Logistische Regression
Unter logistischer Regression oder Logit-Modell versteht man Regressionsanalysen zur (meist multiplen) Modellierung der Verteilung abhängiger diskreter Variablen. Wenn logistische Regressionen nicht näher als multinomiale oder geordnete logistische Regressionen gekennzeichnet sind, ist zumeist die binomiale logistische Regression für dichotome (binäre) abhängige Variablen gemeint. Die unabhängigen Variablen können dabei ein beliebiges Skalenniveau aufweisen, wobei diskrete Variablen mit mehr als zwei Ausprägungen in eine Serie binärer Dummy-Variablen zerlegt werden.
Im binomialen Fall liegen Beobachtungen der Art vor, wobei eine binäre abhängige Variable (den so genannten Regressanden) bezeichnet, die mit , einem bekannten und festen Kovariablenvektor von Regressoren, auftritt. bezeichnet die Anzahl der Beobachtungen. Das Logit-Modell ergibt sich aus der Annahme, dass die Fehlerterme unabhängig und identisch Gumbel-verteilt sind. Eine Erweiterung der logistischen Regression stellt die ordinale logistische Regression dar; eine Variante dieser ist das kumulative Logit-Modell.




Motivation
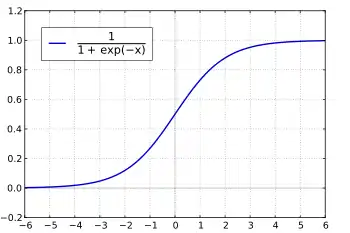
Die Einflüsse auf diskrete Variablen können nicht mit dem Verfahren der klassischen linearen Regressionsanalyse untersucht werden, da wesentliche Anwendungsvoraussetzungen, insbesondere eine Normalverteilung der Residuen und Homoskedastizität, nicht gegeben sind. Ferner kann ein lineares Regressionsmodell bei einer solchen Variablen zu unzulässigen Vorhersagen führen: Wenn man die beiden Ausprägungen der abhängigen Variablen mit 0 und 1 kodiert, so kann man zwar die Vorhersage eines linearen Regressionsmodells als Vorhersage der Wahrscheinlichkeit auffassen, dass die abhängige Variable den Wert 1 annimmt – formal: –, doch kann es dazu kommen, dass Werte außerhalb dieses Bereichs vorhergesagt werden. Die logistische Regression löst dieses Problem durch eine geeignete Transformation des Erwartungswerts der abhängigen Variablen .

Die Relevanz des Logit-Modells wird auch dadurch deutlich, dass Daniel McFadden und James Heckman im Jahr 2000 für ihren Beitrag zu seiner Entwicklung den Alfred-Nobel-Gedächtnispreis für Wirtschaftswissenschaften verliehen bekamen.
Anwendungsvoraussetzungen
Neben der Beschaffenheit der Variablen, wie sie in der Einleitung dargestellt wurde, gibt es eine Reihe von Anwendungsvoraussetzungen. So sollten die Regressoren keine hohe Multikollinearität aufweisen.
Modellspezifikation
Das (binomiale) logistische Regressionsmodell lautet
- ,

hierbei stellt den unbekannten Vektor der Regressionskoeffizienten dar und das Produkt ist der lineare Prädiktor.



Es geht von der Idee der Chancen (englisch odds) aus, d. h. dem Verhältnis von zur Gegenwahrscheinlichkeit bzw. (bei Kodierung der Alternativkategorie mit 0)



Die Chancen können zwar Werte größer 1 annehmen, doch ist ihr Wertebereich nach unten beschränkt (er nähert sich asymptotisch 0 an). Ein unbeschränkter Wertebereich wird durch die Transformation der Chancen in die sogenannten Logits

erzielt; diese können Werte zwischen minus und plus unendlich annehmen. Die Logits dienen als eine Art Kopplungsfunktion zwischen der Wahrscheinlichkeit und dem linearen Prädiktor. In der logistischen Regression wird dann die Regressionsgleichung

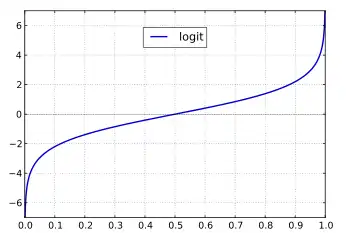
geschätzt; es werden also Regressionsgewichte bestimmt, nach denen die geschätzten Logits für eine gegebene Matrix von unabhängigen Variablen berechnet werden können. Die folgende Grafik zeigt, wie Logits (Ordinate) mit den Ausgangswahrscheinlichkeiten (Abszisse) zusammenhängen:

Die Regressionskoeffizienten der logistischen Regression sind nicht einfach zu interpretieren. Daher bildet man häufig die sogenannten Effektkoeffizienten durch Exponenzieren; die Regressionsgleichung bezieht sich dadurch auf die Chancen:

Die Koeffizienten werden oft auch als Effektkoeffizienten bezeichnet. Hier bezeichnen Koeffizienten kleiner 1 einen negativen Einfluss auf die Chancen, ein positiver Einfluss ist gegeben, wenn .


Durch eine weitere Transformation lassen sich die Einflüsse der logistischen Regression auch als Einflüsse auf die Wahrscheinlichkeiten ausdrücken:

Schätzmethode
Anders als bei der linearen Regressionsanalyse ist eine direkte Berechnung der besten Regressionskurve nicht möglich. Deshalb wird zumeist mit einem iterativen Algorithmus[1] eine Maximum-Likelihood-Lösung geschätzt.
Modelldiagnose
Die Regressionsparameter werden auf der Grundlage des Maximum-Likelihood-Verfahrens geschätzt. Inferenzstatistische Verfahren stehen sowohl für die einzelnen Regressionskoeffizienten als auch für das Gesamtmodell zur Verfügung (siehe Wald-Test und Likelihood-Quotienten-Test); in Analogie zum linearen Regressionsmodell wurden auch Verfahren der Regressionsdiagnostik entwickelt, anhand derer einzelne Fälle mit übergroßem Einfluss auf das Ergebnis der Modellschätzung identifiziert werden können. Schließlich gibt es auch einige Vorschläge zur Berechnung einer Größe, die in Analogie zum Bestimmtheitsmaß der linearen Regression eine Abschätzung der „erklärten Variation“ erlaubt; man spricht hier von sogenannten Pseudo-Bestimmtheitsmaßen. Auch das Informationskriterium nach Akaike und das bayessche Informationskriterium werden in diesem Kontext gelegentlich herangezogen.

Insbesondere bei Modellen zur Risikoadjustierung wird häufig der Hosmer-Lemeshow-Test zur Bewertung der Anpassungsgüte verwendet. Dieser Test vergleicht die vorhergesagten mit den beobachteten Raten von Ereignissen in nach Auftretenswahrscheinlichkeit geordneten Untergruppen der Grundgesamtheit, häufig den Dezilen. Die Teststatistik wird wie folgt berechnet:

Dabei repräsentieren die beobachteten (englisch observed) Ereignisse, die erwarteten (englisch expected) Ereignisse, die Anzahl der Beobachtungen und die Auftretenswahrscheinlichkeit der gten Quantile. Die Anzahl der Gruppen beträgt .




Ebenfalls wird die ROC-Kurve zur Beurteilung der Vorhersagekraft logistischer Regressionen verwendet, wobei die Fläche unter der ROC-Kurve (kurz: AUROC) als Gütekriterium fungiert.
Alternativen und Erweiterungen
Als (im Wesentlichen gleichwertige) Alternative kann das Probit-Modell herangezogen werden, bei dem eine Normalverteilung zugrunde gelegt wird.
Eine Übertragung der logistischen Regression (und des Probit-Modells) auf eine abhängige Variable mit mehr als zwei diskreten Merkmalen ist möglich (siehe Multinomiale logistische Regression oder Geordnete logistische Regression).
Literatur
- Hans-Jürgen Andreß, J.-A. Hagenaars, Steffen Kühnel: Analyse von Tabellen und kategorialen Daten. Springer, Berlin 1997, ISBN 3-540-62515-1.
- Dieter Urban: Logit Analyse. Lucius & Lucius, Stuttgart 1998, ISBN 3-8282-4306-1.
- David Hosmer, Stanley Lemeshow: Applied logistic regression. 2. Auflage. Wiley, New York 2000, ISBN 0-471-35632-8.
- Alan Agresti: Categorical Data Analysis. 2. Auflage. Wiley, New York 2002, ISBN 0-471-36093-7.
- Scott J. Long: Regression Models for Categorical and Limited Dependent Variables. Sage 1997, ISBN 0-8039-7374-8.
Weblinks
Einzelnachweise
- Paul David Allison: Logistic regression using the SAS system theory and application. SAS Institute, Cary NC 1999, S. 48.