RAID
Ein RAID-System dient zur Organisation mehrerer physischer Massenspeicher[1] (üblicherweise Festplattenlaufwerke oder Solid-State-Drives) zu einem logischen Laufwerk, das eine höhere Ausfallsicherheit oder einen größeren Datendurchsatz erlaubt als ein einzelnes physisches Speichermedium. Der Begriff ist ein Akronym für englisch „redundant array of independent disks“, also „redundante Anordnung unabhängiger Festplatten“ (ursprünglich englisch „redundant array of inexpensive disks“; deutsch „redundante Anordnung kostengünstiger Festplatten“; was aus Marketinggründen aufgegeben wurde).
Während die meisten in Computern verwendeten Techniken und Anwendungen darauf abzielen, Redundanzen (in Form von mehrfachem Vorkommen derselben Daten) zu vermeiden, werden bei RAID-Systemen redundante Informationen gezielt erzeugt, damit beim Ausfall einzelner Speichermedien das RAID als Ganzes seine Integrität und Funktionalität behält und nach Ersetzen der ausgefallenen Komponente durch einen Rebuild der ursprüngliche Zustand wiederhergestellt werden kann. Diese Redundanz darf keinesfalls mit einer Datensicherung gleichgesetzt werden.
Geschichte


Das Akronym RAID wurde erstmals 1987 durch David A. Patterson, Garth A. Gibson und Randy H. Katz von der University of California, Berkeley, USA als Abkürzung für „Redundant Array of Inexpensive Disks“ definiert.[2] In der zur International Conference on Management of Data (1988, Chicago, Illinois, USA) veröffentlichten Publikation „A case for redundant arrays of inexpensive disks (RAID)“[3] entwickeln die Autoren Vorschläge, um langsame Plattenzugriffe zu beschleunigen und die Mean Time Between Failures (MTBF) zu erhöhen. Dazu sollten die Daten auf vielen kleineren (preisgünstigen) Platten anstatt auf wenigen großen (teuren) abgelegt werden; deshalb die ursprüngliche Leseweise als „Redundant Arrays of Inexpensive Disks“ – RAID steht damit als Gegensatz zu den damaligen SLEDs (Single Large Expensive Disk). In ihrer Arbeit untersuchen die Autoren die Möglichkeit, kostengünstige kleinere Festplatten (eigentlich Zubehör für Personalcomputer) im Verbund als größeres logisches Laufwerk zu betreiben, um so die Kosten für eine große (zum damaligen Zeitpunkt überproportional teure) SLED-Festplatte (Großrechner-Technologie) einzusparen. Dem gestiegenen Ausfallrisiko im Verbund sollte durch die Speicherung redundanter Daten begegnet werden. Die einzelnen Anordnungen wurden als RAID-Level diskutiert.
“A case for redundant arrays of inexpensive disks (RAID)
ABSTRACT: Increasing performance of CPUs and memories will be squandered if not matched by a similar performance increase in I/O. While the capacity of Single Large Expensive Disks (SLED) has grown rapidly, the performance improvement of SLED has been modest. Redundant Arrays of Inexpensive Disks (RAID), based on the magnetic disk technology developed for personal computers, offers an attractive alternative to SLED, promising improvements of an order of magnitude in performance, reliability, power consumption, and scalability. This paper introduces five levels of RAIDs, giving their relative cost/performance, and compares RAID to an IBM 3380 and a Fujitsu Super Eagle”
Die Varianten RAID 0 und RAID 6 wurden erst später von der Industrie geprägt. Seit 1992 erfolgt eine Standardisierung durch das RAB (RAID Advisory Board), bestehend aus etwa 50 Herstellern. Die weitere Entwicklung des RAID-Konzepts führte zunehmend zum Einsatz in Serveranwendungen, die den erhöhten Datendurchsatz und die Ausfallsicherheit nutzen. Der Aspekt der Kostenersparnis fiel damit weg. Die Möglichkeit, in einem solchen System einzelne Festplatten im laufenden Betrieb zu wechseln, entspricht der heute gebräuchlichen Übersetzung: Redundant Array of Independent Disks (redundante Anordnung unabhängiger Festplatten).
Aufbau und Anschluss – Hardware-RAID, Software-RAID
Der Betrieb eines RAID-Systems setzt mindestens zwei Speichermedien voraus. Diese werden gemeinsam betrieben und bilden einen Verbund, der unter mindestens einem Aspekt betrachtet leistungsfähiger ist als die einzelnen Medien. Mit RAID-Systemen kann man folgende Vorteile erreichen (allerdings schließen sich einige gleichzeitig aus):
- Erhöhung der Ausfallsicherheit (Redundanz)
- Steigerung der Datenübertragungsrate (Leistung)
- Aufbau großer logischer Laufwerke
- Austausch von Speichermedien (auch während des Betriebes)
- Vergrößern des Speichers (auch während des Betriebs)
- Kostenreduktion durch Einsatz mehrerer kleiner, preiswerter Medien
Die genaue Art des Zusammenwirkens der einzelnen Speichermedien wird durch den RAID-Level spezifiziert. Die gebräuchlichsten RAID-Level sind RAID 0, RAID 1 und RAID 5. Sie werden unten beschrieben.
In der Regel erkennen die RAID-Implementierungen nur den Gesamtausfall eines Mediums beziehungsweise Fehler, die vom Medium signalisiert werden (siehe z. B. SMART). Auch können viele Implementierungen schon von der Theorie her nur einzelne Bitfehler erkennen und nicht korrigieren. Da Bitfehler mittlerweile selten sind und das Erkennen von Einzelfehlern ohne Korrekturmöglichkeit nur von relativ geringem Nutzen ist, verzichten heute einige Implementierungen auf die zusätzliche Integritätsprüfung beim Schreiben (read after write) oder Lesen (read and compare) und bieten hierdurch eine zum Teil beachtlich höhere Performance. Beispielsweise verzichten manche RAID-5-Implementierungen[4] heute beim Lesen auf das Überprüfen der Plausibilität mittels Paritäts-Stripes, analog arbeiten auch viele RAID-1-Implementierungen. So erreichen diese Systeme beim Lesen Datendurchsätze, wie sie sonst nur bei RAID 0 erzielt werden. Auch wird bei solchen Implementierungen nicht notwendigerweise der Cache eines Speichermediums deaktiviert. Dennoch legen einige RAID-Level (RAID 2, je nach Hersteller auch RAID 6) ihr besonderes Augenmerk auf die Datenintegrität und Fehlerkorrektur (ECC), dort sind folglich die Cache-Speicher der Platten deaktiviert und zusätzlich werden dann jederzeit alle möglichen Prüfungen durchgeführt (read after write usw.), woraus zum Teil erhebliche Performanceeinbußen resultieren.
Aus Sicht des Benutzers oder eines Anwendungsprogramms unterscheidet sich ein RAID-System nicht von einem einzelnen Speichermedium.
Hardware-RAID

Von Hardware-RAID spricht man, wenn das Zusammenwirken der Speichermedien von einer speziell dafür entwickelten Hardware-Baugruppe, dem RAID-Controller, organisiert wird. Der Hardware-RAID-Controller befindet sich typischerweise in physischer Nähe der Speichermedien. Er kann im Gehäuse des Computers enthalten sein. Besonders im Rechenzentrumsumfeld befindet er sich häufiger in einem eigenen Gehäuse, einem Disk-Array, in dem auch die Festplatten untergebracht sind. Die externen Systeme werden oft auch als DAS oder SAN bezeichnet, oder auch NAS, wenngleich nicht jedes dieser Systeme auch RAID implementiert. Professionelle Hardware-RAID-Implementierungen verfügen über eigene eingebettete CPUs; sie nutzen große, zusätzliche Cache-Speicher und bieten somit höchsten Datendurchsatz und entlasten dabei gleichzeitig den Hauptprozessor. Durch eine durchdachte Handhabung und einen soliden Herstellersupport wird gerade auch bei Störungen eine bestmögliche Unterstützung des Systemadministrators erreicht. Einfache Hardware-RAID-Implementierungen bieten diese Vorteile nicht in gleichem Maße und stehen daher in direkter Konkurrenz zu Software-RAID-Systemen.
Host-RAID

Im unteren Preissegment (praktisch ausschließlich für IDE/ATA- oder SATA-Festplatten) werden sogenannte Host-RAID-Implementierungen angeboten.[5] Rein äußerlich ähneln diese Lösungen den Hardware-RAID-Implementierungen. Es gibt sie als Kartenerweiterungen aus dem Niedrigpreis-Sektor, häufig sind sie aber auch direkt in die Hauptplatinen (engl. mainboards) für den Heimcomputer und Personal Computer integriert. Meistens sind diese Implementierungen auf RAID 0 und RAID 1 beschränkt. Um solche nichtprofessionellen Implementierungen so erschwinglich wie möglich zu halten, verzichten sie weitestgehend auf aktive Komponenten und realisieren die RAID-Level durch eine Software, die in den Treibern der Hardware integriert ist, allerdings für die notwendigen Rechenarbeiten den Hauptprozessor nutzt und auch die internen Bussysteme deutlich mehr belastet. Es handelt sich also eher um eine Software-RAID-Implementierung, die an eine spezielle Hardware gebunden ist. Die Bindung an den Controller ist ein bedeutender Nachteil, erschwert die Wiederherstellung und birgt bei einer Fehlfunktion desselben die Gefahr eines Datenverlustes. Solche Controller werden im Linux-Jargon daher oft auch als Fake-RAID[6] bezeichnet (vgl. auch die sogenannten Win- oder Softmodems, die ebenfalls den Hauptprozessor und Bussysteme zusätzlich belasten).
Software-RAID
Von Software-RAID spricht man, wenn das Zusammenwirken der Festplatten komplett softwareseitig organisiert wird. Auch der Begriff Host based RAID ist geläufig, da nicht das Speicher-Subsystem, sondern der eigentliche Computer die RAID-Verwaltung durchführt. Die meisten modernen Betriebssysteme wie FreeBSD, OpenBSD, Apple macOS, HP HP-UX, IBM AIX, Linux, Microsoft Windows ab Windows NT oder Solaris sind dazu in der Lage. Die einzelnen Festplatten sind in diesem Fall entweder über einfache Festplattencontroller am Computer angeschlossen oder es werden externe Storage-Geräte wie Disk-Arrays von Unternehmen wie EMC, Promise, AXUS, Proware oder Hitachi Data Systems (HDS) an den Computer angeschlossen. Die Festplatten werden zunächst ohne RAID-Controller als sogenannte JBODs („just a bunch of disks“) in das System integriert, dann wird per Software-RAID (z. B. unter Linux mit dem Programm mdadm) die RAID-Funktionalität realisiert. Eine besondere Variante des Software RAID sind Dateisysteme mit einer integrierten RAID-Funktionalität. Ein Beispiel dafür ist das von Sun Microsystems entwickelte RAID-Z.[7]
Pro
Der Vorteil von Software-RAID ist, dass kein spezieller RAID-Controller benötigt wird. Die Steuerung wird von der RAID-Software erledigt. Diese ist entweder schon Teil des Betriebssystems oder wird nachträglich installiert. Dieser Vorteil kommt besonders bei der Disaster Recovery zum Tragen, wenn der RAID-Controller defekt und nicht mehr verfügbar ist. Praktisch alle derzeit verfügbaren Software-RAID-Systeme benutzen die Festplatten so, dass diese auch ohne die spezifische Software ausgelesen werden können.
Contra
Bei einem Software-RAID werden bei Festplattenzugriffen neben dem Hauptprozessor des Computers auch die System-Busse wie PCI stärker belastet als bei einem Hardware-RAID. Bei leistungsschwachen CPUs und Bus-Systemen verringert dies deutlich die Systemleistung; bei leistungsstarken, wenig ausgelasteten Systemen ist dies belanglos. Storage-Server sind in der Praxis oft nicht voll ausgelastet; auf solchen Systemen können Software-RAID-Implementierungen unter Umständen sogar schneller sein als Hardware-RAIDs.
Ein weiterer Nachteil ist, dass bei vielen Software-RAID kein Cache genutzt werden kann, dessen Inhalt auch nach einem Stromausfall erhalten bleibt, wie es bei Hardware-RAID-Controllern mit einer Battery Backup Unit der Fall ist. Dieses Problem lässt sich mit einer unterbrechungsfreien Stromversorgung für den gesamten PC vermeiden. Um die Gefahr von Datenverlusten und Fehlern in der Datenintegrität bei einem Stromausfall oder Systemabsturz zu minimieren, sollten außerdem die (Schreib-)Caches der Festplatten deaktiviert werden.[8]
Da die Platten eines Software-RAIDs prinzipiell auch einzeln angesprochen werden können, besteht bei gespiegelten Festplatten die Gefahr, dass Änderungen nur noch an einer Platte durchgeführt werden – wenn etwa nach einem Betriebssystem-Update die RAID-Software oder der Treiber für einen RAID-Festplatten-Controller nicht mehr funktionieren, eine der gespiegelten Festplatten aber weiterhin über einen generischen SATA-Treiber angesprochen werden kann. Entsprechende Warnhinweise oder Fehlermeldungen während des Bootens sollten deshalb nicht ignoriert werden, nur weil das System trotzdem funktioniert. Ausnahmen bilden hier Software-RAID mit Datenintegrität wie z. B. ZFS. Unvollständige Speichervorgänge werden zurückgesetzt. Fehlerhafte Spiegeldaten werden erkannt und durch korrekte Spiegeldaten ersetzt. Es wird wohl beim Lesen eine Fehlermeldung geben, da die fehlerhafte oder alte Spiegelseite nicht mit dem aktuellen Block übereinstimmt.
Software-Raid und Storage-Server
Mit einem Software-RAID-ähnlichen Ansatz lassen sich auch (logische) Volumes, die von unterschiedlichen Storage-Servern zur Verfügung gestellt werden, auf Seite des Anwendungsservers spiegeln. Das kann in hochverfügbaren Szenarien nützlich sein, weil man damit unabhängig von entsprechender Cluster-Logik in den Storage-Servern ist, welche häufig fehlt, andere Ansätze verfolgt oder herstellerabhängig und somit in gemischten Umgebungen nicht zu gebrauchen ist. Allerdings muss das Host-Betriebssystem entsprechende Features mitbringen (z. B. durch Einsatz von GlusterFS, des Logical Volume Manager oder von NTFS). Solche Storage-Server sind üblicherweise in sich schon redundant. Ein übergreifendes Cluster richtet sich also eher gegen den Ausfall des ganzen Servers oder eines Rechnerraumes (Stromausfall, Wasserschaden, Brand usw.) Ein einfacher Spiegel, vergleichbar mit RAID 1, reicht hier aus; siehe auch Hauptartikel Storage Area Network.
Probleme
Größenänderung
Für Größenänderungen von RAIDs bestehen grundsätzlich zwei Alternativen. Entweder das bestehende RAID wird übernommen und angepasst oder die Daten werden andernorts gesichert, das RAID in der gewünschten Größe/dem gewünschten Level neu aufgesetzt und die zuvor gesicherten Daten zurückgespielt. Letzterer trivialer Fall wird nachfolgend nicht weiter behandelt; es geht ausschließlich um die Größenveränderung eines bestehenden RAID-Systems.
Das Verkleinern eines bestehenden RAID-Systems ist in der Regel nicht möglich.
Bezüglich einer Vergrößerung gibt es allgemein keine Garantie, dass ein bestehendes RAID-System durch das Hinzufügen weiterer Festplatten erweitert werden kann. Das gilt sowohl für Hardware- als auch für Software-RAIDs. Nur wenn ein Hersteller sich der Erweiterung als Option explizit angenommen hat, besteht diese Möglichkeit. Sie ist üblicherweise recht zeitintensiv, da sich durch eine veränderte Laufwerksanzahl die Organisation sämtlicher Daten und Paritätsinformationen ändert und daher die physische Ordnung restrukturiert werden muss. Weiterhin müssen das Betriebssystem und das verwendete Dateisystem in der Lage sein, den neuen Plattenplatz einzubinden.
Eine RAID-Vergrößerung setzt einen neuen Datenträger voraus, der mindestens die Größe des kleinsten bereits verwendeten Datenträgers aufweist.
Austausch
Muss zum Beispiel nach einem Plattenfehler ein RAID-Array wiederhergestellt werden, so benötigt man eine Festplatte, die mindestens so groß wie die ausgefallene Festplatte ist. Dies kann problematisch sein, wenn man zum Beispiel Platten maximaler Größe verwendet. Ist ein Plattentyp auch nur zeitweise nicht lieferbar und die alternativ erhältlichen Platten sind auch nur ein Byte kleiner, kann das RAID-Array nicht mehr einfach wiederhergestellt werden. Vorsorglich nutzen daher manche Hersteller (z. B. HP oder Compaq) Platten mit einer geänderten Plattenfirmware, welche die Platte gezielt geringfügig verkleinert. So wird sichergestellt, dass sich auch Platten anderer Hersteller mit ebenfalls angepasster Firmware auf die vom RAID-Array genutzte Größe einstellen lassen. Ein anderer Ansatz, den einige Hersteller von RAID-Controllern verfolgen, ist die Plattenkapazität beim Einrichten des Arrays geringfügig zu beschneiden, somit können auch Platten unterschiedlicher Serien oder verschiedener Hersteller mit annähernd gleicher Kapazität problemlos verwendet werden. Ob ein Controller diese Funktion unterstützt, sollte aber vor Einrichten eines Arrays überprüft werden, da eine nachträgliche Größenänderung meist nicht möglich ist. Manche RAID-Implementierungen überlassen es dem Benutzer, einigen Plattenplatz nicht auszunutzen. Es empfiehlt sich dann, aber natürlich auch bei Software-RAID, bereits von Anfang an einen geringen Plattenplatz für den Fall eines Modellwechsels zu reservieren und nicht zu nutzen. Aus diesem Grund sollte man auch maximal große Platten, für die es nur einen Hersteller gibt, im Bereich redundanter RAID-Systeme behutsam einsetzen.
Defekte Controller
Auch Hardware kann defekt sein (z. B. in Form eines RAID-Controllers). Das kann zum Problem werden, besonders dann, wenn kein identischer Ersatzcontroller verfügbar ist. In der Regel kann ein intakter Plattensatz nur am gleichen Controller beziehungsweise an der gleichen Controller-Familie betrieben werden, an dem er auch erstellt wurde. Häufig kommt es (besonders bei älteren Systemen) auch vor, dass nur exakt der gleiche Controller (Hardware + Firmware) den Plattensatz ohne Datenverlust ansprechen kann. Im Zweifelsfall sollte man unbedingt beim Hersteller nachfragen. Aus dem gleichen Grund sind unbekannte Hersteller, aber auch onboard RAID-Systeme mit Vorsicht einzusetzen. In jedem Fall sollte sichergestellt sein, dass man auch nach Jahren einen leicht zu konfigurierenden, passenden Ersatz bekommt.
Abhilfe schafft unter Umständen Linux, die Plattensätze einiger IDE-/SATA-RAID-Controller (Adaptec HostRAID ASR, Highpoint HPT37X, Highpoint HPT45X, Intel Software RAID, JMicron JMB36x, LSI Logic MegaRAID, Nvidia NForce, Promise FastTrack, Silicon Image Medley, SNIA DDF1, VIA Software RAID und Kompatible) können direkt mit dem dmraid-Tool[9] vom Betriebssystem eingelesen werden.
Fehlerhaft produzierte Datenträgerserien
Festplatten können, wie andere Produkte auch, in fehlerhaften Serien produziert werden. Gelangen diese dann zum Endverbraucher und in ein RAID-System, so können solche serienbehafteten Fehler auch zeitnah auftreten und dann zu Mehrfachfehlern – dem gleichzeitigen Ausfall mehrerer Festplatten – führen. Solche Mehrfachfehler lassen sich dann üblicherweise nur durch das Rückspielen von Datensicherungen kompensieren. Vorsorglich kann man Diversitäts-Strategien nutzen, also einen RAID-Array aus etwa leistungsgleichen Platten mehrerer Hersteller aufbauen, wobei man beachten muss, dass die Plattengrößen geringfügig variieren können und sich die maximale Arraygröße ggf. von der kleinsten Platte ableitet.
Statistische Fehlerrate bei großen Festplatten
Ein verdecktes Problem liegt in dem Zusammenspiel von Arraygröße und statistischer Fehlerwahrscheinlichkeit der verwendeten Laufwerke. Festplattenhersteller geben für ihre Laufwerke eine Wahrscheinlichkeit für nicht korrigierbare Lesefehler an (unrecoverable read error, URE). Der URE-Wert ist ein Durchschnittswert, der innerhalb der Gewährleistungszeit zugesichert wird, er erhöht sich alters- und verschleißbedingt. Für einfache Laufwerke aus dem Consumer-Bereich (IDE, SATA) garantieren die Hersteller typischerweise URE-Werte von maximal (max. ein fehlerhaftes Bit pro gelesene Bit), für Serverlaufwerke (SCSI, SAS) sind es meist zwischen und . Für Consumer-Laufwerke bedeutet das also, dass es während der Verarbeitung von Bit (etwa 12 TB) maximal zu einem URE kommen darf. Besteht ein Array also beispielsweise aus acht je 2 TB großen Platten, so garantiert der Hersteller nur noch, dass der Rebuild statistisch gesehen mindestens in einem von drei Fällen ohne URE klappen muss, obwohl alle Laufwerke korrekt nach Herstellerspezifikation funktionieren. Für kleine RAID-Systeme stellt dies kaum ein Problem dar: Der Rebuild eines RAID 5-Arrays aus drei 500 GB großen Consumer-Laufwerken (1 TB Nutzdaten) wird im Schnitt in 92 von 100 Fällen erfolgreich sein, wenn nur URE-Fehler betrachtet werden. Deswegen stoßen praktisch schon jetzt alle einfachen redundanten RAID-Verfahren (RAID 3, 4, 5 usw.) außer RAID 1 und RAID 2 an eine Leistungsgrenze.[10] Das Problem kann natürlich durch höherwertige Platten, aber auch durch kombinierte RAID-Level wie RAID 10 oder RAID 50 entschärft werden. In der Realität ist das Risiko, dass tatsächlich ein derartiger URE-basierter Fehler eintritt, durchaus geringer, denn es handelt sich bei den Herstellerangaben nur um garantierte Maximalwerte. Dennoch ist der Einsatz hochwertiger Laufwerke mit Fehlerraten von (oder besser) besonders bei professionellen Systemen anzuraten.




Rebuild
Als Rebuild bezeichnet man den Wiederherstellungsprozess eines RAID-Verbundes. Dieser wird notwendig, wenn eine oder mehrere Festplatten (je nach RAID-Level) im RAID-Verbund ausgefallen oder entfernt worden sind und anschließend durch neue Festplatten ersetzt wurden. Da die neuen Festplatten unbeschrieben sind, müssen mit Hilfe der noch vorhandenen Nutzdaten bzw. Paritätsdaten die fehlenden Daten auf diese geschrieben werden. Unabhängig von der Konfiguration des RAID-Systems bedeutet ein Rebuild immer eine höhere Belastung der beteiligten Hardwarekomponenten.
Ein Rebuild kann, abhängig vom RAID-Level, der Plattenanzahl und -größe, durchaus mehr als 24 Stunden dauern. Um bei einem Rebuild weitere Plattenausfälle zu vermeiden, sollte man Festplatten aus unterschiedlichen Herstellungschargen für ein RAID verwenden. Da die Platten unter gleichen Betriebsbedingungen arbeiten und dasselbe Alter besitzen, besitzen sie auch eine ähnliche Lebens- bzw. Ausfallerwartung.
Ein automatischer Rebuild kann je nach verwendetem Controller über Hot-Spare-Platten, welche dem RAID-Verbund zugeordnet sind, erfolgen. Allerdings verfügt nicht jeder Controller oder jede Software über die Möglichkeiten, eine oder mehrere Hot-Spare-Platten anzubinden. Diese ruhen im normalen Betrieb. Sobald der Controller eine defekte Festplatte erkennt und aus dem RAID-Verbund entfernt, wird eine der Hot-Spare-Platten in den Verbund eingefügt, und der Rebuild startet automatisch. Es findet aber i. A. weder bei Controllern noch bei Softwarelösungen eine regelmäßige Überprüfung der Hot-Spare-Platte(n) auf Verfügbarkeit und Schreib-/ Lesefunktionalität statt.
Unter den vorgenannten Problempunkten sollte der Zustand „Rebuild“ eines Systems neu betrachtet werden. Die ursprüngliche Bedeutung „RAID“ (s. a. Erläuterung zu Beginn des Artikels) und dessen Priorität „Ausfallsicherheit durch Redundanz“ wandelt sich in der Praxis mehr und mehr zu einem System, dessen Priorität in der „Maximierung des zur Verfügung gestellten Speicherplatzes durch einen Verbund von günstigen Festplatten maximaler Kapazität“ liegt. Der ehemals kurzzeitige „Betriebszustand“ Rebuild, in dem verfügbare Hotspare-Festplatten sehr kurzfristig den Normalzustand wiederherstellen konnten, entwickelt sich dabei zu einem tagelangen Notfallszenario. Der verhältnismäßig lange Zeitraum unter maximaler Beanspruchung erhöht dabei das Risiko eines weiteren Hardwareausfalls oder anderer Störfälle beträchtlich. Eine weitere Erhöhung der Redundanz, insbesondere bei größeren Festplattenverbänden, z. B. durch Verwendung eines RAID 6, eines ZFS Raid-Z3 oder sogar einer weiteren Spiegelung des gesamten Festplattenverbundes (-> GlusterFS, Ceph etc.) scheint in solchen Szenarien angeraten.
Die gebräuchlichen RAID-Level im Einzelnen
Die gebräuchlichsten RAID Level sind die RAID Level 0, 1 und 5.
Bei der Präsenz von drei Platten à 1 TB, die jeweils eine Ausfallwahrscheinlichkeit von 1 % in einem gegebenen Zeitraum haben, gilt
- RAID 0 stellt 3 TB zur Verfügung. Die Ausfallwahrscheinlichkeit des RAIDs beträgt 2,9701 % (1 in 34 Fällen).
- RAID 1 stellt 1 TB zur Verfügung. Die Ausfallwahrscheinlichkeit des RAIDs beträgt 0,0001 % (1 in 1.000.000 Fällen).
- RAID 5 stellt 2 TB zur Verfügung. Die Ausfallwahrscheinlichkeit des RAIDs beträgt 0,0298 % (1 in 3.356 Fällen).
Technisch wird dieses Verhalten wie folgt erreicht:
RAID 0: Striping – Beschleunigung ohne Redundanz
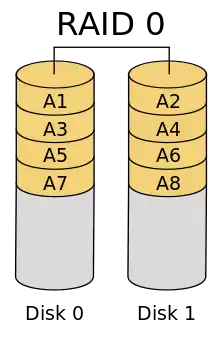
Bei RAID 0 fehlt die Redundanz, daher gehört es streng genommen nicht zu den RAID-Systemen, es ist nur ein schnelles „Array of Independent Disks“.
RAID 0 bietet gesteigerte Transferraten, indem die beteiligten Festplatten in zusammenhängende Blöcke gleicher Größe aufgeteilt werden, wobei diese Blöcke quasi im Reißverschlussverfahren zu einer großen Festplatte angeordnet werden. Somit können Zugriffe auf allen Platten parallel durchgeführt werden (engl. striping, was „in Streifen zerlegen“ bedeutet, abgeleitet von stripe, oder „Streifen“). Die Datendurchsatzsteigerung (bei sequentiellen Zugriffen, aber besonders auch bei hinreichend hoher Nebenläufigkeit) beruht darauf, dass die notwendigen Festplattenzugriffe in höherem Maße parallel abgewickelt werden können. Die Größe der Datenblöcke wird als Striping-Granularität (auch stripe size, chunk size oder interlace size) bezeichnet. Meistens wird bei RAID 0 eine chunk size von 64 kB gewählt.
Fällt jedoch eine der Festplatten durch einen Defekt (vollständig) aus, kann der RAID-Controller ohne deren Teildaten die Nutzdaten nicht mehr vollständig rekonstruieren. Die Daten teilweise wiederherzustellen ist unter Umständen möglich, nämlich genau für jene Dateien, die nur auf den verbliebenen Festplatten gespeichert sind, was typischerweise nur bei kleinen Dateien und eher bei großer Striping-Granularität der Fall sein wird. (Im Vergleich dazu würde die Benutzung getrennter Dateisysteme für die einzelnen Festplatten bei einem Ausfall eines Speichermediums die nahtlose Weiternutzung der Dateisysteme der verbliebenen Medien ermöglichen, während der vollständige Ausfall eines einzelnen und entsprechend größeren Speichermediums einen vollständigen Verlust aller Daten zur Folge hätte.) RAID 0 ist daher nur in Anwendungen zu empfehlen, bei denen Ausfallsicherheit nicht von Bedeutung ist. Auch wenn überwiegend lesende Zugriffe auftreten (während ändernde Zugriffe durch entsprechende Verfahren redundant auch auf einem anderen Medium ausgeführt werden), kann RAID 0 empfehlenswert sein. Die bei einfachem RAID 0 unvermeidbare Betriebsunterbrechung infolge eines Festplatten-Ausfalls (auch einzelner Platten) sollte bei der Planung berücksichtigt werden.
Der Einsatzzweck dieses Verbundsystems erstreckt sich demnach auf Anwendungen, bei denen in kurzer Zeit besonders große Datenmengen vor allem gelesen werden sollen, etwa auf die Musik- oder Videowiedergabe und die sporadische Aufnahme derselben.
Die Ausfallwahrscheinlichkeit eines RAID 0 aus Festplatten in einem bestimmten Zeitraum beträgt . Das gilt nur unter der Annahme, dass die Ausfallwahrscheinlichkeit einer Festplatte statistisch unabhängig von den übrigen Festplatten und für alle Festplatten identisch ist.



Eine Sonderform stellt ein Hybrid-RAID-0-Verbund aus SSD und konventioneller Festplatte dar (s. a. Fusion Drive unter OS X), wobei die SSD als großer Cachespeicher für die konventionelle Festplatte dient. Ein echtes RAID 0 entsteht hier aber nicht, da nach einer Trennung der beiden Laufwerke die Daten beider Datenträger auch separat noch lesbar sind.
RAID 1: Mirroring – Spiegelung
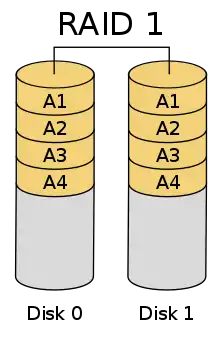
RAID 1 ist der Verbund von mindestens zwei Festplatten. Ein RAID 1 speichert auf allen Festplatten die gleichen Daten (Spiegelung) und bietet somit volle Redundanz. Die Kapazität des Arrays ist hierbei höchstens so groß wie die kleinste beteiligte Festplatte.
Ein Vorteil von RAID 1 gegenüber allen anderen RAID-Verfahren liegt in seiner Einfachheit. Beide Platten sind identisch beschrieben und enthalten alle Daten eines Systems, somit kann (die passende Hardware vorausgesetzt) normalerweise auch jede Platte einzeln in zwei unabhängigen Rechnern (intern oder im externen Laufwerk) unmittelbar betrieben und genutzt werden. Aufwändige Rebuilds sind nur dann notwendig, wenn die Platten wieder redundant betrieben werden sollen. Im Störfall wie auch bei Migrationen beziehungsweise Upgrades bedeutet das einen erheblichen Vorteil.
Fällt eine der gespiegelten Platten aus, kann jede andere weiterhin alle Daten liefern. Besonders in sicherheitskritischen Echtzeitsystemen ist das unverzichtbar. RAID 1 bietet eine hohe Ausfallsicherheit, denn zum Totalverlust der Daten führt erst der Ausfall aller Platten. Die Ausfallwahrscheinlichkeit eines RAID 1 aus Festplatten in einem bestimmten Zeitraum beträgt , falls die Ausfallwahrscheinlichkeit einer Festplatte statistisch unabhängig von den übrigen Festplatten und für alle Festplatten identisch ist.

Aus historischen Gründen wird zwischen Mirroring (alle Festplatten am selben Controller) und Duplexing (für jede Festplatte ein eigener Controller) unterschieden, was heute jedoch nur bei Betrachtungen über den Single Point of Failure eine Rolle spielt: Festplatten-Controller fallen im Vergleich zu mechanisch beanspruchten Teilen (also Festplatten) relativ selten aus, so dass das Risiko eines Controller-Ausfalls aufgrund seiner geringen Wahrscheinlichkeit häufig noch toleriert wird.
Zur Erhöhung der Leseleistung kann ein RAID-1-System beim Lesen auf mehr als eine Festplatte zugreifen und gleichzeitig verschiedene Sektoren von verschiedenen Platten einlesen. Bei einem System mit zwei Festplatten lässt sich so die Leistung verdoppeln. Die Lesecharakteristik entspricht hierbei einem RAID-0-System. Diese Funktion bieten aber nicht alle Controller oder Softwareimplementierungen an. Sie erhöht die Lesegeschwindigkeit des Systems, geht aber auf Kosten der Sicherheit. Eine solche Implementierung schützt vor einem kompletten Datenträgerausfall, aber nicht vor Problemen mit fehlerhaften Sektoren, zumindest falls diese erst nach dem Speichern (read after write verify) auftreten.
Zur Erhöhung der Sicherheit kann ein RAID-1-System beim Lesen stets auf mehr als eine Festplatte zugreifen. Dabei werden die Antwortdatenströme der Festplatten verglichen. Bei Unstimmigkeiten wird eine Fehlermeldung ausgegeben, da die Spiegelung nicht länger besteht. Diese Funktion bieten nur wenige Controller an, auch reduziert sie die Geschwindigkeit des Systems geringfügig.
Eine Spiegelplatte ist kein Ersatz für eine Datensicherung, da sich auch versehentliche oder fehlerhafte Schreiboperationen (Viren, Stromausfall, Benutzerfehler) augenblicklich auf die Spiegelplatte übertragen. Dies gilt insbesondere für unvollständig abgelaufene, schreibende Programme (etwa durch Stromausfall abgebrochene Update-Transaktionen auf Datenbanken ohne Logging-System), wobei es hier nicht nur zu der Beschädigung der Spiegelung, sondern auch zu einem inkonsistenten Datenzustand trotz intakter Spiegelung kommen kann. Abhilfe schaffen hier Datensicherungen und Transaktions-Logs.
Eine Sonderform stellt ein Hybrid-RAID-1-Verbund aus SSD und konventioneller Festplatte dar, welche die Vorteile einer SSD (Lesegeschwindigkeit) mit der Redundanz verbindet.
In der Praxis wird jedoch während des Rebuild-Vorganges das gesamte Array hoch belastet, so dass weitere Ausfälle in diesem Zeitraum mit höherer Wahrscheinlichkeit zu erwarten sind.
RAID 5: Leistung + Parität, Block-Level Striping mit verteilter Paritätsinformation
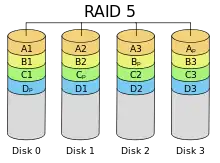
RAID 5 implementiert Striping mit auf Block-Level-verteilten Paritätsinformationen. Zur Berechnung der Parität wird durch die jeweils an gleicher Adresse anliegenden Datenblöcke der am RAID-Verbund beteiligten Festplatten eine logische Gruppe gebildet. Von allen Datenblöcken einer Gruppe enthält ein Datenblock die Paritätsdaten, während die anderen Datenblöcke Nutzdaten enthalten. Die Nutzdaten von RAID-5-Gruppen werden wie bei RAID 0 auf alle Festplatten verteilt. Die Paritätsinformationen werden jedoch nicht wie bei RAID 4 auf einer Platte konzentriert, sondern ebenfalls verteilt.
RAID 5 bietet sowohl gesteigerten Datendurchsatz beim Lesen von Daten als auch Redundanz bei relativ geringen Kosten und ist dadurch eine sehr beliebte RAID-Variante. In schreibintensiven Umgebungen mit kleinen, nicht zusammenhängenden Änderungen ist RAID 5 nicht zu empfehlen, da bei zufälligen Schreibzugriffen der Durchsatz aufgrund des zweiphasigen Schreibverfahrens deutlich abnimmt. An dieser Stelle wäre eine RAID-01-Konfiguration vorzuziehen. RAID 5 ist eine der kostengünstigsten Möglichkeiten, Daten auf mehreren Festplatten redundant zu speichern und dabei das Speichervolumen effizient zu nutzen. Dieser Vorteil kann bei wenigen Platten allerdings durch hohe Controllerpreise vernichtet werden. Daher kann es in einigen Situationen dazu führen, dass ein RAID 10 kostengünstiger ist.
Die nutzbare Gesamtkapazität errechnet sich aus der Formel: (Anzahl der Festplatten − 1) × Kapazität der kleinsten Festplatte. Rechenbeispiel mit vier Festplatten à 1 TB: (4−1) × (1 TB) = 3 TB Nutzdaten und 1 TB Parität.
Da ein RAID 5 nur dann versagt, wenn mindestens zwei Platten gleichzeitig ausfallen, ergibt sich bei einem RAID 5 mit +1 Festplatten eine theoretische Ausfallwahrscheinlichkeit von , falls die Ausfallwahrscheinlichkeit einer Festplatte statistisch unabhängig von den übrigen Festplatten und für alle Festplatten identisch ist. In der Praxis wird jedoch während des Rebuild-Vorganges das gesamte Array hoch belastet, so dass weitere Ausfälle in diesem Zeitraum mit höherer Wahrscheinlichkeit zu erwarten sind.

Die Berechnung der Paritätsdaten eines Paritätsblocks erfolgt durch XOR-Verknüpfung der Daten aller Datenblöcke seiner Gruppe, was wiederum zu einer leichten bis erheblichen Verminderung der Datentransferrate im Vergleich zu RAID 0 führt. Da die Paritätsinformationen beim Lesen nicht benötigt werden, stehen alle Platten zum parallelen Zugriff zur Verfügung. Dieser (theoretische) Vorteil greift allerdings nicht bei kleinen Dateien ohne nebenläufigen Zugriff, erst bei größeren Dateien oder geeigneter Nebenläufigkeit tritt eine nennenswerte Beschleunigung ein. Bei n Festplatten erfordert der Schreibzugriff entweder ein Volumen, das genau (n−1) korrespondierende Datenblöcke ausfüllt, oder ein zwei-phasiges Verfahren (alte Daten lesen; neue Daten schreiben).
Jüngere RAID-Implementierungen berechnen die neue Paritätsinformation bei einem Schreibzugriff nicht durch XOR-Verknüpfung über die Daten aller korrespondierenden Datenblöcke, sondern durch XOR-Verknüpfung von altem und neuen Datenwert sowie des alten Paritätswerts. Anders gesagt: Wechselt ein Datenbit den Wert, dann wechselt auch das Paritätsbit den Wert. Das ist mathematisch dasselbe, aber es sind nur zwei Lesezugriffe erforderlich, nämlich auf die beiden alten Werte und nicht n−2 Lesezugriffe auf die sonstigen Datenblöcke wie früher. Dies erlaubt den Aufbau von größeren RAID-5-Arrays ohne Performanceabfall, beispielsweise mit n = 8. In Verbindung mit Schreibcaches erreicht man im Vergleich zu RAID 1 beziehungsweise RAID 10 hiermit ähnlichen Datendurchsatz bei geringeren Hardwarekosten. Storage-Server werden daher, wenn überhaupt noch klassische RAID-Verfahren zur Anwendung kommen, üblicherweise in RAID-5-Arrays aufgeteilt.
Bei RAID 5 ist die Datenintegrität des Arrays beim Ausfall von maximal einer Platte gewährleistet. Nach Ausfall einer Festplatte oder während des Rebuilds auf die Hotspare-Platte (bzw. nach Austausch der defekten Festplatte) lässt die Leistung deutlich nach (beim Lesen: jeder (n−1)-te Datenblock muss rekonstruiert werden; beim Schreiben: jeder (n−1)-te Datenblock kann nur durch Lesen der entsprechenden Bereiche aller korrespondierenden Datenblöcke und anschließendes Schreiben der Parität geschrieben werden; hinzu kommen die Zugriffe des Rebuilds: (n−1) × Lesen; 1 × Schreiben). Bei dem Rebuild-Verfahren ist daher die Berechnung der Parität zeitlich zu vernachlässigen; im Vergleich zu RAID 1 dauert somit das Verfahren unwesentlich länger und benötigt gemessen am Nutzdatenvolumen nur den (n−1)-ten Teil der Schreibzugriffe.
Eine noch junge Methode zur Verbesserung der Rebuild-Leistung und damit der Ausfallsicherheit ist präemptives RAID 5. Hierbei werden interne Fehlerkorrekturstatistiken der Platten zur Vorhersage eines Ausfalls herangezogen (siehe SMART). Vorsorglich wird nun die Hotspare-Platte mit dem kompletten Inhalt der ausfallverdächtigsten Platte im RAID-Verbund synchronisiert, um zum vorhergesagten Versagenszeitpunkt sofort an deren Stelle treten zu können. Das Verfahren erreicht bei geringerem Platzbedarf eine ähnliche Ausfallsicherheit wie RAID 6 und andere Dual-Parity-Implementierungen. Allerdings wurde präemptives RAID 5 aufgrund des hohen Aufwands bislang nur in wenigen „High-End“-Speichersystemen mit serverbasierten Controllern implementiert. Zudem zeigt eine Studie von Google (Februar 2007), dass SMART-Daten zur Vorhersage des Ausfalls einer einzelnen Festplatte nur eingeschränkt nützlich sind.[11]
Einfluss der Anzahl der Festplatten
Bei RAID-5-Systemen sind Konfigurationen mit 3 oder 5 Festplatten häufig anzutreffen – das ist kein Zufall, denn die Anzahl der Festplatten hat einen Einfluss auf die Schreibleistung.
Einfluss auf die Read-Performance
Sie wird weitestgehend durch die Anzahl der Festplatten, aber auch durch Cache-Größen bestimmt, mehr ist hier immer besser.
Einfluss auf die Write-Performance
Im Unterschied zur Read-Performance ist das Ermitteln der Write-Performance bei RAID 5 deutlich komplizierter und hängt sowohl von der zu schreibenden Datenmenge, als auch von der Anzahl der Platten ab.[4] Ausgehend von Festplatten mit weniger als 2 TB Plattenplatz, ist die atomare Blockgröße (auch Sektorgröße genannt) der Platten häufig 512 Byte (siehe Festplattenlaufwerk). Geht man weiter von einem RAID-5-Verbund mit 5 Platten (4/5 Daten und 1/5 Parität) aus, so ergibt sich folgendes Szenario: Will eine Anwendung 2.048 Byte schreiben, wird in diesem günstigen Fall auf alle 5 Platten genau je ein Block zu 512 Byte geschrieben, wobei einer dieser Blöcke keine Nutzdaten enthält. Im Vergleich zu RAID 0 mit 5 Platten ergibt sich daraus eine Effizienz von 80 % (bei RAID 5 mit 3 Platten wären es 66 %). Möchte eine Anwendung nur einen Block von 512 Byte schreiben, so ergibt sich ein ungünstigerer Fall, es müssen zuerst der abzuändernde Block und der Paritätsblock eingelesen werden, danach wird der neue Paritätsblock berechnet und erst dann können beide 512-Byte-Blöcke geschrieben werden. Das bedeutet einen Aufwand von 2 Lesezugriffen und 2 Schreibzugriffen, um einen Block zu speichern. Geht man vereinfacht davon aus, dass Lesen und Schreiben gleich lange dauern, so beträgt die Effizienz in diesem ungünstigsten Fall, dem sogenannten RAID 5 write Penalty, noch 25 %. In der Praxis wird dieser Worst-Case-Fall bei einem RAID 5 mit 5 Platten aber kaum eintreten, denn Dateisysteme haben häufig Blockgrößen von 2 kB, 4 kB und mehr und zeigen daher praktisch ausschließlich das Well-Case-Schreibverhalten. Gleiches gilt analog für RAID 5 mit 3 Platten. Unterschiedlich verhält sich hingegen etwa ein RAID-5-System mit 4 Platten (3/4 Daten und 1/4 Parität), soll hier ein Block von 2.048 Byte geschrieben werden, sind zwei Schreibvorgänge notwendig, es werden dann einmal 1.536 Byte mit Well-Case-Performance geschrieben und noch einmal 512 Byte mit Worst-Case-Verhalten. Diesem Worst-Case-Verhalten wirken zwar Cache-Strategien entgegen, aber dennoch ergibt sich hieraus, dass bei RAID 5 möglichst ein Verhältnis von zwei, vier oder auch acht Platten für Nutzdaten plus einer Platte für Paritätsdaten eingehalten werden sollte. Daher haben RAID-5-Systeme mit 3, 5 oder 9 Platten ein besonders günstiges Performanceverhalten.
Weniger gebräuchliche oder bedeutungslos gewordene RAID-Level
RAID 2: Bit-Level Striping mit Hamming-Code-basierter Fehlerkorrektur
RAID 2 spielt in der Praxis keine Rolle mehr. Das Verfahren wurde nur bei Großrechnern verwendet. Die Daten werden hierbei in Bitfolgen fester Größe zerlegt und mittels eines Hamming-Codes auf größere Bitfolgen abgebildet (zum Beispiel: 8 Bit für Daten und noch 3 Bit für die ECC-Eigenschaft). Die einzelnen Bits des Hamming-Codeworts werden dann über einzelne Platten aufgeteilt, was prinzipiell einen hohen Durchsatz erlaubt. Ein Nachteil ist jedoch, dass die Anzahl der Platten ein ganzzahliges Vielfaches der Hamming-Codewortlänge sein muss, wenn sich die Eigenschaften des Hamming-Codes nach außen zeigen sollen (diese Forderung entsteht, wenn man einen Bit-Fehler im Hamming-Code analog zu einem Festplatten-Ausfall im RAID 2 sieht).
Der kleinste RAID-2-Verbund benötigt drei Festplatten und entspricht einem RAID 1 mit zweifacher Spiegelung. Im realen Einsatz sah man daher zumeist nicht weniger als zehn Festplatten in einem RAID-2-Verbund.
RAID 3: Byte-Level Striping mit Paritätsinformationen auf separater Festplatte
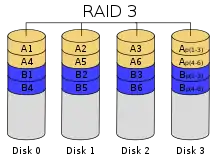
Der wesentliche Gedanke bei RAID 3 ist ein möglichst hoher Leistungsgewinn mit Redundanz im Verhältnis zum Anschaffungspreis. Im RAID 3 werden die eigentlichen Nutzdaten normal auf einer oder mehreren Datenplatten gespeichert. Außerdem wird eine Summeninformation auf einer zusätzlichen Paritätsplatte gespeichert. Für die Paritätsplatte werden die Bits der Datenplatten zusammengezählt und die errechnete Summe wird darauf untersucht, ob sie eine gerade oder eine ungerade Summe darstellt; eine gerade Summe wird auf der Paritätsplatte mit dem Bit-Wert 0 gekennzeichnet; eine ungerade Summe wird mit dem Bit-Wert 1 gekennzeichnet. Die Datenplatten enthalten also normale Nutzdaten, während die Paritätsplatte nur die Summeninformationen enthält.
Beispiel mit zwei Datenplatten und einer Paritätsplatte:
Bits der Datenplatten ⇒ Summe – gerade oder ungerade ⇒ Summen-Bit der Paritätsplatte 0, 0 ⇒ Summe (0) ist gerade ⇒ Summen-Bit 0 0, 1 ⇒ Summe (1) ist ungerade ⇒ Summen-Bit 1 1, 0 ⇒ Summe (1) ist ungerade ⇒ Summen-Bit 1 1, 1 ⇒ Summe (2) ist gerade ⇒ Summen-Bit 0
Ginge beispielsweise das Bit der ersten Datenplatte verloren, könnte man es aus dem Bit der zweiten Datenplatte und dem Summen-Bit der Paritätsplatte errechnen: Bits der Datenplatten & Summen-Bit der Paritätsplatte ⇒ rekonstruiertes Datum ?, 0 & 0 (also eine gerade Summe) ⇒ 0 (denn das erste Bit kann nicht 1 sein) ?, 1 & 1 (also eine ungerade Summe) ⇒ 0 (denn das erste Bit kann nicht 1 sein) ?, 0 & 1 (also eine ungerade Summe) ⇒ 1 (denn das erste Bit kann nicht 0 sein) ?, 1 & 0 (also eine gerade Summe) ⇒ 1 (denn das erste Bit kann nicht 0 sein)
Beispiel mit drei Datenplatten und einer Paritätsplatte:
Bits der Datenplatten ⇒ Summe – gerade oder ungerade ⇒ Summen-Bit der Paritätsplatte 0, 0, 0 ⇒ Summe (0) ist gerade ⇒ Summen-Bit 0 1, 0, 0 ⇒ Summe (1) ist ungerade ⇒ Summen-Bit 1 1, 1, 0 ⇒ Summe (2) ist gerade ⇒ Summen-Bit 0 1, 1, 1 ⇒ Summe (3) ist ungerade ⇒ Summen-Bit 1 0, 1, 0 ⇒ Summe (1) ist ungerade ⇒ Summen-Bit 1
Ginge beispielsweise das Bit der ersten Datenplatte verloren, könnte man es aus den Bits der anderen Datenplatten und dem Summen-Bit der Paritätsplatte errechnen. Bits der Datenplatten & Summen-Bit der Paritätsplatte ⇒ rekonstruiertes Datum ?, 0, 0 & 0 (also eine gerade Summe) ⇒ 0 (denn das erste Bit kann nicht 1 sein) ?, 0, 0 & 1 (also eine ungerade Summe) ⇒ 1 (denn das erste Bit kann nicht 0 sein) ?, 1, 0 & 0 (also eine gerade Summe) ⇒ 1 (denn das erste Bit kann nicht 0 sein) ?, 1, 1 & 1 (also eine ungerade Summe) ⇒ 1 (denn das erste Bit kann nicht 0 sein) ?, 1, 0 & 1 (also eine ungerade Summe) ⇒ 0 (denn das erste Bit kann nicht 1 sein)
In der Mikroelektronik ist dies identisch mit der XOR-Verknüpfung.
Der Gewinn durch ein RAID 3 ist folgender: Man kann beliebig viele Datenplatten verwenden und braucht für die Paritätsinformationen trotzdem nur eine einzige Platte. Die eben dargestellten Berechnungen ließen sich auch mit 4 oder 5 oder noch mehr Datenplatten (und nur einer einzigen Paritäts-Platte) durchführen. Damit ergibt sich auch gleich der größte Nachteil: Die Paritätsplatte wird bei jeder Operation, vor allem Schreiboperation, benötigt, sie bildet dadurch den Flaschenhals des Systems; auf diese Platten wird bei jeder Schreiboperation zugegriffen.
RAID 3 ist inzwischen vom Markt verschwunden und wurde weitgehend durch RAID 5 ersetzt, bei dem die Parität gleichmäßig über alle Platten verteilt wird. Vor dem Übergang zu RAID 5 wurde RAID 3 zudem partiell durch RAID 4 verbessert, bei dem Ein- beziehungsweise Ausgabe-Operationen mit größeren Blockgrößen aus Geschwindigkeitsgründen standardisiert wurden.
Ein RAID-3-Verbund aus nur zwei Festplatten (eine Datenplatte + eine Paritätsplatte) ist ein Spezialfall. Die Paritätsplatte enthält in diesem Fall die gleichen Bit-Werte wie die Datenplatte, damit entspricht der Verbund in der Wirkung einem RAID 1 mit zwei Festplatten (eine Datenplatte + eine Kopie der Datenplatte).
RAID 4: Block-Level Striping mit Paritätsinformationen auf separater Festplatte
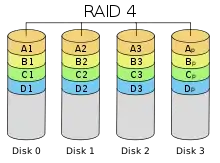
Es werden ebenfalls Paritätsinformationen berechnet, die auf eine dedizierte Festplatte geschrieben werden. Allerdings sind die Einheiten, die geschrieben werden, größere Datenblöcke (englisch stripes oder chunks) und nicht einzelne Bytes, was die Gemeinsamkeit zu RAID 5 ausmacht.
Ein Nachteil bei klassischem RAID 4 besteht darin, dass die Paritätsplatte bei allen Schreib- und Leseoperationen beteiligt ist. Dadurch ist die maximal mögliche Datenübertragungsgeschwindigkeit durch die Datenübertragungsgeschwindigkeit der Paritätsplatte begrenzt. Da bei jeder Operation immer eine der Datenplatten und die Paritätsplatte verwendet werden, muss die Paritätsplatte weit mehr Zugriffe durchführen als die Datenplatten. Sie verschleißt dadurch stärker und ist daher häufiger von Ausfällen betroffen.
Wegen der fest definierten Paritätsplatte bei RAID 4 wird stattdessen fast immer RAID 5 bevorzugt.
Eine Ausnahme bildet ein Systemdesign, bei dem die Lese- und Schreiboperationen auf ein NVRAM erfolgen. Das NVRAM bildet einen Puffer, der die Übertragungsgeschwindigkeit kurzfristig erhöht, die Lese- und Schreiboperationen sammelt und in sequenziellen Abschnitten auf das RAID-4-Plattensystem schreibt. Dadurch werden die Nachteile von RAID 4 vermindert und die Vorteile bleiben erhalten.
NetApp nutzt RAID 4 in ihren NAS-Systemen, das verwendete Dateisystem WAFL wurde speziell für den Einsatz mit RAID 4 entworfen. Da RAID 4 nur bei sequentiellen Schreibzugriffen effektiv arbeitet, verwandelt WAFL wahlfreie Schreibzugriffe (random writes) im NVRAM-Cache in sequentielle – und merkt sich jede einzelne Position für den späteren Abruf. Beim Lesen tritt allerdings das klassische Fragmentierungsproblem auf: Zusammengehörige Daten stehen nicht notwendigerweise auf physisch hintereinanderliegenden Blöcken, wenn sie im Nachhinein aktualisiert oder überschrieben wurden. Die verbreitetste Beschleunigung von Lesezugriffen, der Cache prefetch, ist daher ohne Wirkung. Die Vorteile beim Schreiben ergeben somit einen Nachteil beim Lesen. Das Dateisystem muss dann regelmäßig defragmentiert werden.
RAID 6: Block-Level Striping mit doppelt verteilter Paritätsinformation
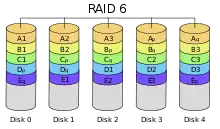
RAID 6 (unter diversen Handelsnamen angeboten, zum Beispiel Advanced Data Guarding) funktioniert ähnlich wie RAID 5, verkraftet aber den gleichzeitigen Ausfall von bis zu zwei Festplatten. Insbesondere beim intensiven Einsatz hochkapazitiver SATA-/IDE-Festplatten kann die Wiederherstellung der Redundanz nach dem Ausfall einer Platte viele Stunden bis hin zu Tagen dauern; bei RAID 5 besteht währenddessen kein Schutz vor einem weiteren Ausfall.
RAID 6 implementiert Striping mit doppelten, auf Block-Level verteilten Paritätsinformationen. Im Gegensatz zu RAID 5 gibt es bei RAID 6 mehrere mögliche Implementierungsformen, die sich insbesondere in der Schreibleistung und dem Rechenaufwand unterscheiden. Im Allgemeinen gilt: Bessere Schreibleistung wird durch erhöhten Rechenaufwand erkauft. Im einfachsten Fall wird eine zusätzliche XOR-Operation über eine orthogonale Datenzeile berechnet, siehe Grafik. Auch die zweite Parität wird rotierend auf alle Platten verteilt. Eine andere RAID-6-Implementierung rechnet mit nur einer Datenzeile, produziert allerdings keine Paritätsbits, sondern einen Zusatzcode, der 2 Einzelbit-Fehler beheben kann. Das Verfahren ist rechnerisch aufwändiger. Zum Thema Mehrbit-Fehlerkorrektur siehe auch Reed-Solomon-Code.
Für alle RAID-6-Implementierungen gilt gemeinsam: Der Performance-Malus bei Schreiboperationen (Write Penalty) ist bei RAID 6 etwas größer als bei RAID 5, die Leseleistung ist bei gleicher Gesamtplattenzahl geringer (eine Nutzdatenplatte weniger) beziehungsweise der Preis pro nutzbarem Gigabyte erhöht sich um eine Festplatte je RAID-Verbund, also im Schnitt um ein Siebtel bis zu ein Fünftel. Ein RAID-6-Verbund benötigt mindestens vier Festplatten.
RAIDn
Bei RAIDn handelt es sich um eine Entwicklung der Inostor Corp., einer Tochter von Tandberg Data. RAIDn hebt die bisher starre Definition der RAID-Level auf.
Dieses RAID wird definiert durch die Gesamtzahl der Festplatten (n) sowie die Anzahl der Festplatten, die ohne Datenverlust ausfallen dürfen (m). Als Schreibweise hat sich RAID(n,m) oder RAID n+m eingebürgert.
Aus diesen Definitionen können die Kenndaten des RAID wie folgt berechnet werden:
- Lesegeschwindigkeit = n × Lesegeschwindigkeit der Einzelplatte
- Schreibgeschwindigkeit = (n − m) × Schreibgeschwindigkeit der Einzelplatte
- Kapazität = (n − m) × Kapazität der Einzelplatte
Einige spezielle Definitionen wurden wie folgt festgelegt:
- RAID(n,0) entspricht RAID 0
- RAID(n,n-1) entspricht RAID 1
- RAID(n,1) entspricht RAID 5
- RAID(n,2) entspricht RAID 6
RAID DP: Block-Level Striping mit doppelter Paritätsinformation auf separaten Festplatten
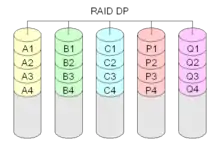
RAID DP (double, dual oder manchmal diagonal parity) ist eine von NetApp weiterentwickelte Version von RAID 4. Hierbei wird eine zweite Parität nach derselben Formel wie die erste Parität P berechnet, jedoch mit anderen Datenblöcken. Die erste Parität wird horizontal, die zweite Parität Q diagonal berechnet. Zudem wird bei der Berechnung der diagonalen Parität jeweils die erste Parität mit einbezogen, dafür aber abwechselnd eine Festplatte nicht. Da in einem RAID DP zwei beliebige Festplattenfehler kompensiert werden können, ist die Verfügbarkeit eines solchen Systems gegenüber einer Single-Paritätslösung (also z. B. RAID 4 oder RAID 5) gesteigert.
RAID-DP-Sets bestehen in der Regel aus 14 + 2 Platten. Somit liegt der Brutto-Netto-Verschnitt ähnlich niedrig wie bei RAID 4/RAID 5.







RAID DP vereinfacht die Wiederherstellung. Hierbei werden zuerst mit der diagonalen Parität die Daten der ersten ausgefallenen Festplatte berechnet und danach aus der horizontalen Parität der Inhalt der zweiten Festplatte.
Die Rechenoperationen beschränken sich im Gegensatz zum RAID 6, wo ein Gleichungssystem zu lösen ist, auf einfache XOR-Operationen. RAID DP kann jederzeit auf RAID 4 umgeschaltet werden (und umgekehrt), indem man einfach die zweite Paritätsplatte abschaltet (bzw. wiederherstellt). Dies geschieht ohne ein Umkopieren oder Umstrukturieren der bereits gespeicherten Daten im laufenden Betrieb.
Details zu RAID DP können in der USENIX Veröffentlichung Row-Diagonal Parity for Double Disk Failure Correction gefunden werden.[12]
Nichteigentliche RAIDs: Festplattenverbund
NRAID
Streng genommen handelt es sich bei NRAID (= Non-RAID: kein eigentliches RAID) nicht um ein wirkliches RAID – es gibt keine Redundanz. Bei NRAID (auch als linear mode oder concat(enation) bekannt) werden mehrere Festplatten zusammengeschlossen. Die von einigen RAID-Controllern angebotene NRAID-Funktion ist mit dem klassischen Herangehen über einen Logical Volume Manager (LVM) zu vergleichen und weniger mit RAID 0, denn im Gegensatz zu RAID 0 bietet NRAID kein Striping über mehrere Platten hinweg und daher auch keinen Gewinn beim Datendurchsatz. Dafür kann man Festplatten unterschiedlicher Größe ohne Speicherverlust miteinander kombinieren (Beispiel: eine 10-GB-Festplatte und eine 30-GB-Festplatte ergeben in einem NRAID eine virtuelle 40-GB-Festplatte, während in einem RAID 0 nur 20 GB (10 + 10 GB) genutzt werden könnten).
Da es bei dem zugrunde liegenden linear mode keine Stripes gibt, wird bei einem solchen Verbund erst die erste Festplatte mit Daten gefüllt und erst dann, wenn weiterer Platz benötigt wird, kommt die zweite Platte zum Einsatz. Reicht auch diese nicht aus wird – falls vorhanden – die nächste Platte beschrieben. Folglich gibt es bei einem Ausfall einer Platte zwei Möglichkeiten: Zum einen kann diese (noch) keine Daten enthalten, dann gehen – je nach Implementierung der Datenwiederherstellung – möglicherweise auch keine Daten verloren. Zum anderen kann die defekte Platte bereits Daten enthalten haben, dann hat man auch hier den Nachteil, dass der Ausfall der einzelnen Platte den gesamten Verbund beschädigt. Das fehlende Striping erleichtert aber auch das Wiederherstellen einzelner nicht betroffener Dateien. Im Unterschied zu RAID 0 führt der Ausfall einer Platte hier also nicht unbedingt zu einem kompletten Datenverlust, zumindest solange sich die Nutzdaten komplett auf der noch funktionierenden Platte befinden.
NRAID ist weder einer der nummerierten RAID-Levels, noch bietet es Redundanz. Man kann es aber durchaus als entfernten Verwandten von RAID 0 betrachten. Beide machen aus mehreren Festplatten eine einzige logische Einheit, deren Datenkapazität – mit denen für RAID 0 genannten Einschränkungen – der Summe der Kapazitäten aller verwendeten Platten entspricht. Heutzutage sind Controller, die mit der Eigenschaft NRAID verkauft werden, in der Lage, dies zu tun. Die Platten, die auch von unterschiedlicher Größe sein können, werden einfach aneinandergehängt. Im Unterschied zu RAID 0 werden allerdings keine Stripesets gebildet. Es gibt weder Ausfallsicherheit, noch Performancegewinn. Der Vorteil liegt im Wesentlichen in der Größe des resultierenden Laufwerks, so wie in einer etwas verbesserten Situation bei der Datenrettung. Ein Vorteil im Vergleich zu einer LVM-Lösung ist, dass es bei NRAID problemlos möglich ist, vom RAID-Verbund zu booten.
Da die meisten modernen Betriebssysteme mittlerweile über einen Logischen Volume Manager (LVM, wird manchmal auch als Manager für dynamische Datenträger bezeichnet) verfügen, ist es aber oft sinnvoller, diesen zu benutzen. Der im Betriebssystem integrierte LVM birgt praktisch keine messbaren Performancenachteile und arbeitet unabhängig von spezieller Hardware, er kann daher auch Festplatten verschiedener Typen (SCSI, SATA, USB, iSCSI, AoE, uvm.) miteinander zusammenfassen. Auch braucht man bei einem defekten RAID-Controller nicht nach einem baugleichen Modell zu suchen, die Platten können in der Regel einfach an jeden beliebigen Controller mit gleichem Festplatten-Interface angeschlossen werden. Die Wiederherstellung erfolgt dann über das jeweilige Betriebssystem. Wurde allerdings (falls dies überhaupt möglich ist) direkt vom zusammengesetzten logischen Volume gebootet, kann dies die Wiederherstellung enorm erschweren.
SPAN
Von VIA wird in seiner RAID-Konfiguration unter anderem die Option SPAN angeboten. Sie dient zur Kapazitätserweiterung ohne Leistungsgewinn wie bei NRAID. Während bei RAID 0 (Striping) die Daten gleichzeitig auf mehrere Festplatten verteilt werden, gelangen die Daten bei SPAN zusammenhängend auf eine Festplatte. Bei RAID 0 sollten nach Möglichkeit gleich große Festplatten verwendet werden, da die überschüssige Kapazität des größeren Datenträgers verlorengeht. Bei SPAN sind unterschiedlich große Festplatten ohne Kapazitätsverlust zu einer großen Festplatte zusammenfassbar, was Linear Mode oder NRAID entspricht.
JBOD
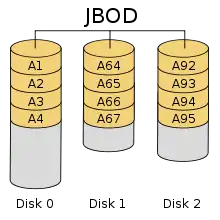
JBOD bedeutet Just a Bunch of Disks, also: Nur ein Haufen Festplatten. Bei JBOD fehlt die Redundanz, daher gehört es nicht zu den RAID-Systemen, es ist nur ein einfaches „Array of Independent Disks“. Der Begriff wird in der Praxis in Abgrenzung zu RAID-Systemen auf drei verschiedene Arten verwendet:
- Konfiguration eines RAID-Controllers mit mehreren Festplatten, die keinen Verbund bilden. Viele Hardware-RAID-Controller sind in der Lage, die angeschlossenen Festplatten dem Betriebssystem einzeln zur Verfügung zu stellen; die RAID-Funktionen des Controllers werden dabei abgeschaltet und er arbeitet als einfacher Festplatten-Controller.
- Ein JBOD kann auch, unabhängig vom Controller, eine auf beliebige Arten an den Computer angeschlossene Anzahl von Festplatten bezeichnen. Mithilfe einer Volume Management Software kann ein solches JBOD zu einem gemeinsamen logischen Volume zusammengeschaltet werden.
- Konfiguration eines RAID-Controllers als Aneinanderreihung („concatenation“) einer oder mehrerer Festplatten, die so als ein einziges Laufwerk erscheinen. Es ist jedoch auch möglich, eine Festplatte in mehrere logische Datenträger aufzuteilen, um diese für das Betriebssystem als mehrere Festplatten erscheinen zu lassen, zum Beispiel um Kapazitätsgrenzen zu umgehen. Diese Konfiguration ist identisch mit NRAID oder SPAN und ist genau genommen auch kein RAID-System.
RAID-Kombinationen
Obwohl die RAID-Level 0, 1 und 5 die weitaus größte Verwendung finden, existieren neben den Leveln 0 bis 6 noch „RAID-Kombinationen“. Hier wird ein RAID nochmals zu einem zweiten RAID zusammengefasst. Beispielsweise können mehrere Platten zu einem parallelen RAID 0 zusammengefasst werden und aus mehreren dieser RAID-0-Arrays zum Beispiel ein RAID-5-Array gebildet werden. Man bezeichnet diese Kombinationen dann etwa als RAID 05 (0+5). Umgekehrt würde ein Zusammenschluss von mehreren RAID-5-Arrays zu einem RAID-0-Array als RAID 50 (oder RAID 5+0) bezeichnet werden. Auch RAID-1- und RAID-5-Kombinationen sind möglich (RAID 15 und RAID 51), die beliebtesten Kombinationen sind allerdings das RAID 01, bei dem je zwei Platten parallel arbeiten und dabei von zwei anderen Platten gespiegelt werden (insgesamt vier Platten), oder RAID 10, bei dem (mindestens) zwei mal zwei Platten gespiegelt werden und dabei per RAID 0 zu einem Ganzen ergänzt werden.
Selten werden RAIDs auch mit mehr Layern zusammengefasst (z. B. RAID 100).
RAID 01
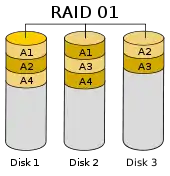
Ein RAID-01-Verbund ist ein RAID 1 über mehrere RAID 0. Dabei werden die Eigenschaften der beiden RAIDs kombiniert: Sicherheit (geringer als beim RAID 10) und gesteigerter Datendurchsatz.
Häufig wird behauptet, ein konventioneller, aktueller RAID-01-Verbund benötige mindestens vier Festplatten. Das ist nicht ganz richtig. Mindestens vier (oder genereller: eine gerade Anzahl ≥ 4) Festplatten werden nur für den bekannteren, klassischen RAID-10-Verbund benötigt. Aber auch mit nur drei Festplatten lässt sich auf vielen RAID-Controllern ein RAID-01-Verbund bilden. Die Vorgehensweise ist folgende: Zunächst werden die Platten (genau wie bei RAID 0) nur in fortlaufend nummerierte Chunks (= Blöcke, Nummerierung beginnend mit 1) eingeteilt, dann werden alle Chunks mit ungeraden Nummern mit dem nächsthöheren Nachbarn mit gerader Nummer gespiegelt. Die Platten werden dabei jeweils zu 50 % mit Nutzdaten belegt, die übrigen 50 % jeder Platte enthalten eine Kopie der Nutzdaten einer der anderen Platten. Die Nutzdaten sowie die gespiegelten Daten werden verteilt (striped). Bei drei Platten sieht das so aus:
- Platte A: 50 % Nutzdaten + 50 % Spiegelung Nutzdaten Platte C
- Platte B: 50 % Nutzdaten + 50 % Spiegelung Nutzdaten Platte A
- Platte C: 50 % Nutzdaten + 50 % Spiegelung Nutzdaten Platte B
Die Nutzdaten werden dabei ebenso wie die gespiegelten Daten RAID-0-typisch über die Platten A, B und C verteilt (striped). Bei Ausfall einer Platte sind immer noch alle Daten vorhanden. Hinsichtlich der Ausfallwahrscheinlichkeit gibt es theoretisch keinen Unterschied zu RAID 5 mit drei Festplatten. Zwei von drei Laufwerken müssen intakt bleiben, damit das System funktioniert. Im Unterschied zu RAID 5 steht bei RAID 01 mit vier Festplatten jedoch weniger Speicherplatz zur Verfügung.
RAID 05
Ein RAID-05-Verbund besteht aus einem RAID-5-Array, das aus mehreren striped RAID 0 besteht. Er benötigt mindestens drei RAID 0, somit mind. 6 Festplatten. Bei RAID 05 besteht fast doppelte Ausfallchance im Vergleich zu einem herkömmlichen RAID 5 aus Einzelplatten, da bei einem RAID 0 schon beim Defekt eines Laufwerkes alle Daten verloren sind.
RAID 10
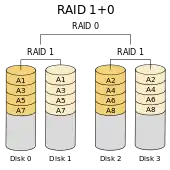
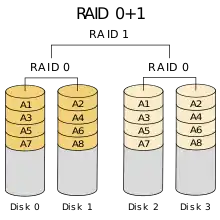
Ein RAID-10-Verbund ist ein RAID 0 über mehrere RAID 1. Es werden dabei die Eigenschaften der beiden RAIDs kombiniert: Sicherheit und gesteigerte Schreib-/Lesegeschwindigkeit.
Ein RAID-10-Verbund benötigt mindestens vier Festplatten.
Während die RAID-1-Schicht einer RAID-0+1-Implementation nicht in der Lage ist, einen Schaden in einem untergeordneten RAID 0 differenziert den einzelnen Festplatten zuzuordnen, bietet RAID 10 gegenüber RAID 0+1 eine bessere Ausfallsicherheit und schnellere Rekonstruktion nach einem Plattenausfall, da nur ein Teil der Daten rekonstruiert werden muss.[14] Auch hier hat man wie bei RAID 0+1 nur die Hälfte der gesamten Festplattenkapazität zur Verfügung.
RAID 1.5
RAID 1.5 ist eigentlich kein eigenes RAID-Level, sondern ein durch das Unternehmen Highpoint eingeführter Ausdruck für eine RAID-1-Implementierung mit gesteigerter Performance. Es nutzt typische Vorteile einer RAID-0-Lösung auch bei RAID 1. Die Optimierungen können im Unterschied zu RAID 10 bereits mit nur zwei Festplatten verwendet werden. Dabei werden die beiden Platten in einfacher Geschwindigkeit wie bei RAID 1 üblich gespiegelt beschrieben, während beim Lesen beide Platten mit hohem Datendurchsatz wie bei RAID 0 genutzt werden. Die RAID-1.5-Erweiterungen, nicht zu verwechseln mit RAID 15, werden allerdings nicht nur von Highpoint implementiert. Versierte RAID-1-Implementierungen, wie die unter Linux oder Solaris, lesen ebenfalls von allen Platten und verzichten auf den Ausdruck RAID 1.5, der keinen Extravorteil bietet.
RAID 15
Das RAID-15-Array wird gebildet, indem man mindestens drei RAID-1-Arrays als Bestandteile für ein RAID 5 verwendet; es ist im Konzept ähnlich wie RAID 10, außer dass das Striping mit einer Parität erfolgt.
Bei einem RAID 15 mit acht Festplatten dürfen bis zu drei beliebige Platten gleichzeitig ausfallen (insgesamt bis zu fünf, sofern maximal ein Mirrorset komplett ausfällt).
Ein RAID-15-Verbund benötigt mindestens sechs Festplatten.
Der Datendurchsatz ist gut, aber nicht sehr hoch. Die Kosten sind mit denen anderer RAID-Systeme nicht direkt vergleichbar, dafür ist das Risiko eines kompletten Datenverlustes recht gering.
RAID 1E
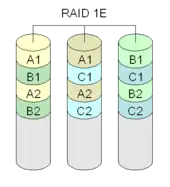
Beim RAID 1E werden einzelne Datenblöcke auf die jeweils nächste Festplatte gespiegelt. Es dürfen hierbei weder zwei benachbarte noch die erste und die letzte Festplatte gleichzeitig ausfallen. Für ein RAID 1E wird immer eine ungerade Anzahl von Festplatten benötigt. Die nutzbare Kapazität reduziert sich um die Hälfte.
Es gibt allerdings noch andere Versionen von RAID 1E, die flexibler sind als die hier dargestellte Variante.
RAID 1E0
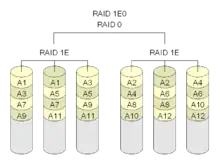
Bei einem RAID 1E0 werden mehrere RAID 1E mit einem RAID 0 zusammengeschaltet. Die maximale Anzahl der redundanten Platten und die Nettokapazität entspricht dem zugrundeliegenden RAID 1E.
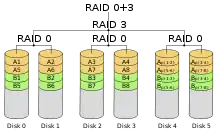
RAID-30-Verbund
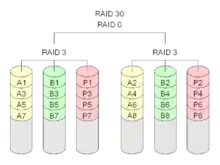
RAID 30 wurde ursprünglich von American Megatrends entwickelt. Es stellt eine Striped-Variante von RAID 3 dar (das heißt ein RAID 0, welches mehrere RAID 3 zusammenfasst).
Ein RAID-30-Verbund benötigt mindestens sechs Festplatten (zwei Legs mit je drei Festplatten). Es darf eine Festplatte in jedem Leg ausfallen.
RAID-45-Verbund
Ein RAID-45-Verbund fasst, ähnlich dem RAID 55, mehrere RAID 4 mit einem RAID 5 zusammen. Man benötigt hierfür mindestens drei RAID-4-Legs zu je drei Festplatten und damit neun Festplatten. Bei neun Festplatten sind nur vier Festplatten nutzbar, das Verhältnis verbessert sich allerdings mit der Anzahl der verwendeten Festplatten. RAID 45 wird daher nur in großen Festplattenverbänden eingesetzt. Die Ausfallsicherheit ist sehr hoch, da mindestens drei beliebige Festplatten, zusätzlich eine Festplatte in jedem Leg und dazu noch ein komplettes Leg ausfallen dürfen.
RAID-50-Verbund
Ein RAID-50-Verbund besteht aus einem RAID-0-Array, das aus mehreren striped RAID 5 besteht.
Ein RAID-50-Verbund benötigt mindestens sechs Festplatten, beispielsweise zwei RAID-5-Controller mit jeweils drei Platten pro Controller zusammengeschaltet mit einem Software-Stripe RAID 0. Das garantiert einen sehr hohen Datendurchsatz beim Schreiben und Lesen, da die Rechenarbeit auf zwei XOR-Units verteilt wird.
Bei einem RAID-50-Verbund mit sechs Festplatten darf nur eine Platte gleichzeitig ausfallen (insgesamt bis zu zwei, sofern die beiden Platten nicht zum selben RAID-5-Verbund gehören).
Ein RAID-50-Verbund wird bei Datenbanken verwendet, bei denen Schreibdurchsatz und Redundanz im Vordergrund stehen.
RAID 51
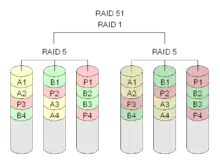
Der RAID-51-Verbund wird ähnlich wie RAID 15 gebildet, indem man die gesamte Reihe eines RAID 5 spiegelt, und ist ähnlich wie RAID 01, abgesehen vom Paritätsschutz.[15]
Bei einem Sechs-Festplatten-RAID-51 dürfen bis zu drei beliebige gleichzeitig ausfallen. Darüber hinaus dürfen vier Festplatten ausfallen, solange nur eine Platte aus dem gespiegelten RAID-5-Verbund betroffen ist.
Ein RAID-51-Verbund benötigt mindestens sechs Festplatten.
Die Datenübertragungs-Leistung ist gut, aber nicht sehr hoch. Die Kosten sind mit denen anderer RAID-Systeme nicht direkt vergleichbar.
RAID 53
RAID 53 ist eine in der Praxis gängige Bezeichnung für ein RAID 30.
RAID 55
Der RAID-55-Verbund wird ähnlich wie RAID 51 gebildet, indem mehrere RAID-5-Systeme über ein weiteres RAID 5 zu einem RAID 55 zusammengeschaltet werden. Im Gegensatz zu RAID 51 ist der Overhead geringer und es ist möglich, schneller die Daten zu lesen.
Bei einem Neun-Festplatten-RAID-55-System dürfen bis zu drei beliebige Festplatten gleichzeitig ausfallen. Insgesamt dürfen maximal fünf Festplatten ausfallen (3+1+1). Ein RAID-55-Verbund benötigt mindestens neun Festplatten (drei Legs zu je drei Festplatten). Die Datenübertragungs-Geschwindigkeit ist gut, aber nicht sehr hoch. Die Kosten sind mit denen anderer RAID-Systeme nicht direkt vergleichbar.
RAID 5E
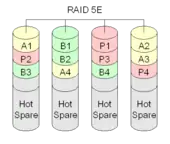
RAID 5E ist die Abkürzung für RAID 5 Enhanced. Es kombiniert ein RAID 5 mit einem Hot-Spare. Der Hot-Spare wird dabei allerdings nicht als getrenntes Laufwerk ausgeführt, sondern auf die einzelnen Platten aufgeteilt. Anders ausgedrückt wird auf jeder Platte Speicherplatz für den Fall eines Ausfalles reserviert. Sollte eine Festplatte ausfallen, wird der Inhalt dieser Platte im freien Speicherplatz mit Hilfe der Parität wiederhergestellt und das Array kann als RAID 5 weiterbetrieben werden.
Der Vorteil liegt nicht in einer gesteigerten Sicherheit gegenüber RAID 5, sondern in der höheren Geschwindigkeit durch ständige Nutzung aller vorhandenen Plattenspindeln, inklusive der üblicherweise leer mitlaufenden Hot-Spare-Platte.
Die Technik wird schon lange bei IBM für RAID-Controller eingesetzt, jedoch immer mehr durch RAID 5EE ersetzt.
RAID 5EE
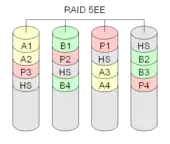
RAID 5EE arbeitet ähnlich wie RAID 5E. Allerdings wird hierbei der freie Speicherplatz nicht am Ende der Festplatten reserviert, sondern ähnlich der RAID-5-Parität über die Platten diagonal verteilt. Dadurch bleibt beim Ausfall eine höhere Übertragungsgeschwindigkeit bei der Wiederherstellung der Daten.
RAID 5DP und RAID ADG
RAID 5DP ist die von Hewlett-Packard verwendete Bezeichnung der Implementierung für RAID 6 in den Speicher-Systemen der VA-Baureihe. Durch die Übernahme von Compaq AG durch Hewlett Packard ging die für die durch Compaq entwickelte RAID-6-Variante RAID ADG für die Compaq Smart Arrays ebenfalls in das geistige Eigentum von Hewlett Packard über. Das Akronym ADG steht hier für Advanced Data Guarding.
RAID-60-Verbund
Ein RAID-60-Verbund besteht aus einem RAID-0-Array, das mehrere RAID 6 kombiniert. Hierzu sind mindestens zwei Controller mit je vier Festplatten, also gesamt acht Festplatten, notwendig. Prinzipiell skalieren sich die Unterschiede von RAID 5 und RAID 6 hoch auf die Unterschiede zwischen RAID 50 und RAID 60: Der Durchsatz ist geringer, während die Ausfallsicherheit höher ist. Der gleichzeitige Ausfall von zwei beliebigen Laufwerken ist jederzeit möglich; weitere Ausfälle sind nur dann unkritisch, wenn maximal zwei Platten je gestriptem RAID 6 betroffen sind.
Matrix-RAID
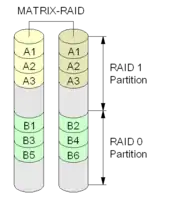
Ab der Intel ICH6R-Southbridge ist seit etwa Mitte 2004 erstmals eine Technik integriert, die als „Matrix-RAID“ vermarktet wird und die Idee von RAID 1.5 aufgreift. Sie soll die Vorteile von RAID 0 und RAID 1 auf nur zwei Festplatten vereinen. Jede der beiden Platten wird vom Controller zu diesem Zweck in zwei Bereiche aufgeteilt. Ein Bereich wird dann auf die andere Festplatte gespiegelt, während im verbleibenden Bereich die Daten auf beide Platten aufgeteilt werden. Man kann dann zum Beispiel im aufgeteilten Bereich sein „unwichtiges“ Betriebssystem und Programme installieren, um von RAID 0 zu profitieren, während man im gespiegelten Bereich dann seine wichtigen Daten abspeichern kann und auf die Redundanz von RAID 1 vertrauen kann. Im Falle eines Plattencrashes müsste man dann nur sein Betriebssystem und Programme neu aufspielen, während die wichtigen Daten im anderen Festplattenbereich erhalten bleiben.
Mit mehreren Festplatten kann man in einem Matrix-RAID auch andere RAID-Typen einsetzen und beispielsweise ab drei Festplatten eine Partition als RAID 5 betreiben.
RAID S beziehungsweise Parity RAID
RAID S beziehungsweise Parity RAID, manchmal auch als RAID 3+1, RAID 7+1 oder RAID 6+2 beziehungsweise RAID 14+2 bezeichnet, ist ein proprietäres Striped-Parity-RAID des Herstellers EMC. Ursprünglich nannte EMC diese Form RAID S bei den Symmetrix-Systemen. Seit dem Marktauftritt der neuen Modelle DMX heißt diese RAID-Variante Parity-RAID. Inzwischen bietet EMC auch Standard-RAID-5 an. Laut Angaben von EMC dürfen bei Parity-RAID-„+2“-Typen bis zu zwei Festplatten ausfallen.
RAID S stellt sich wie folgt dar: Ein Volume ist jeweils auf einem physischen Laufwerk, mehrere Volumes (meistens drei bzw. sieben) werden willkürlich zu Paritätszwecken kombiniert. Dies ist nicht genau identisch mit RAID 3, 4 oder 5, denn bei RAID S geht es immer um zahlreiche (evtl. 100 oder 1.000) Laufwerke die nicht alle gemeinsam einen einzelnen Verbund bilden. Vielmehr bilden wenige Platten (typisch: 4 bis 16) einen RAID-S-Verbund, ein oder mehrere dieser Verbünde bilden logische Einheiten – eine Ähnlichkeit zu den RAID-Leveln 50 oder 60 und RAID-Z ist unverkennbar. Außerdem werden bei RAID 5 die auf physischen Laufwerken befindlichen Volumes, abweichend Chunks genannt. Mehrere Chunks für Daten werden zusammen mit einem Paritäts-Chunk zu einem Stripe zusammengefasst. Aus beliebig vielen Stripes wird dann die Basis für eine Partition oder ein logisches Volume gebildet.
Ein Parity RAID 3+1 beinhaltet drei Daten-Volumes und ein Paritäts-Volume. Hiermit ist eine Nutzung von 75 % der Kapazität möglich. Beim Parity RAID 7+1 hingegen sind sieben Daten-Volumes und ein Paritäts-Volume vorhanden. Hiermit ist jedoch bei geringerer Ausfallsicherheit eine Nutzung von 87,5 % der Kapazität möglich. Bei normalem RAID 5 aus vier Platten beinhaltet ein Stripe drei Chunks mit Daten und einen Paritäts-Chunk. Bei normalem RAID 5 aus acht Platten beinhaltet ein Stripe dann sieben Chunks mit Daten und ebenfalls einen Paritäts-Chunk.
Darüber hinaus bietet EMC noch als Option für diese RAID-Varianten die Hypervolume Extension (HVE) an. HVE erlaubt mehrere Volumes auf demselben physischen Laufwerk.
EMC parity RAID EMC parity RAID mit HVE --------------- ----------------------- A1 B1 C1 pABC A B C pABC A2 B2 C2 pABC D E pDEF F A3 B3 C3 pABC G pGHI H I A4 B4 C4 pABC pJKL J K L
Hinweis: A1, B1 etc. stellen einen Datenblock dar; jede Spalte stellt eine Festplatte dar. A, B etc. sind gesamte Volumes.
RAID TP beziehungsweise RAID Triple Parity
RAID TP beziehungsweise RAID Triple Parity ist ein proprietäres RAID mit dreifacher Parität vom Hersteller easyRAID. Laut Herstellerangaben können bei RAID TP ohne Datenverlust bis zu drei Festplatten ausfallen. Eine weitere Triple Parity Implementierung stammt von Sun Microsystems und wird als Triple-Parity RAID-Z oder RAID-Z3 vermarktet.[16] Diese in das ZFS integrierte Version nutzt zur Absicherung der Daten einen Reed-Solomon-Code, auch hier können ohne Datenverlust bis zu drei Festplatten eines RAID-Verbunds defekt sein.
Beim RAID TP von easyRAID werden die Datenblöcke und die Paritäten zeitgleich jeweils auf die einzelnen physischen Festplatten geschrieben. Die drei Paritäten werden auf verschiedene Stripes auf unterschiedlichen Platten abgelegt. Der RAID-Triple-Parity-Algorithmus benutzt einen speziellen Code mit einem Hamming-Abstand von mindestens 4.
| Disk1 | Disk2 | Disk3 | Disk4 | Disk5 |
|---|---|---|---|---|
| A1 | B1 | pP(A1,B1) | pQ(A1,B1) | pR(A1,B1) |
| C1 | pP(C1,D1) | pQ(C1,D1) | pR(C1,D1) | D1 |
| pP(E1,F1) | pQ(E1,F1) | pR(E1,F1) | E1 | F1 |
| A2 | B2 | pP(A2,B2) | pQ(A2,B2) | pR(A2,B2) |
| C2 | pP(C2,D2) | pQ(C2,D2) | pR(C2,D2) | D2 |
| pP(E2,F2) | pQ(E2,F2) | pR(E2,F2) | E2 | F2 |
Hinweis: A1, B1 etc. stellen einen Datenblock dar; jede Spalte stellt eine Festplatte dar. A, B etc. sind gesamte Volumes.
Hierzu benötigt man mindestens vier Festplatten. Die Kapazität errechnet sich aus Festplattenanzahl minus drei.
RAID-Z im Dateisystem ZFS
RAID-Z ist ein von Sun Microsystems im Dateisystem ZFS integriertes RAID-System. ZFS ist ein weiterentwickeltes Dateisystem, welches zahlreiche Erweiterungen für die Verwendung im Server- und Rechenzentrumsbereich enthält. Hierzu zählen die enorme maximale Dateisystemgröße, eine einfache Verwaltung selbst komplexer Konfigurationen, die integrierten RAID-Funktionalitäten, das Volume-Management sowie der prüfsummenbasierte Schutz vor Platten- und Datenübertragungsfehlern. Bei redundanter Speicherung ist so eine automatische Fehlerkorrektur möglich. Die Integration der RAID-Funktionalität in das Dateisystem hat den Vorteil, dass Blockgrößen des Dateisystems und der RAID-Volumes aufeinander abgestimmt werden können,[17] wodurch sich zusätzliche Optimierungsmöglichkeiten ergeben.[18] Das ins Dateisystem integrierte RAID-Subsystem bietet gegenüber klassischen Hardware- oder Software-RAID-Implementierungen den Vorteil, dass durch das integrierte RAID-System zwischen belegten und freien Datenblöcken unterschieden werden kann und somit bei der Rekonstruktion eines RAID-Volumens nur belegter Plattenplatz gespiegelt werden muss, woraus im Schadensfall, besonders bei wenig gefüllten Dateisystemen, eine enorme Zeitersparnis resultiert. Elementare redundante Einheiten nennt das ZFS Redundancy Groups: Diese sind als Verbünde aus RAID 1, RAID Z1 (~RAID 5) und RAID Z2 (~RAID 6) realisiert. Eine oder mehrere Redundancy Groups bilden (analog zu kombiniertem RAID 0) zusammen ein ZFS-Volume (oder ZFS-Pool), aus dem dynamisch „Partitionen“ angefordert werden können. RAID-Z1 arbeitet analog zu RAID 5, gegenüber einem traditionellen RAID-5-Array ist RAID-Z1 gegen Synchronisationsprobleme („write hole“) geschützt und bietet daher Performance-Vorteile – analog gilt dies auch für RAID-Z2 und RAID 6. Seit Juli 2009 ist auch RAID-Z3, also eine RAID-Z-Implementierung mit drei Paritätsbits, verfügbar.[16] Der Begriff write hole bezeichnet eine Situation, die bei Schreibzugriffen entsteht, wenn die Daten bereits auf die Festplatten geschrieben wurden, die dazugehörige Paritätsinformation aber noch nicht. Sollte während dieses Zustands ein Problem beim Berechnen oder Schreiben der Paritätsinformation auftreten, passen diese nicht mehr zu den gespeicherten Datenblöcken.
Zusammenfassung
- Anzahl der Festplatten
- Die Anzahl der Festplatten gibt an, wie viele Festplatten benötigt werden, um das jeweilige RAID aufzubauen.
- Nettokapazität
- Die Nettokapazität gibt die nutzbare Kapazität in Abhängigkeit von der Anzahl der verwendeten Festplatten an. Dies entspricht der Anzahl der benötigten Festplatten ohne RAID, die die gleiche Speicherkapazität aufweisen.
- Ausfallsicherheit
- Die Ausfallsicherheit gibt an, wie viele Festplatten ausfallen dürfen, ohne dass ein Datenverlust auftritt. Zu beachten ist, dass es insbesondere bei den Kombinations-RAIDs einen Unterschied geben kann zwischen der Anzahl der Festplatten, die auf jeden Fall ausfallen können () und der Anzahl der Festplatten, die im günstigsten Fall ausfallen können (). Es gilt immer , und für Standard-RAIDs sind diese beiden Werte identisch.
- Leg
- Ein Leg (englisch für Bein) oder lower level RAID ist ein RAID-Array, welches mit anderen gleichartigen Legs über ein übergeordnetes RAID-Array (upper level RAID) zusammengefasst wird. Hierbei ist in unten stehender Tabelle die Anzahl der Festplatten in einem Leg und die Anzahl der Legs im übergeordneten Array (sofern das RAID tatsächlich kombiniert ist).







| RAID | n (Anzahl der Festplatten) | k (Nettokapazität) | S (Ausfallsicherheit) | Leseperformance | Schreibperformance |
|---|---|---|---|---|---|
| 0 | keine (0) | ||||
| 1 | 1 (Größe des kleinsten Mediums) | ||||
| 2 | |||||
| 3 | |||||
| 4 | |||||
| 5 | |||||
| 6 | |||||
| DP | |||||









Anmerkung: Die RAIDs 3 und 4 können prinzipiell auch mit zwei Festplatten benutzt werden, allerdings erhält man dann exakt die gleiche Ausfallsicherheit wie mit RAID 1 bei der gleichen Anzahl Festplatten. Dabei ist aber RAID 1 technisch einfacher und würde in dem Fall immer bevorzugt werden. Dasselbe trifft für übergeordnete Arrays oder Legs in Kombinations-RAIDs zu.
| RAID | n (Anzahl der Festplatten) | k (Nettokapazität) | S (Ausfallsicherheit) | Leseperformance | Schreibperformance |
|---|---|---|---|---|---|
| 00 | keine (0) | ||||
| 10 | Mindestens alle Geräte bis auf eines in einem Leg: , höchstens alle Geräte bis auf eines in jedem Leg: | ||||
| 0+1 | Mindestens ein Gerät in jedem Leg bis auf einen. , höchstens alle Geräte in jedem Leg bis auf einen: | ||||
| 1E | Mindestens ein Gerät: , höchstens jedes zweite Gerät (das erste und letzte sind auch Nachbarn): | ||||
| 1E0 | Mindestens ein Gerät: , höchstens jedes zweite Gerät (das erste und letzte sind auch Nachbarn) in jedem Leg: | ||||
| 1.5 | |||||
| Matrix- RAID | Abhängig von der Aufteilung der Partitionen der Festplatten und vom verwendeten RAID für die redundante Partition | Für die RAID-0-Partition: 0, für die redundante Partition: abhängig vom verwendeten RAID | |||
| 15 | Mindestens alle Geräte eines Legs und alle Geräte bis auf eines in einem anderen Leg: , höchstens alle Geräte eines Legs und alle Geräte bis auf eines in jedem anderen Leg: | ||||
| 51 | Mindestens ein Gerät in jedem Leg und zusätzlich ein Gerät in jedem Leg bis auf einen: , höchstens alle Geräte in jedem Leg bis auf einen und ein Gerät in dem anderen Leg: | ||||
| 55 | Mindestens das Minimum aus den Legs und den Geräten pro Leg: , höchstens alle Geräte eines Legs und ein Gerät in jedem anderen Leg: | ||||
| 45 | |||||
| 5E | |||||
| 5EE | |||||
| 30 (genannt 53) | Mindestens ein Gerät: , höchstens ein Gerät pro Leg: | ||||
| 5DP | |||||
| ADG | |||||
| S 3+1 | 1 | ||||
| S 7+1 | 1 | ||||
| TP | 3 |































Anmerkung: Die für angegebenen Fälle, welche Geräte genau ausfallen, dienen zur anschaulichen Darstellung. Die Werte geben lediglich an, dass in jedem beliebigen Fall genau diese Anzahl an Geräten ausfallen kann, ohne dass Daten verloren gehen. Die Angabe erhebt nicht den Anspruch darauf, dass in dem speziellen Fall nicht noch weitere Festplatten ohne Datenverlust ausfallen können.
Andere Begriffe
Cache
Der Cache-Speicher spielt bei RAID eine große Rolle. Grundsätzlich sind folgende Caches zu unterscheiden:
- Betriebssystem
- RAID-Controller
- Enterprise Disk-Array
Eine Schreibanforderung wird heute üblicherweise bereits quittiert, wenn die Daten im Cache angelangt sind und somit bevor die Daten tatsächlich permanent gespeichert wurden; weiterhin kann es vorkommen, dass der Cache nicht in der Reihenfolge bereinigend entleert wird, in der er gefüllt wurde; hierdurch kann ein Zeitraum entstehen, in dem bereits als gespeichert angenommene Daten durch einen Strom- oder Hardware-Ausfall verloren gehen können, was zu fehlerhaften Datei-Inhalten führen kann (etwa wenn das Dateisystem von einer Verlängerung der Datei ausgeht, obwohl aber die entsprechenden Daten noch gar nicht geschrieben wurden). In Enterprise-Speichersystemen überlebt der Cache daher Resets. Der Schreib-Cache bringt einen Geschwindigkeitsgewinn, solange der Cache (RAM) nicht voll ist, oder solange die Schreibanforderungen in suboptimaler Reihenfolge oder überlappend eingehen, da das Schreiben in den Cache schneller ist als das Schreiben auf Platte.
Der Lese-Cache ist heute in Datenbank-Anwendungen oft von großer Bedeutung, da hierdurch fast nur noch zum Schreiben auf das langsame Speichermedium zugegriffen werden muss.
Cache Controller mit Pufferbatterie

Die Pufferbatteriefunktion ist nicht zu verwechseln mit einer unterbrechungsfreien Stromversorgung. Diese schützt zwar auch vor Stromausfall, kann aber keine Systemabstürze oder das Einfrieren des Systems verhindern. Höherwertige RAID-Controller bieten daher die Möglichkeit, den eigenen Cachespeicher vor Ausfall zu schützen. Dies wird klassisch durch eine Pufferbatterie für den Controller oder bei neueren Systemen mit einem nichtflüchtigen NAND-Flash-Speicher und hochkapazitativen Kondensatoren erreicht. Diese Sicherung des Cachespeichers soll dafür sorgen, dass Daten, die bei einem Stromausfall oder einem Systemausfall im Cache liegen und noch nicht auf die Platten geschrieben wurden, nicht verloren gehen und damit das RAID konsistent bleibt. Die Pufferbatterie wird häufig als BBU (Battery Backup Unit) oder BBWC (Battery Backed Write Cache) bezeichnet. Vor allem für performanceoptimierte Datenbanksysteme ist das zusätzliche Absichern des Cache wichtig, um gefahrlos den Schreibcache zu aktivieren. Den Cachespeicher zu schützen ist für diese Systeme besonders wichtig, da bei einem eventuellen Beschädigen der Datenbank Daten verloren gehen können und dieses nicht sofort erkannt werden kann. Da aber in den Datenbanken kontinuierlich weitergearbeitet wird, können die Daten im Fall, dass ihr Verlust später bemerkt wird, auch nicht einfach durch Rücksicherung aus dem (hoffentlich vorhandenen) Backup wiederhergestellt werden, da die nachfolgenden Änderungen dann verloren wären. Um optimal zu funktionieren, setzt dies voraus, dass der in den Festplatten eingebaute und nicht per Batterie abgesicherte Cache der Festplatten deaktiviert ist. Würde der Plattencache zusätzlich zum Controllercache Daten vor dem Schreiben zwischenspeichern, würden diese beim Systemausfall natürlich verloren gehen.
Logical Volume Manager
Die Funktionen eines Logical Volume Managers (LVM) werden oft mit denen eines Software-RAID-Systems vermischt. Das liegt wohl hauptsächlich daran, dass die Verwaltung beider Subsysteme meist über eine gemeinsame grafische Benutzeroberfläche erfolgt. Dabei gibt es eine klare Abgrenzung. Echte RAID-Systeme bieten immer Redundanz (außer RAID 0) und verfügen folglich auch immer über eine RAID-Engine, welche die zusätzlichen, für die Redundanz benötigten Daten erzeugt. Die häufigsten Engine-Varianten sind bei RAID 1 die Datenduplizierung und bei RAID 5 und den meisten anderen Verfahren die XOR-Bildung. Es werden bei RAID also immer zusätzliche Datenströme in erheblichem Umfang erzeugt, der Datendurchsatz der RAID-Engine ist daher ein wichtiger Performancefaktor. Aufgabe eines LVM ist es, physische Datenträger (oder Partitionen) auf logische Datenträger abzubilden. Einer der häufigsten Anwendungsfälle ist das nachträgliche Vergrößern von Partitionen und Dateisystemen, die durch den LVM verwaltet werden. Ein LVM erzeugt hierbei aber keine zusätzlichen Datenströme, er hat auch keine Engine und bietet daher auch keine Redundanz, somit erzeugt er auch nur minimalen Rechenaufwand. Daher hat er auch praktisch keinen Performance-Einfluss (wenngleich auch einige LVM-Implementierungen integrierte RAID-0-Erweiterungen besitzen). Die Aufgabe des LVMs besteht im Wesentlichen also darin, Datenströme aus den Dateisystemen auf die jeweils zugehörigen Datenträgerbereiche zu verteilen, sie ähnelt am ehesten der Arbeitsweise einer MMU. In einigen Systemen (z. B. HP-UX oder Linux) sind Software-RAID und LVM optionale Erweiterungen und können völlig unabhängig voneinander installiert und genutzt werden. Manche Hersteller lizenzieren daher das Volume-Management und RAID (Mirroring und/oder RAID 5) auch separat.
Performance
Zur Bestimmung der Leistungsfähigkeit eines Festplattensubsystems gibt es zwei wesentliche Parameter, die Anzahl der bei zufälligem Zugriff möglichen I/O-Operationen pro Zeit, also IOPS (I/O pro Sekunde), und der Datendurchsatz bei sequentiellem Zugriff gemessen in MB/s. Die Leistung eines RAID-Systems ergibt sich aus der kombinierten Leistung der verwendeten Festplatten.
Die Anzahl der IOPS leitet sich direkt von der mittleren Zugriffszeit und der Drehzahl einer Festplatte ab. Bei SATA-Platten liegt die Zugriffszeit bei 8 bis 10 ms, eine halbe Umdrehung dauert je nach Drehzahl etwa 2 bis 4 ms. Vereinfacht ist das gleichbedeutend mit einer Dauer für einen nicht sequentiellen Zugriff von gerundet 10 ms. Hieraus ergibt sich, dass pro Sekunde maximal 100 I/Os möglich sind, also ein Wert von 100 IOPS. Leistungsstärkere SCSI- oder SAS-Platten haben Zugriffszeiten von unter 5 ms und arbeiten mit höheren Drehzahlen, daher liegen deren I/O-Werte bei ungefähr 200 IOPS. Bei Systemen, die viele gleichzeitige Benutzer (oder Tasks) abzuarbeiten haben, ist der IOPS-Wert eine besonders wichtige Größe.
Der sequentielle Datendurchsatz ist ein Wert, der im Wesentlichen von der Drehzahl und der Schreibdichte und der Anzahl der beschriebenen Oberflächen einer Festplatte abhängt. Erst beim wiederholten Zugriff hat auch der Platten-Cache einen leistungssteigernden Einfluss. Bei gleicher Konfiguration (Schreibdichte, Oberflächen) liefert eine aktuelle Platte mit 10.000 Umdrehungen pro Minute also etwa doppelt so schnell Daten wie eine einfache IDE-Platte, die mit 5.200 Umdrehungen pro Minute arbeitet. Beispielsweise liefert die Samsung Spinpoint VL40 mit 5.400 min−1 einen Datenstrom mit im Mittel etwa 33 MB/s, die WD Raptor WD740GD mit 10.000 min−1 hingegen schafft im Mittel 62 MB/s.
IOPS und MB/s bei RAID 0
Bei kleinen Chunk-Größen (2 kB) nutzt ein RAID-0-Verbund aus zwei Platten praktisch bei jedem Zugriff beide Platten, also verdoppelt sich der Datendurchsatz (pro I/O-Prozess), jedoch bleiben die IOPS unverändert. Bei großen Chunks hingegen (32 kB) wird für einen einzelnen Zugriff meist nur eine Platte genutzt, folglich kann ein weiterer I/O auf der zweiten Platte stattfinden, somit verdoppeln sich die IOPS-Werte, wobei der Datenstrom (pro I/O-Prozess) gleich bleibt und sich nur bei Systemen mit vielen gleichzeitigen Tasks kumuliert. Besonders Server profitieren also von größeren Chunks. Systeme mit zwei Platten (Typ: 100 IOPS) im RAID 0 können theoretisch also bis zu 200 IOPS bei etwa 60 MB/s erreichen.
IOPS und MB/s bei RAID 1
Moderne RAID-1-Implementierungen verhalten sich beim Schreiben wie die einzelnen verwendeten Platten. Die Chunkgröße ist für schreibende Zugriffe nicht von Belang. Beim Lesen hingegen arbeiten zwei Platten gleichzeitig, analog zu den RAID-0-Systemen. Daher haben auch bei RAID 1 die Chunkgrößen den gleichen Einfluss auf die Performance von Lesezugriffen wie bei RAID 0, auch hier profitieren besonders Server von größeren Chunks. Systeme mit zwei Platten (Typ: 100 IOPS) im RAID 1 können also theoretisch lesend bis zu 200 IOPS bei etwa 60 MB/s erreichen, schreibend bis zu 100 IOPS bei etwa 30 MB/s.
IOPS und MB/s bei RAID 10
Die Kombination aus RAID 0 und RAID 1 verdoppelt die Leistung im Vergleich zu purem RAID 1. Aktuelle Systeme mit acht Platten (Typ: 100 IOPS) im RAID 10 können also theoretisch lesend bis zu 800 IOPS bei etwa 240 MB/s erreichen, schreibend bis zu 400 IOPS bei etwa 120 MB/s.
IOPS und MB/s bei RAID 5
RAID 5 arbeitet mit mindestens drei Platten, wobei sich auch hier die Lese- und Schreibperformance stark unterscheidet. In minimaler RAID-5-Konfiguration mit drei Platten (Typ: 100 IOPS) ergeben sich lesend bis zu 300 IOPS. Da aber für einen Schreibzugriff bei kleinen Blöcken (< Stripe-Size) immer zwei lesende (Sektor-alt, Parity-alt) und zwei schreibende Zugriffe (Sektor-neu, Parity-neu)[18] nötig sind, werden beim Schreiben eines RAID-5-Verbunds mit drei Platten im Mittel nur 50 bis 75 IOPS erreicht (je nachdem, ob die dritte Platte für andere Zugriffe genutzt wird), beim Schreiben kompletter Stripes kann der Lesezugriff allerdings entfallen und dann bis zu 200 IOPS erreichen. Die Schreibleistung steht also in Abhängigkeit zur linear zusammenhängenden Datenmenge (> Stripe-Size), zur Lage der Daten (Stripe-Alignment) und steht im direkten Zusammenhang zur Stripe-Size. Daher sollten zum Erzielen einer guten Schreibleistung bei Systemen mit vielen Platten die Chunk-Size niedrig gewählt werden, im Besonderen niedriger als bei Systemen, die mit wenig Platten (drei) im Verbund arbeiten. Eine Chunk-Size von 128 kB im RAID 5 mit drei Platten führt beispielsweise zu einer Stripe-Size von 256 kB, für ein RAID-5-System mit fünf Platten ergibt sich eine Stripe-Size von 256 kB jedoch aus einer Chunk-Size von 64 kB. Die Schreibleistung kann also im ungünstigen Fall durchaus geringer sein als die eines RAID-1-Verbunds oder einer einzelnen Platte, besonders wenn häufig kleinere nicht zusammenhängende Daten geschrieben werden sollen. Aktuelle Systeme mit beispielsweise acht Platten (Typ: 100 IOPS) im RAID 5 können theoretisch lesend bis zu 800 IOPS erreichen, schreibend je nach Zugriffsmuster von 200 bis zu 700 IOPS.
Einfluss der Anzahl der Festplatten
Bei RAID 0 hat die Anzahl der beteiligten Festplatten einen linearen Einfluss auf die Performance. Die I/O-Geschwindigkeit lesend ist bei acht Platten auch achtmal so hoch wie die einer einzelnen Platte, ebenso wie die Schreibgeschwindigkeit. Bei RAID 10 hingegen steigt nur die Lesegeschwindigkeit genau so schnell wie bei RAID 0, die Schreibgeschwindigkeit hingegen nur halb so schnell. Weitaus komplizierter verhält sich der Zugewinn bei RAID 5 (siehe vorigen Absatz). Der Zugewinn beim Schreibzugriff liegt im ungünstigen Fall bei nur einem Viertel. Im Mischbetrieb (50 % read, 50 % write) ergeben sich bei solchen Zugriffsmustern für ein RAID 10 aus acht Platten etwa 533 IOPS und für RAID 5 ungefähr 320 IOPS.[4] RAID 6 verhält sich ganz ähnlich wie RAID 5 jedoch sind beim Schreiben die Zusammenhänge noch etwas komplexer, lesend ist der Zugewinn gleich hoch, schreibend jedoch noch niedriger. Vorteilhafterweise ist der netto zur Verfügung stehende Platz bei RAID 5 im Vergleich zu RAID 10 (bei 8 Platten im Verhältnis 7:4) deutlich höher. Aus diesen Gesichtspunkten sind RAID 5 und RAID 6 besonders dort hervorragend geeignet, wo Daten in großen Blöcken verarbeitet werden oder Lesezugriffe dominieren, etwa bei der Bild- und Videobearbeitung und generell auch bei Archiven. Hat man häufig nicht sequentielle Schreibzugriffe auf kleine Datenmengen (< Stripe-Size), zum Beispiel bei einem gut ausgelasteten Messaging- (SMS) oder Mailserver oder einer interaktiven Datenbankanwendung, ist RAID 10 die bessere Wahl.
Rechenbeispiel Mailserver
Ein Mail-Server führt heute neben dem Mailversand häufig noch eine Virenprüfung und eine Spam-Analyse durch. Daher gehen wir davon aus, dass pro Mail inklusive Anhang im Mittel rund 25 Schreibzugriffe und etwa 50 Lesezugriffe (IOPS) notwendig sind. Weiter gehen wir davon aus, dass keine weiteren Ressourcen einen begrenzenden Einfluss haben. Das RAID-1-System mit zwei einfachen Platten (siehe weiter oben) kann folglich etwa 240 Mails pro Minute verarbeiten, das RAID-5-System mit acht Platten hingegen kommt auf maximal 480 Mails pro Minute. Als RAID-10-Konfiguration mit acht Platten sind bereits knapp 1.000 Mails pro Minute möglich. Wechselt man bei dem RAID-10-System auf Hochleistungsplatten, so kann der Durchsatz auf das Zwei- bis Dreifache gesteigert werden, also maximal etwa 2.500 Mails pro Minute.
Performance, RAID 10 zu RAID 5
Vielerorts wird die Frage diskutiert, ob RAID 10 (auch RAID 01) oder RAID 5 für verschiedene Anwendungen das bessere System sei. Dabei sind generell zwei Aspekte zu beachten, die Read-Performance und die Write-Performance eines Systems. Eine genauere Betrachtung lohnt eigentlich nur bei Verwendung von hochwertigen Hardware-Cache-Controllern. Bei Verwendung von Software-RAID- oder „Fake-RAID“-Systemen ist die Performance stark von anderen Faktoren wie Prozessorleistung und verfügbaren Arbeitsspeicher abhängig und daher schwer vergleichbar.
Read-Performance
Sie ist bei beiden Systemen praktisch identisch und wird weitestgehend durch die Anzahl der Festplatten aber auch durch Cache-Größen bestimmt, mehr ist hier immer besser.
Write-Performance
Hier verhalten sich beide Systeme unterschiedlich. Da bei RAID 10 alles doppelt geschrieben wird, reduziert sich die nutzbare Write-Performance im Vergleich zur maximal möglichen Schreibleistung, die sich ebenfalls aus der Anzahl der Platten ergibt, immer auf 50 % (Effizienz ist 50 %). Blockgrößen oder andere Parameter haben bei RAID 10 keinen Einfluss auf die Leistung. Bei RAID 5 ist der Sachverhalt komplizierter und hängt von der zu schreibenden Datenmenge ab. Ausgehend von Festplatten mit weniger als 2 TB Plattenplatz ist die atomare Blockgröße (auch Sektorgröße genannt) der Platten häufig 512 Byte (siehe Festplatte: Speichern und Lesen von Daten). Geht man weiter von einem RAID-5-Verbund mit 5 Platten (4/5 Daten und 1/5 Parität) aus, so ergibt sich folgendes Szenario: Will eine Anwendung 2.048 Byte schreiben, wird in diesem günstigen Fall auf alle 5 Platten genau je ein Block zu 512 Byte geschrieben, wobei einer dieser Blöcke keine Nutzdaten enthält. Daraus ergibt sich eine theoretische Effizienz von 80 % (bei RAID 5 mit 3 Platten wären es 66 %). Möchte eine Anwendung aber nur einen Block von 512 Byte schreiben, so ergibt sich ein ungünstigerer Fall (siehe RAID 5 write Penalty), es müssen zuerst der abzuändernde Block und der Paritätsblock eingelesen werden, danach wird der neue Paritätsblock berechnet und erst dann können beide 512-Byte-Blöcke geschrieben werden.[4] Das bedeutet einen Aufwand von 2 Lesezugriffen und 2 Schreibzugriffen, um einen Block zu speichern; geht man vereinfacht davon aus, dass Lesen und Schreiben gleich lange dauern, so beträgt die Effizienz in diesem ungünstigsten Fall nur noch 25 %. Zusätzlich zur Blockgröße muss bei RAID-5-Systemen noch die Paritätsberechnung beachtet werden. Bei sehr schreibintensiven Zugriffen (z. B. Datenbank-Log-Dateien) führt die zeitintensive Parity-Berechnung bei RAID-5-Systemen zu einer weiteren, möglichen Geschwindigkeitseinbußen gegenüber RAID 10.
Fazit
In der Praxis hat das schlechtere Worst-case-Verhalten und die zeitintensive Parityberechnung von RAID 5 merklich negative Einflüsse nur dann, wenn viele, schnelle und kleine Schreibzugriffe erfolgen. Bei Zugriffen als Fileserver überwiegen dann die Vorteile von RAID 5 der höheren Lesegeschwindigkeit und günstigeren Kosten pro Kapazität. Bei performanceorientierten Datenbanksystemen wird jedoch RAID 1 beziehungsweise 10 empfohlen, da hier keine Paritätsberechnung stattfindet und die Blockgröße nicht relevant ist. Bei neueren Festplatten, deren atomare Blockgröße oft 4.096 Byte beträgt, gewinnt die schlechtere Worst-Case-Effizienz weiter an Bedeutung. Für alle performanceorientierten Systeme mit Schutz vor Datenverlust bei Plattenausfall gilt der deutlich erhöhte Kostenfaktor. Für den sicheren Betrieb wird ein hochwertiger Hardware-RAID-Controller mit entsprechender Hardware-Cacheabsicherung (BBU) benötigt. Dafür erhält man ein deutlich sichereres und schnelleres System. Viele Hersteller von Datenbanksystemen empfehlen für ihre Systeme RAID 1 oder 10, zumindest für die schreibintensiven Log-Dateien.[19]
Drive Extender
Mit dem Drive Extender des Microsoft Windows Home Servers findet sich eine Art virtuelles RAID, das aber auf JBOD basiert. Neue Dateien landen in der Regel zunächst auf der Systemplatte und werden dann erst später auf eine der anderen Festplatten verschoben, hinterlassen aber einen Verweis (Tombstone), der 4 kB Festplattenspeicher belegt. Der Benutzer kann dadurch arbeiten, als ob der Server über eine einzige große Festplatte verfügen würde.
Stripe (Chunk) Size
Stripes (Chunks) sind Untereinheiten eines Stripe-Set, die Stripe Size bezeichnet die Größe eines Datenblocks, der auf einer Platte gespeichert wird. Alle Blöcke oder Sektoren eines Stripes liegen auf der gleichen Platte. Ein Stripe-Set setzt sich aus je einem Stripe pro Datenträger eines RAID-Verbunds zusammen. So besitzt beispielsweise ein aus vier Festplatten bestehendes RAID-0-Array mit einer Stripe Size von 256 KiB einen Stripe Set von 1 MiB. Unabhängig davon wird beim Formatieren eines Arrays die File System Block Size für das jeweilige Dateisystem gesetzt. Die Performanceauswirkungen der eingestellten Stripe (Chunk) Size[18] im Verhältnis zu der gewählten File System Block Size sind komplex.
Hot Swapping
Mit Hot Swapping bietet sich die Möglichkeit, Speichermedien im laufenden Betrieb auszutauschen. Dazu muss der Bus-Controller Hot-Plugging unterstützen (i. d. R. nur SCSI, SAS oder SATA). Damit es nicht zu einem Ausfall des Systems führt, ist ein Austausch nur in Arrays mit redundanter Datenhaltung möglich – bei einem RAID-0-System würde das Ersetzen (bzw. Entfernen) eines Mediums unweigerlich zum Ausfall führen.
Hot-Spare-Laufwerk
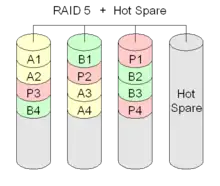
Das Hot-Spare-Laufwerk ist ein unbenutztes Reservelaufwerk. Fällt ein Laufwerk innerhalb des RAID-Verbundes aus, wird es durch das Reservelaufwerk ersetzt. Dadurch ist die Redundanz schnellstmöglich wiederhergestellt. Während der Rebuild-Phase hat man allerdings keine Redundanz. Zur Vermeidung dieses Problems kann ein RAID 6 oder RAID DP statt RAID 5 verwendet werden, da hier zwei Paritätsplatten vorhanden sind. Außerdem gibt es Speichersysteme, die intern ständig alle Plattenbereiche prüfen. Sollte ein Datenblock „dirty“ sein, so wird die Platte bis zu diesem Bereich kopiert, der Dirty-Block aus der Prüfsumme beziehungsweise der Spiegelplatte rekonstruiert und dann weiter kopiert. Dadurch kann die Wiederherstellungszeit reduziert werden.
In größeren RAID-Systemen, in denen die Möglichkeit besteht, an einem RAID-Controller mehrere unterschiedliche RAID-Arrays einzurichten, gibt es darüber hinaus auch die Möglichkeit, dass ein Hot-Spare-Laufwerk entweder einem einzelnen RAID-Array oder einer Geräteeinheit (Shelf, Enclosure) zugeordnet ist oder für die Verwendung im gesamten RAID-System zur Verfügung steht. In diesem Fall spricht man dann von einem Local-Spare-Laufwerk oder auch Dedicated Hot-Spare-Laufwerk (bei Zuordnung zu einem bestimmten Array) oder einem Global-Spare-Laufwerk (wenn das Laufwerk für alle Arrays verwendet werden kann).
Drive Clone
Viele RAID-Controller bieten die Möglichkeit, auftretende Laufwerksfehler durch Medien-Tests oder den SMART-Status frühzeitig zu erkennen. Wenn ein Laufwerk zu viele dieser meist korrigierbaren Fehler liefert, besteht die Möglichkeit, das betroffene Laufwerk schon vor dem endgültigen Ausfall zu ersetzen. Dazu kopiert der Controller alle vorhandenen Daten der einen Festplatte auf ein bisher unbenutztes Spare-Laufwerk. Beim Ausfall der Originalfestplatte verkürzt sich dadurch die Wiederherstellungszeit und damit auch die kritische Zeit für einen weiteren Ausfall auf ein Minimum.
RAIDIOS (RAID I/O Steering)
Zertifizierter Standard von Intel zur Verwendung der vorhandenen Anschlüsse. Es wird nur der fehlende I/O-Controller (mit 0 Kanälen) nachgerüstet. Kostengünstige und ökonomische Variante.
Tape-RAID
Auch Hersteller von Backup-Programmen haben das Problem, dass durch defekte Medien (Bänder wie DAT, DLT, QIC usw.) Daten einer Datensicherung oder Archivierung teilweise oder ganz verloren gehen können. Daher nutzen umfangreiche Backup-Lösungen[20] die gleichen Mechanismen zur Herstellung redundanter Datenträgersätze, wie sie auch bei Festplatten zum Einsatz kommen. Häufig werden die Daten über mehrere Bandlaufwerke verteilt auf mehreren Bändern im RAID-3- oder RAID-5-Modus gespeichert. Da sich Backups auch über viele Bänder hinweg durchführen lassen, muss dies auch bei Tape-RAID möglich sein. Die eingesetzte Software muss folglich in der Lage sein, den Bandsatz dynamisch zu erweitern. Das bedeutet, die Software muss aus zusätzlichen Bändern automatisch weitere zusätzliche RAID-Verbünde herstellen und diese automatisch an bestehende Bandsätze anhängen können.
- RAIL: Eine ähnliche Implementierung ist ein Redundant Array of Independent Libraries (redundante Reihe unabhängiger Bandbibliotheken).[20] Dabei werden die RAID-Level nicht über mehrere Bandlaufwerke verteilt gebildet, sondern über mehrere unabhängige Bandbibliotheken (Tape-Libraries) hinweg, wobei die Librarys auch auf mehrere Standorte verteilt sein können, um die Daten, beispielsweise auch im Katastrophenfall, sicher und redundant zu lagern.
Siehe auch
Weblinks
- RAID-Informationen von tecchannel.de
- Original-Dokument von Patterson, Gibson, Katz (englisch, PDF, 1,14 MB)
Einzelnachweise
- Im Kontext dieses Artikels sind, sofern nicht anders angegeben, die Begriffe „Festplatte“, „solid state drive“, „Speichermedium“ oder „Massenspeicher“ synonym zu betrachten.
- The Story so Far in ComputerWorld
- D. A. Patterson, G. Gibson, R. H. Katz: A case for redundant arrays of inexpensive disks (RAID). 1988, (PDF)
- Tom Treadway, Adaptec Storage Advisors: Yet another RAID-10 vs RAID-5 question. Archiviert vom Original am 31. Januar 2010; abgerufen am 17. April 2007.
- Serial ATA (SATA) chipsets – Linux support status, Übersicht: RAID und Host-RAID mit SATA, 31. Dezember 2007.
- Fake RAID Howto, Ludwin Janvier, How to install Ubuntu onto a fakeRAID system, 18. Januar 2010.
- Die Besonderheiten von RAID-Z (Servermeile Technet – Die Wissens-Datenbank)
- Cache-Einstellungen von RAID-Controllern und Festplatten (Thomas Krenn Wiki)
- dmraid-Tool 2004–2011 Heinz Mauelshagen, Red Hat GmbH
- Robin Harris: Why RAID 5 stops working in 2009. Storage Bits, ZD Net Blog, 18. Juli 2007.
- Failure Trends in a Large Disk Drive Population (PDF; 247 kB). Eduardo Pinheiro, Wolf-Dietrich Weber, Luiz André Barroso, 5th USENIX Conference on File and Storage Technologies (FAST’07), im Februar 2007.
- Proceedings of the Third USENIX Conference on File and Storage Technologies (PDF; 216 kB) Usenix Publikation, 31. März bis 2. April 2004.
- SNIA – Dictionary R. Storage Networking Industry Association (SNIA), abgerufen am 2. Februar 2011: „RAID Level 6 [Storage System] Any form of RAID that can continue to execute read and write requests to all of a RAID array’s virtual disks in the presence of any two concurrent disk failures.“
- aput.net
- RAID 50-51-15 Datenrettung und Datenwiederherstellung. In: AABBOO GmbH. (aabboo.de [abgerufen am 9. Mai 2017]).
- Adam Leventhal: Triple-Parity RAID-Z (Memento vom 4. August 2009 im Internet Archive). In: Adam Leventhal’s Weblog. Abgerufen am 2. November 2009.
- ZFS: WHEN TO (AND NOT TO) USE RAID-Z Sun Blogs, 31. Mai 2006 (via archive.org)
- The Software-RAID HOWTO, 5.10 Chunk sizes, 3. Juni 2004.
- technet.microsoft.com Storage Top 10 Best Practices
- Tape-RAID Tecchannel, im Artikel Kostenguenstig optisch speichern, 12. Oktober 2001.