Very Long Instruction Word
Very Long Instruction Word (VLIW) bezeichnet eine Eigenschaft einer Befehlssatzarchitektur (englisch Instruction Set Architecture, kurz ISA) einer Familie von Mikroprozessoren. Ziel ist die Beschleunigung der Abarbeitung von sequentiellen Programmen durch Ausnutzung von Parallelität auf Befehls-Ebene. Im Gegensatz zu superskalaren Prozessoren werden bei VLIW die Befehle nicht dynamisch zur Laufzeit vom Prozessor den einzelnen Funktionseinheiten zugewiesen, sondern der Compiler gruppiert parallel ausführbare Befehle. VLIW schließt die Verwendung einer Pipeline-Architektur nicht aus.
Realisierung
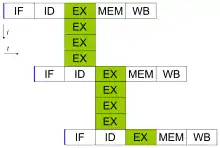
Der Compiler überprüft während der Übersetzung eines Programms, welche Instruktionen parallel ausgeführt werden können. Diese parallelisierbaren Instruktionen werden in Gruppen zusammengefasst und ins Befehlsformat eingetragen. Dabei richtet sich die Gruppengröße nach der Anzahl der zu Verfügung stehenden parallel arbeitenden Ausführungseinheiten. Dies ist wiederum architekturabhängig. Die Instruktionen eines Befehls, der auch Leerinstruktionen zum Auffüllen enthalten kann, werden durch die Ausführungseinheiten zur Laufzeit des Programms parallel verarbeitet.
Eigenschaften
Wie der Name bereits sagt, ist ein Hauptmerkmal für VLIW das breite Befehlsformat, welches mehrere Instruktionen auf einmal enthält. Im Gegensatz zur Superskalartechnik übernimmt der Compiler die Aufgabe der Umordnung und Markierung der parallel ausführbaren Befehle, mit dem Ziel, die verfügbare Parallelität von Befehlsfolgen optimal zu nutzen. Zusätzliche Hardwarelogik, wie beispielsweise bei der Superskalartechnik, ist nicht notwendig; dadurch ist auf der CPU mehr Platz für weitere Funktionseinheiten vorhanden.
Die Parallelität auf Befehlsebene, die VLIW bietet, kann nicht immer voll ausgenutzt werden, wenn z. B. in einem Takt auf Grund von Datenabhängigkeiten nur ein Befehl ausgeführt werden kann. In diesen Fällen wird die Breite des Befehlswortes nicht ausgenutzt. Manche Hersteller versuchen, dieses Overhead-Problem durch eigene VLIW-Erweiterungen zu lösen. Texas Instruments entwickelte beispielsweise die VelociTI-Technik, bei der mehrere Befehle aufeinander folgender Takte in ein Befehlswort gepackt werden können. Bits an den Grenzen der einzelnen Befehle zeigen an, ob der folgende Befehl noch im gleichen oder erst im nächsten Takt ausgeführt werden soll. Ein ähnliches Konzept verwendet Intel in seiner IA-64-Architektur.
Vorteile:
- Mehr Platz für die Funktionseinheiten
- Einfacher Kontrollpfad
- Gute Ausnutzung durch Compiler-Techniken wie Software-Pipelining
Nachteile:
- Code lässt sich nicht unbedingt ohne größere Änderung auf andere Prozessoren portieren
Beispiele
Die VLIW-Architektur wurde erstmals 1978 im russischen Superskalarrechner ELBRUS-1 von Boris Babajan realisiert. Im Jahre 1999 wurde gemäß internationaler Ankündigung des russischen Mikroprozessors Elbrus 2000 diese Architektur erstmals auf Mikroprozessoren übertragen.
Pioniere waren auch Cydrome in den 1980er Jahren (Bob Rau), Multiflow (Josh Fisher) und Culler-Harrison in den 1970ern (Glen Culler) und in der Tschechoslowakei Norbert Fristacky.
Die VLIW-Architektur wird in den CPUs von Transmeta benutzt, im Crusoe und im Efficeon. Ebenfalls auf der VLIW-Architektur basieren die (nicht massenvermarkteten) Prozessoren von Tilera Technologies, einem Joint Venture u. a. von Intel, welches sich auf massive SMP-Mehrkernprozessoren spezialisiert hat.
Eine moderne, abgeänderte Implementation der VLIW-Architektur ist Intels Itanium-CPU, welche in diesem Fall EPIC genannt wird.
AMD verwendet bei seinen Grafikprozessoren der Serien R600-RV870 eine VLIW-Technik, um bis zu fünf parallele Instruktionen auf einem VLIW-Shader auszuführen. Die Entwicklung der R600-Architektur datiert allerdings in die Zeit zurück, als ATI Technologies noch ein eigenständiges Unternehmen war. Zu Anfang war die Architektur der von Nvidia noch leistungsmäßig unterlegen, erlaubte aber AMD in der Weiterentwicklung immer mit deutlich niedrigeren Transistormengen und Shader-Taktraten gegenüber Hauptkonkurrent Nvidia erfolgreich zu konkurrieren. Nvidias skalare Lösung setzt auf eine hohe Auslastung und braucht dabei nicht nur mehr Transistoren für eine vergleichbare Leistung, sondern auch einen viel höheren Takt, was bezüglich Energieeffizienz letztendlich zu großen Nachteilen gegenüber der VLIW-Architektur führt.
Literatur
- Binu Mathew: Very Large Instruction Word Architectures. In: Vojin G. Oklobdzija (Ed.): The Computer Engineering Handbook, CRC Press, Boca Raton 2001, ISBN 9780849308857, (online; PDF; 182 kB).
| nach Wortbreite |
1-Bit-Architektur • Bit-Slice-Architektur • 4-Bit-Architektur • 8-Bit-Architektur • 16-Bit-Architektur • 32-Bit-Architektur • 64-Bit-Architektur | |
| nach Befehlssatzaufbau | ||
| mit Optimierung für Einsatzzweck |
(Haupt-)Prozessor • Grafikprozessor • GPGPU • Streamprozessor • Soundprozessor • Gleitkommaeinheit • Netzwerkprozessor • Physikbeschleuniger • Vektorprozessor • TensorFlow Processing Unit |