Von-Neumann-Zyklus
Der Von-Neumann-Zyklus bezeichnet in der Technischen Informatik einen Prozess bei der Befehlsverarbeitung in einem klassischen Von-Neumann-Rechner.
Moderne Mikroprozessoren verwenden heutzutage jedoch getrennte Caches für Daten und Befehle und können deshalb als modifizierte Harvard-Prozessoren oder als Fast-Von-Neumann-Prozessoren bezeichnet werden, weshalb sie intern kaum noch etwas mit dem klassischen Von-Neumann-Zyklus gemein haben.
Die Teilschritte
Der Zyklus besteht aus fünf Teilschritten
- FETCH – Befehlsabruf: Aus dem Speicher wird der nächste zu bearbeitende Befehl entsprechend der Adresse im Befehlszähler in das Befehlsregister geladen und der Befehlszähler wird um die Länge des Befehls erhöht.
- DECODE – Dekodierung: Der Befehl wird durch das Steuerwerk in Schaltinstruktionen für das Rechenwerk aufgelöst.
- FETCH OPERANDS – Operandenabruf: Aus dem Speicher werden nun die Operanden geholt. Das sind die Werte, die durch den Befehl verändert werden sollen oder die als Parameter verwendet werden.
- EXECUTE – Befehlsausführung: Eine arithmetische oder logische Operation wird vom Rechenwerk ausgeführt. Bei Sprungbefehlen und erfüllter Sprungbedingung wird an dieser Stelle der Befehlszähler verändert.
- WRITE BACK – Rückschreiben des Resultats: Sofern notwendig, wird das Ergebnis der Berechnung in den Speicher zurückgeschrieben.
Die letzten drei Phasen des Von-Neumann-Zyklus müssen nicht bei jeder Befehlsart alle ausgeführt werden. Viele arithmetisch-logische Befehle der aktuellen CPUs schreiben tatsächlich ihr Ergebnis nicht in den Hauptspeicher (HS) zurück. Das macht später ein getrennter Speicherbefehl, bei dem nur die WriteBack-Phase interessiert und deshalb der Operandenabruf fehlt und die Executephase „verkümmert“ ist. Andererseits wird bei Mehradressmaschinen das Ergebnis normalerweise sofort in den HS geschrieben. Aber auch alle modernen Prozessoren besitzen Befehle, die ihr Ergebnis sofort wieder in den HS schreiben, beispielsweise der auf einen Speicherplatz bezogene Inkrement-Befehl oder der Exchange-Befehl. Das ist weder selten noch wird dafür spezielle Hardware benötigt. Um eine zusätzliche Adressangabe im Befehl zu sparen, wird das Resultat auf den gleichen Platz eines Operanden „zurückgeschrieben“ (write back).
Dabei kann ein Teilschritt mehrere Takte dauern. Nach dem Beenden des Zyklus beginnt dieser wieder von vorn und ein weiterer Befehl wird abgearbeitet. Es ist zu beachten, dass die letzten drei Phasen des Zyklus nicht bei jeder Befehlsart alle ausgeführt werden müssen. Beispielsweise schreiben viele arithmetisch-logischen Befehle der aktuellen CPUs ihr Ergebnis nicht sofort in den Hauptspeicher zurück. Das macht später ein getrennter Speicherbefehl, bei dem nur die WriteBack-Phase durchlaufen wird.
Moderne Zentralprozessoren haben Taktfrequenzen von 2 bis 5 GHz. Pro Takt werden bei aktuellen Prozessoren
- mehrere dieser oben genannten Teilschritte parallel (gleichzeitig) durch so genanntes Pipelining ausgeführt,
- jeder Teilschritt wird im Allgemeinen pro Takt auch noch mehrfach ausgeführt. Bei der Befehlsausführung nennt man das Ports. Beispielsweise kann die Haswell-CPU bis zu 8 neue Befehle pro Takt neu anfangen, deren Ausführungszeit meist zwischen 1 und 5 Takten liegen, so dass sich bis zu 40 Maschinenanweisungen in der EXECUTE-Phase befinden können.
Als weitere leistungssteigernde Merkmale kommen hinzu:
- SIMD-Befehle
- Mehrere Kerne
Das führt dazu, dass aktuelle Prozessoren in Mainstream-PCs bis zu 2000 arithmetische Befehle parallel ausführen können. Diese Werte sind praktisch unerreichbar.
FETCH
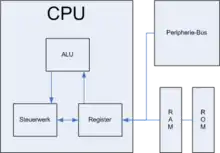
In das Befehlsregister, das zusammen mit Steuer- und Rechenwerk (arithmetisch-logische Einheit, ALU) den Hauptprozessor (CPU) darstellt, wird aus RAM- oder ROM-Speicher der nächste zu bearbeitende Befehl geladen. Anschließend wird der Befehlszähler (der Instruction Pointer) erhöht, so dass er auf die nächste Speicherstelle zeigt. Diese Erhöhung ist schon hier notwendig, damit ein Sprungbefehl mit „Rückkehrabsicht“ (Unterprogrammsprung) die Adresse des Folgebefehls vor dem Sprung sichern kann.
Prozessoren können oft mehrere Befehle aus dem Speicher in einen Zwischenspeicher (Prefetch-Registerblock) laden, während der aktuelle Befehl noch ausgeführt wird. Dieses Verfahren wird als OpCode Prefetching (dt. Operationscode-Vorabruf) bezeichnet.
- Vorteil: Deutliche Steigerung der Verarbeitungsgeschwindigkeit weil die Wirkung des Von-Neumann-Flaschenhalses reduziert wird.
- Nachteil: Bei Programmverzweigungen müssen die „unnütz“ geladenen Befehle evtl. wieder verworfen werden.