Perzeptron
Das Perzeptron (nach engl. perception, „Wahrnehmung“) ist ein vereinfachtes künstliches neuronales Netz, das zuerst von Frank Rosenblatt 1957 vorgestellt wurde. Es besteht in der Grundversion (einfaches Perzeptron) aus einem einzelnen künstlichen Neuron mit anpassbaren Gewichtungen und einem Schwellenwert. Unter diesem Begriff werden heute verschiedene Kombinationen des ursprünglichen Modells verstanden, dabei wird zwischen einlagigen und mehrlagigen Perzeptren (engl. multi-layer perceptron, MLP) unterschieden. Perzeptron-Netze wandeln einen Eingabevektor in einen Ausgabevektor um und stellen damit einen einfachen Assoziativspeicher dar.

Geschichte
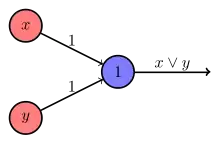
1943 führten die Mathematiker Warren McCulloch und Walter Pitts das „Neuron“ als logisches Schwellwert-Element mit mehreren Eingängen und einem einzigen Ausgang in die Informatik ein.[1] Es konnte als Boolesche Variable die Zustände wahr und falsch annehmen und „feuerte“ (= wahr), wenn die Summe der Eingangssignale einen Schwellenwert überschritt (siehe McCulloch-Pitts-Zelle). Dies entsprach der neurobiologischen Analogie eines Aktionspotentials, das eine Nervenzelle bei einer kritischen Änderung ihres Membranpotentials aussendet. McCulloch und Pitts zeigten, dass durch geeignete Kombination mehrerer solcher Neuronen jede einfache aussagenlogische Funktion (UND, ODER, NICHT) beschreibbar ist.
1949 stellte der Psychologe Donald O. Hebb die Hypothese auf, Lernen beruhe darauf, dass sich die aktivierende oder hemmende Wirkung einer Synapse als Produkt der prä- und postsynaptischen Aktivität berechnen lasse.[2] Es gibt Anhaltspunkte, dass die Langzeit-Potenzierung und das sogenannte spike-timing dependent plasticity (STDP) die biologischen Korrelate des Hebbschen Postulates sind. Überzeugende Evidenz für diese These steht aber noch aus.
1957 schließlich publizierte Frank Rosenblatt das Perzeptron-Modell, das bis heute die Grundlage künstlicher neuronaler Netze darstellt.[3]
Einlagiges Perzeptron
Beim einlagigen Perzeptron gibt es nur eine einzige Schicht aus künstlichen Neuronen, welche zugleich den Ausgabevektor repräsentiert. Jedes Neuron wird dabei durch eine Neuronenfunktion repräsentiert und erhält den gesamten Eingabevektor als Parameter. Die Verarbeitung erfolgt ganz ähnlich zur sogenannten Hebbschen Lernregel für natürliche Neuronen. Allerdings wird der Aktivierungsfaktor dieser Regel durch eine Differenz zwischen Soll- und Istwert ersetzt. Da die Hebbsche Lernregel sich auf die Gewichtung der einzelnen Eingangswerte bezieht, erfolgt also das Lernen eines Perzeptrons durch die Anpassung der Gewichtung eines jeden Neurons. Sind die Gewichtungen einmal gelernt, so ist ein Perzeptron auch in der Lage, Eingabevektoren zu klassifizieren, die vom ursprünglich gelernten Vektor leicht abweichen. Gerade darin besteht die gewünschte Klassifizierungsfähigkeit des Perzeptrons, der es seinen Namen verdankt.
Berechnung der Ausgabewerte
Mit einem Bias , den Eingaben und den Gewichten berechnen sich die Ausgabewerte zu




- .[4]

Anmerkungen
- Der Bias ist als Schwellenwert (engl. threshold) mit einem negativen Vorzeichen festgelegt.
- Verwendet man stattdessen den Schwellenwert , so ergibt sich die erste Bedingung zu und es ändert sich auch beim zugehörigen Funktionsterm das entsprechende Vorzeichen.


Perzeptron-Lernregel
Es gibt verschiedene Versionen der Lernregel, um auf die unterschiedlichen Definitionen des Perzeptrons einzugehen. Für ein Perzeptron mit binären Ein- und Ausgabewerten wird hier die Lernregel angegeben. Diese Regel konvergiert nur, wenn der Trainings-Datensatz linear separierbar ist, siehe dazu unten unter "Varianten".
Folgende Überlegungen liegen der Lernregel des Perzeptrons zu Grunde:
- Wenn die Ausgabe eines Neurons 1 (bzw. 0) ist und den Wert 1 (bzw. 0) annehmen soll, dann werden die Gewichtungen nicht geändert.
- Ist die Ausgabe 0, soll aber den Wert 1 annehmen, dann werden die Gewichte inkrementiert.
- Ist die Ausgabe 1, soll aber den Wert 0 annehmen, dann werden die Gewichte dekrementiert.
Mathematisch wird der Sachverhalt folgendermaßen ausgedrückt:
- ,
- .


Dabei ist
- die Änderung des Gewichts für die Verbindung zwischen der Eingabezelle und Ausgabezelle ,
- die gewünschte Ausgabe des Neurons ,
- die tatsächliche Ausgabe,
- die Eingabe des Neurons und
- die Lernrate.





Eine Gewichtsaktualisierung im Schritt verläuft danach wie folgt:

- bei korrekter Ausgabe,
- bei Ausgabe 0 und gewünschter Ausgabe 1 und
- bei Ausgabe 1 und gewünschter Ausgabe 0.



Rosenblatt konnte im Konvergenztheorem nachweisen, dass mit dem angegebenen Lernverfahren alle Lösungen eingelernt werden können, die ein Perzeptron repräsentieren kann.
XOR-Problem
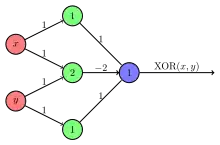
Frank Rosenblatt zeigte, dass ein einfaches Perzeptron mit zwei Eingabewerten und einem einzigen Ausgabeneuron zur Darstellung der einfachen logischen Operatoren AND, OR und NOT genutzt werden kann. Marvin Minsky und Seymour Papert wiesen jedoch 1969 nach, dass ein einlagiges Perzeptron den XOR-Operator nicht auflösen kann (Problem der linearen Separierbarkeit). Dies führte zu einem Stillstand in der Forschung der künstlichen neuronalen Netze.
Die in diesem Zusammenhang zum Teil äußerst polemisch geführte Diskussion war letztlich ein Richtungsstreit zwischen den Vertretern der symbolischen Künstlichen Intelligenz und der „Konnektionisten“ um Forschungsgelder. Frank Rosenblatt hatte zwar gezeigt, dass logische Operatoren wie XOR (identisch zur Zusammensetzung OR but NOT AND) durch Verwendung eines mehrlagigen Perzeptrons beschrieben werden können, er starb jedoch zu früh, um sich gegen die Angriffe seiner KI-Kollegen zu wehren.
Varianten der Perzeptron-Lernregel
Die oben angegebene Standard-Lernregel konvergiert nur, wenn der Trainings-Datensatz linear separierbar ist. Ist dies nicht der Fall, so wird die Standard-Lernregel keine approximative Lösung erzeugen (zum Beispiel eine Lösung mit möglichst wenigen falsch zugeordneten Daten). Stattdessen wird der Lernvorgang vollständig versagen.
Da lineare Separierbarkeit des Trainings-Datensatzes oft nicht vor Trainingsbeginn bekannt ist, sollten daher Varianten des Trainingsalgorithmus benutzt werden, die robust sind in dem Sinne, dass sie im nicht linear separablen Fall zu einer approximativen Lösung konvergieren.
Ein solches robustes Verfahren ist der Maxover-Algorithmus.[5] Im linear separablen Fall löst er das Trainingsproblem vollständig, auch unter weiteren Optimierungsbedingungen wie maximaler Stabilität (maximaler Abstand zwischen den Daten mit Ausgabe 0 und 1). Im nicht linear separablen Fall erzeugt er eine Lösung mit wenigen falsch zugeordneten Daten. In beiden Fällen geschieht eine graduelle Annäherung an die Lösung im Laufe des Lernvorganges. Der Algorithmus konvergiert zu einer global optimalen Lösung im linear separablen Fall, bzw. zu einer lokal optimalen Lösung im nicht linear separablen Fall.
Der Pocket-Algorithmus[6] lernt mit einer Standard-Perzeptron-Lernregel. Er behält diejenige Lösung, die bisher die wenigsten falsch zugeordneten Daten produzierte, in seiner „Tasche“ (pocket), und gibt diese als approximative Lösung aus. Im linear separablen Fall lernt dieser Algorithmus vollständig. Im nicht linear separablen Fall wird ausgenutzt, dass die Standard-Perzeptron-Lernregel zufällige Lösungen produziert, unter denen stochastisch solche approximativen Lösungen auftauchen. Der Pocket-Algorithmus hat somit Nachteile: Zum einen erfolgt keine graduelle Annäherung an die Lösung, sondern stochastische Sprünge werden ausgenutzt. Da diese zu unvorhersehbaren Zeitpunkten im Lernvorgang auftreten, gibt es keine Sicherheit darüber, wie weit sich der Algorithmus nach einer bestimmten Anzahl von Lernschritten einer optimalen Lösung angenähert hat. Zum anderen muss in jedem Lernschritt die Gesamtzahl der richtig zugeordneten Daten ermittelt werden. Der Algorithmus arbeitet also nicht lokal, wie für neuronale Netze typisch.
Ist die lineare Separabilität des Trainingsdatensatzes bekannt, so können verschiedene Varianten der Standard-Perzeptron-Lernregel genutzt werden. Das "Perzeptron der optimalen Stabilität" (maximaler Abstand zwischen den Daten mit Ausgabe "0" und "1") kann erzeugt werden mit dem Min-Over-Algorithmus (Krauth und Mezard, 1987)[7]. Ein besonders schneller Algorithmus, der auf quadratischer Optimierung basiert, ist das AdaTron (Anlauf and Biehl, 1989)[8]. Optimale Stabilität, zusammen mit dem Kernel-Trick, sind die konzeptuellen Voraussetzungen der Support Vector Machine.
Das Perzeptron als linearer Klassifikator
Jenseits aller (pseudo-)biologischen Analogien ist ein einlagiges Perzeptron letztlich nichts weiter als ein linearer Klassifikator der Form (lineare Diskriminanzfunktion, multiple lineare Regression). In der Nomenklatur der künstlichen neuronalen Netze werden bis als Gewichte und bis als Eingangssignale bezeichnet, wobei letztere nur Werte von 1 oder 0 („wahr“ oder „falsch“) annehmen können. Überschreitet die Summe einen Schwellenwert, so wird die Zuordnung der gesuchten Klasse auf „wahr“ bzw. 1 gesetzt, sonst auf „falsch“ bzw. 0.






Mehrlagiges Perzeptron
Die Beschränkung des einlagigen Perzeptrons konnte später mit dem mehrlagigen Perzeptron gelöst werden, bei dem es neben der Ausgabeschicht auch noch mindestens eine weitere Schicht verdeckter Neuronen gibt (engl. hidden layer). Sind die Ausgänge nur mit Eingängen einer nachfolgenden Schicht verknüpft, so dass der Informationsfluss nur in einer Richtung verläuft, spricht man von Feed-forward-Netzen. Dabei haben sich folgende Topologien bewährt:
- Fully connected: Die Neuronen einer Schicht werden mit allen Neuronen der direkt folgenden Schicht verbunden.
- Short-Cuts: Einige Neuronen sind nicht nur mit allen Neuronen der nächsten Schicht verbunden, sondern darüber hinaus mit weiteren Neuronen der übernächsten Schichten.
Sind im Netz Neuronen vorhanden, deren Ausgänge mit Neuronen derselben oder einer vorangegangenen Schicht verbunden sind, handelt es sich um ein Rekurrentes neuronales Netz.
Mehrlagige Perzeptronen benötigen komplexere Lernregeln als einlagige Perzeptronen. Backpropagation ist ein möglicher Algorithmus für Überwachtes Lernen.
Die Erweiterung dieser Netztopologien um weitere verborgene Schichten und Einführung anderer Architekturen (zum Beispiel rekurrente neuronale Netze), die ebenfalls meist mittels backpropagation trainiert werden, wird heute unter dem Schlagwort Deep Learning zusammengefasst.
Literatur
- Rosenblatt, Frank (1958): The perceptron: a probabilistic model for information storage and organization in the brain. Psychological Reviews 65 (1958) 386–408
- M. L. Minsky und S. A. Papert, Perceptrons. 2nd Edition, MIT-Press 1988, ISBN 0-262-63111-3
Weblinks
Einzelnachweise
- A logical calculus of the ideas immanent in nervous activity. WS McCulloch, W Pitts. Bull Math. Biophys., 5, 115-133, 1943.
- Organization of Behaviour. D Hebb. Wiley. New York. 1949.
- Frank Rosenblatt: The perceptron – A perceiving and recognizing automaton. Cornell Aeronautical Laboratory, Report No. 85-460-1, Januar 1957. Siehe dazu auch: Frank Rosenblatt: The perceptron – a probabilistic model for information storage and organization in the brain. Psychological Review 65, 1958. doi:10.1037/h0042519
- Michael Nielsen: Chapter 1: Using neural nets to recognize handwritten digits. Abschnitt: Perceptrons. Abgerufen am 9. August 2019 (englisch).
- Andreas Wendemuth: Learning the Unlearnable. In: Journal of Physics A: Math. Gen. 28. 1995, S. 5423–5436 (PDF (Memento vom 5. März 2016 im Internet Archive) [abgerufen am 14. März 2016]).
- S.I. Gallant. Perceptron-based learning algorithms. IEEE Transactions on Neural Networks, vol. 1, no. 2, pp. 179–191 (1990)
- W. Krauth and M. Mezard. Learning algorithms with optimal stabilty in neural networks. J. of Physics A: Math. Gen. 20: L745-L752 (1987)
- J.K. Anlauf and M. Biehl. The AdaTron: an Adaptive Perceptron algorithm. Europhysics Letters 10: 687-692 (1989)