Diskriminanzfunktion
Eine Diskriminanzfunktion oder Trennfunktion ist eine Funktion, die bei der Diskriminanzanalyse jeder Beobachtung einen Scorewert zuordnet. Aus dem Scorewert wird die Gruppenzugehörigkeit jeder Beobachtung und die Grenzen zwischen den Gruppen bestimmt. Bei bekannter Gruppenzugehörigkeit der Beobachtungen werden also die Merkmalsvariablen bei minimalen Informationsverlust zu einer einzigen Diskriminanzvariablen zusammengefasst.
Die Fisher’sche Diskriminanzfunktion ist die bekannteste Diskriminanzfunktion, die das Fisher’sche Kriterium realisiert. Sie wurde 1936 von R. A. Fisher entwickelt und beschreibt eine Metrik, die die Güte der Trennbarkeit zweier Klassen in einem Merkmalsraum misst und wurde 1936 von ihm in The use of multiple measurements in taxonomic problems veröffentlicht.
Einleitung
Gegeben seien d-dimensionale Merkmalsvektoren , von denen der Klasse und der Klasse angehören. Eine Diskriminanzfunktion beschreibt nun die Gleichung einer Hyperebene, die die Klassen optimal voneinander trennt. Davon gibt es, je nach Trennbarkeit der Klassen, lineare und nicht-lineare, was im folgenden Bild in zwei Dimensionen erläutert ist.






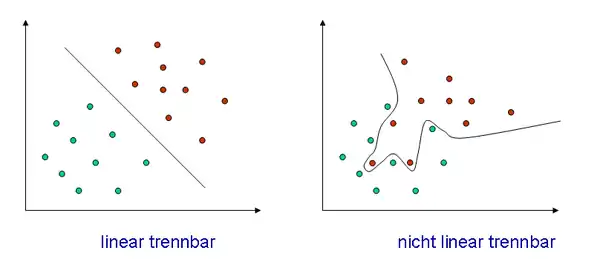
Beispiel
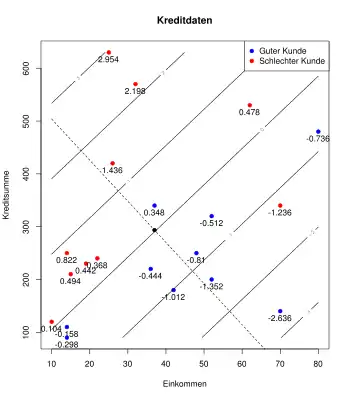
Die Grafik rechts zeigt gute (blau) und schlechte (rot) Kreditkunden einer Bank. Auf der x-Achse ist das Einkommen und auf der y-Achse die Kreditsumme der Kunden (in Tausend EUR) dargestellt. Die Diskriminanzfunktion ergibt sich zu
- .

Die parallelen schwarzen Linien von links unten nach rechts oben ergeben sich für .

Die Werte der Diskriminanzfunktion für jede Beobachtung sind unterhalb des Datenpunktes angegeben. Man sieht, dass die schlechten Kunden hohe Werte in der Diskriminanzfunktion haben während gute Kunden niedrige Werte erhalten. So könnte eine daraus abgeleitete Regel für neue Kunden sein:

Lineare Diskriminanzfunktion
Wie das einleitende Beispiel zeigt, suchen wir eine Richtung in den Daten, so dass die Gruppen bestmöglich voneinander getrennt werden. In der Grafik ist diese Richtung mit der gestrichelten Linie gekennzeichnet. Die gestrichelte und die schwarze Linie, die sich im schwarzen Punkt kreuzen bilden ein neues gedrehtes Koordinatensystem für die Daten.
Solche Drehungen werden mit Linearkombinationen der Merkmalsvariablen beschrieben. Die kanonische lineare Diskriminanzfunktion für Merkmalsvariablen ist daher gegeben durch:


mit der Diskriminanzvariable, 's die Merkmalsvariablen und die Diskriminanzkoeffizienten. Ähnlich zur multiplen linearen Regression werden die Diskriminanzkoeffizienten berechnet; jedoch wird nicht ein quadratischer Fehler für , sondern bzgl. eines Diskriminanzmaßes optimiert.



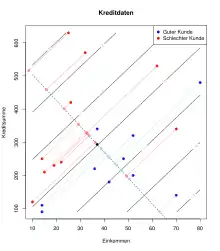
Für jede mögliche Richtung werden die Datenpunkte (rote und blaue Punkte) auf die gestrichelte Linie projiziert (hellblaue und hellrote Punkte). Dann werden die Gruppenmittelpunkte (für die hellroten und hellblauen Punkte) und das Gesamtmittel (schwarzer Punkt) bestimmt.
Zum einen wird nun der Abstand jedes hellroten bzw. hellblauen Punktes zu seinem Gruppenmittelpunkt bestimmt und diese quadrierten Abstände aufsummiert zu (Intravarianz, engl. within scatter). Je kleiner ist, desto näher liegen die projizierten Punkte an ihren Gruppenmittelpunkten.

Zum anderen wird für jeden hellroten und hellblauen Punkt der Abstand zwischen dem zugehörigen Gruppenmittelpunkt und dem Gesamtmittelpunkt und quadrierten Abstände aufsummiert zu (Intervarianz, engl. between scatter). Je größer ist, desto weiter liegen die Gruppenmittelwerte auseinander.

Daher wird die Richtung in den Daten so gewählt, dass

maximal ist. Je größer ist, desto deutlicher sind die Gruppen voneinander getrennt.

Fisher’sches Kriterium
Das Berechnen der optimal trennenden Hyperebene ist in zwei Dimensionen noch relativ einfach, wird jedoch in mehreren Dimensionen schnell zu einem komplexeren Problem. Daher bedient sich Fisher eines Tricks, der zunächst die Dimension reduziert und danach die Diskriminanzfunktion berechnet. Dazu werden die Daten in eine einzige Dimension projiziert, wobei die Projektionsrichtung von entscheidender Bedeutung ist.
Die Klassen sind viel besser voneinander getrennt, wenn die Merkmalsvektoren in Richtung projiziert sind, als in Richtung .


Um diese Tatsache formal zu schreiben, werden ein paar Definitionen benötigt.
Bezeichne den Mittelwert der Klasse und den Mittelwert des gesamten Merkmalsraumes.




heißt Intravarianz (englisch: within scatter) und misst die Varianz innerhalb der Klassen, während die Intervarianz (englisch: between scatter)

die Varianz zwischen den Klassen beschreibt. Die geeignetste Projektionsrichtung ist dann offensichtlich diejenige, die die Intravarianz der einzelnen Klassen minimiert, während die Intervarianz zwischen den Klassen maximiert wird.
Diese Idee wird mit dem Fisher’schen Kriterium anhand des Rayleigh-Quotienten mathematisch formuliert:

Mit diesem Kriterium wird die Güte der Trennbarkeit der Klassen im Merkmalsraum gemessen. Damit gilt dann, dass die Projektionsrichtung genau dann optimal ist (im Sinne der Trennbarkeit der Klassen), wenn maximal ist.


Die Erläuterungen lassen bereits erkennen, dass das Fisher'sche Kriterium nicht nur zu einer Diskriminanzfunktion, sondern auch zu einem Optimierungsverfahren für Merkmalsräume erweitert werden kann. Bei letzterem wäre ein Projektionsverfahren denkbar, das einen hochdimensionalen Merkmalsraum ähnlich der Hauptkomponentenanalyse in eine niedere Dimension projiziert und dabei gleichzeitig die Klassen optimal voneinander trennt.
Fisher’sche Diskriminanzfunktion
Eine Diskriminanzfunktion ordnet Objekte den jeweiligen Klassen zu. Mit dem Fisher’schen Kriterium kann bereits die optimale Projektionsrichtung, genauer gesagt der Normalenvektor der optimal trennenden Hyperebene, bestimmt werden. Es muss dann nur noch für jedes Objekt getestet werden, auf welcher Seite der Hyperebene es liegt.
Dazu wird das jeweilige Objekt zunächst auf die optimale Projektionsrichtung projiziert. Danach wird der Abstand zum Ursprung gegen einen vorher bestimmten Schwellwert getestet. Die Fisher’sche Diskriminanzfunktion ist demnach von folgender Form:


Ein neues Objekt wird nun je nach Ergebnis von entweder oder zugewiesen. Bei ist anwendungsabhängig zu entscheiden, ob überhaupt einer der beiden Klassen zuzuordnen ist.



Anzahl von Diskriminanzfunktionen
Zur Trennung von Klassen lassen sich maximal Diskriminanzfunktionen bilden, die orthogonal (d. h. rechtwinklig bzw. unkorreliert) sind. Die Anzahl der Diskriminanzfunktionen kann auch nicht größer werden als die Anzahl der Merkmalsvariablen, die zur Trennung der Klassen bzw. Gruppen verwendet werden:[1]


- .

Standardisierte Diskriminanzkoeffizienten
Wie bei der linearen Regression kann man auch mit Hilfe von Merkmalsvariablen, welche den größten Einfluss auf die Diskriminanzvariable haben, die standardisierten Diskriminanzkoeffizienten des Ziels herauszufinden. Dafür werden die Merkmalsvariablen standardisiert:



mit das arithmetische Mittel und die Standardabweichung. Danach werden die Koeffizienten neu berechnet:



und es gilt
- .

| Variable | Koeffizient | Stand. Koeffizient |
|---|---|---|
| Einkommen | 0,048 | 1,038 |
| Kreditsumme | −0,007 | −1,107 |
Wäre jetzt einer der standardisierten Koeffizienten aus dem Beispiel nahe Null, dann könnte man die Diskriminanzfunktion vereinfachen, wenn man diese Merkmalsvariable weglässt bei nur geringfügig geringerer Diskriminationskraft.
Beispiel
Ein einfacher Quader-Klassifikator soll anhand des Alters einer Person bestimmen, ob es sich um einen Teenager handelt oder nicht. Die Diskriminanzfunktion ist


Da der Merkmalsraum eindimensional ist (nur das Alter wird zur Klassifikation herangezogen), sind die Trennflächen-Punkte bei und . In diesem Fall muss vereinbart werden, dass die Trennflächen mit zur Klasse „Teenager“ gehören.


Einzelnachweise
- Backhaus, K., Erichson, B., Plinke, W., Weiber, R. (2008). Multivariate Analysemethoden. Eine anwendungsorientierte Einführung. Springer: Berlin, S. 200. ISBN 978-3-540-85044-1
Literatur
- R. Kraft: Diskriminanzanalyse. (PDF; 99 kB) Technische Universität München-Weihenstephan, 8. Juni 2000, abgerufen am 24. Oktober 2012.
- Christopher M. Bishop, Neural Networks for Pattern Recognition, Oxford University Press, 1995.
- Richard O. Duda and Peter E. Hart, Pattern Classification and Scene Analysis, Wiley-Interscience Publication, 1974.
- Keinosuke Fukunaga, Introduction to Statistical Pattern Recognition, Academic Press, 1990.