Backpropagation
Backpropagation oder auch Backpropagation of Error bzw. auch Fehlerrückführung[1] (auch Rückpropagierung) ist ein verbreitetes Verfahren für das Einlernen von künstlichen neuronalen Netzen. Es gehört zur Gruppe der überwachten Lernverfahren und wird als Verallgemeinerung der Delta-Regel auf mehrschichtige Netze angewandt. Dazu muss ein externer Lehrer existieren, der zu jedem Zeitpunkt der Eingabe die gewünschte Ausgabe, den Zielwert, kennt. Die Rückwärtspropagierung ist ein Spezialfall eines allgemeinen Gradientenverfahrens in der Optimierung, basierend auf dem mittleren quadratischen Fehler.
Geschichte
Nach verschiedenen Quellen[2][3][4][5] wurden die Grundlagen des Verfahrens im Kontext der Steuerungstheorie hergeleitet durch Prinzipien dynamischer Programmierung, und zwar durch Henry J. Kelley[6] im Jahre 1960 und Arthur E. Bryson im Jahre 1961.[7] 1962 publizierte Stuart Dreyfus eine einfachere Herleitung durch die Kettenregel.[8] Vladimir Vapnik zitiert einen Artikel aus dem Jahre 1963[9] in seinem Buch über Support Vector Machines. 1969 beschrieben Bryson und Yu-Chi Ho das Verfahren als mehrstufige Optimierung dynamischer Systeme.[10][11]
Seppo Linnainmaa publizierte im Jahre 1970 schließlich die allgemeine Methode für automatisches Differenzieren (AD) diskreter Netzwerke verschachtelter differenzierbarer Funktionen.[12][13] Dies ist die moderne Variante des Backpropagation-Verfahrens, welche auch bei dünner Vernetzung effizient ist.[14][15][4][5]
1973 verwendete Stuart Dreyfus Backpropagation, um Parameter von Steuersystemen proportional zu ihren Fehlergradienten zu adjustieren.[16] Paul Werbos erwähnte 1974 die Möglichkeit, dieses Prinzip auf künstliche neuronale Netze anzuwenden,[17] und im Jahre 1982 tat er dies auf die heute weit verbreitete Art und Weise.[18][5] Vier Jahre später zeigten David E. Rumelhart, Geoffrey E. Hinton und Ronald J. Williams durch Experimente, dass diese Methode zu nützlichen internen Repräsentationen von Eingabedaten in tieferen Schichten neuronaler Netze führen kann, was die Grundlage von Deep Learning ist.[19] Eric A. Wan war 1993 der erste,[4] der einen internationalen Mustererkennungswettbewerb durch Backpropagation gewann.[20]
Fehlerminimierung
Beim Lernproblem wird für beliebige Netze eine möglichst zuverlässige Abbildung von gegebenen Eingabevektoren auf gegebene Ausgabevektoren angestrebt. Dazu wird die Qualität der Abbildung durch eine Fehlerfunktion beschrieben, die hier durch den quadratischen Fehler definiert wird:
- .

Dabei ist
- der Fehler,
- die Anzahl der Muster, die dem Netz vorgestellt werden,
- die gewünschte Soll-Ausgabe oder Zielwert (target) und
- die errechnete Ist-Ausgabe (output).




Der Faktor wird dabei lediglich zur Vereinfachung bei der Ableitung hinzugenommen.

Das Ziel ist nun die Minimierung der Fehlerfunktion, wobei aber im Allgemeinen lediglich ein lokales Minimum gefunden wird. Das Einlernen eines künstlichen neuronalen Netzes erfolgt bei dem Backpropagation-Verfahren durch die Änderung der Gewichte, da die Ausgabe des Netzes – außer von der Aktivierungsfunktion – direkt von ihnen abhängig ist.
Algorithmus
Der Backpropagation-Algorithmus läuft in folgenden Phasen:
- Ein Eingabemuster wird angelegt und vorwärts durch das Netz propagiert.
- Die Ausgabe des Netzes wird mit der gewünschten Ausgabe verglichen. Die Differenz der beiden Werte wird als Fehler des Netzes erachtet.
- Der Fehler wird nun wieder über die Ausgabe- zur Eingabeschicht zurück propagiert. Dabei werden die Gewichtungen der Neuronenverbindungen abhängig von ihrem Einfluss auf den Fehler geändert. Dies garantiert bei einem erneuten Anlegen der Eingabe eine Annäherung an die gewünschte Ausgabe.
Der Name des Algorithmus ergibt sich aus dem Zurückpropagieren des Fehlers (engl. error back-propagation).
Herleitung
Die Formel des Backpropagation-Verfahrens wird durch Differenziation hergeleitet: Für die Ausgabe eines Neurons mit zwei Eingaben und erhält man eine zweidimensionale Hyperebene, wobei der Fehler des Neurons abhängig von den Gewichtungen der Eingaben ist. Diese Fehleroberfläche enthält Minima, die es zu finden gilt. Dies kann nun durch das Gradientenverfahren erreicht werden, indem von einem Punkt auf der Oberfläche aus in Richtung des stärksten Abfallens der Fehlerfunktion abgestiegen wird.




Neuronenausgabe
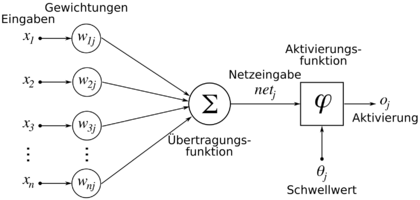
Für die Herleitung des Backpropagation-Verfahrens sei die Neuronenausgabe eines künstlichen Neurons kurz dargestellt. Die Ausgabe eines künstlichen Neurons lässt sich definieren durch



und die Netzeingabe durch


Dabei ist
- eine differenzierbare Aktivierungsfunktion deren Ableitung nicht überall gleich null ist,
- die Anzahl der Eingaben,
- die Eingabe und
- die Gewichtung zwischen Eingabe und Neuron .




Auf einen Schwellwert wird hier verzichtet. Dieser wird meist durch ein immer „feuerndes“ on-Neuron realisiert und dessen Ausgabe mit dem konstanten Wert 1 belegt. Auf diese Weise entfällt eine Unbekannte.

Ableitung der Fehlerfunktion
Die partielle Ableitung der Fehlerfunktion ergibt sich durch Verwendung der Kettenregel:

Aus den einzelnen Termen kann nun die folgende Formel berechnet werden. Dabei ist die Herleitung im Gegensatz zur einfachen Delta-Regel abhängig von zwei Fällen:
- Liegt das Neuron in der Ausgabeschicht, so ist es direkt an der Ausgabe beteiligt,
- liegt es dagegen in einer verdeckten Schicht, so kann die Anpassung nur indirekt berechnet werden.
Konkret:

- mit

Dabei ist
- die Änderung des Gewichts der Verbindung von Neuron zu Neuron ,
- eine feste Lernrate, mit der die Stärke der Gewichtsänderungen bestimmt werden kann,
- das Fehlersignal des Neurons , entsprechend zu ,
- die Soll-Ausgabe des Ausgabeneurons ,
- die Ausgabe des Neurons ,
- die Ist-Ausgabe des Ausgabeneurons und
- der Index der nachfolgenden Neuronen von .






Bei einem einschichtigen Netzwerk ist . Die Ausgabe entspricht dann also den Eingängen des Netzwerks.

Modifizierung der Gewichte
Die Variable geht dabei auf die Unterscheidung der Neuronen ein: Liegt das Neuron in einer verdeckten Schicht, so wird seine Gewichtung abhängig von dem Fehler geändert, den die nachfolgenden Neuronen erzeugen, welche wiederum ihre Eingaben aus dem betrachteten Neuron beziehen.
Die Änderung der Gewichte kann nun wie folgt vorgenommen werden:
- .

Dabei ist
- der neue Wert des Gewichts,
- der alte Wert des Gewichts und
- die oben berechnete Änderung des Gewichts (basierend auf )


Erweiterung
Die Wahl der Lernrate ist wichtig für das Verfahren, da ein zu hoher Wert eine starke Veränderung bewirkt, wobei das Minimum verfehlt werden kann, während eine zu kleine Lernrate das Einlernen unnötig verlangsamt.
Verschiedene Optimierungen von Rückwärtspropagierung, z. B. Quickprop, zielen vor allem auf die Beschleunigung der Fehlerminimierung; andere Verbesserungen versuchen vor allem die Zuverlässigkeit zu erhöhen.
Backpropagation mit variabler Lernrate
Um eine Oszillation des Netzes, d. h. alternierende Verbindungsgewichte zu vermeiden, existieren Verfeinerungen des Verfahrens, bei dem mit einer variablen Lernrate gearbeitet wird.
Backpropagation mit Trägheitsterm
Durch die Verwendung eines variablen Trägheitsterms (Momentum) kann der Gradient und die letzte Änderung gewichtet werden, so dass die Gewichtsanpassung zusätzlich von der vorausgegangenen Änderung abhängt. Ist das Momentum gleich 0, so hängt die Änderung allein vom Gradienten ab, bei einem Wert von 1 lediglich von der letzten Änderung.

Ähnlich einer Kugel, die einen Berg hinunter rollt und deren aktuelle Geschwindigkeit nicht nur durch die aktuelle Steigung des Berges, sondern auch durch ihre eigene Trägheit bestimmt wird, lässt sich der Backpropagation ein Trägheitsterm hinzufügen:

Dabei ist
- die Änderung des Gewichts der Verbindung von Neuron zu Neuron zum Zeitpunkt ,
- eine Lernrate,
- das Fehlersignal des Neurons und
- die Eingabe des Neurons ,
- der Einfluss des Trägheitsterms . Dieser entspricht der Gewichtsänderung zum vorherigen Zeitpunkt.




Damit hängt die aktuelle Gewichtsänderung sowohl vom aktuellen Gradienten der Fehlerfunktion (Steigung des Berges, 1. Summand), als auch von der Gewichtsänderung des vorherigen Zeitpunktes ab (eigene Trägheit, 2. Summand).
Durch den Trägheitsterm werden unter anderem Probleme der Backpropagation-Regel in steilen Schluchten und flachen Plateaus vermieden. Da zum Beispiel in flachen Plateaus der Gradient der Fehlerfunktion sehr klein wird, käme es ohne Trägheitsterm unmittelbar zu einem "Abbremsen" des Gradientenabstiegs, dieses "Abbremsen" wird durch die Addition des Trägheitsterms verzögert, so dass ein flaches Plateau schneller überwunden werden kann.
Sobald der Fehler des Netzes minimal wird, kann das Einlernen abgeschlossen werden und das mehrschichtige Netz ist nun bereit, die erlernten Muster zu klassifizieren.
Biologischer Kontext
Als Verfahren des maschinellen Lernens ist Backpropagation ein mathematisch fundierter Lernmechanismus künstlicher neuronaler Netze und versucht nicht, tatsächliche neuronale Lernmechanismen biologistisch zu modellieren. Es ist kein Resultat neurophysiologischer Experimente und wird deshalb häufig von Neurowissenschaftlern kritisiert. Es gibt keine neurophysiologische Evidenz, die nahelegt, dass Backpropagation oder ein ähnliches Verfahren von biologischen Neuronen benutzt wird (Dies gilt nicht für Gradientenverfahren im Allgemeinen). Im Folgenden werden einige Gründe für die biologische Inplausibilität von Backpropagation dargelegt: (entnommen aus Y. Bengio et al.[21])
- Es ist unklar, wie Information über die Zielwerte in den synaptischen Spalt der letzten Neuronenschicht gelangen kann.
- Biologische Neuronen kommunizieren über binäre Zustandsänderungen (spikes), nicht über kontinuierliche Werte.
- Biologische Neuronen sind zeitsensibel, d. h. ihre Aktivität variiert nicht nur abhängig von der Intensität der Eingangs-Informationen, sondern von dessen Zeitverhalten ("timing") (Spike Time Dependent Plasticity, STDP).
- Backpropagation setzt zeitlich perfekt synchronisierte, diskrete Schritte voraus.
- Ein potenzieller Feedbackmechanismus müsste über die exakten, nicht-linearen Ableitungen der, im Gehirn in Struktur und Selektivität immens variierenden, Neuronen im Vorwärtsteil verfügen.
- Der Feedbackmechanismus müsste über exakt symmetrische Gewichte verfügen (weight transport problem).
Siehe auch
Literatur
- David E. Rumelhart, Geoffrey E. Hinton, Ronald J. Williams: Learning representations by back-propagating errors. In: Nature. Band 323, 1986, S. 533–536 (nature.com).
- Raúl Rojas: Theorie der Neuronalen Netze. Springer, 1996, ISBN 3-540-56353-9. (E-Book der englischen Version; PDF; 4,6 MB), S. 151 ff.
- Burkhard Lenze: Einführung in die Mathematik neuronaler Netze. Logos-Verlag, Berlin 2003, ISBN 3-89722-021-0.
- Robert Callan: Neuronale Netze im Klartext. Pearson Studium, München 2003.
- Andreas Zell: Simulation neuronaler Netze. R. Oldenbourg Verlag, München 1997, ISBN 3-486-24350-0.
Weblinks
- Michael Nielsen: Neural Networks and Deep Learning Determination Press 2015 (Kapitel 2, e-book)
- Backpropagator’s Review (lange nicht gepflegt)
- Ein kleiner Überblick über Neuronale Netze (David Kriesel) – kostenloses Skriptum in Deutsch zu Neuronalen Netzen. Reich illustriert und anschaulich. Enthält ein Kapitel über Backpropagation samt Motivation, Herleitung und Variationen wie z. B. Trägheitsterm, Lernratenvariationen u. a.
- Membrain: freier Neuronale-Netze-Editor-und-Simulator für Windows
- Leicht verständliches Tutorial über Backpropagation mit Implementierungen (englisch)
- Blogbeitrag zum Thema Backpropagation und Gradient Descent inkl. Programmierbeispiele
Quellen
- Werner Kinnebrock: Neuronale Netze: Grundlagen, Anwendungen, Beispiele. R. Oldenbourg Verlag, München 1994, ISBN 3-486-22947-8.
- Stuart Dreyfus: Artificial Neural Networks, Back Propagation and the Kelley-Bryson Gradient Procedure. In: J. Guidance, Control and Dynamics. 1990.
- Eiji Mizutani, Stuart Dreyfus, Kenichi Nishio: On derivation of MLP backpropagation from the Kelley-Bryson optimal-control gradient formula and its application. In: Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN 2000). Como Italy, July 2000. (online) (Seite nicht mehr abrufbar, Suche in Webarchiven) Info: Der Link wurde automatisch als defekt markiert. Bitte prüfe den Link gemäß Anleitung und entferne dann diesen Hinweis.
- Jürgen Schmidhuber: Deep learning in neural networks: An overview. In: Neural Networks. 61, 2015, S. 85–117. ArXiv
- Jürgen Schmidhuber: Deep Learning. In: Scholarpedia. 10(11), 2015, S. 328–332. Section on Backpropagation
- Henry J. Kelley: Gradient theory of optimal flight paths. In: Ars Journal. 30(10), 1960, S. 947–954. (online)
- Arthur E. Bryson: A gradient method for optimizing multi-stage allocation processes. In: Proceedings of the Harvard Univ. Symposium on digital computers and their applications. April 1961.
- Stuart Dreyfus: The numerical solution of variational problems. In: Journal of Mathematical Analysis and Applications. 5(1), 1962, S. 30–45. (online)
- A. E. Bryson, W. F. Denham, S. E. Dreyfus: Optimal programming problems with inequality constraints. I: Necessary conditions for extremal solutions. In: AIAA J. 1, 11, 1963, S. 2544–2550.
- Stuart Russell, Peter Norvig: Artificial Intelligence A Modern Approach. S. 578 (englisch): “The most popular method for learning in multilayer networks is called Back-propagation.”
- Arthur Earl Bryson, Yu-Chi Ho: Applied optimal control: optimization, estimation, and control. Blaisdell Publishing Company or Xerox College Publishing, 1969, S. 481.
- Seppo Linnainmaa: The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master’s Thesis (in Finnish), Univ. Helsinki, 1970, S. 6–7.
- Seppo Linnainmaa: Taylor expansion of the accumulated rounding error.In: BIT Numerical Mathematics. 16(2), 1976, S. 146–160.
- Andreas Griewank: Who Invented the Reverse Mode of Differentiation? Optimization Stories. In: Documenta Matematica. Extra Volume ISMP, 2012, S. 389–400.
- Andreas Griewank, Andrea Walther: Principles and Techniques of Algorithmic Differentiation. 2. Auflage. SIAM, 2008.
- Stuart Dreyfus: The computational solution of optimal control problems with time lag. In: IEEE Transactions on Automatic Control. 18(4), 1973, S. 383–385.
- Paul Werbos: Beyond regression: New tools for prediction and analysis in the behavioral sciences. PhD thesis. Harvard University 1974.
- Paul Werbos: Applications of advances in nonlinear sensitivity analysis. In: System modeling and optimization. Springer, Berlin/ Heidelberg 1982, S. 762–770. (online)
- David E. Rumelhart, Geoffrey E. Hinton, Ronald J. Williams: Learning representations by back-propagating errors. In: Nature. Band 323, 1986, S. 533–536.
- Eric A. Wan: Time series prediction by using a connectionist network with internal delay lines. In: Santa Fe Institute Studies in the Sciences of Complexity-Proceedings. Vol. 15, Addison-Wesley Publishing Co., 1993, S. 195–195.
- Y. Bengio et al.: Towards Biologically Plausible Deep Learning. arxiv:1502.04156 2016.