Paging
Als Paging (vgl. engl. page „Speicherseite“) bezeichnet man die Methode der Speicherverwaltung per Seitenadressierung durch Betriebssysteme. Nur selten wird die deutsche Bezeichnung Kachelverwaltung verwendet.[1]
Das Paging ermöglicht eine virtuelle Speicherverwaltung. Der virtuelle Speicher bezeichnet den vom tatsächlich vorhandenen physischen Arbeitsspeicher unabhängigen Adressraum, der einem Prozess vom Betriebssystem zur Verfügung gestellt wird. Da meist mehr virtuelle Adressen existieren als im physischen Arbeitsspeicher umsetzbar sind, werden einige Speicherbereiche vorübergehend auf die Festplatte ausgelagert.
Beim Paging wird der virtuelle Adressraum in gleich große Stücke unterteilt, die man als Seiten (engl. pages) bezeichnet. Auch der physische Adressraum ist derart unterteilt. Die entsprechenden Einheiten im physischen Speicher nennt man Seitenrahmen oder auch Kacheln (engl. page frames). Die Seiten werden in der sogenannten Seitentabelle (engl. page table) verwaltet, die Informationen darüber enthält, wo für eine (virtuelle) Seite der entsprechende (reale) Seitenrahmen im Arbeitsspeicher tatsächlich zu finden ist, sowie meistens Zusatzinformationen zum Beispiel zu Gültigkeit, Schreibrechten oder ob (sowie evtl. wohin) die Seite ausgelagert wurde.
Wenn ein Prozess eine virtuelle Adresse anspricht, die keiner physischen Arbeitsspeicher-Adresse zugeordnet ist, wird ein Systemaufruf ausgelöst. Dieser Aufruf wird Seitenfehler (engl. page fault) genannt. Als unmittelbare Folge des Seitenfehlers kommt es zu einer synchronen Prozessunterbrechung (Trap). Das Betriebssystem prüft dann, ob ein zugehöriger Seitenrahmen existiert und gerade ausgelagert ist – dann wählt es einen wenig benutzten Seitenrahmen aus, schreibt dessen Inhalt zurück auf die Festplatte, lädt den benötigten Seitenrahmen in den frei gewordenen Arbeitsspeicherbereich, ändert die Zuordnungstabelle und setzt den unterbrochenen Prozess mit dem fehlgeschlagenen Befehl fort.
Existiert zu der angeforderten virtuellen Adresse kein ausgelagerter Seitenrahmen, so kann das Betriebssystem entweder einen (ggf. zuvor „freigeschaufelten“) leeren realen Seitenrahmen zuordnen und den Prozess fortsetzen, oder den Prozess abbrechen unter dem Hinweis „Seitenfehler“. Aktuell verbreitete Betriebssysteme brechen einen Prozess in diesem Fall ab.
Funktionsweise
Virtueller Adressraum
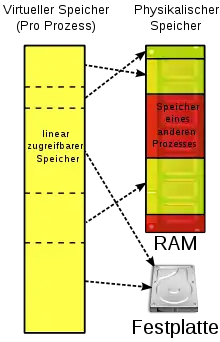
Der physische Adressraum ist durch den tatsächlich verfügbaren Arbeitsspeicher (Hauptspeicher) gegeben. Eine physische Adresse ist eine reale Adresse einer Speicherzelle im Arbeitsspeicher. Meistens verwenden Prozesse jedoch nicht mehr physische, sondern nur noch virtuelle (logische) Adressen. Das Prinzip der virtuellen Speicherverwaltung ermöglicht es, dass alle aktiven Prozesse mehr Speicherplatz belegen dürfen, als tatsächlich im physischen Adressraum zur Verfügung steht. Die virtuellen Adressen bilden den virtuellen Adressraum. Diese gehen nun nicht direkt an den Speicherbus, sondern an die Memory Management Unit (MMU, dt. Speicherverwaltungseinheit), welche die virtuellen Adressen auf die physischen Adressen abbildet.[2]
Aus der Sicht des Programmierers, der mit virtuellen Adressen arbeitet, erscheint der Adressraum (fast) unbegrenzt. Er braucht keine Rücksicht darauf zu nehmen, ob diese Adressen im real vorhandenen physischen Arbeitsspeicher wirklich existieren. Das Betriebssystem löst diese Aufgabe mit der vorübergehenden Auslagerung von Speicherbereichen auf einen Massenspeicher, meistens die Festplatte.[3] Bei der Speicherverwaltung werden also Daten vom Arbeitsspeicher auf die Festplatte ein- und ausgelagert.
Häufig verfügt ein System über sehr viel mehr virtuellen als physischen Speicher. Konkret legt das installierte RAM fest, wie groß der physische Speicher ist, während der virtuelle Adressraum von der Architektur des Befehlssatzes abhängt. Mit einem 32-Bit-Prozessor kann man maximal Byte (also 4 GiB) Speicher adressieren, mit einem 64-Bit-System Byte (16 EiB), auch wenn beispielsweise nur 512 MiB RAM tatsächlich installiert sind.[2]


Das Konzept der virtuellen Speicherverwaltung ist meist Basis für Multitasking, da so jede Task einen eigenen Adressraum besitzen kann, was die Abschirmung der Tasks voneinander unterstützt; zusätzlich ist die Größe des Task-Adressraums nicht mehr abhängig davon, wie viel Arbeitsspeicher andere Tasks belegen.[2]
Zur Organisation des virtuellen Speichers gibt es einerseits den segmentorientierten Ansatz (siehe Segmentierung), bei dem der Speicher in Einheiten unterschiedlicher Größen aufgeteilt ist, und andererseits den seitenorientierten Ansatz (Paging), bei dem alle Speichereinheiten gleich lang sind.
Seitenauslagerung
Beim Paging wird der virtuelle Adressraum in gleich große Stücke unterteilt, die man als Seiten (engl. pages) bezeichnet. Auch der physische Adressraum ist derart unterteilt. Die entsprechenden Einheiten im physischen Speicher nennt man Seitenrahmen oder auch Kacheln (engl. page frames). Seiten und Seitenrahmen sind in der Regel gleich groß, beispielsweise 4 KiB.[4]
Beispiel: Die physische Größe des Arbeitsspeichers sei 64 KiB. Ein Programm benötigt insgesamt 200 KiB Speicher. Um das größere Programm trotzdem auf dem kleineren Arbeitsspeicher ausführen zu können, kann man den Adressraum in Seiten (Pages) aufteilen, beispielsweise vier Seiten zu 64 KiB, wobei dann die letzte Seite nur teilweise gefüllt ist. Es befindet sich dann jeweils eine der vier Seiten im physischen Arbeitsspeicher, die anderen drei sind auf die Festplatte ausgelagert.[5]
Der Teil der Festplatte, der für die ausgelagerten Seiten verwendet wird, wird Paging-Area oder Schattenspeicher genannt. Zum Ein- und Auslagern der Seiten existieren viele verschiedene Strategien. Grundsätzlich wird immer versucht, die Seiten im Arbeitsspeicher zu halten, die auch in naher Zukunft verwendet werden, um möglichst selten ein Paging durchzuführen.[6]
Solange die Speicherzugriffe Seiten betreffen, die im Arbeitsspeicher liegen, arbeitet das System ganz normal. Wird aber eine Seite im ausgelagerten Speicher angesprochen, muss die angeforderte Seite eingelagert werden (und unter Umständen eine andere Seite ausgelagert werden). Außerdem muss eine Adressabbildung aktiviert werden. Das ganze Verfahren heißt Seitenauslagerung oder Paging.[7]
Adressabbildung
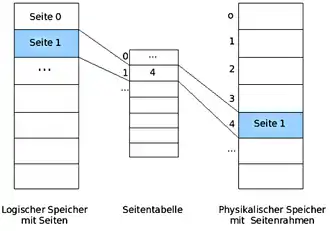
Im Multiprogramming-Betrieb stellt der Memory-Manager jedem Prozess einen eigenen virtuellen Adressraum zur Verfügung, d. h. eine Menge von Adressen, die ein Prozess zur Adressierung des Speichers benutzen kann.[8] Der virtuelle Adressraum eines Prozesses wird nun beim Paging in Einheiten aufgebrochen, die sogenannten Seiten. Diese werden in der sogenannten Seitentabelle (page table) verwaltet, die Informationen darüber enthält, wo für eine Seite die entsprechenden Seitenrahmen im Arbeitsspeicher tatsächlich zu finden sind.[9] Mathematisch kann die Tabelle als eine Funktion aufgefasst werden, die die virtuelle Seitennummer als Argument nimmt und die Seitenrahmennummer (Page-Frame-Nummer) als Ergebnis liefert. Dadurch kann eine virtuelle Adresse auf eine physische Adresse abgebildet werden.[10]
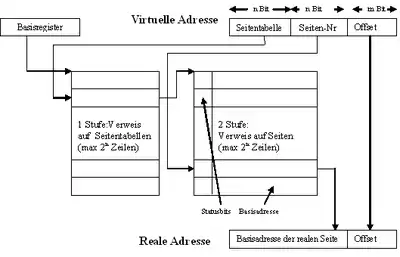
Eine virtuelle Adresse wird in zwei Teile zerlegt: Eine virtuelle Seitennummer (höherwertige Bits) und einen Offset (niederwertige Bits). Die virtuelle Seitennummer wird als Index für den Eintrag in der Seitentabelle benutzt. Der Offset stellt den relativen Abstand einer Adresse zu einer Basisadresse dar. Er ist also die Distanz, die die genaue Byteadresse innerhalb einer Seite angibt. Mit Hilfe der virtuellen Seitennummer als Index wird in der Seitentabelle der zugehörige Eintrag ausfindig gemacht. Dieser enthält einen Verweis auf den Seitenrahmen (Page-Frame). Die Seitenrahmennummer wird zur physischen Adresse ergänzt und zusammen mit der Distanz (Offset) erhält man die physische Adresse. Die Größe des Offsets sollte also so gewählt werden, dass damit jede Adresse innerhalb einer Seite angesprochen werden kann.[11]
Die folgende Grafik veranschaulicht, wie aus einer virtuellen Adresse eine physische Adresse (hier: Reale Adresse) berechnet wird:
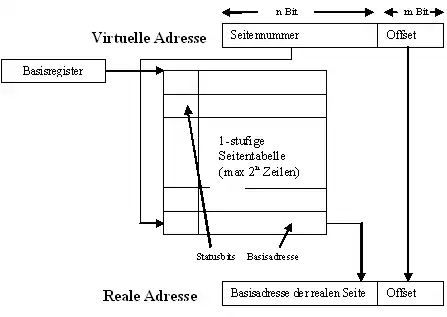
Die virtuelle Adresse besteht aus zwei Binärzahlen, die n-bit-lange Seitennummer und der m-bit-lange Offset. Der höherwertige Teil der physischen Adresse (hier: Basisadresse der realen Seite) wird der Seitentabelle entnommen, mit der Seitennummer als Index. Wird dieser mit dem Offset konkateniert, so ergibt sich eine neue Zahl, die genau die physische Speicheradresse ist. Derartige Berechnungen werden von der Memory Management Unit durchgeführt.
Die Adressen auf der Festplatte, an denen die ausgelagerten Seiten liegen, werden nicht in der Seitentabelle gespeichert. Diese enthält nur Informationen, die die Hardware zur Umrechnung einer virtuellen Adresse in eine physische benötigt. Bei der Behandlung von Seitenfehlern wird auf eigene Tabellen im Betriebssystem zurückgegriffen.[12]
Aufbau eines Seitentabelleneintrages
Über die Seitennummer als Index kann ein Eintrag in der Seitentabelle adressiert werden. Der genaue Aufbau eines solchen Eintrages ist stark maschinenabhängig. Die darin enthaltene Information ist jedoch von Maschine zu Maschine etwa gleich. Nach Andrew S. Tanenbaum (2009) sieht ein typischer Seitentabelleneintrag folgendermaßen aus:[13]
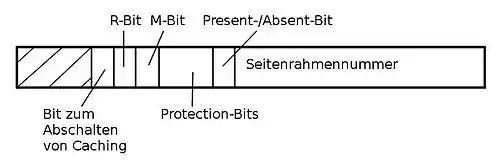
Die einzelnen Einträge haben dabei die folgenden Bedeutungen:[14]
- Seitenrahmennummer: Eine physische Adresse im Arbeitsspeicher, auf den der Eintrag verweist (siehe Abschnitt oben).
- Present-/Absent-Bit: Dieses zeigt an, ob die Seite momentan im Arbeitsspeicher liegt (Bit auf 1 gesetzt) oder nicht (Bit auf 0 gesetzt). Letzteres erzeugt einen Seitenfehler.
- Protection-Bits (auch Schutzbits): Diese regeln den Zugriff auf die Seite. Im einfachsten Fall enthält das Feld nur 1 Bit, mit 0 für Lese- und Schreibzugriff und 1 für Schreibzugriff. Eine ausgefeiltere Methode benutzt drei Bits, jeweils eines für das Leserecht, eines für das Schreibrecht und eines für das Recht, die Seite auszuführen.
- M-Bit (Modified-Bit, auch Dirty-Bit): Das M-Bit wird gesetzt, wenn ein Programm auf eine Seite schreibt. Dies verwendet das Betriebssystem beim Auslagern einer Seite: Wenn die Seite verändert wurde, muss der Seitenrahmen zurück auf die Festplatte geschrieben werden, wenn nicht, kann er einfach überschrieben werden, weil die Kopie der Seite auf der Festplatte noch aktuell ist.
- R-Bit (Referenced-Bit): Das R-Bit wird bei jedem Zugriff auf die Seite gesetzt, egal ob Lese- oder Schreibzugriff. Es hilft dem Betriebssystem bei der Entscheidung, welche Seite bei einem Seitenfehler ausgelagert werden soll. Seiten, die nicht benutzt wurden, sind bessere Kandidaten als solche, auf die ständig zugegriffen wird.
- Bit zum Abschalten von Caching: Mit diesem Bit kann das Caching abgeschaltet werden. Dies ist insbesondere für Seiten relevant, die auf Geräteregister statt auf Speicher abgebildet werden. Rechner, die einen getrennten E/A-Adressraum haben und keine Memory-Mapped-Ein-/Ausgabe benutzen, brauchen dieses Bit nicht.
Seitenfehler
Wenn ein Prozess eine Adresse anspricht, die nicht im Arbeitsspeicher geladen ist, erzeugt die MMU einen sogenannten Seitenfehler (engl. page fault), dessen Behandlung vom Betriebssystem übernommen wird. Für einen Seitenfehler gibt es zwei generelle Ursachen:
- Der eigentlich zugehörige Seitenrahmen ist nur vorübergehend nicht im Arbeitsspeicher vorhanden, etwa weil er gerade ausgelagert ist oder der Prozess das erste Mal auf diese Seite zugreift.
- Die Seite ist ungültig bzw. der Prozess hat auf eine ihm nicht erlaubte virtuelle Adresse zugegriffen. Dabei wird eine „Segmentation fault“ oder „General protection fault“ ausgelöst.[15]
Als unmittelbare Folge eines Seitenfehlers kommt es zu einer synchronen Prozessunterbrechung (Trap): Es wird ein sogenannter Pagefault-Interrupt ausgelöst. Das Betriebssystem springt im Kernelmodus auf eine spezielle Unterbrechungsroutine zur Bearbeitung des Seitenfehlers und versucht unter Beachtung der Seitenersetzungsstrategie und der Vergabestrategie die Seite in einen Seitenrahmen zu laden. Anschließend erhält der unterbrochene Prozess nach Möglichkeit entweder sofort oder später wieder den Prozessor (siehe dazu Prozesszustände). Insbesondere werden die folgenden Schritte durch das Betriebssystem ausgeführt:[16]
- Es wird überprüft, ob die Anforderung erlaubt ist.
- Es wird ein freier Seitenrahmen im Arbeitsspeicher gesucht. Falls kein freier Seitenrahmen gefunden werden kann, muss zuerst durch Auslagerung des Inhalts eines Seitenrahmens auf die Festplatte Platz geschafft werden.
- Es werden die benötigten Informationen auf der Festplatte gesucht und in den gefundenen Seitenrahmen kopiert.
- Der zugehörige Eintrag in der Seitentabelle wird angepasst, d. h., die Adresse der Seite wird eingetragen und das entsprechende Present-/Absent-Bit wird gesetzt.
Um einen freien Seitenrahmen zu finden, kann beispielsweise eine Freelist verwaltet werden. Dafür eignet sich ein Bitvektor, der für jeden Seitenrahmen ein Bit enthält. Ist das Bit gesetzt, so wird dieser benutzt, andernfalls ist er frei und kann belegt werden. Sobald ein Seitenrahmen belegt oder freigegeben wird, muss natürlich die Freelist entsprechend angepasst werden.[17]
Translation Lookaside Buffer
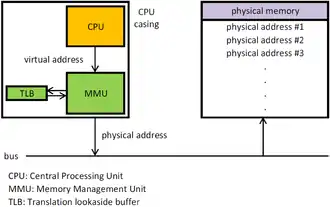
Translation Lookaside Buffer (Adressumsetzpuffer, kurz: TLB) werden eingesetzt, um die Übersetzung der virtuellen in die physischen Adressen zu beschleunigen.
Würde ausschließlich die Seitentabelle im Arbeitsspeicher gehalten, würde die Ausführungsgeschwindigkeit deutlich verringert. Beispielsweise ist für einen 1-Byte-Befehl, der ein Register in ein anderes kopiert, ohne Paging nur ein Speicherzugriff nötig, um den Befehl aus dem Speicher zu holen. Mit Paging ist mindestens ein zusätzlicher Speicherzugriff auf die Seitentabelle erforderlich. Wenn also nun zwei Speicherzugriffe pro Befehl erforderlich werden, würde die Leistung der CPU in etwa halbiert.
Deshalb werden die zuletzt ermittelten Werte für die Adresse der physischen Speicherseite im Translation Lookaside Buffer (TLB) gecacht, wodurch erneute Zugriffe auf Adressen in dieser Seite nicht aufwändig neu ermittelt werden müssen, sondern aus dieser Liste entnommen werden können. Der TLB kann eine begrenzte Menge dieser Referenzen halten und kann dadurch die Ausführung von Speicherzugriffen deutlich beschleunigen. Dies wird über assoziative Ordnungsregister realisiert, die parallele Zugriffe erlauben. Der TLB ist normalerweise ein Teil der MMU. Die Felder des TLB sind normalerweise eins zu eins aus der Seitentabelle entnommen, mit Ausnahme der virtuellen Seitennummer, die in der Seitentabelle nicht benötigt wird. Ein weiteres Feld gibt zudem an, ob der Eintrag momentan benutzt wird.[18]

Die Anzahl der Felder eines TLB hängt von der Rechnerarchitektur ab und liegt häufig zwischen 8 und 256. IA-64-Architekturen verfügen beispielsweise über 128 Einträge im TLB. Aufgrund der hohen Lokalität vieler Programme, kann bereits bei acht Einträgen eine beachtliche Leistungssteigerung erzielt werden.[19]
Wenn eine virtuelle Adresse zur Übersetzung an die MMU geschickt wird, überprüft also diese zuerst, ob ein entsprechender Eintrag im TLB vorhanden ist, indem sie die virtuelle Seitennummer mit allen Einträgen gleichzeitig (parallel) vergleicht. Wird ein passender Eintrag gefunden, kann die Seitennummer aus dem TLB verwendet werden. Andernfalls tritt ein TLB-Fehler auf. Die MMU holt entsprechend den Eintrag aus der Seitentabelle und schreibt ihn zudem in den TLB.
Weitere Eigenschaften
Seitengröße
Die Größe der Seitenrahmen (Page-Frames) hat einen erheblichen Einfluss auf die Speicherausnutzung. Für große Seiten erhält man mehr Treffer pro Seitenaufruf, d. h., es sind weniger Einlagerungen nötig. Zudem reicht dann eine kleinere Seitentabelle aus. Allerdings können sich dann auch weniger Seiten gleichzeitig im Arbeitsspeicher befinden und es gibt eine größere interne Fragmentierung, die dadurch entsteht, dass einem Prozess insgesamt ein größerer Speicherbereich zugewiesen ist, als er eigentlich benötigt. Konkret besteht die interne Fragmentierung aus einem Teil der letzten Seite eines Prozesses. Sind die Seitenrahmen dagegen zu klein, benötigt man sehr lange Seitentabellen. Die optimale Seitengröße stellt einen Ausgleich zwischen diesen Effekten dar.[20][21]
Eine standardmäßige Seitengröße wird normalerweise durch die Hardware vorgegeben. Die Seitengröße neigt dazu, mit dem Speicher zu wachsen, aber nicht linear. Wenn sich der Speicher vervierfacht, wird die Seitengröße meistens nicht einmal verdoppelt.[22]
Der Pentium 4 und alle anderen IA-32-Prozessoren stellen ein Paging mit einer Seitengröße von 4 KiB zur Verfügung. Ab dem Pentium Pro kann die Seitengröße wahlweise auf 4 MiB eingestellt werden.[23] Bei der AMD64-Architektur werden physische Seitengrößen von 4 KiB, 2 MiB, 4 MiB und 1 GiB unterstützt.[24] Einige Prozessoren unterstützen auch mehrere Seitengrößen, die man teils gleichzeitig nutzen kann. So kann man beispielsweise für das Betriebssystem und den Grafikspeicher eine große Seitengröße (Large Pages) vorsehen, z. B. 8 MiB.[25]
Auch wenn die Hardware gewisse Seitengrößen vorgibt, kann das Betriebssystem diese beeinflussen. Wenn die Hardware beispielsweise für 4-KiB-Seiten entworfen wurde, kann das Betriebssystem die Seitenrahmen 0 und 1, 2 und 3, 4 und 5 usw. als 8-KiB-Seiten behandeln, indem es bei einem page fault gleich zwei aufeinander folgende Seitenrahmen nachlädt.[26]
Die folgende Tabelle zeigt Seitengrößen unter Windows in Abhängigkeit von der Prozessorarchitektur:[27]
| Prozessorarchitektur | Größe der Small Page | Größe der Large Page |
|---|---|---|
| x86 | 4 KiB | 4 MiB |
| AMD64 | 4 KiB | 2 MiB |
| Intel 64 | 8 KiB | 16 MiB |
Seitentabellen für große Speicherbereiche
Da die Anzahl der Einträge einer (einstufigen) Seitentabelle von der Größe des virtuellen Adressraums und der gewählten Seitengröße abhängt, ergibt sich ein Problem, wenn der virtuelle Adressraum zu groß und/oder die gewählte Seitengröße zu klein wird. Bei einem 64-Bit-Computer mit einem Adressraum von Byte und 4 Kibibyte () großen Seiten hätte die Seitentabelle Einträge. Mit beispielsweise 8 Byte pro Eintrag (52 Bit für die Adressierung, 7 Statusbits gemäß obigem Beispiel) wäre die Seitentabelle dann über 33 Millionen Gibibyte (32 Pebibyte) groß, im Gegensatz zu einer Größe von nur 4 Mebibyte bei gleicher Seitengröße auf einem 32-Bit-Computer mit beispielsweise 4-Byte-Seitentabelleneinträgen (20 Bit für die Adressierung, 7 Statusbits gemäß demselben obigen Beispiel). Für virtuelle 64-Bit-Adressräume mit Paging sind also andere Lösungen nötig.[28] Deshalb wurden die Konzepte der mehrstufigen Seitentabelle und der invertierten Seitentabelle entwickelt.


Mehrstufige Seitentabelle
Die Adressumsetzung mit Hilfe einer k-stufigen Seitentabelle geschieht durch Aufteilung einer virtuellen Adresse in k*n höherwertige Bits als Seitentabellenverweise und m niederwertige Bits als Offset. Mit dem k-ten Verweis in der virtuellen Adresse wird aus der k-ten Seitentabelle die Basisadresse der Seitentabelle der Stufe k+1 ausgelesen. Die letzte Stufe enthält dann den tatsächlichen Verweis auf die reale Basisadresse. Die aus der letzten Stufe der Seitentabellen ausgelesene Basisadresse der realen Speicherseite zusammen mit dem unveränderten Offset ergeben die reale Adresse.
Der Vorteil bei diesem Ansatz gegenüber der einstufigen Seitentabelle ist der, dass nicht immer alle Seitentabellen im Speicher gehalten werden müssen. Besonders die nicht benötigten Tabellen sollten nicht nutzlos im Speicher gehalten werden. Die Seitentabellen selbst können also auch ausgelagert werden, sie unterliegen ebenfalls dem Paging.[29]
Für die IA-32-Prozessoren entschied man sich beispielsweise für eine zweistufige Seitenverwaltung, bei der ein zentrales Seitenverzeichnis (page directory) auf bis zu 1024 Seitentabellen (page tables) verweist. Die virtuelle Adresse wurde für die Umsetzung in drei Teile aufgeteilt:
- Die höchstwertigen 10 Bit werden benutzt, um eine der max. 1024 Einträge im Seitenverzeichnis auszuwählen, der einen Verweis auf die Seitentabelle enthält.
- Die Bits 12–21 bilden die Seitennummer in der entsprechenden Tabelle.
- Die niederwertigsten 12 Bit bilden den Offset.[30]
Bei x64-Windows ist die Seitentabelle sogar vierstufig. Es wird eine 48 Bit breite virtuelle Adresse in 4 Indices zu je 9 Bit und einen Offset zu 12 Bit eingeteilt.[31]
Invertierte Seitentabelle
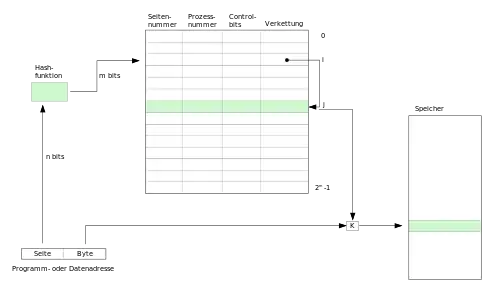
Bei der Methode der invertierten Seitentabelle wird in der Seitentabelle nicht mehr ein Eintrag pro virtueller Seite angelegt, sondern nur noch ein Eintrag für jeden physischen Seitenrahmen. Wenn der virtuelle Adressraum wesentlich größer als der physische Speicher ist, wird dadurch sehr viel Speicherplatz der Tabelle eingespart.
Jeder Eintrag in der Tabelle speichert das zugehörige Paar (Prozessnummer, Seitennummer). Der Zugriff auf die Seitentabelle erfordert nun jedoch einen Suchvorgang: Wenn ein Prozess mit der Prozessnummer n auf die virtuelle Seite p zugreifen will, muss die Hardware die gesamte Tabelle nach dem Eintrag (n,p) durchsuchen. Dies macht einen Speicherzugriff wesentlich aufwändiger. Abhilfe schafft das Vorschalten einer Hashtabelle mit den virtuellen Adressen als Hashwerten. Alle Seiten, die denselben Hashwert haben, werden verkettet.
Zusätzlich wird der Speicherzugriff durch einen Translation Lookaside Buffer (TLB) beschleunigt. Wenn alle häufig benutzten Seiten in den TLB passen, ist die Adressumrechnung gleich schnell wie mit herkömmlichen Methoden. Bei einem TLB-Fehler muss jedoch die invertierte Seitentabelle von der Software durchsucht werden.[32]
Demand Paging und Prepaging
Beim sogenannten Demand Paging (Einlagern bei Bedarf) erfolgt eine Einlagerung nur auf Anforderung, also wenn die Daten tatsächlich benötigt werden. In der reinsten Form des Demand Paging startet ein Prozess mit keiner einzigen Seite im Arbeitsspeicher. Sobald die CPU den ersten Befehl laden will, gibt es einen Seitenfehler und das Betriebssystem lagert die entsprechende Seite ein. Es folgen weitere Seitenfehler, bis der Prozess die wichtigsten Seiten „zusammengetragen“ hat und mit relativ wenigen Seitenfehlern laufen kann.[33]
Beim sogenannten Prepaging können dagegen auch Seiten in den Hauptspeicher geholt werden, die noch nicht angefordert wurden. Es wird dabei die räumliche Lokalitätseigenschaft ausgenutzt. Diese besagt, dass nach einem Zugriff auf einen Adressbereich mit hoher Wahrscheinlichkeit der nächste Zugriff auf eine Adresse in unmittelbarer Nachbarschaft erfolgt.
Auch Kombinationen von Demand Paging und Prepaging werden in der Praxis eingesetzt: Man kann zum Beispiel beim Holen einer angeforderten Seite gleich die benachbarten Seiten oder sonstige Seiten nach einem bestimmten Algorithmus mit in den Hauptspeicher laden.[34]
Thrashing und Working-Set-Modell
Wenn in einem Rechnersystem zu viele Seitenfehler in zu kurzer Zeit auftreten, ist das System überwiegend mit dem Nachladen und Auslagern von Seiten beschäftigt. Die verfügbare Rechenleistung ist deutlich herabgesetzt. Dieser Zustand wird als Thrashing (engl. wörtlich: Dreschen) oder Seitenflattern bezeichnet.[35]
Thrashing tritt beispielsweise auf, wenn zu viele Prozesse im Speicher sind. Durch die zusätzliche Belastung mit Prozessen nimmt einerseits die verfügbare Seitenzahl pro Prozess im Arbeitsspeicher ab und andererseits die Zahl der Seitenaustauschaktivitäten zu. Prozesse laufen nicht mehr ab, ohne nach kurzer Zeit auf nicht vorhandene Seiten zu stoßen. Es können jedoch nur Seiten aus dem Speicher verdrängt werden, die kurz danach wieder benötigt werden. Ab einer gewissen Grenze wird die zur Verfügung stehende Rechenleistung nahezu vollständig darauf verwendet, Speicherinhalte ein- und auszulagern und nach rechenbereiten Prozessen zu suchen.[36]
Die Menge von Seiten, die ein Prozess zu einem bestimmten Zeitpunkt benutzt, wird als Arbeitsbereich (engl. working set) bezeichnet.[37] Liegt der gesamte Arbeitsbereich eines Prozesses im Arbeitsspeicher, läuft er mit sehr wenigen Seitenfehlern ab. Das Working-Set-Modell versucht deshalb die Seitenfehlerrate zu verringern, indem sich das Betriebssystem den Arbeitsbereich eines Prozesses merkt, wenn es ihn auslagert und dafür sorgt, dass er wieder eingelagert wird, bevor er erneut ausgeführt wird.[38]
Um Thrashing zu vermeiden, sollten die folgenden Punkte beachtet werden:
- Der Arbeitsspeicher sollte ausreichend groß sein, um alle Working-Sets der gleichzeitig auszuführenden Prozesse aufnehmen zu können, auch in einem Extrem-Lastfall mit maximal vielen gleichzeitigen Prozessen.
- Zu jedem gegebenen Zeitpunkt sollte mindestens einer der Prozesse, die das System zu verarbeiten hat, vom Prozessor bearbeitet werden können, das heißt sein Arbeitsbereich befindet sich im Arbeitsspeicher. In diesem Betriebszustand wartet der Prozessor nicht auf das Nachladen von Seiten, sondern arbeitet an einem Prozess, während parallel für andere Prozesse Seiten nachgeladen werden.
- Programme sollten auf ihre Daten möglichst lokal zugreifen und wahlfreie Zugriffe auf ständig wechselnde Speicherseiten vermeiden.
Entscheidend sind dabei folgende Größen:
- t: Die Zeit, die der Prozessor braucht, um auf eine Speicherstelle zuzugreifen
- T: Die Zeit, die benötigt wird, um eine Seite nachzuladen
- s: Der Anteil an Seiten, der sich im Arbeitsspeicher befindet, im Verhältnis zur Gesamtzahl aller für die Programmausführung benötigten Seiten (0 < s ≤ 1)
- p(s): Die Wahrscheinlichkeit eines Seitenfehlers, abhängig von s
Damit Thrashing vermieden wird, muss p(s) ≤ t/T sein. Der minimale Anteil w an Seiten, der sich im Arbeitsspeicher befinden muss (also der Arbeitsbereich), wird bestimmt durch die Gleichung
- p(w) = t/T.
Da Speicherzugriffe meist lokal gehäuft auftreten, ist die Wahrscheinlichkeit sehr hoch, dass der nächste Programmschritt und das nächste benötigte Datenelement sich auf derselben Seite befinden wie der gerade verarbeitete Schritt und das gerade verarbeitete Element. Auf der anderen Seite ist das Verhältnis T/t typischerweise sehr groß: RAM ist ca. 100000-mal so schnell wie Festplattenspeicher.
Experimentelle Messungen und Berechnungen, die bereits in den 1960er Jahren durchgeführt wurden, ergeben unter diesen Bedingungen für w einen Wert von nicht wesentlich weniger als 0,5. Das bedeutet, dass der Auslagerungsspeicher kaum größer als der Arbeitsspeicher sein muss. In der Praxis wird z. B. unter UNIX-Betriebssystemen für die meisten Anwendungsfälle eine Größe des Auslagerungsspeichers vom Zwei- bis Dreifachen des Arbeitsspeichers empfohlen (abhängig davon, ob das jeweilige System den Auslagerungsspeicher zusätzlich zum Arbeitsspeicher oder den Arbeitsspeicher als echte Teilmenge des Auslagerungsspeichers verwaltet).[39]
Seitenersetzungsstrategien
Wenn ein Seitenfehler auftritt, muss unter Umständen eine Seite im Arbeitsspeicher verdrängt werden, um für die neue Seite Platz zu schaffen. Die Leistung eines Pagingsystems hängt wesentlich davon ab, welche Seiten im Arbeitsspeicher man beim Nachladen neuer Seiten verdrängt. Wenn man eine viel benutzte Seite verdrängt, dann erzeugt man Aufwand für zusätzliche Nachladevorgänge. Nach Möglichkeit sollten also Seiten ausgelagert werden, die nur selten benutzt werden.
Das Gebiet der Seitenersetzungsalgorithmen wurde sowohl theoretisch als auch experimentell intensiv erforscht. Die Problematik besteht darin, dass das Betriebssystem nicht wissen kann, wann auf welche Seite das nächste Mal zugegriffen wird.[40]
Not-Recently-Used-Algorithmus (NRU)
Diese Paging-Strategie lagert bevorzugt Seiten aus, die innerhalb eines Zeitintervalls nicht benutzt (referenziert) und nicht modifiziert wurden. Dazu werden die Seiten in regelmäßigen Abständen als ungelesen und unverändert markiert. Wenn eine Seite ausgelagert werden muss, wird geprüft, bei welchen Seiten sich diese Markierungen nicht geändert haben.
Das Betriebssystem führt mit Hilfe der beiden Statusbits Statistiken über die Benutzung von Seiten:
- Das M-Bit wird gesetzt, wenn ein Programm auf die Seite schreibt.
- Das R-Bit wird sowohl bei Lese- als auch bei Schreibzugriff gesetzt.
Das Betriebssystem setzt nun in regelmäßigen Abständen (z. B. bei jedem Timerinterrupt) die R-Bits auf 0. Dadurch ist das R-Bit nur bei den Seiten gesetzt, die in letzter Zeit gebraucht wurden. Bei einem Seitenfehler teilt das Betriebssystem die Seiten nach dem Zustand der R- und M-Bits in vier Kategorien ein, die mit entsprechender Priorität ausgelagert werden:
- R=0, M=0 (nicht referenziert, nicht modifiziert)
- R=0, M=1 (nicht referenziert, modifiziert)
- R=1, M=0 (referenziert, nicht modifiziert)
- R=1, M=1 (referenziert, modifiziert)
Die Leistung des NRU-Algorithmus ist zwar nicht optimal, aber in vielen Fällen ausreichend.[41]
First-In-First-Out-Algorithmus (FIFO)
Bei dieser Methode werden diejenigen Elemente, die zuerst gespeichert wurden, auch wieder zuerst aus dem Speicher genommen. Auf die Seitenersetzung übertragen bedeutet dies, dass jeweils die älteste Seite ersetzt wird. Das Betriebssystem führt eine Liste mit allen Seiten im Speicher, wobei am Eingang der jüngste und am Ende der älteste Eintrag steht. Bei einem Seitenfehler wird das Ende abgehängt und eine neue Seite am Eingang angehängt. Diese Strategie ist ineffizient, da die älteste Seite durchaus eine Seite mit sehr häufigen Zugriffen sein kann.[42]
Second-Chance-Algorithmus und Clock-Algorithmus
Der Second-Chance-Algorithmus ist eine Verbesserung des First-In-First-Out-Algorithmus. Es soll dabei verhindert werden, dass die älteste Seite ausgelagert wird, obwohl sie häufig benutzt wird. Deshalb wird zunächst das R-Bit abgefragt. Es gibt nun zwei Fälle:
- Das R-Bit ist nicht gesetzt: Die Seite ist sowohl alt als auch unbenutzt. Sie wird sofort ersetzt.
- Das R-Bit ist gesetzt: Das R-Bit wird gelöscht und die Seite wird an den Listeneingang verschoben. Die Suche wird fortgesetzt.
Der Second-Chance-Algorithmus ist allerdings ineffizient, da er ständig Seiten in der Liste verschiebt. Eine Verbesserung dazu stellt der Clock-Algorithmus dar: Die Seiten werden in einer ringförmigen Liste gehalten und ein Zeiger zeigt auf die älteste Seite, vergleichbar mit einem Uhrzeiger. Wenn nun das R-Bit 0 ist, wird die Seite ausgelagert (und die neue Seite an derselben Stelle eingelagert), ansonsten wird das R-Bit auf 0 gesetzt und der Zeiger rückt um eine Seite vor.[43]
Least-Recently-Used-Algorithmus (LRU)
Diese Strategie lagert diejenige Seite aus, deren letzte Referenzierung zeitlich am längsten zurückliegt. Man geht also von der Annahme aus, dass Seiten, die lange nicht genutzt wurden, auch in Zukunft nicht verwendet werden und Seiten, die in der jüngsten Vergangenheit genutzt wurden, auch in Zukunft häufig verwendet werden. Der LRU-Algorithmus ist zwar eine gute Annäherung an den optimalen Algorithmus, er ist allerdings nur ziemlich aufwändig zu realisieren. Es muss einiger Aufwand betrieben werden, um jeweils die am längsten unbenutzte Seite schnell im Zugriff zu haben.[44]
Eine Möglichkeit besteht darin, eine nach der zeitlichen Nutzung sortierte Liste zu führen. Bei jedem Zugriff wird dabei die aktuell genutzte Seite an den Listeneingang gehängt. Das Finden, Verschieben und Löschen einer Seite in der Liste sind jedoch sehr aufwändige Operationen.
Eine weitere Möglichkeit besteht darin, LRU mit Spezialhardware zu implementieren. Die LRU-Hardware führt beispielsweise für eine Maschine mit n Seitenrahmen eine -Matrix. Anfangs sind alle Einträge auf 0 gesetzt. Wird auf einen Seitenrahmen k zugegriffen, setzt die Hardware alle Bits der Zeile k auf 1 und dann alle Bits der Spalte k auf 0. Zu jedem Zeitpunkt ist dadurch die am längsten nicht benutzte Seite diejenige mit dem niedrigsten Binärwert in der entsprechenden Zeile der Matrix.[45]

Aufgrund des hohen Aufwands werden in der Praxis sogenannte Pseudo-LRU-Algorithmen vorgezogen, die das R- und das M-Bit benutzen. Dazu gehören auch der Second-Chance-Algorithmus und der Clock-Algorithmus.[46]
Working-Set-Algorithmus
Der Working-Set-Algorithmus basiert auf der Idee, dass bei einem Seitenfehler eine Seite ausgelagert wird, die nicht mehr zum Arbeitsbereich eines Prozesses gehört. Dazu führt die Seitentabelle neben dem R-Bit noch zusätzlich einen Eintrag, der die (ungefähre) Zeit des letzten Zugriffs beinhaltet. Der Algorithmus funktioniert folgendermaßen:
- Die Hardware setzt das R-Bit bei Lese- und Schreibzugriff.
- In regelmäßigen Abständen (periodischer Timerinterrupt) werden die R-Bits gelöscht.
- Bei einem Seitenfehler wird die Seitentabelle nach einer Seite durchsucht, die ausgelagert werden soll:
- Ist bei einem Eintrag R=1 (R-Bit gesetzt), wurde die Seite im aktuellen Timerintervall verwendet und gehört offensichtlich zum Arbeitsbereich. Sie kommt dann für die Auslagerung nicht in Frage. Die neue virtuelle Zeit wird nun in das Feld für den Zeitpunkt des letzten Zugriffs eingetragen.
- Ist bei einem Eintrag R=0 (R-Bit gelöscht), ist die Seite ein Kandidat für die Auslagerung. Es wird ihr Alter berechnet (Laufzeit des Prozesses minus Zeitpunkt des letzten Zugriffs) und mit einem Wert t verglichen. Ist das Alter größer als t, gehört die Seite nicht mehr zum Arbeitsbereich und kann ausgelagert werden.
- Der Rest der Tabelle wird noch durchlaufen, um die Zugriffszeiten auf den neusten Stand zu bringen.
Der Working-Set-Algorithmus hat den Nachteil, dass bei jedem Seitenfehler die gesamte Seitentabelle durchlaufen werden muss, bis ein passender Kandidat gefunden ist.[47]
WSClock-Algorithmus
Der WSClock-Algorithmus ist einerseits eine Verbesserung des Clock-Algorithmus, nutzt andererseits aber auch Informationen über den Arbeitsbereich.[48] Wie beim Clock-Algorithmus werden die Seiteneinträge in einer ringförmigen Datenstruktur gehalten. Jeder Eintrag enthält ein R-Bit, ein M-Bit und ein Feld für den Zeitpunkt des letzten Zugriffs (vergleichbar zum Working-Set-Algorithmus). Bei einem Seitenfehler wird wie beim Clock-Algorithmus zunächst die Seite untersucht, auf die der Zeiger zeigt. Entscheidend sind die folgenden Fälle:
- Das R-Bit ist gesetzt: Die Seite ist also kein geeigneter Kandidat für die Auslagerung. Das R-Bit wird auf 0 gesetzt und der Zeiger rückt vor.
- Das R-Bit ist nicht gesetzt und das Alter ist größer als t:
- Wenn M=0 ist, wurde die Seite nicht modifiziert und sie kann einfach gelöscht und ersetzt werden, weil die Kopie auf der Festplatte noch aktuell ist.
- Wenn M=1 ist, ist die Kopie auf der Festplatte nicht mehr aktuell. Die Seite wird vorgemerkt, aber noch nicht sofort ausgelagert, weil es weiter unten in der Liste vielleicht noch eine „saubere“ Seite gibt, die einfach gelöscht werden kann.
Wenn ein Zeiger die gesamte Liste einmal durchlaufen hat, gibt es folgende Fälle:
- Es wurde mindestens eine Seite vorgemerkt: Die erste vorgemerkte Seite, auf die der Zeiger trifft, wird auf der Festplatte aktualisiert und ausgelagert.
- Es wurde keine Seite vorgemerkt: Alle Seiten gehören also zum Arbeitsbereich. Ohne zusätzliche Informationen besteht die einfachste Strategie darin, irgendeine Seite auszulagern und durch eine neue zu ersetzen.
Wegen seiner guten Leistung und einfachen Implementierung ist der WSClock-Algorithmus in realen Systemen weit verbreitet.[49]
Beispiele
Einfaches fiktives Beispiel
Die Adresslänge in diesem Beispiel sei 16 Bit, wobei die oberen 8 Bit die Seitennummer und die unteren 8 Bit der Offset sind. (Die Adresse eines Bytes ergibt sich also = Seitenrahmen * 256 + Offset.)
Seitentabelle Eintrag Gültig Seitenrahmen 0 Nein – 1 Ja 0x17 2 Ja 0x20 3 Ja 0x08 4 Nein – 5 Ja 0x10
Zu übersetzende Adressen:
| virtuelle Adresse | physische Adresse | Bemerkung |
|---|---|---|
| 0x083A | ungültig | da die Seitentabelle nur Einträge bis Seite 5 enthält. |
| 0x01FF | 0x17FF | Seite 0x01 befindet sich in Seitenrahmen 0x17, also werden die oberen 8 bit der virtuellen Adresse durch 0x17 ersetzt |
| 0x0505 | 0x1005 | Seite 0x05 befindet sich in Seitenrahmen 0x10, also werden die oberen 8 bit der virtuellen Adresse durch 0x10 ersetzt |
| 0x043A | ungültig | da die Seite 0x04 als ungültig markiert wurde. |
32-Bit-Paging
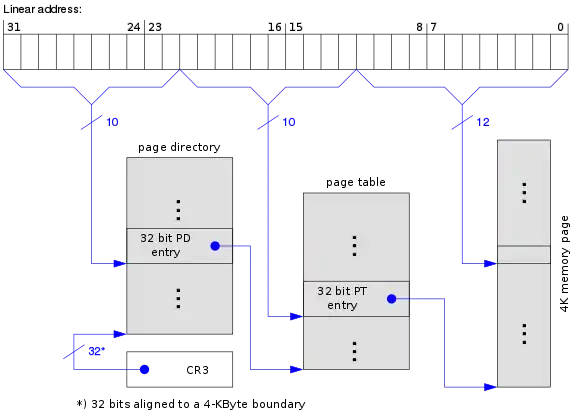
Die meisten Architekturen verwenden ein mehrstufiges Paging, um die Seitentabellen kleinzuhalten. Die IA32-Architektur verwendete ursprünglich ein zweistufiges Paging. Die 32 Bit der linearen Adresse werden hierbei wie folgt aufgeteilt:
| Bits | Zuordnung |
|---|---|
| 31 … 22 | Index im Seitenverzeichnis (engl. page directory, kurz: PD) |
| 21 … 12 | Index in der Seitentabelle (engl. page table, kurz: PT) |
| 11 … 0 | Offset in der Speicherseite |
Das Seitenverzeichnis und jede Seitentabelle bestehen aus 1024 Einträgen zu je 4 Byte und belegen somit jeweils genau eine Speicherseite. Jeder Eintrag hat folgenden Aufbau:
32-Bit-Eintrag im Seitenverzeichnis (Page directory entry) Bits: 31 … 12 11 … 9 8 7 6 5 4 3 2 1 0 Inhalt: Bit 31…12 der Basisadresse ign. G PS D A PCD PWT U/S R/W P
- Bedeutungen
- P – present. Seite ist im RAM vorhanden, wenn Bit auf 1
- R/W – read/write. Schreibzugriffe nur erlaubt, wenn Bit auf 1
- U/S – user/supervisor. Ring-3-Code darf nur auf die Seite zugreifen, wenn Bit auf 1
- PWT und PCD – wird zur Cache-Steuerung benutzt
- A – accessed. Wird von der CPU automatisch gesetzt, sobald auf die Seite zugegriffen wird
- D – dirty. Wird von der CPU automatisch gesetzt, sobald in die Seite geschrieben wurde
- PS – page size. Ist dieses Bit gesetzt, verweist dieser Verzeichniseintrag direkt auf eine 4-MiB-Seite statt auf eine Seitentabelle (siehe #Page Size Extension)
- G – global. Kennzeichnet eine globale Speicherseite
Page-Size Extension
Zur Optimierung großer, zusammenhängender Speicherbereiche (z. B. Framebuffer für Grafikkarten usw.) und um den Verwaltungsaufwand im Speichermanagement des Betriebssystems zu verringern, unterstützen CPUs ab dem Pentium (offiziell dokumentiert ab Pentium Pro) außerdem 4 MiB große Seiten. Dieses Feature wird Page-Size Extension (PSE) genannt. Hierbei markiert ein spezielles Bit im zugehörigen Seitenverzeichnis-Eintrag, dass die zweite Stufe im Paging für diesen Adressbereich umgangen werden soll. Damit geben die Bits 21 bis 0 der logischen Adresse direkt den Offset in der 4 MiB großen Speicherseite an.
Um die Page-size Extension zu aktivieren, muss das Betriebssystem das Bit 4 im Steuerregister CR4 setzen.[50]
Da die 4-MiB-Seiten nur auf „glatten“ Adressen beginnen dürfen, müssen die Bits 12 bis 20 im Seitenverzeichniseintrag stets 0 sein. Dies wurde mit der PSE-36-Erweiterung abgeschafft, indem diese Bits eine neue Bedeutung bekamen:
| Bits: | 31 … 22 | 21 | 20 … 17 | 16 … 13 | 12 | 11 … 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSE (ab Pentium): | Bit 31…22 der Basisadresse | 0 | PAT | ign. | G | PS | D | A | PCD | PWT | U/S | R/W | P | |||||||||||||||||||
| PSE-36 (ab Pentium II Xeon) | Bit 31…22 der Basisadresse | 0 | Bit 35…32 | PAT | ign. | G | PS | D | A | PCD | PWT | U/S | R/W | P | ||||||||||||||||||
| PSE-36 (ab AMD K8) | Bit 31…22 der Basisadresse | 0 | Bit 39…32 | PAT | ign. | G | PS | D | A | PCD | PWT | U/S | R/W | P | ||||||||||||||||||
Die PSE-36-Erweiterung ermöglichte es, ohne großen Änderungsaufwand am Betriebssystemkern, auf mehr als 4 GiB physischen Hauptspeicher zugreifen zu können. Allerdings ist Hauptspeicher jenseits der 4-GiB-Grenze nur über 4-MiB-Seiten ansprechbar.
PSE-36 wurde nur von Windows NT 4.0 verwendet, neue Windows-Versionen und Linux setzen ausschließlich auf PAE.
Physical-Address Extension
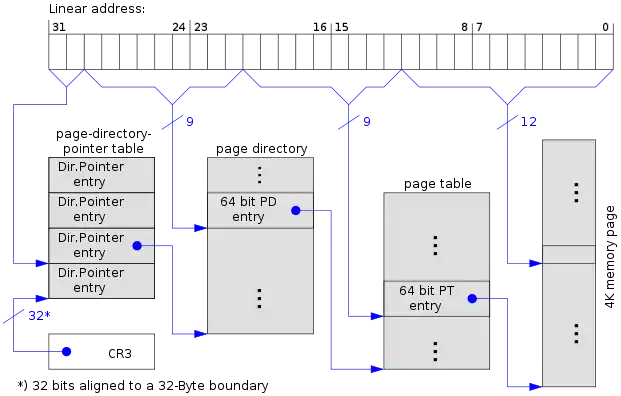
Ab dem Pentium Pro ist es möglich, bis zu 236 Bytes (= 64 GiB) physischen Speicher zu adressieren. Diese Technik wird Physical-Address Extension genannt. Dafür wird das Paging um eine dritte Stufe erweitert. Die obersten beiden Bits der linearen Adresse wählen nun einen aus 4 Einträgen der so genannten page directory pointer table (kurz: PDPT) aus.
Die Einträge in den Tabellen wurden auf 8 Bytes erweitert, jede der Tabellen enthält allerdings nur noch 512 Einträge, so dass die Gesamtgröße der Tabelle wieder bei 4 KiB liegt:
64-Bit-Eintrag in Seitentabelle (Page table entry) Bits: 63 62 … 52 51 … 32 Inhalt: NX reserved Bit 51…32 der Basisadresse Bits: 31 … 12 11 … 9 8 7 6 5 4 3 2 1 0 Inhalt: Bit 31…12 der Basisadresse ign. G PAT D A PCD PWT U/S R/W P
Auch mit PAE ist es möglich, die letzte Adressübersetzungsstufe des Pagings zu deaktivieren. Die Bits 20 bis 0 der logischen Adresse bilden dann direkt den Offset einer 2 MiB großen Speicherseite.
| Bits | Zuordnung | |
|---|---|---|
| 4 KiB Page | 2 MiB Page | |
| 31 … 30 | Index in der PDPT | |
| 29 … 21 | Index im Seitenverzeichnis (engl. page directory, kurz: PD) | |
| 20 … 12 | Index in der Seitentabelle (engl. page table, kurz: PT) | Offset in der Speicherseite |
| 11 … 0 | Offset in der Speicherseite | |
64-Bit-Modus
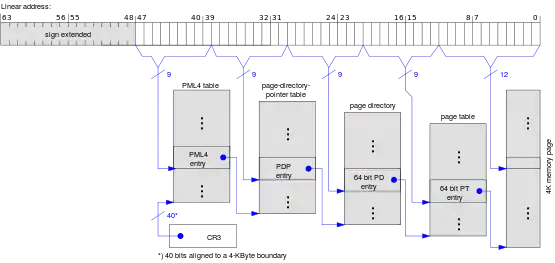
Mit der Einführung des 64-Bit-Modus beim AMD Athlon 64 wurde dieses Prinzip noch einmal angewendet. Das Paging wurde um eine vierte Stufe erweitert (Page Map Level 4, kurz PML4) und die PDPT wurde von 4 auf 512 Einträge vergrößert, so dass sie genauso groß wie die nachfolgenden Seitentabellen ist.
Neben den bereits im 32-Bit-Modus verfügbaren 4 KiB und 2 MiB großen Seiten sind im 64-Bit-Modus auch 1 GiB große Seiten möglich. Hierbei verweisen die unteren 22 Bits eines Eintrags in der Page-Directory-Pointer Table direkt auf die Startadresse einer 1-GiB-Seite:
| Bits | Zuordnung | ||
|---|---|---|---|
| 4 KiB Page | 2 MiB Page | 1 GiB Page | |
| 63 … 48 | Kopie von Bit 47, als Vorzeichenerweiterung | ||
| 47 … 39 | Index in der PML4 table (engl. page mapping layer 4) | ||
| 38 … 30 | Index in der PDPT | ||
| 29 … 21 | Index im Seitenverzeichnis (engl. page directory, kurz: PD) | 30-Bit-Offset | |
| 20 … 12 | Seitentabelle (engl. page table, kurz: PT) | 21-Bit-Offset | |
| 11 … 0 | 12-Bit-Offset in der Speicherseite | ||
5-Level-Paging
Eine nochmalige Erweiterung[51] erfuhr das Konzept durch eine fünfte Stufe, die den Adressbereich noch einmal um 9 bit und damit auf 128 PiB erweitert. Die neue Tabelle wird als PML5 table bezeichnet, ist analog zur PML4 aufgebaut und enthält ebenso 512 Einträge. Um diesen Modus nutzen zu können, muss die Software zunächst mit einem neuen Flag feststellen, ob 5-Level-Paging unterstützt wird, oder ob nur 4-Level-Paging möglich ist.
| Bits | Zuordnung | ||
|---|---|---|---|
| 4 KiB Page | 2 MiB Page | 1 GiB Page | |
| 63 … 57 | Kopie von Bit 56, als Vorzeichenerweiterung | ||
| 56 … 48 | Index in der PML5 table (engl. page mapping layer 5) | ||
| 47 … 39 | Index in der PML4 table (engl. page mapping layer 4) | ||
| 38 … 30 | Index in der PDPT | ||
| 29 … 21 | Index im Seitenverzeichnis (engl. page directory, kurz: PD) | 30-Bit-Offset | |
| 20 … 12 | Seitentabelle (engl. page table, kurz: PT) | 21-Bit-Offset | |
| 11 … 0 | 12-Bit-Offset in der Speicherseite | ||
Literatur
- Albert Achilles: Betriebssysteme. Eine kompakte Einführung mit Linux. Springer: Berlin, Heidelberg, 2006.
- Uwe Baumgarten, Hans-Jürgen Siegert: Betriebssysteme. Eine Einführung. 6., überarbeitete, aktualisierte und erweiterte Auflage, Oldenbourg Verlag: München, Wien, 2007.
- Mario Dal Cin: Rechnerarchitektur. Grundzüge des Aufbaus und der Organisation von Rechnerhardware. Teubner: Stuttgart, 1996.
- Roland Hellmann: Rechnerarchitektur. Einführung in den Aufbau moderner Computer. 2. Auflage, de Gruyter: Berlin, Boston, 2016
- Peter Mandl: Grundkurs Betriebssysteme. Architekturen, Betriebsmittelverwaltung, Synchronisation, Prozesskommunikation, Virtualisierung. 4. Auflage, Springer Vieweg: Wiesbaden, 2014.
- Andrew S. Tanenbaum: Moderne Betriebssysteme. 4., aktualisierte Auflage. Pearson Studium, München u. a., 2016, ISBN 978-3-8689-4270-5.
- Klaus Wüst: Mikroprozessortechnik. Grundlagen, Architekturen, Schaltungstechnik und Betrieb von Mikroprozessoren und Mikrocontrollern. 4. Auflage, Vieweg+Teubner: Wiesbaden, 2011.
Einzelnachweise
-
Verwendung Begriff "Kachelverwaltung":
- Karlsruher Institut für Technologie, Prüfung (Seite nicht mehr abrufbar, Suche in Webarchiven) Info: Der Link wurde automatisch als defekt markiert. Bitte prüfe den Link gemäß Anleitung und entferne dann diesen Hinweis. , abgerufen am 1. September 2014
- Uni Ulm, Netzwerktreiber-Projekt, abgerufen am 1. September 2014
- RabbitMQ 2.0.0 unterstützt aktuellen AMQP-Standard – Artikel bei Heise Developer, vom 26. August 2010
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 243.
- Wüst: Mikroprozessortechnik. 2011, S. 173.
- Wüst: Mikroprozessortechnik. 2011, S. 174; Tanenbaum: Moderne Betriebssysteme. 2009, S. 243.
- Wüst: Mikroprozessortechnik. 2011, S. 173.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 223.
- Wüst: Mikroprozessortechnik. 2011, S. 173.
- Anmerkung: Normalerweise hat jeder Prozess seinen eigenen Adressraum, der unabhängig von den Adressräumen der anderen Prozessen ist, mit Ausnahme von speziellen Umständen, wenn Prozesse ihre Adressräume teilen wollen.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 225; Tanenbaum: Moderne Betriebssysteme. 2009, S. 243–244.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 246.
- Achilles: Betriebssysteme. 2006, S. 57; Tanenbaum: Moderne Betriebssysteme. 2009, S. 246; Mandl: Grundkurs Betriebssysteme. 2014, S. 225.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 247.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 246.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 246–247.
- Michael Wen: Finite Programming in C++. iUniverse: New York u. a., 2005, S. 69.
- Achilles: Betriebssysteme. 2006, S. 59, ferner Mandl: Grundkurs Betriebssysteme. 2014, S. 227.
- Achilles: Betriebssysteme. 2006, S. 59.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 249.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 226.
- Mario Dal Cin: Rechnerarchitektur. Grundzüge des Aufbaus und der Organisation von Rechnerhardware. Teubner: Stuttgart, 1996, S. 136; Wolfram Schiffmann: Technische Informatik 2. Grundlagen der Computertechnik. 5. Auflage, Springer: Berlin, Heidelberg, 2005, S. 310.
- Zur Berechnung einer optimalen Ausnutzung des Arbeitsspeichers durch Minimierung des Speicherverschnitts siehe Mario Dal Cin: Rechnerarchitektur. 1996, S. 137.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 275.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 195.
- AMD: AMD64 Technology, Kap. 5.1 Page Translation Overview, S. 120: "The following physical-page sizes are supported: 4 Kbytes, 2 Mbytes, 4 Mbytes, and 1 Gbytes."
- Roland Hellmann: Rechnerarchitektur. Einführung in den Aufbau moderner Computer. 2. Auflage, de Gruyter: Berlin, Boston, 2016.
- Tanenbaum: Moderne Betriebssysteme. S. 273.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 252, mit Verweis auf Tanenbaum: Moderne Betriebssysteme. 2009.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 253.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 251–253.
- Wüst: Mikroprozessortechnik. 2011, S. 195–196.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 251.
- Tanenbaum: Moderne Betriebssysteme. S. 254–255.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 263.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 223.
- Peter J. Denning: The Working Set Model for Program Behavior. In: Commun. of the ACM 11, 1968, S. 323–333. (Online)
- Achilles: Betriebssysteme. 2006, S. 60.
- Peter J. Denning: Working Sets Pasts and Present. In: IEEE Trans. on Software Engineering. Vol. SE-6, No.1, Januar 1980, S. 64–84. (Online)
- Peter J. Denning: Virtual Memory. In: Computing Surveys Vol. 2, Sept. 1970, S: 153-189; Tanenbaum: Moderne Betriebssysteme. 2009, S. 263–264.
- Per Brinch Hansen: Operating System Principles. Prentice Hall: Englewood Cliifs (NJ), 1973, S. 185–191.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 255.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 257.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 258.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 258–259.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 241–242.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 260.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 242.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 265–266.
- Richard W. Carr, John L. Hennessy: WSClock – A Simple and Effective Algorithm for Virtual Memory Management. In: Proc. Eighth Symp. on Operating Systems Principles ACM, 1981, S. 87–95. (Online)
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 267–268.
- support.amd.com (PDF)
- 5-Level Paging and 5-Level EPT. Intel, 2017, abgerufen am 12. Februar 2020.