Kernregression
Unter Kernregression (englisch kernel regression, daher auch Kernel-Regression) versteht man eine Reihe nichtparametrischer statistischer Methoden, bei denen die Abhängigkeit einer zufälligen Größe von Ausgangsdaten mittels Kerndichteschätzung geschätzt wird. Die Art der Abhängigkeit, dargestellt durch die Regressionskurve, wird im Gegensatz zur linearen Regression nicht als linear festgelegt. Der Vorteil ist eine bessere Anpassung an die Daten im Falle nichtlinearer Zusammenhänge. Abhängig davon, ob die Ausgangsdaten selbst zufällig sind oder nicht, unterscheidet man zwischen Random-Design- und Fixed-Design-Ansätzen. Das grundlegende Verfahren wurde 1964 unabhängig voneinander von Geoffrey Watson und Elisbar Nadaraia (englische Transkription: Elizbar Nadaraya) vorgeschlagen.
Eindimensionale Kernregression
Kerndichteschätzer
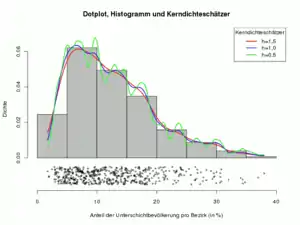
Ein Kerndichteschätzer zur Bandweite ist eine Schätzung der unbekannten Dichtefunktion einer Variablen. Ist eine Stichprobe, ein Kern, so ist die Kerndichteschätzung definiert als:





- .

Wie die Grafik rechts zeigt, ist die Wahl der Bandbreite entscheidend für die Qualität der Approximation.

| Typische Kerne mit | |||
|---|---|---|---|
| unbeschränktem Träger | Träger | ||
| Kern | Kern | ||
| Gauß-Kern | Gleichverteilungs- oder Rechteckskern | ||
| Cauchy-Kern | Dreieck-Kern | ||
| Picard-Kern | Kosinus-Kern | ||
Epanechnikov-Kern (p=1) quartischer Kern (p=2) Triweight-Kern (p=3) |
|||













Nadaraya-Watson-Schätzer
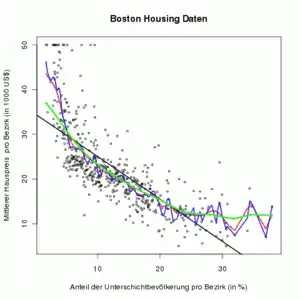
Der Nadaraya-Watson-Schätzer schätzt eine unbekannte Regressionsfunktion aus den Beobachtungsdaten als[1][2]



mit und einem Kern und einer Bandweite . Die Funktion ist dabei eine Funktion, die Beobachtungen nahe ein großes Gewicht und Beobachtungen weit entfernt von ein kleines Gewicht zuordnet. Die Bandweite legt fest, in welchem Bereich um die Beobachtungen ein großes Gewicht haben.



Während die Wahl des Kerns meist recht frei erfolgen kann, hat die Wahl der Bandweite einen großen Einfluss auf die Glattheit des Schätzers. Die Grafik rechts zeigt, dass eine große Bandweite (grün) zu einer glatteren Schätzung führt als die Wahl einer kleinen Bandweite (blau).
Ableitung
Die Idee des Nadaraya-Watson-Schätzers beruht darauf, dass die unbekannte Regressionsfunktion

mit Hilfe des bedingten Erwartungswertes durch die gemeinsame Dichte und die Randdichte dargestellt wird.



Die unbekannten Dichten und werden mit Hilfe einer Kerndichteschätzung geschätzt. Zur Berechnung der gemeinsamen Dichte aus den Beobachtungen wird ein bivariater Kerndichteschätzer mit Produktkern und Bandweiten und genutzt:


- .

Es folgt

und mittels Kerndichteschätzung für der Nadaraya-Watson-Schätzer.
Eigenschaften
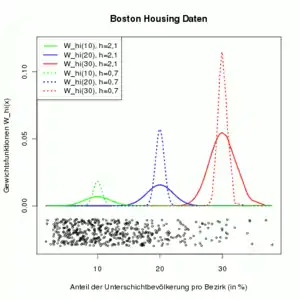


1. Wie im Fall der linearen Regression kann der Nadaraya-Watson-Schätzer auch als Linearkombination der mit Gewichtsfunktionen geschrieben werden:


- .

Damit ist der Nadaraya-Watson-Schätzer das (lokal) gewichtete Mittel der Beobachtungswerte , es gilt
- .

Die Grafik rechts zeigt die Gewichte für verschiedene Werte von (blau: , grün: , rot: ). Das Punktdiagramm unterhalb von Null zeigt die Daten der erklärenden Variable. Je größer die Bandweite ist (durchgezogene Linie vs. gestrichelte Linie), desto mehr Beobachtungen um haben ein Gewicht ungleich null. Je weniger Daten zu Verfügung stehen (rechts), desto stärker müssen die verfügbaren Beobachtungen gewichtet werden.



2. Die mittlere quadratische Abweichung ergibt sich approximativ als

mit und unabhängig von und . Damit ist die Konvergenz langsamer als bei der linearen Regression, d. h. mit der gleichen Zahl von Beobachtungen kann der Vorhersagewert in der linearen Regression präziser geschätzt werden als beim Nadaraya-Watson-Schätzer.



Dabei ist die quadrierte Verzerrung (englisch bias) des Nadaraya-Watson-Schätzers

mit und die erste bzw. zweite Ableitung der unbekannten Regressionsfunktion, die erste Ableitung der Dichte und .





mit und .


Bandweitenwahl
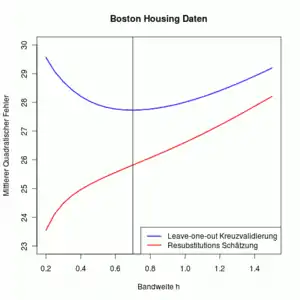

Das Hauptproblem bei der Kernregression ist die Wahl einer geeigneten Bandweite . Als Basis dient die Minimierung der mittleren quadratische Abweichung

bzw. deren Approximation. Die Approximation enthält jedoch die zweite Ableitung der unbekannten Regressionsfunktion sowie die unbekannte Dichtefunktion und deren Ableitung. Stattdessen wird die datenbasierten gemittelte quadratische Abweichung

minimiert. Da zur Schätzung von der Wert von genutzt wird, führt eine Bandweite zu einem (Resubstitution Schätzung). Daher wird eine Leave-One-Out-Kreuzvalidierung durchgeführt, d. h. zur Berechnung des Schätzwertes werden alle Beobachtungen herangezogen außer der i-ten. Damit wird der für verschiedene Bandweiten berechnet. Die Bandweite, die einen minimalen ASE ergibt, wird dann zur Schätzung der unbekannten Regressionsfunktion genommen.





Konfidenzbänder
Nach der Schätzung der Regressionsfunktion stellt sich die Frage, wie weit diese von der wahren Funktion abweicht. Die Arbeit von Bickel und Rosenblatt (1973)[3] liefert zwei Theoreme für punktweise Konfidenzbänder und gleichmäßige Konfidenzbänder.
Neben der Information über die Abweichung zwischen und liefern die Konfidenzbänder einen Hinweis darauf, ob ein mögliches parametrisches Regressionsmodell, z. B. eine lineare Regression, zu den Daten passt. Liegt der geschätzte Verlauf der Regressionsfunktion des parametrischen Regressionsmodells außerhalb der Konfidenzbänder, so ist dies ein Hinweis darauf, dass das parametrische Regressionsmodell nicht zu den Daten passt. Ein formaler Test ist mit Hilfe von Bootstrapping-Verfahren möglich.
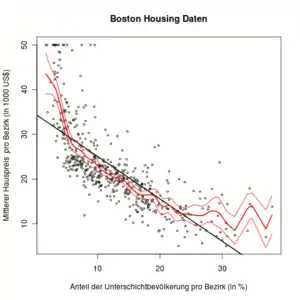
Punktweise Konfidenzbänder: Unter bestimmten Voraussetzungen konvergiert in Verteilung

mit , und .



Wenn die Bandweite klein genug ist, dann kann die asymptotische Verzerrung vernachlässigt werden gegen die asymptotische Varianz . Damit können approximative Konfidenzbänder berechnet werden




mit das Quantil der Standardnormalverteilung. Die unbekannte Dichte wird dabei mit einer Kerndichteschätzung geschätzt und mit





- .

Die Grafik rechts zeigt den Nadaraya-Watson-Schätzer mit punktweisen 95% Konfidenzband (rote Linien). Die schwarze lineare Regressionsgerade liegt in verschiedenen Bereichen deutlich außerhalb der Konfidenzbandes. Dies ist ein Hinweis darauf, dass ein lineares Regressionsmodell hier nicht angemessen ist.
Gleichmäßige Konfidenzbänder: Unter etwas stärkeren Voraussetzungen als zuvor und mit , mit und für Kerne mit Träger in konvergiert




mit
- .

Die Bedingung ist keine Einschränkung, da die Daten erst auf das Intervall transformiert werden können. Danach wird das Konfidenzband berechnet und wieder zurücktransformiert auf die Originaldaten.


Gasser-Müller-Schätzer
Im Fixed-Design-Fall mit ist die Dichte bekannt, muss also nicht geschätzt werden. Dies vereinfacht sowohl die Berechnungen als auch die mathematische Behandlung des Schätzers. Für diesen Fall wurde der Gasser-Müller-Schätzer definiert als[4]


mit

und , und .



Eigenschaften
1. Der Gasser-Müller Schätzer ist wie der Nadaraya-Watson-Schätzer ein linearer Schätzer und die Summe der Gewichtsfunktionen ist eins.
2. Für die mittlere quadratische Abweichung gilt:
- .

Lokal polynomiale Kernregression
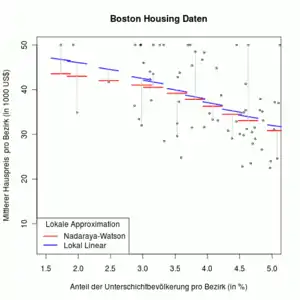

Der Nadaraya-Watson Schätzer kann als Lösung des folgenden lokalen Minimierungsproblem geschrieben werden:
- ,

d .h. für jedes wird ein lokal konstanter Wert bestimmt, der gleich dem Wert des Nadaraya-Watson Schätzer an der Stelle ist.

Anstelle einer lokalen Konstanten kann auch ein Polynom verwendet werden:
- ,

d. h. der unbekannten Regressionswert wird durch ein lokales Polynom approximiert. Die lokal polynomiale Kernregression ergibt sich an jeder Stelle durch

- .

Die Grafik rechts zeigt an ausgewählten Stellen die verwendeten lokalen Polynome. Der Nadaraya-Watson Schätzer (rot) nutzt lokal konstanten Funktionen . Die lokal lineare Kernregression (blau) nutzt lokal lineare Funktionen an der Stelle . Die ausgewählten Stellen sind in der Grafik mit Datenpunkten identisch. Die senkrechten grauen Linien verbinden die lokalen Polynome mit dem zugehörigen x-Wert (Datenpunkt). Der Schnittpunkt mit dem roten bzw. blauen Polynom ergibt den Schätzwert an der entsprechenden Stelle für den Nadaraya-Watson Schätzer und die lokal lineare Kernregression.

Vorteile und Eigenschaften
Die lokal polynomiale Regression bietet gegenüber dem Nadaraya-Watson Schätzer einige Vorteile:
- Im Allgemeinen wird das lokal konstante von Beobachtungswerten beeinflusst die sowohl links als auch rechts vom Wert liegen. An den Rändern funktioniert das jedoch nicht und dies führt zu Randeffekten (englisch boundary effects). Die lokal polynomiale Kernregression approximiert jedoch lokal mit einem Polynom und kann dieses Problem vermeiden.
- Um die te Ableitung zu schätzen, könnte man einfach den Nadaraya-Watson entsprechend oft ableiten. Mit der lokal polynomialen Kernregression ergibt sich jedoch ein deutlich eleganterer Weg:

- Meist wird oder benutzt. Ungerade Ordnungen sind besser als gerade Ordnungen.




- Wie im Fall der linearen Regression und des Nadaraya-Watson-Schätzer kann auch die lokal polynomiale Kernregression auch als Linearkombination der mit Gewichtsfunktionen geschrieben werden:

- .

Schätzung der Regressionsparameter
Definiert man die folgenden Matrizen:
- ,


und

so ergeben sich die Schätzung der Regressionsparameter als

- .

Die für die Ableitung notwendigen Koeffizienten werden im Schätzverfahren also automatisch mit berechnet!
Um die Schätzung praktisch durchzuführen, berechnet man


und berechnet

Lokal lineare Kernregression
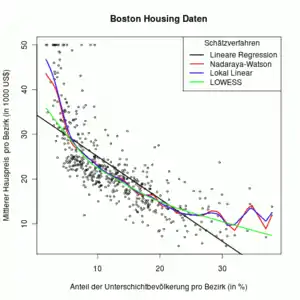
Eines der bekanntesten lokal linearen Regressionsmodelle () ist der lokal gewichtete Regression-Streudiagramm-Glätter, abgekürzt mit LOESS oder veraltet LOWESS (englisch für locally weighted scatterplot smoothing, deutsch lokal gewichtete Streudiagrammglättung).[5] Der LOWESS ist jedoch keine lokal-lineare Kernregression, denn

- die Regressionsgewichte werden robust geschätzt und
- die Bandweite variiert mit .
Die Grafik rechts zeigt zwei verschiedene Methoden der Kernregression: Lokal konstant (rot, Nadaraya-Watson) und lokal linear (blau). Insbesondere an den Rändern approximiert die lokal lineare Kernregression die Daten etwas besser.
Die lokal lineare Kernregression ergibt sich als
- .

Die mittlere quadratische Abweichung der lokal linearen Regression ergibt sich, wie beim Nadaraya-Watson-Schätzer, als

mit

und die Varianz ist identisch zur Varianz des Nadaraya-Watson-Schätzers . Die einfachere Form der Verzerrung macht die lokal lineare Kernregression attraktiver für praktische Zwecke.

Einzelnachweise
- Elizbar A. Nadaraya: On estimating regression. In: Theory of Probability and its Applications. Band 9, Nr. 1, 1964, S. 141–142, doi:10.1137/1109020.
- Geoffrey S. Watson: Smooth Regression Analysis. In: Sankhyā: The Indian Journal of Statistics, Series A. Band 26, Nr. 4, Dezember 1964, S. 359–372.
- Bickel, Rosenblatt (1973) On some global measures of the deviations of density function estimators, Annals of Statistics 1, S. 1071–1095
- Theo Gasser, Hans-Georg Müller: Estimating Regression Functions and Their Derivatives by the Kernel Method. In: Scandinavian Journal of Statistics. Band 11, Nr. 3, 1984, S. 171–185.
- W.S. Cleveland: Robust Locally Weighted Regression and Smoothing Scatterplots. In: Journal of the American Statistical Association. Band 74, Nr. 368, Dezember 1979, S. 829–836, JSTOR:2286407.
Literatur
- Jianqing Fan, Irene Gijbels: Local Polynomial Modelling and Its Applications. Chapman and Hall/CRC, 1996, ISBN 978-0-412-98321-4.
- Wolfgang Härdle, Marlene Müller, Stefan Sperlich, Axel Werwatz: Nonparametric and Semiparametric Models. Springer Verlag, Berlin, Heidelberg 2004, ISBN 978-3-540-20722-1 (hu-berlin.de).
- Tristen Hayfield, Jeffrey S. Racine: Nonparametric Econometrics: The np Package. In: Journal of Statistical Software. Band 27, Nr. 5, 2008 (jstatsoft.org).
- M.P. Wand, M.C. Jones: Kernel Smoothing. Chapman and Hall/CRC, 1994, ISBN 978-0-412-55270-0.