Hypertext Transfer Protocol
Das Hypertext Transfer Protocol (HTTP, englisch für Hypertext-Übertragungsprotokoll) ist ein zustandsloses Protokoll zur Übertragung von Daten auf der Anwendungsschicht über ein Rechnernetz. Es wird hauptsächlich eingesetzt, um Webseiten (Hypertext-Dokumente) aus dem World Wide Web (WWW) in einen Webbrowser zu laden. Es ist jedoch nicht prinzipiell darauf beschränkt und auch als allgemeines Dateiübertragungsprotokoll sehr verbreitet.
| Hypertext Transfer Protocol | |
|---|---|
| Familie: | Internetprotokollfamilie |
| Einsatzfeld: | Datenübertragung (Hypertext u. a.) auf Anwendungsschicht |
| aufbauend auf | TCP (Transport) |
| Einführung: | 1991 |
| aktuelle Version: | 2 (2015) |
| Vorabversion: | 3 |
| Standard: | RFC 1945 HTTP/1.0 (1996) RFC 2616 HTTP/1.1 (1999) |

HTTP wurde von der Internet Engineering Task Force (IETF) und dem World Wide Web Consortium (W3C) standardisiert. Aktuelle Version ist HTTP/2, welche als RFC 7540 am 15. Mai 2015 veröffentlicht wurde. Die Weiterentwicklung wird von der HTTP-Arbeitsgruppe der IETF (HTTPbis) organisiert. Es gibt zu HTTP ergänzende und darauf aufbauende Standards wie HTTPS für die Verschlüsselung übertragener Inhalte oder das Übertragungsprotokoll WebDAV.
Eigenschaften
Nach etablierten Schichtenmodellen zur Einordnung von Netzwerkprotokollen nach ihren grundlegenderen oder abstrakteren Aufgaben wird HTTP der sogenannten Anwendungsschicht zugeordnet. Diese wird von den Anwendungsprogrammen angesprochen, im Fall von HTTP ist das meist ein Webbrowser. Im ISO/OSI-Schichtenmodell entspricht die Anwendungsschicht der 7. Schicht.
HTTP ist ein zustandsloses Protokoll. Informationen aus früheren Anforderungen gehen verloren. Ein zuverlässiges Mitführen von Sitzungsdaten kann erst auf der Anwendungsschicht durch eine Sitzung über einen Sitzungsbezeichner implementiert werden. Über Cookies in den Header-Informationen können aber Anwendungen realisiert werden, die Statusinformationen (Benutzereinträge, Warenkörbe) zuordnen können. Dadurch werden Anwendungen möglich, die Status- beziehungsweise Sitzungseigenschaften erfordern. Auch eine Benutzerauthentifizierung ist möglich. Normalerweise kann die Information, die über HTTP übertragen wird, auf allen Rechnern und Routern gelesen werden, die im Netzwerk durchlaufen werden. Über HTTPS jedoch kann die Übertragung verschlüsselt erfolgen.
Durch Erweiterung seiner Anfragemethoden, Header-Informationen und Statuscodes ist HTTP nicht auf Hypertext beschränkt, sondern wird zunehmend zum Austausch beliebiger Daten verwendet, außerdem ist es Grundlage des auf Dateiübertragung spezialisierten Protokolls WebDAV. Zur Kommunikation ist HTTP auf ein zuverlässiges Transportprotokoll angewiesen, wofür in nahezu allen Fällen TCP verwendet wird.
Derzeit werden hauptsächlich zwei Protokollversionen, HTTP/1.0 und HTTP/1.1, verwendet. Neuere Versionen alltäglicher Webbrowser wie Chromium, Chrome, Opera, Firefox, Edge und Internet Explorer sind darüber hinaus bereits kompatibel zu der neu eingeführten Version 2 des HTTP (HTTP/2)
Aufbau
Die Kommunikationseinheiten in HTTP zwischen Client und Server werden als Nachrichten bezeichnet, von denen es zwei unterschiedliche Arten gibt: die Anfrage (englisch Request) vom Client an den Server und die Antwort (englisch Response) als Reaktion darauf vom Server zum Client.
Jede Nachricht besteht dabei aus zwei Teilen, dem Nachrichtenkopf (englisch Message Header, kurz: Header oder auch HTTP-Header genannt) und dem Nachrichtenrumpf (englisch Message Body, kurz: Body). Der Nachrichtenkopf enthält Informationen über den Nachrichtenrumpf wie etwa verwendete Kodierungen oder den Inhaltstyp, damit dieser vom Empfänger korrekt interpretiert werden kann (siehe Hauptartikel: Liste der HTTP-Headerfelder). Der Nachrichtenrumpf enthält schließlich die Nutzdaten.
Funktionsweise
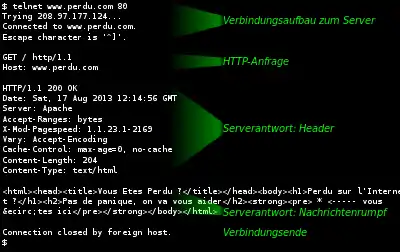
Wenn in einem Web Browser der Link zur URL http://www.example.net/infotext.html aktiviert wird, so wird an den Rechner mit dem Hostnamen www.example.net die Anfrage gerichtet, die Ressource /infotext.html zurückzusenden.
Der Name www.example.net wird dabei zuerst über das DNS-Protokoll in eine IP-Adresse umgesetzt. Zur Übertragung wird über TCP auf den Standard-Port 80 des HTTP-Servers eine HTTP-GET-Anforderung gesendet.
Anfrage:
GET /infotext.html HTTP/1.1
Host: www.example.net
Enthält der Link Zeichen, die in der Anfrage nicht erlaubt sind, werden diese %-kodiert. Zusätzliche Informationen wie Angaben über den Browser, zur gewünschten Sprache etc. können über den Header (Kopfzeilen) in jeder HTTP-Kommunikation übertragen werden. Mit dem „Host“-Feld lassen sich verschiedene DNS-Namen unter der gleichen IP-Adresse unterscheiden. Unter HTTP/1.0 ist es optional, unter HTTP/1.1 jedoch erforderlich. Sobald der Header mit einer Leerzeile (beziehungsweise zwei aufeinanderfolgenden Zeilenenden) abgeschlossen wird, sendet der Rechner, der einen Web-Server (an Port 80) betreibt, seinerseits eine HTTP-Antwort zurück. Diese besteht aus den Header-Informationen des Servers, einer Leerzeile und dem tatsächlichen Inhalt der Nachricht, also dem Dateiinhalt der infotext.html-Datei. Übertragen werden Dateien normalerweise in Seitenbeschreibungssprachen wie (X)HTML und alle ihre Ergänzungen, zum Beispiel Bilder, Stylesheets (CSS), Skripte (JavaScript) usw., die meistens von einem Browser in einer lesbaren Darstellung miteinander verbunden werden. Prinzipiell kann jede Datei in jedem beliebigen Format übertragen werden, wobei die „Datei“ auch dynamisch generiert werden kann und nicht auf dem Server als physische Datei vorhanden zu sein braucht (zum Beispiel bei Anwendung von CGI, SSI, JSP, PHP oder ASP.NET). Jede Zeile im Header wird durch den Zeilenumbruch <CR><LF> abgeschlossen. Die Leerzeile nach dem Header darf nur aus <CR><LF>, ohne eingeschlossenes Leerzeichen, bestehen.
Antwort:
Der Server sendet eine Fehlermeldung sowie einen Fehlercode zurück, wenn die Information aus irgendeinem Grund nicht gesendet werden kann, allerdings werden auch dann Statuscodes verwendet, wenn die Anfrage erfolgreich war, in dem Falle (meistens) 200 OK. Der genaue Ablauf dieses Vorgangs (Anfrage und Antwort) ist in der HTTP-Spezifikation festgelegt.
Geschichte

Ab 1989 entwickelten Tim Berners-Lee und sein Team am CERN, dem europäischen Kernforschungszentrum in der Schweiz, das Hypertext Transfer Protocol, zusammen mit den Konzepten URL und HTML, womit die Grundlagen des World Wide Web geschaffen wurden. Erste Ergebnisse dieser Bemühungen war 1991 die Version HTTP 0.9.[1]
HTTP/1.0
Die im Mai 1996 als RFC 1945 (Request for Comments Nr. 1945) publizierte Anforderung ist als HTTP/1.0 bekannt geworden. Bei HTTP/1.0 wird vor jeder Anfrage eine neue TCP-Verbindung aufgebaut und nach Übertragung der Antwort standardmäßig vom Server wieder geschlossen. Sind in ein HTML-Dokument beispielsweise zehn Bilder eingebettet, so werden insgesamt elf TCP-Verbindungen benötigt, um die Seite auf einem grafikfähigen Browser aufzubauen.
HTTP/1.1
1999 wurde eine zweite Anforderung als RFC 2616 publiziert, die den HTTP/1.1-Standard wiedergibt.[2] Bei HTTP/1.1 kann ein Client durch einen zusätzlichen Headereintrag (Keepalive) den Wunsch äußern, keinen Verbindungsabbau durchzuführen, um die Verbindung erneut nutzen zu können (persistent connection). Die Unterstützung auf Serverseite ist jedoch optional und kann in Verbindung mit Proxys Probleme bereiten. Mittels HTTP-Pipelining können in der Version 1.1 mehrere Anfragen und Antworten pro TCP-Verbindung gesendet werden. Für das HTML-Dokument mit zehn Bildern wird so nur eine TCP-Verbindung benötigt. Da die Geschwindigkeit von TCP-Verbindungen zu Beginn durch Verwendung des Slow-Start-Algorithmus recht gering ist, wird so die Ladezeit für die gesamte Seite signifikant verkürzt. Zusätzlich können bei HTTP/1.1 abgebrochene Übertragungen fortgesetzt werden.
Eine Möglichkeit zum Einsatz von HTTP/1.1 in Chats ist die Verwendung des MIME-Typs multipart/replace, bei dem der Browser nach Senden eines Boundary-Codes und eines neuerlichen Content-Length-Headerfeldes sowie eines neuen Content-Type-Headerfeldes den Inhalt des Browserfensters neu aufbaut.
Mit HTTP/1.1 ist es neben dem Abholen von Daten auch möglich, Daten zum Server zu übertragen. Mit Hilfe der PUT-Methode können so Webdesigner ihre Seiten direkt über den Webserver per WebDAV publizieren und mit der DELETE-Methode ist es ihnen möglich, Daten vom Server zu löschen. Außerdem bietet HTTP/1.1 eine TRACE-Methode, mit der der Weg zum Webserver verfolgt und überprüft werden kann, ob die Daten korrekt dorthin übertragen werden. Damit ergibt sich die Möglichkeit, den Weg zum Webserver über die verschiedenen Proxys hinweg zu ermitteln, ein traceroute auf Anwendungsebene.
Aufgrund von Unstimmigkeiten und Unklarheiten wurde 2007 eine Arbeitsgruppe gestartet, die die Spezifikation verbessern sollte. Ziel war hier lediglich eine klarere Formulierung, neue Funktionen wurden nicht eingebaut. Dieser Prozess wurde 2014 beendet und führte zu sechs neuen RFCs:
HTTP/2
Im Mai 2015 wurde von der IETF HTTP/2 als Nachfolger von HTTP/1.1 verabschiedet. Der Standard ist durch RFC 7540 und RFC 7541 spezifiziert.[3] Die Entwicklung war maßgeblich von Google (SPDY) und Microsoft (HTTP Speed+Mobility)[4] mit jeweils eigenen Vorschlägen vorangetrieben worden. Ein erster Entwurf, der sich weitgehend an SPDY anlehnte, war im November 2012 publiziert und seither in mehreren Schritten angepasst worden.
Mit HTTP/2 soll die Übertragung beschleunigt und optimiert werden.[5] Dabei soll der neue Standard jedoch vollständig abwärtskompatibel zu HTTP/1.1 sein.
Wichtige neue Möglichkeiten sind
- die Möglichkeit des Zusammenfassens mehrerer Anfragen,
- weitergehende Datenkompressionsmöglichkeiten,
- die binär kodierte Übertragung von Inhalten und
- Server-initiierte Datenübertragungen (push-Verfahren),
- einzelne Streams lassen sich priorisieren.
Eine Beschleunigung ergibt sich hauptsächlich aus der neuen Möglichkeit des Zusammenfassens (Multiplex) mehrerer Anfragen, um sie über eine Verbindung abwickeln zu können. Die Datenkompression kann nun (mittels neuem Spezialalgorithmus namens HPACK[6]) auch Kopfdaten mit einschließen. Inhalte können binär kodiert übertragen werden. Um nicht auf serverseitig vorhersehbare Folgeanforderungen vom Client warten zu müssen, können Datenübertragungen teilweise vom Server initiiert werden (push-Verfahren). Durch die Verwendung von HTTP/2 können Webseitenbetreiber die Latenz zwischen Client und Server verringern und die Netzwerkhardware entlasten.[7]
Die ursprünglich geplante Option, dass HTTP/2 standardmäßig TLS nutzt, wurde nicht umgesetzt. Allerdings kündigten die Browser-Hersteller Google und Mozilla an, dass ihre Webbrowser nur verschlüsselte HTTP/2-Verbindungen unterstützen werden. Dafür ist ALPN eine Verschlüsselungs-Erweiterung, die TLSv1.2 oder neuer braucht.[8]
HTTP/2 wird von den meisten Browsern unterstützt, darunter Google Chrome (inkl. Chrome unter iOS und Android) ab Version 41, Mozilla Firefox ab Version 36,[9] Internet Explorer 11 unter Windows 10, Opera ab Version 28 (sowie Opera Mobile ab Version 24) und Safari ab Version 8.
HTTP/3
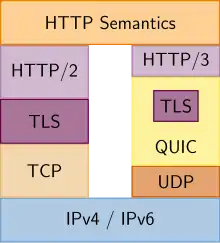
Im November 2018 wurde von der IETF beschlossen, dass HTTP/3 QUIC verwenden solle.[10]
Google arbeitet schon seit 2012 an einer Alternative unter dem Namen QUIC. QUIC setzt nicht mehr auf das verbindungsorientierte TCP, sondern auf das verbindungslose User Datagram Protocol (UDP). Auch bei dem darauf aufbauenden HTTP/3 werden Datenströme getrennt verarbeitet. Geht ein Paket unterwegs verloren, betrifft es nicht mehr alle Datenströme, wie es bei TCP der Fall ist. Bei HTTP/3 wird der betroffene Strom warten, bis das fehlende Paket eintrifft. HTTP/3 ist generell verschlüsselt und verspricht deutliche Geschwindigkeitsvorteile.[11][12]
Google Chrome Canary war ab Mitte 2019 der erste verfügbare Browser, der eine experimentelle #QUIC- und HTTP/3-Unterstützung integriert hatte. cURL zog bald nach. Die Vorab-Versionen von Firefox (nightly und beta) versuchen seit April 2021 automatisch, HTTP/3 zu verwenden, wenn es vom Webserver (derzeit z.B Google oder Facebook) angeboten wird. Webserver können die Unterstützung anzeigen, indem sie den Alt-Svc-Antwortheader verwenden oder die HTTP/3-Unterstützung mit einem HTTPS-DNS-Eintrag ankündigen. Sowohl der Client als auch der Server müssen dieselbe QUIC- und HTTP/3-Entwurfsversion unterstützen, um sich verbinden zu können. Firefox unterstützt beispielsweise derzeit die Entwürfe 27 bis 32 der Spezifikation, sodass der Server die Unterstützung einer dieser Versionen (z. B. „h3-32“) im Alt-Svc- oder HTTPS-Eintrag melden muss, damit Firefox versucht, QUIC und HTTP/3 mit diesem Server zu verwenden. Beim Besuch einer solchen Website sollte in den Netzwerkanforderungsinformationen darauf hingewiesen werden, dass HTTP/3 verwendet wird.
HTTP-Anfragemethoden
- GET
- ist die gebräuchlichste Methode. Mit ihr wird eine Ressource (zum Beispiel eine Datei) unter Angabe eines URI vom Server angefordert. Als Argumente in dem URI können auch Inhalte zum Server übertragen werden, allerdings soll laut Standard eine GET-Anfrage nur Daten abrufen und sonst keine Auswirkungen haben (wie Datenänderungen auf dem Server oder ausloggen). (siehe unten)
- POST
- schickt unbegrenzte, je nach physischer Ausstattung des eingesetzten Servers, Mengen an Daten zur weiteren Verarbeitung zum Server, diese werden als Inhalt der Nachricht übertragen und können beispielsweise aus Name-Wert-Paaren bestehen, die aus einem HTML-Formular stammen. Es können so neue Ressourcen auf dem Server entstehen oder bestehende modifiziert werden. POST-Daten werden im Allgemeinen nicht von Caches zwischengespeichert. Zusätzlich können bei dieser Art der Übermittlung auch Daten wie in der GET-Methode an den URI gehängt werden. (siehe unten)
- HEAD
- weist den Server an, die gleichen HTTP-Header wie bei GET, nicht jedoch den Nachrichtenrumpf mit dem eigentlichen Dokumentinhalt zu senden. So kann zum Beispiel schnell die Gültigkeit einer Datei im Browser-Cache geprüft werden, und Dateigrößen können im Voraus abgerufen und durch die
Content-Length-Zeile erlesen werden. - PUT
- dient dazu, eine Ressource (zum Beispiel eine Datei) unter Angabe des Ziel-URIs auf einen Webserver hochzuladen. Besteht unter der angegebenen Ziel-URI bereits eine Ressource, wird diese ersetzt, ansonsten neu erstellt.
- PATCH
- Ändert ein bestehendes Dokument ohne dieses wie bei PUT vollständig zu ersetzen. Wurde durch RFC 5789 spezifiziert.
- DELETE
- löscht die angegebene Ressource auf dem Server.
- TRACE
- liefert die Anfrage so zurück, wie der Server sie empfangen hat. So kann überprüft werden, ob und wie die Anfrage auf dem Weg zum Server verändert worden ist – sinnvoll für das Debugging von Verbindungen.
- OPTIONS
- liefert eine Liste der vom Server unterstützten Methoden und Merkmale.
- CONNECT
- wird von Proxyservern implementiert, die in der Lage sind, SSL-Tunnel zur Verfügung zu stellen.
RESTful Web Services verwenden die unterschiedlichen Anfragemethoden zur Realisierung von Webservices. Insbesondere werden dafür die HTTP-Anfragemethoden GET, POST, PUT/PATCH und DELETE verwendet.
WebDAV fügt die Methoden PROPFIND, PROPPATCH, MKCOL, COPY, MOVE, LOCK und UNLOCK zu HTTP hinzu.
Argumentübertragung
Häufig will ein Nutzer Informationen an eine Website senden. Dazu stellt HTTP prinzipiell zwei Möglichkeiten zur Verfügung:
- HTTP-GET
- Die Daten sind Teil der URL und bleiben deshalb beim Speichern oder der Weitergabe des Links erhalten. Sie müssen URL-kodiert werden, das heißt reservierte Zeichen müssen mit „%<Hex-Wert>“ und Leerzeichen mit „+“ dargestellt werden.
- HTTP-POST
- Übertragung der Daten mit einer speziell dazu vorgesehenen Anfrageart im HTTP-Nachrichtenrumpf, so dass sie in der URL nicht sichtbar sind.
HTTP GET
Hier werden die Parameter-Wertepaare durch das Zeichen ? in der URL eingeleitet.
Oft wird diese Vorgehensweise gewählt, um eine Liste von Parametern zu übertragen, die die Gegenstelle bei der Bearbeitung einer Anfrage berücksichtigen soll. Häufig besteht diese Liste aus Wertepaaren, welche durch das &-Zeichen voneinander getrennt sind. Die jeweiligen Wertepaare sind in der Form Parametername=Parameterwert aufgebaut. Seltener wird das Zeichen ; zur Trennung von Einträgen der Liste benutzt.[13]
Ein Beispiel: Auf der Startseite von Wikipedia wird in das Eingabefeld der Suche „Katzen“ eingegeben und auf die Schaltfläche „Artikel“ geklickt. Der Browser sendet die folgende oder eine ähnliche Anfrage an den Server:
GET /wiki/Spezial:Search?search=Katzen&go=Artikel HTTP/1.1
Host: de.wikipedia.org
…
Dem Wikipedia-Server werden zwei Wertepaare übergeben:
| Argument | Wert |
|---|---|
| search | Katzen |
| go | Artikel |
Diese Wertepaare werden in der Form
Parameter1=Wert1&Parameter2=Wert2
mit vorangestelltem ? an die geforderte Seite angehängt.
Dadurch erfährt der Server, dass der Nutzer den Artikel Katzen betrachten will. Der Server verarbeitet die Anfrage, sendet aber keine Datei, sondern leitet den Browser mit einem Location-Header zur richtigen Seite weiter, etwa mit:
HTTP/1.0 302 Found
Date: Fri, 13 Jan 2006 15:12:44 GMT
Location: http://de.wiki.li/Katzen
…
Der Browser befolgt diese Anweisung und sendet aufgrund der neuen Informationen eine neue Anfrage, etwa:
GET /wiki/Katzen HTTP/1.1
Host: de.wikipedia.org
…
Und der Server antwortet und gibt den Artikel Katzen aus, etwa:
HTTP/1.1 200 OK
Date: Fri, 13 Jan 2006 15:12:48 GMT
Last-Modified: Tue, 10 Jan 2006 11:18:20 GMT
Content-Language: de
Content-Type: text/html; charset=utf-8
Die Katzen (Felidae) sind eine Familie aus der Ordnung der Raubtiere (Carnivora)
innerhalb der Überfamilie der Katzenartigen (Feloidea).
…
Der Datenteil ist meist länger, hier soll nur das Protokoll betrachtet werden.
Nachteil dieser Methode ist, dass die angegebenen Parameter mit der URL meist in der Historie des Browsers gespeichert werden und so persönliche Daten unbeabsichtigt im Browser gespeichert werden können. Stattdessen sollte man in diesem Fall die Methode POST benutzen.
HTTP POST
Da sich die Daten nicht in der URL befinden, können per POST große Datenmengen, zum Beispiel Bilder, übertragen werden.
Im folgenden Beispiel wird wieder der Artikel Katzen angefordert, doch diesmal verwendet der Browser aufgrund eines modifizierten HTML-Codes (method="POST") eine POST-Anfrage. Die Variablen stehen dabei nicht in der URL, sondern gesondert im Rumpfteil, etwa:
POST /wiki/Spezial:Search HTTP/1.1
Host: de.wikipedia.org
Content-Type: application/x-www-form-urlencoded
Content-Length: 24
search=Katzen&go=Artikel
Auch das versteht der Server und antwortet wieder mit beispielsweise folgendem Text:
HTTP/1.1 302 Found
Date: Fri, 13 Jan 2006 15:32:43 GMT
Location: http://de.wiki.li/Katzen
…
HTTP-Statuscodes

Jede HTTP-Anfrage wird vom Server mit einem HTTP-Statuscode beantwortet. Er gibt zum Beispiel Informationen darüber, ob die Anfrage erfolgreich bearbeitet wurde, oder teilt dem Client, also etwa dem Browser, im Fehlerfall mit, wo (zum Beispiel Umleitung) beziehungsweise wie (zum Beispiel mit Authentifizierung) er die gewünschten Informationen (wenn möglich) erhalten kann.
- 1xx – Informationen
- Die Bearbeitung der Anfrage dauert trotz der Rückmeldung noch an. Eine solche Zwischenantwort ist manchmal notwendig, da viele Clients nach einer bestimmten Zeitspanne (Zeitüberschreitung) automatisch annehmen, dass ein Fehler bei der Übertragung oder Verarbeitung der Anfrage aufgetreten ist, und mit einer Fehlermeldung abbrechen.
- 2xx – Erfolgreiche Operation
- Die Anfrage wurde bearbeitet und die Antwort wird an den Anfragesteller zurückgesendet.
- 3xx – Umleitung
- Um eine erfolgreiche Bearbeitung der Anfrage sicherzustellen, sind weitere Schritte seitens des Clients erforderlich. Das ist zum Beispiel der Fall, wenn eine Webseite vom Betreiber umgestaltet wurde, so dass sich eine gewünschte Datei nun an einem anderen Platz befindet. Mit der Antwort des Servers erfährt der Client im Location-Header, wo sich die Datei jetzt befindet.
- 4xx – Client-Fehler
- Bei der Bearbeitung der Anfrage ist ein Fehler aufgetreten, der im Verantwortungsbereich des Clients liegt. Ein 404 tritt beispielsweise ein, wenn ein Dokument angefragt wurde, das auf dem Server nicht existiert. Ein 403 weist den Client darauf hin, dass es ihm nicht erlaubt ist, das jeweilige Dokument abzurufen. Es kann sich zum Beispiel um ein vertrauliches oder nur per HTTPS zugängliches Dokument handeln.
- 5xx – Server-Fehler
- Es ist ein Fehler aufgetreten, dessen Ursache beim Server liegt. Zum Beispiel bedeutet 501, dass der Server nicht über die erforderlichen Funktionen (das heißt zum Beispiel Programme oder andere Dateien) verfügt, um die Anfrage zu bearbeiten.
Zusätzlich zum Statuscode enthält der Header der Server-Antwort eine Beschreibung des Fehlers in englischsprachigem Klartext. Zum Beispiel ist ein Fehler 404 an folgendem Header zu erkennen:
HTTP/1.1 404 Not Found
…
HTTP-Authentifizierung
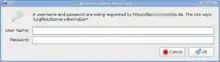
Stellt der Webserver fest, dass für eine angeforderte Datei Benutzername oder Passwort nötig sind, meldet er das dem Browser mit dem Statuscode 401 Unauthorized und dem Header WWW-Authenticate. Dieser prüft, ob die Angaben vorliegen, oder präsentiert dem Anwender einen Dialog, in dem Name und Passwort einzutragen sind, und überträgt diese an den Server. Stimmen die Daten, wird die entsprechende Seite an den Browser gesendet. Es wird nach RFC 2617 unterschieden in:
- Basic Authentication
- Die Basic Authentication ist die häufigste Art der HTTP-Authentifizierung. Der Webserver fordert eine Authentifizierung an, der Browser sucht daraufhin nach Benutzername/Passwort für diese Datei und fragt gegebenenfalls den Benutzer. Anschließend sendet er die Authentifizierung mit dem Authorization-Header in der Form Benutzername:Passwort Base64-codiert an den Server. Base64 bietet keinen kryptographischen Schutz, daher kann dieses Verfahren nur beim Einsatz von HTTPS als sicher angesehen werden.
- Digest Access Authentication
- Bei der Digest Access Authentication sendet der Server zusätzlich mit dem WWW-Authenticate-Header eine eigens erzeugte zufällige Zeichenfolge (Nonce). Der Browser berechnet den Hashcode der gesamten Daten (Benutzername, Passwort, erhaltener Zeichenfolge, HTTP-Methode und angeforderter URI) und sendet sie im Authorization-Header zusammen mit dem Benutzernamen und der zufälligen Zeichenfolge zurück an den Server, der diese mit der selbst berechneten Prüfsumme vergleicht. Ein Abhören der Kommunikation nützt hier einem Angreifer nichts, da sich aufgrund der verwendeten kryptologischen Hashfunktion aus dem Hashcode die Daten nicht rekonstruieren lassen und für jede Anforderung anders lauten.
HTTP-Kompression
Um die übertragene Datenmenge zu verringern, kann ein HTTP-Server seine Antworten komprimieren. Ein Client muss bei einer Anfrage mitteilen, welche Kompressionsverfahren er verarbeiten kann. Dazu dient der Header Accept-Encoding (etwa Accept-Encoding: gzip, deflate). Der Server kann dann die Antwort mit einem vom Client unterstützten Verfahren komprimieren und gibt im Header Content-Encoding das verwendete Kompressionsverfahren an.
HTTP-Kompression spart vor allem bei textuellen Daten (HTML, XHTML, CSS, Javascript-Code, XML, JSON) erhebliche Datenmengen, da sich diese gut komprimieren lassen. Bei bereits komprimierten Daten (etwa gängige Formate für Bilder, Audio und Video) ist die (erneute) Kompression nutzlos und wird daher üblicherweise nicht benutzt.
In Verbindung mit einer mit TLS verschlüsselten Kommunikation führt die Komprimierung allerdings zum BREACH-Exploit, wodurch die Verschlüsselung gebrochen werden kann.
Applikationen über HTTP
HTTP als textbasiertes Protokoll wird nicht nur zur Übertragung von Webseiten verwendet, es kann auch in eigenständigen Applikationen, den Webservices, verwendet werden. Dabei werden die HTTP-eigenen Befehle wie GET und POST für CRUD-Operationen weiterverwendet. Dies hat den Vorteil, dass kein eigenes Protokoll für die Datenübertragung entwickelt werden muss. Beispielhaft wird dies bei REST eingesetzt.
HTTP im Vergleich mit dem QUIC-Protokoll
HTTP stützt sich auf das Transmission Control Protocol (TCP). TCP bestätigt den Erhalt jedes Datenpakets. Dies führt dazu, dass im Falle eines Paketverlustes alle anderen Pakete auf die erneute Übertragung des verloren gegangenen warten müssen, wenn der Empfängercache überläuft (Head-of-Line Blocking[14])
Das QUIC-Protokoll soll in seiner Gesamtheit ein schnelleres Versenden von Datenpaketen über das verbindungslose UDP ermöglichen. Funktionen, die UDP fehlen -- wie beispielsweise Empfangsbestätigungen -- müssen vom übergeordneten Protokoll bereitgestellt werden. QUIC regelt die Verbindungskontrolle selbst. Sender und Empfänger tauschen bei einer Datenverbindung lediglich beim ersten Handshake das Zertifikat und den Schlüssel aus, wodurch sich die Latenz verringert. Bei weiteren Sendevorgängen „erinnert“ sich QUIC an die in der Vergangenheit bestehende Verbindung und greift auf die gespeicherten Daten zu. Als Verschlüsselungsprotokoll wird aktuell die TLS Version 1.3 verwendet. Im QUIC-Protokoll besteht außerdem die Möglichkeit des Multiplexing. Dabei können über eine Client-Server-Verbindung mehrere Datenströme gleichzeitig übertragen werden, was die Ladezeit nochmals deutlich reduziert.[15]
Siehe auch
Weblinks
- Arbeitsgruppe der IETF zur Weiterentwicklung von HTTP
- HttpTea, ein HTTP-Analysator (Freeware, englisch)
- Linkkatalog zum Thema HTTP bei curlie.org (ehemals DMOZ)
- Microsofts ausführlicher Bericht zu http 2.0 (englisch)
Einzelnachweise
- Tim Berners-Lee: The Original HTTP as defined in 1991. In: w3.org, abgerufen am 13. November 2010.
- RFC 2616 Hypertext Transfer Protocol – HTTP/1.1
- RFCs für HTTP/2 festgelegt und -geschrieben. iX, News-Meldung vom 15. Mai 2015 14:23 Uhr.
- Christian Kirsch: Microsoft bringt eigenen Vorschlag für HTTP 2. heise.de, 29. März 2012, abgerufen am 4. April 2012.
- Christian Kirsch: Googles SPDY soll das Web beschleunigen. heise.de, 13. November 2009; abgerufen am 4. April 2012
- Entwurf der Spezifikation von HPACK (dem Header-Kompressionsalgorithmus für HTTP/2). HTTP-Arbeitsgruppe der IETF
- HTTP/2 - schneller surfen mit neuer Protokollversion. pcwelt.de, 30. Januar 2016, abgerufen am 21. Februar 2018.
- M. Belshe, R. Peon, M. Thomson: Hypertext Transfer Protocol Version 2, Use of TLS Features. Abgerufen am 10. Februar 2015.
- Firefox 36 implementiert HTTP/2
- IETF: HTTP über Quic wird zu HTTP/3. 12. November 2018, abgerufen am 27. April 2019.
- Kim Rixecker: HTTP/3: Wir erklären die nächste Version des Hypertext Transfer Protocols. In: t3n Magazin. 13. August 2021, abgerufen am 19. August 2021.
- Tonino Jankov: Was ist HTTP/3? - Hintergrundinformationen über das schnelle neue UDP-basierte Protokoll. In: Kinsta. 18. Mai 2021, abgerufen am 19. August 2021.
- Appendix B: Performance, Implementation, and Design Notes. In: World Wide Web Consortium [W3C] (Hrsg.): HTML 4.01 Specification. 24. Dezember 1999, B.2.2: Ampersands in URI attribute values (w3.org).
- Was ist HTTP? Abgerufen am 25. März 2021.
- QUIC: Das steckt hinter dem experimentellen Google-Protokoll. Abgerufen am 25. März 2021.