätzung, jedoch können die Ergebnisse der festen Effekte als untere Grenze, die Kleinste-Quadrate-Ergebnisse als obere Grenze für den zugrundeliegenden Effekt angesehen werden.[27]
Eine mögliche Abhilfe für Probleme aufgrund von fehlerbehafteten Datenerhebungen ist das Anwenden einer Instrumentvariablenstrategie.[28] Wenn es zum Beispiel zwei Messungen einer Variablen gibt, kann eine hiervon als Instrument für die zweite Messung verwendet werden, was dann eine konsistente Schätzung des Effektes der doppelt gemessenen Variablen erlaubt.[29]
Ein weiteres Problem ist, dass die Berechnung auf Basis von Abweichungen vom Mittelwert nicht nur die unbeobachtbare individuelle Heterogenität bereinigt, sondern auch einen Teil der Variation in den erklärenden Variablen entfernt – es wird also sowohl „gute“ als auch „schlechte“ Variation aus dem Modell entfernt.[30] Am deutlichsten wird dies bei erklärenden Variablen, die über die Zeit konstant sind: Diese werden vom Within-Schätzer und dem Differenzen-Schätzer gänzlich aus der Schätzgleichung entfernt.[31] Dies ist auch ein Problem für das eingangs erwähnte Beispiel der Regression von Einkommen auf Bildung: Die vor dem Berufsleben erworbene Bildung ist aus späterer Sicht eine Konstante, die verbliebene Variation im Modell beruht also vor allem auf später erworbenen Abschlüssen. Die Anwendbarkeit von Schätzer für feste Effekte auf dieses Modell wurde deswegen bereits in den 1980er Jahren bestritten.[32] In einer Arbeit aus dem Jahr 1981 haben Jerry Hausman und William E. Taylor einen Weg aufgezeigt, wie unter zusätzlichen Annahmen an die Daten auch im feste Effekte Kalkül Koeffizienten für über die Zeit konstante Variablen geschätzt werden können.[33]
Vergleich beider Modelle
Die Entscheidung, ob und welcher Schätzer des Modells mit zufälligen effekten oder des Modells mit festen Effekten angewandt werden soll, hängt von der Natur des zu Grunde liegenden Modells ab. Falls das zu Grunde liegende Modell die Feste-Effekte-Struktur (also eine Korrelation zwischen individueller Heterogenität und erklärenden Variablen) aufweist, so ist der Within-Schätzer konsistent und der Schätzer für zufällige Effekte inkonsistent. Besteht dagegen eine RE-Struktur, so sind sowohl der Within-Schätzer als auch Schätzer für zufällige Effekte konsistent, aber der Schätzer für zufällige Effekte ist effizienter, hat also eine kleinere Varianz und erlaubt damit eine genauere Schätzung. Für die Entscheidung, welches Modell vorliegt, besteht die Möglichkeit der Durchführung des Hausman-Spezifikationstests. Dabei werden die Unterschiede zwischen den beiden Schätzern verglichen; fallen diese statistisch betrachtet groß aus, so wird dies als Anzeichen für das Vorliegen eines Modell mit festen Effekten angesehen.[34]
Modelle mit zufälligen Effekten können auch verwendet werden, um Within-Schätzer für zeitveränderliche Variablen zu erhalten, indem die Between-Schätzer der Variablen in das Modell aufgenommen werden.[35][36][37] Dadurch ist es möglich, zufällige Effekte zeitkonstanter Variablen und feste Effekte zeitveränderlicher Variablen in einem Modell zu schätzen. Dieses Modell wird auch als „mixed-effects model“ oder „hybrid model“ bezeichnet.
Lineare Panelmodelle stoßen außerdem an ihre Grenzen, wenn die erklärte Variable in zeitverzögerter Form zugleich erklärende Variable ist, zum Beispiel als

In einem solchen Modell sind mit den herkömmlichen Schätzern auf Basis Linearer Panelmodelle keine konsistenten Schätzungen möglich.[38] In solchen Fällen muss deswegen auf Dynamische Paneldatenmodelle zurückgegriffen werden. Schätzmethoden sind hier der dem feste Effekte Kalkül nahe Arellano-Bond-Schätzer (nach Manuel Arellano und Stephen Bond) und der dem zufällige Effekte Kalkül ähnliche Bhargava-Sargan-Schätzer (nach Alok Bhargava und John Denis Sargan).
Literatur
- Joshua D. Angrist und Jörn-Steffen Pischke: Mostly Harmless Econometrics: An Empiricist's Companion, Princeton University Press, 2008
- Badi. H. Baltagi: Econometric Analysis of Panel Data. 5. Auflage. John Wiley & Sons, 2013.
- A. Colin Cameron und Pravin K. Trivedi: Microeconometrics - Methods and Applications, Cambridge University Press, 2005, ISBN 0521848059, insb. Kapitel 21
- Jeffrey M. Wooldridge: Econometric Analysis of Cross Section and Panel Data: Second Edition, Cambridge: MIT Press, 2002, insb. Kapitel 10
- STATA-FAQ: What is the between estimator?. Abgerufen am 5. Oktober 2011.
- STATA-FAQ: Fixed-, between-, and random-effects and xtreg. Abgerufen am 5. Oktober 2011.
- Ludwig Fahrmeir, Thomas Kneib, Stefan Lang: Regression: Modelle, Methoden und Anwendungen. 2. Auflage. Springer Verlag, 2009, ISBN 978-3-642-01836-7.
Anmerkungen
- Ludwig Fahrmeir, Thomas Kneib, Stefan Lang: Regression: Modelle, Methoden und Anwendungen., Springer Verlag 2009, S. 253
- Ludwig Fahrmeir, Thomas Kneib, Stefan Lang: Regression: Modelle, Methoden und Anwendungen., Springer Verlag 2009, S. 253
- Für einen Überblick hierzu, siehe unter anderem David Card: Estimating the Return to Schooling: Progress on Some Persistent Econometric Problems, Econometrica, 69.5, September 2001, S. 1127–1160
- Wooldridge, Econometric Analysis of Cross Section and Panel Data, 2002, S. 251
- Denkbar wäre auch, als dritten unbeobachteten Term einen zwischen Personen konstanten, aber sich über die Zeit ändernden Term anzunehmen, der für unbeobachtete Variablen steht, die sich über die Zeit ändern, aber alle Individuen gleich betreffen, zum Beispiel die konjunkturelle Entwicklung.
- Siehe hierzu zum Beispiel Joshua D. Angrist und Whitney K. Newey: Over-Identification Tests in Earnings Functions with Fixed Effects, Journal of Business and Economic Statistics 9.3, S. 321
- Cameron & Trivedi, Microeconometrics, 2005, S. 700
- Wooldridge, Econometric Analysis of Cross Section and Panel Data, 2002, S. 257
- Wooldridge, Econometric Analysis of Cross Section and Panel Data, 2002, S. 258
- Wooldridge, Econometric Analysis of Cross Section and Panel Data, 2002, S. 258f.
- Wooldridge, Econometric Analysis of Cross Section and Panel Data, 2002, S. 259
- Cameron & Trivedi, Microeconometrics, 2005, S. 702
- Cameron & Trivedi, 2005, Microeconometrics, S. 703
- Für weitere Details, siehe Cameron & Trivedi, Microeconometrics, 2005, S. 82
- Ludwig von Auer: Ökonometrie. Eine Einführung. Springer, ISBN 978-3-642-40209-8, 6., durchges. u. aktualisierte Auflage. 2013, S. 408.
- Für die genaue Berechnung siehe Wooldridge, Econometric Analysis of Cross Section and Panel Data, 2002, S. 260f.
- Cameron & Trivedi, Microeconometrics, 2005, S. 81f.
- Wooldridge, Econometric Analysis of Cross Section and Panel Data, 2002, S. 260
- Cameron & Trivedi, Microeconometrics, 2005, S. 703
- Cameron & Trivedi, Microeconometrics, 2005, S. 726
- Cameron & Trivedi, Microeconometrics, 2005, S. 726
- Wooldridge, Econometric Analysis of Cross Section and Panel Data, 2002, S. 269f.
- Cameron & Trivedi, Microeconometrics, 2005, S. 727
- Cameron & Trivedi, Microeconometrics, 2005, S. 732f.
- Wooldridge, Econometric Analysis of Cross Section and Panel Data, 2002, S. 279–281
- Angrist & Pischke, Mostly Harmless Econometrics, 2009, S. 225
- Richard B. Freeman: Longitudinal Analyses of the Effects of Trade Unions, Journal of Labor Economics, 2.1, Januar 1984, S. 1–26
- Angrist & Pischke, Mostly Harmless Econometrics, 2009, S. 226f.
- Für Beispiele hiefür siehe zum Beispiel Orley Ashenfelter & Alan B. Krueger: Estimates of the Economic Returns to Schooling from a New Sample of Twins, American Economic Review, 84.5, 1994, S. 1157–1173 oder Andreas Ammermüller & Jörn-Steffen Pischke: Peer Effects in European Primary Schools: Evidence from the Progress in International Reading Literacy Study, Journal of Labor Economics, 27.3, 2009, S. 315–348
- Angrist & Pischke, Mostly Harmless Econometrics, 2009, S. 226
- Wooldridge, Econometric Analysis of Cross Section and Panel Data, 2002, S. 266
- siehe zum Beispiel Jerry A. Hausman und William E. Taylor, Panel Data and Unobservable Individual Effects, Econometrica, 49.6, 1981, S. 1377f.; Angrist & Newey, Over-Identification Tests in Earnings Functions with Fixed Effects, Journal of Business and Economic Statistics 9.3, dagegen argumentieren, dass auch die nachschulische Bildung erwachsener Männer in den USA noch einige Varianz aufweist und deswegen als zeitvariant aufgefasst werden kann.
- Siehe hierzu Jerry A. Hausman und William E. Taylor, Panel Data and Unobservable Individual Effects, Econometrica 49.6, 1981, S. 1377–1398
- Wooldridge, Econometric Analysis of Cross Section and Panel Data, 2002, S. 288
- Paul D. Allison: Fixed effects regression models. SAGE Publications, Thousand Oaks 2009, ISBN 978-0-7619-2497-5.
- Hans-Jürgen Andreß, Katrin Golsch, Alexander Schmidt: Applied Panel Data Analysis for Economic and Social Surveys. Springer-Verlag, Heidelberg / New York / Dordrecht / London 2003, ISBN 978-3-642-32913-5, S. 164–166.
- Daniel McNeish, Ken Kelley: Fixed Effects Models Versus Mixed Effects Models for Clustered Data:Reviewing the Approaches. Disentangling the Differences,and Making Recommendations. In: Psychological Methods. Band 24, Nr. 1, 2018, S. 20–35, doi:10.1037/met0000182.
- Für das Beispiel des Within-Schätzers, siehe Cameron & Trivedi, Microeconometrics, 2005, S. 763f.
