Single Point of Failure
Unter einem Single Point of Failure (kurz SPOF bzw. deutsch einzelner Ausfallpunkt) versteht man einen Bestandteil eines technischen Systems, dessen Ausfall den Ausfall des gesamten Systems nach sich zieht.
Bei hochverfügbaren Systemen muss darauf geachtet werden, dass alle Komponenten eines Systems redundant ausgelegt sind. Auch sollte die Diversität eine Rolle spielen. Hierbei kommen Systeme unterschiedlichen Aufbaues (beispielsweise verschiedener Hersteller) für die gleiche Aufgabe zum Einsatz. Damit wird ein gleichzeitiger Ausfall mehrerer Systeme aus einem einzelnen Grund unwahrscheinlicher.
Prinzip
Je nach Anforderungen dürfen redundante Geräte nicht am selben Ort betrieben werden, da ansonsten immer noch ein SPOF besteht:
- Beim Unfall von Fukushima waren die Diesel-betriebenen Notstromaggregate zwar mehrfach vorhanden, was in vielen Schadenszenarien eine genügende Absicherung darstellt. Jedoch zerstörte der Tsunami einen großen Teil der Notstromaggregate. Seither wurden mobile Notstromgeräte und solche, die sich auf einer vor Überschwemmungen sicheren Anhöhe befinden, umgesetzt.[1]
- Dasselbe Problem stellt sich etwa bei der Datensicherung: Wenn Daten auf eine externe Festplatte gesichert werden und diese im eigenen Büro aufbewahrt wird, ist dies in den Szenarien “Laptop durch ausgeschütteten Kaffee zerstört” und “Dieb stiehlt den Laptop” sicherlich ausreichend, aber nicht mehr, wenn ein Brand das gesamte Büro zerstört. In einem solchen Fall müsste die Festplatte zum Beispiel in einem Bankschließfach gelagert werden, um die Redundanz zu gewährleisten.
Im IT-Bereich
Als einfache Schritte zur Vermeidung von mehreren SPOF im IT-Betrieb kann man mehrere unterbrechungsfreie Stromversorgungen (USV) verwenden, Teile des Servers redundant auslegen (Netzteile und Netzwerkkarten) und die Menge der nutzenden Endgeräte ausreichend erhöhen.
Bei der Anbindung an mehrere Trafos des Energieversorgers, der Einbindung einer Kreuzverkabelung (mehrere Strompfade), eines oder mehrerer Generatoren als Netzersatzanlage, IT-Systemen mit mehreren Netzteilen oder der Verwendung mehrerer STS (Vorschaltgeräten), der redundanten Klimatechnik und multiplen Zugriffen auf die Endgeräte über das betriebseigene Netz (CorporateNetwork) erhält man eine weitgehend gegen Ausfälle abgesicherte Infrastruktur. Die nächste Steigerung der Verfügbarkeit wird durch die Verwendung intern hochredundanter (fehlertoleranter) Server oder Cluster-Systeme erreicht. Darüber hinaus können Ausweichrechenzentren für den Katastrophenfall eingesetzt werden.
- Beispiel
In einer Firma soll das Computernetzwerk gegenüber Strom- und Server-Ausfälle gesichert werden. "SPOF" bezeichnet jeweils ein einzelnes Element, dessen Ausfall das gesamte System beeinträchtigt.
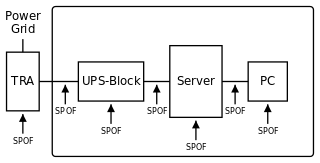 Mögliche Störungspunkte in einem unabgesicherten Betrieb. Nebst anderen Schwachstellen: Bei einem Stromausfall springt zwar die unterbrechungsfreie Stromversorgung (UPS) ein; jedoch ist aber die Verbindung zwischen UPS und Computer nicht vor Ausfällen geschützt. Ebenso ist kein zweiter Computer (PC) vorhanden, sollte dieser Störungen aufweisen.
Mögliche Störungspunkte in einem unabgesicherten Betrieb. Nebst anderen Schwachstellen: Bei einem Stromausfall springt zwar die unterbrechungsfreie Stromversorgung (UPS) ein; jedoch ist aber die Verbindung zwischen UPS und Computer nicht vor Ausfällen geschützt. Ebenso ist kein zweiter Computer (PC) vorhanden, sollte dieser Störungen aufweisen.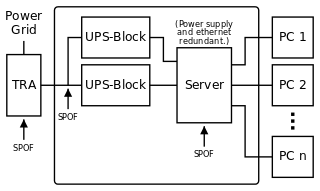 Erste Reduktion der Störungspunkte für einen IT-Betrieb. Einige SPOFs wurden eliminiert. Jedoch können Daten nur über einen Server ausgetauscht werden. Ebenso kann bei Stromausfall nur so lange gearbeitet werden, wie die beiden UPS-Blöcke Strom liefern
Erste Reduktion der Störungspunkte für einen IT-Betrieb. Einige SPOFs wurden eliminiert. Jedoch können Daten nur über einen Server ausgetauscht werden. Ebenso kann bei Stromausfall nur so lange gearbeitet werden, wie die beiden UPS-Blöcke Strom liefern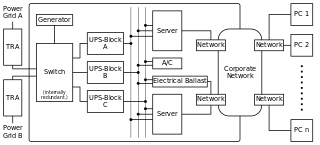 Redundante und kreuzverkabelte Stromversorgung im Rechenzentrum. Der Betrieb ist gegen Ausfälle des einen Stromnetzes, des Servers und der elektrischen/elektronischen Verbindungen sehr gut abgesichert.
Redundante und kreuzverkabelte Stromversorgung im Rechenzentrum. Der Betrieb ist gegen Ausfälle des einen Stromnetzes, des Servers und der elektrischen/elektronischen Verbindungen sehr gut abgesichert.
Aviatik
In der Luftfahrt ist die Vermeidung von single points of failure von herausragender Bedeutung. Wenn ein Ausfall die Sicherheit nicht beeinträchtigt, oder bestätigen Sicherheitsanalysen, dass der Ausfall ausreichend selten eintritt, ist ein single point of failure jedoch zulässig .
Die FAA teilt die Bordsysteme – aufgrund ihrer möglichen Fehlfunktionen – in folgende Kategorien ein:
- Minor Failure (darf häufiger als 1 pro 100'000 Betriebsstunden auftreten, hat keinen Einfluss auf die Sicherheit)
- Major Failure (muss seltener als einmal pro 100'000 h auftreten, alle Insassen überleben den Vorfall)
- Hazardous Failure (muss seltener als einmal pro 10 Millionen Betriebsstunden auftreten, erfordert hohes fliegerisches Können, einige Insassen sterben beim Vorfall)
- Catastrophic Failure (muss seltener als einmal pro Milliarde Betriebsstunden auftreten, Flugzeug ist auch beim besten Können der Piloten unrettbar verloren, die meisten Passagiere sterben beim Vorfall)
Bedeutet ein Systemausfall ein major failure, ist eine einzelne, nicht ausfallsichere Auslegung erlaubt. Hingegen soll der Ausfall eines einzelnen Systems nicht in einem catastrophic failure münden.[2]
- Messgeräte und Avionik
Ein modernes Flugzeug verarbeitet pausenlos Dutzende von verschiedenen Messwerten: Flughöhe, Geschwindigkeit, Positionswerte des Trägheitsnavigationssystems, Triebwerksdaten, der Empfang der Signale des Instrumentenlandesystems und viele mehr.
Je nach Anforderung müssen diese Daten nicht nur ausfallsicher erhoben werden, sondern auch ausfallsicher verarbeitet werden. Bei modernen Flugzeugen sind somit drei voneinander unabhängige Flugkontrollrechner im Einsatz, welche die Rohdaten von drei voneinander unabhängigen Quellen (Pitotrohre, statische Sonden …) beziehen.
Unter der Annahme, dass die zweifache Fehlfunktion eines Systems extrem unwahrscheinlich ist, kann ein dreifach ausgelegtes System den richtigen Messwert erkennen und den falschen verwerfen. Sind nur noch zwei Systeme aktiv, kann das System die Piloten wenigstens noch auf einen fragwürdigen Messwert hinweisen – es kann aber nicht mehr entscheiden, welcher der beiden Werte nun korrekt ist.
- Steuerung
Die Steuerungssysteme eines Verkehrsflugzeuges wurden aus Gründen der Sicherheit doppelt oder gar dreifach ausgelegt und waren gleichzeitig spätestens für die moderneren Grossraumflugzeuge Boeing 747, Lockheed Tristar oder Douglas DC-10 in rein mechanischer Form über Hebel, Gestänge oder Seilzüge nicht mehr praktikabel.[3] An ihre Stelle traten hydraulische und später elektrische/elektronische Systeme, um die Steuerbefehle an die Klappen-Antriebe zu übertragen (sogenanntes Fly-by-Wire). Mittels elektrischer Signalübertragung war es nun viel einfacher, die notwendige Redundanz zu gewährleisten.
Im Falle hydraulischer Signalübertragung war es gegen alle Unwahrscheinlichkeit in Einzelfällen möglich, dass alle drei Systeme aufgrund örtlicher Nähe der redundanten Systeme von demselben Schadensvorfall beschädigt wurden und ausfielen. So zerstörten bei United-Airlines-Flug 232 zersplitternde Triebwerksteile einer DC-10 alle drei Hydrauliksysteme. Bei Japan-Air-Lines-Flug 123 wurden nach einer Druckentladung aus der Druckkabine alle vier Systeme einer Boeing 747 zerstört.
Eine weitergehende Verbesserung stellt das EBHA (electric back-up hydraulic actuator) an Bord der Airbus 380 und Gulfstream 650[4] dar. Normalerweise werden hydraulisch bewegte Aktuatoren elektrisch/elektronisch angesteuert; der Ausfall der hydraulischen Leitungen würde also einen solchen Aktuator trotzdem stilllegen. Ein EBHA hingegen verfügt über ein eigenes, autarkes hydraulisches System. EBHAs erlauben es, eines von drei hydraulischen Systemen und somit Gewicht einzusparen.
Einzelnachweise
- Tadashi Narabayashi: Countermeasures derived from the lessons of the Fukushima Daiichi nuclear power plant accident. In: Proceedings of the 2013 21st International Conference on Nuclear Engineering. Abgerufen am 17. Juli 2019.
- AC 25.1309–1A „Systems Design and Analysis“, FAA, siehe AC 25.1309-1
- Eyewitness Report: United Flight 232 (Memento vom 18. April 2001 im Internet Archive)
- G650 flies with electric backup hydraulic actuators. In: Australian Aviation. Abgerufen am 25. April 2021 (australisches Englisch).