Informationsgehalt
Der Informationsgehalt (oder auch Überraschungswert) einer Nachricht ist eine logarithmische Größe, die angibt, wie viel Information in dieser Nachricht übertragen wurde.
Dieser Begriff wurde von Claude Shannon erstmals in seiner Informationstheorie formalisiert: Der Informationsgehalt eines Zeichens ist seine statistische Signifikanz. Er bezeichnet also die minimale Anzahl von Bits, die benötigt werden, um ein Zeichen (also eine Information) darzustellen oder zu übertragen. Wichtig ist dabei, dass dies nicht unbedingt der Anzahl der tatsächlich empfangenen Bits (der Datenmenge) entspricht, da der Informationsgehalt vom semantischen Kontext abhängig ist.
Definition
Der Informationsgehalt eines Zeichens x mit einer Auftrittswahrscheinlichkeit px ist definiert als
- .

a entspricht dabei der Mächtigkeit des Alphabets (d. h. der Anzahl der möglichen Zustände einer Nachrichtenquelle).
Abhängig von der gewählten Basis a ändert sich auch die Einheit des Informationsgehaltes. Dies stellte schon Shannon in A Mathematical Theory of Communication[1] fest. Im Allgemeinen kann die Einheit des Informationsgehaltes als Shannon (sh) bezeichnet werden, aber diese Einheitsbezeichnung hat sich nicht durchgesetzt. Im wohl häufigsten Fall, dass für das Alphabet (mit der Mächtigkeit a) das Binäralphabet gewählt wird, entspricht die Einheit des Informationsgehaltes dem Bit.
Im folgenden Text sei a = 2 (das Binärsystem) angenommen, wodurch man als Ergebnis die Anzahl der Binärziffern (in Bit) erhält. Stattdessen könnte auch jedes andere Zahlensystem verwendet werden.
Allgemeines
Der Begriff der Information, wie er in der Informationstheorie nach Shannon[2] verwendet wird, ist streng von dem gewöhnlichen Gebrauch dieses Begriffes zu unterscheiden. Insbesondere darf er nicht mit dem Begriff der Bedeutung gleichgesetzt werden. In Shannons Theorie können z. B. zwei Nachrichten, von denen eine von besonderer Bedeutung ist, während die andere nur „Unsinn“ darstellt, genau die gleiche Menge an Information enthalten. Für den einfachen Fall, in dem nur zwischen zwei möglichen Nachrichten zu wählen ist, wird dabei willkürlich festgelegt, dass die Information, die mit dieser Situation verbunden ist, gleich 1 ist. Die beiden Nachrichten, zwischen denen bei einer solchen Auswahl entschieden werden soll, können dabei völlig beliebig sein. Eine Nachricht könnte z. B. der Text des Telefonbuches sein und die andere Nachricht der einzelne Buchstabe „A“. Diese beiden Nachrichten könnten dann beispielsweise durch die Symbole 0 und 1 codiert werden.
Allgemeiner wird durch eine beliebige Nachrichtenquelle eine Folge von Auswahlvorgängen aus einer Menge von elementaren Zeichen vorgenommen, wobei diese ausgewählte Folge dann die eigentliche Nachricht darstellt. Hierbei ist leicht einzusehen, dass die Wahrscheinlichkeiten der Zeichen bei der Erzeugung der Nachricht von besonderer Wichtigkeit sind. Denn wenn die aufeinanderfolgenden Zeichen ausgewählt werden, ist diese Auswahl, zumindest vom Standpunkt des Kommunikationssystems aus, von dieser Wahrscheinlichkeit bestimmt. Diese Wahrscheinlichkeiten sind in den meisten Fällen sogar voneinander abhängig, d. h., sie hängen von den vorangegangenen Auswahlereignissen ab. Ist z. B. das letzte Wort einer Wortfolge der Artikel „die“, dann ist die Wahrscheinlichkeit dafür, dass als nächstes Wort wieder ein Artikel oder ein Verb auftritt, sehr gering.
Ein Maß, welches in besonderer Weise den natürlichen Anforderungen genügt, die man an dieses Informationsmaß stellt, entspricht genau dem, welches in der statistischen Physik als Entropie bekannt geworden ist. Wie dieses Informationsmaß von den entsprechenden Wahrscheinlichkeiten abhängt, wird im folgenden Abschnitt erklärt.
Formal werden die zu übertragenden Informationen als Zeichen bezeichnet. Dabei steht nur ein endlicher Zeichenvorrat zur Verfügung, Zeichen können aber beliebig kombiniert werden. Die minimale Anzahl von Bits, die für die Darstellung oder Übertragung eines Zeichens benötigt werden, hängt nun von der Wahrscheinlichkeit ab, mit der ein Zeichen auftritt: Für Zeichen, die häufig auftreten, verwendet man weniger Bits als für Zeichen, die selten verwendet werden. Datenkompressionstechniken machen sich das zu Nutze, insbesondere Entropiekodierungen wie die Arithmetische Kodierung und die Huffman-Kodierung. Ein ähnliches Verfahren wird zum Ausbalancieren von Binärbäumen verwendet.
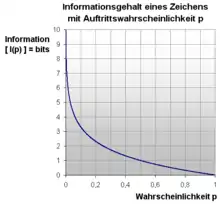
Grundsätzlich wird der Informationsgehalt für statistisch unabhängige Ereignisse und statistisch abhängige Ereignisse unterschiedlich berechnet.
Man könnte auch sagen, dass der Informationsgehalt eines Zeichens proportional zum (negativen) Logarithmus der Wahrscheinlichkeit ist, mit der man es erraten kann. Der Informationsgehalt ist also ein Maß für die maximale Effizienz, mit der eine Information übertragen werden kann.
Ein alternatives Maß für den Informationsgehalt einer Zeichenkette ist die Kolmogorov-Komplexität bzw. der algorithmische Informationsgehalt: er ist definiert als die Länge des kürzesten Programms, das diese Zeichenkette erzeugen kann. Ein weiterer Ansatz ist die sogenannte Algorithmische Tiefe, die besagt, wie aufwändig es ist, eine bestimmte Nachricht zu erzeugen. Gregory Chaitin ist ebenfalls über die Shannonsche Definition der Entropie einer Information hinausgegangen (siehe Algorithmische Informationstheorie).
In diesem Zusammenhang spielen auch die Kreuzentropie sowie die Kullback-Leibler-Divergenz als Maße für die durch eine schlechte Kodierung ausgelösten Verschwendungen von Bits eine Rolle.
Informationsgehalt statistisch unabhängiger Ereignisse
Sei eine Folge von n statistisch unabhängig aufeinanderfolgenden Ereignissen. Der Informationsgehalt ist dann die Summe der Informationsgehalte aller Ereignisse:



Ebenso lässt sich der Informationsgehalt mit der Entropie (mittlerer Informationsgehalt eines Zeichens) berechnen.


Bei einer Gleichverteilung der Wahrscheinlichkeiten für alle Zeichen aus dem Alphabet lässt sich die Gesamtinformation auch über die maximale Entropie beziehungsweise die Alphabetsgröße berechnen:




- bzw.


Der Informationsgehalt der beiden Quellen „01010101…“ und „10010110…“ ist aus der Betrachtung von statistisch unabhängigen Ereignissen nach obiger Formel gleich. Zu erkennen ist, dass die Zeichen der ersten Quelle durch eine sich wiederholende Struktur geordnet sind. Deshalb würde man intuitiv in der ersten Kette weniger Information als in der zweiten Kette vermuten. Bei der Betrachtung als statistisch unabhängiges Ereignis wird aber jedes Zeichen einzeln betrachtet und nicht der eventuelle Zusammenhang mehrerer Zeichen berücksichtigt.
Eine andere Definition der Information eines Zeichens liefert die bedingte Entropie. Bei ihr wird das Auftreten vorangegangener Zeichen berücksichtigt. Die aufeinanderfolgenden Zeichen werden in diesem Fall als statistisch abhängige Ereignisse betrachtet.
Informationsgehalt statistisch abhängiger Ereignisse
Bei statistisch abhängigen Ereignissen kennt man den Kontext der Ereignisse genauer und kann daraus Schlussfolgerungen ziehen, die den Informationsgehalt beeinflussen. Dabei können meistens die folgenden Ereignisse durch Ausschlussverfahren und Bindungen ‚erraten‘ werden. Ein Beispiel für statistisch abhängige Ereignisse ist ein Text in der deutschen Sprache: das „c“ tritt meistens paarweise mit einem „h“ oder „k“ auf. Andere Buchstaben unterliegen ebenfalls solchen paarweisen Bindungen.
Hierzu wird ähnlich wie bei statistisch unabhängigen Ereignissen der durchschnittliche und kontextsensitive Informationsgehalt eines Zeichens mit der Anzahl der vorhandenen Zeichen multipliziert:

Die bedingte Entropie berechnet sich folgend:

Bedingte Entropie als Differenz von Quell-Information und Transinformation:

Interpretation: Seien X und Y zwei stationär abhängige Quellen. H(X) sei die stationär betrachtete Quell-Entropie. I(X;Y) ist die Transinformation, die Information, die von X nach Y fließt, also die Menge an Information, von der man von X auf Y schließen kann. Ist diese Information hoch, so ist auch die Abhängigkeit von X und Y hoch. Dementsprechend ist die über X nach einer Beobachtung Y nicht so hoch, da man nicht sehr viel neue Information über Y erhält.
Bedingte Entropie als Gesamtinformation abzüglich der Entropie von H(Y):

Interpretation: Im statistisch abhängigen Fall zieht man von der Gesamtinformation (Verbundentropie) die gemeinsame Information (= I(X;Y)) von X und Y ab. Außerdem soll auch die neue Information, die Y mit sich bringt nicht mit eingerechnet werden, denn man möchte am Ende nur die Menge an Information von X herausbekommen, die X alleine beinhaltet. Deshalb rechnet man: H(X|Y) = H(X,Y) − I(X;Y) − H(Y|X)
Bemerkung: Die Information von statistisch abhängigen Ereignissen ist immer kleiner oder gleich der von statistisch unabhängigen Ereignissen, da wie folgt gilt: H(X|Y) ≤ H(X)
Verbundwahrscheinlichkeit H(X,Y)
Gibt es mögliche Ereignisse und mögliche Ereignisse , so ist die Verbundwahrscheinlichkeit die Wahrscheinlichkeit dafür, dass je ein Ereignis paarweise mit einem Ereignis auftritt.






Die Wahrscheinlichkeit , dass das Ereignis auftritt, ist die Gesamtwahrscheinlichkeit, dass paarweise mit dem Ereignis auftritt

- .

Mit der bedingten Wahrscheinlichkeit ergibt sich die Verbundwahrscheinlichkeit dann zu
- .

Der mittlere Informationsgehalt der Verbundentropie je Ereignispaar statistisch abhängiger Ereignisse ist somit definiert durch:

Informationsgehalt bei analogen Signalen
Der Informationsgehalt eines einzelnen Werts aus einem analogen Signal ist grundsätzlich unendlich, da die Auftrittswahrscheinlichkeit eines Wertes bei einer kontinuierlichen Wahrscheinlichkeitsverteilung gleich Null ist. Für den mittleren Informationsgehalt eines reellen, kontinuierlichen Signals kann statt der Entropie nach Shannon die differentielle Entropie berechnet werden.
Alternativ kann das Signal mit Hilfe eines Analog-Digital-Umsetzers in ein digitales umgewandelt werden, dabei geht jedoch Information verloren. Da nach der Umsetzung nur noch diskrete Werte vorkommen, kann deren Informationsgehalt wieder bestimmt werden.
Beispiele für statistisch unabhängige Ereignisse
Beispiel 1
An einer Quelle tritt ein Zeichen x mit der Wahrscheinlichkeit p(x) = 0,0625 auf. Für die maximale Effizienz zur Übertragung in einem Kanal ist eine Information von für jedes Zeichen x notwendig.

Beispiel 2
Gegeben sei eine Zeichenkette „Mississippi“. Sie besteht aus n = 11 Zeichen. Das Alphabet mit den Auftrittswahrscheinlichkeiten


Die Gesamtinformation beträgt:

Daraus folgt die Gesamtanzahl von 21 Bit, die notwendig ist, um die einzelnen Buchstaben des Wortes „Mississippi“ binär optimal zu kodieren.
Beispiel 3
Alphabet Z = {a, b} mit p(a) = 0,01 und p(b) = 0,99. Die Zeichenkette bestehe aus 100 Zeichen.
- (seltenes Auftreten ⇒ hohe Information im Falle des Auftretens)
- (häufiges Auftreten ⇒ wenig Information im Falle des Auftretens)


Gesamtinformation:

Damit folgt eine Gesamtinformation von 9 bit.
Siehe auch
Literatur
- Sebastian Dworatschek: Grundlagen der Datenverarbeitung. 8. Auflage, Walter De Gruyter, Berlin 1989, ISBN 3-11-012025-9.
- Martin Werner: Information und Codierung. Grundlagen und Anwendungen, 2. Auflage, Vieweg + Teubner Verlag, Wiesbaden 2008, ISBN 978-3-8348-0232-3.
- Werner Heise, Pasquale Quattrocchi: Informations- und Codierungstheorie. Mathematische Grundlagen der Daten-Kompression und -Sicherung in diskreten Kommunikationssystemen, 3. Auflage, Springer Verlag, Berlin / Heidelberg 1995, ISBN 3-540-57477-8.
Einzelnachweise
- C. E. Shannon: The Bell System Technical Journal Vol 27 (1948), pp. 379
- C. E. Shannon: Bell Syst. Techn. J. 30 (1951) 50
Weblinks
- Grundlagen der Informationstheorie (abgerufen am 16. Februar 2018)
- Informationsgehalt einer Nachricht (abgerufen am 16. Februar 2018)
- Informationstheorie (abgerufen am 16. Februar 2018)
- Codierungstheorie (abgerufen am 16. Februar 2018)
- Informationsgehalt und Komplexität von Zeitreihen (abgerufen am 16. Februar 2018)