Grafikprozessor
Ein Grafikprozessor (englisch graphics processing unit, kurz GPU; dieses teilweise lehnübersetzt Grafikeinheit[1] und seltener auch Video-Einheit[1] oder englisch video processing unit sowie visual processing unit, kurz VPU genannt[2]) ist ein auf die Berechnung von Grafiken spezialisierter und optimierter Prozessor für Computer, Spielkonsolen und Smartphones. Zusätzlich gibt er die berechneten Grafiken an ein Display oder mehrere aus. Früher hatten Grafikkarten gar keine eigenen Rechenfähigkeiten und waren reine Ausgabekarten. Ab Mitte der 1990er Jahre wurden zuerst 2D-Fähigkeiten und später rudimentäre 3D-Fähigkeiten integriert, der Grafikprozessor war festverdrahtet oder seine Programmierbarkeit war beschränkt auf seine Firmware. Seit Mitte der 2000er Jahre kann der Hauptprozessor (CPU) Programme auf die Grafikkarte oder auch in die Grafikeinheit laden, welche so in beschränktem Rahmen flexibel programmierbar ist.


Grafikprozessoren findet man auf dem Die von CPUs mit integrierter Grafikeinheit, auf der Hauptplatine (Onboard, als integrierter Grafikprozessor) wie auch auf Erweiterungskarten (Steckkarte). Im letzteren Fall sind mehrere GPUs auf einer Grafikkarte, bzw. auch mehrere Grafikkarten pro PC möglich. Für Notebooks gibt es externe Erweiterungsboxen, in die eine Grafikkarte gesteckt werden kann. In Dockingstationen kann eine eigene Grafikeinheit verbaut sein. Fast alle heute produzierten Grafikprozessoren für Personal Computer stammen von AMD, Intel oder Nvidia. Die Integration auf Steckkarten liegt dagegen bis auf Sonder- und Referenzmodelle seit einiger Zeit bei anderen Herstellern.
Komponenten
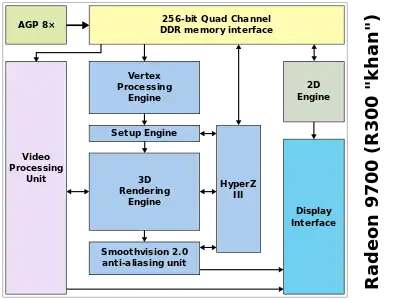
Display controller
Zur Anbindung eines Bildschirms an einen Computer – etwa über MDA, CGA etc. – benötigt man einen sogenannten Bildschirm-Adapter (analog Netzwerk-Adapter). Der Chip auf der (z. B.) ISA-Karte ist ein vergleichsweise simpler Video Display Controller. Etwaige Berechnungen zur Bildsynthese erfolgen auf der CPU, der Display Controller verpackt diesen Datenstrom lediglich in ein entsprechendes Signal (CGA, EGA, …) für den Bildschirm. Die Karte enthält zusätzlich ein wenig Speicher, den sogenannten Bildschirmpuffer, engl. display buffer.
RAMDAC
Der RAMDAC ist zuständig für die Umwandlung von digitalen Daten, welche im Videospeicher/Bildschirmpuffer vorliegen, in ein analoges Bildsignal.
GCA
Das englisch sogenannte Graphics and Compute Array (kurz GCA) oder auch die „3D-Engine“ (aus dem englischen ‚3D engine‘ entlehnt) können auch für Grafik-Berechnungen ausgelegt sein. Das Array besteht zudem aus den sogenannten Shader-Prozessoren, beinhaltet aber auch den Geometry-Prozessor (siehe auch Geometry-Shader).
Video-Kompression/-Dekompression
Zur Verringerung der Datenmenge eines Videos sind verschiedene Kompressions-Algorithmen entwickelt worden. Diese beschreiben umfangreiche Berechnungen, welche mit dem – bereits an sich umfangreichen – unkomprimierten Datenstrom durchgeführt werden müssen, um daraus den Komprimierten zu erhalten. Zum Abspielen eines komprimierten Videos, sind entsprechende Berechnungen auf den komprimierten Datenstrom durchzuführen.
Diese Berechnungen können ganz oder anteilig auf der Grafikkarte, dem Grafikprozessor oder auf einer anderen dafür entwickelten anwendungsspezifisch integrierten Schaltung durchgeführt werden.
Geschichte
Vorläufer der Grafikprozessoren gab es seit etwa Anfang der 1980er Jahre. Damals dienten diese nur als Bindeglied zwischen der CPU und der Bildschirmausgabe und wurden daher Bildschirm-Adapter (analog Netzwerk-Adapter) Video Display Controller genannt. Weder hatten sie die Funktionalität, noch waren sie für eigenständige Berechnungen ausgelegt. Zunächst waren sie vor allem für eine selbständige Text- und Grafikausgabe zuständig und schonten damit den Systembus. Einige konnten später immerhin Sprites selbständig darstellen.
Das änderte sich Mitte der 1980er Jahre mit Rechnern wie dem Commodore Amiga oder dem Atari ST. Diese verfügten bereits über Blitting-Funktionen. Im x86-PC-Bereich kamen Grafikprozessoren mit solchen Zusatzfunktionen mit der zunehmenden Verbreitung grafischer Oberflächen auf, insbesondere dem Betriebssystem Windows. Bausteine wie der ET-4000/W32 konnten einfache Befehle (z. B. „zeichne Viereck“) selbständig abarbeiten. Wegen des hauptsächlichen Einsatzes unter Windows wurden sie auch „Windows-Beschleuniger“ genannt.
Mitte der 1990er Jahre kamen die ersten 3D-Beschleuniger auf den Markt. Diese Grafikprozessoren waren in der Lage, einige Effekte und dreiecksbasierte Algorithmen (wie beispielsweise Z-Puffern, Texture Mapping) und Antialiasing auszuführen. Besonders dem Bereich Computerspiele verhalfen solche Steckkarten (wie die 3dfx Voodoo Graphics) zu einem Entwicklungsschub. Zur damaligen Zeit waren solche Anwendungen vorrangig durch den Prozessor begrenzt.
Die Bezeichnung GPU wurde erstmals von Nvidia intensiv genutzt, um die 1999 erschienene Nvidia-GeForce-256-Serie zu vermarkten. Diese Grafikkarte war (im Endkunden-Geschäft) als erste mit einer T&L-Einheit ausgestattet.
GPUs waren und sind wegen ihrer Spezialisierung auf Grafikberechnungen und Konzentration auf massiv parallelisierbare Aufgaben den CPUs in ihrer theoretischen Rechenleistung meist deutlich überlegen. Eine CPU ist für universelle Datenverarbeitung ausgelegt, die einzelnen CPU-Kerne sind zudem meist für schnelles Abarbeiten von sequentiellen Aufgaben optimiert. Die GPU zeichnet sich hingegen durch ein hohes Maß an Parallelisierung aus, da sich 3D-Berechnungen sehr gut parallelisieren lassen; dafür ist sie für 3D-Berechnungen spezialisiert, sie ist bei Berechnungen schnell, die diese Funktionalität verwenden. Es sind nach wie vor für bestimmte Aufgaben (z. B. für Texturfilterung) spezialisierte Einheiten („Fixed Function Units“) in der GPU enthalten. Ein aktuell übliches Anwendungsprogramm kann aufgrund der fehlenden Universalität i. A. nicht auf einer GPU ausgeführt werden. Ein Algorithmus, der sich auf die Fähigkeiten der GPU beschränkt, aber sehr seriell mit relativ wenig Datenparallelität arbeitet, kann die GPU nicht auslasten. Die relativ kleinen Caches in der GPU würden zu größeren Latenzen in der Programmausführung führen, die aufgrund mangelnder Parallelisierung des Programms nicht durch gleichzeitiges Abarbeiten vieler Aufgaben ausgeglichen werden könnten. Bei sequentiellen Aufgaben ist die CPU daher schneller.
Der Leistungsvorsprung gegenüber CPUs bei stark parallelisierbaren Aufgaben und die bereits vorhandenen SIMD-Eigenschaften machen aktuelle GPUs für wissenschaftliche, grafische und/oder datenintensive Anwendungen interessant. Diese Verwendung bezeichnet man als GPGPU. Die Einbeziehung der GPU hat z. B. im Volunteer-Computing-Projekt Folding@home zu einer enormen Steigerung der Rechenleistung geführt. Sie beschränkte sich zunächst auf die Chips des Herstellers ATI/AMD, im Jahr 2008 kam aber auch Nvidia-GPUs ab der GeForce-8-Serie hinzu. Für Grafikkarten von Nvidia existiert CUDA als API zur Nutzung der GPU für Berechnungen. Diese wird inzwischen auch genutzt, um in Spielen mittels PhysX Physikberechnungen durchzuführen. Inzwischen gibt es die offene Programmierplattform OpenCL, mit der Programme für CPU und GPU gleichermaßen entwickelt werden können. Zudem können heutige GPUs nicht nur mit einfacher Genauigkeit, sondern mit doppelter Genauigkeit rechnen.
Architekturen
Eine Grafikkarte ist ein Add-In-Board, das den Grafikprozessor enthält. Diese Grafikkarte enthält auch eine Reihe von Komponenten, die erforderlich sind, damit der Grafikprozessor funktioniert und eine Verbindung zum Rest des Systems hergestellt werden kann.
Es gibt zwei grundlegende Typen von Grafikprozessoren: integrierte und diskrete. Eine integrierte GPU wird überhaupt nicht auf einer eigenen Karte geliefert und ist stattdessen neben der CPU eingebettet. Eine diskrete GPU ist ein eigenständiger integrierter Schaltkreis (Mikrochip), der auf einer eigenen Leiterplatte montiert und normalerweise an einen Peripheral Component Interconnect Steckplatz (PCI) angeschlossen ist.
Die meisten GPUs auf dem Markt sind tatsächlich integrierte Grafikprozessoren. Eine CPU mit einer vollständig integrierten GPU auf der Hauptplatine ermöglicht dünnere und leichtere Systeme, geringeren Stromverbrauch und niedrigere Systemkosten.
Viele Computerprogramme können mit integrierten GPUs gut ausgeführt werden. Für ressourcenintensivere Anwendungen mit hohen Leistungsanforderungen ist eine diskrete GPU besser geeignet. Diese GPUs erhöhen die Rechenleistung auf Kosten des zusätzlichen Energieverbrauchs und der Wärmeerzeugung. Diskrete GPUs erfordern im Allgemeinen eine eigene Kühlung für maximale Rechenleistung.[3]
Fermi-GPU-Architektur
Bei der sogenannten Fermi-GPU-Architektur besteht der Hauptprozessor aus komplexen Prozessorkernen mit großen Caches. Die Kerne sind für die Leistung mit einem Thread optimiert und können mithilfe von Hyper-Threading bis zu zwei Hardware-Threads pro Kern verarbeiten.
Im Gegensatz dazu besteht eine GPU aus Hunderten von einfacheren Kernen, die Tausende von gleichzeitigen Hardware-Threads verarbeiten können. GPUs sind so konzipiert, dass sie den Gleitkommadurchsatz maximieren, wobei die meisten Transistoren in jedem Kern eher der Berechnung als der komplexen Parallelität auf Befehlsebene und großen Caches gewidmet sind. Die heutige Fermi-GPU-Architektur verfügt über Beschleunigerkerne, die als CUDA-Kerne bezeichnet werden. Jeder CUDA-Kern verfügt über eine Einheit für Ganzzahl-Operationen und logische Operationen (arithmetisch-logische Einheit) und eine Einheit für Gleitkomma-Operationen (FPU), die einen Ganzzahl- oder Gleitkomma-Befehl pro Taktzyklus ausführt. Eine Host-Schnittstelle verbindet die GPU über den Peripheral Component Interconnect Express Bus mit der CPU. Der GigaThread Global Scheduler verteilt Thread-Blöcke an Multiprozessor Thread-Scheduler. Dieser Scheduler verarbeitet die gleichzeitige Ausführung des Kernels und die Ausführung von Threadblöcken außerhalb der Reihenfolge.
Jeder Multiprozessor verfügt über Lade- und Speichereinheiten, sodass Quell- und Zieladressen für mehrere Threads pro Taktzyklus berechnet werden können. Special Function Units führen Rechenoperationen wie Sinus, Kosinus, Quadratwurzel und Interpolation aus. Jede Special Function Unit führt einen Befehl pro Thread und pro Takt aus. Der Multiprozessor plant Threads in Gruppen von parallelen Threads, die als Warps bezeichnet werden. Jeder Multiprozessor verfügt über zwei Warp-Scheduler und zwei Befehlsausgabeeinheiten, sodass zwei Warps gleichzeitig ausgegeben und ausgeführt werden können.[4]
Anwendungen
Der Grafikprozessor übernimmt rechenintensive Aufgaben der 2D- und 3D-Computergrafik und entlastet dadurch den Hauptprozessor (CPU). Die Funktionen werden über Software-Bibliotheken wie DirectX oder OpenGL angesteuert. Die freigewordene Prozessorzeit kann somit für andere Aufgaben verwendet werden:
- Unterstützung der Grafikschnittstellen DirectX und OpenGL
- Antialiasing – zum Teil winkelunabhängige Kantenglättung
- Anisotropes Filtern – Abbildung / Rasterung von Texturen
- Multi-GPU-Techniken – Zusammenarbeit mehrerer Grafikprozessoren
- freie Programmierbarkeit nahezu jeder GPU-Komponente (Shader, beinhaltet T&L)
- Textur – Musterabbildung, mit Hilfe mindestens einer Texture Mapping Unit (TMU)
- Bildsynthese, mit Hilfe von mindestens einem Raster Operation Processor (ROP), auch bekannt als Render Output Unit oder Raster Operations Pipeline
Früher wurden Grafikprozessoren hauptsächlich verwendet, um 3D-Grafikanwendungen in Echtzeit zu beschleunigen. Zu Beginn des 21. Jahrhunderts erkannten Informatiker jedoch, dass GPUs das Potenzial hatten, einige der schwierigsten Computerprobleme der Welt zu lösen.
Heute wird die Grafiktechnologie in größerem Umfang auf eine immer größere Anzahl von Problemen angewendet. Die heutigen GPUs sind programmierbarer als je zuvor und bieten die Flexibilität, eine breite Palette von Anwendungen zu beschleunigen, die weit über das herkömmliche Rendern von Grafiken hinausgehen.
Computerspiele sind rechenintensiver geworden, mit hyperrealistischen Grafiken und riesigen, komplizierten Welten im Spiel. Mit fortschrittlichen Anzeigetechnologien wie 4K-Bildschirmen und hohen Bildwiederholfrequenzen sowie Virtual-Reality-Spielen steigen die Anforderungen an die Grafikverarbeitung rasant. GPUs können Grafiken sowohl in 2D als auch in 3D rendern.
Dank der Parallelverarbeitung durch GPUs können Videos und Grafiken schneller und einfacher in höher aufgelösten Formaten gerendert werden. Darüber hinaus verfügen moderne GPUs über eigene Medien- und Display-Engines, die eine wesentlich energieeffizientere Erstellung und Wiedergabe von Videos ermöglichen.
Die GPU-Technologie kann auch für künstliche Intelligenz und maschinelles Lernen verwendet werden. Weil GPUs außerordentlich viel Rechenleistung bieten, können sie eine unglaubliche Beschleunigung erzielen, die die Parallelverarbeitung bei der Bilderkennung ausnutzt. Viele der heutigen Deep-Learning-Technologien basieren auf GPUs, die in Verbindung mit CPUs arbeiten.[3]
Architekturen
| Familie (Codename) | Chipnamen | Markennamen (mit Umbenennungen) | verbaut in Verkaufsserien (ohne Umbenennungen) |
|---|---|---|---|
| AMD/ATI[5] | |||
| R100 | R100, RV100, RV200, RS100, RS200 | 7xxx, 320-345 | |
| R200 | R200, RV250, RV280, RS300 | 8xxx – 9250 | |
| R300 | R300, R350, RV350, RV380, RS400, RS480 | 9500 – 9800, X300 – X600, X1050 – X1150, 200M | ATI-Radeon-9000-Serie, ATI-Radeon-X-Serie, ATI-Radeon-X1000-Serie |
| R400 | R420, R423, RV410, RS600, RS690, RS740 | X700 – X850, X12xx, 2100 | ATI-Radeon-X-Serie, ATI-Radeon-X1000-Serie |
| R500 | RV515, R520, RV530, RV560, RV570, R580 | X1300 – X2300, HD2300 | ATI-Radeon-X1000-Serie |
| R600 | R600, RV610, RV630, RV620, RV635, RV670, RS780, RS880 | HD2400 – HD4290 | ATI-Radeon-HD-2000-Serie, ATI-Radeon-HD-3000-Serie |
| R700 | RV770, RV730, RV710, RV740 | HD4330 – HD5165, HD5xxV | ATI-Radeon-HD-4000-Serie |
| Evergreen | Cedar, Redwood, Juniper, Cypress, Palm (AMD Wrestler/Ontario), Sumo/Sumo2 (AMD Llano) | HD5430 – HD5970, alle HD6000er, die nicht unter Northern Islands aufgeführt sind, HD7350 | ATI-Radeon-HD-5000-Serie |
| Northern Islands | Aruba (AMD Trinity/Richland), Barts, Turks, Caicos, Cayman | HD6450, HD6570, HD6670, HD6790 – HD6990, HD64xxM, HD67xxM, HD69xxM, HD7450 – HD7670 | AMD-Radeon-HD-6000-Serie |
| GCN 1.0 Southern Islands | Cape Verde, Pitcairn, Tahiti, Oland, Hainan | HD7750 – HD7970, R7 240, R7 250, R9 270, R9-280, R7 370, 520, 530 | AMD-Radeon-HD-7000-Serie, AMD-Radeon-HD-8000-Serie, AMD-Radeon-R200-Serie, AMD-Radeon-500-Serie |
| GCN 1.1 Sea Islands | Bonaire, Kabini, Kaveri und Godavari, Hawaii | HD7790, R7 260, R9 290, R7 360, R9 390 | AMD-Radeon-R200-Serie, AMD-Radeon-R300-Serie |
| GCN 1.2 Volcanic Islands | Tonga, Fiji, Carrizo, Carrizo-L | R9 285, R9 M295X, R9 380, R9 Fury | AMD-Radeon-R300-Serie |
| GCN 4. Generation | Polaris | RX 480, RX 470, RX 460, RX540(X) – RX590 | AMD-Radeon-400-Serie, AMD-Radeon-500-Serie |
| GCN 5. Generation | Vega | RX Vega 56, RX Vega 64 (Liquid Cooled), Vega Frontier Edition, VII | AMD-Radeon-Vega-Serie |
| RDNA | Navi | RX 5700, RX 5700 XT | AMD-Radeon-5000-Serie |
| Nvidia[6] | |||
| NV04 Fahrenheit | Riva TNT, TNT2 | Nvidia Riva | |
| NV10 Celsius | GeForce 256, GeForce 2, GeForce 4 MX | Nvidia-GeForce-256-Serie, Nvidia-GeForce-2-Serie, Nvidia-GeForce-4-Serie MX | |
| NV20 Kelvin | GeForce 3, GeForce 4 Ti | Nvidia-GeForce-2-Serie, Nvidia-GeForce-4-Serie Ti | |
| NV30 Rankine | GeForce 5 / GeForce FX | Nvidia-GeForce-FX-Serie | |
| NV40 Curie | GeForce 6, GeForce 7 | Nvidia-GeForce-6-Serie, Nvidia-GeForce-7-Serie | |
| NV50 Tesla | GeForce 8, GeForce 9, GeForce 100, GeForce 200, GeForce 300 | Nvidia-GeForce-8-Serie, -9-Serie, -100-Serie, -300-Serie | |
| NVC0 Fermi | GeForce 400, GeForce 500 | Nvidia-GeForce-400-Serie, Nvidia-GeForce-500-Serie | |
| NVE0 Kepler | GeForce 600, GeForce 700, GeForce GTX Titan | Nvidia-GeForce-600-Serie, Nvidia-GeForce-700-Serie | |
| NV110 Maxwell | GeForce 750, GeForce 900 | Nvidia-GeForce-900-Serie | |
| NV130 Pascal | GeForce GTX 1060, GeForce GTX 1070(ti), GeForce GTX 1080(ti), Titan X | Nvidia-Geforce-1000-Serie | Nvidia-GeForce-10-Serie |
| NV140 Volta | GV100 | Titan V, Quadro GV100 | |
| NV160 Turing | GeForce RTX 2080 TI, GeForce RTX 2080 Super, GeForce RTX 2080, GeForce RTX 2070 Super, GeForce RTX 2070, GeForce RTX 2060 Super, GeForce RTX 2060 | Nvidia-Geforce-2000-Serie | Nvidia-GeForce-20-Serie |
Stromverbrauch
Nachdem die großen Hersteller von CPUs seit etwa Anfang 2005 begonnen haben, den Stromverbrauch ihrer Produkte insbesondere bei geringer Auslastung teilweise sehr deutlich zu reduzieren, entstand in dieser Hinsicht ein Druck auf die Hersteller von Grafikprozessoren, die bisher jedoch eher das Gegenteil taten: Highend-Grafikkarten wandeln nicht selten selbst ohne Last mehr als 50 W in Verlustwärme um[7], obwohl es in diesem Zustand praktisch keine Leistungsunterschiede zu wesentlich einfacheren Modellen oder Onboard-Grafik gibt. Ende des Jahres 2007 fügte AMD mit der ATI-Radeon-HD-3000-Serie erstmals effiziente Stromsparmechanismen in seine Desktopgrafikkarten ein. Nvidia entwickelte das Verfahren HybridPower, das es erlaubte, eine High-End-Grafikkarte im 2D-Modus auszuschalten und auf den sparsamen Onboard-Grafikchip umzuschalten, wofür allerdings eine Hybrid-SLI-fähige Hauptplatine Voraussetzung war. Nach relativ kurzer Zeit verabschiedete sich Nvidia von diesem Konzept. Inzwischen (2009) beherrschen die GPUs beider Hersteller relativ effiziente Stromsparmechanismen. (Siehe auch: Green IT)
Hersteller
Aktuell
AMD, ARM Limited, Qualcomm, Intel, Nvidia, PowerVR
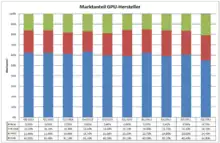
Seit Jahren ist Intel mit Abstand Marktführer bei Grafikprozessoren für PCs. Der Hauptgrund ist die hohe Anzahl von Büro-Computern, die fast nur mit auf der Hauptplatine integrierten Grafikprozessoren ausgestattet sind, die einen Bestandteil der überwiegend von Intel gelieferten Chipsätze darstellen. Im für PC-Spieler geeigneteren Bereich der steckkartenbasierten Grafiklösungen teilen sich AMD und Nvidia den Markt.
Ehemalig
3dfx, 3DLabs, Cirrus Logic, Cyrix, D-Systems, Diamond Multimedia, Matrox, NeoMagic, Oak Technology, S3 Graphics, S3 Inc., SiS, Trident Microsystems, Tseng Labs, XGI Technology Inc.
Aufgrund des starken Wettbewerbs und der damit verbundenen hohen Entwicklungskosten wurden die meisten Hersteller aufgekauft (3dfx, 3DLabs) oder konzentrieren sich auf einen Nischenmarkt (Matrox, XGI).
Weblinks
- Grafikchips 2006–2008 in Zahlen (deutsch)
- GPU-Datenbank (englisch)
- General-Purpose Computation Using Graphics Hardware (englisch)
Einzelnachweise und Anmerkungen
- Mali-G52/V52: ARM bringt neue GPU/VPU für AI-Smartphones – Golem, am 6. März 2018
- Der ehemalige Grafikchip-Hersteller 3DLabs nutzte die Abkürzung VPU, um auf die volle Programmierbarkeit von Fragment- und Vertex-Shadern seiner Produkte zu verweisen.
- Intel Corporation: What Is a GPU?
- ResearchGate GmbH: Graphics processing unit (GPU) programming strategies and trends in GPU computing
- RadeonFeature
- nouveau/CodeNames
- Stromfresser Grafikkarte: 78 Boards im Test (Seite nicht mehr abrufbar, Suche in Webarchiven) Info: Der Link wurde automatisch als defekt markiert. Bitte prüfe den Link gemäß Anleitung und entferne dann diesen Hinweis. . Anmerkung: der GeForce 7600 GS, dem sparsamsten Chip in der Tabelle, werden von einem Test der c't 04/2007 immer noch 10 W im 2D- und 20 bis 27 W im 3D-Betrieb nachgesagt.
| nach Wortbreite |
1-Bit-Architektur • Bit-Slice-Architektur • 4-Bit-Architektur • 8-Bit-Architektur • 16-Bit-Architektur • 32-Bit-Architektur • 64-Bit-Architektur | |
| nach Befehlssatzaufbau | ||
| mit Optimierung für Einsatzzweck |
(Haupt-)Prozessor • Grafikprozessor • GPGPU • Streamprozessor • Soundprozessor • Gleitkommaeinheit • Netzwerkprozessor • Physikbeschleuniger • Vektorprozessor • TensorFlow Processing Unit |