Diskriminanzanalyse
Die Diskriminanzanalyse ist eine Methode der multivariaten Verfahren in der Statistik und dient der Unterscheidung von zwei oder mehreren Gruppen, die mit mehreren Merkmalen (auch Variablen) beschrieben werden. Dabei kann sie Gruppen auf signifikante Unterscheidungen ihrer Merkmale prüfen und dafür geeignete oder ungeeignete Merkmale benennen.[1] Sie wurde 1936 von R. A. Fisher zum ersten Mal in The use of multiple measurements in taxonomic problems[2] beschrieben.
Eingesetzt wird die Diskriminanzanalyse in der Statistik und im Maschinellen Lernen, um durch Raumtransformation eine gute Darstellung von Merkmalen zu erreichen, und dient als Klassifikator (Diskriminanzfunktion) oder zur Dimensionsreduzierung. Die Diskriminanzanalyse ist verwandt mit der Hauptkomponentenanalyse (PCA), welche ebenfalls eine gute Darstellungsmöglichkeit finden soll, beachtet aber im Gegensatz zu dieser die Klassenzugehörigkeit der Daten.
Problemstellung
Wir betrachten Objekte, die jeweils genau einer von mehreren gleichartigen Klassen angehören. Es ist bekannt, welcher Klasse jedes einzelne Objekt angehört. An jedem Objekt werden Ausprägungen von Merkmalen beobachtet. Aus diesen Informationen sollen lineare Grenzen zwischen den Klassen gefunden werden, um später Objekte, deren Klassenzugehörigkeit unbekannt ist, einer der Klassen zuordnen zu können. Die lineare Diskriminanzanalyse ist also ein Klassifikationsverfahren.
Beispiele:
- Kreditnehmer können z. B. in kreditwürdig und nicht kreditwürdig eingeteilt werden. Wenn ein Bankkunde einen Kredit beantragt, versucht das Institut anhand von Merkmalen wie Höhe des Einkommens, Zahl der Kreditkarten, Beschäftigungsdauer bei der letzten Arbeitsstelle etc., auf die zukünftige Zahlungsfähigkeit und -willigkeit des Kunden zu schließen.
- Kunden einer Supermarktkette können als Markenkäufer und Noname-Käufer klassifiziert werden. In Frage kommende Merkmale wären etwa die jährlichen Gesamtausgaben in diesen Läden, der Anteil von Markenprodukten an den Ausgaben etc.
An diesem Objekt kann mindestens ein statistisches metrisch skaliertes Merkmal beobachtet werden. Dieses Merkmal wird im Modell der Diskriminanzanalyse als eine Zufallsvariable interpretiert. Es gibt mindestens zwei verschiedene Gruppen (Populationen, Grundgesamtheiten). Aus einer dieser Grundgesamtheiten stammt das Objekt. Mittels einer Zuordnungsregel, der Klassifikationsregel, wird das Objekt einer dieser Grundgesamtheiten zugeordnet. Die Klassifikationsregel kann oft durch eine Diskriminanzfunktion angegeben werden.

Klassifikation bei bekannten Verteilungsparametern
Für das bessere Verständnis wird die Vorgehensweise anhand von Beispielen erläutert.
Maximum-Likelihood-Methode
Eine Methode der Zuordnung ist die Maximum-Likelihood-Methode: Man ordnet das Objekt der Gruppe zu, deren Likelihood am größten ist.
Beispiel
Eine Gärtnerei hat die Möglichkeit, eine größere Menge Samen einer bestimmten Sorte Nelken günstig zu erwerben. Um den Verdacht auszuräumen, dass es sich dabei um alte, überlagerte Samen handelt, wird eine Keimprobe gemacht. Man sät also 1 g Samen aus und zählt, wie viele dieser Samen keimen. Aus Erfahrung ist bekannt, dass die Zahl der keimenden Samen pro 1 g Saatgut annähernd normalverteilt ist. Bei frischem Saatgut (Population I) keimen im Durchschnitt 80 Samen, bei altem (Population II) sind es nur 40 Samen.
- Population I: Die Zahl der frischen Samen, die keimen, ist verteilt als
- Population II: Die Zahl der alten Samen, die keimen, ist verteilt als


Die Keimprobe hat nun

ergeben. Die Grafik zeigt, dass bei dieser Probe die Likelihood der Population I am größten ist. Man ordnet also diese Keimprobe als frisch ein.
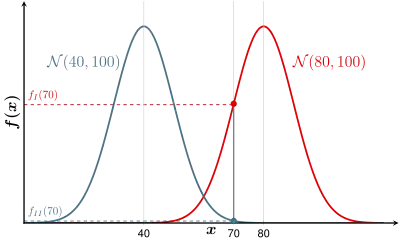
Aus der Grafik ersieht man, dass man als Klassifikationsregel (Entscheidungsregel) auch angeben kann:
- Ordne das Objekt der Population I zu, wenn der Abstand von zum Erwartungswert am kleinsten ist, bzw. wenn
- ist.



Der Schnittpunkt der Verteilungsdichten (bei ) entspricht so der Entscheidungsgrenze.

Gleiche Varianzen
Die Merkmale der beiden Gruppen sollten die gleiche Varianz haben. Bei verschiedenen Varianzen ergeben sich mehrere Zuordnungsmöglichkeiten.
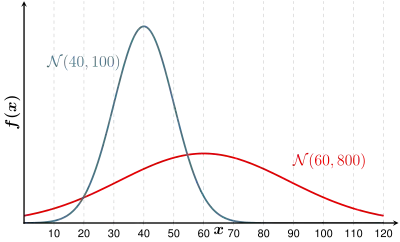
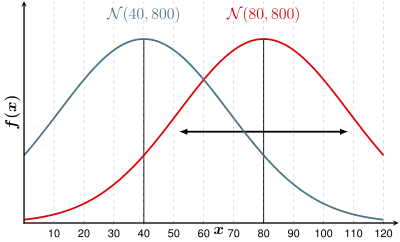
In der obigen Grafik sind zwei Gruppen mit verschiedenen Varianzen gezeigt. Die flache Normalverteilung hat eine größere Varianz als die schmale, hohe. Man erkennt, wie die Varianz der Gruppe I die Normalverteilung der Gruppe II „unterläuft“. Wenn nun in der Stichprobe beispielsweise resultierte, müsste man die Samen als frisch einordnen, da die Wahrscheinlichkeitsdichte für Gruppe I größer ist als für Gruppe II.

Im „Standardmodell“ der Diskriminanzanalyse wird von gleichen Varianzen und Kovarianzen ausgegangen.
Große Intergruppenvarianz
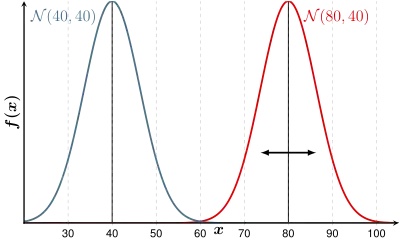
Die Varianz zwischen den Gruppenmittelwerten, die Intergruppenvarianz, sollte groß sein, weil sich dann die Verteilungen nicht durchmischen: Die Trennung der Gruppen ist schärfer.
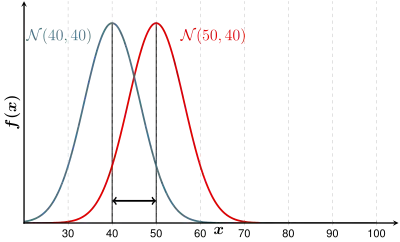 |
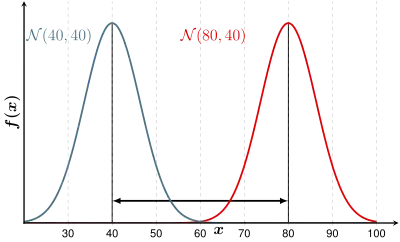 |
| Schlechter: Kleine Varianz zwischen den Gruppen | Besser: Große Varianz zwischen den Gruppen |
|---|
Kleine Intragruppenvarianz
Die Varianz innerhalb einer Gruppe, die Intragruppenvarianz, sollte möglichst klein sein, dann durchmischen sich die Verteilungen nicht, die Trennung ist besser.
 |
 |
| Schlechter: Große Varianz in einer Gruppe | Besser: Kleine Varianz in einer Gruppe |
|---|
Mehrere Merkmale – Zwei Gruppen – Gleiche Kovarianzmatrizen
Das interessierende Objekt kann mehrere zu beobachtende Merkmale aufweisen. Man erhält hier als modellhafte Verteilungsstruktur einen Zufallsvektor . Dieser Vektor ist verteilt mit dem Erwartungswertvektor und der Kovarianzmatrix . Die konkrete Realisierung ist der Merkmalsvektor , dessen Komponenten die einzelnen Merkmale enthalten.




Bei zwei Gruppen ordnet man analog zu oben das beobachtete Objekt der Gruppe zu, bei der die Distanz des Merkmalsvektors zu dem Erwartungswertvektor minimal wird. Verwendet wird hier, teilweise etwas umgeformt, die Mahalanobis-Distanz als Distanzmaß.
Beispiel
In einem großen Freizeitpark wird das Ausgabeverhalten von Besuchern ermittelt. Insbesondere interessiert man sich dafür, ob die Besucher in einem parkeigenen Hotel nächtigen werden. Jeder Familie entstehen bis 16 Uhr Gesamtausgaben (Merkmal ) und Ausgaben für Souvenirs (Merkmal ). Die Marketingleitung weiß aus langjähriger Erfahrung, dass die entsprechenden Zufallsvariablen und gemeinsam annähernd normalverteilt sind mit den Varianzen 25 [€2] und der Kovarianz [€2]. Bezüglich der Hotelbuchungen lassen sich die Konsumenten in ihrem Ausgabeverhalten in zwei Gruppen I und II einteilen, so dass die bekannten Verteilungsparameter in der folgenden Tabelle aufgeführt werden können:





| Gruppe | Gesamtausgabe | Ausgaben für Souvenirs | |
|---|---|---|---|
| Erwartungswert | Erwartungswert | Varianzen von und | |
| Hotelbucher I | 70 | 40 | 25 |
| Keine Hotelbucher II | 60 | 20 | 25 |


Für die Gruppe I ist also der Zufallsvektor multivariat normalverteilt mit dem Erwartungswertvektor

und der Kovarianzmatrix

Für die Gruppe II gilt Entsprechendes.
Die Grundgesamtheiten der beiden Gruppen sind in der folgenden Grafik als dichte Punktwolken angedeutet. Die Ausgaben für Souvenirs werden als Luxusausgaben bezeichnet. Der rosa Punkt steht für die Erwartungswerte der ersten Gruppe, der hellblaue für die Gruppe II.
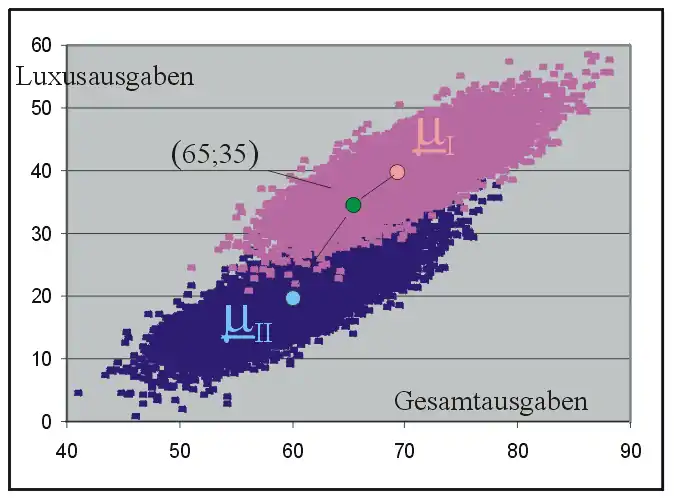
Eine weitere Familie hat den Freizeitpark besucht. Sie hat bis 16 Uhr insgesamt 65 € ausgegeben und für Souvenirs 35 € (grüner Punkt in der Grafik). Soll man für diese Familie ein Hotelzimmer bereithalten?
Ein Blick auf die Grafik lässt schon erahnen, dass der Abstand des grünen Punktes zum Erwartungswertvektor der Gruppe I minimal ist. Deshalb vermutet die Hotelverwaltung, dass die Familie ein Zimmer nehmen wird.
Für die Mahalanobis-Distanz

des Merkmalsvektors zum Zentrum der Gruppe I errechnet man

und von zum Zentrum der Gruppe II

Mehrere Merkmale – Mehrere Gruppen – Gleiche Kovarianzmatrizen
Es können der Analyse mehr als zwei Populationen zu Grunde liegen. Auch hier ordnet man analog zu oben das Objekt der Population zu, bei der die Mahalanobis-Distanz des Merkmalsvektors zu dem Erwartungswertvektor minimal wird.
(Fishersche) Diskriminanzfunktion
In der Praxis ist es umständlich, bei jedem zu klassifizierenden Merkmal die Mahalanobis-Distanz zu ermitteln. Einfacher ist die Zuordnung mittels einer linearen Diskriminanzfunktion. Ausgehend von der Entscheidungsregel
- „Ordne das Objekt der Gruppe I zu, wenn die Distanz des Objektes zur Gruppe I kleiner ist“:

resultiert durch Umformen dieser Ungleichung die Entscheidungsregel mit Hilfe der Diskriminanzfunktion :

- „Ordne das Objekt der Gruppe I zu, wenn gilt“:
- .

Die Diskriminanzfunktion errechnet sich im Fall zweier Gruppen und gleicher Kovarianzmatrizen als

Die Diskriminanzfunktion resultiert auch als empirischer Ansatz, wenn man die Varianz zwischen den Gruppen maximiert und die Varianz innerhalb der Gruppen minimiert. Dieser Ansatz heißt Fisher'sche Diskriminanzfunktion, weil sie von R.A. Fisher 1936 vorgestellt worden ist.
Bayessche Diskriminanzanalyse
Bisher wurde von der Annahme ausgegangen, dass die Gruppen in der Grundgesamtheit gleich groß sind. Dies ist aber nicht der Regelfall. Man kann die Zugehörigkeit zu einer Gruppe auch als zufällig betrachten. Die Wahrscheinlichkeit, mit der ein Objekt Gruppe angehört, wird als A-priori-Wahrscheinlichkeit bezeichnet. Bei Gruppen beruht die lineare Diskriminanzregel auf der Annahme, dass in Gruppe multivariat normalverteilt ist mit Erwartungswert und Kovarianzmatrix , die in allen Gruppen gleich ist, d. h. . Die Bayes-Regel für die lineare Diskriminanzanalyse (LDA) lautet dann






wobei die Kosten bezeichnen, die entstehen, wenn ein Objekt, das zu Gruppe i gehört, irrtümlicherweise zu Gruppe j zugeordnet wird.

Nimmt man im obigen Modell nicht an, dass die Kovarianzmatrizen in den Gruppen identisch sind, sondern dass sie sich unterscheiden können, d. h. , so lautet die Bayes-Regel für die quadratische Diskriminanzanalyse (QDA)


Die Grenzen bei Durchführung der linearen Diskriminanzanalyse sind linear in , bei der quadratischen quadratisch.
Siehe auch: Bayes-Klassifikator
Klassifikation bei unbekannten Verteilungsparametern
Meistens werden die Verteilungen der zu Grunde liegenden Merkmale unbekannt sein. Sie müssen also geschätzt werden. Man entnimmt beiden Gruppen eine so genannte Lernstichprobe im Umfang bzw. . Mit diesen Daten werden die Erwartungswertvektoren und die Kovarianzmatrix geschätzt. Analog zum oberen Fall verwendet man die Mahalanobisdistanz oder die Diskriminanzfunktion, mit den geschätzten anstelle der wahren Parameter.




Geht man von dem Standardmodell mit gruppengleichen Kovarianzmatrizen aus, muss erst mit Hilfe des Boxschen M-Tests die Gleichheit der Kovarianzmatrizen bestätigt werden.
Beispiel
Freizeitpark-Beispiel von oben:
Die Grundgesamtheit ist nun unbekannt. Es wurden in jeder Gruppe je 16 Familien näher untersucht. Es ergaben sich in der Stichprobe die folgenden Werte:
| Ausgaben von Familien in einem Freizeitpark | |||||
|---|---|---|---|---|---|
| Gruppe 1 | Gruppe 2 | ||||
| Gesamt | Souvenirs | Gruppe | Gesamt | Souvenirs | Gruppe |
| 64,78 | 37,08 | 1 | 54,78 | 17,08 | 2 |
| 67,12 | 38,44 | 1 | 57,12 | 18,44 | 2 |
| 71,58 | 44,08 | 1 | 61,58 | 24,08 | 2 |
| 63,66 | 37,40 | 1 | 53,66 | 17,40 | 2 |
| 53,80 | 19,00 | 1 | 43,80 | 7,99 | 2 |
| 73,21 | 41,17 | 1 | 63,21 | 29,10 | 2 |
| 63,95 | 31,40 | 1 | 53,95 | 11,40 | 2 |
| 78,33 | 45,92 | 1 | 68,33 | 34,98 | 2 |
| 72,36 | 38,09 | 1 | 62,36 | 18,09 | 2 |
| 64,51 | 34,10 | 1 | 54,51 | 14,10 | 2 |
| 66,11 | 34,97 | 1 | 56,11 | 14,97 | 2 |
| 66,97 | 36,90 | 1 | 56,97 | 16,90 | 2 |
| 69,72 | 41,24 | 1 | 59,72 | 21,24 | 2 |
| 64,47 | 33,81 | 1 | 54,47 | 13,81 | 2 |
| 72,60 | 19,05 | 1 | 62,60 | 30,02 | 2 |
| 72,69 | 39,88 | 1 | 62,69 | 19,88 | 2 |
Die Mittelwerte für jede Gruppe, der Gesamtmittelwert, die Kovarianzmatrizen und die gepoolte (vereinte) Kovarianz errechneten sich wie folgt:
| Variable | Pooled Mean | Means for | |
|---|---|---|---|
| Group 1 | Group 2 | ||
| Gesamt | 62,867 | 67,867 | 57,867 |
| Souvenir | 27,562 | 35,783 | 19,342 |
| Pooled Covariance Matrix | ||
|---|---|---|
| Gesamt | Souvenir | |
| Gesamt | 32,59 | |
| Souvenir | 30,58 | 54,01 |
| Covariance Matrix for Group 1 | ||
|---|---|---|
| Gesamt | Souvenir | |
| Gesamt | 32,59 | |
| Souvenir | 25,34 | 56,90 |
| Covariance Matrix for Group 2 | ||
|---|---|---|
| Gesamt | Souvenir | |
| Gesamt | 32,59 | |
| Souvenir | 35,82 | 51,11 |
Daraus erhält man nach obiger Formel die Diskriminanzfunktion
- .

Die Klassifikationsregel lautet jetzt:
- Ordne das Objekt der Gruppe I zu, wenn
- ist.
Um die Güte des Modells zu überprüfen, kann man die Stichprobenwerte klassifizieren. Es ergibt sich hier die Klassifikationsmatrix
| Gruppe | Richtig zugeordnet | falsch zugeordnet |
| I | 14 | 2 |
| II | 13 | 3 |
Nun soll wieder die Familie mit den Beobachtungen eingeordnet werden.

Die folgende Grafik zeigt das Streudiagramm der Lernstichprobe mit den Gruppenmittelwerten. Der grüne Punkt ist die Lokalisation des Objekts .
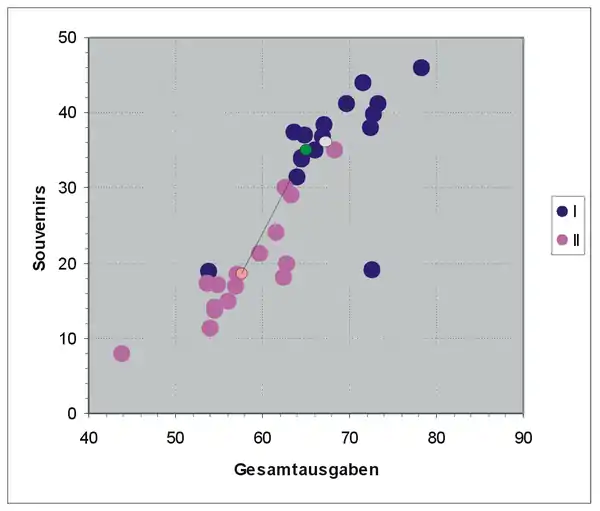
Schon aus der Grafik ist zu erkennen, dass dieses Objekt zu Gruppe I gehört. Die Diskriminanzfunktion ergibt

Da
ist, ordnet man das Objekt der Gruppe I zu.
Weitere Stichworte
- Wilks Lambda
- Flexible Diskriminanzanalyse
- Kerndichteschätzer
- Support Vector Machine
Literatur
- Maurice M. Tatsuoka: Multivariate Analysis: Techniques for Educational and psychological Research. John Wiley & Sons, Inc., New York, 1971, ISBN 0-471-84590-6
- K. V. Mardia, J. T. Kent, J. M. Bibby: Multivariate Analysis. New York, 1979
- Ludwig Fahrmeir, Alfred Hamerle, Gerhard Tutz (Hrsg.): Multivariate statistische Verfahren. New York, 1996
- Joachim Hartung, Bärbel Elpelt: Multivariate Statistik. München, Wien, 1999
- Backhaus, Klaus; Erichson, Bernd; Plinke, Wulff u. a.: Multivariate Analysemethoden.
Einzelnachweise
- Klaus Backhaus, SpringerLink (Online service): Multivariate Analysemethoden eine anwendungsorientierte Einführung. Springer, Berlin 2006, ISBN 978-3-540-29932-5.
- R.A. Fisher (1936), The use of multiple measurements in taxonomic problems, Annals Eugen., Vol. 7, pp. 179–188, doi:10.1111/j.1469-1809.1936.tb02137.x