Interprozesskommunikation
Der Begriff Interprozesskommunikation (englisch interprocess communication, kurz IPC) bezeichnet in der Informatik verschiedene Verfahren des Informationsaustausches zwischen den Prozessen eines Systems. Mithilfe eines Shared Memory erfolgt die Kommunikation dadurch, dass mehrere Prozesse auf einen gemeinsamen Datenspeicher zugreifen können, beispielsweise gemeinsame Bereiche des Arbeitsspeichers. Bei einer Message Queue dagegen werden Nachrichten von einem Prozess an eine Nachrichtenschlange geschickt, von wo diese von einem anderen Prozess abgeholt werden können.
Die Kommunikation zwischen den Prozessen sollte in einer gut strukturierten Weise erfolgen. Um Race Conditions zu vermeiden, sollten die kritischen Abschnitte, in denen auf gemeinsam genutzten Speicher zugegriffen wird, vor einem (quasi-)gleichzeitigen Zugriff geschützt werden. Dies kann durch verschiedene Mechanismen wie Semaphore oder Monitore realisiert werden. Wenn jedoch jeder Prozess aus einer Menge von Prozessen auf ein Ereignis wartet, das nur ein anderer Prozess aus der Menge auslösen kann, entsteht eine Deadlock-Situation.
Klassische Problemstellungen der Interprozesskommunikation sind das Erzeuger-Verbraucher-Problem, das Philosophenproblem und das Leser-Schreiber-Problem.
Grundlagen
Ein Programm ist eine den Regeln einer bestimmten Programmiersprache genügende Folge von Anweisungen (bestehend aus Deklarationen und Instruktionen), um bestimmte Funktionen bzw. Aufgaben oder Probleme mithilfe eines Computers zu bearbeiten oder zu lösen.[1] Jedes Programm wird normalerweise in einem (Betriebssystem-)Prozess ausgeführt, der zum Ablauf einem Prozessor zugeordnet werden muss. Ein Prozess stellt auf einem Rechnersystem die Ablaufumgebung für ein Programm zur Verfügung und ist eine dynamische Folge von Aktionen mit entsprechenden Zustandsänderungen, oder anders gesagt, die Instanzierung eines Programms. Als Prozess bezeichnet man auch die gesamte Zustandsinformation eines laufenden Programms.[2] Werden verschiedene Prozesse in kurzen Abständen immer abwechselnd aktiviert, entsteht der Eindruck von Gleichzeitigkeit, auch wenn zu jedem Zeitpunkt unter Umständen immer nur ein Prozess verarbeitet wird (oder zumindest die Anzahl der Prozesse wesentlich höher ist als die Anzahl der vorhandenen CPUs).[3]
In Multitasking-Systemen laufen die meisten Prozesse nebenläufig und wissen kaum etwas voneinander. Ein Speicherschutz schützt das Betriebssystem davor, dass ein Prozess auf die Speichersegmente eines anderen Prozesses zugreifen kann (und so die Stabilität des Systems beeinträchtigen würde). Voraussetzung dafür ist eine Memory Management Unit (Speicherverwaltungseinheit, kurz MMU). Dennoch gibt es Anwendungsfälle, bei denen Prozesse mit anderen Prozessen kommunizieren müssen. Einige davon sind:
- Mehrere Prozesse müssen spezielle Daten gemeinsam verwenden.
- Die Prozesse sind untereinander abhängig und müssen aufeinander warten.
- Daten müssen von einem Prozess an einen anderen weitergereicht werden.
- Die Verwendung von Systemressourcen muss koordiniert werden.[4]
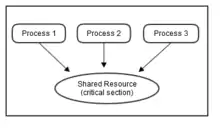
Kommunikation meint in diesem Zusammenhang grundsätzlich den Austausch von Informationen nach bestimmten Regeln. Sie sollte also in einer gut strukturierten Weise erfolgen. Das Regelwerk fasst man in der Datenkommunikation bzw. bei Rechennetzwerken unter dem Begriff Protokoll zusammen.[5]
Beispiele:
- Drucker-Spooler: Wenn ein Prozess eine Datei drucken möchte, trägt er den Dateinamen in einen speziellen Spoolerordner (spooler directory) ein. Ein anderer Prozess, der Drucker-Daemon (printer daemon), überprüft zyklisch, ob es irgendwelche Dateien zu drucken gibt. Wenn es welche gibt, druckt er diese aus und entfernt danach ihren Namen wieder aus dem Ordner.[6]
- Pipe: Durch die Eingabe eines „|“-Zeichens in der Unix-Shell wird die Ausgabe eines ersten Prozesses an einen zweiten Prozess weitergereicht.
Man nennt zwei Prozesse konkurrent, wenn es mindestens ein Zeitintervall gibt, in dem sie beide begonnen, aber nicht abgeschlossen sind. Im Einprozessorsystem können konkurrente Prozesse nur abschnittweise sequentiell bearbeitet werden, während im Mehrprozessorsystem datenunabhängige Abschnitte gleichzeitig ausgeführt werden können.[7]
Ein Betriebsmittel muss in dem Sinne determiniert sein, dass unter der Kontrolle des Betriebssystems ablaufende Programme jeweils identische Resultate liefern, unabhängig davon, in welcher Umgebung sie ablaufen, d. h. unabhängig mit welchen anderen Programmen zusammen. Andererseits sind die tatsächlichen Vorgänge nicht-determiniert, da es möglich sein muss, auf Ereignisse unabhängig von der Reihenfolge ihres Auftretens zu reagieren. Solche Ereignisse sind beispielsweise Betriebsmittelanforderungen, Laufzeitfehler und asynchrone Unterbrechungen, die von Ein- und Ausgabegeräten erzeugt werden.[8]
Techniken
Shared Memory
Mit der Shared Memory stellt das Betriebssystem einen Mechanismus bereit, durch den mehrere Prozesse auf einen gemeinsamen Datenspeicher zugreifen können. Um dies zu ermöglichen, muss ein Prozess als Erstes einen gemeinsamen Datenspeicher anlegen. Danach müssen alle Prozesse, die ebenfalls darauf zugreifen sollen, mit diesem Datenspeicher bekannt gemacht werden: Dies geschieht, indem der Speicherbereich im Adressraum der entsprechenden Prozesse eingefügt wird (siehe auch Speicherverwaltung). Ebenfalls muss hierbei den Prozessen mitgeteilt werden, wie diese auf den Speicherbereich zugreifen können (lesend / schreibend). Wurde all dies erledigt, kann der Datenspeicher wie ein gewöhnlicher Speicherbereich verwendet werden.
Shared Memory ist die schnellste Form der Interprozesskommunikation, da von zwei oder mehreren Prozessen ein bestimmter Speicherbereich gemeinsam benutzt wird, und somit das Kopieren zwischen Server und Clients nicht notwendig ist. Für eine ordnungsgemäße Kommunikation muss jedoch darauf geachtet werden, dass die einzelnen Prozesse untereinander synchronisiert werden. Als Mechanismus für die Prozesssynchronisation werden häufig Monitore oder Semaphore verwendet.[9]
Bei der Speicherverwaltung mittels Paging kann Shared Memory durch die Verwendung von gemeinsamen Seiten umgesetzt werden. Es verweisen dabei mehrere Seitentabelleneinträge verschiedener Prozesse auf gemeinsam genutzte Speicherbereiche (Seitenrahmen) im physischen Arbeitsspeicher.[10]
Kommunikation über Dateien
Eine einfache Form der Kommunikation ist der Austausch von Dateien: Ein Prozess kann Daten in Dateien schreiben, die ein anderer Prozess ebenfalls lesen (oder beschreiben) kann. Diese Variante erfordert ebenfalls eine Synchronisation. Häufig bietet das Betriebssystem einen Lock-Mechanismus an, der ganze Dateien sperrt. Es sind aber auch klassische Mechanismen wie Semaphore möglich.[11]
Message Queue (Nachrichtenschlange)
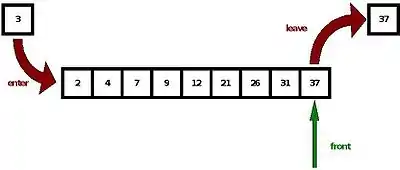
Bei diesem Mechanismus werden Nachrichten von einem Prozess an eine Message Queue (dt. Nachrichtenschlange) geschickt, die in Form einer verketteten Liste verwaltet wird. Dort kann die Nachricht von einem anderen Prozess abgeholt werden. Jede Message Queue hat eine eindeutige Kennung, wodurch sie auch von einem anderen Prozess identifiziert werden kann. Normalerweise wird nach dem First-In-First-Out-Prinzip (FIFO) gearbeitet. Die Nachrichten können aber auch mit einer Priorität versehen werden. Wenn ein Prozess eine Nachricht mit einer Priorität N abholt, holt er sich in der Schlange (Queue) die erste Nachricht mit der Priorität N, auch wenn diese beispielsweise als letzte eingefügt wurde.[12]
Warteschlangen werden beispielsweise häufig zur Datenübergabe zwischen asynchronen Prozessen in verteilten Systemen verwendet, wenn also Daten vor ihrer Weiterverarbeitung gepuffert werden müssen. Der Zugriff erfolgt dabei durch im Betriebssystem verankerte APIs. Die Größe der Warteschlange wird durch das Betriebssystem limitiert.
(Namenlose) Pipes
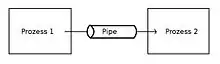
Die Pipe (oder Pipeline, von engl. Rohrleitung) ist eine der wichtigsten Anwendungen für Warteschlangen. Es handelt sich um einen Datenstrom zwischen zwei Prozessen durch einen Puffer nach dem FIFO-Prinzip. Das bedeutet vereinfacht, dass ein Ergebnis eines Computerprogramms als Eingabe eines weiteren Programms verwendet wird. Es handelt sich um die älteste und erste Technik der Interprozesskommunikation. Sie wurde 1973 von Douglas McIlroy für das Betriebssystem Unix erfunden.
Eine Pipe besitzt immer die folgenden zwei grundlegenden Eigenschaften:
- Bei einer Pipe können Daten immer nur in eine Richtung fließen. Ein Prozess kann praktisch immer nur in eine Pipe schreiben oder aus einer Pipe lesen. Will man anstatt der Halbduplex-Verbindung eine Vollduplex-Verbindung erstellen, benötigt man dazu zwei Pipes zwischen den Prozessen.
- Pipes können nur von Prozessen eingerichtet werden, die gemeinsame Vorfahren besitzen. Gewöhnlich wird eine Pipe eingerichtet, indem ein Elternprozess eine Pipe erzeugt und einen Kindprozess mittels fork() kreiert, der dabei diese Pipe erbt. Anschließend steht einer guten Kommunikation zwischen dem Elternprozess und dem Kindprozess nichts mehr im Wege.[13]
In unixoiden Betriebssystemen werden die Programme über das Pipe-Symbol „|“ verbunden. Beispielsweise sendet
who | sort
die Ausgabe von who in das sort-Programm, wodurch eine alphabetisch geordnete Liste der angemeldeten Benutzer ausgegeben wird.[14]
Benannte Pipes (FIFO-Pipes)
Unbenannte Pipes können nur mit den Prozessen kommunizieren, die miteinander verwandt sind. Benannte Pipes (engl. named pipes, auch FIFO-Pipes) können dagegen auch zur Kommunikation zwischen Prozessen eingesetzt werden, die nicht miteinander verwandt sind. Dazu bekommen sie wie Dateien entsprechende Namen. Jeder Prozess, der den Namen einer benannten Pipe kennt, kann über diesen Namen die Verbindung zur Pipe und damit zu anderen Prozessen herstellen. Für benannte Pipes müssen auch Zugriffsrechte vergeben werden, d. h., es muss festgelegt werden, wer in diese etwas schreiben und wer daraus auslesen darf.[15]
Sockets
Ein Socket ist der Endpunkt einer Kommunikationsstrecke, der von Programmen ähnlich wie eine Datei durch einen Dateideskriptor angesprochen wird. Im Gegensatz zu Pipes kann ein Socket gleichzeitig mit mehreren anderen in Kontakt stehen und kann auch von laufenden Programmen eingerichtet werden. Ursprünglich wurde die Socket-API 1984 für das BSD-Unix zur Kommunikation zwischen verschiedenen Rechnern über ein Netzwerk eingeführt, es besteht allerdings auch die Möglichkeit, eine Kommunikation zwischen Prozessen auf demselben Rechner auszuführen. Dies wird über den Geltungsbereich (domain) festgelegt: Der Bereich local domain ermöglicht die Kommunikation unterschiedlicher Prozesse auf einem Rechner, der Bereich internet domain den Informationsaustausch zwischen Prozessen auf unterschiedlichen Rechnern über die TCP/IP-Protokollfamilie. Wie die TCP/IP-Protokollfamilie sind BSD-Sockets mittlerweile auch in den meisten wichtigen Betriebssystemen außerhalb der Unix-Familie implementiert worden.[16]
Race Conditions
Unabhängige (disjunkte) Prozesse können beliebig „nebeneinander“ ablaufen, da sie nicht auf gemeinsame Daten schreiben. Sie können aber durchaus auf gewisse Daten gemeinsam zugreifen (diese dürfen während der Laufzeit nur nicht verändert werden). Wenn konkurrente Prozesse jedoch gemeinsame Daten enthalten, die verändert werden, spricht man von überlappenden Prozessen. Probleme, die dabei entstehen können, verdeutlicht das folgende Beispiel, bei dem die Variable a gleichzeitig von Prozess 1 und Prozess 2 benutzt wird:
a := 10
Prozess 1 Prozess 2
(1.1) a := a*a (2.1) a := a/2
(1.2) print(a) (2.2) print(a)
Die Ergebnisse, die Prozess 1 und Prozess 2 drucken, hängen von der Reihenfolge ab, in der ihre Anweisungen ausgeführt werden. Beispielsweise liefert bei der Anweisungs-Reihenfolge 1.1-1.2-2.1-2.2 Prozess 1 das Ergebnis 100 und Prozess 2 das Ergebnis 50. Bei der Anweisungsreihenfolge 2.1-1.1-1.2-2.2 geben jedoch beide Prozesse das Ergebnis 25 aus.[17] Die unterschiedlichen Ergebnisse hängen also von den relativen Geschwindigkeiten der überlappenden Prozesse ab.[17]
Die Art von Fehler in einem System oder einem Prozess, in dem der Ausgang des Prozesses unerwartet von der Reihenfolge oder Dauer anderer Ereignisse abhängt, nennt man Race Condition (Wettlaufsituation). Der Begriff entstammt der Vorstellung, dass zwei Signale in einem Wettlauf versuchen, die Systemantwort jeweils zuerst zu beeinflussen.
Race Conditions sind ein häufiger Grund für nur schwer auffindbare Programmfehler. Die Schwierigkeit liegt darin, dass sie nur selten, unter gewissen Bedingungen, auftreten. Ein geändertes Speichermodell oder Laufzeitverhalten des Systems kann den Fehler wieder „unsichtbar“ machen.
Andrew S. Tanenbaum macht das folgende Beispiel für eine Race Condition:
- Wenn ein Prozess einen Druckauftrag erteilt, trägt er den Dateinamen der zu druckenden Datei in eine Spooler-Ordner (spooler directory) ein. Der Drucker-Daemon prüft regelmäßig, ob es irgendwelche Dateien zu drucken gibt. Falls dies zutrifft, druckt er diese aus und entfernt danach ihren Namen wieder aus dem Ordner. Die Einträge seien mit 0, 1, 2 … nummeriert und es gebe zwei Variablen: out zeigt auf die nächste zu druckende Datei und in auf den nächsten freien Eintrag im Ordner. Seien nun die Einträge 0 bis 3 leer (bereits ausgedruckt) und die Einträge 4 bis 6 belegt (mit Namen von Dateien, die gedruckt werden sollen). Zwei Prozesse und entscheiden sich nun mehr oder weniger gleichzeitig, dass sie eine weitere Datei zum Ausdruck einreihen wollen.


- Es kann nun folgendes passieren: Der Prozess liest in aus und speichert deren Wert 7 in der lokalen Variable next_free_slot. Genau jetzt erfolgt ein Timerinterrupt und die CPU entscheidet, dass der Prozess nun lange genug gelaufen ist, und wechselt deshalb zum Prozess . Der Prozess liest in aus und bekommt genau wie eine 7. Auch er speichert sie in seiner lokalen Variablen next_free_slot. In diesem Augenblick glauben beide Prozesse, dass der nächste verfügbare Eintrag 7 ist.
- Wenn Prozess nun weiterläuft, speichert er den Namen seiner Datei im Eintrag 7 und aktualisiert in auf 8. Ist Prozess wieder an der Reihe, so weist next_free_slot auf den Eintrag 7 und er löscht also den Eintrag, den Prozess soeben angelegt hatte. Danach setzt Prozess in wiederum auf 8. Prozess wird dadurch niemals eine Ausgabe erhalten.[18]
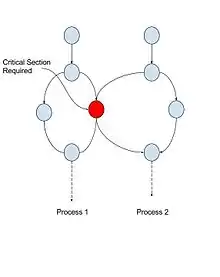
Führt ein Prozess interne Berechnungen durch, ist dies unproblematisch. Manchmal muss er aber auch auf gemeinsam genutzten Speicher oder Dateien zugreifen oder andere kritische Operationen ausführen. Dies kann zu eben solchen Wettlaufsituationen führen. Die Teile des Programms, in denen auf gemeinsam genutzten Speicher zugegriffen wird, bezeichnet man als kritischen Abschnitt (critical section) oder kritische Region (critical region). Im Gegensatz dazu sind unkritische Abschnitte solche, in denen nicht auf von mehreren Prozessen gemeinsam benutzte Daten zugegriffen wird. Kritische Abschnitte in Prozessen müssen eindeutig gegen die unkritischen Abschnitte abgegrenzt sein.[19]
Andrew S. Tanenbaum nennt vier Bedingungen, die eingehalten werden müssen, um Race Conditions zu vermeiden:[19]
- Keine zwei Prozesse dürfen gleichzeitig in ihren kritischen Abschnitten sein. Es braucht also einen wechselseitigen Ausschluss (mutual exclusion) der Prozesse.
- Es dürfen keine Annahmen über Geschwindigkeit und Anzahl der CPUs gemacht werden.
- Kein Prozess, der außerhalb seines kritischen Abschnitts läuft, darf andere Prozesse blockieren.
- Kein Prozess sollte ewig darauf warten müssen, in seinen kritischen Abschnitt einzutreten.
Synchronisation
Aktives Warten
Unter aktivem Warten (busy waiting) versteht man das fortlaufende Überprüfen einer Variablen, bis ein gewisser Wert erscheint. Nach diesem Prinzip wird ein Spinlock verwendet, um eine gemeinsam genutzte Ressource vor konkurrenten Prozessen zu schützen. Während sich ein Prozess in einem kritischen Abschnitt befindet, muss ein anderer Prozess, der ebenfalls den kritischen Abschnitt betreten will, „aktiv“ warten. Dadurch wird jedoch viel CPU-Zeit verschwendet.[20]
Sperrvariablen und strikter Wechsel
Um zu verhindern, dass mehrere Prozesse gleichzeitig einen kritischen Abschnitt betreten, kann man eine Sperrvariable einführen, die nur die Werte 0 oder 1 annehmen kann. Wenn nun ein Prozess den kritischen Abschnitt betreten will, fragt er zunächst die Sperrvariable ab. Ist diese 1, so ist die Sperre gesetzt und der Prozess muss warten, bis ein anderer Prozess den kritischen Abschnitt verlassen hat. Ist sie 0, befindet sich kein Prozess im kritischen Abschnitt. Der Prozess setzt die Sperrvariable also auf 1 und betritt den kritischen Abschnitt. Beim Verlassen setzt er die Variable wieder auf 0, damit wieder andere Prozesse den kritischen Abschnitt betreten können. Ein Prozess braucht also bei Eintritt zwei Operationen, eine zum Testen der Sperrvariable und eine zum Setzen der Sperrvariable.
Es besteht jedoch folgendes Fehlerszenario: Es kann passieren, dass Testen und Setzen der Sperrvariable durch eine CPU-Scheduling-Entscheidung unterbrochen wird: Ein Prozess sieht, dass die Sperre 0 ist, doch bevor er diese auf 1 setzen kann, wird er unterbrochen. In der Zwischenzeit setzt ein Prozess die Sperre auf 1. Wenn nun Prozess wieder an der Reihe ist, setzt er die Sperre ebenfalls auf 1 und es befinden sich zwei Prozesse gleichzeitig im kritischen Abschnitt.[21]
Abhilfe dagegen schafft ein strikter Wechsel mit einer ganzzahligen Variablen turn. Wenn turn auf 1 gesetzt ist, kann der Prozess den kritischen Abschnitt betreten. Wenn nun den kritischen Abschnitt wieder verlässt, setzt er turn auf 2. Dies ermöglicht es den kritischen Abschnitt zu betreten. Am Ende des kritischen Abschnitts setzt dann seinerseits turn wieder auf 1.
Dieses „sich Abwechseln“ ist jedoch keine gute Voraussetzung, wenn einer der Prozesse sehr viel langsamer als der andere ist. Der eine Prozess hängt solange in einer Warteschleife fest, bis der andere Prozess den kritischen Abschnitt wieder freigibt.[22]
Wechselseitiger Ausschluss mit Hardware-Unterstützung
Um zu verhindern, dass ein Prozess zwischen Lesen und Setzen einer Sperrvariablen die CPU verliert (und dadurch versehentlich zwei Prozesse in einen kritischen Abschnitt eintreten), kann auf Hardware-Unterstützung zurückgegriffen werden.
In manchen Prozessorarchitekturen ist der TSL-Befehl (Test and Set Lock) verfügbar, der in einer unteilbaren Operation einen Registerwert liest und schreibt. Durch den Befehl
TSL RX LOCK
wird der Inhalt des Speicherwortes LOCK ins Register RX eingelesen und ein Wert ungleich null wird dann an der Speicheradresse von LOCK abgelegt. Solange die CPU den TSL-Befehl ausführt, kann kein anderer Prozess auf das Speicherwort zugreifen. Der Speicherbus bleibt gesperrt.
Um den Zugriff auf einen kritischen Abschnitt zu koordinieren, kann also eine gemeinsam genutzte LOCK-Variable eingesetzt werden. Wenn ein Prozess eintreten will, kopiert er die Sperrvariable LOCK ins Register RX und überschreibt sie mit einem Wert ungleich 0 (mit dem TSL-Befehl in einer einzigen unteilbaren Operation). Nun vergleicht er den alten Wert, der nun in RX steht, mit 0. Falls dieser nicht 0 ist, war die Sperre bereits gesetzt, also geht das Programm in die Warteschleife. Wenn der Wert 0 wird, kann der aufrufende Prozess den kritischen Abschnitt betreten. Wenn ein Prozess den kritischen Abschnitt verlässt, setzt er mithilfe eines gewöhnlichen MOVE-Befehls den Wert von LOCK wieder zurück auf 0.[23] Siehe dazu den folgenden Assembler-Code:
enter_critical_section:
TSL RX LOCK // kopiere die Sperrvariable LOCK ins Register RX und überschreibe LOCK mit einem Wert ungleich 0
CMP RX, #0 // war die Sperrvariable 0?
JNE enter_critical_section // wenn der Wert nicht 0 ist, dann war die Sperre schon gesetzt -> gehe in die Schleife
RET // sonst springe zurück und betrete kritischen Abschnitt
leave_critical_section:
MOVE LOCK, #0 // speichere 0 in die Sperrvariable LOCK
RET // springe zurück
Eine Alternative zu TSL ist der XCHG-Befehl, der die Inhalte zweier Speicherstellen automatisch austauscht, zum Beispiel von einem Register und einem Speicherwort.[24]
Algorithmus von Peterson
Der Algorithmus von Peterson wurde 1981 von Gary L. Peterson formuliert und bietet eine Lösung für das wechselseitige Ausschlussproblem. Bevor ein kritischer Abschnitt betreten wird, ruft jeder Prozess enter_section(int process) mit seiner eigenen Prozessnummer, 0 oder 1, als Parameter auf. Der Eintritt in den kritischen Abschnitt wird damit so lange verzögert, bis er sicher ist. Sobald ein Prozess den kritischen Abschnitt wieder verlässt ruft er leave_section(int process) mit seiner eigenen Prozessnummer als Parameter auf. Jetzt kann ein anderer Prozess den kritischen Abschnitt betreten, sofern er das möchte.
#define FALSE 0
#define TRUE 1
#define N 2 // Anzahl der Prozesse
int turn; // Gibt an, wer gerade an der Reihe ist
int interested[N]; // Alle Werte mit 0 (FALSE) initialisieren
void enter_section(int process)
{
int other; // Variable für Nummer des anderen Prozesses
other = 1 - process; // Der andere Prozess
interested[process] = TRUE; // Interesse zeigen
turn = other; // Flag setzen
while (interested[other] == TRUE && turn == other) ; // Leeranweisung (Aktives Warten)
}
void leave_section(int process) // Prozess, der den kritischen Abschnitt verlässt
{
interested[process] = FALSE; // Zeigt den Ausstieg aus dem kritischen Abschnitt an
}
Wenn nun beispielsweise Prozess 0 enter_section(0) aufruft, bekundet er sein Interesse, indem er interested[0] auf TRUE und die Variable turn auf 0 (seine Prozessnummer) setzt. Wenn der Prozess 1 nicht interessiert ist (interested[1]==FALSE und turn==0), kehrt die Funktion sofort zurück (und der kritische Abschnitt kann betreten werden). Wenn nun der Prozess 1 (etwas später) enter_section(1) aufruft, muss er so lange warten, wie interested[0] == TRUE gilt. Jedoch erst wenn der Prozess 0 leave_section(0) aufruft, um die kritische Region zu verlassen, wird interested[0] auf FALSE gesetzt, und der Prozess 1 kann in den kritischen Abschnitt eintreten.
Für den Fall, dass beide Prozesse fast gleichzeitig enter_section(int process) aufrufen und jeweils ihre Prozessnummern in turn speichern, zählt das zuletzt beendete Speichern, d. h., das erste Speicherergebnis wird überschrieben und geht verloren. Da beide Prozesse ihr Interesse angezeigt haben, gilt sowohl interested[0] == TRUE als auch interested[1] == TRUE Konnte nun beispielsweise der Prozess 0 als Letzter in turn speichern, gilt turn == 0. Der Prozess 1 kann unter dieser Bedingung den kritischen Abschnitt nicht betreten, er muss in der Warteschleife warten, bis der andere Prozess interested auf FALSE setzt.[25]
Passives Warten
Beim passiven Warten wird ein Prozess, der einen kritischen Abschnitt betreten will, „schlafen gelegt“ (beispielsweise indem er in eine Warteschlange eingefügt wird) solange er warten muss. Der Zustand bleibt solange bestehen, bis er in den kritischen Abschnitt eintreten darf. Dann wird er von einem anderen Prozess aufgeweckt.
Semaphor
Das Konzept der Semaphore wurde 1965 von Edsger W. Dijkstra entwickelt und setzt auf Sperrmechanismen auf.[26] Beim Start des Semaphors wird der Semaphorzähler mit einem ganzzahligen Wert initialisiert, der anzeigt, wie viele Prozesse gleichzeitig eine Ressource nutzen können. Außerdem verwaltet das Semaphor eine Warteschlange für die Prozesse, die am Eingang des kritischen Abschnitts warten müssen. Bei der Nutzung eines Semaphors für gegenseitigen Ausschluss wird der Semaphorzähler einfach mit 1 initialisiert. Für den Eintritt in den kritischen Abschnitt und den Austritt aus diesem stehen zwei Operationen zur Verfügung:
- Die down-Operation down(s) wird beim Eintritt in den kritischen Abschnitt aufgerufen. Sie prüft zunächst, ob der Wert des Semaphorzählers größer als 0 ist. Trifft dies zu, wird der Wert des Semaphorzählers um 1 reduziert und der Prozess kann eintreten. Wenn der Semaphorzähler gerade auf 0 steht, wird dem ankommenden Prozess der Eintritt verwehrt und er wird in die Warteschlange eingereiht.
- Die up-Operation up(s) wird beim Verlassen des kritischen Abschnitts aufgerufen. Der Semaphorzähler wird wieder um 1 erhöht, womit ein weiterer Prozess in den kritischen Bereich eintreten kann.[27]
Die Verwendung von Semaphoren soll durch eine Analogie veranschaulicht werden: Man nehme an, eine Bibliothek habe 10 Studierzimmer, die jeweils immer nur von einem Studenten benutzt werden können. Ein Rezeptionist „Semaphor“ sorgt nun dafür, dass die „Ressource“ Studierzimmer korrekt belegt wird. Dazu führt er einen Zähler, der über die Anzahl der freien Studierzimmer Buch führt (und mit 10 initialisiert wird). Jedes Mal, wenn ein Student ein Studierzimmer betritt, wird der Zähler um eins reduziert. Wenn der Zähler 0 ist, sind alle Studierzimmer belegt und die ankommenden Studenten müssen in einer Warteschlange eingereiht werden. Die wartenden Studenten dürfen in der Zwischenzeit schlafen. Erst wenn ein Student ein Studierzimmer verlässt, wird der vorderste Student in der Warteschlange „aufgeweckt“ und zu den Studierzimmern eingelassen.
Bei der Implementierung von Semaphoren muss jedoch beachtet werden, dass die Operationen down(s) und up(s) selbst kritische Abschnitte aufweisen. Um Race Conditions zu vermeiden, können beispielsweise der TSL- oder der XCHG-Befehl verwendet werden, um die kritischen Abschnitte von down(s) und up(s) zu schützen. Dadurch wird aktives Warten zwar nicht ganz vermieden, die Operationen des Semaphors sind allerdings sehr kurz.[28]
Mutex
Der Begriff Mutex ist nicht einheitlich definiert. Nach Peter Mandl handelt es sich um ein binäres Semaphor, d. h. um ein Semaphor mit dem Maximalwert N=1.[29] Ein Mutex verfügt praktisch über eine Variable, die nur zwei Zustände, nämlich locked und unlocked, annehmen kann. Es wird also theoretisch nur ein Bit zur Darstellung benötigt. Für das Arbeiten auf einem Mutex stehen die beiden Prozeduren mutex_lock und mutex_unlock zur Verfügung.[30]
Einige Autoren weisen durchaus auf Unterschiede zwischen Mutexen und binären Semaphoren hin. Der wesentliche Unterschied dürfte darin bestehen, dass ein Mutex dem aufrufenden Prozess (bzw. Thread) gehört, während mit einem Semaphor kein Besitzer verbunden ist. Wenn beispielsweise bei einem Semaphor der Semaphorzähler 0 (locked) ist, kann ihn ein anderer Prozess (bzw. Thread) erhöhen, auch wenn es sich nicht um den Prozess handelt, der ihn ursprünglich gesperrt hat.[31]
Monitor
Die Implementierung des wechselseitigen Ausschlusses mit Hilfe von Synchronisationsprimitiven wie Semaphore ist ziemlich fehleranfällig. Deshalb entwickelten 1974 C.A.R. Hoare und 1975 Per Brinch Hansen ein auf höherem Abstraktionsniveau angesiedeltes Synchronisationsmittel, den Monitor. Ein Monitor ist ein Modul (ein abstrakter Datentyp, eine Klasse), in dem die von Prozessen gemeinsam genutzten Daten und ihre Zugriffsprozeduren (oder Methoden) zu einer Einheit zusammengeführt sind. Zugriffsprozeduren mit kritischen Abschnitten auf den Daten werden als Monitor-Operationen speziell gekennzeichnet. Zugriffsprozeduren ohne kritische Abschnitte können vom Modul zusätzlich angeboten werden.
Die Funktionalität von Monitoren ist derjenigen von Semaphoren gleichwertig. Monitore sind jedoch für den Programmierer leichter zu überschauen, „da gemeinsam benutzte Daten und Zugriffskontrollen zentral gebündelt an einer Stelle lokalisiert sind und nicht wie im Falle von Semaphoren getrennt über mehrere Prozesse verteilt im Programmcode stehen“.[32] Grundlegende Eigenschaften eines Monitors sind:
- Kritische Abschnitte, die auf denselben Daten arbeiten, sind Prozeduren eines Monitors.
- Ein Prozess betritt einen Monitor durch Aufruf einer Prozedur des Monitors.
- Nur ein Prozess kann zur selben Zeit den Monitor benutzen. Jeder andere Prozess, der den Monitor betritt, wird suspendiert und muss warten, bis der Monitor verfügbar wird.[32]
Ein Monitor wird oft als ein Raum angesehen, in dem nur ein Akteur (Prozess) Platz findet. Wollen weitere Akteure in den Monitorraum, so müssen sie warten, bis im Monitorraum Platz frei geworden ist.
Wenn ein Prozess eine Monitorprozedur aufruft, prüfen in der Regel die ersten Befehle der Prozedur, ob ein anderer Prozess gerade im Monitor aktiv ist. Wenn kein anderer Prozess den Monitor benutzt, kann er eintreten. Andernfalls wird der aufrufende Prozess „schlafen gelegt“, bis der andere Prozess den Monitor verlassen hat. Der wechselseitige Ausschluss von Monitoreintritten wird nun vom Compiler realisiert, beispielsweise unter Verwendung eines Mutex oder eines binären Semaphors. Der Programmierer muss nicht wissen, wie der Compiler den wechselseitigen Ausschluss regelt. Dadurch ist es sehr viel unwahrscheinlicher, dass etwas schiefgeht. Es reicht zu wissen, dass zwei Prozesse in ihren kritischen Abschnitten nicht gleichzeitig ausgeführt werden dürfen, wenn man alle kritischen Abschnitte in Monitorprozeduren bündelt.[33]
Deadlocks
Eine Menge von Prozessen befindet sich in einem Deadlock-Zustand, wenn jeder Prozess aus der Menge auf ein Ereignis wartet, das nur ein anderer Prozess aus der Menge auslösen kann. Kein Prozess wird jemals aufwachen, da er jeweils auf Ereignisse wartet, die andere Prozesse auslösen, die jedoch wieder auf Ereignisse von ihm warten.[34]
Andrew S. Tanenbaum macht das folgende Beispiel: Zwei Prozesse wollen beide ein Dokument einscannen und anschließend auf eine CD brennen. Prozess belegt fürs Erste den Scanner. Prozess verfährt etwas anders und reserviert sich zunächst den CD-Brenner. Nun versucht Prozess den CD-Brenner ebenfalls zu reservieren, was aber fehlschlägt, weil Prozess diesen noch nicht freigegeben hat. Fatalerweise will jedoch Prozess den Scanner nicht freigeben, solange der CD-Brenner nicht verfügbar ist. Die beiden Prozesse blockieren sich also gegenseitig.[35]
Für Deadlocks gibt es auch Beispiele aus dem alltäglichen Leben: Wenn an einer Straßenkreuzung von allen vier Seiten gleichzeitig Autos ankommen und die Vortrittsregel „rechts vor links“ gilt, müssen theoretisch alle vier Autos (endlos) warten, denn jedes Auto wartet darauf, dass das jeweils rechts wartende Auto zuerst fährt.[36]
Klassische Problemstellungen
Erzeuger-Verbraucher-Problem
Das Erzeuger-Verbraucher-Problem (producer-consumer problem, auch bekannt als Problem des begrenzten Puffers) thematisiert die Zugriffsregelung auf eine Datenstruktur mit elementerzeugenden (schreibenden) und elementverbrauchenden (lesenden) Prozessen. So können sich zwei Prozesse einen Puffer mit fester Größe teilen: Einer der Prozesse, der Erzeuger, legt Informationen in den Puffer, der andere, der Verbraucher, nimmt sie heraus.[37] Die Zugriffsregelung soll nun verhindern, dass der Verbraucher auf die Datenstruktur (Puffer) zugreift, wenn diese keine Elemente enthält und der Erzeuger auf die Datenstruktur zugreift, wenn die Aufnahmekapazität bereits ausgeschöpft ist.
Eine mögliche Lösung wäre, die Anzahl der Nachrichten in einem Puffer mit einer Variable count zu verfolgen. Die maximale Anzahl der Nachrichten, die ein Puffer aufnehmen kann, sei dabei N. Ist nun count gleich N, wird der Erzeuger schlafen gelegt, andernfalls kann er eine Nachricht hinzufügen und count wird um eins erhöht. Wenn count gleich 0 ist, wird der Verbraucher schlafen gelegt, andernfalls kann er eine Nachricht entfernen und count wird um eins reduziert. Jeder der Prozesse prüft auch, ob der andere aufgeweckt werden sollte, und falls dies zutrifft, tut er dies.[37]
Durch diese Implementierung können jedoch Race Conditions entstehen, beispielsweise folgendermaßen: Der Puffer ist leer und in dem Moment, als der Verbraucher count prüft, wird der Prozess durch eine CPU-Scheduling-Entscheidung unterbrochen. Anschließend wird der Erzeuger gestartet, der eine Nachricht in den Puffer legt und count um eins erhöht. Überzeugt davon, dass count davor 0 war und der Verbraucher deshalb schläft, löst er ein wakeup aus um den Erzeuger zu wecken. Das Wakeup-Signal geht dabei verloren. Wenn der Verbraucher jedoch das nächste Mal läuft, geht er davon aus, dass der Wert von count 0 ist, da er diesen Wert zuvor gelesen hatte. Er wird sich deshalb schlafen legen. Der Erzeuger wird nun zunehmen den Puffer füllen und sich dann ebenfalls schlafen legen. Wenn sie nicht gestorben sind, dann schlafen sie noch immer.[38]
Das Problem des verlorenen Weckrufs lässt sich beispielsweise durch die Verwendung von Semaphoren lösen.
Philosophenproblem

Das Philosophenproblem ist ein Synchronisationsproblem, das Edsger W. Dijkstra 1965 veröffentlichte und löste. Es ist nützlich, um Prozesse zu veranschaulichen, die um den exklusiven Zugriff auf eine begrenzte Anzahl Ressourcen wie beispielsweise Ein-/Ausgabegeräte konkurrieren.
Bei der Problemstellung müssen genau zwei Betriebsmittel (hier Gabeln) belegt werden, bevor die Arbeit gemacht werden kann. Es sitzen fünf Philosophen (fünf Prozesse/Threads) um einen runden Tisch. Jeder Philosoph hat einen Teller mit Spaghetti vor sich und zwischen zwei Tellern liegt jeweils eine Gabel. Zum Essen braucht ein Philosoph genau zwei Gabeln. Ein Philosoph verbringt seine Zeit entweder mit Denken oder mit Essen. Wenn er Hunger bekommt, greift er nach seiner linken und seiner rechten Gabel (in beliebiger Reihenfolge). Wenn es ihm gelingt, die beiden Gabeln zu ergreifen, isst er für eine gewisse Zeit lang und legt danach die Gabeln wieder hin. Es können also maximal zwei Philosophen gleichzeitig essen. Die Hauptfrage ist: Kann man ein Programm für die Philosophen schreiben, das funktioniert und niemals verklemmt?[39]
Eine einfache Lösung besteht darin, die Gabeln als Semaphore zu realisieren und mit 1 zu initialisieren. Da aber nicht zwei Semaphore gleichzeitig aufnehmen können, besteht die Gefahr eines Deadlocks, wenn Philosophen zwischen den beiden Gabelaufnahmen unterbrochen werden. Wenn beispielsweise alle Philosophen quasi gleichzeitig ihre linke Gabel aufnehmen, wird es keinem möglich sein, seine rechte Gabel aufzunehmen. Die Philosophen warten ewig auf die rechte Gabel.
Eine mögliche Lösung besteht nun darin, eine Statusvariable stat zu verwenden, die für einen Philosophen drei Zustände verfolgt: Denken (0), Hungrig (1) und Essen (2). Damit ein Philosoph vom hungrigen Status (stat == 1) in den essenden Status (stat == 2) übergehen kann, darf keiner seiner Nachbarn gerade essen. Ein Feld von Semaphoren mit einem Semaphor pro Philosoph ermöglicht es nun, auch Philosophen zu blockieren, falls die benötigten Gabeln in Gebrauch sind.[40]
Leser-Schreiber-Problem
Beim Leser-Schreiber-Problem geht es um zwei Typen von Prozessen (bzw. Threads), die Leser und die Schreiber. Man geht nun von der Situation aus, dass eine Menge von Lesern und Schreibern einen gemeinsamen kritischen Bereich betreten wollen. Dabei gilt es jedoch, folgende Bedingungen einzuhalten:
- Im kritischen Abschnitt dürfen sich niemals Leser und Schreiber gleichzeitig aufhalten.
- Im kritischen Abschnitt dürfen sich beliebig viele Leser gleichzeitig aufhalten.
- Im kritischen Abschnitt dürfen sich niemals mehrere Schreiber gleichzeitig aufhalten.
Andrew S. Tanenbaum nennt dazu ein Beispiel für ein Reservierungssystem einer Fluggesellschaft, in welchem es viele konkurrente Prozesse gibt, die Lese- und Schreibrechte wünschen. Es ist akzeptabel, wenn mehrere Prozesse gleichzeitig die Datenbank auslesen, aber wenn ein Prozess die Datenbank aktualisiert (beschreibt), darf kein anderer Prozess auf die Datenbank zugreifen, nicht einmal zum Lesen.[41]
Eine Lösung bietet sich mit Hilfe eines Semaphors db an: Wenn ein Leser Zugriff auf die Datenbank bekommt, führt er ein down auf das Semaphor db aus. Wenn er fertig ist, führt er ein up aus. Solange mindestens ein aktiver Leser existiert, kann kein Schreiber in den kritischen Abschnitt eintreten. Ein Schreiber, der eintreten will, wird also solange stillgelegt, als es Leser im kritischen Abschnitt gibt. Falls jedoch fortlaufend neue Leser in den kritischen Bereich eintreten, kann es sein, dass ein Schreiber niemals Zugriff erhält. Er verhungert. Eine mögliche Lösung für dieses Problem besteht darin, dass ankommende Leser hinter bereits wartende Schreiber gestellt werden. Auf diese Weise braucht der Schreiber nur auf Leser zu warten, die vor ihm da waren, bis er zugreifen kann.[42]
Siehe auch
Literatur
- Erich Ehses, Lutz Köhler, Petra Riemer, Horst Stenzel, Frank Victor: Systemprogrammierung in UNIX / Linux. Grundlegende Betriebssystemkonzepte und praxisorientierte Anwendungen. Vieweg+Teubner: Wiesbaden, 2012.
- Peter Mandl: Grundkurs Betriebssysteme. Architekturen, Betriebsmittelverwaltung, Synchronisation, Prozesskommunikation, Virtualisierung. 4. Auflage, Springer Vieweg: Wiesbaden, 2014.
- Peter Pacheco: An Introduction to Parallel Programming. Elsevier: Amsterdam, u. a., 2011.
- Abraham Silberschatz, Peter B. Galvin, Greg Gagne: Operating System Concepts. Eighth Edition, John Wiley & Sons: Hoboken (New Jersey), 2008.
- Andrew S. Tanenbaum: Moderne Betriebssysteme. 3., aktualisierte Auflage. Pearson Studium, München u. a., 2009, ISBN 978-3-8273-7342-7.
- Jürgen Wolf, Klaus-Jürgen Wolf: Linux-Unix-Programmierung. Das umfassende Handbuch. 4. Aufl., Rheinwerk Verlag: Bonn, 2016. (ältere, ebenfalls zitierte Ausgabe: Jürgen Wolf: Linux-UNIX-Programmierung. Das umfassende Handbuch. 3., aktualisierte und erweiterte Auflage, Rheinwerk: Bonn, 2009.)
Einzelnachweise
- ISO/IEC 2382-1:1993 definiert „computer program“: „A syntactic unit that conforms to the rules of a particular programming language and that is composed of declarations and statements or instructions needed to solve a certain function, task, or problem.“ Bis 2001 definierte die DIN 44300 „Informationsverarbeitung Begriffe“ identisch.
- Mandl: Grundkurs Betriebssysteme. 4. Aufl., 2014, S. 78.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 124–125.
- Jürgen Wolf: Linux-UNIX-Programmierung. Das umfassende Handbuch. 3., aktualisierte und erweiterte Auflage, Galileo Computing: Bonn, 2009, S. 275.
- Mandl: Grundkurs Betriebssysteme. 4. Aufl., 2014, S. 196.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl. 2009, S. 162.
- Wolfgang K. Giloi: Rechnerarchitektur. 2. Auflage, Springer-Verlag: Berlin, Heidelberg, 1993, S. 48.
- Lutz Richter: Betriebssysteme. 2. Auflage, B. G. Teubner: Stuttgart, 1985, S. 41.
- Jürgen Wolf, Klaus-Jürgen Wolf: Linux-Unix-Programmierung. Das umfassende Handbuch. 4. Aufl., Rheinwerk Verlag: Bonn, 2016, S. 354, 424-427; ferner Mandl: Grundkurs Betriebssysteme. 2014, S. 198.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 344.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 199.
- Jürgen Wolf, Klaus-Jürgen Wolf: Linux-Unix-Programmierung. Das umfassende Handbuch. 4. Aufl., Rheinwerk Verlag: Bonn, 2016, S. 354, 411.
- Jürgen Wolf, Klaus-Jürgen Wolf: Linux-Unix-Programmierung. Das umfassende Handbuch. 4. Aufl., Rheinwerk Verlag: Bonn, 2016, S. 359.
- Daniel J. Barrett: Linux. kurz & gut. 2. Aufl., O'Reilly: Beijing, u. a., 2012 (Deutsche Übersetzung von Kathrin Lichtenberg).
- Jürgen Wolf, Klaus-Jürgen Wolf: Linux-Unix-Programmierung. Das umfassende Handbuch. 4. Aufl., Rheinwerk Verlag: Bonn, 2016, S. 351.
- Konrad Heuer, Reinhard Sippel: UNIX-Systemadministration. Linux, Solaris, AIX, FreeBSD, Tru64-UNIX. Springer: Berlin, Heidelberg, 2004, S. 106–107.
- Lutz Richter: Betriebssysteme. 2. Auflage, B. G. Teubner: Stuttgart, 1985, S. 42.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 162–163.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl., 2009, S. 163.
- Tanenbaum: Moderne Betriebssysteme. S. 166.
- Tanenbaum: Moderne Betriebssysteme. S. 165–166; Mandl: Grundkurs Betriebssysteme. S. 160.
- Tanenbaum: Moderne Betriebssysteme. S. 166–167.
- Tanenbaum: Moderne Betriebssysteme. 2014, S. 168–170.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 170.
- Tanenbaum: Moderne Betriebssysteme. S. 167–168.
- Edsger W. Dijkstra: Cooperating sequential processes (EWD-123). E.W. Dijkstra Archive. Center for American History, University of Texas at Austin, September 1965. (Original)
- Mandl: Grundkurs Betriebssysteme. 2014, S. 162–163, ferner Tanenbaum: Moderne Betriebssysteme. 2009, S. 173.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 174.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 164; so auch Jürgen Quade, Michael Mächtel: Moderne Realzeitsysteme kompakt. Eine Einführung mit Embedded Linux. dpunkt.verlag: Heidelberg, 2012, S. 100–105.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 176.
- Peter Pacheco: An Introduction to Parallel Programming. Elsevier: Amsterdam, u. a., 2011, S. 174; Richard H. Carver, Kuo-Chung Tai: Modern Multithreading. Implementing, Testing, and Debugging Multithreaded Java and C++ Pthreads Win32 Programs. Wiley Interscience: Hoboken, 2006, S. 91–92.
- Cornelia Heinisch, Frank Müller-Hofmann, Joachim Goll: Java als erste Programmiersprache. Vom Einsteiger zum Profi. 6. Auflage, Vieweg + Teubner: Wiesbaden, 2011, S. 764.
- Tanenbaum: Moderne Betriebssysteme. 2009, 182.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 516.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 512.
- Dietrich Boles: Parallele Programmierung spielend gelernt mit dem Java-Hamster-Modell. Programmierung mit Java-Threads. Vieweg+Teubner: Wiesbaden, 2008, S. 226.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 171.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 172.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 212–213; Mandl: Grundkurs Betriebssysteme. 2014, S. 166.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 213–215.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 215.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 215–217.