Konfidenzintervall
Ein Konfidenzintervall, kurz KI, (auch Vertrauensintervall, Vertrauensbereich oder Erwartungsbereich genannt) ist in der Statistik ein Intervall, das die Präzision der Lageschätzung eines Parameters (z. B. eines Mittelwerts) angeben soll. Das Konfidenzintervall gibt den Bereich an, der mit einer gewissen Wahrscheinlichkeit (der Überdeckungswahrscheinlichkeit) den Parameter einer Verteilung einer Zufallsvariablen einschließt. Ein häufig verwendetes Konfidenzniveau ist 95 %.
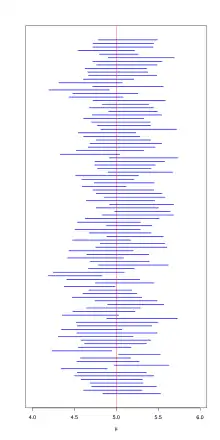
Die häufig anzutreffende Formulierung, dass der wahre Wert mit 95 % Wahrscheinlichkeit im für die vorliegende Stichprobe berechneten Konfidenzintervall liegt, ist streng genommen nicht korrekt,[1][2] da der wahre Wert keine Zufallsgröße, nicht stochastisch ist. Stochastisch sind vielmehr die obere und untere Grenze des Konfidenzintervalls. Folglich lautet die korrekte Formulierung: Bei der Berechnung eines Konfidenzintervalls mit einem bestimmten Schätzverfahren enthält es den wahren Wert mit 95 % Wahrscheinlichkeit. Es handelt sich nicht um eine Eigenschaft des Intervalls, sondern des Verfahrens. Wird es für viele Stichproben aus derselben Grundgesamtheit wiederholt, so sollte es Konfidenzintervalle liefern, die den wahren Wert näherungsweise mit einer dem Konfidenzniveau entsprechenden relativen Häufigkeit überdecken.


Das Schätzen von Parametern mit Hilfe von Konfidenzintervallen wird Intervallschätzung genannt, die entsprechende Schätzfunktion ein Bereichs- oder Intervallschätzer. Ein Vorteil gegenüber Punktschätzern ist, dass man an einem Konfidenzintervall direkt die Signifikanz ablesen kann: ein für ein vorgegebenes Konfidenzniveau breites Intervall weist auf einen geringen Stichprobenumfang oder auf eine starke Variabilität in der Grundgesamtheit hin.
Abzugrenzen von Konfidenzintervallen sind Prognoseintervalle sowie Konfidenz- und Vorhersagebänder.
Definition
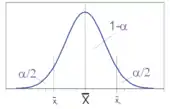
Für ein fest vorgegebenes ist ein -Konfidenzintervall für zum Konfidenzniveau (auch: ein -Konfidenzintervall) durch die beiden – auf einer Zufallsstichprobe basierenden – Statistiken und definiert, welche[3]








erfüllen. Die Statistiken und sind die Grenzen des Konfidenzintervalls, für die stets angenommen wird. Das Konfidenzniveau wird auch Überdeckungswahrscheinlichkeit genannt. Die Realisierungen und von bzw. bilden das Schätzintervall . Die Grenzen des Konfidenzintervalls sind Funktionen der Zufallsstichprobe und daher ebenfalls zufällig. Im Gegensatz dazu ist der unbekannte Parameter fest. Wenn man das Zufallsexperiment auf identische Art und Weise wiederholt, dann wird ein -Konfidenzintervall den unbekannten Parameter in aller Fälle überdecken. Da der unbekannte Parameter keine Zufallsvariable ist, kann man allerdings nicht sagen, dass in einem -Konfidenzintervall mit Wahrscheinlichkeit liegt. Solch eine Interpretation ist dem bayesschen Pendant von Konfidenzintervall, den sogenannten Glaubwürdigkeitsintervallen vorbehalten.[4] Das Konfidenzniveau wird auch Überdeckungswahrscheinlichkeit genannt. Oft setzt man . Die Wahrscheinlichkeit lässt sich als relative Häufigkeit interpretieren: Verwendet man für eine große Anzahl von Konfidenzschätzungen Intervalle, die jeweils das Niveau besitzen, so nähert sich die relative Häufigkeit, mit denen die konkreten Intervalle den Parameter überdecken, dem Wert .[5]







Formale Definition
Rahmenbedingungen
Gegeben sei ein statistisches Modell sowie eine Funktion

- ,

die im parametrischen Fall auch Parameterfunktion genannt wird. Die Menge enthält die Werte, die Ergebnis einer Schätzung sein können. Meist ist


Konfidenzbereich
Eine Abbildung

heißt ein Konfidenzbereich, Vertrauensbereich,[6] Bereichsschätzfunktion[7] oder ein Bereichsschätzer,[6] wenn sie die folgende Bedingung erfüllt:
- Für alle ist die Menge in enthalten. (M)



Ein Konfidenzbereich ist also eine Abbildung, die jeder Beobachtung eine vorerst beliebige Teilmenge von zuordnet ( ist hier die Potenzmenge der Menge , also die Menge aller Teilmengen von )


Die Bedingung (M) stellt sicher, dass allen Mengen eine Wahrscheinlichkeit zugeordnet werden kann. Dies wird zur Definition des Konfidenzniveaus benötigt.

Konfidenzintervall
Ist und ist für jedes immer ein Intervall, so heißt auch ein Konfidenzintervall.[6]



Werden Konfidenzintervalle in der Form
- ,

definiert, so nennt man auch die obere Konfidenzschranke und die untere Konfidenzschranke.[8]


Konfidenzniveau und Irrtumsniveau
Gegeben sei ein Konfidenzbereich . Dann heißt ein Konfidenzbereich zum Konfidenzniveau[7] oder Sicherheitsniveau[6] , wenn
- .

Der Wert wird dann auch das Irrtumsniveau[6] genannt. Eine allgemeinere Formulierung ist mit Formhypothesen möglich (siehe Formhypothesen#Konfidenzbereiche zu Formhypothesen).

Für die oben genannten Spezialfälle bei Konfidenzbereichen mit oberer und unterer Konfidenzschranke ergibt sich somit

bzw.

und

Konstruktion von Konfidenzintervallen
Konstruktion des Wald-Konfidenzintervalls
Wald-Konfidenzintervalle können mittels der sogenannten Wald-Statistik berechnet werden. Beispielsweise gilt für das asymptotische Wald-Konfidenzintervall, dass es mittels der Fisher-Information, der negativen zweiten Ableitung der Log-Likelihood-Funktion, konstruiert werden kann.[9] So umschließen die Intervallgrenzen des folgenden Konfidenzintervalls in 95 % der Fälle den wahren Parameter (asymptotisch für große Stichprobenumfänge)

- ,

wobei die Log-Likelihood-Funktion und die beobachtete Fisher-Information darstellt (die Fisher-Information an der Stelle des ML-Schätzers ).



Der Ausdruck wird auch als Standardfehler des Maximum-Likelihood-Schätzers bezeichnet.[9] Häufig wird statt der beobachteten Fisher-Information auch die erwartete Fisher-Information verwendet.[9]


Beispiel
Wird die Likelihood zum Beispiel mithilfe einer angenommenen Normalverteilung und einer Stichprobe (deren Variablen unabhängig und identisch verteilte Zufallsvariablen sind) mit Größe berechnet, so ist und somit


- also der bekannte Standardfehler des Mittelwertes.

Konstruktion anderer Konfidenzintervalle
Konfidenzintervalle lassen sich auch mithilfe von alternativen Parametrisierungen der Log-Likelihood-Funktion finden: zum Beispiel kann die Logit-Transformation oder der Logarithmus verwendet werden. Dies ist vorteilhaft, wenn die Log-Likelihood-Funktion sehr schief ist. Auch mithilfe des Likelihood-Quotienten können Konfidenzintervalle konstruiert werden.[9]
Eine nichtparametrische Art Konfidenzintervalle zu schätzen sind Bootstrap-Konfidenzintervalle, bei denen man keine Verteilung annehmen muss, sondern Bootstrapping benutzt.
Beschreibung des Verfahrens
Man interessiert sich für den unbekannten Parameter einer Grundgesamtheit. Dieser wird durch eine Schätzfunktion aus einer Stichprobe vom Umfang geschätzt. Es wird davon ausgegangen, dass die Stichprobe eine einfache Zufallsstichprobe ist, in etwa die Grundgesamtheit widerspiegelt und dass deshalb die Schätzung in der Nähe des wahren Parameters liegen müsste. Die Schätzfunktion ist eine Zufallsvariable mit einer Verteilung, die den Parameter enthält.

Man kann zunächst mit Hilfe der Verteilung ein Intervall angeben, das den unbekannten wahren Parameter mit einer Wahrscheinlichkeit überdeckt. Ermitteln wir z. B. das 95-%-Konfidenzintervall für den wahren Erwartungswert einer Grundgesamtheit, dann bedeutet dies, dass wir ein Konfidenzintervall ermitteln, das bei durchschnittlich 95 von 100 gleich großen Zufallsstichproben den Erwartungswert enthält.

Beispiel
Das Verfahren kann anhand eines normalverteilten Merkmals mit dem unbekannten Erwartungswert und der bekannten Varianz demonstriert werden: Es soll der Erwartungswert dieser Normalverteilung geschätzt werden. Verwendet wird die erwartungstreue Schätzfunktion: der Stichprobenmittelwert .


Der Erwartungswert der Grundgesamtheit wird anhand unserer Stichprobe geschätzt
- Schätzfunktion:

- Punktschätzung:

wobei die Zufallsvariable für die i-te Beobachtung (vor der Ziehung der Stichprobe) steht. Der Stichprobenmittelwert folgt einer Normalverteilung mit Erwartungswert und Varianz (siehe Stichprobenmittel#Eigenschaften)



- .

Die Grenzen des zentralen Schwankungsintervalls
- ,

das mit der Wahrscheinlichkeit überdeckt, bestimmen sich aus der Beziehung
- .

Man standardisiert zur Standardnormalverteilung und erhält für die standardisierte Zufallsvariable


die Wahrscheinlichkeit
- ,

wobei das -Quantil der Standardnormalverteilung ist. Löst man nach dem unbekannten Parameter auf, so ergibt sich aus



das -Konfidenzintervall für

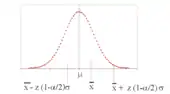


Das Schätzintervall, die Realisierung eines Konfidenzintervalles anhand einer konkreten Stichprobe, ergibt sich dann als

Die Grenzen des Schätzintervalles hängen jedoch von ab und ändern sich damit von Stichprobe zu Stichprobe. Ist die Stichprobe aber extrem ausgefallen, überdeckt das Intervall den Parameter nicht. Dies ist in α × 100 % aller Stichproben der Fall, d. h., das durch bestimmte Intervall überdeckt den wahren Parameter also mit einer Wahrscheinlichkeit von .
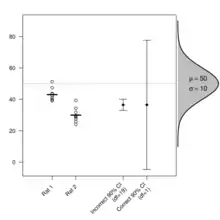
Von besonderem Interesse ist die Breite des Konfidenzintervalls. Diese bestimmt sich durch die Standardabweichung der Schätzfunktion und das gewählte Konfidenzniveau. Durch Erhöhung des Stichprobenumfangs kann die Breite verringert werden. Erwünscht ist in der Regel ein möglichst schmales Konfidenzintervall, denn dies weist bei konstantem Konfidenzniveau auf eine genaue Schätzung hin.
Als absoluter Fehler wird die halbe Breite des Konfidenzintervalls bezeichnet. Im obigen Fall gilt also


Der absolute Fehler ist ein Maß für die Genauigkeit der Schätzung (Breite des Konfidenzintervalls: ).

Der absolute Fehler ist von Bedeutung, wenn bei einem gegebenen Konfidenzintervall und einer gegebenen Konfidenzintervalllänge der benötigte Stichprobenumfang ermittelt werden soll. Die Frage lautet also: Welchen Stichprobenumfang benötigt man, um einen Parameter (z. B. arithmetisches Mittel) mit vorgegebener Genauigkeit und vorgegebenem Sicherheitsgrad zu schätzen?
Enthält die zugrundeliegende Stichprobe korrelierte Daten, so ist dies in der Schätzung der Standardabweichung zu berücksichtigen. Wird dies nicht berücksichtigt, so stößt man auf das Problem der Pseudoreplikation.

Ausgewählte Schätzintervalle
Übersicht für stetige Verteilungen
Eine Übersicht über alle Fälle bei normalverteilten Merkmalen findet sich im Artikel Normalverteilungsmodell.
| Erwartungswert eines normalverteilten Merkmals mit bekannter Varianz : ist das -Quantil der Standardnormalverteilung. |
|
| Erwartungswert eines normalverteilten Merkmals mit unbekannter Varianz: Die Varianz der Grundgesamtheit wird durch die korrigierte Stichprobenvarianz geschätzt. ist das -Quantil der t-Verteilung mit Freiheitsgraden. Für kann das Quantil der t-Verteilung näherungsweise durch das entsprechende Quantil der Standardnormalverteilung ersetzt werden. |
|
| Erwartungswert eines unbekannt verteilten Merkmals mit unbekannter Varianz: Falls genügend groß ist, kann aufgrund des zentralen Grenzwertsatzes das Konfidenzintervall bestimmt werden. |
|
| Standardabweichung eines normalverteilten Merkmals:
ist das p-Quantil der Chi-Quadrat-Verteilung mit Freiheitsgraden. |












Diskrete Verteilungen
Konfidenzintervalle für den Parameter p der Binomialverteilung sind beschrieben in dem
Das sogenannte Clopper-Pearson-Konfidenzintervall kann mit Hilfe der Beta- oder F-Verteilung bestimmt werden. Dieses Konfidenzintervall wird auch exakt genannt, da das geforderte Konfidenzniveau tatsächlich eingehalten wird. Bei Näherungsmethoden, die (meistens) auf der Approximation der Binomialverteilung durch die Normalverteilung basieren, wird das Konfidenzniveau oft nicht eingehalten.
Ist die Zahl der Elemente in der Grundgesamtheit bekannt, kann für den Parameter (mit Hilfe eines Korrekturfaktors) auch ein Konfidenzintervall für ein Urnenmodell ohne Zurücklegen angegeben werden.[10]
Konfidenzintervalle und Hypothesentests
Die Begriffe Konfidenzbereich und statistischer Test sind dual zueinander, unter allgemeinen Bedingungen können aus einem Konfidenzbereich für einen Parameter statistische Tests für entsprechende Punkthypothesen gewonnen werden und umgekehrt:
Testet man von einem Parameter die Nullhypothese: , dann wird die Nullhypothese bei einem Signifikanzniveau nicht abgelehnt, wenn das entsprechende -Konfidenzintervall, berechnet mit den gleichen Daten, den Wert enthält. Daher ersetzen Konfidenzintervalle gelegentlich auch Hypothesentests.


Beispielsweise testet man in der Regressionsanalyse, ob im multiplen linearen Regressionsmodell mit der geschätzten Regressionshyperebene

die wahren Regressionskoeffizienten gleich Null sind (siehe Globaler F-Test). Wenn die Hypothese nicht abgelehnt wird, sind die entsprechenden Regressoren vermutlich für die Erklärung der abhängigen Variablen unerheblich. Eine entsprechende Information liefert das Konfidenzintervall für einen Regressionskoeffizienten: Überdeckt das Konfidenzintervall die Null , so ist bei einem Signifikanzniveau der Regressionskoeffizient statistisch nicht verschieden von .





Die Begriffe der Unverfälschtheit und des gleichmäßig besten Tests lassen sich hierüber auf Konfidenzbereiche übertragen.
Beispiele für ein Konfidenzintervall
Beispiel 1
Ein Unternehmen möchte ein neues Spülmittel einführen. Um die Käuferakzeptanz auszuloten, wird das Spülmittel in einem Test-Supermarkt platziert. Mit dieser Aktion soll der durchschnittliche tägliche Absatz in einem Supermarkt dieser Größe geschätzt werden. Man definiert nun den täglichen Absatz als Zufallsvariable [Stück] mit den unbekannten Parametern Erwartungswert und Varianz . Man geht auf Grund langjähriger Beobachtungen hier davon aus, dass annähernd normalverteilt ist. Die Marktforschungsabteilung hat ein Konfidenzniveau von 0,95 (95 %) als ausreichend erachtet. Dann wird 16 Tage lang der tägliche Absatz erfasst. Es ergibt sich

| Tag | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Absatz | 110 | 112 | 106 | 90 | 96 | 118 | 108 | 114 | 107 | 90 | 85 | 84 | 113 | 105 | 90 | 104 |

Bei normalverteilter Grundgesamtheit mit unbekannter Varianz wird das Konfidenzintervall für den Erwartungswert angegeben als

Es ist das Mittel der Stichprobe

und die Varianz der Stichprobe

Es ist das -Quantil der t-Verteilung mit 15 Freiheitsgraden

Der Wert für t ist nicht trivial zu errechnen und muss daher aus einer Tabelle abgelesen werden.
Das 95-%-Konfidenzintervall berechnet sich dann als

Im Mittel enthalten 95 % der so geschätzten Intervalle den wahren Mittelwert , also den durchschnittlichen Tagesabsatz an Spülmittelflaschen in vergleichbaren Supermärkten. Für dieses konkrete Intervall trifft die Aussage, dass es mit 95 % Wahrscheinlichkeit den wahren Mittelwert enthält, jedoch nicht zu. Man weiß lediglich, dass dieses Intervall aus einer Menge (von Intervallen) stammt, von denen 95 % den wahren Mittelwert enthalten.
Beispiel 2
Ein Unternehmen lieferte ein Los (eine Charge) von 6000 Stück (z. B. Schrauben) an den Kunden. Dieser führt mittels Stichprobennahme gemäß der internationalen Norm ISO 2859-1[11] eine Eingangsprüfung durch. Dabei werden z. B. 200 Schrauben (je nach gewähltem AQL) zufällig über das gesamte Los gezogen und auf Übereinstimmung mit den vereinbarten Anforderungen (Qualitätsmerkmalen) geprüft. Von den 200 geprüften Schrauben erfüllen 10 Stück die gestellten Anforderungen nicht. Mittels der Berechnung des Konfidenzintervalls (Excel-Funktion BETAINV) kann der Kunde abschätzen, wie groß der zu erwartende Anteil fehlerhafter Schrauben im ganzen Los ist: bei einem Konfidenzniveau von 95 % berechnet man das Clopper-Pearson-Konfidenzintervall [2,4 %, 9 %] für den Anteil fehlerhafter Schrauben im Los (Parameter: n=200, k=10).
Literatur
- Ulrich Krengel: Einführung in die Wahrscheinlichkeitstheorie und Statistik. 8. Auflage. Vieweg, 2005.
- Joachim Hartung: Statistik. 14. Auflage. Oldenbourg, 2005.
Weblinks
Einzelnachweise
- Significance Test Controversy (englisch)
- What is the Real Result in the Target Population? In: Statistics in Brief: Confidence Intervals. PMC 2947664 (freier Volltext) (englisch)
- Leonhard Held und Daniel Sabanés Bové: Applied Statistical Inference: Likelihood and Bayes. Springer Heidelberg New York Dordrecht London (2014). ISBN 978-3-642-37886-7, S. 56.
- Leonhard Held und Daniel Sabanés Bové: Applied Statistical Inference: Likelihood and Bayes. Springer Heidelberg New York Dordrecht London (2014). ISBN 978-3-642-37886-7, S. 57.
- Karl Mosler und Friedrich Schmid: Wahrscheinlichkeitsrechnung und schließende Statistik. Springer-Verlag, 2011, S. 214.
- Hans-Otto Georgii: Stochastik. Einführung in die Wahrscheinlichkeitstheorie und Statistik. 4. Auflage. Walter de Gruyter, Berlin 2009, ISBN 978-3-11-021526-7, S. 229, doi:10.1515/9783110215274.
- Ludger Rüschendorf: Mathematische Statistik. Springer Verlag, Berlin Heidelberg 2014, ISBN 978-3-642-41996-6, S. 230–231, doi:10.1007/978-3-642-41997-3.
- Ludger Rüschendorf: Mathematische Statistik. Springer Verlag, Berlin Heidelberg 2014, ISBN 978-3-642-41996-6, S. 245, doi:10.1007/978-3-642-41997-3.
- Supplement: Loglikelihood and Confidence Intervals. Abgerufen am 14. Juli 2021.
- Siehe zum Beispiel Kap. IV, Abschnitte 3.1.1 und 3.2 bei Hartung. Hier werden die Wilson- und Clopper-Pearson-Intervalle, sowie der Korrekturfaktor für die hypergeometrische Verteilung besprochen.
- Annahmestichprobenprüfung anhand der Anzahl fehlerhaften Einheiten oder Fehler [Attributprüfung] - Teil 1: Nach der annehmbaren Qualitätsgrenzlage AQL geordnete Stichprobenpläne für die Prüfung einer Serie von Losen.