TRIPS-Prozessor
Der TRIPS-Prozessor (Tera-op, Reliable, Intelligently adaptive Processing System) ist ein Forschungsprozessor der University of Texas at Austin. Die Prozessorarchitektur ist so ausgelegt, dass sich weitere Kerne möglichst einfach hinzufügen lassen. Das Projekt wird von IBM und der DARPA gefördert.

Die TRIPS-Architektur soll ein Nachfolger der gängigen RISC-Architektur werden und wird als EDGE-Architektur bezeichnet. Die EDGE-Architektur weist Blöcke auf, die elementare Anweisungen unabhängig voneinander ausführen, sowie datengesteuerte (out-of-order) Anweisungsausführung.
TRIPS wird entwickelt, um Prozessoren mit mehr als einem Teraflop zu realisieren. Auch Intels Terascale-Prozessor wird in diesem Zusammenhang entwickelt, basiert jedoch auf einer anderen Architektur mit gleichartigen Rechenelementen.
Aufbau der Architektur
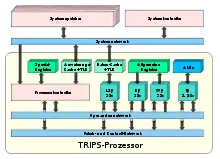
Der TRIPS-Prozessor besteht aus einer oder mehreren Arithmetisch-logische Einheit (ALU), Caches und Registern. Die ALUs führen Ganzzahl- und Gleitkomma-Rechenoperationen aus. Für Daten und Instruktionen sind getrennte Caches vorgesehen. Zusätzlich sind mehrere Übersetzungspuffer (TLB) vorgesehen, welche virtuelle auf physische Adressen abbilden.
Bei den Registern unterscheidet man beim TRIPS zwischen allgemeinen und speziellen Registern (Special Function Register, SFC). Allgemeine Register werden verwendet, um beliebige Daten oder Adressen zu speichern. Spezialregister sind für die Konfiguration und Kontrolle des Prozessorstatus zuständig.
Im Gegensatz zu herkömmlichen RISC-Prozessoren definiert der TRIPS-Prozessor eine Reihe von internen Queues und sind Teil des Befehlssatzes und des Datenflussmodells. Dies ermöglicht es, eine Serie von Anweisungen als Block auszuführen, anstatt immer nur einzelne Befehle. Die Anweisungs-Queue (Instruction Queue, IQ) kann hierbei bis zu 128 Instruktionen gleichzeitig verarbeiten, die Lese-Queue (Read Queue, RQ) puffert 32 Lesezugriffe auf allgemeine Register und die Schreib-Queue (Write Queue, WQ) puffert bis zu 32 schreibende Zugriffe auf allgemeine Register. Eine zusätzliche Laden- und Halten-Queue (Load & Store Queue, LSQ) puffert 32 Speicherzugriffe. Queues puffern hierbei nur transiente Zustände, während persistente Zustände in Registern, Caches und dem Systemspeicher gehalten werden.
Der Rest des TRIPS besteht aus einem systemweiten Netzwerk, welches die einzelnen Rechenblöcke miteinander verbindet. Zugriffe von Prozessoren, die über dieses Netzwerk auf einen gemeinsamen Speicher zugreifen wollen, werden von einem Systemkontroller gesteuert.
Implementierung

TRIPS-Prozessoren werden aus einzelnen Kacheln (Tiles) aufgebaut, wobei jedes Kachel eine elementare Funktion erfüllt. Die einzelnen Tiles werden in eine zweidimensionalen Anordnung (Array) gebracht. Man unterscheidet hierbei die folgenden Arten von Tiles:
- die Execution Tiles (ET) enthalten IQ und ALU.
- die Register Tiles (RT) enthalten allgemeine Register, RQ und WQ.
- die Data Tiles (DT) enthalten Daten-Cache, Daten-TLB und LSQ.
- die Instruction Tiles (IT) enthalten Anweisungs-Cache und Anweisungs-TLB.
- das Global Control Tile (GT) enthält die Spezialregister und die Logik des globalen Prozessorkontrollers.
Die meisten Prozessorressourcen werden zusätzlich in Bänke unterteilt und können somit auf mehrere Tiles verteilt sein. Die TRIPS-Architektur bildet dadurch eine Grid-Architektur auf Prozessorebene. Dies erlaubt hohe Taktfrequenzen, hohe Parallelität der Instruktionen und gute Erweiterbarkeit. Da es in einer solchen Grid-Architektur zu hohen Latenzen kommen kann, wenn Daten von einem Tile zu einem weit entfernten Tile gebracht werden müssen, könnte es hierbei jedoch zu Skalierungsproblemen kommen, weshalb die Skalierbarkeit des Systems derzeit noch eingehender anhand von Prototypen untersucht wird.
Ein Vorteil der Architektur ist es, dass die Queues und Register durch eine mehrfache Ausführung identischer Tiles mehrfach vorhanden sind. Dadurch können eine sehr hohe Anzahl an Instruktionen sowie bis zu vier Threads parallel und dadurch gleichzeitig bearbeitet werden.
Erster Prototyp
Im ersten – im Frühling 2007 realisierten – TRIPS-Prototyp werden zwei TRIPS-Prozessorkerne und ein L2-Cache (Secondary Memory System) mit Schnittstellen zur Peripherie des Mainboards auf dem Prozessor-Die gefertigt.
| Kürzel | Name | Beschreibung |
|---|---|---|
| NT | Network-Tile | Bilden ein Netzwerk, in dem Daten aus und in den Speicher transportiert werden. |
| MT | Memory-Tile | Bilden den Speicher des L2-Cache, in dem Daten gespeichert werden. |
| DMA | Direct Memory Access | Kontroller für den Speicherdirektzugriff (Northbridge) |
| SDC | Static DRAM Controller | Bietet Speicherzugriff auf die SDRAM-Bänke des Arbeitsspeichers |
| EBC | External Bus Controller | Stellt die Verbindung mit Bussen (Southbridge) her, die sich außerhalb des Prozessors befinden, und kümmert sich um Unterbrechungsanforderungen (Interrupt Request, IRQ) und externe Busschnittstellen (External Bus Interface, EBI). |
| C2C | Chip-to-Chip Connector | Dient dazu, eine direkte Verbindung mit anderen TRIPS-Prozessoren herzustellen. Der C2C ist im TRIPS-Prozessor vierfach vorhanden, um Arrays aus TRIPS-Prozessoren zu bilden und damit Rechencluster aufbauen zu können. |
Der Prototyp wurde in einem 130 nm Prozess als ASIC gefertigt und besteht aus etwa 170 Millionen Transistoren. Der TRIPS-Prozessor beherrscht 4-faches Multithreading und kann bis zu 16 Instruktionen je Takt und Prozessor bei einer Taktfrequenz 500 MHz ausführen. Dies resultiert in einer Spitzenleistung von 16 GOps (16 Milliarden Operationen je Sekunde).
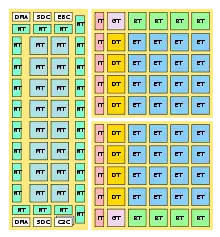 Anordnung der Tiles im TRIPS-Prototypen |
 Layout des TRIPS-Prototypen |
 Foto des TRIPS-Prototypen |
Mikrobusse
Die einzelnen Tiles im Array werden untereinander über einfache Mikronetzwerke verbunden. Man unterscheidet hierbei die in der folgenden Tabelle aufgeführten Mikrobusse:
| Kürzel | Name des Busses | |
|---|---|---|
| ∎∎∎ | GDN | Global Dispatch Network |
| ∎∎∎ | GSN | Global Status Network |
| ∎∎∎ | OPN | Operand Network |
| ∎∎∎ | GCN | Global Control Network |
| ∎∎∎ | OCN | On Chip Network |
| ∎∎∎ | GRN | Global Refill Network |
| ∎∎∎ | ESN | External Store Network |
| ∎∎∎ | DSN | Data Status Network |
Die in der Tabelle aufgeführten Farben entsprechen hierbei den Farben der Busse in der nebenstehenden Abbildung.
Execution Tile
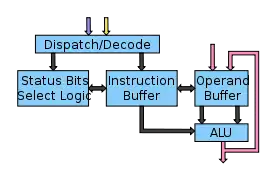
Jeder der 16 Execution Tiles besteht aus einer einfachen Daten-Pipeline, einer Bank von 64 Reservierungsstationen (reservation station) und einer Integer- sowie einer Gleitkomma-Einheit. Alle Einheiten mit Ausnahme der Divisionseinheit sind als Pipeline-Architektur ausgeführt. Die Divisionseinheit benötigt 24 Takte.
Die Reservierungsstationen enthalten je acht Anweisungen für jeden der acht TRIPS-Blöcke, wodurch die TRIPS-Blöcke kontinuierlich angesteuert werden. Jede Reservierungsstation besitzt Felder für zwei 64-Bit Operanden und einem 1-Bit Prädikat.
Register Tile
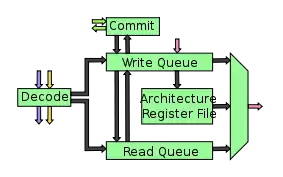
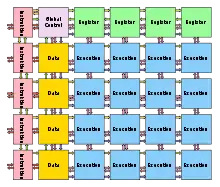
Die Mikroarchitektur des TRIPS-Prozessors wird in Register und Bänke unterteilt, um den Stromverbrauch und die Zeitverzögerungen zu verringern. Jedes Register Tile enthält eine Bank sowie eine Verbindung mit dem Operand Network. Dies erlaubt es dem Compiler, wichtige Schreib-/Lese-Anweisungen in einem Register zu platzieren, das sich nahe dem zu beschreibenden bzw. auszulesenden Register befindet.
Daten, die sofort nach der Definition gelesen werden, werden vom Compiler nicht im Register abgelegt, wodurch die Datendurchsatz-Bandbreite des Registers um etwa 70 % niedriger ausfallen kann als bei einem Register eines RISC- oder CISC-Prozessors. Die vier verteilten Bänke haben deshalb trotz einer geringen Anzahl an Anschlüssen (2×Lesen und 1×Schreiben) eine ausreichende Bandbreite.
Jeder der vier Register Tiles enthält eine 32-Register große Bank für jeden der vier vom Kern unterstützten SMT-Threads. Auf diese Weise sind für jeden Thread 128 Register verfügbar, die auf die 128 Register großen Bänke der Register Tiles verteilt werden.
Zusätzlich enthält jedes Register Tile eine Schreib- und eine Lese-Queue. Die Schreib-Queue enthält bis zu acht Lesezugriffe und die Lese-Queue enthält bis zu acht Schreibzugriffe. Die Queues stellen eine dynamische und kontinuierliche Weiterleitung der Zugriffe auf die Register sicher.
Data Tile
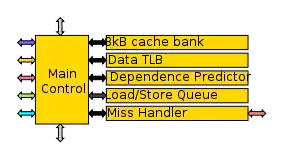
Jedes Data Tile ist ein Teilnehmer im Operand Network. Es enthält eine 2-Wege L1-cache Bank mit 8 kB Größe. Virtuelle Adressen sind über die Data Tiles in einem Interleaving-Verfahren in einer Cache-Reihe mit 64 Bytes verteilt.
Zusätzlich zur L1-Cache Bank enthält jedes Data Tile eine Kopie der Laden-/Speichern-Queue, eine Abhängigkeitsvorhersage, einen rückseitig zusammenführenden Schreibpuffer mit einem Eintrag, einer Daten-TLB und einem modellspezifischen Halte-Register (Modell Specific Hold Register, MSHR). Das MSHR behandelt bis zu 16 Anfragen für bis zu vier Cache-Lines.
Da die Data Tiles im Netzwerk verteilt sind, wurde eine speicherseitige Abhängigkeitsvorhersage implementiert, welche mit jeder Datencachebank verbunden ist. Die Abhängigkeitsvorhersage in jedem Data Tile verwendet einen 1024 Bit langen Bitvektor.[1]
Instruction Tile
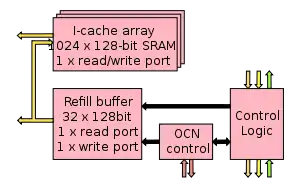
Das Instruction Tile beherbergt einen lokalen 2-Wege 16 kB L1-Cache und wird vom Global Control Tile angesteuert. Das Global Control Tile enthält hierfür eine Tabelle, welche die Position der Daten in den Instruction Tiles speichert.
Jedes der fünf 16 kB Bänke speichert einen 128-Byte großen Block. Hierdurch macht der L1-Cache in Summe 640 Bytes aus und wird auf 128 Blöcke verteilt.
Global Control Tile
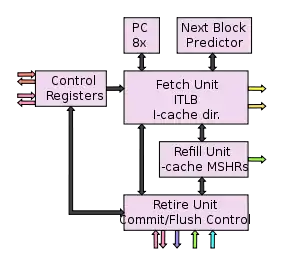
Das Global Control Tile enthält Anweisungscache-Tag-Arrays, die Anweisungs-TLB (I-TLB) und die Nächster-Block-Vorhersage (next block predictor). Das Global Control Tile behandelt das Management für die TRIPS-Blockverwaltung.
Die Blockverwaltung beinhaltet hierbei die Vorhersage, Fetching, Weiterleitung (Dispatching), Vervollständigungsdetektierung, Leeren des Caches (flushing) bei Falschvorhersagen oder Interrupts, sowie das Commit.
Zudem enthält das Global Control Tile spezielle Register um die Spekulations-, Ausführungs- und Threading-Modi an die jeweiligen Anforderungen anzupassen.
Memory Tile
Der TRIPS-Prototyp besitzt einen 1 MB große statischen NUCA-Speicher,[2] welcher in 16 Speicher-Tiles (Memory Tile, MT) unterteilt wird. Jedes Memory Tile enthält eine 64 kB große 4-Wege Speicherbank. Zudem enthalten die Memory Tiles einen OCN-Router sowie einem MSHR mit einem einzelnen Eintrag.
Jede Speicherbank kann über einen Konfigurationsbefehl vom OCN als L2-Cache oder als Notizspeicher konfiguriert werden. Jedes IT/DT-Paar verfügt über eine eigene Schnittstelle zum Secondary Memory System. Dadurch wird eine hohe Bandbreite vom Speicher zu den Kernen gewährleistet um Streaming-Anwendungen zu ermöglichen.
siehe auch: Datenstrom
Network Tile
Um das Speichersystem der Memory Tiles herum sind die Network Tiles angeordnet. Die Network Tiles enthalten eine programmierbare Routingtabelle mit welchem das Ziel einer Speicheranforderung bestimmt wird. Durch die Ansteuerung der TLBs und der NTs über das Programm kann der Speicher auf verschiedene Arten aufgeteilt werden.
Programmierung
Der TRIPS-Prozessor verwendet eine Block-Atomare Ausführung. Dies bedeutet, dass Anweisungen nicht einzeln, sondern als Block verarbeitet werden. Ein Programm-Zähler (program counter, PC), wobei es sich um einen Zeiger handelt, speichert die aktuell ausgeführte Stelle im Programm.
Ein Programm-Block besteht hierbei aus dem Laden von Daten (Fetch), dem Ausführen einer Reihe von Anweisungen (Execute), sowie dem Zurückschreiben von Daten in den Speicher (Commit). Im Programm-Block werden bis zu 128 Befehle zusammengefasst. Sobald in einem dieser Befehle ein Fehler auftritt wird der ganze Block, ohne die Möglichkeit die Fehlerstelle exakt zu bestimmen, verworfen.
Der TRIPS-Prozessor kann durch Pipelining-Techniken bis zu 8 Programm-Blöcke gleichzeitig verarbeiten. Hierbei wird die Sprungvorhersage eingesetzt um den nächsten zur Ausführung benötigten Block abzuschätzen.
Datenflussausführung
Die einzelnen Anweisungsblöcke werden nicht wie in traditionellen Prozessoren in der Reihenfolge der Anweisungen verarbeitet, sondern in der Reihenfolge des Datenflusses. Die Abhängigkeiten der Anweisungen voneinander werden direkt in den Anweisungen selbst gespeichert. Eine Anweisung wird ausgeführt sobald alle von der Anweisung benötigten Daten verfügbar sind.
Sprungausführung
Die meisten Befehle des TRIPS-Prozessors sind so ausgelegt, dass ihre Ausführung vom erfolgreichen Test eines logischen Vergleichs mit einem booleschen Ergebnis abhängig gemacht werden kann. Jede Anweisung ist hierfür von einem Tristate-Prädikat abhängig. Eine Anweisung wird daher entweder immer ausgeführt, oder nur wenn das zugehörige Prädikat wahr bzw. falsch ist. Das Prädikat kann jedoch nur innerhalb eines Anweisungsblocks verwendet werden.
Sollen Werte infolge eines Sprunges nicht verändert werden, so wird eine null-Anweisung ausgeführt, welche ein NULL-Token bewirkt. Erreicht ein NULL-Token eine Speicher- oder Schreibanweisung, so wird diese Anweisung nicht ausgeführt, wodurch der Speicherzustand gehalten wird.
Schwieriger ist hierbei der Zusammenhang mit dem bedingten Laden von Daten aus dem Speicher. Da der Speicher sehr langsam ist sollten keine Daten geladen werden die nicht benötigt werden. Allerdings kann jedoch meist erst zur Laufzeit bestimmt werden, ob dies erforderlich ist. Wird von der LSQ festgestellt, dass ein Wert geladen und zur Ausführung gebracht wurde, ohne dass eine Anweisung diesen benötigt (Page-Miss), muss der Anweisungsblock erneut ausgeführt werden. Deshalb wird ein load dependance predictor eingesetzt um eine Abhängigkeitsanalyse durchzuführen. Dadurch kann zumeist festgestellt werden ob ein Wert tatsächlich aus dem Speicher geladen werden muss.
Datenformate
Die TRIPS Architektur unterstützt Datenbreiten mit 8 Bit (Byte, Oktett), 16 Bit (Halbwort), 32 Bit (Wort) und 64 Bit (Doppelwort). Die Interpretation der Daten als vorzeichenbehaftete Größen oder Gleitkommazahlen wird durch die Anweisungen festgelegt.
Anweisungs-Formate
Der TRIPS-Prozessor verwendet spezifische VLIW-Anweisungen. Die dabei verwendete Sprache wird als TRIPS Assembler Sprache (TRIPS Assembly Language, TASL) bezeichnet. Hierbei unterscheidet man zwischen sechs verschiedenen Formaten mit unterschiedlicher Bitlängen von bis zu 32 Bit.
┌──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┐
│31│30│29│28│27│26│25│24│23│22│21│20│19│18│17│16│15│14│13│12│10│09│08│07│06│05│04│03│02│01│00│ Bit
├──┴──┴──┴──┴──┴──┴──┼──┴──┼──┴──┴──┴──┼──┴──┴──┴──┴──┴──┴──┴──┴──┼──┴──┴──┴──┴──┴──┴──┴──┴──┤
│ OPCODE │ PR │ XOP │ T1 │ T0 │ G
├────────────────────┼─────┼───────────┼──────────────────────────┼──────────────────────────┤
│ OPCODE │ PR │ XOP │ IMM │ T0 │ I
├────────────────────┼─────┼───────────┼──────────────────────────┼──────────────────────────┤
│ OPCODE │ PR │ LSID │ IMM │ T0 │ L
├────────────────────┼─────┼───────────┼──────────────────────────┼──────────────────────────┤
│ OPCODE │ PR │ LSID │ IMM │ 0 │ S
├────────────────────┼─────┼────────┬──┴──────────────────────────┴──────────────────────────┤
│ OPCODE │ PR │ EXIT │ OFFSET │ B
├────────────────────┼─────┴────────┴─────────────────────────────┬──────────────────────────┤
│ OPCODE │ CONST │ T0 │ C
└────────────────────┴────────┬──┬──────────────┬─────────────────┴──┬───────────────────────┤
│V │ GR │ RT1 │ RT0 │ R
└──┴──────────────┴────────────────────┴─────┬──┬──────────────┤
│V │ GR │ W
└──┴──────────────┘
| Code | Bedeutung | Beschreibung |
|---|---|---|
| G | Global | Anweisungsformat für den globalen Kontroller |
| I | Instruction | Instruktionspufferformat |
| L | Load | Ladeanweisungsformat |
| S | Store | Speicheranweisungsformat |
| B | Branch | Sprunganweisung |
| C | Constant | Anweisung mit einem Datenwert |
| R | Read | Lesen aus dem Speicher |
| W | Write | Schreiben in den Speicher |
| Code | Bedeutung |
|---|---|
| OPCODE | Primary Opcode |
| XOP | Extended Opcode |
| PR | Predicate Field |
| IMM | Signed Immediate |
| T0 | Target 0 Specifier |
| T1 | Target 1 Specifier |
| LSID | Load/Sotre ID |
| EXIT | Exit Number |
| OFFSET | Branch Offset |
| CONST | 16-bit Constant |
| V | Valid Bit |
| GR | General Register Index |
| TR0 | Read Target 0 Specifier |
| RT1 | Read Target 1 Specifier |
Siehe auch
Weblinks
- Homepage des TRIPS Teams (englisch)
- Scale - C, Fortran und Java Compiler für TRIPS (Memento vom 9. August 2011 im Internet Archive; englisch)
- The Distributed Microarchitecture of the TRIPS Prototype Prozessor. (PDF; 429 kB) cs.utexas.edu (englisch)
Einzelnachweise
- S. Sethumadhavan, R. McDonald, R. Desikan, D. Burger, S. W. Keckler: Design and implementation of the TRIPS primary memory system. International Conference on Computer Design, Oktober 2006.
- C. Kim, D. Burger, S. W. Keckler: An adaptive, non-uniform cache structure for wire-delay dominated on-chipcaches. International Conference on Architectural Support for Programming Languages and Operating Systems, Oktober 2002, S. 211–222.