ETL-Prozess
Extract, Transform, Load (ETL) ist ein Prozess, bei dem Daten aus mehreren, gegebenenfalls unterschiedlich strukturierten Datenquellen in einer Zieldatenbank vereinigt werden.
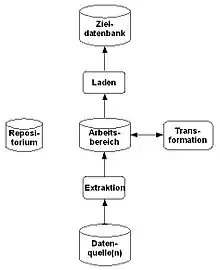
- Extraktion
- der relevanten Daten aus verschiedenen Quellen
- Transformation
- der Daten in das Schema und Format der Zieldatenbank
- Laden
- der Daten in die Zieldatenbank
Bekannt ist der Prozess vor allem durch die Verwendung beim Betrieb eines Data-Warehouses. Hier müssen große Datenmengen aus mehreren operationalen Datenbanken konsolidiert werden, um dann im Data-Warehouse gespeichert zu werden.
Funktionsweise
Das Verfahren lässt sich als allgemeiner Prozess der Informationsintegration auch auf andere Datenbanken übertragen. Dabei gilt es, heterogen strukturierte Daten aus unterschiedlichen Quellen zusammenzuführen. Der Prozess muss sowohl effizient ablaufen, um Sperrzeiten bei den Quellen zu minimieren, als auch die Qualität der Daten sichern, damit sie trotz möglicher Änderungen der Quellen vollständig und konsistent im Data-Warehouse gehalten werden können.
Neuere Einsatzgebiete von Data-Warehouses erfordern das beschleunigte Hinzufügen von Daten. Der Fokus von ETL richtet sich daher zunehmend auf die Minimierung der Latenzzeit, bis die Daten aus den Quellsystemen zur Verfügung stehen. Hierzu ist eine häufigere Durchführung des Prozesses notwendig.
Im Allgemeinen wird bei allen Schritten ein Repositorium eingebunden, das insbesondere die notwendigen Datenbereinigungs- und Transformationsregeln sowie die Schemadaten als Metadaten aufnimmt und langfristig hält.
Die meisten ETL-Programmsysteme haben Routinen zum Data-Profiling. Bei Migrationen aus Altsystemen ist oft die Datenqualität der Quellsysteme nicht absehbar. Diese wird im Data Profiling gemessen. Die Mappingregeln in der Transformation müssen darauf abgestimmt sein, um ein Funktionieren des Zielsystems nach dem Load zu gewährleisten.
Extraktion
Bei der Extraktion wird in der Regel ein Ausschnitt der Daten aus den Quellen extrahiert und für die Transformation bereitgestellt. Die Quellen können aus verschiedenen Informationssystemen mit verschiedenen Datenformaten und -strukturen bestehen. Hierbei findet eine Schematransformation vom Schema der Quelldaten in das Schema des Arbeitsbereichs statt.
Um das Data-Warehouse mit aktuellen Daten zu versorgen, muss die Extraktion regelmäßig stattfinden. Dies kann synchron mit den Quellen oder asynchron geschehen. Bei synchroner Extraktion wird jede Änderung am Quellsystem sofort an das Data-Warehouse propagiert. Dieser Ansatz ermöglicht das Konzept des Real-Time-Data-Warehousing, welches den Bedarf nach sofort verfügbaren Daten unter Wahrung der Trennung von operativen und auswertenden Systemen deckt. Die asynchrone Extraktion kann periodisch, ereignisgesteuert oder anfragegesteuert erfolgen.
- periodisch
- Die Quelle erzeugt in regelmäßigen Abständen Auszüge ihrer Daten, die regelmäßig abgefragt werden.
- ereignisgesteuert
- Die Quelle erzeugt bei bestimmten Ereignissen – beispielsweise nach einer bestimmten Anzahl von Änderungen – einen Auszug.
- anfragegesteuert
- Die Quelle stellt Auszüge erst auf Anfrage bereit.
Hierbei ist zu beachten, dass der Zugriff auf die Quellsysteme nur während deren „Ruhezeit“ stattfinden sollte, also nach der Nachverarbeitung. Bei den Auszügen aus den Quellen kann es sich um ganze oder teilweise Snapshots handeln oder um Teile von Logdateien, in denen alle Änderungen zum jeweils letzten Snapshot aufgelistet sind.
Transformation
Die aus den unterschiedlich strukturierten Quellen stammenden Daten, denen unterschiedliche Wertebereiche zugrunde liegen können, müssen in ein einheitliches Datenschema transformiert werden. Die Transformation besteht im Wesentlichen aus der Anpassung der Daten an die vorgegebenen Zielstrukturen (Schema-Mapping) des Arbeitsspeichers. Unter Transformation fällt hierbei auch die meist aufwändige Datenbereinigung. Die Transformation findet in einem eigenen Arbeitsbereich (Staging-Area) statt.
Typische Transformationen und Transformationsschritte kann man in zwei Bereiche einteilen:
- Syntaktische Transformationen
- Hier geht es um die Verbesserung, Umsetzung oder Korrektur der Daten basierend auf formalen Aspekten. Die Daten werden gemäß der im Zielsystem notwendigen und angewandten Syntax modifiziert. Ein Beispiel dafür ist die Anpassung von Datentypen (z. B. numerische Darstellung des Tagesdatums YYYYMMDD hin zu einem standardisierten Datumsformat wie ISO 8601).
- Semantische Transformationen
- Hierbei werden die Daten auf inhaltliche Aspekte überprüft und wenn nötig modifiziert und angereichert. Hierunter fallen z. B.
- Eliminierung von Duplikaten (Objektidentifizierung),
- Schlüsselanpassung (z. B. unterschiedliche Ländercodierungen hin zu DIN ISO Ländercodes),
- Anpassung von Datenwerten (z. B. unterschiedliche Codierung des Geschlechts wie 1 (weiblich), 2 (männlich) hin zu f (female) und m (male)),
- Umrechnung von Maßeinheiten (z. B. unterschiedliche Volumina wie Gallone und Hektoliter hin zu Liter),
- Aggregation (z. B. Einzelumsätze eines Vertriebsprodukts hin zu monatlichen Umsätzen je Vertriebsprodukt),
- Anreicherung der gelesenen Daten aus den Quellsystemen mit Zusatzinformation. Beispiele für Zusatzinformationen sind extern beschaffte demographische Daten, eindeutige Firmenkennzeichner wie D&B-Nummer, die sogenannte D-U-N-S-Nummer, und alle anderen Daten, deren Kombination mit den Daten der eigenen Systeme zu einer informativen Aufwertung der verarbeiteten Daten führen können.
- Hierbei werden die Daten auf inhaltliche Aspekte überprüft und wenn nötig modifiziert und angereichert. Hierunter fallen z. B.
Laden
Beim Laden müssen die Daten aus dem Arbeitsbereich in das Data-Warehouse eingebracht werden. Dies soll in der Regel möglichst effizient geschehen, so dass die Datenbank während des Ladens nicht oder nur kurz blockiert wird und ihre Integrität gewahrt wird. Zusätzlich kann eine Versionshistorie angefertigt werden, in der Änderungen protokolliert werden, so dass auf Daten zurückgegriffen werden kann, die zu früheren Zeitpunkten gültig waren (Siehe Slowly Changing Dimensions).
Im Hinblick auf die Integration der Daten im Data-Warehouse ist eine weitere Schematransformation vom Schema des Arbeitsbereichs in das Schema des Data-Warehouses notwendig.
Tools/Hersteller
Auch wenn man ETL-Prozesse mit eigenen Programmen umsetzen kann, sprechen folgende Gründe für den Einsatz von Standardwerkzeugen:
- Jedes Standardwerkzeug unterstützt den Zugriff auf die gängigen Datenbanksysteme sowie ERP- und Dateisysteme.
- Die Entwicklung wird durch geeignete Transformationen, Methoden und Verfahren (wie Visualisierung des Datenflusses, Fehlerbehandlung, Scheduling) unterstützt.
- Meist sind auch für High-Performance-Loading die entsprechenden Voraussetzungen bereits im Standardwerkzeug implementiert. Eine genaue Kenntnis der Mechanismen der Zielsysteme entfällt dadurch meistens.
- Entwicklung und Wartung der ETL-Prozesse sind in der Regel durch visualisierende Standardwerkzeuge einfacher und kostengünstiger durchzuführen als bei Systemen auf Basis entwickelter Programme unter Verwendung von Programmiersprachen.
Führende Hersteller von Programmen zur Datenintegration: SAS Institute, IBM (Produkt: Information Server), Informatica (PowerCenter), SAP-Business Objects (BusinessObjects Data Integrator), SAP Data Services, Altova (MapForce), Oracle (Oracle Warehouse Builder, Oracle Data Integrator) und Microsoft (SQL Server Integration Services). Ein weiterer Anbieter ist Comit mit der Data Management Suite (DMS).
Die bekanntesten Tools im Open-Source-Umfeld sind Kettle Pentaho Data Integration, Scriptella ETL, CloverETL, Talend Open Studio und das Perl-Framework Catmandu,[1] das aus dem Bibliotheksumfeld kommt.
Literatur
- Andreas Bauer, Holger Günzel: Data-Warehouse-Systeme – Architektur, Entwicklung, Anwendung. dpunkt, Heidelberg 2013, ISBN 978-3-89864-785-4. online (Memento vom 30. Dezember 2013 im Internet Archive)
- Wolfgang Lehner: Datenbanktechnologie für Data-Warehouse-Systeme, Konzepte und Methoden. dpunkt, Heidelberg 2003, ISBN 3-89864-177-5.
Einzelnachweise
- LibreCat ist ein offenes Konsortium aus anfänglich 3 Universitätsbibliotheken, die an Catmandu arbeiten.