Sternschema
Das Sternschema ist eine besondere Form eines Datenmodells, dessen Ziel nicht die Normalisierung ist, sondern eine Optimierung auf effiziente Leseoperationen. Hauptanwendungsfeld sind Data-Warehouse und OLAP-Anwendungen.
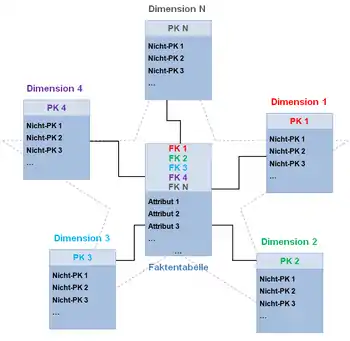
Die Bezeichnung Sternschema rührt daher, dass die Tabellen sternförmig angeordnet werden: Im Zentrum steht eine Faktentabelle, um die sich mehrere Dimensionstabellen gruppieren.
Ein Sternschema liegt in der Regel denormalisiert vor. Mögliche Anomalien und ein erhöhter Speicherbedarf werden dabei aus Performancegründen in Kauf genommen. Eine Verbesserung ist durch das dem Sternschema verwandte Schneeflockenschema möglich. Dort müssen allerdings mehrstufige Dimensionstabellen über Join-Abfragen verknüpft werden.
Definition
Als logisches Datenbankschema für Data-Warehouse-Anwendungen hat sich das sogenannte Sternschema durchgesetzt. Dieses Schema setzt sich aus einer Faktentabelle und mehreren Dimensionstabellen zusammen, welche abfragefreundlich um eine Faktentabelle sternförmig geordnet werden und sich bei diesem Schema auf genau eine Faktentabelle beziehen. Der Name dieses Schemas leitet sich daher aus der sternförmigen Anordnung der Dimensionstabellen um die im Mittelpunkt liegende Faktentabelle ab. Die angesprochene Faktentabelle verfügt über informationstragende Attribute, wie z. B. Umsätze, Zeiträume, Kosten etc., und als Primärschlüssel einen zusammengesetzten Schlüssel aus den Primärschlüsseln der beteiligten Dimensionstabellen.
Dabei steht jede Dimensionstabelle in einer 1:n-Beziehung zu einer Faktentabelle. Die 1:n-Beziehung wird durch einen Schlüssel der Dimensionstabelle und einen Fremdschlüssel der Faktentabelle vermittelt. Die Faktentabelle integriert m:n-Beziehungen implizit in einer einzigen Tabelle und enthält aus diesem Grunde viel Redundanz. Der Schlüssel der Faktentabelle besteht aus dem Primärschlüssel der jeweiligen Dimensionstabelle als Fremdschlüssel.
Das Sternschema erlaubt die Auswahl, Zusammenfassung und Navigation der Messwerte bzw. Fakten. Die Dimensionstabellen sind üblicherweise nicht normalisiert und liegen deshalb denormalisiert vor: Es existieren funktionale Abhängigkeiten zwischen Nicht-Schlüsselattributen, so dass die 3. Normalform (3NF) verletzt wird. Diese Verletzung wird jedoch bei diesem Schema in Kauf genommen, denn die Datenstruktur ermöglicht eine bessere Verarbeitungsgeschwindigkeit zu Lasten der Datenintegrität und des Speicherplatzes.
Fakten- und Dimensionstabellen
Die zu verwaltenden Daten werden als Fakten bezeichnet; sie werden typischerweise fortlaufend in der Faktentabelle gespeichert. Andere Namen für die Fakten sind Metriken, Messwerte oder Kennzahlen. Faktentabellen können sehr groß werden, was ein Data-Warehouse zwingt, die Daten nach und nach zu verdichten (aggregieren) und schließlich nach einer Halteperiode zu löschen oder auszulagern (Archivierung). Die Tabellen enthalten Kenn- oder Ergebniszahlen, die sich aus dem laufenden Geschäft ableiten lassen und wirtschaftliche Leistung widerspiegeln, wie z. B. Profitabilität, Kosten, Leistung/Erlös, Ausgaben, Einnahmen, Aufwände, Erträge etc. Jedoch erst wenn diese Zahlen in einen Zusammenhang gebracht werden, ergeben sie auch einen Sinn. Ein Beispiel sei, dass Umsätze in einem bestimmten Bereich mit festgelegten Produkten in einem definierten Zeitraum verglichen werden, was Dimensionen widerspiegelt, in denen die wirtschaftlichen Leistungen ausgewertet und analysiert werden.
Im Gegensatz dazu enthält die Dimensionstabelle die „beschreibenden“ Daten. Die Faktentabelle enthält Fremdschlüssel auf die Dimensionseinträge, die deren Bedeutung definieren. Typischerweise stellt die Gesamtmenge der Fremdschlüssel auf die Dimensionstabellen gleichzeitig den Primärschlüssel in der Faktentabelle dar. Das impliziert, dass es jeden Eintrag zu einer Kombination von Dimensionen nur einmal geben kann.
Dimensionstabellen sind vergleichsweise statisch und üblicherweise erheblich kleiner als Faktentabellen. Die Bezeichnung „Dimension“ rührt daher, dass jede Dimensionstabelle eine Dimension eines mehrdimensionalen OLAP-Würfels darstellt.
Aufgrund der Existenz funktionaler Abhängigkeiten zwischen Nicht-Schlüsselattributen wird in den Dimensionstabellen bewusst die dritte Normalform verletzt. Um der 3NF zu genügen, müsste die betreffende Dimensionstabelle in einzelne hierarchische Tabellen zerlegt werden, jedoch aus Gründen der Performance sieht man bei dem Sternschema von einer Normalisierung der Dimensionstabellen ab und akzeptiert die hierdurch auftretende Redundanz.
Vorteil der Trennung von Fakten und Dimensionen ist, dass die Fakten nach jeder Dimension generisch und unabhängig analysiert werden können. Eine OLAP-Anwendung benötigt kein „Wissen“ über die Bedeutung einer Dimension. Die Interpretation ist allein dem Benutzer überlassen.
Die Größe von Dimensionstabellen sei jedoch zu beachten. Faktentabellen können in einem Sternschema oft mehr als 10 Millionen Datensätze umfassen. Dimensionstabellen sind zwar kleiner, können bei einzelnen Dimensionen jedoch eine erhebliche Größe annehmen. Zur Verringerung solcher großer Datenbestände und den damit einhergehenden verkürzten Zugriffszeiten können einzelne, sehr große Dimensionstabellen durch Normalisierung in ein Schneeflockenschema überführt werden.
Slowly Changing Dimensions
Ein Problem des Sternschemas ist, dass Daten in den Dimensionstabellen über einen langen Zeitraum hinweg einen Bezug auf Daten in den Faktentabellen haben. Über die Zeit hinweg können aber auch Änderungen der Dimensionsdaten notwendig werden. Diese Änderungen dürfen sich aber in der Regel nicht auf Daten vor der Änderung auswirken. Wenn sich beispielsweise der Verkäufer für eine Produktgruppe ändert, dann darf der jeweilige Eintrag in der Dimensionstabelle nicht einfach überschrieben werden. Stattdessen muss ein neuer Eintrag generiert werden, da sonst die Verkaufszahlen des vorherigen Verkäufers nicht mehr feststellbar wären. Ein Konzept zur Vermeidung solcher Konflikte sind Slowly Changing Dimensions. Dieses Konzept fasst im Data-Warehousing Methoden zusammen, um Änderungen in Dimensionstabellen zu erfassen und ggf. historisch zu dokumentieren.
Eigenschaften Sternschema
- Dimensionentabellen
- Primärschlüssel zur Identifizierung der Dimensionenwerte
- Abbildung der Dimensionenhierarchie durch Attribute
- Denormalisiert, das heißt nicht normalisierte Dimensionstabellen
- Faktentabelle
- Fremdschlüssel zu den Dimensionentabellen, das heißt die unterste Ebene jeder Dimension wird als Schlüssel in die Faktentabelle aufgenommen
- Fremdschlüssel auf die Dimensionen bilden zusammengesetzten Primärschlüssel für die Fakten
Vor- & Nachteile Sternschema
Vorteile
- schnelle Anfrageverarbeitung: Analytische Anfragen befinden sich typischerweise auf höheren Aggregationsniveaus und durch den Verzicht auf eine Normalisierung der Dimensionstabellen werden Joins eingespart. Des Weiteren kann ein spezieller Join (Star Join) gut optimiert werden.
- Datenvolumen: Dimensionstabellen sind im Vergleich zu Fakttabellen sehr klein. Das zusätzliche Datenvolumen durch eine Denormalisierung der Dimensionstabelle muss nicht beachtet werden.
- Änderungsanomalien können leicht kontrolliert werden, da kaum Änderungen an Klassifikationen stattfinden.
- einfaches, intuitives Datenmodell: Das Sternschema besitzt wesentlich weniger Relationen als ein konvergierendes Schneeflockenschema und die JOIN-Tiefe ist nicht größer 1
- Verständlichkeit & Nachvollziehbarkeit: eine Modernisierung des Berichtswesens ist durch das Sternschema möglich. Dafür können Datensammlungen zur Trenderkennung und für das Data-Mining erstellt werden.
Nachteile
- Verschlechtertes Antwortzeitverhalten bei häufigen Abfragen sehr großer Dimensionstabellen (Browsing-Funktionalität)
- Redundanz innerhalb einer Dimensionstabelle durch das mehrfache Speichern identischer Werte bzw. Fakten.
- Aggregationsbildung ist schwierig
Sternschema vs. Schneeflockenschema (normalisiert)
| Sternschema | Schneeflockenschema | |
|---|---|---|
| Ziel |
|
|
| Ergebnis |
|
|
Anforderungsdiagramm des Sternschemas
1. Betriebliche Anforderungen sammeln:
Aufbau eines Sternschemas beginnt mit der Frage
- Welche Fakten interessieren nach welchen Kriterien?
- Verfügbare Daten, geforderte Auswertungen & Tabelleninhalte
2. Anforderungsdiagramm erstellen:
Definierte Spezifikationen lassen sich in einem Anforderungsdiagramm subsumieren
- Erforderliche Indikatoren:
- Attribute, die das Ergebnis einer Unternehmenseinheit bewerten
- Frage: Wie gut?
- Dimensionen:
- Attribute, entlang derer die Indikatoren gemessen werden
- Fragen: Was? Wann? Wo?
- Kategorien:
- Wertebereiche einer Dimension
- Fragen: Wie genau?
Star Join
Das Sternschema führt bei typischen Abfragen zu sogenannten Star Joins, welche wie folgt aussehen:
SELECT Fakt- oder Dimensionsattribut
FROM Fakt- oder Dimensionstabellen
WHERE Bedingung
GROUP BY Fakt- oder Dimensionsattribut
ORDER BY Fakt- oder Dimensionsattribut
Beispiel

Zum Beispiel wählt die Abfrage mehrere relevante Measures aus der Faktentabelle aus, verknüpft die Faktenzeilen anhand der Ersatzschlüssel mit einer oder mehreren Dimensionen, belegt die Geschäftsspalten der Dimensionstabellen mit Filterprädikaten, gruppiert nach einer oder mehreren Geschäftsspalten und aggregiert schließlich die aus der Faktentabelle abgerufenen Measures über einen bestimmten Zeitraum. In dem folgenden Beispiel werden die Summe der Verkäufe eines Produktes über einen definierten Zeitraum dargestellt.
select ProductAlternateKey, CalendarYear, sum(SalesAmount)
from FactInternetSales Fact
join DimProduct
on DimProduct.ProductKey = Fact.ProductKey
join DimTime
on Fact.OrderDateKey = TimeKey
where ProductAlternateKey like 'XYZ%'
and CalendarYear between 2008 and 2009
group by ProductAlternateKey,CalendarYear
Die Anzahl der verwendeten Joins (hier in diesem Beispiel sind es 2 Joins) sind beim Sternschema im Gegensatz zum Schneeflockenschema unabhängig von der Länge der Aggregationspfade.
Siehe auch
Literatur
- A. Kemper, A. Eickler: Datenbanksysteme. Eine Einführung. 6. Auflage. Oldenbourg Wissenschaftsverlag, München 2006, ISBN 3-486-57690-9.
- R. Kimball, M. Ross: The Data Warehouse Toolkit. The Complete Guide to Dimensional Modeling. 2. Auflage. John Wiley & Sons, New York 2002, ISBN 0-471-20024-7 (englisch).
- P. Rob, C. Coronel, K. Crockett: Database systems: design, implementation & management. Cengage Learning, London 2008, ISBN 1-84480-732-0 (englisch).
- L. Langit: Foundations of SQL Server 2005 Business Intelligence. 1. Auflage. Apress, New York 2007, ISBN 978-1-59059-834-4 (englisch).