Speicherverwaltung
Die Speicherverwaltung (engl. memory management) ist der Teil eines Betriebssystems, der (Teile der) Speicherhierarchie verwaltet. Insbesondere soll sie einen effizienten und komfortablen Zugriff auf den physischen Arbeitsspeicher (Hauptspeicher) eines Computers ermöglichen. In diesem Zusammenhang spricht man auch von der Hauptspeicherverwaltung.[1] Das Verwalten der höheren Ebenen der Speicherhierarchie wie beispielsweise des Cache-Speichers wird dagegen üblicherweise von der Hardware vorgenommen.
Eine der Schlüsselfunktionen eines Betriebssystems in der Speicherverwaltung ist normalerweise die Bereitstellung eines virtuellen (logischen) Adressraums für jeden Prozess. Man kann sich darunter eine Menge von Speicheradressen vorstellen, auf die Prozesse zugreifen können. Dieser Adressraum ist entkoppelt vom physischen Arbeitsspeicher des Computers – er kann sowohl größer als auch kleiner als dieser sein. Die virtuellen (logischen) Adressen gehen nicht direkt an den Speicherbus, sondern an die Memory Management Unit (MMU, dt. Speicherverwaltungseinheit), welche die virtuellen Adressen auf die physischen Adressen abbildet. Normalerweise lädt das Betriebssystem einen Teil des Adressraumes in den Arbeitsspeicher, ein anderer Teil bleibt auf der Festplatte. Bei Bedarf werden Programmteile zwischen den beiden Speichern hin- und hergeschoben.
Je nach Einsatzbereich des Computers werden zur Speicherverwaltung unterschiedliche Techniken verwendet. In Multiuser-/Multiprogramming-Betriebssystemen nutzt man heute meist die virtuelle Speicherverwaltung mit diversen Optimierungsmöglichkeiten im Demand-Paging-Verfahren.[1]
Speicherhierarchie
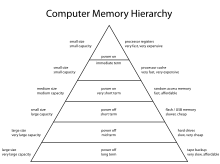
Normalerweise werden in einem Rechnersystem unterschiedliche Speichertechnologien eingesetzt. Je kürzer die Zugriffszeiten einer bestimmten Speicherart sind, desto teurer sind diese und desto knapper werden sie bemessen sein. Es wird deshalb versucht, einen Kompromiss aus Geschwindigkeit, Kosten und Persistenz zu finden, indem der Speicher in einer Speicherhierarchie (engl. memory hierarchy) angelegt und versucht wird, durch geschickte Speicherverwaltung die Vorteile der verschiedenen Komponenten zu nutzen und dabei gleichzeitig deren Nachteile zu umschiffen. Es besteht also ein Speicher mit mehreren Stufen, die unterschiedlich „weit“ vom Prozessor entfernt liegen:
- Die internen Register der CPU bilden die oberste Schicht der Speicherhierarchie. CPU-Register sind Teil der CPU und verursachen deshalb kaum Zugriffsverzögerungen. Ihre Speicherkapazität ist üblicherweise auf einem 32-Bit-Prozessor und Bit auf einem 64-Bit-Prozessor. CPU-Register werden durch die Software kontrolliert.
- Der Cache-Speicher ist ein Puffer-Speicher, der vom Prozessor aus direkt zugreifbar ist. Ein Cache enthält Kopien der Hauptspeicherbereiche, die momentan am häufigsten benutzt werden. Da Programme oft verhältnismäßig lange auf einer eng begrenzten Menge von Daten und Code arbeiten, ist der Cache trotz seiner geringen Größe sehr effizient. Der Cache ist also ein relativ kleiner Hochgeschwindigkeitsspeicher, der häufig benötigte Daten zwischen der CPU und dem Hauptspeicher puffert. Heutige CPUs integrieren oft zwei oder mehr Cache-Levels, wodurch der Zugriff nochmals schneller ist. Cache-Speicher werden üblicherweise über die Hardware kontrolliert.



- Der Arbeitsspeicher oder Hauptspeicher (engl. main memory oder RAM = random access memory) ist das Arbeitstier des Speichersystems. Er enthält die gerade auszuführenden Programme oder Programmteile und die dabei benötigten Daten. Alle Anfragen des Prozessors, die nicht aus dem Cache beantwortet werden können, werden zum Arbeitsspeicher weitergeleitet. Die gängigsten RAMs sind „flüchtig“, das heißt, die gespeicherten Daten gehen nach Abschaltung der Stromzufuhr verloren.
- Massenspeicher können große Mengen an Daten dauerhaft speichern. Magnetische Festplatten sind etwa um den Faktor 100 pro Bit billiger als RAM und besitzen zudem meist 100 Mal mehr Kapazität. Dafür dauert der wahlfreie Zugriff etwa 100.000 Mal länger. Zudem können Daten auf der Platte nicht direkt vom Prozessor verarbeitet werden, sondern müssen dazu zuerst in den Hauptspeicher geladen werden. Der Plattenspeicher kann als Ergänzung oder Erweiterung des Hauptspeichers genutzt werden und wird deshalb allgemein auch als Hintergrundspeicher oder Sekundärspeicher (engl. secondary storage) bezeichnet.
- Hinzu kommen die Wechseldatenträger (z. B. DVD, CD, USB-Stick, Disketten, Magnetband).
Die Speicherverwaltung (engl. memory manager) des Betriebssystems verwaltet diese Speicherhierarchie. Sie verfolgt, welche Speicherbereiche gerade benutzt werden, teilt Prozessen Speicher zu, wenn sie ihn benötigen und gibt ihn anschließend wieder frei.[2]
In allen Ebenen der Speicherhierarchie kann die sog. Lokalitätseigenschaft ausgenutzt werden: Die zeitliche Lokalität besagt, dass Adressbereiche, auf die zugegriffen wird, auch in naher Zukunft mit hoher Wahrscheinlichkeit wieder benutzt werden und die räumliche Lokalität, dass nach einem Zugriff auf einen Adressbereich mit hoher Wahrscheinlichkeit der nächste Zugriff auf eine Adresse in unmittelbarer Nachbarschaft erfolgt. Im zeitlichen Verlauf werden also immer wieder Speicheradressen angesprochen, die sehr nahe beieinander liegen. Dies kann man ausnutzen, indem man bei einem Speicherzugriff auch gleich die benachbarten Adressbereiche in die nächste Hierarchiestufe bringt.
Direkte Speicherverwaltung
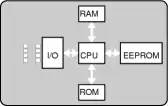
Das einfachste Verfahren ist, überhaupt keine Speicherabstraktion einzusetzen. Jedes Programm hat einfach den physischen Speicher vor sich: eine Menge von Adressen von 0 bis zu einem gewissen Maximum, wobei jede Adresse einer Zelle zugeordnet ist, die eine bestimmte Anzahl Bits enthält.
Auf Großrechnern, Minirechnern, PCs wird die direkte Adressierung des physischen Speichers heute nicht mehr eingesetzt. Demgegenüber gibt es in vielen eingebetteten Systemen und Smartcards noch immer keine Speicherabstraktion: „Geräte wie Radios, Waschmaschinen und Mikrowellen sind heutzutage voller Software (im ROM) und in den meisten Fällen adressiert die Software absoluten Speicher. Dies funktioniert hier, weil alle Programme im Voraus bekannt sind und die Benutzer nicht einfach ihre eigene Software auf ihrem Toaster laufen lassen dürfen.“[3]
Speicherverwaltung bei Monoprogramming
Im Monoprogramming wird der Arbeitsspeicher nur dem gerade aktiven Programm und dem Betriebssystem zugeteilt. Es wird nur ein Prozess zur gleichen Zeit ausgeführt. Dieser Prozess hat dann exklusiven Zugriff auf den physischen Arbeitsspeicher und kann diesen direkt adressieren. Eine Verwaltung des Speichers ist bei diesen Computern sehr einfach und besteht darin, die angeforderte Adresse über den Datenbus zugänglich zu machen.[4]
Auch in diesem einfachsten Speichermodell sind noch mehrere Optionen der Organisation möglich. So kann der Speicher in verschiedene Teile aufgeteilt werden, zum Beispiel:
- Das Betriebssystem liegt am unteren Rand des Speichers im RAM, das Benutzerprogramm darüber. Dieses Modell wurde früher in Großrechnern und Minicomputern eingesetzt, wird heute aber kaum noch verwendet.
- Das Betriebssystem liegt am oberen Rand des Speichers im ROM. Dieses Modell wird in einigen PDAs und eingebetteten Systemen benutzt.
- Die Gerätetreiber liegen oben im ROM und der Rest des Systems liegt unten im RAM. Dieses Modell wurde von frühen PCs (z. B. unter MS-DOS) verwendet.[5]
Mit Hilfe von Swapping können aber auch ohne Speicherabstraktion mehrere Programme gleichzeitig ausgeführt werden: Dazu muss das Betriebssystem den gesamten Inhalt des Arbeitsspeichers auf einer Festplatte ablegen und dann das nächste Programm von der Festplatte holen und im Arbeitsspeicher ausführen.[6]
Speicherverwaltung mit festen Partitionen

Auch bei direkter Speicherverwaltung ist es möglich, mehrere Programme gleichzeitig auszuführen (Multiprogramming-Betrieb), indem der Arbeitsspeicher in feste Teile, sogenannte Partitionen, zerlegt wird. In jeder Partition wird dabei genau ein Programm ausgeführt. Diese Technik wurde beispielsweise im Betriebssystem IBM OS/360 eingesetzt.[7]
Bei dieser Technik musste allerdings verhindert werden, dass die Benutzerprogramme untereinander und mit dem Betriebssystem selbst in Konflikt gerieten. Das eine Programm könnte beispielsweise an einer Speicheradresse einen Wert überschreiben, den das andere Programm zuvor dort abgelegt hat. Dies würde unmittelbar zum Absturz der beiden Programme führen. Deshalb wurde jeder Speicherblock mit einem Schutzschlüssel ausgestattet, der wiederum in einem speziellen CPU-Register gespeichert war. Wenn ein Prozess versuchte, auf den Speicher mit einem Schutzcode zuzugreifen, der sich vom eigenen PSW-Schlüssel (Programmstatuswort) unterschied, wurde ein Systemaufruf ausgelöst.[8]
Swapping
In der Praxis ist die Gesamtmenge an Arbeitsspeicher, die von allen laufenden Prozessen benötigt wird, oft viel größer, als der tatsächlich vorhandene physische Arbeitsspeicher. Somit können nicht mehr alle Prozesse die ganze Zeit im Arbeitsspeicher gehalten werden. Eine einfache Strategie, der Überlastung des Speichers zu begegnen, ist das sogenannte Swapping. Dieser Begriff bezieht sich üblicherweise auf Datenverschiebungen zwischen Arbeitsspeicher und Festplatte. Ein Prozess wird dabei vollständig in den Arbeitsspeicher geladen, darf eine gewisse Zeit laufen, und wird anschließend wieder auf die Festplatte ausgelagert. Indem der Festplattenspeicher ebenfalls verwendet werden kann, um Speicheranfragen von Programmen zu bedienen, können Anfragen, die über das verfügbare RAM hinausgehen, dann über Swap-Speicher bedient werden.[9]
Der wesentliche Unterschied zu festen Partitionen ist, dass die Anzahl der Prozesse, die Größe des Speicherplatzes und auch der Speicherort von Prozessen sich verändern können. Ein Prozess wird dahin geladen, wo gerade Platz ist. Es besteht auch die Möglichkeit, dass Prozesse dynamisch wachsen, da Programme beispielsweise dynamisch Speicher auf einem Heap reservieren. Es stellt sich also die Frage, wie viel Speicher für einen Prozess reserviert werden soll. Wenn ein Prozess größer als das reservierte Segment wird, entsteht ein Problem. Falls es neben dem wachsenden Prozess eine Speicherlücke gibt, kann er einfach dort „hineinwachsen“. Andernfalls muss der wachsende Prozess entweder in eine Lücke verschoben werden, die groß genug für ihn ist, oder es müssen Prozesse ausgelagert werden, um eine passende Lücke zu schaffen.[10]
Durch das Swapping können ungenutzte Lücken im Arbeitsspeicher entstehen (Fragmentierung). Solche Lücken können zu einer großen Lücke zusammengefasst werden, indem man alle Prozesse so weit wie möglich im Speicher nach unten schiebt. Dadurch werden alle Lücken zu einer einzigen großen Lücke im oberen Teil des Speichers zusammengefasst. Diese Technik wird Speicherverdichtung genannt. Allerdings ist sie sehr zeitaufwendig, weshalb sie normalerweise nicht eingesetzt wird.[10]
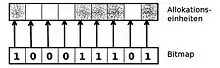
Wenn der Speicher dynamisch zugeteilt wird, muss ihn das Betriebssystem verwalten. Dazu bieten sich zwei unterschiedliche Techniken an: Bitmaps und verkettete Listen. Bei der Speicherverwaltung mit Bitmaps wird der gesamte Speicher in Allokationseinheiten fester Größe eingeteilt. Eine Bitmap speichert, ob die Allokationseinheit belegt (=1) oder frei (=0) ist.[11] In einer verketteten Liste (Segmentliste) von Speichersegmenten definiert ein Eintrag der Liste eine Lücke (L) oder einen Prozess (P) und enthält die Startadresse, die Länge und einen Zeiger auf den nächsten Eintrag. Die Liste ist nach den Startadressen sortiert. Dadurch wird die Aktualisierung der Liste bei Termination eines Prozesses relativ einfach.[12]
Im Gegensatz zum Swapping können beim virtuellen Speicher Programme auch dann laufen, wenn sich nur ein Teil von ihnen im Arbeitsspeicher befindet.[13] Dadurch können auch Programme ausgeführt werden, die größer als der vorhandene Arbeitsspeicher sind.[14]
Video: Aus- und Einlagern kompletter Prozesse
Virtuelle Speicherverwaltung
Das Konzept der virtuellen Speicherverwaltung wurde erstmals 1961 von John Fotheringham beschrieben.[15] Dieses erlaubt, dass der Programmcode, die Daten und der Stack größer sein können, als der tatsächlich verfügbare Hauptspeicher. Im Gegensatz dazu darf bei der realen Speicherverwaltung ein Prozess maximal so groß wie der Hauptspeicher sein.
Virtueller Adressraum
Die von einem Programm generierten Speicheradressen werden virtuelle Adressen genannt und bilden den virtuellen Adressraum. Die virtuellen Adressen gehen nun nicht direkt an den Speicherbus, sondern an die Memory Management Unit (MMU, dt. Speicherverwaltungseinheit), welche die virtuellen Adressen auf die physischen Adressen abbildet.[16]
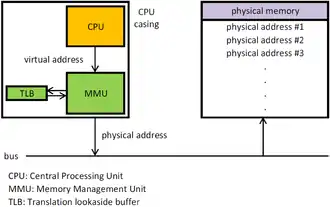
Die Grundidee hinter der virtuellen Speicherverwaltung ist, dass der Adressraum eines Programms in Einheiten aufgebrochen wird, die dem physischen Speicherbereich zugeordnet werden, wobei nicht alle im physischen Speicher vorhanden sein müssen: Wenn das Programm auf einen Teil des Adressraumes zugreift, der sich aktuell im physischen Speicher befindet, dann kann die Hardware die notwendigen Zuordnungen schnell durchführen. Wenn das Programm jedoch auf einen Teil des Adressraumes zugreifen will, der nicht im physischen Speicher ist, so wird das Betriebssystem alarmiert, das fehlende Stück zu beschaffen und den fehlgeschlagenen Befehl noch einmal auszuführen.[17]
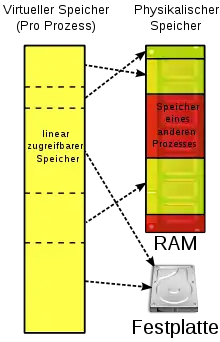
Häufig verfügt ein System über sehr viel mehr virtuellen Speicher als physischen Speicher. Konkret legt das installierte RAM fest, wie groß der physische Speicher ist, während der virtuelle Adressraum von der Architektur des Befehlssatzes abhängt. Mit einem 32-Bit-Prozessor kann man maximal Byte (also 4 GB) Speicher adressieren, mit einem 64-Bit-System Byte (16 Exabytes), auch wenn beispielsweise nur 512 MB RAM tatsächlich installiert sind.[17]


Das Konzept der virtuellen Speicherverwaltung funktioniert besonders gut bei Systemen mit Multiprogramming, wenn dabei einzelne Teile von mehreren Programmen gleichzeitig im Speicher sind: Während ein Programm darauf wartet, dass Teile von ihm eingelesen werden, kann die CPU einem anderen Prozess zugeteilt werden.[17]
Zur Organisation des virtuellen Speichers gibt es einerseits den segmentorientierten Ansatz, bei dem der Speicher in Einheiten unterschiedlicher Größen aufgeteilt ist, und andererseits den seitenorientierten Ansatz, bei dem alle Speichereinheiten gleich lang sind.
Paging
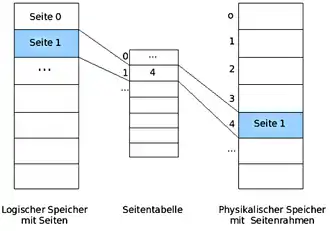
Paging (von engl. page „Speicherseite“) meint die Methode der Speicherverwaltung per Seitenadressierung. Beim Paging wird der virtuelle Adressraum in gleich große Stücke unterteilt, die man als Seiten (engl. pages) bezeichnet. Auch der physische Adressraum ist derart unterteilt. Die entsprechenden Einheiten im physischen Speicher nennt man Seitenrahmen oder auch Kacheln, engl. (page)frames. Seiten und Seitenrahmen sind in der Regel gleich groß. In realen Systemen kommen Seitengrößen zwischen 512 Byte und 4 MByte vor, möglich wäre mitunter auch 1 GB.[18] Typisch sind Seiten zu 4 KByte.[19]
Für das Umrechnen von virtuellen zu physischen Adressen wird eine Seitentabelle verwendet, die die Abbildung zwischen virtuellen und physischen Adressen beinhaltet. Wenn ein Programm eine virtuelle Adresse anspricht, die keiner physischen Adresse zugeordnet ist, wird ein Systemaufruf ausgelöst. Dieser Aufruf wird Seitenfehler (engl. page fault) genannt. Als unmittelbare Folge des Seitenfehlers kommt es zu einer synchronen Programmunterbrechung (engl.: trap). Das Betriebssystem wählt dann einen wenig benutzten Seitenrahmen aus, schreibt dessen Inhalt zurück auf die Festplatte, lädt die angeforderte Seite in den frei gewordenen Seitenrahmen, ändert die Zuordnungstabelle und führt den unterbrochenen Befehl noch einmal aus.[20]
Bei der heute üblichen Abrufstrategie des Paging spricht man auch von Demand Paging, da hier eine Einlagerung nur auf Anforderung erfolgt, also wenn die Daten tatsächlich benötigt werden. Beim sog. Prepaging können dagegen auch Seiten in den Hauptspeicher geholt werden, die noch nicht angefordert wurden, beispielsweise wenn man die Lokalität von Programmen gut einschätzen kann (siehe Lokalitätseigenschaft). Auch Kombinationen von Demand Paging und Prepaging werden in der Praxis eingesetzt: Man kann zum Beispiel beim Holen einer angeforderten Seite gleich die benachbarten Seiten oder sonstige Seiten nach einem bestimmten Algorithmus mit in den Hauptspeicher laden.[21]
Segmentierung
Ein weiterer Mechanismus der Speicherverwaltung ist die Einteilung des Hauptspeichers in Segmente mit völlig unabhängigen Adressräumen. Ein Segment bildet eine logische Einheit. Zum Beispiel könnte ein Segment eine Prozedur, ein Feld, einen Stack oder eine Menge von Variablen enthalten, aber normalerweise keine Mischung verschiedener Typen. Segmente sind üblicherweise größer als Seiten. Verschiedene Segmente können verschieden groß sein und sind es normalerweise auch. Zudem kann sich die Größe eines Segments während der Ausführung ändern.[22]
Der Hauptvorteil der Segmentierung ist, dass die Segmentgrenzen mit den natürlichen Programm- und Datengrenzen übereinstimmen. Programmsegmente können unabhängig von anderen Segmenten neu übersetzt und ausgetauscht werden. Datensegmente, deren Länge sich während der Laufzeit ändert (Stacks, Queues) können durch Segmentierung effizient den vorhandenen Speicherraum nutzen. Andererseits erfordert die Verwaltung variabler Speichersegmente aufwendige Algorithmen zur Hauptspeicherzuteilung, um eine starke Fragmentierung zu vermeiden, d. h. eine „Zerstückelung“ des Speicherraums mit ungenutzten Speicherbereichen (Fragmente) zwischen benutzten Speicherbereichen. Ein weiteres Problem der Segmentierung ist die hohe Redundanz (Superfluity) bei großen Segmenten: Oft wird nur ein Bruchteil des eingelagerten Segments vom Prozess tatsächlich benötigt.[23]
Ein Vorzug der Segmentierung liegt darin, dass die gemeinsame Nutzung von Programmen ziemlich gut unterstützt wird. Ein Programm muss nur eintrittsinvariant geschrieben und einmal als Segment geladen werden. Dann können mehrere Benutzer mit jeweils eigenen Datenbereichen darauf zugreifen.[24]
Paged Segments
Die Kombination von Segmentierung und Paging dient dazu, die Vorteile der beiden Verfahren miteinander zu vereinigen. Wenn man Segment- und Seitenadressierung kombiniert, spricht man auch von Segment-Seitenadressierung. Jedes Segment wird dabei wiederum in gleich große Seiten aufgeteilt. Die Adressangabe enthält die Segmentnummer, die Seitennummer und die relative Byte-Adresse innerhalb der Seite.[25]
Siehe auch
Literatur
- Albert Achilles: Betriebssysteme. Eine kompakte Einführung mit Linux. Springer: Berlin, Heidelberg, 2006.
- Uwe Baumgarten, Hans-Jürgen Siegert: Betriebssysteme. Eine Einführung. 6., überarbeitete, aktualisierte und erweiterte Auflage, Oldenbourg Verlag: München, Wien, 2007.
- Peter Mandl: Grundkurs Betriebssysteme. Architekturen, Betriebsmittelverwaltung, Synchronisation, Prozesskommunikation, Virtualisierung. 4. Auflage, Springer Vieweg: Wiesbaden, 2014.
- Andrew S. Tanenbaum: Moderne Betriebssysteme. 3., aktualisierte Auflage. Pearson Studium, München u. a., 2009, ISBN 978-3-8273-7342-7.
Weblinks
Einzelnachweise
- Mandl: Grundkurs Betriebssysteme. 4. Aufl. 2014, S. 213.
- Tanenbaum: Moderne Betriebssysteme. 3. Aufl. 2009, S. 55–59, 228; Carsten Vogt: Betriebssysteme. Spektrum: Heidelberg, Berlin, 2001, S. 131–143.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 232.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 219.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 229.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 230.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 219.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 230.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 220.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 236.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 237–238.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 238–240.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 235.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 241.
- John Fotheringham: Dynamic storage allocation in the Atlas computer, including an automatic use of a backing store. In: Communications of the ACM Volume 4, Issue 10 (October 1961). S. 435–436 (ACM)
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 243.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 243.
- AMD: AMD64 Technology, Kap. 5.1 Page Translation Overview, S. 120: "The following physical-page sizes are supported: 4 Kbytes, 2 Mbytes, 4 Mbytes, and 1 Gbytes."
- Klaus Wüst: Mikroprozessortechnik. Grundlagen, Architekturen, Schaltungstechnik und Betrieb von Mikroprozessoren und Mikrocontrollern. 4. Auflage, Vieweg+Teubner: Wiesbaden, 2011, S. 174; Siehe ferner Tanenbaum: Moderne Betriebssysteme. 2009, S. 243, der eine typische Seitengröße zwischen 512 Byte und 64 KB nennt.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 244.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 223.
- Tanenbaum: Moderne Betriebssysteme. 2009, S. 291.
- Wolfram Schiffmann, Robert Schmitz: Technische Informatik 2. Grundlagen der Computertechnik. 4., neu bearbeitete Auflage, 2002, S. 283.
- Achilles: Betriebssysteme. 2006, S. 57.
- Mandl: Grundkurs Betriebssysteme. 2014, S. 251 mit Verweis auf Uwe Baumgarten, Hans-Jürgen Siegert: Betriebssysteme. 6. Auflage, Oldenbourg-Verlag, 2006.