Hidden Markov Model
Das Hidden Markov Model, kurz HMM (deutsch verdecktes Markowmodell, oder verborgenes Markowmodell) ist ein stochastisches Modell, in dem ein System durch eine Markowkette – benannt nach dem russischen Mathematiker A. A. Markow – mit unbeobachteten Zuständen modelliert wird. Ein HMM kann dadurch als einfachster Spezialfall eines dynamischen bayesschen Netzes angesehen werden.
Die Modellierung als Markowkette bedeutet, dass das System auf zufällige Weise von einem Zustand in einen anderen übergeht, wobei die Übergangswahrscheinlichkeiten nur jeweils vom aktuellen Zustand abhängen, aber nicht von den davor eingenommenen Zuständen. Außerdem wird angenommen, dass die Übergangswahrscheinlichkeiten über die Zeit konstant sind. Bei einem HMM werden jedoch nicht die Zustände selbst von außen beobachtet; sie sind verborgen (engl. hidden, siehe auch Latentes Variablenmodell). Stattdessen sind jedem dieser inneren Zustände beobachtbare Ausgabesymbole (sogenannte Emissionen) zugeordnet, die je nach Zustand mit gewissen Wahrscheinlichkeiten auftreten. Die Aufgabe besteht meist darin, aus der beobachteten Sequenz der Emissionen zu wahrscheinlichkeitstheoretischen Aussagen über die verborgenen Zustände zu kommen.
Da die Markowmodelle eng verwandt mit den in der Regelungstechnik verwendeten Zustandsraummodellen sind, ist darauf zu achten, dass der Begriff „beobachten“ nicht mit dem regelungstechnischen Begriff der „Beobachtbarkeit“, der von Rudolf Kálmán 1960 eingeführt wurde und eine eigenständige Systemeigenschaft beschreibt, verwechselt wird. „Beobachten“ im Sinn der Markowmodelle wird in der Regelungstechnik mit „messen“ bezeichnet. Die im Sinn der Markowtheorie „unbeobachteten“ oder „hidden“ Zustände können sehr wohl im Sinne der Regelungstechnik beobachtbar sein, müssen es aber nicht.
Wichtige Anwendungsgebiete sind Sprach- und Schrifterkennung, Computerlinguistik und Bioinformatik, Spamfilter, Gestenerkennung in der Mensch-Maschine-Kommunikation, physikalische Chemie[1] und Psychologie.
Markowansatz
Gegeben seien zwei zeitdiskrete Zufallsprozesse und , von denen nur der letzte beobachtbar sei. Durch ihn sollen Rückschlüsse auf den Verlauf des ersten Prozesses gezogen werden; hierfür wird ein mathematisches Modell benötigt, das die beiden Prozesse miteinander in Beziehung setzt.


Der hier beschriebene Ansatz zeichnet sich durch die folgenden beiden Annahmen aus:
- 1. Markoweigenschaft
Der aktuelle Wert des ersten Prozesses hängt ausschließlich von seinem letzten Wert ab:
- .

- 2. Markoweigenschaft
Der aktuelle Wert des zweiten Prozesses hängt ausschließlich vom aktuellen Wert des ersten ab:
- .

Haben die beiden Prozesse nun noch jeweils einen endlichen Wertevorrat, so lässt sich das so gewonnene Modell als probabilistischer Automat auffassen, genauer als Markow-Kette. Man sagt auch ist ein Markow-Prozess. Angelehnt an den Sprachgebrauch in der theoretischen Informatik – insbesondere der Automatentheorie und der Theorie formaler Sprachen – heißen die Werte des ersten Prozesses Zustände und die des zweiten Emissionen bzw. Ausgaben.

Definition
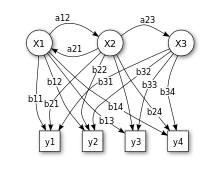
x — (verborgene) Zustände
y — mögliche Beobachtungen (Emissionen)
a — Übergangswahrscheinlichkeiten
b — Emissionswahrscheinlichkeiten
Ein Hidden Markov Model ist ein 5-Tupel mit:

- der Menge aller Zustände, das sind die möglichen Werte der Zufallsvariablen ,
- das Alphabet der möglichen Beobachtungen – die Emissionen der ,
- die Übergangsmatrix zwischen den Zuständen, gibt dabei jeweils die Wahrscheinlichkeit an, dass vom Zustand in den Zustand gewechselt wird,
- die Beobachtungsmatrix, die geben die Wahrscheinlichkeit an, im Zustand die Beobachtung zu machen, sowie
- die Anfangsverteilung, ist die Wahrscheinlichkeit, dass der Startzustand ist.













Ein HMM heiße stationär (oder auch zeitinvariant), wenn sich die Übergangs- und Emissionswahrscheinlichkeiten nicht mit der Zeit ändern. Diese Annahme ist oft sinnvoll, weil auch die modellierten Naturgesetze konstant sind.
Veranschaulichung
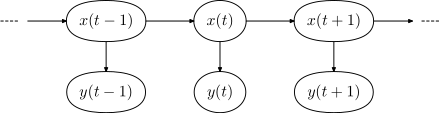
Das Bild zeigt die generelle Architektur eines instanziierten HMMs. Jedes Oval ist die Repräsentation einer zufälligen Variable oder , welche beliebige Werte aus bzw. annehmen kann. Die erste Zufallsvariable ist dabei der versteckte Zustand des HMMs zum Zeitpunkt , die zweite ist die Beobachtung zu diesem Zeitpunkt. Die Pfeile in dem Trellis-Diagramm bedeuten eine bedingte Abhängigkeit.





Im Diagramm sieht man, dass der Zustand der versteckten Variable nur vom Zustand der Variable abhängt, frühere Werte haben keinen weiteren Einfluss. Deshalb ist das Modell ein Markov-Modell 1. Ordnung. Sollten höhere Ordnungen benötigt werden, so können diese durch das Einfügen neuer versteckter Zustände stets auf die 1. Ordnung zurückgeführt werden. Der Wert von hängt weiter ausschließlich von ab.

Beispiel
Gefangener im Verlies
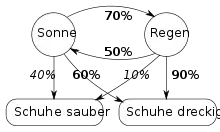
Ein Gefangener im Kerkerverlies möchte das aktuelle Wetter herausfinden. Er weiß, dass auf einen sonnigen Tag zu 70 % ein Regentag folgt und dass auf einen Regentag zu 50 % ein Sonnentag folgt. Weiß er zusätzlich, dass die Schuhe der Wärter bei Regen zu 90 % dreckig, bei sonnigem Wetter aber nur zu 60 % dreckig sind, so kann er durch Beobachtung der Wärterschuhe Rückschlüsse über das Wetter ziehen (das heißt, er kann die Wahrscheinlichkeit für Regenwetter gegenüber sonnigem Wetter abschätzen). Hier bildet das tatsächlich vorhandene, aber nicht sichtbare Wetter den zu ermittelnden versteckten Zustand, die Prozentwerte 70 % und 50 % sind (über längere Zeiten hinweg ermittelte) Trainingsdaten des Modells, und die tatsächlich beobachtbaren Zustände liegen im jeweiligen Aussehen der Schuhe.
Aus den Übergangswahrscheinlichkeiten ergibt sich (langfristig, also ohne den Anfangszustand eingehen zu lassen) die Wahrscheinlichkeit für Sonne von =50%/(50%+70%)41,7 % und für Regen von 58,3%. Damit ergeben sich die Kombinationen von Zuständen mit den Wahrscheinlichkeiten:




| Sonne | Regen | |
|---|---|---|
| Saubere Schuhe | ||
| Dreckige Schuhe | ||




Wenn ein Wärter saubere Schuhe hat, ist die Wahrscheinlichkeit von sonnigem Wetter damit 0,40,40,174,1% und entsprechend ist bei dreckigen Schuhen die Regenwahrscheinlichkeit etwa 67,9 %. Außerdem müssten die Wärter im Mittel zu 0,4+0,1=22,5% der Tage saubere Schuhe haben, andernfalls kann sich der Gefangene überlegen, welche Parameter angepasst werden sollten, damit sein Modell stimmt.





Soweit kann der Gefangene aus der Beobachtung an einem einzelnen Tag schließen. Dabei berücksichtigt er nicht die konkreten Wahrscheinlichkeiten des Wechsels von sonnigen und verregneten Tagen. Bezieht er diese mit ein, so kommt er mit dem Viterbi-Algorithmus zu einem etwas genaueren Ergebnis.
DNA-Sequenz: CpG-Inseln aufspüren
Zur Untersuchung von DNA-Sequenzen mit bioinformatischen Methoden kann das HMM verwendet werden. Beispielsweise lassen sich so CpG-Inseln in einer DNA-Sequenz aufspüren. Dies sind Bereiche eines DNS-Einzelstrangs mit einem erhöhten Anteil von aufeinanderfolgenden Cytosin- und Guanin-Nukleinbasen. Dabei stellt die DNS-Sequenz die Beobachtung dar, deren Zeichen bilden das Ausgabealphabet. Im einfachsten Fall besitzt das HMM zwei verborgene Zustände, nämlich CpG-Insel und nicht-CpG-Insel. Diese beiden Zustände unterscheiden sich in ihrer Ausgabeverteilung, so dass zum Zustand CpG-Insel mit größerer Wahrscheinlichkeit Zeichen und ausgegeben werden.



Problemstellungen
Im Zusammenhang mit HMMs existieren mehrere grundlegende Problemstellungen.[2][3]
Bestimmen der Modellgröße
Gegeben sind die beobachtbaren Emissionen . Es ist zu klären, welche Modelleigenschaften – insbesondere welche orthogonale Dimensionalität – den Schluss auf die nicht direkt beobachtbaren Zustände erlauben und gleichzeitig eine sinnvolle Berechenbarkeit zulassen. Insbesondere ist zu entscheiden, welche Laufzeit für die Modellrechnungen erforderlich werden darf, um die Verwendbarkeit der Schätzungen zu erhalten.
Implementierung
Die Berechnung der Schätzwerte der nicht beobachtbaren Zustände aus den beobachtbaren Ausgabesequenzen muss die erreichbaren numerischen Genauigkeiten beachten. Weiter müssen Kriterien zur Klassifizierung der statistischen Signifikanz implementiert werden. Bei Verwendung eines HMM für einen bestimmten Merkmalsvektor bestimmt die Signifikanz die Wahrscheinlichkeit einer zutreffenden oder falschen Modellhypothese sowie deren Informationsgehalt (Entropie, Bedingte Entropie) bzw. deren Informationsqualität.
Filtern
Gegeben sei ein HMM sowie eine Beobachtungssequenz der Länge . Gesucht ist die Wahrscheinlichkeit , dass der momentane verborgene Zustand zum letzten Zeitpunkt gerade ist. Ein effizientes Verfahren zur Lösung des Filterungsproblems ist der Forward-Algorithmus.




Prädiktion/Vorhersage
Gegeben sei wieder ein HMM und die Beobachtungssequenz sowie ein . Gesucht ist Wahrscheinlichkeit , also die Wahrscheinlichkeit, dass sich das HMM zum Zeitpunkt im Zustand befindet, falls die betreffende Ausgabe beobachtet wurde. Prädiktion ist dabei gewissermaßen wiederholtes Filtern ohne neue Beobachtungen und lässt sich auch einfach mit dem Forward-Algorithmus berechnen.




Glätten
Erneut seien , und ein gegeben. Gesucht ist die Wahrscheinlichkeit , also die Wahrscheinlichkeit, dass sich das Modell zu einem früheren Zeitpunkt in einem bestimmten Zustand befand, unter der Bedingung, dass beobachtet wurde. Mithilfe des Forward-Backward-Algorithmus kann diese Wahrscheinlichkeit effizient berechnet werden.


Dekodierung
Seien wieder sowie gegeben. Es soll die wahrscheinlichste Zustandsfolge aus bestimmt werden, die eine vorgegebene Ausgabesequenz erzeugt haben könnte. Dieses Problem lässt sich effizient mit dem Viterbi-Algorithmus lösen.

Lernproblem
Gegeben sei nur die Ausgabesequenz . Es sollen die Parameter eines HMM bestimmt werden, die am wahrscheinlichsten die Ausgabesequenz erzeugen. Dies ist lösbar mit Hilfe des Baum-Welch-Algorithmus.
Interpretationsproblem
Gegeben seien nur die möglichen Ausgaben . Es sollen die Zustände im Modellsystem und die korrespondierenden Effekte im realen System identifiziert werden, die die Zustandsmenge des Modells beschreibt.[4] Dazu muss vorweg die Bedeutsamkeit der einzelnen Emissionen bestimmt werden.
Anwendungsgebiete
Anwendung finden HMMs häufig in der Mustererkennung bei der Verarbeitung von sequentiellen Daten, beispielsweise bei physikalischen Messreihen, aufgenommenen Sprachsignalen oder Proteinsequenzen. Dazu werden die Modelle so konstruiert, dass die verborgenen Zustände semantischen Einheiten entsprechen (z. B. Phoneme in der Spracherkennung), die es in den sequentiellen Daten (z. B. Kurzzeit-Spektren des Sprachsignals) zu erkennen gilt. Eine weitere Anwendung besteht darin, für ein gegebenes HMM durch eine Suche in einer Stichprobe von sequentiellen Daten solche Sequenzen zu finden, die sehr wahrscheinlich von diesem HMM erzeugt sein könnten. Beispielsweise kann ein HMM, das mit Vertretern einer Proteinfamilie trainiert wurde, eingesetzt werden, um weitere Vertreter dieser Familie in großen Proteindatenbanken zu finden.
Geschichte
Hidden-Markov-Modelle wurden erstmals von Leonard E. Baum und anderen Autoren in der zweiten Hälfte der 1960er Jahre publiziert. Eine der ersten Applikationen war ab Mitte der 1970er die Spracherkennung. Seit Mitte der 1980er wurden HMMs für die Analyse von Nukleotid- und Proteinsequenzen eingesetzt und sind seitdem fester Bestandteil der Bioinformatik.
Literatur
- R. Merkl, S. Waack: Bioinformatik interaktiv. Wiley-VCH, 2002, ISBN 3-527-30662-5.
- G. A. Fink: Mustererkennung mit Markov-Modellen: Theorie, Praxis, Anwendungsgebiete. Teubner, 2003, ISBN 3-519-00453-4.
- Kai-Fu Lee, Hsiao-Wuen Hon: Speaker-Independent Phone Recognition Using Hidden Markov Models. IEEE Transactions on accoustics, speech and signal processing, Nr. 37. IEEE, November 1989, S. 1641–1648 (englisch, IEEE Nr. 8930533, 0096-3518/89/1100-1641).
Weblinks
- R.v. Handel, 28. Juli 2008: Hidden Markov Models (PDF; 900 kB; 123 Seiten) Lecture Notes Princeton University Juli 2008, abgerufen am 24. Februar 2019.
- E.G. Schukat-Talamazzini, 7. Dezember 2018: Spezielle Musteranalysesysteme (PDF; 1,3 MB; 17 Seiten) Vorlesung im WS 2018 an der Universität Jena. Kap. 5, abgerufen am 24. Februar 2019.
- HMM R-Package zum Modellieren und Analysieren von Hidden-Markov-Modellen, das unter GPL2 frei verfügbar ist
- http://code.google.com/p/jahmm/ HMM Java-Bibliothek, die unter der neuen BSD-Lizenz verfügbar ist.
- http://www.ghmm.org/ HMM C-Bibliothek, die unter der LGPL frei verfügbar ist
Einzelnachweise
- S. Schmid, Dissertation, Technische Universität München, München, 2017. Single Protein Dynamics at Steady State Quantified from FRET Time Traces
- L. R. Rabiner: A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. (PDF; 2,2 MB; 30 Seiten) Proceedings of the IEEE, Band 77, Nr. 2, 1989, S. 257–286.
- P. Blunsom, 19. August 2004: Hidden Markov Models (PDF; 237 kB; 7 Seiten), archive.org, abgerufen am 21. Februar 2019.
- S. P. Chatzis: A Variational Bayesian Methodology for Hidden Markov Models.