Skalierbarkeit
Unter Skalierbarkeit versteht man die Fähigkeit eines Systems, Netzwerks oder Prozesses zur Größenveränderung. Meist wird dabei die Fähigkeit des Systems zum Wachstum bezeichnet.
In der Elektronischen Datenverarbeitung bedeutet Skalierbarkeit die Fähigkeit eines Systems aus Hard- und Software, die Leistung durch das Hinzufügen von Ressourcen – z. B. weiterer Hardware – in einem definierten Bereich proportional (bzw. linear) zu steigern.
Eine allgemein gültige Definition dieses Begriffs ist allerdings nicht trivial.[1][2] Es ist erforderlich, für den jeweiligen speziellen Fall stets einen Bereich anzugeben (z. B. muss ein System bei 100 gleichzeitigen Zugriffen nicht zwangsläufig gleich gut skalieren wie bei 100.000 Zugriffen). Ressourcen können z. B. CPU, RAM, Festplatten oder Netzwerk-Bandbreite sein.
Die Skalierbarkeit eines Systems wird mit dem Skalierungsfaktor – auch SpeedUp genannt – angegeben.
In der Betriebswirtschaftslehre dient der Begriff ganz allgemein zur Bezeichnung der Expansionsfähigkeit eines Geschäftsmodells durch Kapazitätsausweitung zur Erreichung höherer Effizienz und Profitabilität. Interessant für Investoren ist insbesondere die Skalierbarkeit von Geschäftsmodellen ohne (hohe) zusätzliche Investitionen und Fixkosten. Dies ist insbesondere in der Internet-Ökonomie möglich. Von Skalierbarkeit spricht man auch in Bezug auf Kapitalmärkte, sofern die Effizienz bei steigendem Handelsvolumen ebenfalls steigt.
Vertikale vs. horizontale Skalierung
Man kann die Leistung eines Systems auf zwei verschiedene Arten steigern:[3]
Vertikale Skalierung (scale up)
Unter vertikaler Skalierung versteht man ein Steigern der Leistung durch das Hinzufügen von Ressourcen zu einem Knoten/Rechner des Systems. Beispiele dafür wären das Vergrößern von Speicherplatz, das Hinzufügen einer CPU, oder das Einbauen einer leistungsstärkeren Grafikkarte.
Charakteristisch für diese Art von Skalierung ist, dass ein System unabhängig von der Implementierung der Software schneller gemacht werden kann. Das heißt, es muss keine Zeile Code geändert werden, um eine Leistungssteigerung durch vertikales Skalieren zu erfahren. Der große Nachteil dabei ist jedoch, dass man früher oder später an eine Grenze stößt, bei der man den Rechner nicht weiter aufrüsten kann, wenn man bereits die beste Hardware verwendet, die zu diesem Zeitpunkt am Markt ist.
Horizontale Skalierung (scale out)
Im Gegensatz zur vertikalen Skalierung sind der horizontalen Skalierung keine Grenzen (aus Sicht der Hardware) gesetzt. Horizontale Skalierung bedeutet die Steigerung der Leistung eines Systems durch das Hinzufügen zusätzlicher Rechner/Knoten. Die Effizienz dieser Art der Skalierung ist jedoch stark von der Implementierung der Software abhängig, da nicht jede Software gleich gut parallelisierbar ist.
Arten von Skalierbarkeit
| A hat Auswirkungen auf B | |||
A |
B |
||
Lastskalierbarkeit |
Räumliche Skalierbarkeit |
nein | |
Zeitlich-räumliche Skalierbarkeit |
nein | ||
Strukturelle Skalierbarkeit |
nein | ||
Räumliche Skalierbarkeit |
Lastskalierbarkeit |
evtl. | |
Zeitlich-räumliche Skalierbarkeit |
evtl. | ||
Strukturelle Skalierbarkeit |
nein | ||
Zeitlich-räumliche Skalierbarkeit |
Lastskalierbarkeit |
evtl. | |
Räumliche Skalierbarkeit |
nein | ||
Strukturelle Skalierbarkeit |
nein | ||
Strukturelle Skalierbarkeit |
Lastskalierbarkeit |
evtl. | |
Räumliche Skalierbarkeit |
nein | ||
Zeitlich-räumliche Skalierbarkeit |
nein | ||
Grundsätzlich unterscheidet man vier Arten von Skalierbarkeit:[4]
Lastskalierbarkeit
Lastskalierbarkeit steht für ein konstantes Systemverhalten über größere Lastbereiche hinweg. Das bedeutet, dass ein System zum einen sowohl bei geringer, mittlerer, als auch bei hoher Last keine zu große Verzögerung aufweist und die Anfragen rasch abgearbeitet werden können.
Beispiel Museumsgarderobe
Bei einer Garderobe in einem Museum, bei welcher Besucher Jacken abgeben und wieder abholen, gilt das First-Come-First-Served-Prinzip. Dabei gibt es eine beschränkte Anzahl an Kleiderhaken und eine größere Anzahl an Besuchern. Die Garderobe, an der sich die Besucher in einer Reihe anstellen, ist ein Karussell. Um einen freien Haken bzw. seine Jacke zu finden, sucht jeder Besucher linear danach.
Unser Ziel ist es nun, die Zeit, die ein Besucher tatsächlich im Museum verbringen kann, zu maximieren.
Die Performance dieses Systems ist unter hoher Last dramatisch schlecht. Erstens wird das Suchen freier Haken immer aufwändiger, je weniger freie Haken zur Verfügung stehen. Zweitens ist unter hoher Auslastung (z. B. im Winter) ein Deadlock vorprogrammiert. Während am Morgen sämtliche Besucher ihre Jacken abgeben, holen sie sich diese am Abend wieder alle ab. Ein Deadlock wird voraussichtlich mittags und am frühen Nachmittag auftreten, wenn keine freien Kleiderhaken mehr verfügbar sind und weitere Besucher am Ende der Schlange stehen, um ihre Jacke abzuholen.
Personen, die ihre Jacke abholen möchten, könnten diesen Deadlock auflösen, indem sie die anreisenden Besucher bitten, in der Schlange vorgelassen zu werden. Da die Personen, welche ihre Jacke abholen, erst nach einem gewissen Timeout danach fragen werden, ist dieses System höchst inperformant.
Das Erhöhen der Anzahl an Kleiderhaken würde das Problem lediglich hinauszögern, jedoch nicht beheben. Die Lastskalierbarkeit ist folglich sehr schlecht.
Räumliche Skalierbarkeit
Räumliche Skalierbarkeit weist ein System bzw. Anwendung auf, wenn der Speicherbedarf bei einer wachsenden Anzahl an zu verwaltenden Elementen nicht inakzeptabel hoch ansteigt. Nachdem „inakzeptabel“ ein relativer Begriff ist, spricht man in diesem Zusammenhang in der Regel von akzeptabel, wenn der Speicherbedarf höchstens sub-linear ansteigt. Um das zu erreichen, kann z. B. eine dünnbesetzte Matrix (engl. sparse matrix) bzw. Datenkompression angewendet werden. Da Datenkompression eine gewisse Zeit beansprucht, steht diese jedoch häufig in Widerspruch zur Lastskalierbarkeit.
Zeitlich-räumliche Skalierbarkeit
Ein System verfügt über eine zeitlich-räumliche Skalierbarkeit, wenn sich das Erhöhen der Anzahl von Objekten, die ein System umfasst, nicht erheblich auf dessen Performance auswirkt. Beispielsweise weist eine Suchmaschine mit linearer Komplexität keine zeitlich-räumliche Skalierbarkeit auf, während eine Suchmaschine mit indizierten, bzw. sortierten Daten, z. B. unter Verwendung einer Hashtabelle oder eines balancierten Baums, sehr wohl eine zeitlich-räumliche Skalierbarkeit vorweisen könnte.
Strukturelle Skalierbarkeit
Strukturelle Skalierbarkeit zeichnet ein System aus, dessen Implementierung das Erhöhen der Anzahl von Objekten innerhalb eines selbst definierten Bereichs nicht maßgeblich behindert.
Abhängigkeit zwischen den Arten von Skalierbarkeit
Da ein System natürlich mehrere Arten von Skalierbarkeit aufweisen kann, stellt sich die Frage, wie und ob diese miteinander zusammenhängen. Siehe dazu die Tabelle oben.
Die Lastskalierbarkeit eines Systems wird nicht zwangsläufig durch eine schlechte räumliche oder strukturelle Skalierbarkeit negativ beeinflusst. Systeme mit schlechter räumlicher oder zeitlich-räumlicher Skalierbarkeit haben, aufgrund des Overheads an Speicherverwaltung bzw. des hohen Suchaufwands, möglicherweise auch eine schlechte Lastskalierbarkeit. Systeme mit guter zeitlich-räumlicher Skalierbarkeit haben unter Umständen eine schlechte Lastskalierbarkeit, wenn z. B. nicht ausreichend parallelisiert wurde.
Der Zusammenhang zwischen struktureller Skalierbarkeit und Lastskalierbarkeit sieht folgendermaßen aus: Während letztere keine Auswirkungen auf erstere hat, kann das umgekehrt sehr wohl der Fall sein.
Die verschiedenen Arten von Skalierbarkeit sind also nicht ganz unabhängig voneinander.
Skalierungsfaktor
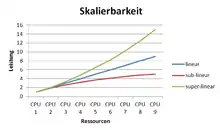
Der Skalierungsfaktor (SpeedUp) beschreibt den tatsächlichen Leistungszuwachs einer zusätzlichen Ressourcen-Einheit. Z. B. kann eine zweite CPU 90 % zusätzliche Leistung bringen.
Von einer super-linearen Skalierbarkeit spricht man, wenn der Skalierungsfaktor beim Hinzufügen von Ressourcen größer wird.
Lineare Skalierbarkeit bedeutet, dass der Skalierungsfaktor eines Systems pro hinzugefügter Ressourcen-Einheit gleich bleibt.
Sub-Lineare Skalierbarkeit steht im Gegensatz dazu für die Abnahme des Skalierungsfaktors beim Hinzufügen von Ressourcen.
Negative Skalierbarkeit wird erreicht, wenn sich die Leistung durch das Hinzufügen von Ressourcen/Rechnern sogar verschlechtert. Mit diesem Problem hat man zu kämpfen, wenn der Verwaltungsaufwand, welcher durch den zusätzlichen Rechner entsteht, größer ist als der dadurch erreichte Leistungszuwachs.
Amdahls Gesetz ist ein relativ pessimistisches Modell zur Abschätzung des Skalierungsfaktors. Basierend darauf ist Gustafsons Gesetz eine weitere Methode zur Berechnung dieses Faktors.
System als Schichtenmodell
Um ein System nun möglichst skalierbar aufzubauen, hat es sich in der Praxis bewährt, ein solches als Schichtenmodell umzusetzen, da mit diesem Ansatz die einzelnen Schichten logisch voneinander getrennt sind und jede Schicht für sich skaliert werden kann.
Eine sehr populäre Architektur im Web-Bereich ist die 3-Schichten-Architektur. Um dabei eine hohe Skalierbarkeit zu erzielen, ist ein entscheidender Faktor, dass jede dieser 3 Schichten gut skaliert.
Während die Präsentationsschicht relativ einfach horizontal skaliert werden kann, ist bei der Logikschicht dafür eine speziell dafür ausgelegte Implementierung des Codes erforderlich. Dabei ist zu berücksichtigen, dass ein möglichst großer Anteil der Logik parallelisiert werden kann (siehe Amdahls Gesetz und Gustafsons Gesetz weiter oben). Am interessantesten ist jedoch die horizontale Skalierung der Datenhaltungsschicht, weshalb diesem Thema ein eigener Abschnitt (siehe horizontales Skalieren der Datenhaltungsschicht weiter unten) gewidmet ist.
Praktische Methoden zur Verbesserung der Skalierbarkeit von Webseiten
Verbesserung der Skalierbarkeit von Webseiten kann durch Steigerung der Performance erzielt werden, da ein Server dadurch mehr Clients in der gleichen Zeit bedienen kann.
Martin L. Abbott und Michael T. Fisher haben 50 Regeln aufgestellt, die es in Bezug auf Skalierbarkeit zu beachten gilt.[5] Für Webseiten sind dabei unter anderem folgende Regeln relevant:
Reduzieren von DNS-Lookups und Anzahl von Objekten
Beim Betrachten des Ladens einer Seite in einem beliebigen Browser mit einem Debugging-Tool (z. B. Firebug) fällt auf, dass ähnliche große Elemente unterschiedlich lange Ladezeiten beanspruchen. Bei genauerer Betrachtung erkennt man, dass einige dieser Elemente einen zusätzlichen DNS-Lookup benötigen. Dieser Vorgang der Adressauflösung kann durch DNS-Caching auf unterschiedlichen Ebenen (z. B. Browser, Betriebssystem, Internet-Provider etc.) beschleunigt werden. Um die Anzahl der Lookups zu reduzieren, könnte man nun alle JavaScript- und CSS-Dateien zu jeweils einer zusammenfassen und man könnte alle Bilder auf ein großes zusammenfügen und mittels CSS-Sprites nur den gewünschten Bildausschnitt anzeigen. Allgemein kann man folgende Regel dazu aufstellen: Je weniger DNS-Lookups beim Laden einer Seite erforderlich sind, desto besser ist die Performance. Die folgende Tabelle[5] veranschaulicht, wie teuer der DNS-Lookup und der Verbindungsaufbau verhältnismäßig sind.
| Object download time | DNS Lookup |
TCP Connection |
Send Request |
Receive Request |
|---|---|---|---|---|
| http://www.example.org/ | 50 ms | 31 ms | 1 ms | 3 ms |
| http://static.example.org/styles.css | 45 ms | 33 ms | 1 ms | 2 ms |
| http://static.example.org/fish.jpg | 0 ms | 38 ms | 0 ms | 3 ms |
| http://ajax.googleapis.com/ajax/libs/jquery.min.js | 15 ms | 23 ms | 1 ms | 1 ms |
Moderne Browser können jedoch mehrere Verbindungen gleichzeitig zu einem Server offen halten, um mehrere Objekte parallel herunterzuladen. Laut HTTP/1.1 RFC 2616 sollte das Maximum an gleichzeitigen Verbindungen je Server im Browser auf 2 limitiert werden. Einige Browser ignorieren diese Richtlinie jedoch und verwenden ein Maximum von 6 gleichzeitigen Verbindungen und mehr. Reduziert man auf einer Webseite nun jedoch alle JavaScript- und CSS-Dateien sowie alle Bilder lediglich auf jeweils eine Datei, so entlastet man zwar die anbietenden Server, hebelt jedoch gleichzeitig diesen Mechanismus der parallelen Verbindungen des Browsers aus.
Idealerweise nutzt man diese Parallelisierung im Browser zur Gänze aus und hat gleichzeitig möglichst wenige DNS-Lookups. Um das zu erreichen, verteilt man eine Webseite am besten auf mehrere Subdomains (z. B. ruft man Bilder von einer Subdomain auf, während man Videos von einer anderen lädt). Durch diese Vorgehensweise lässt sich relativ einfach eine beachtliche Performance-Steigerung erzielen. Es gibt jedoch keine allgemeine Antwort darauf, wie viele Subdomains man verwenden sollte, um die bestmögliche Leistung zu erzielen. Einfache Performance-Tests der zu optimierenden Seite sollten darüber jedoch rasch Aufschluss bieten.
Skalierung hinsichtlich Datenbankzugriffe
Der am schwierigsten zu skalierende Teil eines Systems ist meistens die Datenbank bzw. die Datenhaltungsschicht (s. o.). Der Ursprung dieses Problems kann bis zum Paper A Relational Model of Data for Large Shared Data Banks[6] von Edgar F. Codd zurückverfolgt werden, welches das Konzept eines Relational Database Management System (RDBMS) vorstellt.
Eine Methode, um Datenbanken zu skalieren, ist es, sich zu Nutze zu machen, dass die meisten Anwendungen und Datenbanken wesentlich mehr Lese- als Schreibzugriffe aufweisen. Ein durchaus realistisches Szenario, das in dem Buch von Martin L. Abbott und Michael T. Fisher beschrieben wird, ist eine Buchreservierungsplattform, welche ein Verhältnis zwischen Lese- und Schreibzugriffen von 400:1 aufweist. Systeme dieser Art können relativ einfach skaliert werden, indem mehrere read-only Duplikate dieser Daten angefertigt werden.
Es gibt mehrere Wege, um die Kopien dieser Daten zu verteilen, abhängig davon, wie aktuell die Daten der Duplikate wirklich sein müssen. Grundsätzlich sollte es kein Problem sein, dass diese Daten lediglich alle 3, 30, oder 90 Sekunden synchronisiert werden. Bei dem Szenario der Buchplattform gibt es 1.000.000 Bücher, und 10 % davon werden täglich reserviert. Angenommen, die Reservierungen sind gleichmäßig über den gesamten Tag verteilt, so findet ca. eine Reservierung pro Sekunde (0,86 Sekunden) statt. Die Wahrscheinlichkeit, dass zum Zeitpunkt (innerhalb 90 Sekunden) einer Reservierung ein anderer Kunde das gleiche Buch reservieren möchte, beträgt (90/0,86)/100.000 = 0,104 %. Natürlich kann und wird dieser Fall irgendwann eintreffen, doch diesem Problem kann ganz einfach durch eine abschließende, erneute Überprüfung der Datenbank entgegentreten werden.
Eine Möglichkeit, um diese Methode umzusetzen, ist es, die Daten, z. B. mit einem Key-Value-Store (etwa Redis), zu cachen. Der Cache muss erst nach Ablauf seiner Gültigkeit erneuert werden und entlastet damit die Datenbank enorm. Der einfachste Weg, diesen Cache zu implementieren, ist, ihn in einer bereits bestehenden Schicht (z. B. der Logikschicht) zu installieren. Für eine bessere Performance und Skalierbarkeit verwendet man dafür jedoch eine eigene Schicht, bzw. eigene Server, zwischen der Logikschicht und der Datenhaltungsschicht.
Der nächste Schritt ist nun, die Datenbank zu replizieren. Die meisten bekannten Datenbanksysteme verfügen bereits über eine solche Funktion. MySQL bewerkstelligt dies mit dem master-slave-Prinzip, wobei die master-Datenbank die eigentliche Datenbank mit Schreibrechten ist und die slave-Datenbanken die duplizierten read-only Kopien sind. Die Master-Datenbank zeichnet sämtliche updates, inserts, deletes etc. im sogenannten Binary-Log auf, und die Slaves reproduzieren diese. Diese Slaves steckt man nun hinter einen Load Balancer (s. u.), um die Last entsprechend zu verteilen.
Diese Art von Skalierung lässt die Anzahl der Transaktionen relativ einfach skalieren. Je mehr Duplikate der Datenbank verwendet werden, desto mehr Transaktionen können auch parallel bewältigt werden. In anderen Worten bedeutet das, dass nun beliebig viele User (natürlich abhängig von der Anzahl der Server) gleichzeitig auf unsere Datenbank zugreifen können. Diese Methode hilft uns nicht dabei, auch die Daten an sich zu skalieren. Um nun auch beliebig viele Daten in der Datenbank speichern zu können, ist ein weiterer Schritt nötig. Dieses Problem wird im nächsten Punkt behandelt.
Skalierung hinsichtlich Datenbankeinträge – Denormalisierung
Was man hiermit erreichen möchte, ist, eine Datenbank auf mehrere Rechner aufzuteilen und ihre Kapazität beliebig durch weitere Rechner zu erweitern. Dazu muss die Datenbank zu einem gewissen Grad denormalisiert werden. Unter Denormalisierung versteht man die bewusste Rücknahme einer Normalisierung zum Zweck der Verbesserung des Laufzeitverhaltens einer Datenbankanwendung.
Im Zuge der Denormalisierung muss die Datenbank fragmentiert werden.
Fragmentierung
Man unterscheidet horizontale und vertikale Fragmentierung.
Bei der Horizontalen Fragmentierung (Eng. sharding) wird die Gesamtheit aller Datensätze einer Relation auf mehrere Tabellen aufgeteilt. Wenn diese Tabellen auf demselben Server liegen, dann handelt es sich meistens um Partitionierung. Die einzelnen Tabellen können aber auch auf unterschiedlichen Servern liegen. So können z. B. die Daten für die Geschäfte in den USA auf einem Server in den USA gespeichert werden und die Daten für die Geschäfte mit Europa liegen auf einem Server in Deutschland. Diese Aufteilung wird auch als Regionalisierung bezeichnet.
Horizontale Fragmentierung schafft keine Redundanz der gespeicherten Daten, sondern der Strukturen. Wenn eine Relation geändert werden muss, dann muss nicht nur eine Tabelle geändert werden, sondern es müssen alle Tabellen geändert werden, über die die Daten aus der betreffenden Relation verteilt sind. Hier besteht die Gefahr von Anomalien in den Datenstrukturen.
Bei der Vertikalen Fragmentierung werden die abhängigen Attribute (nicht-Schlüssel-Attribute) einer Tabelle in zwei oder mehrere Gruppen aufgeteilt. Aus jeder Gruppe wird eine eigene Tabelle, die noch um alle Schlüssel-Attribute der Ursprungstabelle ergänzt werden. Das kann dann sinnvoll sein, wenn die Attribute einer Relation Datensätze mit einer sehr großen Satzlänge ergeben. Wenn zusätzlich noch die Zugriffe meistens nur einige wenige Attribute betreffen, dann kann man die wenigen häufig zugegriffenen Attribute in eine Gruppe zusammenfassen und den Rest in eine zweite Gruppe zusammenfassen. Die häufig auszuführenden Zugriffe werden dadurch schneller, weil eine geringere Menge an Daten von der Festplatte gelesen werden muss. Die selten auszuführenden Zugriffe auf die restlichen Attribute werden dadurch nicht schneller, aber auch nicht langsamer.
Ab welcher Satzlänge eine Aufspaltung in mehrere kleinere Tabellen sinnvoll ist, hängt auch von dem Datenbanksystem ab. Viele Datenbanksysteme speichern die Daten in Form von Blöcken mit einer Größe von 4 KiB, 8 KiB oder 16 KiB ab. Wenn die durchschnittliche Satzlänge wenig größer als 50 % eines Datenblocks ist, dann bleibt viel Speicherplatz ungenutzt. Wenn die durchschnittliche Satzlänge größer als die verwendete Blockgröße ist, dann werden die Datenzugriffe aufwändiger. Wenn BLOBs zusammen mit anderen Attributen in einer Relation vorkommen, ist vertikale Fragmentierung fast immer von Vorteil.
Partitionierung
Partitionierung ist ein Spezialfall der horizontalen Fragmentierung.
Große Datenbestände lassen sich leichter administrieren, wenn die Daten einer Relation in mehrere kleine Teile (=Partitionen) aufgeteilt und diese separat gespeichert werden. Wenn eine Partition einer Tabelle gerade aktualisiert wird, dann können andere Partitionen der Tabelle zur selben Zeit reorganisiert werden. Wenn in einer Partition ein Fehler entdeckt wird, dann kann diese einzelne Partition aus einer Datensicherung wiederhergestellt werden, während Programme auf die anderen Partitionen weiter zugreifen können. Die meisten etablierten Datenbankhersteller bieten Partitionierung an, siehe z. B. Partitionierung bei DB2 und Partitionierung bei MySQL.
Die meisten Datenbanksysteme bieten die Möglichkeit, entweder einzelne Partitionen anzusprechen oder alle Partitionen unter einem einheitlichen Tabellennamen anzusprechen.
Durch Partitionierung können die Datenzugriffe beschleunigt werden. Der wesentliche Vorteil ist jedoch die leichtere Administrierbarkeit der gesamten Tabelle.
Skalierbarkeit in der Betriebswirtschaftslehre
Als Skalierbarkeit eines Geschäftsmodells wird die Fähigkeit definiert, durch Einsatz zusätzlicher Ressourcen ein Kapazitäts- und Umsatzwachstum ohne entsprechende Ausweitung der Investitionen und Fixkosten zu erreichen. Für Gründer und Investoren ist insbesondere die Form der Skalierbarkeit eines Geschäftsmodells interessant, die es ermöglicht, Kapazitäts- und Umsatzwachstum ohne entsprechende Ausweitung der Investitionen und Fixkosten zu erreichen.
Bei auf den lokalen Markt zielenden Existenzgründungen ist eine Skalierbarkeit selten gegeben, da das Gewerbe an einen Standort gebunden ist. Auch bei Gründungen, die stark von der individuellen Fachkompetenz des Gründers abhängig sind (z. B. in beratenden und anderen Dienstleistungsberufen), markieren die Grenzen der eigenen Arbeitszeit die Grenzen der Skalierbarkeit. In beiden Fällen kann der Umsatz nicht einfach gesteigert werden, so dass man zusätzliche Ressourcen nutzen und in einen neuen Standort investieren oder neue Mitarbeiter einstellen muss und dadurch neue Fixkosten verursacht.
Bei Produktionseinheiten mit begrenzter Kapazität erfordert die Skalierung über die maximale Kapazität hinaus hohe Investitionen, um eine zweite, dritte usw. Produktionseinheit aufzubauen. In der digitalen Wirtschaft, z. B. bei einem Internethandel hingegen muss zunächst in Website, Software, Werbung usw. investiert werden; anschließend können Umsatzsteigerungen jedoch ohne zusätzlichen Ressourceneinsatz erzielt werden,[7] wenn man von den Logistikkosten absieht.
Folgende Merkmale eines skalierbaren Geschäftsmodells werden allgemein angeführt:
- Geringes Anlagevermögen
- Geringe Fixkosten (im Verhältnis zu den Gesamtkosten)
- Hoher Anteil variabler Kosten
- Effektive Marketing- und Vertriebsaktivitäten, um die Produkte und Dienstleistungen bei Kapazitätserhöhungen rasch absetzen zu können
- Expansion in benachbarte Märkte und Länder
Die Beurteilung der Skalierbarkeit eines Geschäftsmodells ist wichtig für professionelle Investoren, erhöht sie doch die Wahrscheinlichkeit einer hohen Verzinsung ihrer Investitionen und/oder einer schnellen Wertsteigerung des Unternehmens bei sinkender Notwendigkeit großer Kapitalnachschüsse. Das ist interessant für Wagniskapitalgeber, aber auch für Gründer, die die Verwässerung der eigenen Anteile vermeiden und Aussicht auf steigende Gewinnausschüttungen haben.
Auch Geschäftsmodelle, die auf Franchising basieren, sind leichter skalierbar, da die Investitionen für den Aufbau neuer Standorte und Kapazitäten von den Franchisenehmern übernommen werden. So ist es auch möglich, lokale Geschäftsmodelle zu skalieren, die ansonsten enge Kapazitätsgrenzen aufweisen.
Als vertikale Skalierung kann man die Verlängerung der Wertschöpfungskette zwecks Umsatzsteigerung bezeichnen, als horizontale Skalierung die Vermarktung von bestehenden Produkten und Dienstleistungen in benachbarten Märkten, die Erweiterung des Portfolios durch ähnliche Produkte und Dienstleistungen oder auch die Übertragung eines bewährten Geschäftsmodells auf andere Märkte.
Während die Bedeutung des innovativen Charakters eines Geschäftsmodells oft überschätzt wird, wird die Skalierbarkeit von unerfahrenen Unternehmern häufiger vernachlässigt.[8]
Siehe auch
Weblinks
Einzelnachweise
- Mark D. Hill: What is scalability? In: ACM SIGARCH Computer Architecture News. Band 18, Nr. 4, Dezember 1990, ISSN 0163-5964, S. 18–21.
- Leticia Duboc, David S. Rosenblum, Tony Wicks: A Framework for Modelling and Analysis of Software Systems Scalability. In: Proceeding of the 28th international conference on Software engineering ICSE ’06. ACM, New York, NY, USA 2006, ISBN 1-59593-375-1, S. 949–952, doi:10.1145/1134285.1134460.
- M. Michael, J. E. Moreira, D. Shiloach, R. W. Wisniewski: Scale-up x Scale-out: A Case Study using Nutch/Lucene. In: IEEE International (Hrsg.): Parallel and Distributed Processing Symposium, 2007. 30. März 2007, S. 1–8, doi:10.1109/IPDPS.2007.370631.
- André B. Bondi: Characteristics of Scalability and Their Impact on Performance. In: Proceedings of the 2nd international workshop on Software and performance (WOSP ’00). ACM, New York, NY, USA 2000, ISBN 1-58113-195-X, S. 195–203, doi:10.1145/350391.350432.
- L. M. Abbott, M. T. Fisher: Scalability Rules: 50 principles for scaling Web sites. Addison-Wesley, Indiana 2011, ISBN 978-0-321-75388-5, S. 12–34.
- Edgar F. Codd: A Relational Model of Data for Large Shared Data Banks. In: Communications of the ACM. ACM Press, 13. Juni 1970, ISSN 0001-0782, S. 377–387 (eecs.umich.edu (Memento vom 30. Januar 2012 im Internet Archive) [PDF]).
- Patrick Stähler: Geschäftsmodelle in der digitalen Ökonomie: Merkmale, Strategien und Auswirkungen. Josef Eul Verlag, Köln-Lohmar 2001.
- Urs Fueglistaller, Christoph Müller, Susan Müller, Thierry Volery: Entrepreneurship: Modelle – Umsetzung – Perspektiven. Springer Verlag, 2015, S. 116.