Datenstrom
Mit Datenströmen (englisch data streams) bezeichnet man in der Informatik einen kontinuierlichen Fluss von Datensätzen, dessen Ende meist nicht im Voraus abzusehen ist; die Datensätze werden fortlaufend verarbeitet, sobald jeweils ein neuer Datensatz eingetroffen ist. Die einzelnen Datensätze sind dabei von beliebigem, aber festem Typ. Die Menge der Datensätze pro Zeiteinheit (Datenrate) kann variieren und evtl. so groß werden, dass die begrenzten Ressourcen zur Weiterverarbeitung nicht ausreichen und der Empfänger entsprechend reagieren muss (z. B. verwerfen von Datensätzen). Im Gegensatz zu anderen Datenquellen können Datenströme nur Satz um Satz fortlaufend verarbeitet werden – insbesondere ist im Gegensatz zu Datenstrukturen mit wahlfreiem Zugriff (wie z. B. Arrays) meist nur ein sequentieller Zugriff auf die einzelnen Datensätze möglich.
Datenströme werden häufig zur Interprozesskommunikation verwendet (Kommunikation zwischen Prozessen auf einem Rechner) sowie zur Übertragung von Daten über Netzwerke, insbesondere für Streaming Media. Sie sind im Rahmen des Programmierparadigmas Pipes und Filter vielseitig einsetzbar; in Unix-Shells ist dies ein gängiges Arbeitsmittel. Beispiele für Datenströme sind Wetterdaten sowie Audio- und Videoströme (Streaming Media). Die kontinuierliche Übertragung von Daten über ein Netzwerk wird auch als Streaming bezeichnet.
Abweichend von der Bedeutung im Zusammenhang mit dem „Streaming“ wird der Ausdruck ‚Datenstrom‘ im Sprachgebrauch auch allgemeiner als „elektronisch kodierte Daten im Stadium der Übermittlung“[1] verwendet; hierbei ist der Aspekt der fortlaufenden Verarbeitung unwichtig, dafür wird betont, dass die Übermittlung noch nicht abgeschlossen ist. Beispiele dafür sind: Up-/Downloads; beim elektronischen Datenaustausch gesendete Daten; Datenbestände zum Import oder Export bei SAP.
Datenströme vs. statische Daten
Nicht strömende, das heißt statische Daten liegen in der Regel strukturiert abgespeichert vor, oft als Tupel von Werten in Relationen in einer Datenbank. Sie sind begrenzt und nicht zeitlich geordnet. Die Daten in Datenströmen besitzen dagegen eine geordnete zeitliche Reihenfolge und können praktisch unbegrenzt auftreten. Während Daten in Relationen auch gezielt aktualisiert und gelöscht werden können, ist in Datenströmen nur das Einfügen von neuen Daten möglich, da nicht mit wahlfreiem Zugriff auf einzelne Elemente zugegriffen werden kann. Es können allerdings mittels spezieller Datenstromalgorithmen einzelne Tupel eines Datenstroms, basierend auf ihren Eigenschaften, ausgewählt und ggf. zu einem neuen Datenstrom umgewandelt werden. Das (umkehrbare) Umformen strukturierter Daten in eine datenstromartige Aneinanderreihung bezeichnet man auch als Serialisierung.
Geschichte
Das Konzept von Datenströmen in der Datenverarbeitung lässt sich unter anderem auf die von Douglas McIlroy vorgeschlagenen Pipes zur Verknüpfung von Makros zurückführen, die 1964 als „communication files“ im Dartmouth Time-Sharing System implementiert waren und 1972 in das Betriebssystem Unix integriert wurden. Dabei handelt es sich um eine Datenverbindung zwischen zwei Prozessen nach dem FIFO-Prinzip. Inzwischen findet sich das Prinzip von Streams in den meisten modernen Programmiersprachen.
Verarbeitung
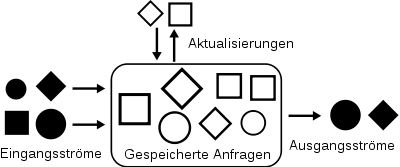
Die meisten Datenströme werden mittels speziell auf eine Anwendung zugeschnittener Programme verarbeitet. Beispielsweise können Audio/Videoströme mit speziellen Wiedergabeprogrammen abgespielt werden. Zur allgemeinen Verwaltung beliebiger Datenströme werden seit Anfang des 21. Jahrhunderts in der Informatik sogenannte Data Stream Management Systeme (DSMS) entwickelt. Diese Systeme, die noch ein relativ neues Forschungsgebiet darstellen, sind vergleichbar mit herkömmlichen Datenbankverwaltungssystemen (DBMS) für statische Daten. Ein Beispiel eines solchen DSMS ist der Stanford Stream Data Manager. Als Anfragesprache wurde in Erweiterung zur SQL im Rahmen dieses Projekts die Continuous Query Language (CQL) entwickelt.
Typische Probleme bei der Verarbeitung von Datenströmen sind große Datenmengen in kurzer Zeit und die begrenzten Ressourcen, die zu ihrer Verarbeitung zur Verfügung stehen, da die eingehenden Daten nicht alle zwischengespeichert werden können und immer nur ein Ausschnitt der Daten bekannt ist. Damit sind auch nur bestimmte Algorithmen möglich. Auch die zur Auswertung zur Verfügung stehende Zeit ist oft beschränkt, da zeitkritische Anwendungen schnelle Ergebnisse erwarten. Bei Systemen, die innerhalb einer garantierten Zeitspanne ein Ergebnis liefern, spricht man auch von Echtzeitsystemen.
Da die eingehenden Datenströme praktisch unbegrenzt sind, sind die daraus berechneten Ergebnisse einer Verarbeitung von Datenströmen oft selbst wiederum Datenströme. Deshalb wird zwischen eingehenden Datenströmen (ingoing stream, instream oder downstream) und ausgehenden Datenströmen (outgoing stream, upstream) unterschieden.
Siehe auch
Literatur
- Mohamed Medhat Gaber: Mining Data Streams Bibliography
- Brian Babcock, Shivnath Babu, Mayur Data, Rajeev Motwani, Jennifer Widom. Models and Issues in Data Stream Systems. In: Proceedings of 21st ACM Symposium on Principles of Database Systems (PODS 2002)
- Michael Cammert, Christoph Heinz, Jürgen Krämer, Bernhard Seeger: Anfrageverarbeitung auf Datenströmen. Datenbank-Spektrum 11: 5–13, (2004).