Relationale Algebra
In der Theorie der Datenbanken versteht man unter einer relationalen Algebra oder Relationenalgebra eine Menge von Operationen zur Manipulation von Relationen. Sie ermöglicht es, Relationen zu filtern, zu verknüpfen, zu aggregieren oder anderweitig zu modifizieren, um Anfragen an eine Datenbank zu formulieren.[1]
Normalerweise werden Anfragen und Programme nicht direkt in einer relationalen Algebra formuliert, sondern in einer deklarativen Sprache wie SQL,[3] XQuery[4] SPARQL[5] oder auch Datalog[6]. Diese Programme und Anfragen werden üblicherweise zunächst in eine (i. Allg. erweiterte) relationale Algebra übersetzt. Der entstehende Operatorbaum wird dann mit Hilfe relationaler Gesetze transformiert, um eine möglichst effiziente Auswertung der Anfragen zu ermöglichen.[7]
Geschichte und Bedeutung
Im Jahr 1941 stellte Alfred Tarski in seinem Papier “On the calculus of relations” erstmals Ideen einer relationalen Algebra vor.[8] Insbesondere führte er die relationalen Operationen „Vereinigung“, „Durchschnitt“ und „Join“ ein, wobei er sich allerdings auf zweistellige Relationen beschränkte.
Am Ende seines Artikels erwähnt er, dass er eigentlich nicht so sehr das Ziel hatte, neue Ergebnisse zu präsentieren, als vielmehr das Interesse an einer bestimmten logischen Theorie zu wecken, die bislang nicht beachtet wurde:
“The aim of this paper has been, not so much to present new results, as to awaken interest in a certain neglected logical theory, and to formulate some new problems concerning this theory.”
Ende der 1960er-Jahre entwickelte Edgar F. Codd am IBM Research Laboratory in San Jose die Grundlagen der heutigen relationalen Algebra.[9][10] Ob ihn die Arbeit Tarskis dazu inspirierte, ist nicht bekannt. Zu Beginn seines Papiers von 1969 stellt er die Behauptung auf, dass das relationale Modell in vielen Aspekten dem Graphenmodell und dem Netzwerkmodell, die zu dieser Zeit „en vogue“ (franz. "in Mode") waren, überlegen sei.
“The first part of this paper is concerned with an explanation
of a relational view of data. This view (or model) of
data appears to be superior in several respects to the graph or
network model [1, 2] presently in vogue.”
Er bezieht sich damit auf die Tatsache, dass die Dauer der Beantwortung von Anfragen sehr stark vom Aufbau des jeweiligen Netzwerks abhängt. Sofern Daten abgerufen werden sollen, die im Netzwerk benachbart sind, muss der Benutzer nur sehr kurz auf eine Antwort warten. Sind die gewünschten Daten jedoch im Netzwerk stark verstreut, kann die Wartezeit unzumutbar lang werden. Die Datenbankentwickler mussten bei der Erstellung eines Netzwerkmodells von vorneherein sämtliche denkbaren Anfragen berücksichtigen, da nachträgliche Änderungen am Datenmodell nur noch sehr schwer umgesetzt werden konnten. Um dieses Problem zu beheben, hatte Codd die Idee, die Daten nicht mehr in einem Netzwerk zu speichern, sondern in Relationen (Tabellen), die je nach Anfrage unterschiedlich miteinander verknüpft werden können:
“Future users of large data banks must be protected from
having to know how the data is organized in the machine (the
internal representation).”
Er wagte folgende geradezu prophetische Prognose, dass Datenbanken künftig viele Relationen in gespeicherter Form enthalten würden:
“The large, integrated data banks of the future will contain many relations of various degrees in stored form.”
Ende 1970, d. h. im selben Jahr, in dem Codds Arbeit publik wurde, stellen Rudolf Bayer und Ed McCreight den B-Baum vor, eine Datenstruktur, die es ermöglicht, Relationen mit einer großen Anzahl von Tupel so auf einer Festplatte zu speichern, dass der lesende Zugriff auf Tupel sowie die Modifikation von Tupeln hocheffizient erfolgen kann.[11][12]
In den 1970er-Jahren begann auf Basis dieser beiden Arbeiten die Erfolgsgeschichte der Relationalen Datenbanken einschließlich der zugehörigen Sprache SQL. An Codds Arbeitsstätte, d. h. am IBM Research Laboratory in San Jose, wurden die Sprache SEQUEL sowie das experimentelle Datenbanksystem System R entwickelt. Später wurde SEQUEL in SQL umbenannt. Zu Beginn der 1980er-Jahre gab es für die Anfragesprache SQL die ersten kommerziellen relationalen Datenbanksysteme: Db2 von IBM und Oracle von Relational Software Inc.[13] Heute ist SQL aus der Welt der Datenbanken nicht mehr wegzudenken (siehe beispielsweise Kategorie:Relationales Datenbankmanagementsystem). Aber auch diverse weitere Sprachen, wie zunächst QBE[14] oder QUEL[15] und später Datalog,[6] XQuery[4] oder SPARQL,[5] basieren letztendlich auf der Idee Codds, Relationen zum Speichern von Daten einzusetzen.
Allgemein
Eine relationale Algebra definiert Operationen, die sich auf eine Menge von Relationen anwenden lassen. Damit können Relationen beispielsweise gefiltert, verknüpft oder aggregiert werden. Die Ergebnisse aller Operationen sind ebenfalls Relationen. Aus diesem Grund bezeichnet man die Relationenalgebra als abgeschlossen.
Ihre Bedeutung hat die Relationenalgebra als theoretische Grundlage für Abfragesprachen in relationalen Datenbanken. Hier werden die Operationen der relationalen Algebra in sogenannten Datenbankoperatoren implementiert. Wenn jede Operation der relationalen Algebra in der Abfragesprache durch (mindestens) einen Ausdruck umgesetzt werden kann, heißt sie relational vollständig; der Ausdruck kann hierbei mehrere Datenbankoperatoren verknüpfen. Wenn jede Operation auch durch (genau) einen Datenbankoperator umgesetzt werden kann, heißt sie streng relational vollständig; es darf also immer nur genau ein Datenbankoperator in ein und demselben umsetzenden Ausdruck enthalten sein. Wenn die Bedingung der strengen relationalen Vollständigkeit auch in die andere Richtung gilt, es also zu jedem Datenbankoperator eine entsprechende Operation der relationalen Algebra gibt, dann heißt die Abfragesprache äquivalent zur relationalen Algebra, kurz: relational äquivalent.[16]
Da es für die relationale Algebra (mehrere) minimale Mengen von Operationen gibt, aus denen alle weiteren Operationen zusammengesetzt werden können, reicht es für die (streng) relationale Vollständigkeit aus, die Abfragesprache mit diesen „Basisoperationen“ zu vergleichen. Das folgt daraus, dass die relationale Algebra trivialerweise selbst-äquivalent ist und durch ein minimales System aus Operationen schon vollständig (im Hinblick auf Operationen) beschrieben ist. Ein übliches minimales System aus Operationen besteht aus den sechs Operationen: Projektion, Selektion, Kreuzprodukt, Vereinigung, Differenz und Umbenennung.
Die relationale Algebra wird wegen ihrer theoretischen Klarheit oft als Bewertungsmaßstab für die Mächtigkeit bzw. Ausdruckskraft von Abfragesprachen genutzt, u. a. mittels der gerade beschriebenen Vergleichsbegrifflichkeiten. Allerdings darf man von der größeren Nähe einer Abfragesprache zur relationalen Algebra nicht auf deren größere Mächtigkeit schließen. Abfragesprachen, die relational vollständig oder sogar streng relational vollständig sind, haben oft einen deutlich größeren Funktionsumfang als dies durch die alleinige Umsetzung der Relationen-Algebra-Operationen möglich wäre. Zum Beispiel ist in der relationalen Algebra die Möglichkeit der Bildung der transitiven Hülle einer Relation, was etwa bei rückbezüglichen Relationen interessant ist, nicht gegeben. Von der strengen relationalen Vollständigkeit einer Abfragesprache lässt sich eher auf eine Mindestfunktionalität, von der relationalen Äquivalenz eher auf eine Maximalfunktionalität schließen, während die nichtstrenge relationale Vollständigkeit die wenigsten konkreten Informationen über die Abfragesprache liefert.
Im Gegensatz zu den Kalkülen ist die relationale Algebra sicher, d. h., sie liefert in endlicher Zeit ein endliches Resultat. Eine relationale Algebra ist darüber hinaus ein Beispiel für eine prozedurale Sprache; im Unterschied zu Kalkülen, die meist als deskriptive Sprachen formalisiert sind.
Operationen
Mengenoperationen
Um Mengenoperationen auf den Relationen und durchführen zu können, müssen beide miteinander kompatibel sein. Die Typkompatibilität zweier Relationen ist gegeben, wenn


- und den gleichen Grad (Attributelementanzahl) haben
- der Wertebereich der Attribute von und identisch ist
Die Typkompatibilität wird auch Vereinigungsverträglichkeit genannt.
Vereinigung
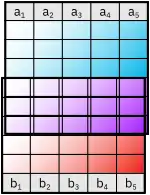
Bei der Vereinigung werden alle Tupel der Relation mit allen Tupeln der Relation zu einer einzigen Relation vereint. Voraussetzung dafür ist, dass und das gleiche Relationenschema haben. Das heißt, sie haben gleiche Attribute und Attributtypen. Duplikate werden bei der Vereinigung gelöscht.

Definition

Beispiel
|
|
|
Voraussetzung
- Vereinigungsverträglichkeit von und
Schnittmenge (Intersection)

Das Ergebnis der Durchschnittsoperation sind all die Tupel, die sich sowohl in als auch in finden lassen. Der Mengendurchschnitt lässt sich auch durch die Mengendifferenz ausdrücken:


Definition

Beispiel
|
|
|
Voraussetzung
- Vereinigungsverträglichkeit von und
Differenz

Statt der in der Mengenlehre üblichen Schreibweise für die Differenz zweier Mengen, , wird in der relationalen Algebra häufig geschrieben. Es handelt sich hierbei jedoch ausdrücklich nicht um die übliche Subtraktion. Bei der Operation werden aus der Relation alle Tupel entfernt, die auch in der Relation vorhanden sind. Die Differenz (ebenso wie die symmetrische Differenz) ist keine monotone Operation, daher ist auch die relationale Algebra im Vergleich zu anderen deklarativen Anfragesprachen (z. B. Datalog) nicht monoton.



Definition

Beispiel
|
|
|

Voraussetzung
- Vereinigungsverträglichkeit von und
Symmetrische Differenz

Bei der symmetrischen Differenz handelt es sich um die Menge aller Tupel, die entweder in oder in , aber nicht in beiden gleichzeitig enthalten sind.


Die Operation kann aus den Grundoperationen abgeleitet werden:

Beispiel
|
|
|
Voraussetzung
- Vereinigungsverträglichkeit von R und S
Kartesisches Produkt (Kreuzprodukt)

Das kartesische Produkt ist eine Operation, welche dem kartesischen Produkt aus der Mengenlehre ähnelt.

Das Resultat des kartesischen Produkts ist die Menge aller Kombinationen der Tupel aus und , d. h., jede Zeile der einen Tabelle wird mit jeder Zeile der anderen Tabelle kombiniert. Wenn alle Merkmale (Spalten) verschieden sind, so umfasst die Resultatstabelle die Summe der Merkmale der Ausgangstabellen. Gleichnamige Merkmale der zwei Tabellen werden durch Voranstellen des Tabellennamens referenziert. Die Anzahl der Tupel (Zeilen) in der Resultatstabelle ist das Ergebnis der Multiplikation der Zeilenanzahlen der Ausgangstabellen.
Definition
Zwei beliebige Relationen und sind gegeben. Das kartesische Produkt ist definiert durch

Beispiel
|
|
|
Projektion
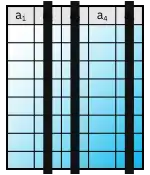
Die Projektion entspricht der Projektionsabbildung aus der Mengenlehre und kann auch Attributbeschränkung genannt werden. Sie extrahiert einzelne Attribute aus der ursprünglichen Attributmenge und ist somit als eine Art Selektion auf Spaltenebene zu verstehen, das heißt, die Projektion blendet Spalten aus. Wenn die Attributliste ist, schreibt man oder in der linearen Schreibweise . heißt auch Projektionsliste. Duplikate in der Ergebnisrelation werden eliminiert.



Definition
Sei eine Relation über und .



Die , das heißt, die Tupel erhalten nur die Attribute aus der Attributliste .

Beispiel
|
|
|


Voraussetzung
- Die angegebenen Spalten müssen in enthalten sein.
Selektion

Bei der Selektion kann man mit einem Vergleichsausdruck (Prädikat) festlegen, welche Tupel in die Ergebnismenge aufgenommen werden sollen. Es werden also Tupel („Zeilen“) ausgeblendet. Man schreibt oder in der linearen Schreibweise . Ausdruck heißt dann Selektionsbedingung.


Definition
Sei eine Relation.

Ausdruck bezeichnet dabei eine Formel. Diese kann bestehen aus:
- Konstantenselektionen Attribut Konstante, wobei ein üblicher (passender) Vergleichsoperator ist.
- Attributselektionen Attribut Attribut
- Eine Verknüpfung einer Formel mit logischen Prädikaten (Klammerung wie üblich).


Beispiel
|
|
|


Voraussetzung
- Jedes Element der angegebenen Spalte muss über den Bedingungsoperator mit dem Vergleichswert vergleichbar sein.
Join
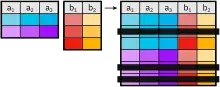
Ein Join (zu deutsch Verbund) bezeichnet die beiden hintereinander ausgeführten Operationen kartesisches Produkt und Selektion. Die Selektionsbedingung ist dabei üblicherweise ein Vergleich von Attributen , wobei ein passender Vergleichsoperator ist. Man bezeichnet den allgemeinen Verbund daher auch als -Verbund (Theta-Verbund). Ein Spezialfall des allgemeinen Verbundes ist der Equi-Join (siehe unten).

Definition
Für zwei Relationen und ist das Ergebnis des allgemeinen Verbundes mit einer Formel Ausdruck als Selektionsbedingung



Die Ableitung ist:

Beispiel
|
|
|
|

Joinverfälschung
Bei der Joinverfälschung wird als erstes die Tabelle gesplittet, bis auf eine Spalte . Die 2 Tabellen werden dann gejoint über die gemeinsame Spalte .

Sei und , dann gilt:



Beispiel

|
|

Equi-Join
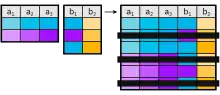

Beim Equi-Join (auch Gleichverbund) wird als erstes das kartesische Produkt gebildet. Dann erfolgt die Selektion mit der Bedingung, dass der Inhalt bestimmter Spalten identisch sein muss. Der Equi-Join ist ein allgemeiner Verbund mit einer Formel der Form .

Definition
Für die Relationen und dazugehörige Attribute (ist Attribut von ) und (ist Attribut von ) ist der Equi-Join




Beispiel
Hier:

|
|
|
|

Natural Join
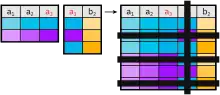
Der Natural Join setzt sich zusammen aus dem Equi-Join und einer zusätzlichen Ausblendung der duplizierten Spalten (Projektion). Der Join erfolgt über die Attribute (Spalten), die in beiden Relationen die gleiche Bezeichnung haben. Gibt es keine gemeinsamen Attribute, so ist das Ergebnis des natürlichen Verbundes das kartesische Produkt. Der natürliche Verbund ist kommutativ und assoziativ, das heißt, es gilt sowie , was eine Rolle bei der Optimierung von Anfragen spielt. Die Anzahl der Attribute der Ergebnisrelation ist die Summe der Anzahlen der beiden Ausgangsrelationen abzüglich der Anzahl der Verbundattribute.


Definition
Für zwei Relationen und ist das Ergebnis des natürlichen Verbundes



Beispiel
|
|
|

Semi Join
Der Semi Join berechnet den Anteil eines Natural Joins, welcher nach einer Reduktion auf die linke Relation übrig bleibt.
Definition
Für zwei Relationen und ist das Ergebnis des halben natürlichen Verbundes

Beispiel
|
|
|

Outer Join
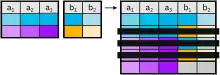
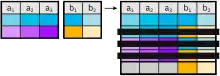
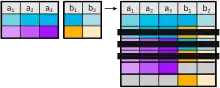
Im Gegensatz zum Equi-Join werden beim Outer-Join auch die Tupel der linken (left outer join) bzw. der rechten (right outer join) Tabelle in die Ergebnisrelation mit aufgenommen, die keinen Join-Partner finden. Die nicht vorhandenen Attribute der Join-Relation werden mit Nullwerten aufgefüllt.
Die Kombination aus Left- und Right-Outer-Join wird Outer-Join oder Full-Outer-Join genannt. Dabei werden alle Tupel in die Ergebnisrelation aufgenommen und jene Attribute eines Tupels mit Nullwerten aufgefüllt, die keinen Join-Partner in der jeweils anderen Relation gefunden haben.
Der Outer-Join kann mit oder ohne (natural outer join) Join-Bedingung verwendet werden.
Beispiel
|
|
|

Umbenennung
Durch diese Operation können Attribute und Relationen umbenannt werden. Diese Operation ist wichtig, um
- Joins von unterschiedlichen benannten Relationen zu ermöglichen,
- kartesische Produkte zu ermöglichen, wo es gleiche Attributnamen gibt, insbesondere auch mit der gleichen Relation
- Mengenoperationen zwischen Relationen mit unterschiedlichen Attributen zu ermöglichen.
Die Schreibweise ist , linear .


Definition
Wir konstruieren eine neue Tupelmenge aus der alten:


Beispiel
|
|

Division
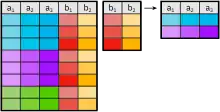
Definition
Da die Division eine abgeleitete Operation ist, definieren wir sie mit Hilfe der anderen Operationen der Relationenalgebra. Seien Relationen und die zu sowie die zu dazugehörigen Attributmengen. .


Die Division ist dann definiert durch:

Anschaulich gesprochen enthält also diejenigen Attribute aus , welche in jeder Kombination mit den Attributen aus in vorkommen.


Beispiel
Gegeben ist eine Relation , die Väter und Mütter, deren Kinder und das Alter dieser Kinder enthält. Zusätzlich dazu ist eine Relation gegeben, die einige Kinder und deren Alter enthält: Maria (4) und Sabine (2). Dividiert man durch , so erhält man als Ergebnis eine Relation, die nur noch diejenigen Ehepaare enthält, die sowohl eine Tochter Maria mit Alter 4 als auch eine Tochter Sabine mit Alter 2 haben:
|
|
|
Die Division wird dann eingesetzt, wenn die Frage „für alle“ enthält. Für unser Beispiel lautet die Frage also: „Wähle alle Eltern aus (Vater, Mutter), die ein Kind mit dem Namen Maria und dem Alter 4 und ein Kind mit dem Namen Sabine und dem Alter 2 (die Relation ) haben.“
Minimalität und Vollständigkeit
Eine minimale Menge von Operationen, das heißt, eine Menge von Operationen, die mindestens notwendig ist, um alle Ausdrücke der relationalen Algebra bilden zu können, umfasst
- Projektion
- Selektion
- Kartesisches Produkt
- Vereinigung
- Differenz
- Umbenennung
Alle anderen Operationen (zum Beispiel Joins) lassen sich durch diese Grundoperationen nachbilden.
Jede andere Menge von Operationen ist relational vollständig, wenn sie die gleiche Mächtigkeit wie die oben genannten Operationen haben.
Erweiterungen der relationalen Algebra
Um andere Abfragesprachen, speziell SQL, vollständig in die relationale Algebra abbilden zu können, ist die relationale Algebra nicht mächtig genug. Es gibt z. B. keine Möglichkeit, die SQL-Operatoren GROUP BY/HAVING, Aggregatfunktionen und Nullwerte in die relationale Algebra zu übersetzen. Wir betrachten hier einige Erweiterungen (die teilweise ähnliches bewirken), die eine vollständige Abbildung in die relationale Algebra, und damit eine vollständige theoretische Betrachtung dieser Abfragesprachen, ermöglichen.
Nullwerte
SQL ermöglicht die Verwendung von NULL-Werten, die mit dem speziellen Prädikat IS NULL abgefragt werden können. Dies ist insbesondere wichtig bei der Bildung von äußeren Verbunden, die eine Relation erzeugen, die alle Werte der einen Relation enthalten, sowie alle Werte der anderen, für die die Verbundbedingung wahr ist, sonst eben NULL-Werte. Dies kann mit der relationalen Algebra so nicht abgebildet werden.
Eine Möglichkeit ist die Definition von Nullwerten wie in SQL mit einer dreiwertigen Logik, das heißt, die booleschen Operatoren werden mittels Wahrheitstabellen so erweitert, dass festgelegt ist, wie zu verfahren ist, wenn ein Operand NULL ist.
| ∧ | true | false | NULL |
|---|---|---|---|
| true | true | false | NULL |
| false | false | false | false |
| NULL | NULL | false | NULL |
Selektionsbedingungen oder Verbunde, die auf Nullwerte angewendet werden, ergeben NULL. Eine Schwierigkeit damit (d. h. mit der SQL-artigen Behandlung von Nullwerten) besteht darin, dass die Ergebnisse von Abfragen mit Unterabfragen, die NULL ergeben, nicht notwendigerweise der Intention des Benutzers entsprechen. Diese Art der Nullwertbehandlung ist auch nicht orthogonal, d. h. das Verhalten auf der einen Ebene (boolesche Operatoren, 3-wertige Logik) entspricht nicht dem auf einer anderen (Verbunde, 3-wertige Logik wird auf 2-wertige abgebildet).
Eine andere Möglichkeit ist die Unterscheidung zweier verschiedener Arten von Nullwerten, die jeweils „beliebig“ oder „nicht definiert“ bedeuten.
Gruppierungsoperator und Aggregatfunktionen
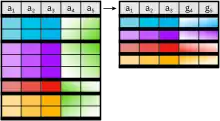
Die Gruppierung wendet Funktionen auf gleiche Attribute in einer Relation an. Der Operator γ erhält eine Liste von Funktionen und eine Attributliste. Die Funktionen werden dann auf Tupel angewendet für die die Attribute der Attributliste gleich sind. Die Ausgabe ist eine neue Relation bestehend aus der Attributliste und einem neuen Attribut, das die Ergebnisse der Funktionsliste enthält.
Die Funktionen sind dann die üblichen Aggregatfunktionen count, sum, max, avg ….
Definition
Seien R eine Relation und A = {A1, …, An} Attribute aus R. F(X) sei eine Funktionsliste f1(x1), …, fn(xn). Die Gruppierung ist dann

Für eine leere Attributmenge (also γF(X);{}(…)) wird ein zusätzliches Attribut erzeugt, das den Wert der Funktionsanwendung über die gesamte Relation enthält. Dies wird ausgenutzt, um die Relation mit der Selektion in Teilrelationen mit gleichen Attributen zu zerlegen, die dann mit der Funktionsanwendung wieder zusammengesetzt werden.
Weiter gilt, dass eine Gruppierung mit einer leeren Funktionsliste keinen Effekt hat.
NF²


Eine Erweiterung des relationalen Datenbankmodells ist das NF²-Modell. Der Name steht für Non-first-normal-form (NFNF), was andeuten soll, dass die Bedingung atomarer Attributwerte der 1. Normalform aufgebrochen wird. Folglich werden Mengen von Attributen und Mengen von Mengen erlaubt, was dazu führt, dass ein Attribut einer Relation wieder eine Relation sein kann. Die Domäne (Wertebereich) eines kombinierten Attributs ist das Kreuzprodukt der beteiligten Attributdomänen.
NF² erweitert die relationale Algebra dahingehend, dass neben den üblichen (entsprechend angepassten) Operationen der relationalen Algebra zwei Operationen hinzugenommen werden, die eine Relation schachteln (Nestung ν) und entschachteln (Entnestung μ). Die Nestung fasst eine Menge von Attributen in eine Unterrelation zusammen, die einen neuen Attributnamen erhält. Die Entnestung hebt Schachtelungen auf. Diese Operationen dienen dazu NF² Relationen in die 1. Normalform zu transformieren und umgekehrt. Die Operationen sind im Allgemeinen nicht bijektiv.
NF² benötigt aus obigen Gründen keine Fremdschlüssel.
Multimengensemantik
SQL liefert als Ergebnis von Anfragen eine Multimenge zurück, also eine Menge, die Elemente mehrfach enthalten kann. Dies wurde aus Performance-Gründen so gehandhabt, um den zusätzlichen Schritt der Duplikatentfernung zu sparen. Es können also streng genommen nur Anfragen in die relationale Algebra übersetzt werden, die mit DISTINCT angegeben sind.
Für die relationale Algebra kann man dann zusätzlich eine Funktion bag-to-set spezifizieren, die die Duplikate aus einer Multimenge entfernt und somit eine Menge erzeugt, und die Basisoperationen dann einfach als Multimenge spezifizieren. Vorsicht muss man aber bei der Definition abgeleiteter Operationen walten lassen.

Beispiele
Als Relationenschemata für die Beispiele nehmen wir die klassische Beispieldatenbank bestehend aus den Schemata Kunde, Lieferant und Ware. Die Schemata seien:
- KUNDE(Kundennr, Name, Wohnort, Kontostand)
- LIEFERANT(Lieferantennr, Name, Ort, Telefon)
- WARE(Warennr, Bezeichnung, Lieferantennr, Preis)
Grundoperationen der relationalen Algebra werden dann so benutzt:
- Die Preise aller Waren:
- πBezeichnung, Preis(WARE)
- Alle Lieferanten aus Bremen:
- σOrt='Bremen'(LIEFERANT)
- Kunden mit negativem Kontostand:
- σKontostand<0(KUNDE)
- Ort von LIEFERANT umbenennen (zum Beispiel um Mengenoperationen durchführen zu können):
- ρWohnort←Ort(LIEFERANT)
Da die Ergebnisse der relationalen Algebra wieder Relationen sind (die RA ist orthogonal), können die Operationen wieder auf die Ergebnisse von Operationen angewendet werden. Dies erlaubt komplexe Abfragen. Für eine einfachere Schreibweise nehmen wir an, dass das Kreuzprodukt eine implizite Umbenennung der Attribute vornimmt, so dass die neuen Attributnamen mit dem Relationennamen qualifiziert sind, d. h. aus Lieferantennr aus der Relation WARE wird WARE.Lieferantennr:
- Die Telefonnummern aller Lieferanten, die Gemüse in Bremen liefern:
- πTelefon(σBezeichnung='Gemüse' ∧ Ort='Bremen' ∧ LIEFERANT.Lieferantennr=WARE.Lieferantennr(LIEFERANT × WARE))
- Alle Orte, die wenigstens einen Lieferanten und wenigstens einen Kunden enthalten
- πOrt(ρOrt←Wohnort(KUNDE)) ∩ πOrt(LIEFERANT)
Siehe auch
Literatur
- Edgar F. Codd: A Relational Model of Data for Large Shared Data Banks. In: Communications of the ACM. 6/13/1970, S. 377–387. (Die fundamentale Arbeit, mit der Codd 1970 erstmals das relationale Datenmodell vorstellte. ACM Classics oder Peter Morcinek: FHTW Berlin [PDF; 1,4 MB])
- Alfons Kemper, André Eickler: Datenbanksysteme – Eine Einführung. ISBN 3-486-57690-9
- Peter Kandzia, Hans-Joachim Klein: Theoretische Grundlagen relationaler Datenbanksysteme. ISBN 3-411-14891-8
- Andreas Heuer, Gunter Saake: Datenbanken: Konzepte und Sprachen. MITP Verlag, ISBN 3-8266-0619-1, S. 297 ff.
- H. Buff Datenbanktheorie. Book-on-Demand, Norderstedt, ISBN 3-0344-0201-5, 312 Seiten
- H.-J. Schek, P. Pistor: Data Structures for an Integrated Data Base Management and Information Retrieval System (Non First Normal Form NF²), Proceedings of the 8th International Conference on Very Large Data Bases, 1982, ISBN 0-934613-14-1, S. 197–207
- Dirk Leinders, Jerzy Tyskiewicz, Jan Van den Bussche: On the expressive power of semijoin queries: arxiv:cs.DB/0308014
Weblinks
- Erklärvideos zur Relationalen Algebra, Big Data Analytics Group, Uni Saarland
- RAT, Software Rational Algebra Translator to SQL
- SELECT2OBaum: Umwandlung von SQL in die relationale Algebra
- Datenbank / Einführung in Joins. In: SELFHTML. Abgerufen am 4. Juli 2017 (Anschauliche Beispiele).
- Bibliographie-Server
- Weitere Beispiele
Einzelnachweise
- Jeffery D. Ullman: Principles od Database and Knowledgebase Systems. Volume I: Classical Database Systems. Computer Science Press, 1988, ISBN 0-7167-8158-1, S. 53.
- Jeffery D. Ullman: Principles of Database and Knowledgebase Systems. Volume I: Classical Database Systems. Computer Science Press, 1988, ISBN 0-7167-8158-1, S. 210.
- Torsten Grust, Jens Teubner: Relational Algebra: Mother Tongue – XQuery: Fluent. In: Proc. of the first Twente Data Management Workshop on XML Databases. Enschede 2004, S. 9–16 (uni-konstanz.de).
- Richard Cyganiak: A relational algebra for SPARQL. Hrsg.: Hewlett-Packard Development Company. Bristol 2005 (semanticscholar.org hp.com).
- Werner Kießling, Gerhard Köstler: Multimedia-Kurs Datenbanksysteme. Springer-Verlag, Berlin/Heidelberg 1998, ISBN 3-540-63836-9.
- Jeffery D. Ullman: Principles od Database and Knowledge-base Systems – Volume II: The New Technologies. Computer Science Press, 1989, ISBN 0-7167-8162-X, S. 633–733., Chapter 11
- Alfred Tarski: On the calculus of relations. In: The Journal of Symbolic Logic. Band 6, Nr. 3. Association for Symbolic Logic, New York September 1941, S. 73–89, JSTOR:2268577.
- Edgar F. Codd: Derivability, Redundancy and Consistency of Relations Stored in Large Data Banks. In: ACM SIGMOD Record. Band 38, Nr. 1. Association for Computing Machinery, New York 1969, S. 17–36 (acm.org).
- Edgar F. Codd: A Relational Model of Data for Large Shared Data Banks. In: Communications of the ACM. Band 13, Nr. 6. Association for Computing Machinery, New York 1970, S. 377–387 (acm.org).
- Rudolf Bayer, Edward M. McCreight: Organization and Maintenance of Large Ordered Indexes. In: Proceedings of the 1970 ACM SIGFIDET (SIGFIDET '70). Association for Computing Machinery, 1970, S. 107–141.
- Rudolf Bayer, Edward M. McCreight: Organization and Maintenance of Large Ordered Indexes. In: Acta Informatica. Band 1, Nr. 3. Springer-Verlag, 1972, S. 173–189.
- Alexis Leon and Mathews Leon: SQL – A Complete Reference. Tata McGraw-Hill, New Delhi 1999, ISBN 0-07-463708-8, S. 68–69 (eingeschränkte Vorschau in der Google-Buchsuche).
- Jeffery D. Ullman: Principles od Database and Knowledgebase Systems – Volume I: Classical Database Systems. Computer Science Press, 1988, ISBN 0-7167-8158-1, S. 195–210.
- Jeffery D. Ullman: Principles od Database and Knowledgebase Systems – Volume I: Classical Database Systems. Computer Science Press, 1988, ISBN 0-7167-8158-1, S. 185–195.
- Günther Pernul, Rainer Unland: Datenbanken im Unternehmen – Analyse, Modellbildung und Einsatz. In: Lehrbücher Wirtschaftsinformatik. 2., korrigierte Auflage. Oldenbourg Wissenschaftsverlag, ISBN 3-486-27210-1, S. 228, 248 (eingeschränkte Vorschau in der Google-Buchsuche).