Rekurrentes neuronales Netz
Als rekurrente bzw. rückgekoppelte neuronale Netze bezeichnet man neuronale Netze, die sich im Gegensatz zu den Feedforward-Netzen durch Verbindungen von Neuronen einer Schicht zu Neuronen derselben oder einer vorangegangenen Schicht auszeichnen. Im Gehirn ist dies die bevorzugte Verschaltungsweise neuronaler Netze, insbesondere im Neocortex. In künstlichen neuronalen Netzen wird die rekurrente Verschaltung von Modellneuronen benutzt, um zeitlich codierte Informationen in den Daten zu entdecken.[1][2] Beispiele für solche rekurrenten neuronalen Netze sind das Elman-Netz, das Jordan-Netz, das Hopfield-Netz sowie das vollständig verschaltete neuronale Netz.
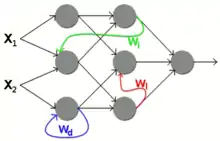



Rekurrente Netze lassen sich folgendermaßen unterteilen:
- Bei einer direkten Rückkopplung (englisch direct feedback) wird der eigene Ausgang eines Neurons als weiterer Eingang genutzt.
- Die indirekte Rückkopplung (englisch indirect feedback) verbindet den Ausgang eines Neurons mit einem Neuron der vorhergehenden Schichten.
- Die seitliche Rückkopplung (englisch lateral feedback) verbindet den Ausgang eines Neurons mit einem anderen Neuron derselben Schicht.
- Bei einer vollständigen Verbindung hat jeder Neuronenausgang eine Verbindung zu jedem anderen Neuron.
Praktische Anwendung finden rekurrente neuronale Netze bei Problemstellungen, die das Verarbeiten von Sequenzen erfordern. Beispiele dafür sind Handschrifterkennung, Spracherkennung und Maschinenübersetzung. Die hierbei vorherrschende Art der rekurrenten neuronalen Netze sind LSTMs beziehungsweise ähnliche Varianten, die auf einer direkten Rückkopplung basieren.
Die Implementierung von Rekurrenten neuronalen Netzen kann in gängigen Programmbibliotheken wie PyTorch bequem in Python erfolgen und dann mit Just-in-time-Kompilierung in effizienten Code übersetzt werden.
Trainieren von rekurrenten neuronalen Netzen
Rekurrente künstliche neuronale Netze sind schwierig durch Methoden des maschinellen Lernens zu trainieren.[3] Ein populärer Ansatz ist es daher, nicht das Netz, sondern das Auslesen des Netzes zu trainieren. Das rekurrente neuronale Netz wird im Rahmen von Reservoir Computing als sogenanntes Reservoir betrachtet. Im Falle von LSTMs werden die Netze durch Backpropagation-Through-Time (siehe Backpropagation) während des Trainingsvorgangs in ein Feedforward-Netz entsprechend der Sequenzlänge umgewandelt.[4] Damit wird die Komplexität des Lernverhaltens ähnlich dem der herkömmlichen Feedforward-Netze.
Ausgangspunkt für die Backpropagation-Through-Time ist, dass die totale Verlustfunktion der Zeitreihe, welche aus Zeitschritten besteht, wie folgt dargestellt werden kann:

- ,

wobei eine Funktion ist, welche die Ausgabe (Output) des Netzwerkens (zum Zeitpunkt ) mit dem Ziel vergleicht und wobei der zeitinvariante Parametervektor des rekurrenten neuronalen Netzes ist. Backpropagation-Through-Time erlaubt durch Anwenden der Kettenregel die Berechnung der (komponentenweisen) totalen Ableitung . Da der Output selbst von Werten des vorherigen Zeitschrittes abhängt und diese von , müssen diese vorherigen Zeitschritte in die Ableitung mit einbezogen werden.









Probleme beim Training von rekurrenten neuronalen Netzen können aufgrund von verschwindenden oder explodierenden Gradienten auftreten. Um diese Probleme zu umgehen, kann Teacher-Forcing angewendet werden, wobei man jedoch den Bias-Exposure tradeoff eingeht[5].
Literatur
- Andreas Zell: Simulation neuronaler Netze. R. Oldenbourg Verlag, München 1997, ISBN 3-486-24350-0.
Einzelnachweise
- Rudolf Kruse et al.: Neuronale Netze | Computational Intelligence. In: Computational Intelligence: Eine methodische Einführung in Künstliche Neuronale Netze, Evolutionäre Algorithmen, Fuzzy-Systeme und Bayes-Netze. Zweite Auflage. Springer-Vieweg, Wiesbaden, 2015, abgerufen am 5. April 2017.
- Rudolf Kruse et al.: Computational Intelligence: Eine methodische Einführung in Künstliche Neuronale Netze, Evolutionäre Algorithmen, Fuzzy-Systeme und Bayes-Netze. Zweite Auflage. Springer-Vieweg, Wiesbaden 2015, ISBN 978-3-658-10903-5, S. 515.
- Reservoir Computing. Reservoir Lab Ghent, 30. Mai 2008, archiviert vom Original am 5. April 2010; abgerufen am 2. April 2010.
- Chris Nicholson, Adam Gibson: A Beginner's Guide to Recurrent Networks and LSTMs - Deeplearning4j: Open-source, distributed deep learning for the JVM. In: deeplearning4j.org. Archiviert vom Original am 16. Juli 2016; abgerufen am 16. Juli 2016.
- Quantifying Exposure Bias for Open-ended Language Generation https://arxiv.org/abs/1905.10617#:~:text=The%20exposure%20bias%20problem%20refers,network%20language%20models%20(LM).