PageRank
Der PageRank-Algorithmus ist ein Verfahren, eine Menge verlinkter Dokumente, beispielsweise das World Wide Web, anhand ihrer Struktur zu bewerten und zu gewichten. Dabei wird jedem Element ein Gewicht, der PageRank, aufgrund seiner Verlinkungsstruktur zugeordnet. Der Algorithmus wurde von Larry Page (daher der Name PageRank) und Sergei Brin an der Stanford University entwickelt und von dieser zum Patent angemeldet.[1] Er diente der Suchmaschine Google des von Brin und Page gegründeten Unternehmens Google Inc. als Grundlage für die Bewertung von Seiten.
Der PageRank-Algorithmus ist eine spezielle Methode, die Linkpopularität einer Seite bzw. eines Dokumentes festzulegen. Das Grundprinzip lautet: Je mehr Links auf eine Seite verweisen, desto höher ist das Gewicht dieser Seite. Je höher das Gewicht der verweisenden Seiten ist, desto größer ist der Effekt. Das Ziel des Verfahrens ist es, die Links dem Gewicht entsprechend zu sortieren, um so eine Ergebnisreihenfolge bei einer Suchabfrage herzustellen, d. h. Links zu wichtigeren Seiten weiter vorne in der Ergebnisliste anzuzeigen.
Der PageRank-Algorithmus bildet einen zufällig durch das Netz surfenden Benutzer nach. Die Wahrscheinlichkeit, mit der dieser auf eine bestimmte Webseite stößt, korreliert mit dem PageRank der Webseite.
Der PageRank-Algorithmus
Konstruktion
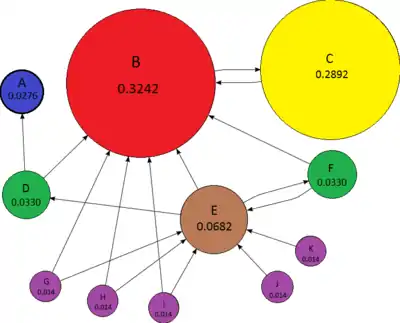

Das Prinzip des PageRank-Algorithmus ist, dass jede Seite ein Gewicht (PageRank) besitzt, das umso größer ist, je mehr Seiten (mit möglichst hohem eigenen Gewicht) auf diese Seite verweisen. Das Gewicht einer Seite berechnet sich also aus den Gewichten der auf verlinkenden Seiten . Verlinkt auf insgesamt verschiedene Seiten, so wird das Gewicht von anteilig auf diese Seiten aufgeteilt. Folgende rekursive Formel kann als Definition des PageRank-Algorithmus angesehen werden:






Dabei ist die Gesamtanzahl der Seiten und ein Dämpfungsfaktor zwischen 0 und 1, mit dem ein kleiner Anteil des Gewichts () einer jeden Seite abgezogen und gleichmäßig auf alle vom Algorithmus erfassten Seiten verteilt wird. Dies ist notwendig, damit das Gewicht nicht zu Seiten „abfließt“, die auf keine anderen Seiten verweisen. Oft wird die obige Formel auch ohne den Normierungsfaktor angegeben.




Analog kann die Gleichung auch als zeilenweise Notation des linearen Gleichungssystems

mit dem Spaltenvektor , dem konstanten Spaltenvektor und der Matrix mit Koeffizienten




interpretiert werden, wobei das Kronecker-Delta bezeichnet und die Matrix durch



definiert ist.
Diese Gleichung führt auf das Eigenwertproblem
- ,

wobei die sogenannte Google-Matrix ist und die Transponierte der Matrix bezeichnet.


Für ist die Lösung des Gleichungssystems eindeutig (Satz von Perron-Frobenius). Ein kleinerer Dämpfungsfaktor führt zu einer homogeneren Verteilung des PageRanks.

Die Lösung des linearen Gleichungssystems kann analytisch oder numerisch erfolgen. Durch Verwendung der Jacobi-Iteration zur numerischen Lösung ergibt sich obige rekursive Gleichung. Andere numerische Verfahren zur Matrixinvertierung, wie das Minimale-Residuum-, das Überrelaxations- oder das Gauß-Seidel-Verfahren, konvergieren jedoch in der Regel schneller.
Zufallssurfermodell
Das Zufallssurfermodell (engl. Random Surfer Model) bietet eine alternative Interpretation des Page-Rank-Algorithmus, welche aus der Stochastik kommt. Normiert man den PageRank auf 1, so kann man das Gewicht einer Seite als Wahrscheinlichkeit interpretieren, dass ein zufälliger Surfer (Zufallspfad) sich auf dieser Seite befindet. Ein zufälliger Surfer bewegt sich durch das Netz, indem er mit der Wahrscheinlichkeit zufällig einen der ausgehenden Links der aktuellen Seite wählt. Mit Wahrscheinlichkeit wählt er eine beliebige neue Seite. Das Modell kann als Markow-Kette verstanden werden, der normierte Page-Rank ist dann die Stationäre Verteilung dieser Kette.
Rational Surfer Modell
Das Rational Surfer Modell ist ein von Google 2010 eingereichtes Patent. Es stellt eine Weiterentwicklung des Zufallssurfermodells dar. Hierbei wird die Wichtigkeit eines Links je nach Platzierung nach empirischen Daten unterschieden. Ziel ist es, Links stärker zu gewichten, welche von einem rationalen Surfer mit höherer Wahrscheinlichkeit geklickt werden. Somit soll Linkkauf entgegengewirkt werden.
Geschichte
Die Idee des PageRank-Algorithmus stammt ursprünglich aus der Soziometrie und lässt sich in der Fachliteratur erstmals 1953 bei Katz nachweisen. Bereits 1949 verwendete Seeley das Verfahren zur Erklärung des Zustandekommens des Status eines Individuums, allerdings gibt es in seiner Beschreibung noch keine Normierung auf die Anzahl der ausgehenden Kanten und keinen Dämpfungsterm. Letzterer wurde 1965 von Charles H. Hubbell eingeführt.
Brin und Page entwickelten den Algorithmus 1996 an der Stanford University. Page meldete 1997 ein Patent an[2], das auf die Stanford University eingetragen war. Zusammen veröffentlichten Brin und Page den Algorithmus 1998. In ihrer Originalarbeit zitieren sie Massimo Marchiori (Universität Padua, Entwickler von Hyper Search), Eugene Garfield, der in den 1950er Jahren citation analysis entwickelte, und Jon Kleinberg[3], der etwa gleichzeitig wie Brin und Page „Hubs und Authorities“ (HITS) entwickelte.
Neben Brin und Page entwickelte nicht nur Kleinberg, sondern auch Robin Li um 1996 in China einen ähnlichen Algorithmus (RankDex), den er bei der Suchmaschine Baidu verwendete (Patent 1999).
Nach der Google-Gründung erhielt die Stanford University von Google 1,8 Millionen Anteile für das Patent, das exklusiv an Google ging. 2005 verkauften sie die Aktien für 336 Millionen Dollar.[4]
Forscher der Washington State University geben an, dass Googles PageRank-Algorithmus auch dazu geeignet sein kann, die geometrische Ausrichtung von Wassermolekülen relativ zu anderen Molekülen in einer Lösung, z. B. denen giftiger Chemikalien näherungsweise zu berechnen.[5]
Anpassungen
Der heute von Google verwendete Algorithmus hat vermutlich nicht mehr exakt diese Form, geht aber auf diese Formel zurück. Alternative Algorithmen sind das Verfahren der Hubs und Authorities von Jon Kleinberg, der Hilltop- und der TrustRank-Algorithmus.
2013 wurde das Ranking durch den neuen Algorithmus Hummingbird ersetzt. Der PageRank ist nur noch ein Aspekt, den Hummingbird in seine Bewertung einbezieht.[6]
Toolbar- und Verzeichnis-Werte
Informationen über den PageRank lassen sich aus der Google Toolbar und dem Google-Verzeichnis entnehmen. Der von Google in der Toolbar angezeigte PageRank liegt zwischen 0 und 10. Der im Google-Verzeichnis angegebene Wert lag bis Anfang 2008 zwischen 0 und 7, entspricht inzwischen aber dem in der Toolbar angezeigten Wert. Die angezeigten Werte bilden den realen PageRank auf einer logarithmischen Skala ab und geben das Ergebnis als gerundeten ganzzahligen Wert wieder.
Der in der Google-Toolbar angezeigte PageRank wurde früher alle dreißig Tage aktualisiert. Inzwischen wird das Intervall zwischen den Updates sehr unregelmäßig durchgeführt, die Intervalllänge schwankt dabei zwischen etwas weniger als dreißig bis zu über hundert Tagen. Die letzte Aktualisierung des PageRank wurde von Google am 6. Dezember 2013 durchgeführt.
Google hat mittlerweile den Toolbar PageRank endgültig abgeschafft und die Auslieferung der entsprechenden Daten eingestellt. Somit ist der PageRank für Webseitenbetreiber nicht mehr öffentlich einsehbar. Intern wird Google die Daten für die Algorithmen jedoch weiterhin nutzen.[7]
Manipulation
Aufgrund der wirtschaftlichen Bedeutung ist es inzwischen zu gezielten Manipulationen und Fälschungen gekommen. So wurde das System in der Praxis von Suchmaschinenoptimierern durch Suchmaschinen-Spamming in Gästebüchern, Blogs und Foren, dem Betreiben von Linkfarmen und anderen unseriösen Methoden unterlaufen. Hierzu gehört unter anderem die Möglichkeit, den in der Toolbar angezeigten PageRank einer niedrig eingestuften Seite durch Weiterleitung auf eine bestehende Seite mit hohem PageRank zu spiegeln. Die Weiterleitung bewirkt ein Kopieren der Anzeige des hohen PageRanks der Zielseite mit dem folgenden Update. Wird die Weiterleitung anschließend entfernt, so wird dem Besucher für die Dauer des dann laufenden Intervalls der eigentliche Seiteninhalt in Verbindung mit dem gespiegelten PageRank präsentiert. Der eigentliche PageRank-Wert und das Ranking im Suchalgorithmus ist hiervon unberührt, lediglich die Anzeige wird manipuliert. Dies kann beispielsweise in betrügerischer Absicht dafür genutzt werden, beim Verkauf der Domain oder von Links einen höheren Preis zu erzielen.
Anfang 2005 implementierte Google mit rel="nofollow" ein neues Attribut für Verweise, als Versuch, gegen Spam vorzugehen. Links, die mit diesem Attribut versehen werden, werden nicht für die PageRank-Berechnung berücksichtigt. Durch Kennzeichnung ausgehender Links kann so beispielsweise dem Gästebuch-, Blog- und Forum-Spamming entgegengewirkt werden. Allerdings ist diese Methode umstritten, da zum einen nicht alle Suchmaschinen das Attribut beachten und zum anderen die Links zwar nicht für die PageRank-Berechnung berücksichtigt werden, die verlinkten Seiten jedoch von den meisten Suchmaschinen weiterhin gecrawlt werden.
Nachteile
Die Nachteile von PageRank im Überblick:
- Entscheidend ist nicht das Interesse der Leser, sondern lediglich das anderer Webseitenbetreiber.
- Finanzkräftige Seitenbetreiber können sich Backlinks erkaufen und werden dadurch in Suchergebnissen höher positioniert. Dies führt dazu, dass statt qualitativ hochwertigen Inhalts oft die finanziellen Möglichkeiten über die Reihenfolge der Suchergebnisse entscheiden.
- Webmaster sehen oft im PageRank das einzige Bewertungskriterium für den Linktausch. Der Inhalt der verlinkten Seiten gerät in den Hintergrund.
- Der PageRank liefert keinen Beitrag zur qualitativen Messung von Websites.
Sonstige Verwendungszwecke
PageRank wird heute auch regelmäßig in der Bibliometrie, der Analyse von Sozialen- und Informationsnetzwerken sowie für Linkvorhersagen und Empfehlungen verwendet. Es wird sogar zur Systemanalyse von Straßennetzen sowie in der Chemie, Biologie, Neurowissenschaft und Physik eingesetzt.[8]
Wissenschaftliche Forschung und Hochschulwesen
PageRank wird seit kurzem verwendet, um den wissenschaftlichen Einfluss von Forschern zu quantifizieren. Die zugrunde liegenden Zitations- und Kollaborationsnetzwerke werden in Verbindung mit dem Pagerank-Algorithmus verwendet, um ein Ranking-System für einzelne Publikationen zu entwickeln, das sich auf einzelne Autoren überträgt. Der neue Index, der als Pagerank-Index (Pi) bekannt ist, erweist sich im Vergleich zum h-Index als gerechter, da dieser viele Nachteile aufweist.[9]
Für die Analyse von Proteinnetzwerken in der Biologie ist PageRank ebenfalls ein nützliches Werkzeug.[10][11]
In jedem Ökosystem kann eine abgewandelte Version des PageRank verwendet werden, um die Arten zu bestimmen, die für das Fortbestehen des Ökosystems wichtig sind.[12]
Eine ähnliche neue Anwendung von PageRank besteht darin, akademische Promotionsprogramme auf der Grundlage ihrer Erfolge bei der Einstellung ihrer Absolventen in Fakultätspositionen zu bewerten. Im Sinne von PageRank sind akademische Abteilungen miteinander verbunden, indem sie ihre Lehrkräfte voneinander (und von sich selbst) anwerben.[13]
Siehe auch
Literatur
- Amy N. Langville und Carl D. Meyer: Google's pagerank and beyond: the science of search engine rankings, Princeton, N.J: Princeton University Press 2006. ISBN 978-1-4008-3032-9 (sample chapter)
- Arvind Arasu, Junghoo Cho, Héctor García-Molina, Andreas Paepcke und Sriram Raghavan: Searching the Web, Technical Report, Stanford University, USA, 2000 (online; PDF; 1,7 MB)
- Sergei Brin, Lawrence Page: The Anatomy of a Large-Scale Hypertextual Web Search Engine. In: Computer Networks and ISDN Systems, Band 30, 1998, S. 107–117
- Charles H. Hubbell: An input-output approach to clique identification. In: Sociometry, Nummer 28, Seite 377–399, 1965
- Leo Katz: A new status index derived from sociometric analysis. In: Psychometrika, Nummer 18(1), Seite 39–43, 1953 (PDF)
- J. Seeley: The net of reciprocal influence: A problem in treating sociometric data, Canadian Journal of Psychology, 3, 234–240, 1949.
Weblinks
- eFactory: Erläuterungen und Berechnungsbeispiele zum PageRank-Verfahren
- Franz Embacher (Universität Wien): Bewertung von Webseiten durch Google
- Suchmaschinen-Doktor: Der PageRank-Algorithmus - Geschichte, Mathematik, Beispiele und Erweiterungen
- Linkkatalog zum Thema PageRank bei curlie.org (ehemals DMOZ)
Einzelnachweise
- Patent US6285999: Method for node ranking in a linked database. Angemeldet am 10. Januar 1997, Erfinder: Lawrence Page.
- Method for node ranking in a linked database, US-Patent 6285999. Prioritätsdatum 10. Januar 1997, erteilt 9. Januar 1998, veröffentlicht 4. September 2001. Page wird als Erfinder genannt
- Ebenso zitiert Page diese in seinem Patent sowie Katz, Hubbell und andere
- Stanford earns 335 Million off google stocks, Redorbit 2005
- Wired: Researchers Fight Toxic Waste With Google PageRank 17. Februar 2012
- Amit Singhal: Fifteen years on—and we’re just getting started. In: Google Blog. Google, 26. September 2013, abgerufen am 5. Mai 2021 (englisch).
- Google has confirmed it is removing Toolbar PageRank. Searchengineland.co, 8. März 2016, abgerufen am 10. März 2016.
- David F. Gleich: PageRank Beyond the Web. In: SIAM Review. Band 57, Nr. 3, 1. Januar 2015, ISSN 0036-1445, S. 321–363, doi:10.1137/140976649 (siam.org [abgerufen am 12. Januar 2022]).
- Upul Senanayake, Mahendra Piraveenan, Albert Zomaya: The Pagerank-Index: Going beyond Citation Counts in Quantifying Scientific Impact of Researchers. In: PLoS ONE. Band 10, Nr. 8, 19. August 2015, ISSN 1932-6203, S. e0134794, doi:10.1371/journal.pone.0134794, PMID 26288312, PMC 4545754 (freier Volltext) – (plos.org [abgerufen am 12. Januar 2022]).
- Gábor Iván, Vince Grolmusz: When the Web meets the cell: using personalized PageRank for analyzing protein interaction networks. In: Bioinformatics. Band 27, Nr. 3, 1. Februar 2011, ISSN 1460-2059, S. 405–407, doi:10.1093/bioinformatics/btq680 (oup.com [abgerufen am 12. Januar 2022]).
- Dániel Bánky, Gábor Iván, Vince Grolmusz: Equal Opportunity for Low-Degree Network Nodes: A PageRank-Based Method for Protein Target Identification in Metabolic Graphs. In: PLoS ONE. Band 8, Nr. 1, 29. Januar 2013, ISSN 1932-6203, S. e54204, doi:10.1371/journal.pone.0054204, PMID 23382878, PMC 3558500 (freier Volltext) – (plos.org [abgerufen am 12. Januar 2022]).
- Google trick tracks extinctions. 4. September 2009 (bbc.co.uk [abgerufen am 12. Januar 2022]).
- Benjamin M. Schmidt, Matthew M. Chingos: Ranking Doctoral Programs by Placement: A New Method. In: PS: Political Science & Politics. Band 40, Nr. 03, Juli 2007, ISSN 1049-0965, S. 523–529, doi:10.1017/S1049096507070771 (cambridge.org [abgerufen am 12. Januar 2022]).
- Pankaj Gupta, Ashish Goel, Jimmy Lin, Aneesh Sharma, Dong Wang: WTF: the who to follow service at Twitter. In: Proceedings of the 22nd international conference on World Wide Web - WWW '13. ACM Press, Rio de Janeiro, Brazil 2013, ISBN 978-1-4503-2035-1, S. 505–514, doi:10.1145/2488388.2488433 (acm.org [abgerufen am 12. Januar 2022]).