Netzwerkprozessor
Ein Netzwerkprozessor (englisch Network Processor, NP, auch englisch Network Processing Unit, NPU) ist ein programmierbarer Mikroprozessor, der für die Verarbeitung und Weiterleitung von Datenpaketen in Kommunikationsnetzen optimiert ist.[1]

Netzwerkprozessoren können durch Techniken wie massive Parallelverarbeitung und Pipelining viele Pakete gleichzeitig und unabhängig voneinander bearbeiten[2]. Die daraus resultierenden Wirespeed-Datenübertragungsraten betragen bei aktuellen Prozessoren bis zu 200 Gbit/s duplex (Stand 2013)[3].
Einsatzbereiche
Netzwerkprozessoren werden sowohl im Zugangsnetz (DSLAMs, Basisstationen, Intrusion-Prevention-Systeme/Firewalls, Deep Packet Inspection) als auch im Kernnetz (Switches, Router) verwendet. Durch ihre Programmierbarkeit können sie modifiziert werden, so dass in kurzer Zeit neue Dienste oder Protokolle unterstützt werden können. Insbesondere Netzwerkprozessoren für hochbitratige Netze sind auf Aufgaben spezialisiert, die für die Schichten 2 (Ethernet), 3 (IP) und 4 (TCP) des OSI-Netzwerkmodells charakteristisch sind[4].
Die wichtigsten Schritte bei der Paketverarbeitung sind (häufig ausgeführt in der angegebenen Reihenfolge):
- Media Access Control
- Die Media Access Control übernimmt Funktionen wie Ethernet Framing oder ATM Cell Segmentation and Reassembly.
- Header Parsing und Klassifizierung
- Die Header von Datenpaketen werden geparst und mit bekannten Mustern verglichen (Pattern Matching). Damit können Pakete in unterschiedliche Protokolle (z. B. VLAN-tagged Ethernet, IPv4, IPv6) klassifiziert und im Verlauf entsprechend behandelt werden. Pakete zur Netzsteuerung- und kontrolle werden zur Weiterverarbeitung gegebenenfalls zu einer externen CPU geleitet (Kontrollpfad, „Slow Path“).
- Zugriffssteuerung
- Über Paketfilter wird die Kommunikation zum Beispiel auf bestimmte Quell- oder Zieladressen beschränkt.
- Address Learning
- Wurde ein Ethernetpaket empfangen, so werden die MAC-Adresse des Senders und die zugehörige Empfangsschnittstelle (Portnummer) direkt in die Source Address Table (SAT) eingetragen. IP-Routingtabellen hingegen werden normalerweise indirekt über ein Routingprotokoll (z. B. BGP, OSPF) aktualisiert.
- Tabellen-Lookup
- Um die Zieladresse bzw. die nächste Teilstrecke herauszufinden, ist das Durchsuchen einer Adress- bzw. Routingtabelle notwendig. Ein übliches Suchverfahren ist der Longest Prefix Match.
- Header Update
- Das Paket wird je nach Protokoll in geeigneter Weise modifiziert, zum Beispiel, indem ein MPLS Label getauscht oder der Time-to-Live Wert heruntergesetzt wird.
- Traffic Management/Queuing
- Basierend auf der vorangegangenen Routingentscheidung steuert der Traffic Manager den Verkehrsfluss so, dass konfigurierte Quality of Service (QoS) Parameter eingehalten werden (Traffic Shaping, Traffic Policing; siehe auch: ATM Traffic Management). In Abhängigkeit dieser Dienstgüteparameter und der individuellen Priorisierung werden die Pakete in verschiedene Ausgangswarteschlangen (queues) einsortiert.
Geschichte
Als Ende der 1990er Jahre die Datenraten und Funktionen in IP-Routern stark zunahmen, beschritten die Hersteller bei der Paketverarbeitung einen neuen Weg: Programmierbare, auf Netzwerkaufgaben spezialisierte Prozessoren sollten bislang verwendete definierte ASICs ersetzen. Vorreiter waren die beiden Firmen Cisco und Juniper, die im Jahr 2000 die ersten selbstentwickelten Netzwerkprozessoren einsetzten: Toaster 2 (Parallel eXpress Forwarding, PXF, Cisco) und Internet Processor II (Juniper)[5]. Intel folgte kurz darauf mit dem IXP1200, dem ersten frei erhältlichen Netzwerkprozessor[6].
Im Zuge des Internetbooms in der zweiten Hälfte der 1990er Jahre entstanden Dutzende von High-Tech-Startups, die Netzwerkprozessoren für die neue Generation von Netzwerkgeräten bauen wollten. Anfang 2003 vermarkteten bereits 30 verschiedene Chiphersteller Netzwerkprozessoren[7]. Mit dem Platzen der Dotcom-Blase erlahmte jedoch die Investitionstätigkeit der Netzbetreiber, was zu einem Bankrott der meisten Netzwerkprozessor Anbieter führte. In der Folge setzte ein Konzentrationsprozess ein, der u. a. zu folgenden Übernahmen führte: Avago/LSI/Agere, Broadcom/Sandburst, Netronome/Intel, Marvell/Xelerated, PMC-Sierra/Wintegra.
Der Markt für frei erhältliche Netzwerkprozessoren ist schätzungsweise 350 Mio. US-Dollar groß (2012) und wuchs seit 2005 um mehr als 6 % jährlich[3]. Obwohl Netzwerkprozessoren ihren Platz als wichtiger Baustein für Netzwerkgeräte gefunden haben, ist das Umfeld für reine Chiphersteller herausfordernd, da immer mehr ihrer großen Kunden dazu übergehen, Netzwerkprozessoren selber zu entwickeln.
Architektur und Aufbau

Da die einzelnen Aufgaben bei der Verarbeitung von Datenpaketen relativ einfach sind, verwenden die meisten Netzwerkprozessoren effiziente, in ihrer Funktion nochmals reduzierte RISC-Prozessoren, die Prozessorelemente genannt werden. Für Standard-Prozessoren übliche Blöcke wie Caches, Memory-Management Units (MMU) und Gleitkommaeinheiten (FPU) fehlen häufig.
Aufgrund der Tatsache, dass der Programmfluss stark an die Verfügbarkeit der einzelnen Datenpakete gekoppelt ist, werden Netzwerkprozessoren zum Teil nicht als befehlsgetriebene Von-Neumann-Systeme realisiert. Stattdessen findet die (exotische) Datenfluss-Architektur Verwendung. Sie gehört nach der Flynnschen Klassifikation zur Klasse der MISD-Architekturen (Multiple Instruction, Single Data).
Mikroarchitektur
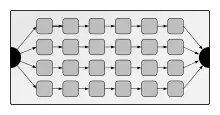
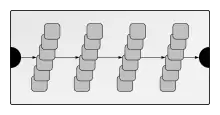
Das Ziel hoher Datenverarbeitungsgeschwindigkeiten kann außer mit schnellen Prozessortaktraten durch die grundlegenden Techniken Parallelisierung und Pipelining erreicht werden. Dabei können die einzelnen Prozessorelemente jeweils verschiedenartig angeordnet werden[2]. Beispielhaft werden drei typische Topologien vorgestellt.
- Parallele Prozessor-Pipelines
- Eine Möglichkeit, Parallelisierung und Pipelining zu verbinden, ist die parallele Prozessor-Pipeline Architektur. Ankommende Pakete werden einer Pipeline zugeordnet, die dann vollständig durchlaufen wird. Beispiel: Cisco Toaster[8].
- Pipeline aus Parallelprozessoren
- Diese Architekturvariante ähnelt einer reinen Pipeline bestehend aus superskalaren Prozessorelementen. Diese können auch von unterschiedlichem Typ sein. Beispiel: EZChip NP[8].
Funktionsblöcke
Zur Beschleunigung spezieller, rechenintensiver Aufgaben besitzen die meisten Netzwerkprozessoren dedizierte, fest codierte Funktionsblöcke. Darunter sind Engines für Hash- und CRC Berechnung, Statistik, Pattern Matching sowie Bandbreitenmanagement (traffic management). Diese Blöcke sind nicht programmierbar, sondern nur in engen Grenzen konfigurierbar.
Außerdem werden häufig externe Koprozessoren zur Unterstützung eingesetzt. Beispiele sind General Purpose Processors (GPPs) für Control Plane Management, Knowledge Based Processors[9] oder Sicherheits-Koprozessoren.
Programmierung
Aus Performanzgründen setzen viele Netzwerkprozessoren effiziente, auf niedriger Ebene realisierte Hardware-Funktionen ein. Dies zieht wiederum eine systemnahe Programmierung in Assembler oder in der Programmiersprache C nach sich. Die Programmerstellung ähnelt daher der eines Mikrocontrollers. Nur wenige der verfügbaren Netzwerkprozessoren können in ANSI C unter Verwendung einer Standard GNU Toolchain programmiert werden[4].
Abgrenzung
Netzwerkprozessoren werden unterschieden von Kommunikationsprozessoren und konfigurierbaren ASSPs.
Kommunikationsprozessor
Kommunikationsprozessoren verarbeiten Pakete im Datenpfad mit vergleichsweise niedrigeren Bitraten (1–10 Gbit/s). Sie sind daher preisgünstiger als Netzwerkprozessoren. Beispiele sind die OCTEON-Chips von Cavium oder die PowerQUICC-Chips von Freescale. Kommunikationsprozessoren haben einen oder mehrere Standard (MIPS, ARM etc.) Prozessorkerne integriert, die Paketverarbeitung auf den oberen Netzwerkschichten (Ebene 4 bis Ebene 7) und Kontrollprotokollverarbeitung ermöglichen.
Konfigurierbarer ASSP
Im Bereich hoher Datenraten sind ASSPs eine Konkurrenz zu Netzwerkprozessoren. Sie sind nur konfigurierbar, nicht programmierbar, und somit weniger komplex. Daher werden sie häufig für Ebene-2-Paketverarbeitung (Ethernet) eingesetzt. Beispiele sind die StrataXGS-Chips von Broadcom (BCM56xxx).
Hersteller und Produkte

- Alcatel-Lucent – Selbst entwickelter Netzwerkprozessorchipsatz (FP-Serie). Seit 2011 in der dritten Generation mit dem FP3, dem ersten Prozessor mit 400 Gbit/s Durchsatz simplex.
- AMCC – Marktführer bis 2005 (nP-Serie), keine aktuellen Produkte.
- Avago – Mit dem Kauf von Agere im Jahr 2007 wurde LSI Corporation Anbieter von Netzwerkprozessoren (APP-Serie), die in Zugangsnetzen eingesetzt werden. Ende 2013 wurde LSI von Avago übernommen.
- Broadcom – Durch verschiedene Akquisitionen mehrere Netzwerkprozessor-Produktlinien im Portfolio, darunter BCM880xx (Sandburst-Familie) und BCM88650 (Dune). Der BCM88030 war der erste frei erhältliche 100-Gbit/s-duplex-Netzwerkprozessor.
- Cavium – Die OCTEON-Serie ist mehr Kommunikations- als Netzwerkprozessor und wird vorwiegend im Zugangsnetz eingesetzt.
- Cisco – Verschiedene selbstentwickelte Netzwerkprozessoren, u. a. Toaster (2000), Silicon Packet Processor (2007), Quantum Flow (2008) und nPower (2013), letzterer mit einem Durchsatz von 400 Gbit/s simplex.
- Ericsson – 2013 Vorstellung des selbstentwickelten SNP 4000 Prozessors mit 200 Gbit/s simplex, auf dem sich im Gegensatz zu anderen Produkten Software unter SMP Linux mit der GNU C/C++ Toolchain entwickeln lässt[4].
- EZChip – Marktführer im Bereich verkäuflicher High-End-Netzwerkprozessoren (NP-Serie)[3]. Mit dem NP-2/NP-3, dem ersten 10-Gbit/s-Netzwerkprozessor mit integriertem Traffic Manager, konnte EZChip namhafte Kunden wie Cisco, Juniper, Huawei und ZTE gewinnen. Im Jahr 2013 in Produktion ist der NP-4 mit 100 Gbits/s Durchsatz simplex.
- Huawei – Solar 2.0 Chipsatz (100 Gbit/s simplex, 2009), Solar 3.0 Chipsatz (200 Gbit/s simplex, 2011).
- Intel – Mit der IXP Serie der Pionier unter den Herstellern verkäuflicher Netzwerkprozessoren. Marktführer 2006, jedoch Ende 2007 Verkauf der Sparte an Netronome.
- Juniper – Erster Hersteller, der spezifische ASICs zur Paketverarbeitung entwickelte (ABC Chipsatz). In der Folge Entwicklung verschiedener eigener Netzwerkprozessoren, u. a. Internet Processor II (2000) und Trio (2009).
- Marvell – Xelerated, im Jahr 2012 von Marvell übernommen, war der erste Hersteller mit einem 20-Gbit/s-full-duplex-Netzwerkprozessor in Produktion. Bis zuletzt blieben die Prozessoren ohne Traffic-Management-Funktionen. Marvell führt die spezielle Dataflow-Architektur[10] der Xelerated Prozessoren weiter.
- Netronome – Mit den Intel IXP-Netzwerkprozessoren Marktführer 2007 und den folgenden Jahren. Weiterentwicklung der Intel IXP28xx-Architektur als NFP-Serie.
- PMC-Sierra – Mit dem Kauf von Wintegra im Jahr 2010 Marktführer bei verkäuflichen Netzwerkprozessoren für Zugangsnetze (WinPath-Serie)[3]. Unter den bekanntgegebenen Kunden befinden sich Alcatel-Lucent, Cisco und Ericsson.
Literatur
- Ran Giladi: Network Processors: Architecture, Programming, and Implementation. Morgan Kaufmann (Elsevier), 2008, ISBN 978-0-12-370891-5 (Inhaltsverzeichnis und EZChip NP Programmcode (Memento vom 25. August 2014 im Internet Archive)).
- Douglas Comer: Network Systems Design Using Network Processors: Intel 2XXX Version. Addison-Wesley, 2005, ISBN 978-0-13-187286-8 (Inhaltsverzeichnis und Intel NP Programmcode).
Weblinks
- Linley Gewnnap: Netzwerkprozessoren enträtselt. Special Report. EE Times, 12. August 2004. Abgerufen am 23. Februar 2014.
Einzelnachweise
- Netzwerkprozessoren. (Nicht mehr online verfügbar.) Universität Paderborn, Fakultät für Elektrotechnik, Informatik und Mathematik, ehemals im Original; abgerufen am 1. März 2014. (Seite nicht mehr abrufbar, Suche in Webarchiven)
- Christian Hermsmeyer, Haoyu Song, Ralph Schlenk, Riccardo Gemelli, Stephan Bunse: Towards 100G Packet Processing: Challenges and Technologies In: Bell Labs Technical Journal. Band 14, Nummer 2, Sommer 2009, ISSN 1538-7305, S. 57–79 (PDF; 350 kB (Memento vom 14. Mai 2014 im Internet Archive)).
- Bob Wheeler, Jag Bolaria: A Guide to Network Processors. Executive Summary (web preview). Abgerufen am 1. März 2014.
- Bob Wheeler: A New Era of Network Processing. White Paper (PDF; 370 kB). Oktober 2013. Abgerufen am 1. März 2014.
- Craig Matsumoto: How Cisco beat chip world to net. EE Times, 20. Oktober 2000. Abgerufen am 23. Februar 2014.
- Craig Matsumoto: Intel makes IXP its net processor cornerstone. EE Times, 25. August 2000. Abgerufen am 23. Februar 2014.
- Douglas Comer: Network Processors: Programmable Technology for Building Network Systems. In: The Internet Protocol Journal. Band 7, Nummer 4, Dezember 2004, ISSN 1944-1134, S. 2–12 (PDF; 440 kB).
- Niraj Shah: Understanding Network Processors (GZIP-PDF; 1,9 MB). Tech. Report Version 1.0, EECS, University of California, Berkeley, September 2001.
- Broadcom: Knowledge-Based Processors. Product Information. (Memento vom 2. März 2014 im Internet Archive) Abgerufen am 2. März 2014.
- Marvell Technology Group: Dataflow Architecture. Product Information. (Memento vom 8. Juli 2014 im Internet Archive) Abgerufen am 1. März 2012.
| nach Wortbreite |
1-Bit-Architektur • Bit-Slice-Architektur • 4-Bit-Architektur • 8-Bit-Architektur • 16-Bit-Architektur • 32-Bit-Architektur • 64-Bit-Architektur | |
| nach Befehlssatzaufbau | ||
| mit Optimierung für Einsatzzweck |
(Haupt-)Prozessor • Grafikprozessor • GPGPU • Streamprozessor • Soundprozessor • Gleitkommaeinheit • Netzwerkprozessor • Physikbeschleuniger • Vektorprozessor • TensorFlow Processing Unit |