Intel Itanium
Der Intel Itanium ist ein 64-Bit-Mikroprozessor, der gemeinsam von Hewlett-Packard und Intel entwickelt wurde und 2001 erstmals auf den Markt kam. Entwicklungsziel war eine Hochleistungsarchitektur der „Post-RISC-Ära“ unter Verwendung eines abgewandelten VLIW-Designs. Der native Befehlssatz des Itanium ist IA-64. Die Befehle der älteren x86-Prozessoren können nur in einem (sehr langsamen) Firmware-Emulationsmodus ausgeführt werden. Daneben bestehen Erweiterungen zur leichteren Migration von Software, die für Prozessoren der PA-RISC-Familie entwickelt wurde. Nachfolger ist der Itanium 2.
| Itanium >> | |
|---|---|
Logo von Intel Itanium | |
| Produktion: | 2001 bis 2002 |
| Produzent: | Intel |
| Prozessortakt: | 733 MHz bis 800 MHz |
| FSB-Takt: | 133 MHz |
| L3-Cachegröße: | 2 MiB bis 4 MiB |
| Fertigung: | 180 nm |
| Befehlssatz: | IA‑64, IA‑32 (Emulation) |
| Mikroarchitektur: | Itanium |
| Sockel: | PAC418 „Slot M“ |
| Name des Prozessorkerns: | Merced |
Design
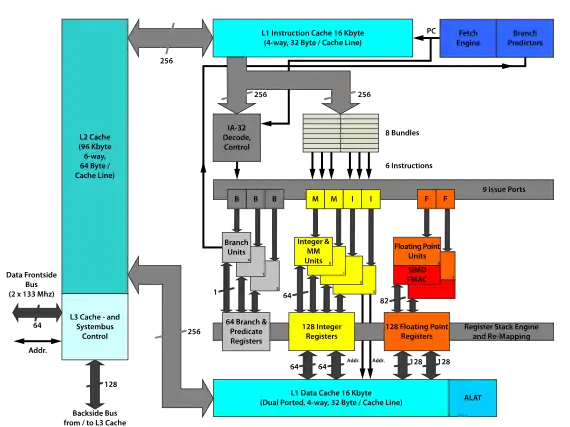

Die Post-RISC-Architektur des Itanium-Designs nennt sich Explicitly Parallel Instruction Computing (EPIC) und ist eine Variante der VLIW-Architekturen. Die Besonderheit von EPIC besteht darin, dass die CPU ausgewählte Instruktionen paarweise laden und auch gleichzeitig ausführen kann – praktisch so, als ob es mehrere völlig unabhängige CPUs gäbe. Die Instruktionen passend parallel ausführbar zusammen zu bündeln ist eine nicht-triviale Aufgabe, die hier bereits der Compiler optimal lösen muss. Daher kommt dem Compiler bzw. dessen Optimierungsfähigkeiten eine besonders wichtige Bedeutung zu. Das Design verlagert also einen Teil der Komplexität weg von der CPU und hin zum Compiler. Weiter verwendet die CPU ähnlich wie RISC-Prozessoren nur eine kleine Zahl von Instruktionen, die sehr schnell ausgeführt werden können. Der Itanium verfügt wie die meisten modernen CPUs über mehrere parallele Funktionseinheiten – eine Voraussetzung für EPIC. Beim Laden und der Weitergabe der Instruktionen an die Funktionseinheiten unterscheidet sich der Itanium jedoch von der RISC-Philosophie durch den explizit parallelen Ansatz.
In einem traditionellen, superskalaren Design untersucht eine komplexe Dekodierlogik jede Instruktion vor ihrem Durchlauf durch die Pipeline. Man spricht von dynamischem Scheduling. Es wird geprüft, welche Befehle parallel auf unterschiedlichen Einheiten ausgeführt werden können. Die Instruktionsfolgen A = B + C und D = E + F beeinflussen sich nicht gegenseitig, sie können daher parallelisiert werden.
Die Vorhersage, welche Befehle gleichzeitig ausgeführt werden können, ist jedoch oft kompliziert. Die Argumente einer Instruktion hängen vom Resultat einer anderen ab, jedoch nur, wenn auch eine weitere Bedingung wahr ist. Eine leichte Modifikation des obigen Beispiels führt genau zu diesem Fall: A = B + C; IF A==5 THEN D = E + F. Hier sind die beiden Berechnungen weiter voneinander unabhängig, aber die zweite Befehlsfolge benötigt das Ergebnis der ersten Berechnung, um zu wissen, ob sie überhaupt ausgeführt werden soll.
In diesen Fällen versucht eine CPU, die dynamisches Scheduling einsetzt, unter Verwendung verschiedener Methoden das wahrscheinliche Ergebnis der Bedingung vorherzusagen. Moderne CPUs erreichen dabei Trefferquoten von etwa 90 %. In den restlichen 10 % der Fälle muss nicht nur auf das Ergebnis der ersten Berechnung gewartet werden, sondern auch die gesamte bereits vorsortierte Pipeline gelöscht und neu aufgebaut werden. Dies führt dazu, dass etwa 20 % der theoretischen Maximalrechenleistung des Prozessors verlorengehen.
Der Itanium geht das Problem ganz anders an, er verwendet statisches Scheduling, verlässt sich für die Sprungvorhersage also auf den Compiler. Dieser hat zwar einen vollständigeren Überblick über das Programm, jedoch nicht über die konkreten Laufzeitbedingungen (d. h. Use-cases und Parametrisierung die erst zur Laufzeit feststehen). Diese dem Compiler unbekannten Laufzeitinformation können jedoch über die Profile-Guided-Optimization-Technik über definierte Testläufe vorgegeben werden. Ergebnisse sind z. B. welche Sprünge wie oft ausgeführt werden (die GCC bietet dazu beispielsweise die Funktionen fprofile-arcs und fbranch-probabilities) und welche Funktionen Hot-Spots sind. Diese Informationen kann der Compiler verwenden, um bereits bei der Übersetzung des Programmcodes die Entscheidungen zu treffen, die sonst auf dem Chip zur Laufzeit getroffen werden müssten. Sobald dem Compiler bekannt ist, welche Pfade genommen werden, bündelt er parallel ausführbare Instruktionen zu einer größeren Instruktion. Diese lange Instruktion wird in das übersetzte Programm geschrieben. Daher der Name VLIW (Very Long Instruction Word, „sehr langes Befehlswort“).
Das Problem der effektiven Parallelisierung auf den Compiler zu verlagern hat mehrere Vorteile. Zunächst einmal kann der Compiler wesentlich mehr Zeit damit verbringen, den Code zu untersuchen. Diesen Vorteil hat der Chip nicht, da er so schnell wie möglich arbeiten muss. Zweitens ist die Vorhersagelogik recht komplex, und durch den neuen Ansatz lässt sich diese Komplexität enorm reduzieren. Der Prozessor muss den Code nicht mehr untersuchen, sondern löst die VLIW-Instruktionen nur noch in kleinere Einheiten auf, die er an seine Funktionseinheiten weitergibt. Der Compiler kann daher so viel Parallelität wie möglich aus dem Programm holen, und der Prozessor kann dann entsprechend seiner Fähigkeiten (der Anzahl der parallelen Funktionseinheiten) das Beste daraus machen.
Nachteil der Parallelisierung durch den Compiler ist die Tatsache, dass das Laufzeitverhalten eines Programms nicht notwendigerweise aus seinem Quellcode hervorgeht. Dies bedeutet, dass auch der Compiler „falsch“ entscheiden kann, theoretisch auch häufiger als eine ähnliche Logik auf der CPU. Die CPU hat z. B. noch den Vorteil, dass sie sich in gewissen Grenzen merken kann, welcher Sprung wie oft genommen wurde, was der Compiler ohne Testläufe nicht kann. Das Itanium-Design verlässt sich also stark auf die Leistung des Compilers.[1] Es wird Hardwarekomplexität auf dem Mikroprozessor gegen Softwarekomplexität beim Compiler getauscht.
Programme können während der Ausführung von einem sogenannten Profiler untersucht werden, welcher Daten über das Laufzeitverhalten der Anwendung sammelt. Diese Informationen können ebenfalls in den Kompiliervorgang (Feedback-Directed Compilation oder Profile Guided Optimization) einfließen, um so eine bessere Optimierung zu erreichen. Diese Technik ist nicht neu und wurde schon bei anderen Prozessoren verwendet. Die Schwierigkeit liegt darin, repräsentative Daten zu verwenden. Bei synthetischen Benchmarks, die regelmäßig die gleichen Daten verwenden, ist die Profiler-gestützte Optimierung leicht und gewinnbringend anzuwenden.
Implementierung
Die Entwicklung der Itanium-Serie begann 1994 und basierte auf Grundlagenforschung seitens der Firma Hewlett-Packard bezüglich der VLIW-Technik. Ergebnis war ein von Grund auf neu entwickelter VLIW-Prozessor ohne Kompromisse, der sich jedoch nicht für den Arbeitseinsatz eignete (und auch nicht dafür vorgesehen war). Nachdem Intel begonnen hatte, sich an der Entwicklung zu beteiligen, wurden diesem „sauberen“ Prozessor verschiedene Funktionen hinzugefügt, die für die Vermarktung notwendig waren, insbesondere die Fähigkeit zur Ausführung von IA-32-(x86)-Instruktionen. HP steuerte Fähigkeiten zur Erleichterung der Migration von seiner Hausarchitektur HP-PA bei.
Ursprünglich sollte der Itanium bereits 1997 erscheinen, seitdem hatte sich der Zeitplan jedoch mehrfach verschoben, bis im Jahr 2001 die erste Version mit dem Codenamen Merced ausgeliefert wurde. Angeboten wurden Geschwindigkeiten von 733 und 800 MHz sowie Cache-Größen von 2 oder 4 MiB, die Preise lagen dabei zwischen 1.200 und ca. 4.000 US-Dollar. Die Leistung des neuen Prozessors war aber enttäuschend: Im IA-64-Modus war er nur unwesentlich schneller als ein gleich getakteter x86-Prozessor, und wenn er x86-Code ausführen musste, brach die Leistung wegen der verwendeten Emulation auf etwa ein Achtel der Leistung eines vergleichbaren x86-Prozessors ein. Intel behauptete dann, die ersten Itanium-Versionen seien keine „wirkliche“ Veröffentlichung gewesen.
Das größte (aber nicht einzige) Problem des Itanium ist die hohe Latenzzeit seines L3-Caches, wodurch die tatsächlich nutzbare Cache-Bandbreite stark vermindert wird. Intel war gezwungen, für den nächsten Anlauf den L3-Cache auf dem Die zu integrieren. Gleichzeitig wurden die Latenzen des primären und sekundären Caches bis unter die Werte des Power4-Prozessors von IBM gesenkt, der damals die niedrigsten Latenzzeiten erreichte. Außerdem wurde der Front Side Bus des Itanium von 266 MHz bei 64 Bit auf 400 MHz bei 128 Bit erweitert, so dass sich die Systembandbreite verdreifachte.
Diese Probleme wurden mit dem Nachfolger behoben oder zumindest abgemildert.
Probleme
Schon kurz nach der offiziellen Vorstellung des Namens am 4. Oktober 1999[2] wurde der Spitzname Itanic[3] geprägt, der den Namen der Titanic aufgriff und somit den neuen Prozessor mit dem als „unsinkbar“ geltenden Schnelldampfer verglich, der auf seiner Jungfernfahrt mit einem Eisberg kollidierte und sank.
Der Intel Itanium hatte von Anfang an mit zwei großen Problemen zu kämpfen. Das erste war hausgemacht, das zweite war etwas überraschender.
- Das erste war die Folge einer schweren und absehbaren Fehlentscheidung im Hause Intel, keine Hardware-Unterstützung für die Ausführung von x86-32-Code zu bieten und x86-32-Code, wenn auch mit gewisser Hardware-Unterstützung durch geeignete Befehle, zu emulieren (Legacy Drop). Man hoffte vergebens darauf, dass alle wichtigen Programme schnell auf die Itanium-Plattform portiert werden, was aber nur sehr zögerlich passierte oder gar ganz ausblieb. Software, die zum großen Teil noch als x86-32-Code vorlag, lief auf Itanium-Rechnern sehr langsam. Die Emulation erreichte die Geschwindigkeit eines Pentium-100, zu Zeiten als es den AMD Athlon XP mit 1600 MHz, Pentium-III Tualatin mit 1400 MHz und Pentium 4 Willamette mit 2000 MHz gab, zu einem Bruchteil des Preises. Obwohl es verschiedene Bemühungen gab, die Ausführungsgeschwindigkeit von x86-Code zu steigern, blieb der Itanium für diesen Zweck allgemein zu langsam. Die Relevanz dieser Fähigkeit ist zwar umstritten, da die meisten Kunden keine Itanium-Systeme kaufen, um darauf x86-Code auszuführen. Auf der anderen Seite waren dadurch Itanium-Systeme wirklich nur bei Vorliegen von geeigneter Software für Server und nicht als allgemeine PC-Workstations zu gebrauchen. Intel plante die Emulationseinheit für x86-Code durch einen JIT-Compiler, inspiriert von Digitals FX!32 für den Alpha-Prozessor, zu ersetzen. Man erhoffte sich davon schnellere Ausführung und verringerte Chip-Komplexität. Aber eigentlich war der Boden für den Itanium ziemlich schnell verbrannt.
- Das zweite Problem waren die Fortschritte in der CPU-Entwicklung Ende der 1990er und Anfang der 2000er Jahre, teilweise angeheizt durch das Wettrennen zwischen Intel und AMD, teilweise auf Grund technologischer Fortschritte dieser Zeit. Die klassischen CPUs hatten in der Zeit der Konzeptphase und erster Implementierungen des Itaniums sowohl im Bereich Taktfrequenz (Faktor 20) wie auch im Bereich Effizienz (Faktor 2 bis 5) innerhalb weniger Jahre so viel zugelegt, so dass das Zielgebiet des Itaniums schon nahezu erreicht war, als dieser dort nach einigen Verzögerungen einschlug. Insbesondere kam es zu einer Entkopplung zwischen Befehlssatz einer CPU und der Ausführung von Code, die das Grundkonzept des Itaniums ad absurdum führte. Es war im Endeffekt sogar so, dass sich die klassischen CPUs selbst besser an die gegebene Software anpassen konnten (siehe Out-of-order execution, Registerumbenennung, SIMD, Speculative execution, Sprungvorhersage und Prefetching) als der Itanium mit seiner starren Optimierung während der Compilezeit, in der man alles über das Zielsystem wissen musste, inklusive der Zugriffszeiten auf den Hauptspeicher.
Durch die Verlagerung von Hardwarekomplexität in den Compiler tritt, wie schon eben angedeutet, das Problem auf, dass für eine optimale Performance der Software diese auf jedem Zielsystem mit einem für dieses Zielsystem optimierten Compiler jeweils profiliert und kompiliert werden müsste, was bei Closed-Source-Software unmöglich und bei Open-Source-Software aufwendig ist. Bis komplexe Anwendungssoftware auf neue Compiler umgestellt, erfolgreich getestet, ausgeliefert und schlussendlich beim Anwender eingesetzt wird, können weitere Monate oder Jahre vergehen. Bei Prozessoren im superskalaren Design profitieren Anwender in der Regel unmittelbar von Verbesserungen. Davon unbenommen sind in beiden Fällen Verbesserungen durch neue Prozessorbefehle, die erst durch eine Änderung der Software verwendet werden können.
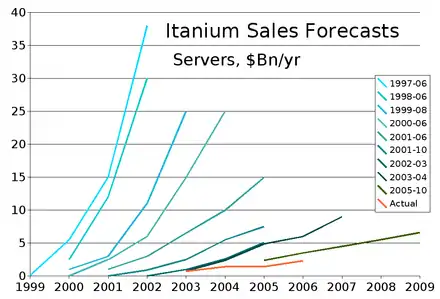
Der Itanium, konzipiert als neue Hochleistungs-CPU, war schon bei Ankunft ein nahezu totes Pferd. Intel hat allerdings über zehn Jahre gebraucht, sich das einzugestehen. Die Entwicklung wurde halbherzig über 10 Jahre bis 2012 fortgeführt. Der Hauptaufwand der Entwicklung wurde in den damals boomenden Markt der x86-64-CPUs gesteckt, wo auch das meiste Geld hereinkam.
Eine Beschleunigung dieses Prozesses hätte möglicherweise erreicht werden können, indem der Hersteller entsprechende optimierende Compiler, mit dem speziellen Wissen um die eigene Architektur, frei und zeitnah angeboten hätte. Insbesondere Programme mit Quelltext, die auf Kundensystemen übersetzt werden, hätten davon profitiert.
Aufgrund der Itanium-Entwicklungen sollten HPs Alpha-Prozessor und die PA-RISC-Architektur auslaufen (Unterstützung dieser Plattformen sollte ab 2007 für noch etwa fünf Jahre gewährleistet sein), SGI hat seine MIPS-basierten Workstations inzwischen zugunsten des Itaniums eingestellt.
Die Oracle Corporation kündigte im März 2011 an, dass sie Itanium-Chips nicht mehr unterstützen werde.[4] Von diesem Schritt war auch HP überrascht.[5] HP verklagte deswegen Oracle, da HP der Auffassung war, es bestünden Verträge mit Oracle, in denen eine langfristige Unterstützung der Itanium-Plattform geregelt sei.[6] Im Streit setzte sich HP vor Gericht durch. Demnach muss Oracle weiterhin Software für Itanium anbieten.[7]
Modelldaten
Merced
- Revision C0, C1 und C2[8]
- L1-Cache: 16 + 16 KiB (Daten + Instruktionen)
- L2-Cache: 96 KiB on-die
- L3-Cache: 2 und 4 MiB mit Prozessortakt
- IA-64, IA-32-Emulation: MMX, SSE
- PAC418
- 64-Bit-Bus mit 133 MHz DDR (FSB266)
- Betriebsspannung (VCore):
- Leistungsaufnahme (TDP): 114 W (2 MiB L3-Cache) und 130 W (4 MiB L3-Cache)
- Erstes Erscheinungsdatum: Juni 2001
- Fertigungstechnik: 180 nm
- Die-Größe: 300 mm² bei 325 Millionen Transistoren (davon 300 Millionen für den L3-Cache)
- Taktraten:
- 733 MHz mit 2 oder 4 MiB L3-Cache
- 800 MHz mit 2 oder 4 MiB L3-Cache
Weblinks
- cpu-collection.de Bilder eines zerlegten Itanium-Moduls auf cpu-collection.de
Einzelnachweise
- Andy Patrizio: Why Intel can't seem to retire the x86. ITworld. 4. März 2013. Archiviert vom Original am 16. Mai 2013. Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis. Abgerufen am 15. April 2013.
- Michael Kanellos: Intel names Merced chip Itanium. In: CNET News.com. 4. Oktober 1999. Abgerufen am 30. April 2007.
- Kraig Finstad: Re:Itanium. In: USENET group comp.sys.mac.advocacy. 4. Oktober 1999. Abgerufen am 24. März 2007.
- Oracle Stops All Software Development For Intel Itanium Microprocessor vom 22. März 2011 (engl.)
- HP Supports Customers Despite Oracle’s Anti-customer Actions, HP News release vom 23. März 2011 (engl.).
- Yasmin El-Sharif: Prozessorstreit: Hewlett-Packard verklagt Oracle. In: Spiegel Online. 16. Juni 2011, abgerufen am 26. Juli 2015.
- Jens Ihlenfeld: Itanium-Prozessor: HP gewinnt gegen Oracle. In: Golem. 1. August 2012, abgerufen am 26. Juli 2015.
- Adrian Offerman: The Processor Portal: Intel Itanium processor (Merced). In: The Chiplist. Abgerufen am 12. Februar 2017 (englisch).
| Vor-x86-Prozessoren | |||||||
| x86 bis zur 4. Generation |
| ||||||
| Pentium-Serie |
| ||||||
| Celeron-Serie |
| ||||||
| Core-Serie | |||||||
| Xeon-Serie | |||||||
| Atom-Serie | |||||||
| x86-kompatible SoCs | |||||||
| Nicht-x86-Prozessoren |
x86-Mikroarchitekturen: 8086 | 80186 | 80286 | 80386 | 80486 | P5 | P6 | NetBurst | Core Solo/Core Duo | Core 2 | Nehalem/Westmere | Sandy/Ivy Bridge | Haswell | Broadwell | Skylake | Kaby Lake | Coffee Lake | Whiskey Lake | Cannon Lake | Cascade Lake | Ice Lake | Comet Lake | Tiger Lake | Alder Lake | Raptor Lake | Meteor Lake • Atom
Non-x86-Mikroarchitekturen: Mikrocontroller: MCS-48 | MCS-51 | MCS-96 | XScale • Server: Itanium | Itanium 2
GPU-Mikroarchitekturen: Larrabee | Intel HD Graphics