Bedingte Entropie
In der Informationstheorie ist die bedingte Entropie ein Maß für die „Ungewissheit“ über den Wert einer Zufallsvariablen , welche verbleibt, nachdem das Ergebnis einer anderen Zufallsvariable bekannt wird. Die bedingte Entropie wird geschrieben und hat einen Wert zwischen 0 und , der ursprünglichen Entropie von . Sie wird in der gleichen Maßeinheit wie die Entropie gemessen.




Speziell hat sie den Wert 0, wenn aus der Wert von funktional bestimmt werden kann, und den Wert , wenn und stochastisch unabhängig sind.
Definition
Seien eine diskrete Zufallsvariable und ihr Wertevorrat, das heißt ist eine höchstens abzählbare Menge mit . Dann ist die Entropie von durch



definiert, wobei für typischerweise die Werte 2 (Bit) oder e (Nat) für die entsprechenden Einheiten angenommen werden. Ist für ein die Wahrscheinlichkeit gleich , so wird per Konvention gesetzt, der entsprechende Term geht also nicht in die Summe ein.





Es sei nun ein Ereignis mit . Dann definiert man die bedingte Entropie von gegeben durch Ersetzen der Wahrscheinlichkeit durch die bedingte Wahrscheinlichkeit, d. h.


- .

Jetzt sei eine diskrete Zufallsvariable mit Wertevorrat . Dann ist die bedingte Entropie von gegeben definiert als gewichtetes Mittel der bedingten Entropien von gegeben den Ereignissen für , d. h.



- .

Auf höherer Abstraktionsebene handelt es sich bei um den bedingten Erwartungswert der Informationsfunktion gegeben und bei um den Erwartungswert der Funktion .



Eigenschaften
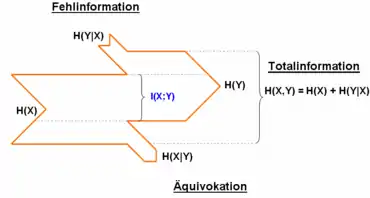
Eine einfache Rechnung zeigt
- ,

also ist die Unsicherheit von gegeben gleich der Unsicherheit von und abzüglich der Unsicherheit von .
Es ist mit Gleichheit genau dann, wenn und stochastisch unabhängig sind. Dies folgt aus der Tatsache, dass genau dann gilt, wenn und stochastisch unabhängig sind. Außerdem bedeutet es, dass ist, also die komplette empfangene Information nur Fehlinformation ist. Analog geht die komplette Information von der Quelle X verloren, so dass dann auch keine Transinformation vorhanden ist.



Außerdem gilt
- ,

mit Gleichheit genau dann, wenn funktional von abhängt, d. h. für eine Funktion .


Blockentropie
Übertragen auf eine multivariate Zufallsvariable der Länge , als Darstellung für einen -Block von Symbolen , lässt sich die bedingte Entropie definieren als die Unsicherheit eines Symbols (nach einem bestimmten vorgegebenen -Block):




- mit ,


wobei die Blockentropie bezeichnet. Für die bedingte Entropie , also die Unsicherheit eines Symbols nach einem -Block, folgt:




Die Definitionen der Blockentropie und der bedingten Entropie sind im Grenzübergang gleichwertig, vgl. Quellentropie.
In engem Zusammenhang zur bedingten Entropie steht auch die Transinformation, die die Stärke des statistischen Zusammenhangs zweier Zufallsgrößen angibt.
Beispiel
Sei X eine Quelle, die periodisch die Zeichen ...00100010001000100010... sendet.
Nun soll unter Berücksichtigung vorangegangener Zeichen die bedingte Entropie des aktuell zu beobachtenden Zeichens berechnet werden.
Keine berücksichtigten Zeichen
|
Die Berechnung erfolgt nach der Definition der Entropie. |
Wahrscheinlichkeitstabelle:
|





Ein berücksichtigtes Zeichen
|
Sei nun X:=xt und Y:=xt-1. Es ergeben sich folgende Wahrscheinlichkeiten: |
Wahrscheinlichkeitstabellen:
|














Zwei berücksichtigte Zeichen
|
Sei X:=xt und Y:=(xt-2, xt-1). Es ergeben sich folgende Wahrscheinlichkeiten:
|
Wahrscheinlichkeitstabellen:
|












Drei berücksichtigte Zeichen
|
Sind bereits drei nacheinander folgende Zeichen bekannt, so ist damit auch das folgende Zeichen determiniert (denn die Quelle verhält sich ja periodisch). Somit erhält man keine neue Information über das nächste Zeichen. Demnach muss die Entropie null sein. Dies kann man auch an der Wahrscheinlichkeitstabelle ablesen:
|




Erläuterung zu den Wahrscheinlichkeitstabellen
Die Tabellen beziehen sich auf die obige Beispielzeichensequenz.
Wobei gilt: Hier betrachtet man ein Zeichen unter der Bedingung des vorangegangenen Zeichens . Ist beispielsweise ein Zeichen , so lautet die Frage: Mit welcher Wahrscheinlichkeit ist das darauffolgende Zeichen bzw. ? Für ist das nächste Zeichen immer . Somit ist . Außerdem folgt daraus, dass ist, da die Zeilensumme immer Eins ist. |
Wobei gilt: Hier betrachtet man die Auftrittshäufigkeit einer Zeichenkombination. Man kann aus der Tabelle lesen, dass die Buchstabenkombinationen (0,1) und (1,0) genauso häufig auftreten. Die Summe aller Matrixeinträge ergibt Eins. |







Entropie und Informationsgehalt
Die Entropie fällt bei diesem Beispiel umso stärker, je mehr Zeichen berücksichtigt werden (siehe auch: Markow-Prozess). Wenn die Anzahl der berücksichtigten Zeichen hinreichend groß gewählt wird, so konvergiert die Entropie gegen Null.
Möchte man den Informationsgehalt der gegebenen Zeichenfolge aus n=12 Zeichen berechnen, so erhält man nach Definition Iges = n⋅H(X|Y) bei...
- ...keinem berücksichtigten Zeichen 9,39 bit Gesamtinformation. (Informationsgehalt statistisch unabhängiger Ereignisse)
- ...einem berücksichtigten Zeichen 8,26 bit Gesamtinformation.
- ...zwei berücksichtigten Zeichen 6 bit Gesamtinformation.
- ...drei berücksichtigten Zeichen 0 bit Gesamtinformation.
Literatur
- Martin Werner: Information und Codierung. Grundlagen und Anwendungen, 2. Auflage, Vieweg+Teubner Verlag, Wiesbaden 2008, ISBN 978-3-8348-0232-3.
- Karl Steinbuch, Werner Rupprecht: Nachrichtentechnik. Eine einführende Darstellung, Springer Verlag, Berlin / Heidelberg 1967.
- R. Mathar: Informationstheorie. Diskrete Modelle und Verfahren, B.G. Teubner Verlag, Stuttgart 1996, ISBN 978-3-519-02574-0.
Weblinks
- Vorlesungsskript: Gemeinsame Entropie und bedingte Entropie. (abgerufen am 19. Januar 2018)
- Bedingte Entropie (abgerufen am 19. Januar 2018)
- Statistische Methoden in der Sprachverarbeitung (abgerufen am 19. Januar 2018)
- Datensicherheit und Shannons Theorie (abgerufen am 19. Januar 2018)
- Wahrscheinlichkeit, Statistik, Induktion (abgerufen am 19. Januar 2018)