Von-Neumann-Architektur
Die Von-Neumann-Architektur (VNA) ist ein Referenzmodell für Computer, wonach ein gemeinsamer Speicher sowohl Computerprogrammbefehle als auch Daten hält. Von-Neumann-Systeme gehören nach der Flynnschen Klassifikation zur Klasse der SISD-Architekturen (Single Instruction, Single Data), im Unterschied zur Parallelverarbeitung.

Die Von-Neumann-Architektur bildet die Grundlage für die Arbeitsweise der meisten heute bekannten Computer. Sie ist benannt nach dem österreichisch-ungarischen, später in den USA tätigen Mathematiker John von Neumann, dessen wesentliche Arbeit zum Thema 1945 veröffentlicht wurde. Sie wird manchmal auch Princeton-Architektur genannt (nach der Princeton University).
Eine oft in der Lehre vorgestellte Konkurrenzarchitektur ist die Harvard-Architektur.
Entwicklung
Von Neumann beschrieb das Konzept 1945 in dem zunächst unveröffentlichten Papier „First Draft of a Report on the EDVAC“[1] im Rahmen des Baus der EDVAC-Rechenmaschine. Es war seinerzeit revolutionär, denn zuvor entwickelte Rechner waren an ein festes Programm gebunden, das entweder hardwaremäßig verschaltet war oder über Lochkarten eingelesen werden musste. Mit der Von-Neumann-Architektur war es nun möglich, Änderungen an Programmen sehr schnell und ohne Änderungen an der Hardware durchzuführen oder in kurzer Folge verschiedene Programme ablaufen zu lassen.
Viele Ideen der Von-Neumann-Architektur waren schon 1936 von Konrad Zuse ausgearbeitet, in zwei Patentschriften 1937 dokumentiert und größtenteils bereits 1938 in der Z1-Maschine mechanisch realisiert worden. 1941 baute Konrad Zuse in Zusammenarbeit mit Helmut Schreyer mit der Zuse Z3 den ersten funktionsfähigen Digitalrechner der Welt. Es gilt aber als unwahrscheinlich, dass von Neumann die Arbeiten Zuses kannte, als er 1945 seine Architektur vorstellte.
Die meisten der heute gebräuchlichen Computer basieren auf dem Grundprinzip der Von-Neumann-Architektur, d. h. ihre Eigenschaften entsprechen denen einer VNA. Dies bedeutet jedoch typischerweise nicht mehr, dass sie intern wie eine einfache VNA mit den wenigen VNA-Funktionsgruppen aufgebaut sind. Im Laufe der Zeit wurden viele der ursprünglich als einfache VNA-Rechnerarchitekturen erdachten, z. B. die x86-Architektur, jenseits davon ausdifferenziert und weitaus komplexer weiterentwickelt. Dies geschah, um Leistungszuwächse zu erzielen, ohne jedoch mit dem leicht beherrschbaren VNA-Modell zu brechen, d. h. aus Softwaresicht kompatibel zu diesem zu bleiben, um dessen Vorteile weiter nutzen zu können.
Mit dem Trend der wachsenden Zahl von parallelen Recheneinheiten (Multicore) und Bussen (z. B. HyperTransport) wird diese Kompatibilität immer aufwendiger und schwieriger zu realisieren. Es ist daher zu erwarten, dass in absehbarer Zukunft ein Paradigmenwechsel zu einem anderen, parallelen Architekturmodell notwendig sein wird, um Leistungszuwächse in Rechnerarchitekturen erzielen zu können. Erste Vorboten sind zum Beispiel das aufkommende NUMA-Computing, bei dem der Speicher nicht mehr als mit „uniformen“-Eigenschaften behaftet betrachtet wird.
Konzept
Die Von-Neumann-Architektur ist ein Schaltungskonzept zur Realisierung universeller Rechner (Von-Neumann-Rechner, VNR). Sie realisiert alle Komponenten einer Turingmaschine. Dabei ermöglicht ihre systematische Aufteilung in die entsprechenden Funktionsgruppen jedoch die Nutzung spezialisierter binärer Schaltwerke und damit eine effizientere Strukturierung der Operationen.
Im Prinzip bleibt es aber dabei, dass alles, was mit einer Turingmaschine berechenbar ist, auch auf einer Maschine mit Von-Neumann-Architektur berechenbar ist und umgekehrt. Gleiches gilt für alle höheren Programmiersprachen, die durch einen Compiler oder Interpreter auf die binäre Repräsentation abgebildet werden. Sie vereinfachen zwar das Handling der Operationen, bieten jedoch keine Erweiterung der von der Turingmaschine vorgegebenen Semantik. Dies wird daran deutlich, dass die Übersetzung aus einer höheren Programmiersprache in die binäre Repräsentation wiederum von einem binären Programm ohne Anwenderinteraktion vorgenommen wird.
Komponenten
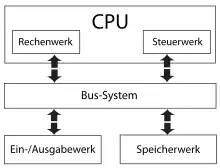
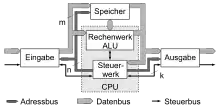
Ein Von-Neumann-Rechner beruht auf folgenden Komponenten, die bis heute in Computern verwendet werden:
- ALU (Arithmetic Logic Unit) Rechenwerk
- selten auch Zentraleinheit oder Prozessor genannt, führt Rechenoperationen und boolesche Verknüpfungen aus. (Die Begriffe Zentraleinheit und Prozessor werden im Allgemeinen in anderer Bedeutung verwendet.)
- Control Unit Steuerwerk oder Leitwerk
- interpretiert die Anweisungen eines Programms und verschaltet dementsprechend Datenquelle, -senke und notwendige ALU-Komponenten; das Steuerwerk regelt auch die Befehlsabfolge.
- BUS Bus System
- dient zur Kommunikation zwischen den einzelnen Komponenten (Steuerbus, Adressbus, Datenbus)
- Memory – (RAM/Arbeitsspeicher) Speicherwerk
- speichert sowohl Programme als auch Daten, welche für das Rechenwerk zugänglich sind.
- I/O Unit – Eingabe-/Ausgabewerk
- steuert die Ein- und Ausgabe von Daten, zum Anwender (Tastatur, Bildschirm) oder zu anderen Systemen (Schnittstellen).
Prinzipien des Modells
Diese Komponenten arbeiten Programmbefehle nach folgenden Regeln ab.
- Prinzipien des gespeicherten Programms:
- Befehle werden geladen und Steuersignale an andere Funktionseinheiten gesendet
- Befehle sind in einem RAM-Speicher mit linearem (1-dimensionalem) Adressraum abgelegt.
- Ein Befehls-Adressregister, genannt Befehlszähler oder Programmzähler, zeigt auf den nächsten auszuführenden Befehl.
- Befehle können wie Daten geändert werden.
- Prinzipien der sequentiellen Programm-Ausführung (siehe auch Von-Neumann-Zyklus):
- Befehle werden aus einer Zelle des Speichers gelesen und dann ausgeführt.
- Normalerweise wird dann der Inhalt des Befehlszählers um Eins erhöht.
- Es gibt einen oder mehrere Sprung-Befehle, die den Inhalt des Befehlszählers um einen anderen Wert als +1 verändern.
- Es gibt einen oder mehrere Verzweigungs-Befehle, die in Abhängigkeit vom Wert eines Entscheidungs-Bit den Befehlszähler um Eins erhöhen oder einen Sprung-Befehl ausführen.
Eigenschaften
Vorteile
Der streng sequentielle Ablauf einer Von-Neumann-Architektur ist der entscheidende Vorteil gegenüber anderen, parallelen Architekturen (z. B. Rechnerverbund, Harvard-Architektur) und der Grund für die ungebrochene Popularität dieser Architektur. Aus der Sicht des Programmierers ist ein einfacher, deterministischer Programmablauf garantiert, Race Conditions und Daten-Inkohärenzen sind durch den einzelnen Bus, über den die CPU auf Daten und Programm zugreift, ausgeschlossen.
Von-Neumann-Flaschenhals
Der Von-Neumann-Flaschenhals der Von-Neumann-Architektur beschreibt Performance-Verringerungen von Prozessoren durch konkurrierende Daten- und Befehlscode-Zugriffe über einen gemeinsamen Bus. Weitergehend beschreibt der Von-Neumann-Flaschenhals auch das für diesen Sachverhalt verantwortliche Konzept des „immer nur eine Sache auf einmal“ (eng. Original: one-word-at-a-time thinking), also den expliziten, erzwungenen Sequentialismus durch den einzigen Bus, über den alle Aktionen laufen.
Der Begriff selbst, „Von-Neumann-Flaschenhals“ (eng. Von Neumann bottleneck), wurde von John W. Backus geprägt, der ihn 1977 in seinem Vortrag anlässlich der Verleihung des Turing Awards einführte:[2]
“Surely there must be a less primitive way of making big changes in the store than by pushing vast numbers of words back and forth through the von Neumann bottleneck. Not only is this tube a literal bottleneck for the data traffic of a problem, but, more importantly, it is an intellectual bottleneck that has kept us tied to one word-at-a-time thinking instead of encouraging us to think in terms of the larger conceptual units of the task at hand. Thus programming is basically planning and detailing the enormous traffic of words through the von Neumann bottleneck, and much of that traffic concerns not significant data itself, but where to find it.”
„Sicherlich muss es einen weniger primitiven Weg geben, große Änderungen im Speicher vorzunehmen, als riesige Mengen von Wörtern durch den Von-Neumann-Flaschenhals hin und her zu drücken. Nicht nur ist diese Röhre ein buchstäblicher Flaschenhals für den Datenverkehr eines Problems, sondern, viel wichtiger, es ist ein intellektueller Flaschenhals, der uns an Ein-Wort-zu-einer-Zeit-Denken fesselte, anstatt uns zu ermutigen, in größeren konzeptionellen Einheiten der anstehenden Aufgabe zu denken. Folglich ist Programmieren grundsätzlich die Planung und die Detaillierung des enormen Verkehrs von Wörtern durch den Von-Neumann-Flaschenhals und ein Großteil jenes Verkehrs betrifft nicht diese Daten selbst, sondern wo was zu finden ist.“
Mit dem Aufkommen von getrennten Caches für Daten und Befehle ist der Von-Neumann-Flaschenhals ein akademisches Problem geworden. In modernen Prozessoren ist die Entkopplung von Speicher und Rechenwerken über mehrere Cache-Hierarchien so weit fortgeschritten, dass unzählige Befehlsdecoder und Rechenwerke sich die Ressource Hauptspeicher ohne große Performance-Verluste teilen.
Von Neumann
Die Von-Neumann-Architektur erlaubt das Lesen eines Befehlscode-Worts oder das Lesen eines Datenworts oder das Schreiben eines Datenwortes. Befehlscode-Lesen und Daten-Lesen und -Schreiben konkurrieren.
Harvard
Die Standard-Harvard-Architektur erlaubt das gleichzeitige Lesen eines Befehlscode-Worts und das Lesen oder Schreiben eines Datenworts. Das erlaubt eine gewisse Parallelisierung der Befehlscode-Abarbeitung. Befehle aus mehreren Worten wie auch Read-Modify-Write-Zugriffe auf Daten verhindern allerdings auch hier, dass Befehle innerhalb eines Speicherzyklus abgearbeitet werden können. Befehle ohne Datenspeicher-Zugriffe werden gegenüber einer Von-Neumann-Architektur nicht beschleunigt.
CPU-Kern
^ ^
| v
RAM-Ctrl RAM-Ctrl
Eine klassische Standard-Harvard-Architektur mit strikter Trennung von Befehls- und Datenbus ist außer in Spezialfällen unüblich. Es wären nur fertige Programme in nichtflüchtigen Speicher ausführbar. Nachladen von Programmen, Programme kompilieren und ausführen sind nicht möglich.
Super-Harvard
Die Super-Harvard-Architekturen findet man häufig in DSPs, die zwei oder vier Bussysteme haben. Beispiele sind Motorola 56001 und Texas Instruments TMS320.
CPU-Kern
^ ^ ^
| v v
RAM-Ctrl RAM-Ctrl RAM-Ctrl
Üblich ist auch eine Aufweichung der Trennung der Bussysteme. Jeder Bus kann sowohl Code wie Daten liefern. Kollisionen vermindern die Performance. Neben Befehlsabarbeitungen durch den CPU-Kern sind weitere Speicherzugriffe durch DMA-Controller und Video-Controller üblich.
CPU-Kern + Dma-Ctrl
^ ^ ^ ^
v v v v
RAM-Ctrl RAM-Ctrl RAM-Ctrl RAM-Ctrl
1993
CPU Kern
zwei Rechenwerke
^ ^
| v
L1I L1D
| |
+-----+----+
RAM-Controller
1997
CPU Kern
mehrere Rechenwerke
^ ^ |
| | v
L1I L1D
| |
+-----+----+
L2
|
RAM-Controller
2008
CPU Kern 1 CPU Kern 2 CPU Kern 3 ... CPU Kern N
mehrere Rechenwerke mehrere Rechenwerke mehrere Rechenwerke mehrere Rechenwerke
^ ^ ^ | ^ ^ ^ | ^ ^ ^ | ^ ^ ^ |
| | | v | | | v | | | v | | | v
L1I L1D L1I L1D L1I L1D L1I L1D
| | | | | | | |
+----L2----+ +----L2----+ +----L2----+ +----L2----+
| | | |
+----L3---------------------L3---------------------L3---------------------L3-----+
| |
+--------------------------------------+-----------------------------------------+
RAM-Controller
Dual-Sockel-Server-System
Sockel 1 Sockel 2
CPU Kern 1 CPU Kern 2 CPU Kern 3 ... CPU Kern N CPU Kern 1 CPU Kern 2 CPU Kern 3 ... CPU Kern N
mehrere Rechenwerke mehrere Rechenwerke mehrere Rechenwerke mehrere Rechenwerke mehrere Rechenwerke mehrere Rechenwerke mehrere Rechenwerke mehrere Rechenwerke
^ ^ ^ | ^ ^ ^ | ^ ^ ^ | ^ ^ ^ | ^ ^ ^ | ^ ^ ^ | ^ ^ ^ | ^ ^ ^ |
| | | v | | | v | | | v | | | v | | | v | | | v | | | v | | | v
L1I L1D L1I L1D L1I L1D L1I L1D L1I L1D L1I L1D L1I L1D L1I L1D
| | | | | | | | | | | | | | | |
+----L2----+ +----L2----+ +----L2----+ +----L2----+ +----L2----+ +----L2----+ +----L2----+ +----L2----+
| | | | | | | |
+----L3---------------------L3---------------------L3---------------------L3-----+ +----L3---------------------L3---------------------L3---------------------L3-----+
| +--------------+ |
+--------------------------------------+-----------------------------------------+ +---------------------------------------+----------------------------------------+
RAM-Controller RAM-Controller
Memory-Wall
Da bei einer Von-Neumann-Architektur im Gegensatz zur Harvard-Architektur nur ein gemeinsamer Bus für Daten und Befehle genutzt wird, müssen sich diese die maximal übertragbare Datenmenge aufteilen. Bei frühen Computern stellte die CPU die langsamste Einheit des Rechners dar, d. h., die Datenbereitstellungszeit war nur ein geringer Anteil an der gesamten Verarbeitungszeit für eine Rechenoperation. Seit geraumer Zeit jedoch wuchs die CPU-Verarbeitungsgeschwindigkeit deutlich stärker als die Datentransferraten der Busse oder der Speicher, was den Einfluss des Von-Neumann-Flaschenhalses verschärft. Der Begriff der „memory wall“ bezeichnet dieses wachsende Ungleichgewicht zwischen der Geschwindigkeit der CPU und des Speichers außerhalb des CPU-Chips.
Von 1986 bis 2000 wuchsen die CPU-Geschwindigkeiten jährlich um 55 %, während die Speichertransfergeschwindigkeiten nur um 10 % anstiegen. Diesem Trend folgend wurde die Speicherlatenz der Flaschenhals der Computerrechenleistung.[3] Als erste Maßnahme wurden schon früh Datenregister eingeführt. Heute nimmt bei leistungsstarken Prozessoren ein dreistufiger Cache etwa die Hälfte der Chipfläche ein und führt die allermeisten Lade- und Schreibbefehle aus, ohne dass der Hauptspeicher zunächst beteiligt ist.
Vergleich zur Harvard-Architektur
Eine der wichtigsten Konkurrenzarchitekturen ist die Harvard-Architektur mit einer physischen Separierung von Befehls- und Datenspeicher, auf die über getrennte Busse zugegriffen wird, also unabhängig und parallel. Der Vorteil dieser Architektur besteht darin, dass Befehle und Daten gleichzeitig geladen bzw. geschrieben werden können, also der Von-Neumann-Flaschenhals umgangen werden kann.
Die physikalische Trennung von Daten und Programm sorgt dafür, dass eine Zugriffsrechtetrennung und Speicherschutz einfach realisierbar sind. Wurde für den Programmcode ein im Betrieb nur lesbarer Speicher verwendet, so ist das Überschreiben selbst durch Schadcode ausgeschlossen. Nachteilig ist allerdings, dass nicht benötigter Datenspeicher nicht als Programmspeicher genutzt werden kann (und umgekehrt), also eine erhöhte Speicherfragmentierung auftritt.
Siehe auch
- Johnny-Simulator, eine Software-Implementierung eines Von-Neumann-Rechners mit zehn vordefinierten Befehlen
Weblinks
- Erklärung des Von Neumann Rechners des Department Informatik der Uni Hamburg mit Java-Applet zur Simulation
- MOPS ist ein Modellrechner mit Von-Neumann-Architektur
- JOHNNY ist ein vereinfachter Modellrechner mit Von-Neumann-Architektur speziell für den Informatikunterricht (Open Source)
Fußnoten
- John von Neumann: First Draft of a Report on the EDVAC. In: IEEE Annals of the History of Computing. Vol. 15, Issue 4, 1993, doi:10.1109/85.238389, S. 27–75 (PDF, 9,556 MB)
- John Backus: Can Programming Be Liberated from the von Neumann Style? A Functional Style and Its Algebra of Programs. In: Communications of the ACM. Vol. 21, No. 8, August 1978, S. 615 (PDF, 3,0 MB)
- William A. Wulf, Sally A. McKee: Hitting the Memory Wall: Implications of the Obvious. In: Computer Architecture News. Vol. 23, Issue 1, März 1995, doi:10.1145/216585.216588, S. 20–24 (PDF, 20 KB)