Nächste-Nachbarn-Klassifikation
Die Nächste-Nachbarn-Klassifikation ist eine nichtparametrische Methode zur Schätzung von Wahrscheinlichkeitsdichtefunktionen. Der daraus resultierende K-Nearest-Neighbor-Algorithmus (KNN, zu Deutsch „k-nächste-Nachbarn-Algorithmus“) ist ein Klassifikationsverfahren, bei dem eine Klassenzuordnung unter Berücksichtigung seiner nächsten Nachbarn vorgenommen wird. Der Teil des Lernens besteht aus simplem Abspeichern der Trainingsbeispiele, was auch als lazy learning („träges Lernen“) bezeichnet wird. Eine Datennormalisierung kann die Genauigkeit dieses Algorithmus erhöhen.[1][2]


k-Nearest-Neighbor-Algorithmus
Die Klassifikation eines Objekts (oft beschrieben durch einen Merkmalsvektor) erfolgt im einfachsten Fall durch Mehrheitsentscheidung. An der Mehrheitsentscheidung beteiligen sich die k nächsten bereits klassifizierten Objekte von . Dabei sind viele Abstandsmaße denkbar (Euklidischer Abstand, Manhattan-Metrik usw.). wird der Klasse zugewiesen, welche die größte Anzahl der Objekte dieser Nachbarn hat. Für zwei Klassen kann ein Unentschieden bei der Mehrheitsentscheidung durch ein ungerades verhindert werden.


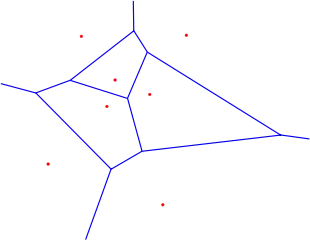
Für ein klein gewähltes besteht die Gefahr, dass Rauschen in den Trainingsdaten die Klassifikationsergebnisse verschlechtert. Für ergibt sich ein Voronoi-Diagramm. Wird zu groß gewählt, besteht die Gefahr, Punkte mit großem Abstand zu in die Klassifikationsentscheidung mit einzubeziehen. Diese Gefahr ist insbesondere groß, wenn die Trainingsdaten nicht gleichverteilt vorliegen oder nur wenige Beispiele vorhanden sind. Bei nicht gleichmäßig verteilten Trainingsdaten kann eine gewichtete Abstandsfunktion verwendet werden, die näheren Punkten ein höheres Gewicht zuweist als weiter entfernten. Ein praktisches Problem ist auch der Speicher- und Rechenaufwand des Algorithmus bei hochdimensionalen Räumen und vielen Trainingsdaten.

Siehe auch
- Mustererkennung
- Merkmalsraum
- Scikit-learn eine freie Software-Bibliothek zum maschinellen Lernen für die Programmiersprache Python
- OpenCV eine freie Programmbibliothek mit Algorithmen für die Bildverarbeitung und maschinelles Sehen
Literatur
- Wolfgang Ertel: Grundkurs Künstliche Intelligenz: Eine praxisorientierte Einführung. 3. Auflage. Springer Vieweg, Wiesbaden 2013, ISBN 978-3-8348-1677-1.
- Thomas A. Runkler: Data Analytics Models and Algorithms for Intelligent Data Analysis. 1. Auflage. Springer Vieweg, Wiesbaden 2012, ISBN 978-3-8348-2588-9.
Einzelnachweise
- S. Madeh Piryonesi, Tamer E. El-Diraby: Role of Data Analytics in Infrastructure Asset Management: Overcoming Data Size and Quality Problems. In: Journal of Transportation Engineering, Part B: Pavements. Band 146, Nr. 2, Juni 2020, ISSN 2573-5438, doi:10.1061/JPEODX.0000175.
- Trevor Hastie: The elements of statistical learning: data mining, inference, and prediction. with 200 full-color illustrations. Springer, New York 2001, ISBN 0-387-95284-5 (englisch, Weitere Autoren: Robert Tibshirani, Jerome Friedman).