Google-Matrix
Die Google-Matrix ist eine quadratische Matrix, die bei der Konstruktion des PageRank-Algorithmus entsteht. Da sie oftmals sehr groß ist (mit vielen Millionen Zeilen und Spalten), sind die numerischen und algebraischen Eigenschaften dieser Matrix für die schnelle und exakte Bestimmbarkeit der PageRanks von großer Bedeutung.

Definition
Die normierte Google-Matrix eines Netzwerks oder gerichteten Graphen mit Knoten ist die reelle -Matrix:



Die einzelnen Komponenten der Google-Matrix sind dabei folgendermaßen definiert:
- Die Linkmatrix ist die zeilenweise auf normierte Adjazenzmatrix des untersuchten Graphen:




- wobei der Ausgangsgrad des Knotens ist, also die Anzahl der Kanten, die den Knoten verlassen.


- Der Vektor ist komponentenweise definiert als


- Er enthält also genau dann eine Eins, wenn der Ausgangsgrad einer Seite bzw. eines Knotens null ist. Diese Knoten werden auch dangling nodes genannt. In der Literatur gibt es verschiedene Methoden, diese Knoten zu behandeln,[1] die hier behandelte ist die häufigste.
- ist eine reelle Zahl zwischen und , die Dämpfungsfaktor genannt wird
- ist ein Einsvektor der Länge , also ein Vektor, der nur Einsen als Einträge hat. Damit ist die Matrix genau die Einsmatrix.




Eigenschaften
PageRank
Zur Berechnung der PageRanks ist man insbesondere an der Existenz und Vielfachheit von Linkseigenvektoren der Matrix interessiert. Diese entsprechen genau den gewöhnlichen Eigenvektoren der Matrix zum Eigenwert . Interpretiert man das Eigenwertproblem



als Berechnung der stationären Verteilung einer Markow-Kette, so ist der Vektor ein stochastischer Vektor bestehend aus den PageRanks. Damit reduziert sich das Eigenvektorproblem zu dem linearen Gleichungssystem

- .

Um dieses lineare Gleichungssystem effizient lösen zu können, stellt sich die Frage nach der Regularität der Matrix und ihrer Konditionszahl.
Normen
Sowohl die Matrix als auch die Matrix sind im Allgemeinen nur substochastisch. Addiert man beide, so erhält man eine zeilenstochastische Matrix, da sich die Nichtnullzeilen der Matrizen ergänzen. Da auch zeilenstochastisch ist (streng genommen sogar doppelt-stochastisch) und durch den Dämpfungsparameter nur Konvexkombinationen gebildet werden (bezüglich derer die stochastischen Matrizen abgeschlossen sind), ist die Google-Matrix ebenfalls eine zeilenstochastische Matrix. Damit gilt für die Zeilensummennorm der Google-Matrix



und damit auch für die Spaltensummennorm der Transponierten
- .

Eigenvektoren und Eigenwerte
Die Existenz eines Eigenvektors von zum Eigenwert folgt direkt daraus, dass die Matrix eine stochastische Matrix ist. Dass sogar betragsgrößter positiver Eigenwert ist, zu dem ein einfacher strikt positiver Eigenvektor existiert, folgt aus dem Satz von Perron-Frobenius, da gilt. Wichtig ist hier, dass erst die Einführung des Dämpfungsparameters die Positivität der Matrix und damit die Lösbarkeit des Eigenwertproblems garantiert.

Des Weiteren lässt sich noch zeigen, dass für alle anderen Eigenwerte gilt.[2] Die Separation der Eigenwerte wird also nur durch den Dämpfungsparameter bestimmt. Damit ist für viele der numerischen Verfahren zur Eigenwertberechnung, wie beispielsweise die Potenzmethode, eine gute Konvergenzgeschwindigkeit garantiert, so lange der Dämpfungsfaktor nicht zu nahe an gewählt wird. Normalerweise gilt .


Regularität und Kondition
Da

gilt, liefert die Neumann-Reihe die Invertierbarkeit der Matrix
- .

Somit ist das Problem als lineares Gleichungssystem lösbar. Gleichzeitig gilt auch für die Norm der Inversen

und damit für die Konditionszahl die Abschätzung
- .

Somit ist nur die Wahl des Dämpfungsparameters für die Kondition verantwortlich und sollte wieder nicht zu nahe an gewählt werden.
Numerische Berechnung des Eigenvektors
Der betragsgrößte Eigenvektor der Google-Matrix wird normalerweise mittels der Potenzmethode näherungsweise bestimmt. Dabei wird ausgehend von einer Startnäherung in jedem Iterationsschritt das Matrix-Vektor-Produkt der Google-Matrix mit der aktuellen Näherung des Eigenvektors gebildet. In jedem Iterationsschritt ist demnach



zu berechnen. Ist die Startnäherung ein stochastischer Vektor, dann ist auch jeder folgende Näherungsvektor stochastisch. Nachdem die Eigenwerte der Google-Matrix gut separiert sind, ist eine langsame Konvergenzgeschwindigkeit der Potenzmethode ausgeschlossen.
Bei der Berechnung kann die spezielle Struktur der Google-Matrix ausgenutzt werden. Die Linkmatrix ist in der Regel extrem dünn besetzt, das heißt fast alle ihre Einträge sind null. Dadurch kann sie zum einen sehr platzsparend gespeichert werden und zum anderen sehr effizient mit einem Vektor multipliziert werden. Auch der Vektor ist in der Regel dünn besetzt, wodurch sich der Term ebenfalls sehr schnell berechnen lässt.



Beispiel
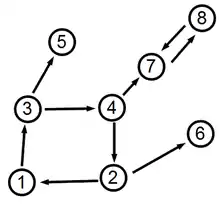
Betrachtet man als Beispiel den rechts stehenden gerichteten Graphen mit 8 Knoten, so sind die Knoten 5 und 6 dangling nodes. Dann ist die zeilenweise normierte Adjazenzmatrix

und der Vektor
- .

Dann ist mit der obigen Konstruktion und einem Dämpfungsparameter von


Der Eigenvektor von zum Eigenwert 1 ist dann
- .

Damit haben die Knoten 7 und 8 die höchsten PageRanks (0.2825 und 0.2654) und die Knoten 1 und 6 die niedrigsten (je 0.0675). Der betragszweite Eigenwert ist , die obige Abschätzung ist also scharf. Des Weiteren ist die Konditionszahl

- ,

auch diese Abschätzung ist also scharf.
Einzelnachweise
- Deeper Inside PageRank Amy N. Langville und Carl D. Meyer. Abgerufen am 30. August 2013.
- T.H. Haveliwala und S.D. Kamvar: The Second Eigenvalue of the Google Matrix. Technischer Report, Stanford University, 2003. Abgerufen am 30. August 2013.
Literatur
- Peter Knabner, Wolf Barth: Lineare Algebra. Grundlagen und Anwendungen (= Springer-Lehrbuch). Springer, Berlin 2012, ISBN 978-3-642-32185-6.