Verzerrung-Varianz-Dilemma
Das Verzerrung-Varianz-Dilemma (häufig auch englisch bias-variance tradeoff) beschreibt das Problem der gleichzeitigen Minimierung zweier Fehlerquellen: der Verzerrung und der Varianz. Es erschwert das Verallgemeinern von Trainingsdaten durch überwachte Lernalgorithmen.
- Die Verzerrung ist der Fehler ausgehend von falschen Annahmen im Lernalgorithmus. Eine hohe Verzerrung kann einen Algorithmus dazu veranlassen, nicht die entsprechenden Beziehungen zwischen Eingabe und Ausgabe zu modellieren (Unteranpassung).
- Die Varianz ist der Fehler ausgehend von der Empfindlichkeit auf kleinere Schwankungen in den Trainingsdaten. Eine hohe Varianz verursacht Überanpassung: es wird das Rauschen in den Trainingsdaten statt der vorgesehenen Ausgabe modelliert.
Die Verzerrung-Varianz-Zerlegung bietet die Möglichkeit, den erwarteten Fehler eines Lernalgorithmus im Hinblick auf ein bestimmtes Problem zu analysieren, und kann als Summe aus drei Termen dargestellt werden: Der Verzerrung, der Varianz und einem irreduziblen Fehler (siehe auch Bayes-Fehler), resultierend aus dem Rauschen innerhalb des Problems selbst.
Das Verzerrung-Varianz-Dilemma gilt für alle Formen des überwachten Lernens: Klassifikation, Regression,[1][2] und strukturiertes Lernen.
Das Dilemma betrifft die Bereiche Statistik und des maschinellen Lernens. Es wurde auch genutzt, um die Wirksamkeit von Heuristiken beim menschlichen Lernen zu erklären.
Motivation
Das Verzerrung-Varianz-Dilemma ist ein zentrales Problem beim überwachten Lernen. Idealerweise möchte man ein Modell wählen, das sowohl die Gesetzmäßigkeiten in den Trainingsdaten genau erfasst, als auch sich auf ungesehene Testdaten generalisieren lässt. Leider ist es in der Regel unmöglich, beides gleichzeitig zu tun. Lernmethoden mit hoher Varianz können möglicherweise ihre Trainingsdaten gut darstellen, aber riskieren Überanpassung bei zu rauschbehafteten oder nicht repräsentativen Trainingsdaten. Im Gegensatz dazu erzeugen Algorithmen mit einer hohen Verzerrung typischerweise einfachere Modelle, die nicht zur übermäßigen Überanpassung neigen, aber möglicherweise ihre Trainingsdaten nicht hinreichend gut modellieren und wichtige Gesetzmäßigkeiten nicht erfassen.
Modelle mit hoher Varianz sind in der Regel komplexer (z. B. Regression mit Polynomen höherer Ordnung), was ihnen erlaubt die Trainingsdaten genauer darzustellen. Dabei stellen sie unter Umständen auch einen Großteil des Rauschens in den Trainingsdaten dar, so dass ihre Vorhersagen weniger genau werden – trotz ihrer zusätzlichen Komplexität. Dagegen neigen Modelle mit höherer Verzerrung in der Regel dazu relativ einfach zu sein (z. B. Regression mit Polynomen niedriger Ordnung oder einfache lineare Regression), aber können Vorhersagen mit niedrigerer Varianz produzieren, wenn sie über die Trainingsdaten hinaus auf neue Daten angewendet werden.
Verzerrung-Varianz-Zerlegung der quadratischen Abweichung
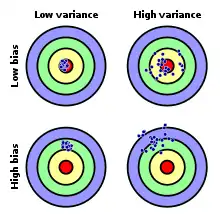
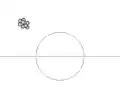
In folgenden Bildern sind verschiedene Verteilungen dargestellt:
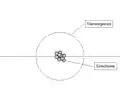
 Richtigkeit schlecht,
Richtigkeit schlecht,
Varianz gut:
Genauigkeit schlecht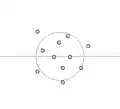 Richtigkeit gut,
Richtigkeit gut,
Varianz schlecht:
Genauigkeit schlecht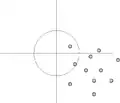 Richtigkeit schlecht,
Richtigkeit schlecht,
Varianz schlecht:
Genauigkeit schlecht Verteilung der Datendichte; Unterscheidung der Abweichungen vom richtigen Wert
Verteilung der Datendichte; Unterscheidung der Abweichungen vom richtigen Wert
Das Verzerrungs-Varianz-Dilemma liegt vor, wenn die Varianz klein ist, aber die Richtigkeit schlecht ist (hohe Verzerrung), bzw. die Varianz hoch ist und die Richtigkeit gut ist (kleine Verzerrung).
Gegeben seien Trainingsdaten, bestehend aus einer Menge von Punkten mit dazugehörigen reellen Werten . Es wird angenommen, dass es zwischen und einen funktionellen, aber rauschbehafteten Bezug gibt, der durch beschrieben wird, wobei der Rauschterm normalverteilt ist und Erwartungswert Null und Varianz besitzt.







Nun soll mit Hilfe eines Lernalgorithmus eine Funktion gefunden werden, die die wahre Funktion so gut wie möglich annähert. Die Genauigkeit dieser Approximation wird anhand der mittleren quadratischen Abweichung zwischen und gemessen: dabei soll sowohl für als auch für Punkte außerhalb der Stichprobe minimiert werden. Eine optimale Annäherung ist unmöglich, da vom Rauschen beeinflusst wird. Dies bedeutet, dass für jede Funktion, die gefunden wird, ein irreduzibler Fehler akzeptiert werden muss.




Die Ermittlung einer Funktion , die sich auf Punkte außerhalb der Trainingsdaten verallgemeinern lässt, geschieht mit einem der vielen Algorithmen, die zum überwachten Lernen genutzt werden. Es stellt sich heraus, dass abhängig von der Wahl der Funktion die erwartete Abweichung bezüglich einer ungesehenen Stichprobe wie folgt zerlegt werden kann:[3]:34[4]:223



Hierbei beschreibt

die Verzerrung der Lernmethode und

ihre Varianz. Der Erwartungswert variiert bei verschiedenen Trainingsdaten , die von der gleichen Verteilung stammen. Die drei Terme repräsentieren:

- das Quadrat der Verzerrung der Lernmethode, welcher als Fehler, verursacht durch vereinfachende Annahmen innerhalb des Verfahrens, interpretiert werden kann. Falls beispielsweise eine nichtlineare Funktion unter Verwendung eines Lernverfahrens für lineare Modelle approximiert wird, gibt es aufgrund einer solchen Annahme Fehler in den Schätzungen .
- die Varianz der Lernmethode. Intuitiv beschreibt dies die Schwankungsbreite der Lernmethode um ihren Erwartungswert.
- den irreduziblen Fehler . Da alle drei Terme nicht negativ sind, stellt dieser Fehler eine untere Schranke für die erwartete Abweichung auf ungesehenen Testdaten dar.[3]:34

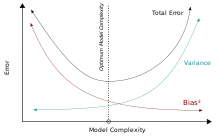
Je komplexer die Modellfunktion ist, desto mehr Datenpunkte wird sie richtig erfassen und desto geringer wird ihre Verzerrung sein. Allerdings lässt eine höhere Komplexität die Modellfunktion mehr schwanken, um die Datenpunkte besser zu erfassen, was somit ihre Varianz vergrößert.
Herleitung
Die Herleitung der Verzerrung-Varianz-Zerlegung für quadratische Abweichungen läuft folgendermaßen ab.[5][6] Abkürzend wird im Folgenden und geschrieben. Nach dem Verschiebungssatz gilt für jede Zufallsvariable




Da deterministisch ist, gilt . Zusammen mit den Annahmen und impliziert dies




- .

Da gilt, folgt

- .

Folglich ergibt sich, da und unabhängig sind,

Anwendung zur Klassifizierung
Die Verzerrung-Varianz-Zerlegung wurde ursprünglich für die Regressionsanalyse als Methode der kleinsten Quadrate formuliert. Für den Fall der Klassifizierung ist es möglich, eine ähnliche Zerlegung zu finden.[7][8] Wenn das Klassifikationsproblem alternativ als probabilistischer Klassifikator formuliert werden kann, so lässt sich die erwartete quadratische Abweichung der vorhergesagten Wahrscheinlichkeiten in Bezug auf die wahren Wahrscheinlichkeiten wie zuvor zerlegen.[9]
Ansätze zur Problemlösung
Dimensionsreduktion und Feature Selection können die Varianz durch Modellvereinfachung verringern. Ebenso neigt ein größerer Satz an Trainingsdaten dazu, die Varianz zu verringern. Das Hinzufügen von Features (Prädiktoren) verringert die Verzerrung, auf Kosten der zusätzlichen erhöhten Varianz. Lernalgorithmen haben in der Regel einige Parameter, um die Verzerrung sowie Varianz zu steuern:
- (Generalisierte) lineare Modelle können regularisiert werden, um ihre Verzerrung zu erhöhen (und somit die Varianz zu verringern).
- In künstlichen neuronalen Netzen nimmt mit der Anzahl der versteckten Knoten die Varianz zu und die Verzerrung ab.[1] Wie in GLMs wird typischerweise Regularisierung eingesetzt.
- In k-nächsten-Nachbarn Modellen führt ein hoher Wert von k zu niedriger Varianz und hoher Verzerrung (siehe unten).
- Im Falle des gedächtnisbasierten Lernens kann Regularisierung durch die Kombination von Prototypenmethoden und Nächste-Nachbarn-Methoden erreicht werden.[10]
- In Entscheidungsbäumen bestimmt die Tiefe des Baumes die Varianz. Entscheidungsbäume werden häufig beschnitten, um die Varianz zu kontrollieren.[3]:307
Eine Möglichkeit zur Lösung des Dilemmas ist es, Modelle mit Mischverteilung und eine Kombination verschiedener Lernalgorithmen zu nutzen.[11][12] Beispielsweise vereint Boosting viele „schwache“ Modelle (mit hoher Verzerrung) zu einem neuen Modell, das größere Varianz als die einzelnen Modelle hat. Dahingegen kombiniert Bagging „starke“ Klassifikatoren (mit hoher Varianz) in einer Weise, die die Varianz des neu konstruierten Klassifikators reduziert.
K-nächste Nachbarn
Im Falle des k-nächste-Nachbarn-Algorithmus existiert eine geschlossene Formel, die die Verzerrung-Varianz-Zerlegung in Relation zum Parameter setzt:[4]:37, 223


wobei die nächsten Nachbarn von innerhalb der Trainingsdaten beschreiben. Die Verzerrung (erster Term) ist eine in monoton steigende Funktion, während die Varianz (zweiter Term) fällt, falls erhöht wird. Tatsächlich verschwindet unter „vernünftigen Annahmen“ die Verzerrung des 1-nächster-Nachbarn Schätzers vollständig, wenn die Größe des Trainingsdatensatzes gegen unendlich strebt.[1]

Anwendung auf das menschliche Lernen
Während das Verzerrung-Varianz-Dilemma großteils im Bereich des maschinellen Lernens angewendet wird, ist es auch im Zusammenhang mit menschlicher Wahrnehmung untersucht worden, vor allem durch Gerd Gigerenzer und Kollegen im Bereich gelernter Heuristiken. Sie argumentieren, dass das menschliche Gehirn das Dilemma im Falle spärlicher und schlecht charakterisierter Trainingsdaten mittels Erfahrungen löst, die durch Heuristiken mit hoher Verzerrung und niedriger Varianz gewonnen werden. Dies spiegelt die Tatsache wider, dass ein Ansatz mit einer Verzerrung gleich Null eine schlechte Generalisierbarkeit auf neue Situationen aufweist und genaue Kenntnis des wahren Zustandes der Welt voraussetzt. Die resultierenden Heuristiken sind relativ einfach, liefern aber bessere Erklärungen bei einer größeren Anzahl von Situationen.[13]
Nach Geman und anderen[1] impliziert das Verzerrung-Varianz-Dilemma, dass Fähigkeiten wie generische Objekterkennung nicht von Grund auf neu erlernt werden können, sondern ein gewisses Maß an vorhandener „Vernetzung“ erfordern, die später durch Erfahrung angepasst wird. Dies liegt daran, dass modellfreie Ansätze, die eine hohe Varianz vermeiden möchten, zur Erklärung unpraktisch große Trainingsdatensätze erfordern.
Einzelnachweise
- Stuart Geman, E. Bienenstock, R. Doursat: Neural networks and the bias/variance dilemma. In: Neural Computation. 4, 1992, S. 1–58. doi:10.1162/neco.1992.4.1.1.
- Bias–variance decomposition. In: Encyclopedia of Machine Learning. Eds. Claude Sammut, Geoffrey I. Webb. Springer 2011. S. 100–101.
- Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani: An Introduction to Statistical Learning. Springer, 2013 (online).
- Trevor Hastie, Robert Tibshirani, JeromeFriedman: The Elements of Statistical Learning. 2009 (online). online (Memento des Originals vom 26. Januar 2015 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis.
- Sethu Vijayakumar: The Bias–Variance Tradeoff. University Edinburgh. 2007. Abgerufen am 19. August 2014.
- Greg Shakhnarovich: Notes on derivation of bias-variance decomposition in linear regression. 2011. Archiviert vom Original am 21. August 2014. Abgerufen am 20. August 2014.
- Pedro Domingos: A unified bias-variance decomposition. In: ICML..
- Giorgio Valentini, Thomas G. Dietterich: Bias–variance analysis of support vector machines for the development of SVM-based ensemble methods. In: JMLR. 5, 2004, S. 725–775.
- Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze: Introduction to Information Retrieval. Cambridge University Press, 2008, S. 308–314 (online).
- F. Gagliardi: Instance-based classifiers applied to medical databases: diagnosis and knowledge extraction. Artificial Intelligence in Medicine. Bande 52, Nr. 3 (2011), S. 123–139. Doi:10.1016/j.artmed.2011.04.002
- Jo-Anne Ting, Sethu Vijaykumar, Stefan Schaal: Locally Weighted Regression for Control. In: Encyclopedia of Machine Learning. Eds. Claude Sammut, Geoffrey I. Webb. Springer 2011. S. 615.
- Scott Fortmann-Roe: Understanding the Bias–Variance Tradeoff. 2012.
- Gerd Gigerenzer, Henry Brighton: Homo heuristicus: Why biased minds make better inferences. In: Topics in Cognitive Science. Band 1, Nr. 1, 2009, S. 107–143, doi:10.1111/j.1756-8765.2008.01006.x, PMID 25164802.
Weblinks
- Scott Fortmann-Roe: Understanding the Bias-Variance Tradeoff, Juni 2012.