Prozess (Informatik)
Ein Prozess (auch Task oder Programminstanz genannt[1]) ist ein Computerprogramm zur Laufzeit. Genauer ist ein Prozess die konkrete Instanziierung eines Programms zu dessen Ausführung innerhalb eines Rechnersystems, ergänzt um weitere (Verwaltungs-)Informationen und Ressourcenzuteilungen des Betriebssystems für diese Ausführung.
Ein Prozess ist die Ablaufumgebung für ein Programm auf einem Rechnersystem, sowie der darin eingebettete Binärcode des Programmes während der Ausführung. Ein Prozess wird vom Betriebssystem dynamisch kontrolliert durch bestimmte Aktionen, mit denen das Betriebssystem ihn in entsprechende Zustände setzt. Als Prozess bezeichnet man auch die gesamte Zustandsinformation eines laufenden Programms. Im Gegensatz dazu handelt es sich bei einem Programm um die (statische) Verfahrensvorschrift für eine Verarbeitung auf einem Rechnersystem.
Die Prozesse werden vom Prozess-Scheduler des Betriebssystems verwaltet. Dieser kann einen Prozess entweder so lange rechnen lassen, bis er endet oder blockiert (nicht-unterbrechender Scheduler), oder dafür sorgen, dass nach jeweils einer kurzen Zeitdauer der gerade ablaufenden Prozess unterbrochen wird, und der Scheduler so zwischen verschiedenen aktiven Prozessen hin und her wechseln kann (unterbrechender Scheduler), wodurch der Eindruck von Gleichzeitigkeit entsteht, auch wenn zu jedem Zeitpunkt nicht mehr als nur ein Prozess verarbeitet wird. Letzteres ist die vorherrschende Scheduling-Strategie heutiger Betriebssysteme.
Eine nebenläufige Ausführungseinheit innerhalb eines Prozesses wird Thread genannt. Bei modernen Betriebssystemen gehört zu jedem Prozess mindestens ein Thread, der den Programmcode ausführt. Oftmals werden nun nicht mehr Prozesse nebenläufig ausgeführt, sondern nur die Threads innerhalb eines Prozesses.[2]
Unterscheidung zwischen Programm und Prozess
Ein Programm ist eine den Regeln einer bestimmten Programmiersprache genügende Folge von Anweisungen (bestehend aus Deklarationen und Instruktionen), um bestimmte Funktionen bzw. Aufgaben oder Probleme mithilfe eines Computers zu bearbeiten oder zu lösen.[3] Ein Programm bewirkt nichts, solange es nicht gestartet wurde. Wird ein Programm gestartet – genauer: eine Kopie (im Hauptspeicher) des Programms (auf dem Festwertspeicher), so wird diese Instanz zu einem (Betriebssystem-)Prozess, der zum Ablauf einem Prozessorkern zugeordnet werden muss.
Andrew S. Tanenbaum veranschaulicht den Unterschied zwischen einem Programm und einem Prozess metaphorisch anhand des Prozesses des Kuchenbackens:
- Das Rezept für den Kuchen ist das Programm (d. h. ein in einer passenden Notation geschriebener Algorithmus), der Bäcker ist der Prozessorkern und die Zutaten für den Kuchen sind die Eingabedaten. Der Prozess ist die Aktivität, die daraus besteht, dass der Bäcker das Rezept liest, die Zutaten herbeiholt und den Kuchen backt. Es kann nun beispielsweise vorkommen, dass der Sohn des Bäckers wie am Spiess schreiend in die Backstube gelaufen kommt. In diesem Fall notiert sich der Bäcker, an welcher Stelle des Rezeptes er sich befindet (der Zustand des aktuellen Prozesses wird gespeichert) und wechselt in einen Prozess mit höherer Priorität, nämlich „Erste Hilfe leisten“. Dazu holt er ein Erste-Hilfe-Handbuch hervor und folgt den dortigen Anweisungen. Den beiden Prozessen „Backen“ und „Erste Hilfe leisten“ liegt also ein unterschiedliches Programm zu Grunde: Kochbuch und Erste-Hilfe-Handbuch. Nachdem der Bäckersohn medizinisch versorgt wurde, kann der Bäcker zum „Backen“ zurückkehren und an dem Punkt fortfahren, an dem er unterbrochen wurde. Das Beispiel veranschaulicht, dass sich mehrere Prozesse einen Prozessorkern teilen können. Eine Scheduling-Strategie entscheidet, wann die Arbeit an einem Prozess unterbrochen und ein anderer Prozess bedient wird.[4]
Ein Prozess stellt auf einem Rechnersystem die Ablaufumgebung für ein Programm zur Verfügung und ist die Instanziierung eines Programms. Als ablaufendes Programm beinhaltet ein Prozess dessen Anweisungen – sie sind eine dynamische Folge von Aktionen, die entsprechende Zustandsänderungen bewirken. Als Prozess bezeichnet man auch die gesamte Zustandsinformation eines laufenden Programms.[5]
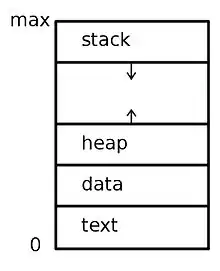
Damit ein Programm ausgeführt werden kann, müssen ihm bestimmte Ressourcen zugeteilt werden. Dazu gehört u. a. ein ausreichender Anteil des Hauptspeichers, in dem der entsprechende Prozess ausgeführt werden soll. Im Allgemeinen übersetzt der Compiler ein Programm in eine ausführbare Datei, die vom Betriebssystem in den Adressraum eines Prozesses geladen werden kann. Ein Programm kann nur zu einem Prozess werden, wenn die ausführbare Datei in den Hauptspeicher geladen wird. Es gibt zwei übliche Techniken, wie ein Benutzer dem Betriebssystem anweist, eine ausführbare Datei zu laden und zu starten: durch Doppelklick auf ein Icon, das die ausführbare Datei repräsentiert, oder durch Eingabe des Dateinamens in der Kommandozeile.[6] Außerdem haben laufende Programme auch noch die Möglichkeit, ohne Beteiligung des Benutzers weitere Prozesse mit Programmen zu starten.
Ein Prozess beinhaltet insbesondere
- den Wert des Befehlszählers,
- die Inhalte der zum Prozess gehörenden Prozessor-Register,
- das Programmsegment, das den ausführbaren Code des Programms enthält,
- das Stack-Segment, das temporäre Daten wie Rücksprungadressen und lokale Variablen enthält,
- das Datensegment, das globale Variablen enthält, und
- unter Umständen einen Heap, der dynamisch angeforderten Speicher umfasst, der auch wieder freigegeben werden kann.[7]
Auch wenn zwei Prozesse zu demselben Programm gehören, werden sie trotzdem als zwei unterschiedliche Ausführungseinheiten angesehen. So können beispielsweise verschiedene Benutzer verschiedene Kopien eines gleichen Mail-Programms ausführen oder ein einziger Benutzer kann verschiedene Kopien eines Browser-Programms aktivieren. Davon ist jede ein separater Prozess. Auch wenn unter Umständen das Programmsegment bei verschiedenen Instanzen eines Programms dasselbe ist, so unterscheiden sich Daten-, Heap- und Stack-Segmente.[8]
Ein Prozess kann seinerseits wieder eine Ausführungsumgebung für anderen Programmcode sein. Ein Beispiel dafür ist die Java-Laufzeitumgebung. Diese besteht üblicherweise aus der Java Virtual Machine (JVM), die für die Ausführung der Java-Anwendungen verantwortlich ist. Mit ihr werden Java-Programme weitgehend unabhängig vom darunter liegenden Betriebssystem ausgeführt. So lässt sich ein kompiliertes Java-Programm Program.class mit dem Kommandozeilenbefehl java Program ausführen. Der Befehl java erzeugt einen gewöhnlichen Prozess für die JVM, welche dann ihrerseits das Java-Programm Program in der virtuellen Maschine ausführt.[8]
Im Zusammenhang mit den Speicherbereichen, die ein laufendes Programm als Prozess nutzen darf, spricht man auch von einem Prozessadressraum. Ein Prozess kann nur Daten verarbeiten, die zuvor in seinen Adressraum geladen wurden; Daten, die momentan von einem Maschinenbefehl verwendet werden, müssen sich zudem im (physischen) Hauptspeicher befinden.[9] Der Adressraum eines Prozesses ist im Allgemeinen virtuell; der virtuelle Speicher bezeichnet den vom tatsächlich vorhandenen Hauptspeicher unabhängigen Adressraum, der einem Prozess vom Betriebssystem zur Verfügung gestellt wird. Die Memory Management Unit (MMU) verwaltet den Zugriff auf den Hauptspeicher. Sie rechnet eine virtuelle in eine physische Adresse um (siehe dazu auch Speicherverwaltung und Paging).
Prozesszustände
Es wird unterschieden zwischen
- dem Ausführungszustand eines Prozesses – welche Daten in den Registern stehen, wie viel Speicher er an welchen Adressen besitzt, aktuelle Ausführungsstelle im Programm (Befehlszähler) usw. (Prozesskontext) sowie
- dem Prozesszustand aus Sicht des Betriebssystems: zum Beispiel „gerade rechnend“, „blockiert“, „wartend“, „fertig“.
Ein Prozessor(kern) kann immer nur einen Prozess gleichzeitig verarbeiten. Bei den ersten Computern wurden daher die Prozesse immer nacheinander als Ganzes verarbeitet, es konnte immer nur ein Prozess zur gleichen Zeit (exklusiv) ablaufen. Um die Wartezeiten beim Zugriff z. B. auf langsame Peripherie-Einheiten nutzen zu können, wurde die Möglichkeit geschaffen, Prozesse nur teilweise auszuführen, zu unterbrechen und später wieder fortzuführen (wieder „aufzusetzen“). Der Begriff Multiprogramming (auch Multiprogrammbetrieb oder Multiprocessing) bezeichnet im Gegensatz zum Einprogrammbetrieb (Singleprocessing) die Möglichkeit der „gleichzeitigen“ oder „quasi-gleichzeitigen“ Ausführung von Programmen/Prozessen in einem Betriebssystem. Die meisten modernen Betriebssysteme wie Windows oder Unix unterstützen den Mehrprozessbetrieb, wobei die Anzahl der nebenläufigen Prozesse meist wesentlich höher ist als die Anzahl der vorhandenen Prozessorkerne.[10]
Ein Prozess durchläuft somit während seiner Lebenszeit verschiedene Zustände. Wenn das Betriebssystem entscheidet, den Prozessor für eine gewisse Zeit einem anderen Prozess zuzuteilen, wird zunächst der aktuell rechnende Prozess gestoppt und in den Zustand rechenbereit versetzt. Danach kann der andere Prozess in den Zustand rechnend versetzt werden. Es kann auch sein, dass ein Prozess blockiert wird, weil er nicht weiterarbeiten kann. Typischerweise geschieht dies durch das Warten auf Eingabedaten, die noch nicht zur Verfügung stehen. Vereinfacht lassen sich vier Zustände unterscheiden:[11]
- Rechnend (engl. running, auch aktiv): Der Prozess wird in diesem Moment auf der CPU ausgeführt, d. h. die Programm-Befehle werden abgearbeitet. Einem Prozess im Zustand rechnend kann das Betriebsmittel CPU auch wieder entzogen werden, er wird dann in den Zustand bereit versetzt.
- (Rechen)bereit (engl. ready): Im Zustand bereit befinden sich Prozesse, die gestoppt wurden, um einen anderen Prozess rechnen zu lassen. Sie können theoretisch ihren Ablauf fortsetzen und warten nun darauf, dass ihnen die CPU wieder zugeteilt wird. Auch wenn ein neuer Prozess erzeugt wird, tritt dieser zunächst in den Zustand bereit ein.
- Blockiert (engl. blocked): Prozesse im Zustand blockiert warten auf bestimmte Ereignisse, die für den weiteren Prozessablauf notwendig sind. Beispielsweise sind E/A-Geräte im Vergleich zur CPU nur sehr langsam arbeitende Komponenten; hat ein Prozess das Betriebssystem mit einer E/A-Geräte-Kommunikation beauftragt, so muss er warten, bis das Betriebssystem diese abgeschlossen hat.
- Beendet (engl. terminated): Der Prozess hat seine Ausführung beendet, das Betriebssystem muss noch „aufräumen“.
Dies lässt sich als Zustandsautomat eines Prozesses mit vier Zuständen modellieren:
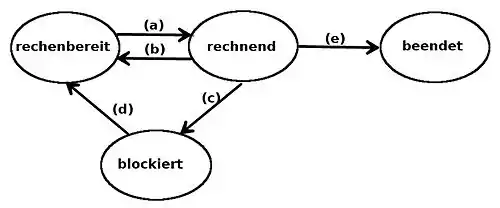
Es ergeben sich dabei u. a. die folgenden Zustandsübergänge:[12]
- (a) Die Prozesse, die sich im Zustand rechenbereit befinden, werden in einer Ready-Queue verwaltet. Der Übergang (a) wird von einem Teil des Betriebssystems ausgeführt, der Prozess-Scheduler genannt wird. Meistens sind mehrere Prozesse gleichzeitig rechenbereit und konkurrieren um die CPU. Der Scheduler trifft die Wahl, welcher Prozess als nächster läuft.
- (b) Dieser Übergang erfolgt, wenn die Rechenzeit, die der Scheduler dem Prozess zugeteilt hat, abgelaufen ist und nun ein anderer Prozess Rechenzeit erhalten soll, oder der aktive Prozess seine Rechenzeit freiwillig vorzeitig unterbricht, zum Beispiel mit einem Systemaufruf.
- (c) Wenn ein Prozess im Zustand rechnend momentan nicht fortfahren kann, meistens weil er eine Dienstleistung des Betriebssystems benötigt oder eine benötigte Ressource im Moment (noch) nicht zur Verfügung steht, so versetzt das Betriebssystem ihn solange in den Zustand blockiert. Beispielsweise wird ein Prozess blockiert, wenn er von einer Pipe oder einer Spezialdatei (z. B. einer Kommandozeile) liest und dort noch keine Daten anliegen.
- (d) Liegt die Ursache des Blockiertseins für einen Prozess nicht mehr vor, zum Beispiel weil das Betriebssystem die Dienstleistung erbracht hat, eine Ressource nun verfügbar ist oder ein externes Ereignis eingetreten ist, auf das der blockierte Prozess gewartet hat (z. B. Tastendruck, Mausklick), so wird dieser wieder in den Zustand rechenbereit versetzt.
- (e) Wenn ein Prozess seine Aufgabe erledigt hat, terminiert er, d. h. er meldet dem Betriebssystem, dass er (genau mit dieser Meldung) endet; das Betriebssystem versetzt ihn in den Zustand beendet. Ein weiterer Grund für eine Terminierung liegt vor, wenn der Prozess einen schwerwiegenden Fehler verursacht hat und das Betriebssystem ihn abbrechen muss, oder der Benutzer eine Terminierung explizit veranlasst.
Das Betriebssystem hat nun Zeit, belegte Ressourcen freizugeben, offene Dateien zu schließen und ähnliche Aufräumarbeiten durchzuführen.
Natürlich sind die Zustandsautomaten moderner Betriebssysteme etwas komplexer, aber im Prinzip sind sie ähnlich konzipiert. Auch die Bezeichnungen der Prozesszustände variieren zwischen den Betriebssystemen. Grundlegend bleibt, dass sich pro Prozessor(kern) nur ein Prozess im Zustand rechnend befinden kann, dagegen können viele Prozesse gleichzeitig rechenbereit und blockiert sein.[13]
Prozesskontext
Die gesamte Information, die für den Ablauf und die Verwaltung von Prozessen von Bedeutung ist, bezeichnet man als Prozesskontext.
Der Prozesskontext beinhaltet u. a. die Informationen, die im Betriebssystem für einen Prozess verwaltet werden und die Inhalte aller zum Prozess gehörenden Prozessorregister (z. B. Allzweckregister, Befehlszähler, Statusregister und MMU-Register). Die Registerinhalte sind wesentlicher Bestandteil des sogenannten Hardware-Kontext.[14] Verliert ein rechnender Prozess die CPU, so findet ein sog. Kontextwechsel (engl. context switch) statt: Dabei wird zunächst der Hardware-Kontext des aktiven Prozesses gesichert; anschließend wird der Kontext des Schedulers hergestellt und dieser ausgeführt; er entscheidet nun, ob/welcher Prozess als nächstes folgen soll. Der Scheduler sichert dann seinen eigenen Kontext, lädt den Hardware-Kontext des neu zu aktivierenden Prozesses in den Prozessorkern und startet ihn anschließend.[14]
Prozessverwaltung
Prozesskontrollblock
Jeder Prozess eines Betriebssystems wird durch einen Prozesskontrollblock (engl. process control block, kurz PCB, auch task control block) dargestellt. Der Prozesskontrollblock beinhaltet viele Informationen, die mit einem bestimmten Prozess verbunden sind. Es werden also alle wichtigen Informationen über einen Prozess gespeichert, wenn er vom Zustand rechnend in die Zustände rechenbereit oder blockiert übergeht: Der Hardware-Kontext eines zu suspendierenden Prozesses wird in seinem PCB gesichert, der Hardware-Kontext des neu zu aktivierenden Prozesses aus seinem PCB in die Ablaufumgebung geladen.[15] Dadurch kann der blockierte oder rechenbereite Prozess zu einem späteren Zeitpunkt fortgesetzt werden, genau in dem Zustand, wie er vor der Unterbrechung war (ggf. mit Ausnahme der Änderung, die ihn zuvor blockierte).[16]
Zu den Informationen, die über einen Prozess im PCB gespeichert werden, gehören unter anderem:[17]
- Der Process identifier (kurz PID, auch Prozessnummer, Prozesskennung oder Prozess-ID): Dies ist ein einzigartiger Schlüssel, welcher der eindeutigen Identifikation von Prozessen dient. Der PID ändert sich während der Laufzeit des Prozesses nicht. Das Betriebssystem stellt sicher, dass systemweit keine Nummer zweimal vorkommt.[18]
- Der Prozessstatus: rechenbereit, rechnend, blockiert oder beendet.
- Der Inhalt des Befehlszählers, der die Adresse des nächsten auszuführenden Befehls enthält.
- Die Inhalte aller anderer CPU-Register, die dem Prozess zur Verfügung stehen/mit ihm zusammenhängen.
- Scheduling-Informationen: Dazu gehören die Priorität des Prozesses, Zeiger auf die Scheduling-Warteschlangen und weitere Scheduling-Parameter.
- Informationen für die Speicherverwaltung: Diese Informationen können beispielsweise die Werte der Basis- und Grenzregister beinhalten und Zeiger auf Codesegment, Datensegment und Stacksegment.
- Buchhaltung: Das Betriebssystem führt auch Buch darüber, wie lange ein Prozess schon gerechnet hat, wie viel Speicher er belegt usw.
- E/A-Statusinformationen: Dies beinhaltet eine Liste der E/A-Geräte (bzw. Ressourcen), die mit dem Prozess verbunden sind/von ihm belegt sind, zum Beispiel auch offene Dateien.
- Elternprozess, Prozessgruppe, CPU-Zeit der Kindprozesse usw.
- Zugriffs- und Benutzerrechte
Prozesstabelle
Das Betriebssystem führt eine Tabelle mit aktuellen Prozessen in einer kerneleigenen Datenstruktur, der sog. Prozesstabelle. Bei der Erzeugung eines neuen Prozesses wird darin ein Prozesskontrollblock als neuer Eintrag angelegt. Viele Zugriffe auf einen Prozess basieren darauf, dass über den PID der zugehörige PCB in der Prozesstabelle gesucht wird. Da PCBs Informationen über die belegten Ressourcen enthalten, müssen sie im Speicher direkt zugreifbar sein. Wesentliches Kriterium, in was für einer Datenstruktur die Tabelle im Betriebssystem gespeichert wird, ist daher ein möglichst effizienter Zugriff.
Operationen auf Prozessen
Prozesserzeugung
Prozesse, die mit (menschlichen) Benutzern interagieren, müssen „im Vordergrund laufen“, also Eingabe- und Ausgaberessourcen belegen und verwenden. Hintergrundprozesse dagegen erfüllen Funktionen, die keine Benutzer-Interaktion benötigen; sie sind meist eher dem Betriebssystem als ganzes zuzuordnen denn einem bestimmten Benutzer. Prozesse, die im Hintergrund bleiben, heißen auf Unix-basierten Betriebssystemen „Daemons“, auf Windows-basierten „Dienste“. Wenn der Computer hochgefahren wird, werden üblicherweise viele Prozesse gestartet, von denen der Benutzer nichts bemerkt. Beispielsweise könnte ein Hintergrundprozess zum Empfangen von E-Mails gestartet werden, der im Zustand „blockiert“ verbleibt, bis eine E-Mail eintrifft. In unixoiden Systemen werden die laufenden Prozesse mit dem Kommando ps angezeigt,[19] unter Windows wird dazu der Taskmanager benutzt.[20]
Ein laufender Prozess kann weitere Prozesse durch einen Systemaufruf erzeugen (lassen) – ein Beispiel-Systemaufruf dafür ist die Funktion fork() in unixoiden Systemen: Diese erzeugt aus einem existierenden Prozess (Elternprozess) einen zusätzlichen, neuen Prozess (Kindprozess). Der Kindprozess wird als Kopie des Elternprozesses erzeugt, erhält jedoch einen eigenen Prozessidentifikator (PID) und wird in der Folge als eigenständige Instanz eines Programms und unabhängig vom Elternprozess ausgeführt.[21] In Windows kann ein Prozess durch die Funktion CreateProcess() gestartet werden.[22]
In manchen Betriebssystemen besteht zwischen Eltern- und Kindprozessen weiterhin eine gewisse Beziehung. Wenn der Kindprozess weitere Prozesse erzeugt, entsteht eine Prozesshierarchie. In Unix formiert ein Prozess zusammen mit seinen Nachkommen eine Prozessfamilie.[23] Versendet beispielsweise ein Benutzer ein Signal mittels Tastatureingabe, so wird dieses an all diejenigen Prozesse der Prozessfamilie weitergeleitet, die momentan mit der Tastatur in Verbindung stehen. Jeder Prozess kann nun selber entscheiden, wie er mit dem Signal umgeht.
In Windows existiert dagegen kein Konzept der Prozesshierarchie. Alle Prozesse sind gleichwertig. Es ist lediglich ein spezielles Token (Handle genannt) vorhanden, das einem Elternprozess erlaubt, seinen Kindprozess zu steuern.[24]
Prozessbeendigung
Ein Prozess endet normalerweise, indem er sich am Ende seines Programmablaufs mittels Systemaufruf als beendet erklärt. Bildschirmorientierte Programme wie Textverarbeitungsprogramme und Webbrowser stellen ein Symbol oder einen Menüpunkt bereit, den der Benutzer anklicken kann, um den Prozess anzuweisen, sich freiwillig zu beenden. Ein Prozess sollte vor seinem Ende sämtliche geöffneten Dateien schließen und jegliche Ressourcen zurückgeben. Als beendender Systemaufruf existiert unter Unix der Systemaufruf exit und unter Windows exitProcess.
Ein Prozess kann auch von einem anderen Prozess beendet (terminiert) werden. Ein Systemaufruf, der das Betriebssystem anweist, einen anderen Prozess zu beenden, heißt unter Unix kill und unter Windows TerminateProcess.
Ein weiterer Grund für eine Terminierung liegt vor, wenn ein Prozess einen schwerwiegenden Fehler verursacht. Dies geschieht häufig aufgrund von Programmierfehlern. Beispielsweise wenn der Prozess auf Ressourcen zugreifen möchte, die ihm nicht (mehr) zugeteilt sind (zum Beispiel Schreiben auf eine bereits geschlossene Datei, Lesen aus einem Speicherbereich, der bereits dem Betriebssystem zurückgegeben wurde). Ebenso bricht das Betriebssystem einen Prozess ab, der illegale Aktionen auszuführen versucht (zum Beispiel Bitkombinationen als Befehle ausführen möchte, die die CPU nicht kennt, oder direkte Hardwarezugriffe, die nur das Betriebssystem darf).[25]
Wenn ein Prozess in unixoiden Betriebssystemen beendet wurde, kann er trotzdem noch in der Prozesstabelle gelistet sein und noch zugeteilte Ressourcen belegen sowie Attribute besitzen. Ein Prozess in diesem Zustand wird Zombie-Prozess genannt. Wenn ein Kindprozess beendet wird, kann der Elternprozess dadurch vom Betriebssystem erfragen, auf welche Art dieser beendet wurde: erfolgreich, mit Fehler, abgestürzt, abgebrochen etc. Um diese Abfrage zu ermöglichen, bleibt ein Prozess, selbst nachdem er beendet wurde, in der Prozesstabelle stehen, bis der Elternprozess diese Abfrage durchführt – egal ob diese Information gebraucht wird oder nicht. Bis dahin hat der Kindprozess den Zustand Zombie.
Prozessbesitzer und Prozessrechte
Ein Aspekt der IT-Sicherheit verlangt, dass sich Benutzer gegenüber dem Computersystem authentifizieren müssen. Ansonsten kann das Betriebssystem nicht beurteilen, auf welche Dateien oder andere Betriebsmittel ein Benutzer zugreifen darf. Bei der am weitesten verbreiteten Form der Authentifizierung wird der Benutzer aufgefordert, einen Login-Namen und ein Passwort einzugeben.[26] Jeder Benutzer erhält so eine eindeutige Benutzer-ID (UID). Benutzer können wiederum in Gruppen organisiert werden, denen eine Gruppen-ID (GID) zugewiesen ist.
Der Zugriff auf gewisse Daten soll insofern beschränkt und kontrolliert sein, als nur autorisierte Benutzer oder Programme auf die Informationen zugreifen dürfen. So baut beispielsweise ein wichtiger Sicherheitsmechanismus von unixoiden Systemen auf diesem Benutzer-Konzept auf: Jeder Prozess trägt die Benutzer-ID und Gruppen-ID seines Aufrufers. Durch den Login-Prozess erfährt das Betriebssystem, mit wessen Benutzer-ID ein Prozess zu starten ist.[27] Man sagt, dass ein Prozess dem Benutzer gehört, der ihn gestartet hat. Der Benutzer ist also der Besitzer des Prozesses. Wenn nun beispielsweise eine Datei erstellt wird, bekommt diese die UID und GID des erzeugenden Prozesses. Die Datei gehört somit ebenfalls dem Benutzer, in dessen Namen (mit dessen UID) sie angelegt wurde. Wenn ein Prozess auf eine Datei zugreift, prüft das Betriebssystem anhand der UID der Datei, ob diese dem Besitzer des Prozesses gehört, und entscheidet daraufhin, ob der Zugriff gestattet wird.[28]
Ein Spezialfall ist der Superuser (oder Root-Benutzer), der mit den weitreichendsten Zugriffsrechten ausgestattet ist. In unixoiden Systemen hat dieses Benutzerkonto die UID 0. Prozessen mit der UID 0 ist es auch gestattet, eine kleine Anzahl geschützter Systemaufrufe durchzuführen, die für normale Benutzer gesperrt sind. Das Setuid-Bit ermöglicht einen erweiterten Schutzmechanismus. Wenn das Setuid-Bit gesetzt ist, dann wird die effektive UID für diesen Prozess auf den Besitzer der ausführbaren Datei gesetzt, anstatt auf den Benutzer, der es aufgerufen hat. Dieses Vorgehen ermöglicht unprivilegierten Benutzern und Prozessen einen kontrollierten Zugriff auf privilegierte Ressourcen.[29]
Prozessumschaltung
Bei einer Prozessumschaltung (engl. context switch) wird der Prozessor an einen anderen Prozess vergeben. Bei nicht unterbrechbaren Prozessen findet eine Prozessumschaltung beim Start und beim Ende einer Prozessausführung statt. Bei unterbrechbaren Prozessen ist eine Umschaltung möglich, wann immer es der Prozessor zulässt. Man spricht auch von der Verdrängung (engl. suspension) eines Prozesses durch einen anderen, wenn ein Prozess mit einer höheren Priorität die CPU erhält.[30]
Prozess-Scheduling
Ein Prozess-Scheduler regelt die zeitliche Ausführung mehrerer Prozesse. Die Strategie, die er verwendet, heißt Schedulingstrategie. Dies ist die Strategie, nach der der Scheduler die Prozess-Umschaltungen vornimmt. Diese sollte eine „bestmögliche“ Zuteilung der CPU an die Prozesse ermöglichen, wobei allerdings (abhängig vom ausführenden System) unterschiedliche Ziele verfolgt werden können. Bei interaktiven Systemen ist beispielsweise eine kurze Antwortzeit erwünscht, d. h. eine möglichst kurze Reaktionszeit des Systems auf die Eingaben eines Benutzers. Wenn er beispielsweise in einem Texteditor eine Tastatureingabe tätigt, sollte der Text sofort erscheinen. Als einer von mehreren Benutzern sollte auch eine gewisse Fairness garantiert werden: Kein (Benutzer-)Prozess sollte unverhältnismäßig lange warten müssen, während ein anderer bevorzugt wird.
Einprozessorsysteme verwalten genau einen Prozessor(kern) (CPU). Es gibt darauf also immer nur einen Prozess, der im Zustand rechnend ist, alle anderen (rechenbereiten) Prozesse müssen warten, bis ihnen der Scheduler die CPU für eine gewisse Zeit zuweist. Auch bei Mehrprozessorsystemen ist die Anzahl der Prozesse meist größer als die Anzahl der Prozessorkerne und die Prozesse konkurrieren um das knappe Betriebsmittel CPU-Zeit.[31] Ein weiteres allgemeines Ziel der Schedulingstrategie ist es, möglichst alle Teile des Systems beschäftigt zu halten: Wenn die CPU und alle Ein-/Ausgabegeräte die ganze Zeit über am Laufen gehalten werden können, wird mehr Arbeit pro Sekunde erledigt, als wenn sich einige Komponenten des Rechnersystems im Leerlauf befinden.[32]
Grob lassen sich Schedulingstrategien in zwei Kategorien einteilen: Eine nicht unterbrechende (engl. nonpreemptive) Schedulingstrategie wählt einen Prozess aus und lässt ihn so lange laufen, bis er blockiert (z. B. wegen Ein-/Ausgabe oder weil er auf einen anderen Prozess wartet) oder bis er freiwillig die CPU abgibt. Im Gegensatz dazu wählt eine unterbrechende (engl. preemptive) Schedulingstrategie einen Prozess aus und lässt ihn nicht länger als eine festgelegte Zeit laufen. Falls er nach diesem Zeitintervall immer noch rechnet, wird er beendet und der Scheduler wählt einen anderen Prozess aus den rechenbereiten Prozessen zur Ausführung aus. Unterbrechendes Scheduling erfordert einen Timerinterrupt, der am Ende des Zeitintervalls dem Scheduler die Kontrolle über die CPU zurückgibt.[33]
Unterbrechungen
Die Hardware oder die Software kann einen Prozess vorübergehend unterbrechen, um einen anderen, in der Regel kurzen, aber zeitkritischen, Vorgang abzuarbeiten (siehe Interrupt). Da Unterbrechungen in Systemen häufige Ereignisse sind, muss entsprechend sichergestellt werden, dass ein unterbrochener Prozess später wieder fortgesetzt werden kann, ohne dass bereits geleistete Arbeit verloren geht. In den unterbrochenen Prozess wird quasi eine Unterbrechungsbehandlung eingeschoben. Diese wird im Betriebssystem ausgeführt.
Das auslösende Ereignis wird Unterbrechungsanforderung (engl. interrupt request, kurz IRQ) genannt. Nach dieser Anforderung führt der Prozessor eine Unterbrechungsroutine aus (auch Unterbrechungsbehandlung genannt, engl. interrupt handler, interrupt service routine oder kurz ISR). Anschließend wird der unterbrochene Prozess dort fortgeführt, wo er unterbrochen wurde.
Synchrone Unterbrechungen
Synchrone Unterbrechungen treten bei internen Ereignissen auf, die insbesondere bei identischen Rahmenbedingungen (Programmausführung mit gleichen Daten) immer an der gleichen Programmstelle auftreten. Die Unterbrechungsstelle im Programm ist also vorhersagbar.
Die Bezeichnung synchron deutet darauf hin, dass diese Unterbrechungen an die Ausführung eines Befehls im Rechnerkern selbst geknüpft sind. Der Rechnerkern erkennt Ausnahmen (engl. exceptions oder traps) im Rahmen seiner Verarbeitung (z. B. eine Division durch null). Der Rechnerkern muss daher auf interne Unterbrechungswünsche sofort reagieren und die Behandlung der aufgetretenen (Fehler-)Situation in der Unterbrechungsbehandlung veranlassen. Sie sind also nicht verzögerbar.[34]
Entsprechend ihrer typischen Bedeutung haben sich für einige Unterbrechungswünsche spezielle Bezeichnungen eingebürgert, zum Beispiel:[35]
- Ein Befehlsalarm tritt auf, wenn ein Benutzerprozess versucht einen privilegierten Befehl auszuführen.
- Ein Seitenfehler tritt bei virtueller Speicherverwaltung mit Paging auf, wenn ein Programm auf einen Speicherbereich zugreift, der sich gerade nicht im Hauptspeicher befindet, sondern beispielsweise auf die Festplatte ausgelagert wurde.
- Ein arithmetischer Alarm tritt auf, wenn eine arithmetische Operation nicht ausgeführt werden kann, beispielsweise wenn durch Null dividiert werden soll.
Asynchrone Unterbrechungen
Asynchrone Unterbrechungen (auch (asynchrone) Interrupts genannt) sind Unterbrechungen, die nicht an den rechnenden Prozess gebunden sind. Sie kommen durch externe Ereignisse zustande und hängen nicht mit der CPU-Verarbeitung zusammen. Dementsprechend sind solche Unterbrechungen unvorhersagbar und nicht reproduzierbar.
Häufig wird eine asynchrone Unterbrechung durch ein Ein-/Ausgabegerät ausgelöst. Diese bestehen üblicherweise aus zwei Teilen: einem Controller und dem Gerät selbst. Der Controller ist ein Chip (oder auch mehrere Chips), der das Gerät auf der Hardwareebene steuert. Er bekommt Befehle vom Betriebssystem, wie das Lesen von Daten vom Gerät, und führt diese aus. Sobald das Ein-/Ausgabegerät seine Aufgabe beendet hat, erzeugt es ein Interrupt. Dazu wird ein Signal auf den Bus gelegt, das vom entsprechenden Interrupt-Controller erkannt wird, der dann aus einem interrupt request eine Unterbrechung der CPU erzeugt, die mit Hilfe eines passenden Programmstücks bearbeitet werden muss (meist eine Interrupt-Service-Routine, kurz ISR).[36]
Beispiele, bei denen Geräte eine Unterbrechungsanforderung generieren, sind:
- Netzwerkkarte: wenn Daten empfangen wurden und im Puffer bereitliegen
- Festplatte: wenn die vorher angeforderten Daten gelesen wurden und abholbereit sind (das Lesen von der Festplatte dauert relativ lange)
- Grafikkarte: wenn das aktuelle Bild fertig gezeichnet wurde
- Soundkarte: wenn wieder Sound-Daten zum Abspielen benötigt werden, bevor der Puffer leer wird.
Die Interrupt-Service-Routinen werden meist an Interrupt-Vektoren adressiert, die in einer Interrupt-Vektor-Tabelle gespeichert sind. Ein Interrupt-Vektor ist also ein Eintrag in dieser Tabelle, der die Speicheradresse der Interrupt-Service-Routinen enthält.[37]
Am Ende einer Interrupt-Bearbeitungsroutine sendet die ISR an den Interrupt-Controller eine Bestätigung. Der alte Prozessorstatus wird anschließend wieder hergestellt und der unterbrochene Prozess kann an der vorher unterbrochenen Stelle weiterarbeiten. Durch eine entsprechende Scheduling-Eintscheidung kann auch ermöglicht werden, dass zunächst ein Prozess mit höherer Priorität die CPU erhält, bevor der unterbrochene Prozess an der Reihe ist. Dies hängt von der Schedulingstrategie des Betriebssystems ab.[38]
Threads
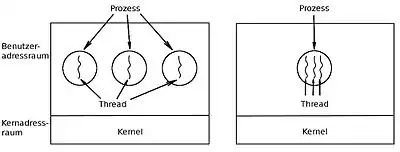
Da die Verwaltung von Prozessen relativ aufwändig ist, unterstützen moderne Betriebssysteme auch ein Ressourcen-schonenderes Konzept, die sogenannten Threads (deutsch: Fäden, Ausführungsstränge). Ein Thread verkörpert eine nebenläufige Ausführungseinheit innerhalb eines Prozesses. Im Gegensatz zu den schwergewichtigen (heavy-weight) Prozessen werden Threads als leichtgewichtige (light-weight) Prozesse (kurz LWP) charakterisiert. Diese lassen sich leichter erzeugen und wieder zerstören: In vielen Systemen läuft die Erstellung eines Threads 10-100-mal schneller ab als die Erstellung eines Prozesses. Insbesondere wenn sich die Anzahl an benötigten Threads dynamisch und schnell verändert, ist diese Eigenschaft von Vorteil.
Threads existieren innerhalb von Prozessen und teilen sich deren Ressourcen. Ein Prozess kann mehrere Threads oder – wenn bei dem Programmablauf keine Parallelverarbeitung vorgesehen ist – auch nur einen einzigen Thread beinhalten. Ein wesentlicher Unterschied zwischen einem Prozess und einem Thread besteht darin, dass jeder Prozess seinen eigenen Adressraum besitzt, während für einen neu gestarteten Thread kein neuer Adressraum eingerichtet werden muss, sondern die Threads auf den gemeinsamen Speicher des Prozesses zugreifen können. Threads teilen sich innerhalb eines Prozesses auch andere betriebssystemabhängige Ressourcen wie Prozessoren, Dateien und Netzwerkverbindungen. Deswegen ist der Verwaltungsaufwand für Threads üblicherweise geringer als der für Prozesse. Ein wesentlicher Effizienzvorteil von Threads besteht zum einen darin, dass im Gegensatz zu Prozessen beim Threadwechsel kein vollständiger Wechsel des Prozesskontextes notwendig ist, da alle Threads einen gemeinsamen Teil des Prozesskontextes verwenden, zum anderen in der einfachen Kommunikation und schnellem Datenaustausch zwischen Threads. Threads eines Prozesses sind aber nicht gegeneinander geschützt und müssen sich daher beim Zugriff auf die gemeinsamen Prozess-Ressourcen abstimmen (synchronisieren).[39]
Die Implementierung von Threads hängt vom jeweiligen Betriebssystem ab. Sie kann auf Kernel- oder auf Benutzerebene erfolgen. So sind Threads in Windows-Betriebssystemen auf Kernelebene realisiert, in Unix sind Thread-Implementierungen sowohl auf der Kernel- als auch auf der Benutzerebene möglich. Bei Threads auf der Benutzerebene führt die entsprechende Threadbibliothek das Scheduling und Umschalten zwischen den Threads durch. Jeder Prozess verwaltet einen privaten Thread-Kontrollblock (analog zum PCB) und der Kern hat keinerlei Kenntnis davon, ob ein Prozess mehrere Threads verwendet oder nicht. Bei Kernel-Threads werden die Threads im Kernelmodus verwaltet. Eine spezielle Threadbibliothek ist dabei für den Anwendungsprogrammierer nicht erforderlich. Der Kern ist hier also an der Erzeugung und Umschaltung von Threads beteiligt.[40]
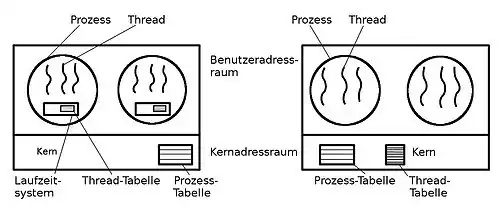
Ein Thread-Paket auf Benutzerebene (links) und ein Thread-Paket vom Betriebssystem-Kern verwaltet (rechts)
Interprozesskommunikation
Der Begriff Interprozesskommunikation (engl. interprocess communication, kurz IPC) meint verschiedene Verfahren des Informationsaustausches zwischen den Prozessen eines Systems. Bei der Variante „Shared Memory“ erfolgt die Kommunikation dadurch, dass mehrere Prozesse auf einen gemeinsamen Datenspeicher zugreifen können, beispielsweise gemeinsame Bereiche des Arbeitsspeichers. Bei einer Message Queue dagegen werden „Nachrichten“ (Datenpakete) von einem Prozess an eine Liste („Nachrichtenschlange“) angehängt; von dort können diese von einem anderen Prozess abgeholt werden. Dritte Variante ist die „Pipe“, ein (Byte-)Datenstrom zwischen zwei Prozessen nach dem FIFO-Prinzip. Um längere Datenpakete effizient übertragen zu können, wird eine Pipe meist durch einen Sende- und/oder Empfangs-Puffer ergänzt.
Die Kommunikation zwischen den Prozessen sollte in einer gut strukturierten Weise erfolgen. Um Race Conditions zu vermeiden, sollten die kritischen Abschnitte, in denen auf gemeinsam genutzte Ressourcen zugegriffen wird, vor einem (quasi-)gleichzeitigen Zugriff geschützt werden. Dies kann durch verschiedene Mechanismen wie Semaphore oder Monitore realisiert werden. Wenn ein Prozess auf die Freigabe einer Ressource oder den Empfang einer Nachricht wartet, die ein anderer Prozess nicht freigibt/sendet, weil jener wiederum darauf wartet, dass ersterer eine andere Ressource freigebe/Nachricht sende, so entsteht eine sogenannte Deadlock-Situation. Es können sich auch mehr als zwei Prozesse gegenseitig blockieren.
Klassische Problemstellungen der Interprozesskommunikation sind das Erzeuger-Verbraucher-Problem, das Philosophenproblem und das Leser-Schreiber-Problem.
Verbesserung der CPU-Ausnutzung
Durch den Einsatz von Multiprogrammierung kann die CPU-Ausnutzung verbessert werden. Wenn ein Prozess einen Anteil seiner Laufzeit auf die Beendigung von Ein-/Ausgaben wartet, so ist die Wahrscheinlichkeit, dass solche Prozesse auf die Ein-/Ausgabe warten . Dies entspricht der Wahrscheinlichkeit, dass die CPU unbeschäftigt wäre. Die CPU-Ausnutzung kann dadurch als Funktion von ausgedrückt werden, die Grad der Multiprogrammierung genannt wird:



- CPU-Ausnutzung =

Es ist durchaus üblich, dass ein interaktiver Prozess 80 % oder mehr im Ein-/Ausgabe-Wartezustand verbringt. Auch auf Servern, die viel Plattenein-/ausgabe durchführen, ist dieser Wert realistisch. Unter dieser Annahme, dass Prozesse 80 % ihrer Zeit im blockierten Zustand verbringen, müssen mindestens 10 Prozesse laufen, damit die CPU weniger als 10 % der Zeit verschwendet wird.
Natürlich stellt dieses probabilistische Modell nur eine Annäherung dar. So setzt es voraus, dass alle Prozesse unabhängig sind. In einer einzigen CPU können jedoch nicht mehrere Prozesse gleichzeitig laufen. Es müsste also noch berücksichtigt werden, dass ein rechenbereiter Prozess warten muss, während die CPU läuft. Ein exaktes Modell kann mit Hilfe der Warteschlangentheorie konstruiert werden. Dennoch veranschaulicht das Modell die Verbesserung der CPU-Ausnutzung: Mit Multiprogrammierung können Prozesse die CPU benutzen, die ansonsten untätig wäre. Es lassen sich so zumindest überschlägige Vorhersagen über die CPU-Performanz machen.[41]
Programmbeispiele
Erzeugen eines Kindprozesses mit dem fork()-Aufruf
Mit Hilfe der fork-Funktion erstellt ein Prozess eine nahezu identische Kopie von sich selber. Der Name bedeutet im Englischen in etwa „sich gabeln, verzweigen oder spalten“: Der aufrufende Prozess gelangt an eine Weggabelung, an der sich Eltern- und Kindprozess trennen.
Das folgende C-Programm deklariert eine Zählervariable counter und weist ihr zunächst den Wert 0 zu. Durch fork() wird danach ein Kindprozess erzeugt, der eine identische Kopie des Elternprozesses ist. Der Systemaufruf fork() liefert bei Erfolg dem Elternprozess den PID des eben geschaffenen Kindes zurück. Im Kind liefert die Funktion dagegen den Rückgabewert 0. Mit Hilfe dieses Rückgabewerts kann man nun Auskunft darüber erlangen, ob es sich jeweils um Eltern- oder Kindprozess handelt und entsprechend in einer if-else-Verzweigung fortfahren. Um die eigene PID zu finden, ist getpid() nötig.
Nach dem Aufruf von fork() laufen also zwei Prozesse quasi-parallel, die beide ihre eigene Version der Zählervariable counter von 0 bis 1000 erhöhen. Man hat nun keinen Einfluss darauf, welcher Prozess zu welchem Zeitpunkt bearbeitet wird. Dementsprechend kann die Ausgabe auf der Konsole von einem Durchgang zum nächsten variieren.[42]
#include <stdio.h>
#include <unistd.h>
int main(void)
{
printf("PROGRAMMSTART\n");
int counter = 0;
pid_t pid = fork();
if (pid == 0)
{
// Hier befinden wir uns im Kindprozess
int i = 0;
for (; i < 1000; ++i)
{
printf(" PID: %d; ", getpid());
printf("Kindprozess: counter=%d\n", ++counter);
}
}
else if (pid > 0)
{
// Hier befinden wir uns im Elternprozess
int j = 0;
for (; j < 1000; ++j)
{
printf("PID: %d; ", getpid());
printf("Elternprozess: counter=%d\n", ++counter);
}
}
else
{
// Fehler bei fork()
printf("fork() fehlgeschlagen!\n");
return 1;
}
printf("PROGRAMMENDE\n");
return 0;
}
Forkbomb
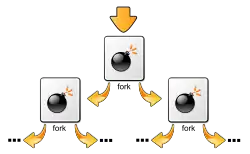
Das folgende Programmbeispiel erzeugt eine Forkbomb. Es wird ein Prozess gestartet, der in einer Endlosschleife mittels fork() immer wieder Kindprozesse erzeugt, die sich gleich verhalten wie der Elternprozess. Dadurch werden die verfügbaren Systemressourcen (Prozesstabellen, CPU usw.) aufgebraucht. Eine Forkbomb realisiert somit eine Denial-of-Service-Attacke, kann aber auch bei unbedachter Anwendung des fork-Aufrufs „hochgehen“.
#include <unistd.h>
int main(void)
{
while(1)
{
fork();
}
return 0;
}
Der konkrete Effekt der Forkbomb hängt in erster Linie von der Konfiguration des Betriebssystems ab. Beispielsweise erlaubt PAM auf Unix, die Zahl der Prozesse und den maximal zu verbrauchenden Speicher pro Benutzer zu beschränken. „Explodiert“ eine Forkbomb auf einem System, welches diese Möglichkeiten der Beschränkung nutzt, scheitert irgendwann der Versuch, neue Kopien der Forkbomb zu starten und das Wachstum ist eingedämmt.
Siehe auch
Literatur
- Albert Achilles: Betriebssysteme. Eine kompakte Einführung mit Linux. Springer: Berlin, Heidelberg, 2006.
- Uwe Baumgarten, Hans-Jürgen Siegert: Betriebssysteme. Eine Einführung. 6., überarbeitete, aktualisierte und erweiterte Auflage, Oldenbourg Verlag: München, Wien, 2007.
- Erich Ehses, Lutz Köhler, Petra Riemer, Horst Stenzel, Frank Victor: Systemprogrammierung in UNIX / Linux. Grundlegende Betriebssystemkonzepte und praxisorientierte Anwendungen. Vieweg+Teubner: Wiesbaden, 2012.
- Robert Love: Linux Kernel Development. A thorough guide to the design and implementation of the Linux kernel. Third Edition, Addison-Wesley: Upper Saddle River (NJ), u. a., 2010. (Online)
- Peter Mandl: Grundkurs Betriebssysteme. Architekturen, Betriebsmittelverwaltung, Synchronisation, Prozesskommunikation, Virtualisierung. 4. Auflage, Springer Vieweg: Wiesbaden, 2014. (Ältere verwendete Ausgabe: Grundkurs Betriebssysteme. Architekturen, Betriebsmittelverwaltung, Synchronisation, Prozesskommunikation. 1. Auflage, Vieweg+Teubner: Wiesbaden, 2008.)
- Abraham Silberschatz, Peter Baer Galvin, Greg Gagne: Operating System Concepts. Ninth Edition, John Wiley & Sons: Hoboken (New Jersey), 2013.
- Andrew S. Tanenbaum: Moderne Betriebssysteme. 3., aktualisierte Auflage. Pearson Studium, München u. a., 2009, ISBN 978-3-8273-7342-7.
- Jürgen Wolf: Linux-UNIX-Programmierung. Das umfassende Handbuch. 3., aktualisierte und erweiterte Auflage, Rheinwerk: Bonn, 2009.
Einzelnachweise und Anmerkungen
- Roland Hellmann: Rechnerarchitektur: Einführung in den Aufbau moderner Computer. Walter de Gruyter, 2013, ISBN 978-3-486-72002-0, S. 271 (google.de [abgerufen am 16. November 2020]).
- Christian Ullenboom: Java ist auch eine Insel. Einführung, Ausbildung, Praxis. 11., aktualisierte und überarbeitete Auflage, Galileo Computing: Bonn, 2014, S. 902.
- ISO/IEC 2382-1:1993 definiert „computer program“: „A syntactic unit that conforms to the rules of a particular programming language and that is composed of declarations and statements or instructions needed to solve a certain function, task, or problem.“ Bis 2001 definierte die DIN 44300 „Informationsverarbeitung Begriffe“ identisch.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 126–127.
- Mandl: Grundkurs Betriebssysteme. 4. Aufl., 2014, S. 78.
- Silberschatz, Galvin, Gagne: Operating System Concepts. 2013, S. 106–107.
- Silberschatz, Galvin, Gagne: Operating System Concepts. 2013, S. 106.
- Silberschatz, Galvin, Gagne: Operating System Concepts. 2013, S. 107.
- Mandl: Grundkurs Betriebssysteme. 4. Aufl., 2014, S. 80.
- Mandl: Grundkurs Betriebssysteme. 4. Aufl., 2014, S. 35–36.
- Mandl: Grundkurs Betriebssysteme. 2008, S. 78; Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 131–132.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 131–133; ferner Silberschatz, Galvin, Gagne: Operating System Concepts. 2013, S. 107, 111–112.
- Silberschatz, Galvin, Gagne: Operating System Concepts. 2013, S. 107.
- Mandl: Grundkurs Betriebssysteme. 4. Aufl., 2014, S. 79.
- Mandl: Grundkurs Betriebssysteme. 4. Aufl., 2014, S. 81.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 133–135.
- Silberschatz, Galvin, Gagne: Operating System Concepts. 2013, S. 107–109; Tanenbaum: Moderne Betriebssysteme. 2009, S. 133–134.
- Anmerkung: Unter Umständen kann explizit von einem Prozess gefordert, dass er den gleichen PID wie ein anderer hat, z. B. durch !CLONE_PID.
- Anmerkung: ps ohne Optionen zeigt nur solche Prozesse an, die aus Textkonsolen bzw. Shell-Fenstern gestartet wurden. Durch die Option x werden auch Prozesse angezeigt, denen kein Terminal zugeordnet ist. Außerdem gibt es das Kommando top: Dieses ordnet die Prozesse danach, wie sehr sie die CPU belasten und zeigt die gerade aktiven Prozesse zuerst an.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 127.
- UNIXguide.net by Hermelito Go: What does fork() do? (abgerufen am 20. April 2016)
- Windows Dev Center: Creating Processes
- Anmerkung: Die Darstellung der Prozesshierarchie gelingt am einfachsten mit dem Shell-Kommando pstree.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 130–131.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 129–130.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 742–743.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 923.
- Peter H. Ganten, Wulf Alex: Debian GNU/Linux. 3. Auflage, Springer: Berlin, u. a., 2007, S. 519.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 924–925.
- Dieter Zöbel: Echtzeitsysteme. Grundlagen der Planung. Springer: Berlin, Heidelberg, 2008, S. 44.
- Mandl: Grundkurs Betriebssysteme. 4. Aufl., 2014, S. 79; Silberschatz, Galvin, Gagne: Operating System Concepts. 2013, S. 110–112.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 198.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 195–196.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 53; Hans-Jürgen Siegert, Uwe Baumgarten: Betriebssysteme. Eine Einführung. 6. Auflage, Oldenbourg Verlag: München, Wien, 2007, S. 54.
- Hans-Jürgen Siegert, Uwe Baumgarten: Betriebssysteme. Eine Einführung. 6. Auflage, Oldenbourg Verlag: München, Wien, 2007, S. 54.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 60–62, 406–410; Mandl: Grundkurs Betriebssysteme. 2014, S. 55.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 60–62, 406–410; Mandl: Grundkurs Betriebssysteme. 2014, S. 55.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 55–58.
- Mandl: Grundkurs Betriebssysteme. 2008, S. 78–79; Tanenbaum: Moderne Betriebssysteme. 3. Aufl. 2009, S. 137–140; Elisabeth Jung: Java 7. Das Übungsbuch. Band 2, mitp: Heidelberg, u. a., 2012, S. 145–146.
- Mandl: Grundkurs Betriebssysteme. 2008, S. 79–82.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 135–136.
- Das Programmbeispiel orientiert sich an Ehses, u. a.: Systemprogrammierung in UNIX / Linux. 2012, S. 50–51; siehe auch Wolf: Linux-UNIX-Programmierung. 3. Aufl., 2009, S. 211–219 und Markus Zahn: Unix-Netzwerkprogrammierung mit Threads, Sockets und SSL. Springer: Berlin, Heidelberg, 2006, S. 79–89.