Temporale Datenhaltung
Unter temporaler Datenhaltung (auch Historisierung genannt) versteht man in der Informationstechnik das Festhalten der zeitlichen Entwicklung der Daten bei Speicherung in einer Datenbank.
Häufig ist es ausreichend, in einem Datenbestand nur den jeweils aktuell (heute) gültigen Wert zu speichern, bei einer Änderung wird der alte Datenwert einfach überschrieben. Wenn jedoch die Anforderung besteht, alle Änderungen zu dokumentieren, ist eine temporale Datenhaltung erforderlich. Diese ermöglicht zu rekonstruieren, welcher Wert zu welchem Zeitpunkt gültig war oder – in weniger häufigen Fällen – erst in Zukunft gültig werden wird.
Bei einer temporalen Datenhaltung sind zwei Arten der zeitlichen Betrachtung relevant:
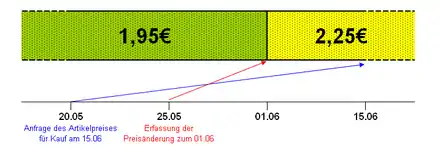
- Gültigkeitszeit: Der Zeitraum, in dem ein Datenelement in der realen Welt gültig ist.
Beispiel: Ein Artikel zum Preis von 1,95 € verteuert sich am 1. Juni 2006 auf 2,25 €. - Transaktionszeit (auch Bearbeitungszeit): Der Zeitpunkt, an dem ein Datenelement im Datenbestand gespeichert wurde.
Beispiel: Obige Preisanpassung des Artikels wurde am 25. Mai 2006 bearbeitet und in den Datenbestand aufgenommen.
In manchen Fällen sind dabei tatsächlich beide Arten relevant, hierfür verwendet man auch den Ausdruck „bitemporal“. Dies gilt beispielsweise für folgende, auf obige Beispiele bezogene Frage: Welcher Preis wurde einem Kunden am 20. Mai 2006 für den Kauf des Artikels genannt, wobei der Kauf erst am 15. Juni 2006 stattfinden sollte?
Details zur temporalen Datenhaltung werden (oft auch in Verbindung mit der Archivierung von Daten) als Anforderungen zur Revisionssicherheit von Informationssystemen definiert – z. B. wie lange Änderungen nachweisbar sein müssen.
Abbildung temporaler Daten in Datenbanksystemen
Bei der Abbildung temporaler Daten existieren folgende Varianten:
- Verwendung temporaler Datenbanken
Dabei handelt es sich um Datenbanksysteme, bei denen systemseitig bereits eine weitergehende Unterstützung temporaler Datenhaltung vorhanden ist, die über die Unterstützung zeitbezogener Datentypen hinausgeht. Derzeit existieren hierfür jedoch lediglich Prototypen und es ist noch kein kommerzielles Datenbanksystem verfügbar, das die Anforderungen der temporalen Datenhaltung umfänglich abbilden würde.[1] - Verwendung spatio-temporaler Datenbanken
Dabei handelt es sich um Datenbanksysteme, die neben der Unterstützung zeitabhängiger Daten auch für die Speicherung räumlicher Informationen ausgelegt sind. Dabei liegt der Fokus aber auf der räumlichen Information. Eingesetzt werden derartige Datenbanken beispielsweise im Bereich der Verkehrstelematik. - Abbildung in herkömmlichen relationalen Datenbanken
Da die Unterstützung temporaler Datentypen auch in herkömmlichen relationalen Datenbanksystemen gegeben ist, können temporale Daten prinzipiell in derartigen Datenbanken gespeichert werden, wobei die temporalen Attribute als „normale“ Attribute abgebildet werden. Die Abhandlung der temporalen Aspekte muss dabei durch die Anwendungsprogramme oder durch ein zur Anwendungsentwicklung verwendetes Framework erfolgen. - Abbildung in anderen Datenbanken (z. B. Objektdatenbanken)
Für andere Datenbanksysteme, insbesondere auch die objektorientierten Datenbanken, besteht keine mit den relationalen Systemen vergleichbare Einheitlichkeit und Verbreitung, so dass eine generelle Aussage über die Abbildung temporaler Daten nicht möglich ist. Dennoch lassen sich sicherlich die meisten der im Folgenden dargelegten Aspekte auch auf solche Datenbanken übertragen.
Im folgenden Abschnitt werden allgemeine Eigenschaften temporaler Datenhaltung betrachtet, die weitestgehend für alle oben genannten Abbildungen gelten. Anschließend erfolgt eine detaillierte Erläuterungen der Abbildung temporaler Daten in herkömmlichen relationalen Datenbanken. Weitere Informationen zu den anderen Abbildungsvarianten finden sich unter Umständen bei der Erläuterung der Datenbankmanagementsysteme selbst.
Begriffserläuterungen und Terminologie
Im Folgenden werden die wichtigsten Begriffe in Bezug auf temporale Datenhaltung erläutert. Diese Erläuterungen decken sich im Wesentlichen mit dem sogenannten „Konsens-Glossar“ (siehe Weblinks).
Gültigkeitszeit und Transaktionszeit
Wie anfangs bereits erwähnt, bezeichnet Gültigkeitszeit (Valid Time) den Zeitpunkt oder Zeitraum, wann ein Sachverhalt im modellierten Abbild der realen Welt (der Bezugswelt) gilt. Dabei können sowohl zukünftige als auch vergangene Zeiträume relevant sein.
Im Gegensatz dazu bezeichnet Transaktionszeit (Transaction Time) den Zeitpunkt, wann ein Sachverhalt in der Datenbank gespeichert wurde und damit den Zeitraum, wann dieser Sachverhalt als korrektes Abbild der Bezugswelt angesehen wurde. Im Gegensatz zur Gültigkeitszeit kann sich die Transaktionszeit also niemals auf die Zukunft beziehen. Ein interessantes Beispiel für temporale Daten findet sich in der Datenbank von Wikipedia selbst, in der eine Transaktionszeitstempelung der Artikel stattfindet,[2] um die Versionen eines Artikels zu verschiedenen Zeitpunkten rekonstruieren zu können (siehe Versionsliste dieses Artikels).
Sind sowohl Gültigkeits- als auch Transaktionszeit relevant, spricht man von bitemporaler Datenhaltung. In diesem Zusammenhang ist auch zu beachten, dass die Transaktionszeit vom System (z. B. dem Datenbanksystem) festgelegt werden kann, die Gültigkeitszeit muss dagegen vom Benutzer angegeben werden.
Im Konsens-Glossar existiert auch der Begriff der benutzerdefinierten Zeit (User-defined Time[3]). Damit sollen anderweitige Zeitangaben, die „normale“ Attribute in der Datenbank darstellen (wie z. B. ein Geburtsdatum), von der temporalen Datenhaltung abgegrenzt werden. Diese Bezeichnung ist unglücklich, da ja auch die Gültigkeitszeit vom Benutzer festgelegt wird.
Als Schnappschuss (Snapshot) bezeichnet man die Betrachtung temporaler Daten zu einem fixierten Zeitpunkt für die Gültigkeits- und ggf. auch die Transaktionszeit. Meist bezieht sich ein solcher Schnappschuss auf die aktuelle Zeit. Eine Datenbank ohne temporale Unterstützung bietet ausschließlich einen solchen Schnappschuss, deshalb werden solche Datenbanken auch als Schnappschuss-Datenbanken bezeichnet.
Zeitpunkte, Zeitintervalle und Zeitdauern
Ein Zeitpunkt (Instant) stellt einen Punkt auf einer verwendeten Zeitachse dar. Dabei können unterschiedliche Granularitäten Verwendung finden (z. B. tagesgenau, sekundengenau).
Zeitangaben können verankert (fixiert) oder unverankert sein. Eine verankerte Zeitangabe bezieht sich auf einen konkreten Zeitpunkt oder ein konkretes Intervall in der Zeitskala. Bei einer Zeitdauer handelt es sich um ein unverankertes Zeitintervall.
Zeitlich verankerte Intervalle werden auch als Perioden (Time Period) bezeichnet. Der Begriff Intervall ohne zusätzliche Angabe ist in dieser Hinsicht missverständlich, vor allem auch deshalb, weil in SQL der Begriff für eine Zeitdauer verwendet wird.
Das kleinste mögliche Zeitintervall bei einer bestimmten Granularität wird als Chronon[3] bezeichnet, bei einem Datum wäre das beispielsweise ein Tag.
Zeitstempelung
Als Zeitstempelung bezeichnet man die Ergänzung eines Zeitbezugs zu einem Datenattribut oder einer Datenzeile, in Verbindung mit relationalen Datenbanken auch als Tupel bezeichnet. Dabei werden Gültigkeits-, Transaktions- und bitemporale Zeitstempelung unterschieden.
Allgemein wird erst einmal nicht definiert, wie dieser Zeitbezug technisch abgebildet ist. Dabei kann es sich um eine einfache Zeitangabe handeln, die die Gültigkeit zu einem einzigen konkreten Zeitpunkt ausdrückt. Häufiger jedoch ist der Zeitbezug in Form eines Zeitintervalls abgebildet. Die allgemeinste Form ist hierbei ein sogenanntes temporales Element,[3] das eine Menge von ein oder mehreren Zeitintervallen darstellt.
Dieser Zeitbezug wird im Konsens-Glossar auch als Zeitstempel (Timestamp) bezeichnet.[3] Hierbei ist wichtig, dass man dies hier nicht mit der herkömmlichen Bedeutung dieses Begriffs verwechseln darf, da es sich hier um eine wesentlich abstraktere Form eines Zeitstempels handelt.
Bei der Befüllung von Zeitstempeln unterscheidet man explizite und implizite Zeitstempelung. Bei der expliziten Zeitstempelung wird der Zeitstempel nicht durch das Datenbanksystem versorgt, sondern muss explizit durch das Anwendungsprogramm (oder durch die verwendete Architektur, z. B. einem Datenbanktrigger) versorgt werden. Eine implizite Zeitstempelung gibt es nur bei „echten“ temporalen Datenbanken, dort übernimmt das Datenbanksystem in der Regel diese Aufgabe. Zu beachten ist dabei, dass dies nur im Falle der Transaktionszeit vollständig gekapselt ablaufen kann, bei der Gültigkeitszeit muss die Angabe des Gültigkeitszeitraums auch explizit vorgegeben werden können, temporale Datenbanken bieten hierbei aber oft spezielle Schnittstellen an und handhaben den Zeitstempel nicht als normales Attribut.
Tupel- versus Attribut-Zeitstempelung
Bei der Einführung einer Zeitstempelung stellt sich die Frage, auf welcher Ebene man diese ergänzt. Im Grunde genommen müsste jedes Attribut, das sich nicht synchron mit einem anderen verhält, für sich allein versioniert, das heißt mit einer eigenen Zeitstempelung versehen werden. Dieses Vorgehen bezeichnet man als Attribut-Zeitstempelung.
Der technische Verwaltungsaufwand für eine Attribut-Zeitstempelung ist jedoch beachtlich, so dass man häufig alle Attribute einer Datenzeile (eines Tupels) gemeinsam versioniert, obwohl die Attribute sich zeitlich nicht synchron verhalten. Dies bezeichnet man als Tupel-Zeitstempelung.
Die Entscheidung, welches Verfahren man wählt, hängt vor allem von der Änderungshäufigkeit der einzelnen Attribute ab. Typischerweise wird man Attribute mit hoher Änderungshäufigkeit eher für sich alleine, hingegen Attribute mit geringer Änderungshäufigkeit gemeinsam versionieren.[4]
Temporale Normalisierung (Coalescing)
Mit der Tupel-Zeitstempelung handelt man sich aber zwangsläufig das Problem ein, dass man bei Auswertungen, die nur eines der gemeinsam versionierten Attribute auswerten, aufeinander folgende Zeiträume erhält, bei denen sich die Attributwerte nicht unterscheiden. Man hätte dann gern diese Zeiträume zusammengefasst. Eine derartige Zusammenfassung wird als temporale Normalisierung bezeichnet (auch Coalescing[3]).
Die Verwendung der Tupel-Zeitstempelung ist aber nicht der einzige Grund, warum man eine temporale Normalisierung benötigt. Beispielsweise ist diese Normalisierung ebenfalls erforderlich, wenn man bitemporale Daten nur separat nach der Gültigkeits- oder der Transaktionszeit auswertet. Außerdem ist eine solche Zusammenfassung auch dann wünschenswert, wenn man bei Auswertungen mehrere mit Zeitstempelung versehene Tupel verknüpft (Join).
Formal versteht man unter temporaler Normalisierung eine Zusammenfassung gleichartiger Attributwerte, wann immer das gemäß der zur Zeitstempelung verwendeten Datentypen möglich ist.[5] Bei Verwendung von Zeitintervallen zur Zeitstempelung sind also aufeinanderfolgende Intervalle mit gleichen Attributwerten zusammenzufassen, bei Verwendung von temporalen Elementen werden sogar alle Zeiträume zusammengefasst, zu denen ein spezieller Attributwert auftritt.
Im folgenden Beispiel werden für die Artikeldaten der Preis und der Ziellagerbestand gemeinsam versioniert. Werden sowohl der Preis als auch der Ziellagerbestand für sich alleine ohne Normalisierung ausgewertet, würde man vier einzelne Intervalle erhalten. Durch die temporale Normalisierung lassen sich dabei je zwei Einzelintervalle zu einem zusammenfassen.
|
|
|
Abbildung in herkömmlichen relationalen Datenbanksystemen
Die Abbildung temporaler Daten in herkömmlichen relationalen Datenbanken ist möglich, dennoch gibt es kein standardisiertes Vorgehen zur Umsetzung, da dies sehr stark von den jeweiligen Anforderungen abhängig ist. Die Komplexitätssteigerung und die Nachteile bei Abbildung temporaler Daten im Vergleich zu einer „herkömmlichen“ Schnappschuss-Abbildung sind dabei erheblich, so dass es auch diverse vereinfachende Abbildungen gibt, die jeweils situationsabhängig möglich sind. Mit der Unterstützung temporaler Daten sind folgende Nachteile verbunden:
- Das Datenvolumen steigt beträchtlich. Unter Umständen ist eine Bereinigungsfunktion notwendig, die ältere Daten archiviert oder löscht.
- Der Zugriff auf den aktuellen Wert wird wesentlich komplexer (Implementierungsaufwand, Performance), dies ist vor allem deshalb bedeutsam, da dies in vielen Fällen die mit Abstand häufigste Form des Zugriffs ist.
- Aus dem ER-Modell (ohne temporale Betrachtung) abgeleitete Integritätsbedingungen können nicht mehr so ohne weiteres mittels der Definition von Primärschlüsseln und Nutzung der referentiellen Integrität abgebildet werden.
Es ist somit nicht zweckmäßig, eine temporale Abbildung für Daten zu unterstützen, für die das aufgrund der Anforderungen nicht unbedingt nötig ist. Das bedeutet auch, dass bei der grundsätzlichen Einführung der Zeitabhängigkeit in ein Datenmodell nicht grundsätzlich alle Relationen umgestellt werden sollten.
Im Folgenden werden zunächst verschiedene konzeptionelle Aspekte bei einer vollwertigen Abbildung temporalen Daten dargelegt. Abschließend erfolgt zudem noch die Diskussion diverser vereinfachender Abbildungen.
Zeitstempelung
Zur Zeitstempelung werden im Regelfall Zeitintervalle verwendet. Da es ein (fixiertes) Zeitintervall nicht als explizites Attribut in relationalen Datenbanken gibt, sind hierfür zwei Zeitattribute (z. B. vom Typ DATE oder TIMESTAMP) in die Tabellendefinition aufzunehmen, die den Beginn und das Ende des Zeitintervalls definieren, im bitemporalen Fall jeweils separat für Gültigkeits- und Transaktionszeit.
Dabei gibt es zwei grundsätzliche Ansätze:[6]
- Interval Representation: Ergänzung zweier Zeitangaben pro Datenzeile (Beginn, Ende)
- Point Representation: Ergänzung nur einer Zeitangabe, die den Beginn der Zeile definiert, das Ende wird hierbei implizit durch den Beginn der zeitlich folgenden Zeile festgelegt
Beide Ansätze haben ihre Vor- und Nachteile:
- Nachteile der Interval Representation:
- Überschneidende Zeilen können eingefügt werden, ohne die Datenbankintegrität zu verletzen. Es ist eine gesonderte Validierung erforderlich (z. B. mittels Datenbanktriggern).
- Es ist ein spezieller Wert zur Kennzeichnung einer unbefristeten Gültigkeit erforderlich. Hierfür kann entweder NULL oder das minimal bzw. maximal mögliche Datum verwendet werden (siehe unten).
- Bei einer Wertänderung ist zusätzlich zum Einfügen einer neuen Zeile ggf. die Anpassung (Terminierung) der bisher gültigen Zeile erforderlich.
- Nachteile der Point Representation:
- Die Ermittlung der Daten zu einem speziellen Zeitpunkt (i. d. R. aktueller Zeitpunkt) ist schwierig und benötigt eine Unterabfrage (Subselect).
- Das Ende der Gültigkeit oder Gültigkeitsunterbrechungen können nur dadurch abgebildet werden, dass alle Datenattribute der Zeile leer (
NULL) gesetzt werden. - Im bitemporalen Fall kann die Point Representation nicht für beide Zeitdimensionen verwendet werden (siehe Beispiel).
Bei der Interval Representation steht man zudem vor der Wahl, ein geschlossenes oder ein rechtsseitig halboffenes Intervall zu verwenden, d. h. das Ende selbst ist nicht mehr Bestandteil des Intervalls. Dabei spricht vieles für letztere Variante, da sonst bei der Ermittlung auf Lückenlosigkeit der Intervalle immer ein Chronon zum Ende addiert werden müsste, was beispielsweise beim Datentyp TIMESTAMP datenbankunabhängig gar nicht möglich ist.
Das folgende Beispiel stellt die SQL-Abfragen für beide Varianten im Falle einer Gültigkeitszeitstempelung dar. Dabei werden die aktuell gültigen Preise zu Artikeln (identifiziert durch ArtNr) ermittelt. Der Gültigkeitsbeginn wird jeweils durch die Spalte GueltigAb ausgedrückt, für die Interval Representation wird das Gültigkeitsende durch UngueltigAb definiert (es handelt sich also um ein rechtsseitig halboffenes Intervall). Zudem wird im Falle eines unbefristeten Gültigkeitsendes unterstellt, dass das maximal mögliche Datum eingetragen wird.
SELECT ArtNr, Preis
FROM Artikel AS a
WHERE a.GueltigAb <= CURRENT_DATE
AND a.UngueltigAb > CURRENT_DATE
|
SELECT ArtNr, Preis
FROM Artikel AS a
WHERE a.GueltigAb = (SELECT MAX(GueltigAb)
FROM Artikel
WHERE ArtNr = a.ArtNr
AND GueltigAb <= CURRENT_DATE
)
|
Noch etwas aufwändiger gestaltet sich eine solche Abfrage im bitemporalen Fall. Auch bei diesem Beispiel werden rechtsseitig halboffene Intervalle verwendet, das Intervall der Transaktionszeit wird dabei durch ErfasstAm und GeloeschtAm definiert. Bei der Point Representation ist zu beachten, dass es nicht möglich ist, auch für die Transaktionszeit lediglich den Beginn des Intervalls als Attribut zu ergänzen, hier muss dann zumindest bei der Transaktionszeit ein Intervall verwendet werden, damit eine sinnvolle Interpretation möglich ist. Abweichend zu obigem Beispiel soll hier nun nicht der Wert zum aktuellen Datum (ausgedrückt durch CURRENT_DATE), sondern zu vorgegebenen Zeitpunkten ermittelt werden, ausgedrückt durch die Parameter :VorgGueltigkeit und :VorgDatenstand.
SELECT ArtNr, Preis
FROM Artikel AS a
WHERE a.GueltigAb <= :VorgGueltigkeit
AND a.UngueltigAb > :VorgGueltigkeit
AND a.ErfasstAm <= :VorgDatenstand
AND a.GeloschtAm > :VorgDatenstand
|
SELECT ArtNr, Preis
FROM Artikel AS a
WHERE a.GueltigAb = (SELECT MAX(GueltigAb)
FROM Artikel
WHERE ArtNr = a.ArtNr
AND GueltigAb <= :VorgGueltigkeit
AND ErfasstAm <= :VorgDatenstand
AND GeloeschtAm > :VorgDatenstand
)
AND a.ErfasstAm <= :VorgDatenstand
AND a.GeloeschtAm > :VorgDatenstand
|
Im obigen Beispiel ist anzumerken, dass für das Ende der Transaktionszeit unterstellt wird, dass für die derzeit gültige Zeile das maximal mögliche Datum eingetragen wird. Häufig wird jedoch für diesen Fall stattdessen NULL verwendet, da dann die Abfrage auf derzeit gültig (ungelöschte) Daten einfacher ist (GeloeschtAm IS NULL). Komplizierter wird in diesem Fall aber die Abfrage auf vergangene Datenstände, wie im obigen Beispiel. Dort müsste jeweils die Spalte GeloeschtAm durch folgendes Konstrukt ersetzt werden:
CASE WHEN GeloeschtAm IS NULL THEN '9999-12-31' ELSE GeloeschtAm END
Dabei ist '9999-12-31' das maximal mögliche Datum, dieser Wert ist allerdings abhängig vom verwendeten Datenbanksystem.
Bestimmen des Primärschlüssels
In temporalen Relationen, die Evolutionen von Objektzuständen ausdrücken, ist es nicht möglich, Tupel (Datenzeilen) zu identifizieren ohne die Zeitdimension einzubeziehen.[7]
Bei Verwendung der Point Representation für die Zeitstempelung ist der „normale“ Primärschlüssel lediglich noch um das den Gültigkeitsbeginn definierende Attribut zu erweitern. Für das Beispiel des Artikels wäre also neben der Artikelnummer noch der Gültigkeitsbeginn in den Primärschlüssel aufzunehmen.
Bei Verwendung der Interval Representation bieten sich mehrere Alternativen an. Hierbei kann entweder der Beginn oder das Ende des Intervalls in den Schlüssel aufgenommen werden. Bei dieser Entscheidung spielt noch eine Rolle, welchen Wert man als Stellvertreter für eine unbefristete Gültigkeit definiert:[8]
- Der Primärschlüssel einer Relation wird einerseits zur Sicherstellung der Eindeutigkeit definiert, andererseits ist die Definition des Primärschlüssels auch eine Optimierungsfrage, da beim Zugriff auf die Daten dieser Schlüssel als Index zur Suche der passenden Zeilen verwendet wird.
- Insbesondere bei der Transaktionszeitstempelung wird häufig die derzeit aktuell gültige Zeile benötigt. Dies ist die Zeile, bei der das Gültigkeitsende unbefristet ist. Dies würde für die Aufnahme des Gültigkeitsendes in den Primärschlüssel sprechen.
- Bei herkömmlichen relationalen Datenbanksystemen ist
NULLnicht als Primärschlüsselspalte möglich, deshalb kann das Gültigkeitsende nicht in den Schlüssel aufgenommen werden, wenn man diese Abbildungsvariante für ein unbefristetes Gültigkeitsende wählt. Alternativ würde sich dann die Verwendung des maximal möglichen Zeitwerts zur Festlegung eines unbefristeten Gültigkeitsendes anbieten.
Zu beachten ist weiterhin, dass bei Verwendung der Interval Representation keine der Varianten eine Überschneidungsfreiheit der Zeilen sicherstellt, diese ist gesondert zu prüfen.
Aus Gründen der Performance wird gelegentlich in temporalen Relationen statt des zusammengesetzten Schlüssels ein zusätzliches Attribut als Surrogatschlüssel (künstlicher Schlüssels) eingeführt, um eine möglichst kurze Identifikation einer Datenzeile zu erhalten. Bei vielen Datenbanksystemen besteht für solche Surrogatschlüssel die Möglichkeit der automatischen Vergabe eindeutiger Identifikationen.
Integritätsprüfungen
Wie bereits erwähnt müssen Integritätsbedingungen, die normalerweise über die Eindeutigkeit des Primärschlüssels oder die referentielle Integrität abgedeckt werden, bei temporalen Daten anderweitig abgesichert werden. Hierzu bieten sich folgende Varianten an:
- Definition von Integritätsregeln (Constraints oder Assertions)
- Datenbanktrigger
- Datenbankprozeduren (Stored Procedures)
- Bereitstellung anderweitiger zentraler Funktionen für Datenbank-Aktualisierungen, beispielsweise im Rahmen eines Frameworks, die die erforderlichen Prüfungen beinhalten.
Insbesondere bei Nutzung von Constraints und Datenbanktriggern kann sich die Problematik ergeben, dass die Integrität während einer aus mehreren Datenbankoperationen bestehenden Aktualisierung temporär verletzt sein kann und erst nach Durchführung aller Datenbankoperationen für einen Aktualisierungsfall wieder eingehalten wird. Hierfür muss das Datenbanksystem die Möglichkeit bieten, die Integritätsprüfungen erst am Ende einer Transaktion durchzuführen.[9]
Bei Verwendung der Interval Representation ist, wie schon erwähnt, die Prüfung auf Überschneidungsfreiheit der Zeilen zu einem Objekt erforderlich. Im Folgenden eine beispielhafte SQL-Abfrage, die überschneidende Einträge für Zeilen zu Artikeln (identifiziert durch ArtNr) aus einer Tabelle mit Namen Artikel liefert, wobei das Gültigkeitszeitintervall durch GueltigAb und UngueltigAb ausgedrückt wird.
SELECT * FROM Artikel AS x, Artikel AS y
WHERE x.ArtNr = y.ArtNr
AND x.UngueltigAb > y.GueltigAb
AND y.UngueltigAb > x.GueltigAb
AND ''Bedingung(en) zum Ausschluss derselben Zeile in x und y''
Letztere Bedingung ist erforderlich, damit eine Zeile nicht als überschneidend mit sich selbst diagnostiziert wird. Wie genau die Bedingung zu formulieren ist, hängt vom gewählten Primärschlüssel ab, manche Datenbanksysteme unterstützen hier spezielle Funktionen oder Datentypen zur Identifikation einer Tabellenzeile.
Wenn über den Primärschlüssel sichergestellt ist, dass es zu einem Gültigkeitsbeginn jeweils nur einen Eintrag geben kann, ist auch eine vereinfachte Prüfung auf folgende Weise möglich:
SELECT * FROM Artikel AS x, Artikel AS y
WHERE x.ArtNr = y.ArtNr
AND x.UngueltigAb > y.GueltigAb
AND y.GueltigAb > x.GueltigAb
Dieser Ansatz hat zudem den Vorteil, dass die zwei Zeilen eines sich überschneidenden Paares nur als eine Ergebniszeile geliefert werden.
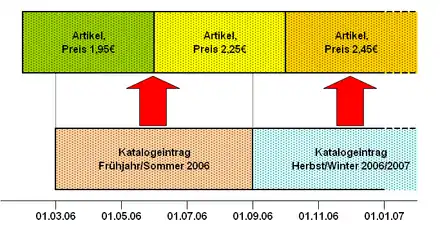
Noch etwas aufwändiger gestaltet sich die Prüfung der referentiellen Integrität im temporalen Sinn, wenn sowohl die referenzierende Tabelle (die Dependent-Tabelle) als auch die referenzierte Tabelle (die Parent-Tabelle) eine Zeitstempelung aufweist. Hierbei muss für jede Zeile der Dependent-Tabelle geprüft werden, ob
- eine davor oder gleichzeitig beginnende zugehörige Parent-Zeile existiert, die sich mit dem Zeitraum der Dependent-Zeile überlappt,
- eine danach oder gleichzeitig beendete zugehörige Parent-Zeile existiert, die sich mit dem Zeitraum der Dependent-Zeile überlappt und
- für alle Zeilen der Parent-Tabelle, deren Gültigkeitsende im Zeitraum der jeweiligen Dependent-Zeile liegt (nicht mit ihm zusammenfällt!), immer ein direkter Nachfolger existiert (keine Lücken, wo es stört).
Nur wenn alle drei Bedingungen gegeben sind, liegt keine Verletzung der Integrität vor.[10]
Im abgebildeten Beispiel referenzieren zwei Katalogeinträge (Dependent) den Artikel (Parent). Dabei existiert ein Katalogeintrag für den Zeitraum 1. März 2006 bis 31. August 2006 sowie ein weiterer Katalogeintrag, der ab dem 1. September 2006 gilt und einen derzeit aktuellen Katalogeintrag darstellt. Für die gesamten durch die Kalendereinträge benötigten Zeiträume muss sichergestellt sein, dass der referenzierte Artikel existiert, wobei in diesen Zeiträumen durchaus Preisänderungen des Artikels stattfinden (der Preis scheint im Katalog nicht dargestellt zu werden). Beide Katalogeinträge beziehen sich somit auf je zwei verschiedene Zeilen des Artikels. In diesem Beispiel ist zu beachten, dass die Tabelle Artikel sowohl den Preis als auch die Existenz des Artikels definiert, d. h., dass der Artikel zur entsprechenden Zeit im Sortiment ist.
Vereinfachende Abbildungen
Als Alternative zu einer Transaktionszeitstempelung kann für den Fall, dass nur in sehr seltenen Fällen auf ältere Daten zurückgegriffen werden muss, über eine Protokollierung (Logging) der Datenbank-Aktualisierungen die Rekonstruierbarkeit älterer Datenkonstellationen sichergestellt werden. Für die Implementierung eines derartigen Protokollierungsverfahrens ist jedoch die Nutzung zentraler Funktionen für Datenbank-Aktualisierungen nötig. Zudem sind Funktionen bereitzustellen, die durch Auswertung des Protokolls alte Datenbankstände rekonstruieren.
Bei der Gültigkeitszeitstempelung ist es für den Fall zyklischer Datenänderungen sinnvoll, statt der üblicherweise verwendeten Intervalle zur Zeitstempelung direkt die Identifikation der Gültigkeitsperiode zu verwenden (z. B. bei einem jährlichen Änderungszyklus kann allein das Jahr als zusätzlicher Primärschlüsselbestandteil verwendet werden). Diese Vorgehensweise hat zudem den Vorteil, dass die von einigen Datenbanksystemen zur Verfügung gestellten Konzepte der Partitionierung zur Steigerung der Effizienz verwendet werden können.
Falls die Temporalität ausschließlich dafür erforderlich ist zu dokumentieren, mit welchen Datenständen eine bestimmte Auswertungsfunktion ausgeführt wurde, kann auch das Ausführungsereignis selbst als Zeitstempel verwendet werden. Zu beachten ist aber, dass dieser Ansatz fragwürdig wird, sobald zwei verschiedene derartige Auswertungsfunktionen existieren, die gleichartige Datentypen einbeziehen.
Ein weiterer Ansatz zur Vereinfachung des Zugriffs auf die aktuellen Daten ist, die Historie in separate Tabellen auszulagern. Dies ist vor allem auch im Hinblick auf die Performance bei Zugriff auf die aktuellen Daten interessant. Dieses Verfahren ist sowohl für die Transaktions- als auch die Gültigkeitszeit möglich, für letztere allerdings nur dann, wenn keine zukünftig gültigen Daten zu erfassen sind. Zudem ist der Preis relativ hoch, da alle Relationen dupliziert werden müssen.
Archivierung und Bereinigung
Eine temporale Datenhaltung führt zwangsläufig zu einem ständigen Anwachsen des Datenvolumens, da veraltete Daten ja absichtlich nicht aus der Datenbank entfernt werden. Insofern ist es bei Einführung einer temporalen Datenhaltung auf längere Sicht erforderlich, sich Gedanken über ein Verfahren zur Datenbankarchivierung zu machen, um damit eine Bereinigung der operativen Datenbank zu ermöglichen.
Mögliche Varianten
Im Gegensatz zu nicht temporalen Daten ist eine Archivierung bei temporaler Datenhaltung nicht erforderlich, um gelöschte oder geänderte Zustände eines Objekts rekonstruieren zu können, da dies durch die Verwendung einer Transaktionszeitstempelung ohnehin möglich ist.
Aus diesem Grund ist situationsabhängig als einfachste Variante eine Bereinigung (Vacuuming) der temporalen Datenbank ausreichend, d. h. ein Löschen älterer nicht mehr erforderlicher Daten. Allerdings ist auch hier erforderlich, dass der Bereinigungsvorgang die Konsistenz der Datenbank aufrechterhält, was ein Hauptaspekt auch bei einer „richtigen“ anwendungsorientierten Datenbankarchivierung ist.
Für die anwendungsorientierte Datenbankarchivierung gibt es wiederum unterschiedliche Verfahren. Ein hauptsächliches Klassifizierungsmerkmal dieser Varianten ist die Unterscheidung zwischen einem eigenständigen und einem integrierenden Archiv. Ein eigenständiges Archiv stellt dabei selbst eine Datenbank dar, die in sich konsistent ist und auf die bei Bedarf direkt zugegriffen werden kann. Ein integrierendes Archiv dient hingegen lediglich dazu, die Daten bei Bedarf in die operative Datenbank zurückzuspielen (Copy-back oder Move-back).
Kriterien zur Auslagerung
Es ist erforderlich, möglichst eindeutige und nachvollziehbare Kriterien festzulegen, die definieren, wann ein Datenelement aus der operativen Datenbank entfernt wird. Bei bitemporalen Datenbanken bietet sich hierbei zunächst die Transaktionszeit an, d. h. beispielsweise alle Datensätze, bei denen das Transaktionszeitende älter als ein festgelegter Stichtag ist, werden aus der Datenbank entfernt und gegebenenfalls archiviert.
Die Verwendung der Transaktionszeit hat vor allem den Vorteil, dass diese vom System vergeben wird und nicht vom Benutzer beeinflussbar ist, somit ist es nicht möglich, dass neu erfasste Daten sich auf einen Zeitraum beziehen, der eigentlich schon ins Archiv ausgelagert wurde.
Die Verwendung der Transaktionszeit ist nicht möglich, wenn nur die Gültigkeitszeit verwaltet wird. Zudem ist es auch im bitemporalen Fall sicherlich häufig nötig zusätzlich zur Transaktionszeit auch die Gültigkeitszeit als Kriterium zu verwenden.
Sicherstellung der Konsistenz
Der Bereinigungs- und Archivierungsvorgang darf die Konsistenz der operativen Datenbank nicht gefährden. Für den Fall eines eigenständigen Archivs gilt dies auch für die zur Archivierung verwendete Datenbank.
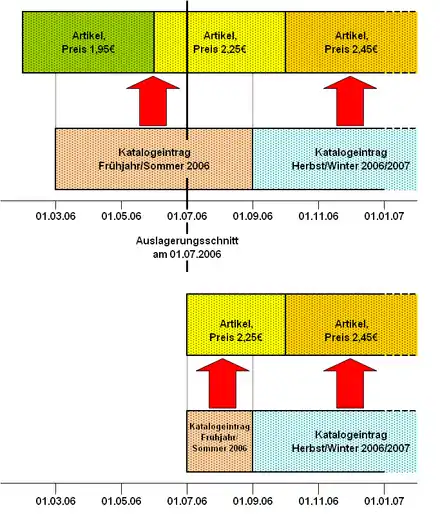
Im Hinblick auf temporale Daten bedeutet dies folgendes:
- Intervalle für die Gültigkeits- oder Transaktionszeit eines Objekts dürfen sich nicht überlappen.
- Für Beziehungen zwischen Objekten muss die referentielle Integrität auch im temporalen Sinn gewahrt bleiben (siehe auch Integritätsprüfungen)
- Die Daten sollten temporal normalisiert sein, d. h. es muss ggf. ein Coalescing durchgeführt werden.
Beim Entfernen von Daten aus der operativen Datenbank ist dabei zur Sicherstellung der referentiellen Integrität unter Umständen ein Zerschneiden von Intervallen erforderlich.[11]
Nebenstehendes Beispiel soll dies verdeutlichen: In der Datenbank soll eine Auslagerung aller Daten erfolgen, deren Gültigkeit vor dem 1. Juli 2006 liegt. Dies bedeutet, dass die Artikelversion mit dem Preis von 1,95 € gänzlich aus der Datenbank entfernt werden kann. Um nun aber die referentielle Integrität weiterhin zu gewährleisten, muss die Artikelversion zum Preis von 2,25 € zerschnitten werden. Gleiches gilt für den Katalogeintrag „Frühjahr/Sommer 2006“. Wenn nun für den Fall eines eigenständigen Archivs die Integrität auch im Archiv gewahrt werden soll, müssen genau die abgeschnittenen Gegenstücke der Intervalle im Archiv eingefügt werden. Dies macht auch deutlich, dass dann in der Archiv-Datenbank nach jeder weiteren Archivierung ein Coalescing notwendig ist, da ja bei einem nächsten Archivierungsvorgang die bei der vorangegangenen Archivierung abgeschnittenen Teile der Intervalle archiviert werden.
Am problematischsten in diesem Zusammenhang ist die Wiedereinlagerung, insbesondere dann, wenn die Wiedereinlagerung nur partiell und nicht übergreifend für einen gesamten Zeitraum durchgeführt wird, und zudem die wieder eingelagerten Daten zugleich im Archiv belassen werden (Copy-back). Dann sind einige Maßnahmen zur Sicherstellung der Konsistenz zu ergreifen, da dann beispielsweise auch Überschneidungen zwischen den Zeitintervallen eines Objekts auftreten können.
Typische Anwendungsgebiete
Im Folgenden eine Aufstellung von typischen Anwendungsfällen für temporale Datenhaltung. Diese Aufstellung erhebt allerdings keinen Anspruch auf Vollständigkeit.
Data-Warehouse
Bei einem Data-Warehouse handelt es sich um eine Datenbank, die vorrangig zur Analyse der Daten angelegt wurde und aus ein oder mehreren anderen Systemen (meist operative Datenbanken) gespeist wird. Typischerweise wird dabei periodisch ein Datenimport zur Übertragung der Daten der operativen Systeme in das Data-Warehouse durchgeführt.
Bei einer solchen Konstellation bietet sich auch an, die Ergänzung der Zeitabhängigkeit beim periodisch durchgeführten Import der Daten zu ergänzen. Der Gültigkeitsbeginn ist dabei der Zeitpunkt des Imports. Dies hat den Vorteil, dass das operative System nicht mit der für temporale Datenhaltung erforderlichen Komplexität belastet wird, zeitabhängige Auswertungen über das Data-Warehouse aber dennoch möglich sind.
Da der Import dabei in der Regel mit einem konstanten Zyklus (z. B. monatlich) durchgeführt wird, müssen zur Zeitstempelung keine Intervalle verwendet werden, sondern der Gültigkeitszeitraum kann mittels eines einzelnen Attributs identifiziert werden (siehe auch vereinfachende Abbildungen). Weiterhin kann dabei eine Dimensionstabelle für die Zeit im Sinne des Sternschemas aufgebaut werden, was Auswertungen im Rahmen des Online Analytical Processing (OLAP) ermöglicht.
Gehaltsabrechnung
Ein typischer Fall für das Erfordernis bitemporaler Daten ist eine Gehaltsabrechnung. Hierbei muss unter anderem die Zugehörigkeit eines Mitarbeiters zu einer Gehaltsgruppe zeitlich korrekt festgehalten werden (Gültigkeitszeit). Bei nachträglicher Korrektur (Transaktionszeit) einer zugeordneten Gehaltsgruppe oder auch nur des Zuordnungszeitraums dieser Gruppe muss nachvollziehbar bleiben, auf welcher Basis ein Abrechnungsvorgang operiert hat.
Risikomanagement im Bankenbereich
Insbesondere durch die Vorschriften, die durch die Basel II-Verordnung definiert werden, müssen Kreditinstitute und Finanzdienstleister nachvollziehbar dokumentieren können, auf Basis welcher Informationen (z. B. Eigenkapital und Ratings) welche Entscheidung getroffen wurde.
Dies erfordert eine umfassende Transaktionszeitstempelung, teilweise auch eine bitemporale Abbildung. Letzteres ist beispielsweise für die Ratings eines Kreditnehmers erforderlich, da zum einen festzuhalten ist, zu welchem Zeitpunkt eine derartige Einschätzung von einer Ratingagentur vorgenommen wurde (Bewertungsdatum). Zum anderen muss aber auch dokumentiert werden, wann diese neue Einschätzung dem Kreditinstitut bekannt und in den Datenbestand aufgenommen wurde.
Literatur
- C.J. Date, Hugh Darwen, Nikos A. Lorentzos: Time and Relational Theory. Temporal Databases in the Relational Model and SQL. 2. Auflage. Morgan Kaufmann, Waltham, Massachusetts 2014, ISBN 978-0-12-800675-7.
- Tom Johnston: Bitemporal Data. Theory and practice. Morgan Kaufmann, Waltham, Massachusetts 2014, ISBN 978-0-12-408055-3.
- Thomas Myrach: Temporale Datenbanken in betrieblichen Informationssystemen. Teubner, Wiesbaden 2005, ISBN 3-519-00442-9.
- Richard T. Snodgrass, Christian S. Jensen: Developing Time-Oriented Database Applications in SQL. Morgan Kaufmann, San Francisco 2000, ISBN 1-55860-436-7 (arizona.edu [PDF; 5,0 MB]).
Weblinks
- Konsens-Glossar (Consensus Glossary of Temporal Database Concepts)
- TimeCenter
- Achim Demelt: Temporale Datenhaltung. (Memento vom 29. September 2004 im Internet Archive) (PDF; 359 kB)
- GUIDE Arbeitskreis Applikation Management: Pragmatische Lösungsansätze zur Modellierung von Zeitaspekten (PDF; 152 kB)
- Management of Temporal Data
Einzelnachweise
- Myrach 2005, Seite 23
- Revision Table. MediaWiki Database Layout
- Konsens-Glossar, Definition benutzerdefinierte Zeit, Chronon, temporales Element, Timestamp, Coalesce
- Myrach 2005, Seite 389–392
- Myrach 2005, Seite 63
- James Clifford, Abdullah Uz Tansel: On An Algebra For Historical Relational Databases. Two Views. In: Shamkant B. Navathe (Hrsg.): Proceedings of the 1985 ACM SIGMOD International Conference on Management of Data. ACM Press, 1985, ISBN 0-89791-160-1, S. 247–265, doi:10.1145/318898.318922.
- Myrach 2005, Seite 134
- Bela Stantic, John Thornton, Abdul Sattar: A Novel Approach to Model NOW in Temporal Databases. (PDF; 167 kB) 2003, abgerufen am 25. Juni 2010.
- Myrach 2005, Seite 158, 164, 173ff
- Snodgrass, Jensen, 1999 (PDF; 5,0 MB), Seite 127ff.
- Theorie und Praxis von bitemporalen Datenbanken und deren Archivierung, Pfister, 2005 (Memento vom 28. September 2007 im Internet Archive), Seite 68fff