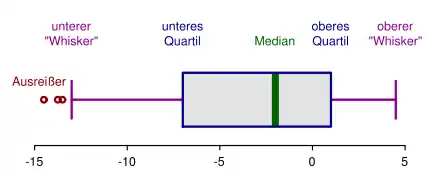
Ausreißer
In der Statistik spricht man von einem Ausreißer, wenn ein Messwert oder Befund nicht in eine erwartete Messreihe passt oder allgemein nicht den Erwartungen entspricht. Die „Erwartung“ wird meistens als Streuungsbereich um den Erwartungswert herum definiert, in dem die meisten aller Messwerte zu liegen kommen, z. B. der Quartilabstand Q75 – Q25. Werte, die weiter als das 1,5-Fache des Quartilabstandes außerhalb dieses Intervalls liegen, werden (meist willkürlich) als Ausreißer bezeichnet.[1] Im Boxplot werden besonders hohe Ausreißer gesondert dargestellt. Die robuste Statistik beschäftigt sich mit der Ausreißerproblematik. Auch im Data-Mining beschäftigt man sich mit der Erkennung von Ausreißern. Von Ausreißern zu unterscheiden sind einflussreiche Beobachtungen.
Überprüfung auf Messfehler
Entscheidend ist es dann, zu überprüfen, ob es sich bei dem Ausreißer tatsächlich um ein verlässliches und echtes Ergebnis handelt, oder ob ein Messfehler vorliegt.
- Beispiel: So wurde das Ozonloch über der Antarktis einige Jahre zwar bereits gemessen, die Messwerte aber als offensichtlich falsch gemessen bewertet (d. h. als „Ausreißer“ interpretiert und ignoriert) und dadurch nicht in ihrer Tragweite erkannt.[2]
Ausreißertests
Ein anderer Ansatz wurde u. a. von Ferguson im Jahr 1961 vorgeschlagen.[3] Danach wird davon ausgegangen, dass die Beobachtungen aus einer hypothetischen Verteilung stammen. Ausreißer sind dann Beobachtungen, die nicht aus der hypothetischen Verteilung stammen. Die folgenden Ausreißertests gehen alle davon aus, dass die hypothetische Verteilung eine Normalverteilung ist und prüfen, ob einer oder mehrere der Extremwerte nicht aus der Normalverteilung stammen:
- Ausreißertest nach Grubbs
- Ausreißertest nach Nalimov
- Ausreißertest nach David, Hartley und Pearson
- Ausreißertest nach Dixon
- Ausreißertest nach Hampel
- Ausreißertest nach Baarda
- Ausreißertest nach Pope
Der Ausreißertest nach Walsh basiert hingegen nicht auf der Annahme einer bestimmten Verteilung der Daten. Im Rahmen der Zeitreihenanalyse können Zeitreihen, bei denen ein Ausreißer vermutet wird, darauf getestet werden und dann mit einem Ausreißermodell modelliert werden.
Unterschiede zu Extremwerten
Ein beliebter Ansatz ist es, den Boxplot zu nutzen, um „Ausreißer“ zu identifizieren. Die Beobachtungen außerhalb der Whisker werden dabei willkürlich als Ausreißer bezeichnet. Für die Normalverteilung kann man leicht ausrechnen, dass knapp 0,7 % der Masse der Verteilung außerhalb der Whiskers liegen. Bereits ab einem Stichprobenumfang von würde man daher (im Mittel) mindestens eine Beobachtung außerhalb der Whiskers erwarten (oder auch Beobachtungen außerhalb der Whiskers bei ). Sinnvoller ist es daher zunächst, statt von Ausreißern von Extremwerten zu sprechen.



Multivariate Ausreißer

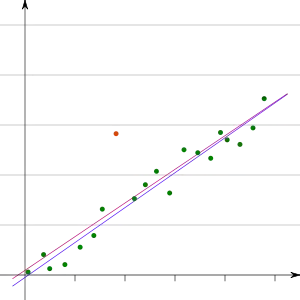
In mehreren Dimensionen wird die Situation noch komplizierter. In der Grafik rechts kann der Ausreißer rechts unten in der Ecke nicht durch Inspektion jeder einzelnen Variablen erkannt werden; er ist in den Boxplots nicht sichtbar. Trotzdem wird er eine lineare Regression deutlich beeinflussen.
Andrews Kurven
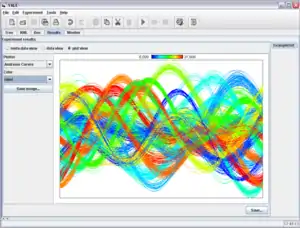
Andrews (1972) schlug vor jede multivariate Beobachtung durch eine Kurve zu repräsentieren:[4]


Damit wird jede multivariate Beobachtung auf eine zweidimensionale Kurve im Intervall abgebildet. Aufgrund der Sinus- und Kosinusterme wiederholt sich die Funktion außerhalb des Intervalls .


Für jeweils zwei Beobachtungen und gilt:



Die Formel (1) links neben dem Gleichheitszeichen entspricht (zumindest approximativ) der Fläche zwischen den beiden Kurven, und die Formel (2) rechts ist (zumindest approximativ) der multivariante euklidische Abstand zwischen den beiden Datenpunkten.
Ist also der Abstand zwischen zwei Datenpunkten klein, dann muss auch die Fläche zwischen den Kurven klein sein, d. h., die Kurven und müssen nahe beieinander verlaufen. Ist jedoch der Abstand zwischen zwei Datenpunkten groß, muss auch die Fläche zwischen den Kurven groß sein, d. h., die Kurven und müssen sehr unterschiedlich verlaufen. Ein multivariater Ausreißer würde als Kurve sichtbar, die sich von allen anderen Kurven in ihrem Verlauf deutlich unterscheidet.

Andrews Kurven haben zwei Nachteile:
- Wenn der Ausreißer in genau einer Variablen sichtbar ist, nimmt der Mensch die unterschiedlichen Kurven umso besser wahr, je weiter vorn diese Variable auftaucht. Am besten sollte sie die Variable sein. D. h., es bietet sich an, die Variablen zu sortieren, z. B. wird die Variable mit der größten Varianz, oder man nimmt die erste Hauptkomponente.
- Wenn man viele Beobachtungen hat, müssen viele Kurven gezeichnet werden, sodass der Verlauf einer einzelnen Kurve nicht mehr sichtbar ist.

Stahel-Donoho Outlyingness
Stahel (1981) und David Leigh Donoho (1982) definierten die sog. Outlyingness, um eine Maßzahl dafür zu erhalten, wie weit ein Beobachtungswert von der Masse der Daten entfernt liegt.[5][6] Durch die Berechnung aller möglichen Linearkombinationen , d. h. die Projektion des Datenpunktes auf den Vektor , mit ergibt sich die Outlyingness



- ,

wobei der Median der projizierten Punkte und die mittlere absolute Abweichung der projizierten Punkte, als robustes Streuungsmaß. Der Median dient dabei als robustes Lage-, die mittlere absolute Abweichung als robustes Streuungsmaß. ist eine Normalisierung.



In der Praxis wird die Outlyingness berechnet, indem für mehrere hundert oder tausend zufällig ausgewählte Projektionsrichtungen das Maximum bestimmt wird.
Ausreißererkennung im Data-Mining
Unter dem englischen Begriff Outlier Detection (deutsch: Ausreißererkennung) versteht man den Teilbereich des Data-Mining, bei dem es darum geht, untypische und auffällige Datensätze zu identifizieren. Anwendung hierfür ist beispielsweise die Erkennung von (potentiell) betrügerischen Kreditkartentransaktionen in der großen Menge der validen Transaktionen. Die ersten Algorithmen zur Outlier Detection waren eng an den hier erwähnten statistischen Modellen orientiert, jedoch haben sich aufgrund von Berechnungs- und vor allem Laufzeitüberlegungen die Algorithmen seither davon entfernt.[7] Ein wichtiges Verfahren hierzu ist der dichtebasierte Local Outlier Factor.
Siehe auch
Literatur
- R. Khattree, D. N. Naik: Andrews Plots for Multivariate Data: Some New Suggestions and Applications. In: Journal of Statistical Planning and Inference. Band 100, Nr. 2, 2002, S. 411–425, doi:10.1016/S0378-3758(01)00150-1.
Weblinks
- Grundlagen der Statistik Ausreißertests
- Learning by Simulations Simulation der Auswirkung eines Ausreißers auf die lineare Regression
Einzelnachweise
- Volker Müller-Benedict: Grundkurs Statistik in den Sozialwissenschaften. 4., überarbeitete Auflage. VS Verlag für Sozialwissenschaften, Wiesbaden 2007, ISBN 978-3-531-15569-2, S. 99.
- Karl-Heinz Ludwig: Eine kurze Geschichte des Klimas: Von der Entstehung der Erde bis heute. 2. Auflage. Beck Verlag 2007, ISBN 978-3-406-56557-1, S. 149.
- T. S. Ferguson: On the Rejection of outliers. In: Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability. Band 1, 1961, S. 253–287 (projecteuclid.org [PDF]).
- D. Andrews: Plots of high-dimensional data. In: Biometrics. 28, 1972, S. 125–136, JSTOR 2528964.
- W. A. Stahel: Robuste Schätzungen: infinitesimale Optimalität und Schätzungen von Kovarianzmatrizen. PhD thesis, ETH Zürich, 1981.
- D. L. Donoho: Breakdown properties of multivariate location estimators. Qualifying paper, Harvard University, Boston 1982.
- H.-P. Kriegel, P. Kröger, A. Zimek: Outlier Detection Techniques. Tutorial. In: 13th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2009). Bangkok, Thailand 2009 (lmu.de [PDF; abgerufen am 26. März 2010]).